[AI人脸替换] docs | 环境部署指南 | 用户界面解析
链接:https://deeplivecam.net/

docs:Deep-Live-Cam
Deep Live Cam是一款基于AI技术的应用程序,专注于**人脸替换与增强**功能,支持静态图像、视频文件及实时摄像头画面处理。
该项目为艺术创作者提供工具支持,可实现自定义角色动画化或模型化应用。通过集成NSFW内容检测模块,系统能主动拦截不当媒体内容,确保AI媒体生成的伦理合规性。
系统架构
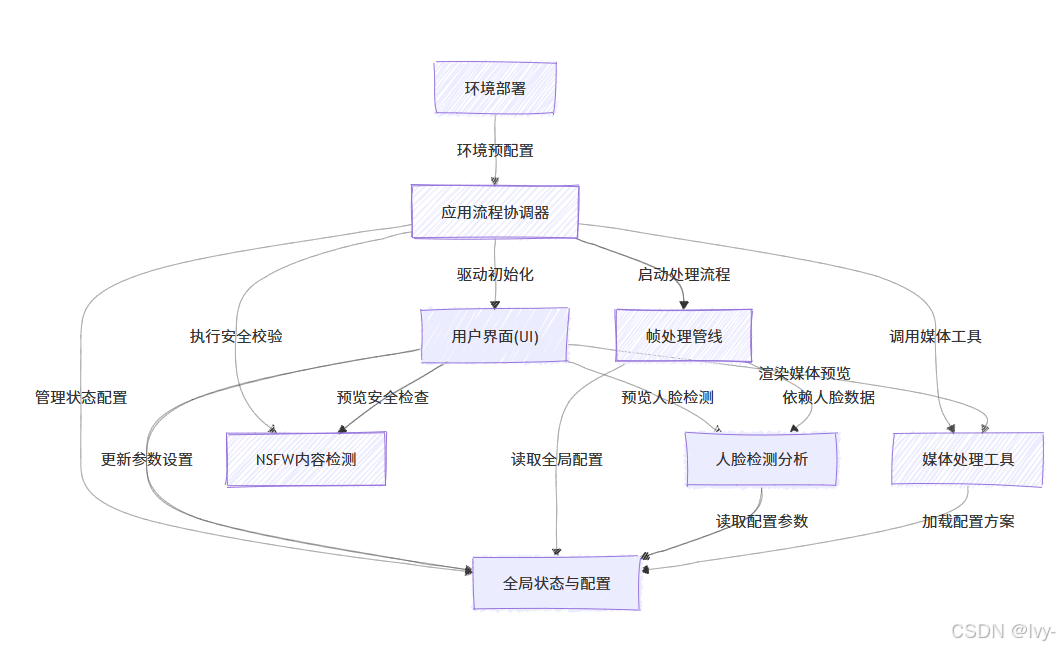
章节导航
- 环境部署指南
- 用户界面解析
- 流程协调器原理
- 全局配置体系
- 媒体处理工具链
- NSFW检测模块
- 帧处理管线
- 人脸分析引擎
应用:(笑嘻嘻belike bush…)
第1章:环境部署指南
想象你即将组装一套乐高模型,在拼接积木前需要完成三项准备工作:
- 工具准备:需要专用拼装垫、拆件器和说明书
- 零件清点:确保所有特定积木齐全
- 空间整理:清理工作台并保证照明充足
本章"环境部署指南"正是Deep Live Cam软件的前置工作,我们将像施工队一样为计算机做好运行准备:安装基础软件、获取项目代码、配置AI模型,最终完成可运行环境的搭建。
环境部署核心要素
该过程确保计算机具备软件运行所需的所有组件:
- 基础软件安装:部署Python(开发语言)和Git(代码管理工具)
- 项目代码获取:从GitHub克隆代码仓库到本地
- AI模型下载:获取实现人脸替换/图像增强的预训练模型
- 依赖库配置:安装项目所需的Python扩展包
- 性能加速选配:启用GPU加速提升处理速度(需硬件支持)
Windows用户可使用自动化脚本setup_deep_live_cam.bat完成主要步骤,其他系统用户或需要精细控制的开发者可参考手动配置流程。
基础安装流程
1. 核心工具准备
首先确保系统已安装下列基础组件:
- Python 3.10(推荐版本):
where python >nul 2>&1 if %ERRORLEVEL% neq 0 (echo 未检测到Python,请安装Python 3.10或更高版本pauseexit /b ) - Pip(Python包管理工具):
where pip >nul 2>&1 if %ERRORLEVEL% neq 0 (echo 未检测到Pip,请通过Python安装包添加pauseexit /b ) - Git(代码版本控制):
where git >nul 2>&1 if %ERRORLEVEL% neq 0 (echo 正在通过winget安装Git...winget install --id Git.Git -e --source winget ) - FFmpeg(多媒体处理):
where ffmpeg >nul 2>&1 if %ERRORLEVEL% neq 0 (echo 正在通过winget安装FFmpeg...winget install --id Gyan.FFmpeg -e --source winget ) - Visual Studio 2022运行库(Windows必需组件):
winget install --id Microsoft.VC++2015-2022Redist-x64 -e --source winget
2. 代码仓库克隆
通过Git获取项目源代码:
git clone https://github.com/hacksider/Deep-Live-Cam.git
cd Deep-Live-Cam
若目录已存在,脚本会提示是否覆盖:
if exist Deep-Live-Cam (set /p overwrite="目录已存在,是否覆盖?(Y/N): "if /i "%overwrite%"=="Y" rmdir /s /q Deep-Live-Cam
)
3. AI模型部署
创建模型目录并下载必需文件:
mkdir models
curl -L -o models/GFPGANv1.4.pth https://huggingface.co/hacksider/deep-live-cam/resolve/main/GFPGANv1.4.pth
curl -L -o models/inswapper_128_fp16.onnx https://huggingface.co/hacksider/deep-live-cam/resolve/main/inswapper_128_fp16.onnx
4. 虚拟环境配置
建议使用虚拟环境隔离依赖:
python -m venv venv
call venv\Scripts\activate
pip install --upgrade pip
pip install -r requirements.txt
完成基础安装后,可通过以下命令启动应用:
python run.py
GPU加速配置
不同显卡类型的加速方案:
| 显卡类型 | 执行提供商 | 关键安装步骤 | 启动参数 |
|---|---|---|---|
| NVIDIA显卡 | cuda | 安装CUDA Toolkit 11.8后执行:pip install onnxruntime-gpu==1.16.3 | --execution-provider cuda |
| 苹果M系列 | coreml | pip install onnxruntime-silicon | --execution-provider coreml |
| Windows | directml | pip install onnxruntime-directml | --execution-provider directml |
| Intel | openvino | pip install onnxruntime-openvino | --execution-provider openvino |
自动化脚本解析
setup_deep_live_cam.bat脚本工作流程:
环境验证
完成安装后,建议运行测试命令验证环境完整性:
python -c "import onnxruntime; print(onnxruntime.get_device())"
应返回当前使用的计算设备信息(如CPU/GPU型号)。
下一章:用户界面解析
第2章:用户界面解析
在第1章:环境部署指南中,我们已成功搭建运行环境并安装所有必备组件。
现在,让我们来探索这个AI工具的控制中枢——用户界面(UI)。
UI设计理念
用户界面如同汽车的驾驶舱,将复杂的AI技术封装为直观的可视化操作面板:
- 控制中枢:通过点击按钮替代命令行输入
- 信息看板:实时显示文件选择状态和处理进度
- 效果预览窗:动态展示人脸替换/增强效果
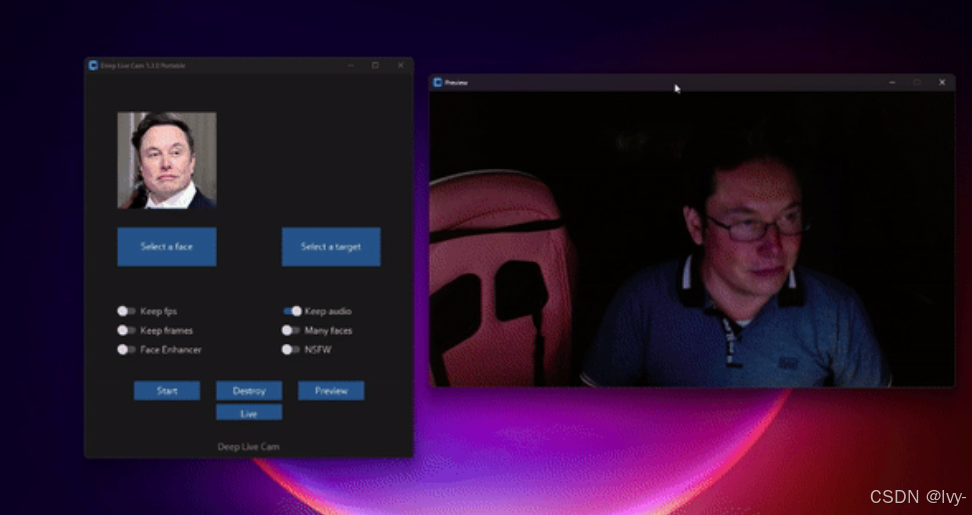
核心功能模块:
- 源人脸选择区(
Select a face) - 目标媒体选择区(
Select a target) - 功能开关组:
Face Enhancer:人脸增强开关Many faces:多人脸处理模式NSFW:内容安全过滤器(默认开启)
- 操作按钮组:
Start:启动处理Preview:实时预览Live:摄像头实时模式
基础操作流程
静态图片处理示例
-
启动UI
python run.py -
选择源人脸
- 点击
Select a face按钮 - 选择含有人脸的图片(如
my_face.jpg) - 预览图将显示在源区域
- 点击
-
选择目标图片
- 点击
Select a target按钮 - 选择待替换人脸的图片(如
target.png)
- 点击
-
配置处理参数
- 启用
Face Enhancer提升画质 - 保持
Many faces关闭(单人脸模式)
- 启用
-
执行处理
- 点击
Start按钮 - 设置输出路径(如
output_swapped.png) - 状态栏显示处理进度
- 点击
实时摄像头模式
- 完成源人脸选择
- 点击
Live按钮 - 系统将:
- 调用默认摄像头设备
- 实时处理视频流(30fps)
- 在独立窗口展示动态效果
技术实现剖析
文件选择模块
# modules/ui.py
def select_source_path():global RECENT_DIRECTORY_SOURCEsource_path = ctk.filedialog.askopenfilename(title='选择源人脸图片',filetypes=[('JPEG文件', '*.jpg'), ('PNG文件', '*.png')])if source_path:modules.globals.source_path = source_path # 更新全局状态preview_image = render_thumbnail(source_path) # 生成缩略图source_label.configure(image=preview_image) # 更新UI显示
功能开关逻辑
enhancer_switch = ctk.CTkSwitch(master=root,text='人脸增强',command=lambda: update_config('face_enhancer', switch_value.get())
)
开关状态变更时,通过update_config函数更新全局配置字典:
modules.globals.fp_ui['face_enhancer'] = enabled
实时预览实现
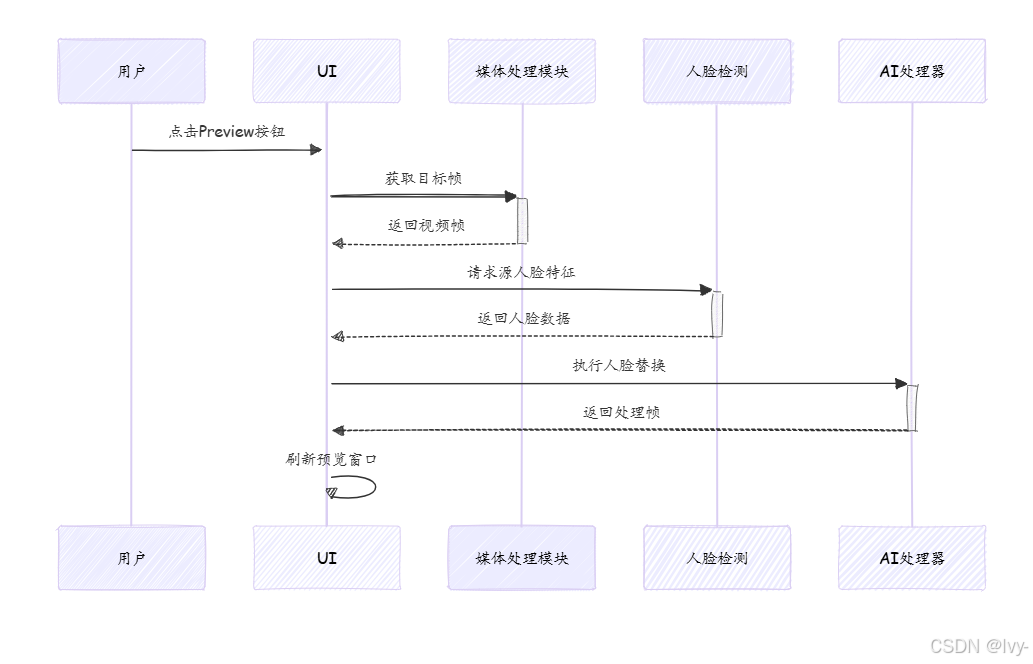
核心交互流程
完整操作的状态变迁:
安全机制
NSFW内容检测在预览和输出阶段自动执行:
if not modules.globals.nsfw:from modules.predicter import predict_frameif predict_frame(temp_frame):show_warning("内容安全警告")return
下一章:应用流程协调器