Day17_【机器学习—特征预处理(归一化和标准化)】
一、特征预处理简介
在机器学习中,特征预处理(Feature Preprocessing)是建模流程特征工程中的至关重要的一步。原始数据往往存在缺失、量纲不一、分布不均、类别不可用等问题,直接用于模型训练会导致性能下降、收敛缓慢甚至模型失效。因此,必须对特征进行系统性的预处理,以提升模型的稳定性、准确性和训练效率。
可分为:归一化处理(了解)、标准化处理(重点)
二、标准化 (重点掌握)
📌 定义:
标准化是将特征值转换为均值为 0、标准差为 1 的分布。
📌 公式:
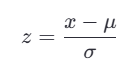
- x:原始值
- μ:该特征的均值
- σ:该特征的标准差
- z:标准化后的值
🧮 示例:
假设某特征“身高”(单位:cm)的均值 μ=170,标准差 σ=10,某个样本身高为 180 cm:
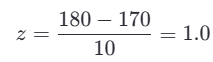
表示该值比平均身高高 1 个标准差。
✅ 优点:
- 不受数据绝对值大小影响
- 对异常值相对稳健(相比归一化)
- 适用于大多数机器学习算法
🔍 适用场景(重点!):
- 基于距离的模型:如 KNN、K-Means、SVM
- 基于梯度下降的模型:如线性回归、逻辑回归、神经网络
- 特征近似服从正态分布时效果更好
⚠️ 注意:标准化不保证数据在固定区间(如 [0,1]),可能仍有负值或超出范围。
二、归一化(了解即可)
⚠️ 注意:在机器学习中,“归一化”通常指 Min-Max Scaling,不是向量单位化。
📌 定义:
将特征值缩放到一个固定的区间,通常是 [0, 1]。
📌 公式:
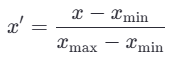
- x:原始值
- xmin、xmax:该特征的最小值和最大值
- x′:归一化后的值(在 [0,1] 区间)
🧮 示例:
某特征“分数”范围是 50~95,某个学生得分为 80:
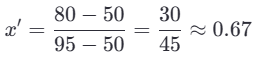
✅ 优点:
- 所有特征统一到 [0,1] 区间,便于比较
- 适合有明确边界的数据(如图像像素 0~255)
❌ 缺点:
- 对异常值敏感:如果出现一个极大或极小的异常值,会导致其他数据被压缩到很小的区间
- 不适用于数据范围可能变化的场景
📌 适用场景:
- 神经网络输入层(常配合 Sigmoid 激活函数)
- 图像处理(像素值归一化)
- 数据有明确物理边界时
三、标准化 vs 归一化 对比表
| 对比项 | 标准化(Standardization) | 归一化(Normalization) |
|---|---|---|
| 目标分布 | 均值为 0,标准差为 1 | 缩放到 [0, 1] 区间 |
| 是否保留原始分布形状 | 是(线性变换) | 是(线性变换) |
| 是否受异常值影响 | 相对较小(用标准差) | 很大(依赖最大/最小值) |
| 是否可能有负值 | ✅ 是(通常有负值) | ❌ 否(缩放到 [0,1]) |
| 适用模型 | KNN、SVM、线性模型、神经网络等 | 神经网络、图像处理、有边界数据 |
| 公式依赖 | 均值 μμ、标准差 σσ | 最小值、最大值 |
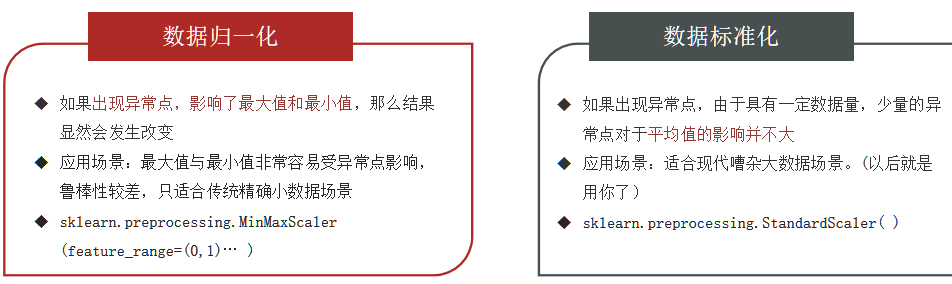
四、在 Python 中的使用(scikit-learn)
标准化
'''标准化'''
from sklearn.preprocessing import StandardScalertf = StandardScaler()
data = [[90, 2, 10, 40],[60, 4, 15, 45],[75, 3, 13, 46]]
new_data = tf.fit_transform(data)
print(new_data)归一化
from sklearn.preprocessing import MinMaxScaler# 1.准备特征数据
data = [[90, 2, 10, 40],[60, 4, 15, 45],[75, 3, 13, 46]]
# 2.创建归一化对象
tf = MinMaxScaler()
# 3.具体归一化动作
new_data = tf.fit_transform(data)
# 4.打印归一化结果
print(new_data)