HTML应用指南:利用POST请求获取全国中国工商银行网点位置信息
中国工商银行(Industrial and Commercial Bank of China, ICBC)作为全球资产规模领先的大型国有商业银行,始终秉持“服务创造价值”的经营理念,致力于为个人客户、企业客户及机构客户提供全面、稳健、高效的综合金融服务。依托持续完善的物理渠道与数字化服务双轮驱动战略,工商银行已构建起覆盖全国、延伸海外的庞大服务网络,形成以总分行管理为核心、营业网点为基础、自助设备与线上平台为延伸的多层次服务体系。
营业网点作为工商银行线下服务的关键节点,不仅是办理存取款、贷款、理财、结算等核心银行业务的重要载体,更是展示品牌形象、推广金融产品、开展客户关系管理与提供专业化咨询的综合服务平台。各营业网点严格执行统一的标准化服务流程与视觉识别系统,注重服务环境的安全性、舒适性与智能化建设,积极引入智能柜员机、远程视频柜员等科技设备,持续提升客户体验与服务效率。
本文将探讨如何通过程序化方式,利用 POST 请求调用公开接口,从工商银行相关服务平台获取营业网点分布数据。通过 Python 的 requests 库发送 HTTP 请求,解析返回的 JSON 结构化数据,提取网点名称、所属行政区、详细地址、营业时间、服务功能等关键字段,实现对网点信息的自动化采集。该数据可广泛应用于分析工商银行的区域渠道布局策略、服务密度演变趋势、城乡金融资源配置均衡性等课题,为金融地理研究、银行网点规划优化及智慧城市建设提供有力的数据支持。
中国工商银行网点查询网址:网点查询
首先,我们找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
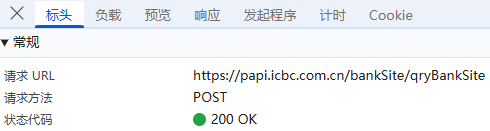
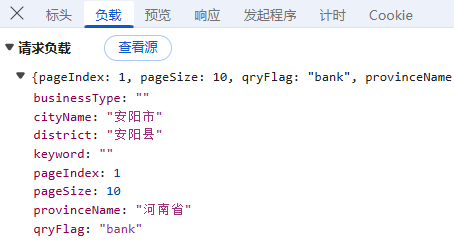
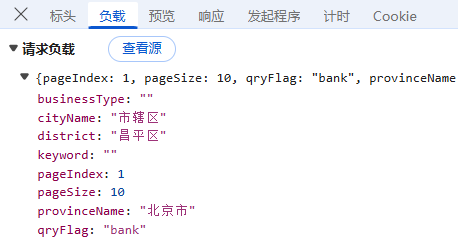
负载:对于POST请求:负载通常包含了传递的参数,因为所有参数都通过URL传递,这里我们可以看到省份、地级市的名称,页面码,每页数量,没有进行加密;
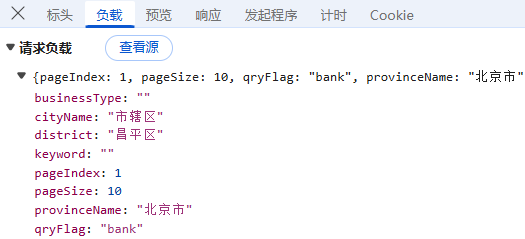
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,我们可以看到数据在list里;
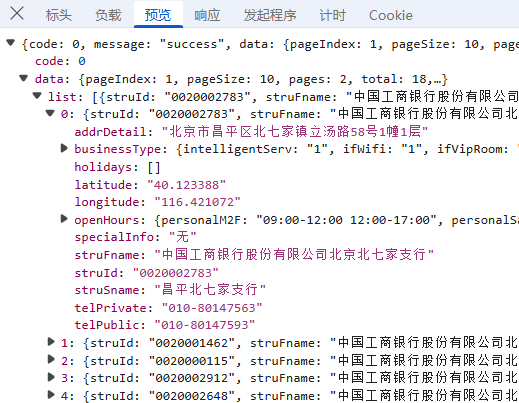
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取省级行政区、地级行政区、县级行政区表数据;
- 我们通过requests库发送HTTP请求,来遍历全国网点的标签数据;
- 地理编码→地址转经纬度,再通过coord-convert库实现BD09转WGS84;
首先,我们观察到它的查询方式依然是通过不同行政区层级进行网点查询,那我们直接在"Fetch/XHR"先找到对应数据存储位置, 我们可以看到响应请求包含省级行政区名、市级行政区等对应内容的响应请求,另外,根据上面负载的内容,我们可以知道,数据是直接通过行政区名称进行传递的;

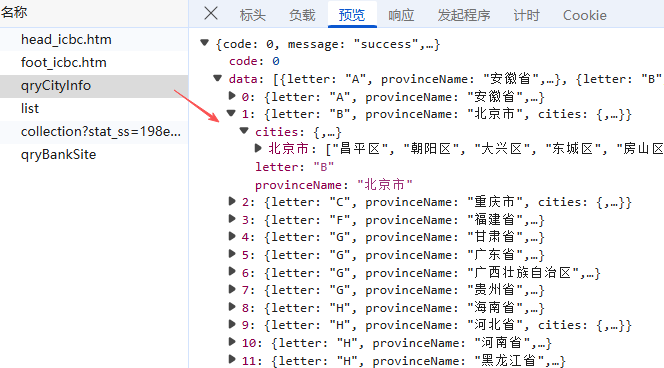
因为网点查询页面的负载包括省级行政区、地级行政区、县级行政区名称,所以我们通过修改行政区名称来进行数据获取,为了方便我们可以建立一个包含省级行政区、地级行政区、县级行政的三级行政区字典,通过遍历行政区名称来查询全国数据;
第一步:利用requests库发送HTTP请求获取所有省级行政区、地级行政区、和县级行政区的三级行政区表,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
import csv
from datetime import datetimeurl = "https://papi.icbc.com.cn/bankSite/qryCityInfo"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}# 获取数据并生成行
rows = []
res = requests.post(url, headers=headers).json()
for item in res['data']:p = item['provinceName']for c, districts in item['cities'].items():rows.extend({'provinceName': p, 'cityName': c, 'district': d} for d in districts)# 保存为CSV
filename = f"icbc_cities.csv"
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:writer = csv.DictWriter(f, fieldnames=['provinceName', 'cityName', 'district'])writer.writeheader()writer.writerows(rows)print(f"数据已保存至 {filename},共 {len(rows)} 条记录。")
数据会以csv表格的形式,保存在运行脚本的目录下,数据标签包括:provinceName(省级行政区)、cityName(地级行政区)、 district(县级行政区);
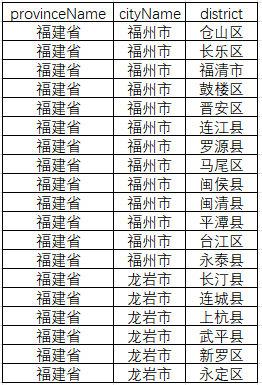
这里有一个tips:1、如果遇到直辖市,需要把对应的cityname 改成市辖区,这里包括"北京市、上海市、重庆市、天津市";
第二步:利用POST请求获取所有银行网点数据,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
import requests
import csv
from datetime import datetime# 配置
URL = "https://papi.icbc.com.cn/bankSite/qryBankSite"
HEADERS = {'content-type': 'application/json','user-agent': 'Mozilla/5.0','x-tag-papi': 'gray'
}
OUTPUT = f"icbc_all_branches.csv"def fetch_branches(province, city, district):payload = {"pageIndex": 1, "pageSize": 10, "qryFlag": "bank","provinceName": province, "cityName": city, "district": district}branches = []try:resp = requests.post(URL, json=payload, headers=HEADERS, timeout=10)data = resp.json()["data"]for page in range(1, data["pages"] + 1):if page > 1:payload["pageIndex"] = pagedata = requests.post(URL, json=payload, headers=HEADERS).json()["data"]for site in data["list"]:branches.append({"省份": province, "城市": city, "区县": district,"网点名称": site["struFname"], "简称": site["struSname"],"地址": site["addrDetail"], "电话": site.get("telPublic", ""),"经度": site["longitude"], "纬度": site["latitude"],"个人营业时间": site["openHours"]["personalM2F"],"对公营业时间": site["openHours"].get("compM2f", "")})except: pass # 失败则返回空列表return branches# 主流程
print("开始查询所有网点...")
all_branches = []with open('icbc_cities.csv', encoding='utf-8-sig') as f:reader = csv.DictReader(f)for row in reader:r = [row['provinceName'], row['cityName'], row['district']]print(f"{r[0]} - {r[1]} - {r[2]}")all_branches.extend(fetch_branches(*r))# 保存结果
with open(OUTPUT, "w", encoding="utf-8-sig", newline="") as f:writer = csv.DictWriter(f, fieldnames=all_branches[0].keys() if all_branches else [])writer.writeheader()writer.writerows(all_branches)print(f"完成!共 {len(all_branches)} 条数据,已保存至 {OUTPUT}")
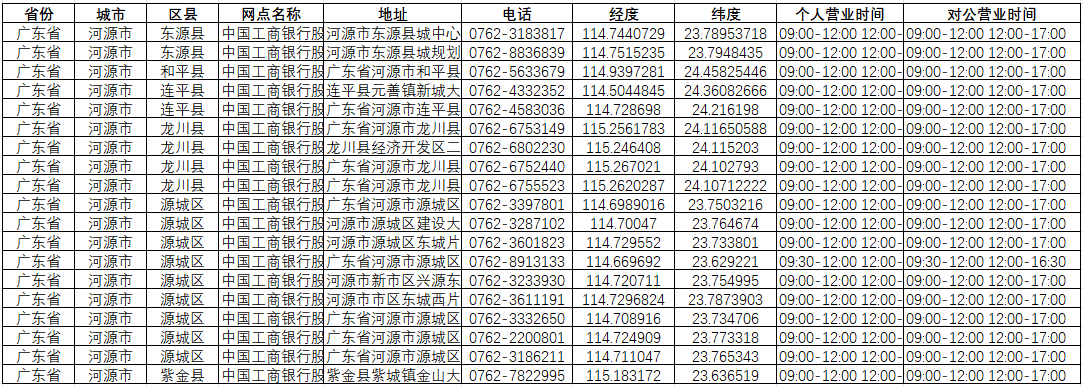
获取数据标签如下:省份、城市、区县、网点名称、地址、电话、经度、纬度、个人营业时间、对公营业时间,其他一些非关键标签,这里省略;
第三步:坐标系转换,由于中国工商银行网点数据使用的是百度坐标系(BD09),为了在ArcGIS上准确展示而不发生偏移,我们需要将网点的坐标从BD09转换为WGS-84坐标系。我们可以利用coord-convert库中的bd2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具;
对CSV文件中的网点坐标列进行转换,完成坐标转换后,再将数据导入ArcGIS进行可视化;
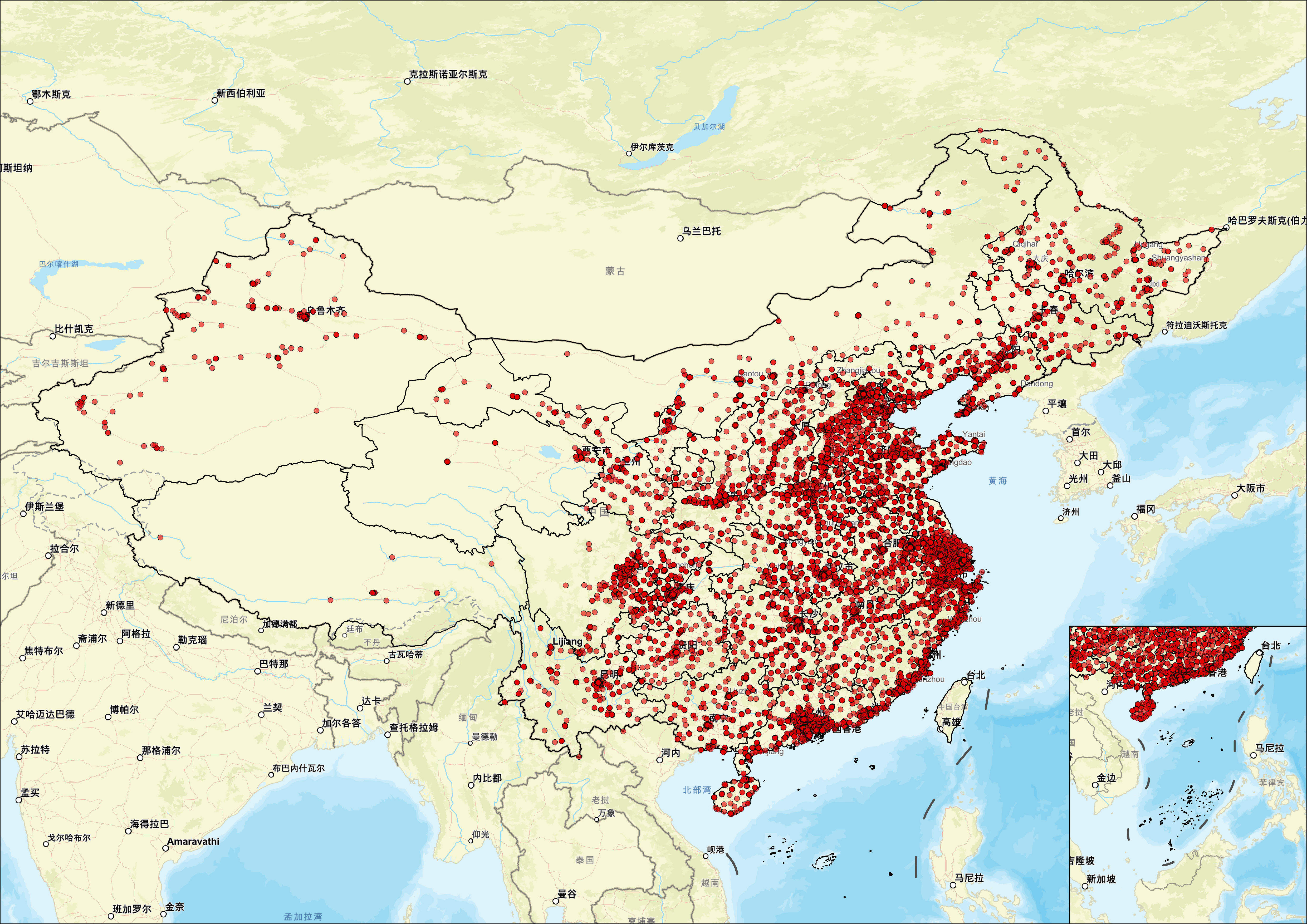
接下来,我们进行看图说话:
地理分布密度差异显著
首先,东部沿海地区的网点分布极为密集。如广东、江苏、浙江、山东等省份,这些地区经济发达,人口稠密,商业活动频繁,对金融服务的需求量大。相比之下,中部地区如河南、湖北、湖南等地,网点分布也较为密集,但相对东部沿海地区略显稀疏。这反映了中部地区的经济发展水平较高,城市化进程较快,金融服务需求较大。而西部和东北部地区,如新疆、青海、西藏、黑龙江等省份的网点分布明显较少。这些地区地广人稀,经济发展相对滞后,人口密度较低,因此对银行网点的需求相对较小。
城市与农村分布差异
在城市与农村的对比中,可以看到大城市和省会城市如北京、上海、广州、深圳等一线城市的网点分布非常密集,几乎覆盖了城市的各个角落。这表明大城市作为经济中心和人口聚集地,对金融服务的高需求。而在中小城市和县城,网点分布虽然相对均匀,但仍有一定的集中趋势,主要集中在城区和经济较发达的乡镇。至于农村地区,网点分布则较为稀疏,尤其是在偏远山区和农业为主的地区,银行网点数量较少,金融服务覆盖面有限。
经济发展水平与网点分布的相关性
值得注意的是,经济发达地区如长三角(上海、江苏、浙江)、珠三角(广东)、京津冀(北京、天津、河北)等区域,网点分布最为密集。这些地区GDP总量大,企业众多,居民收入水平高,金融交易频繁,对银行服务的需求旺盛。相反,在经济欠发达地区,如西北、西南的部分省份,网点分布较少,反映出这些地区经济基础薄弱,产业结构单一,居民收入水平较低,金融需求相对较少。
人口密度与网点分布的关系
此外,人口稠密区如东南沿海、中部平原等人口密集地区,网点分布较多,这是因为这些地区人口基数大,消费能力强,对金融服务的需求量大。而在人口稀疏区,如西北高原、东北林区等人口少的地方,网点分布较少,交通不便,金融服务的可达性较差。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。