【C++高并发内存池篇】ThreadCache 极速引擎:C++ 高并发内存池的纳秒级无锁革命!
📌本篇摘要
-
📝本篇为高并发内存池项目的正式开篇,通过把项目拆成一部分一部分去实现,这里会分成
ThreadCache,CentralCache,PageCache等三部分去分部实现内存池,这里就通过一步步分析来简单实现ThreadCache这步(可能会不完整,后续继续补充),欢迎阅读!

🏠欢迎拜访🏠:
点击进入博主主页
📌本篇主题📌:ThreadCache框架部分简单实现
📅制作日期📅: 2025.08.25
🧭隶属专栏🧭:点击进入所属C++高并发内存池项目专栏
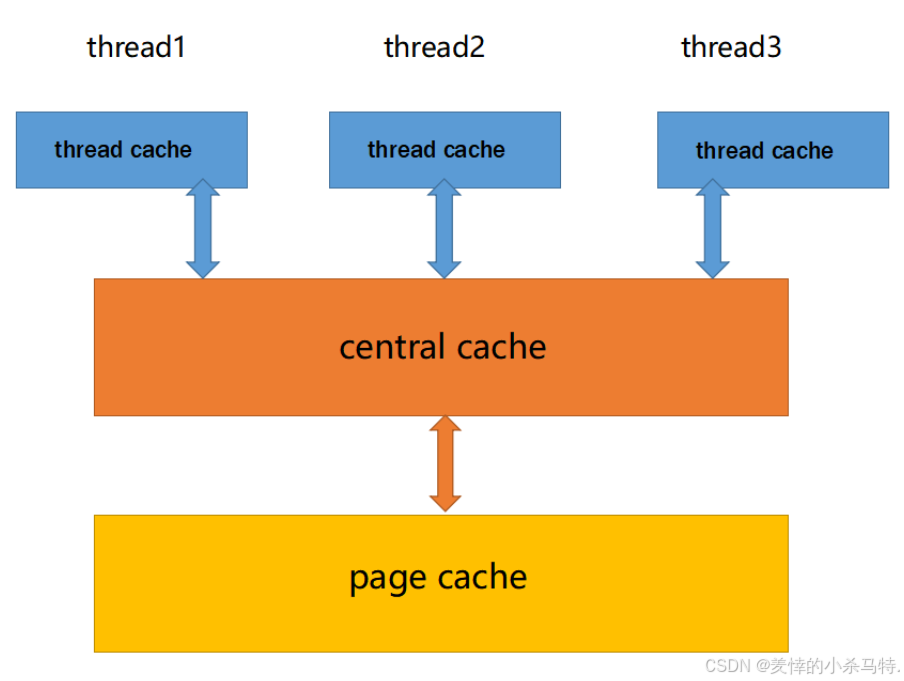
一· 💡concurrent memory pool整体轮廓分析
分为三部分:
-
线程缓存(ThreadCache):。每个线程独有,用于分配小于256KB的内存,申请内存无需加锁,独享特性使并发线程池高效。 -
中心缓存(CentralCache):所有线程共享,ThreadCache能按需从其获取对象,CentralCache也负责回收ThreadCache对象以均衡内存分配,因存在竞争,取内存对象需加桶锁,但竞争不激烈。 -
页缓存(PageCache):位于CentralCache上层,以页为单位存储分配内存,CentralCache无对象时从其分配page并切割给CentralCache,回收符合条件的span对象并合并相邻页缓解内存碎片问题 。
⚠️需注意问题
- 性能问题。
- 多线程环境下,锁竞争问题。
- 内存碎⽚问题。
总之,从整体我们可以看出来,把整个项目的实现分成了三部分,而这三部分,它们两两之间都是有交互的,下面我们就从ThreadCache开始实现!
二· 🔍ThreadCache设计
🎆设计思想
threadcache是哈希桶结构,每个桶是⼀个按桶位置映射⼤⼩的内存块对象的⾃由链表。每个线程都会有⼀个threadcache对象,这样每个线程在这⾥获取对象和释放对象时是⽆锁的。
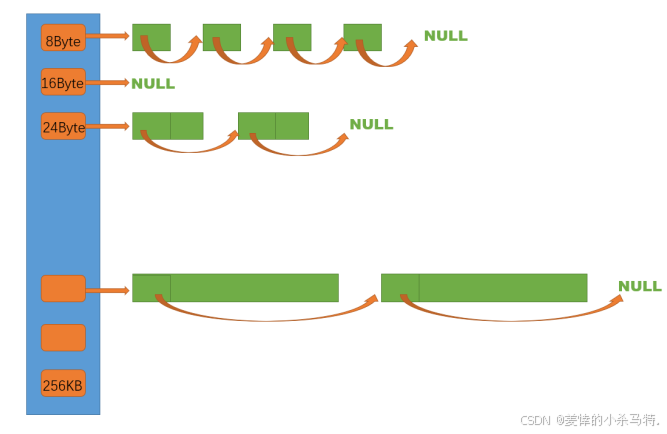
这里拥有对应大小的内存块都是有一定规律的,按照对应对齐数排布的(后面会说到的),这样虽然缓解了外碎片问题,但避免不了出现内碎片的问题!
目前,我们设计的这个简单的ThreadCache功能就分为两步:申请与释放内存(后续需要再进行补充)。
-
申请内存:要申请 ≤256KB 的内存时,先找线程本地的threadcache,按内存大小算出自由链表下标 i;要是自由链表 _freeLists[i] 里有内存对象,直接拿一个出来用;要是 _freeLists[i] 里没对象,就从central cache批量拿一些,放进链表里,再拿一个出来用。 -
释放内存:要释放小于 256k 的内存时,把它放回thread cache,按大小算出自由链表桶位置 i,把对象推进_freeLists[i];要是链表太长了,就回收一部分内存对象到central cache。
📝 代码设计
- 首先我们还是
先描述后组织;发现可以把这个threadcache拆成几个部分:一个就是放不同块大小的链表freelist;一个就是这些链表的集合;因此我们先来实现freelist;之后再把这些链表组织起来就成了threadcache了。
✅ FreeList设计
- 这里只需要支持我们
删除(拿到对应内存块)以及插入(还回对应内存块)即可,用到的是我们之前定长内存池设计的去前指针大小字节保存下一个地址的方式进行的;而这个内存块链表不仅threadcache这里用到后面Centralcache也会用到,因此我们把它放到common公共类里面方便使用!
🛠️内存块链表整体代码实现:
class FreeList {
public:// FreeList(){}// //这里不给它写构造,否则因为多个freelist的话初始化就会多次调用,然后没给_freelist初始化,就走缺省参数变成nullptr//然后就需要重复FREELIST_NUMS次;因此这里直接不写了只给个缺省参数,这样调试看起来就不会显示来回跳转初始化freelist数组的过程了,方便观察!//获得不用大小的内存块void Push(void* ptr) {//头插:assert(ptr);*(void**)ptr= _freelist;_freelist = ptr;}//弹出对应大小内存块void* Pop() {//头删:assert(_freelist);void* next = *(void**)_freelist;void* obj = _freelist;_freelist = next;return obj;}bool empty() { return _freelist==nullptr; }~FreeList(){}
private:void* _freelist=nullptr;
};
✅ ThreadCache设计
大致思路:这里对于线程申请内存就往threadcache要,然后它就会向底层的freelist要,如果没有就会向Centralcache索取一块给对应的线程用,然后剩下的就挂到对应的freelist里面方便下次使用,回收内存就挂到对应freelist里面(可能多了填充到对应的CentralCache里面,这里先暂不做处理)。
容量设计:
static const int MAX_BYTES = 256 * 1024;//线程缓存最大256kb
static const int FREELIST_NUMS = 208;//哈希桶个数
整体大致设计:
class ThreadCache {
public:void* Allocate(size_t size);//指针以及对应空间实际长度void Deallocate(void* ptr, size_t size);//ThreadCache没了就向CentralCache索取void* FetchFromCentralCache(size_t blocksize,size_t index);private:FreeList _freelists[FREELIST_NUMS];//哈希桶数组
};
首先先看下对应的块的大小及分布的freelist的下标位置:
// 整体控制在最多10%左右的内碎片浪费
// [1,128] 8byte对齐 freelist[0,16)
// [128+1,1024] 16byte对齐 freelist[16,72)
// [1024+1,8*1024] 128byte对齐 freelist[72,128)
// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184)
// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)
这里在一定范围内就按照指定对齐数向上取整得到对应大小内存块,我们为了拥有更大的利用率,因此进行这样设计!
📊 其次就是这里还会出现两个问题:
- 申请内存块的时候大小不一定,如何找到对应freelist中真正内存块大小呢?
-
上面我们说了,每次申请内存并不会直接给你对应大小的,比如你申请15;它会给你一个16的内存块,依此类推,可以理解成有个
补齐的原则。 -
下面有个简单的算法,我们也不难想到:先找到对应的对齐数是多少,然后通过相除方法得到:
判断对齐数是多少:
//判断要开辟的真实字节数(也就是哪一个哈希桶)static size_t Real_Size(size_t size) {if (size <= 128){return _Real_Size(size, 8);}else if (size <= 1024){return _Real_Size(size, 16);}else if (size <= 8 * 1024){return _Real_Size(size, 128);}else if (size <= 64 * 1024){return _Real_Size(size, 1024);}else if (size <= 256 * 1024){return _Real_Size(size, 8 * 1024);}else{assert(false);return -1;}}获得对应的真实字节数:
static size_t _Real_Size(size_t size,size_t alignnum) {size_t rsize;if (size %alignnum == 0) rsize = size;else rsize=(size / alignnum + 1)* alignnum;return rsize;}
但是这种方法因为用到了除法,乘法等,对于要求非常高的时候,效率会是十分低的,因此改进成对应的位操作:
static inline size_t _Real_Size(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}
🔍下面进行解释下:
比如
对齐数是8,拿到的是1-7,此时给它+7就是8-14;此时~(alignNum - 1)后最低位是8的位是1;此时8-14对应8的那位为1后面无论是几&后都是0;因此real_size就是8。
⏳一句话总结:
(bytes + alignNum - 1)完成对不足对齐数倍数进行进位,此时进了一位或者一位多一点 & ~(alignNum - 1) 干掉不足对齐数的那些位。
- 如何根据想要申请的字节数找到对应真实内存块的freelist的下标呢?
- 可以判断这个大小字节落在哪个对齐数的桶集内,然后通过求出它落在这个这个桶集的第几个
freelist里面,然后再加上之前的那些桶的下标即可。
获得落在哪个桶集,并累加之前桶集的总数:
static size_t Index(size_t size) {//相同对齐数的哈希桶分一组(前四种):int groups[4] = { 16,56,56,56 }; if (size <= 128) {return _Index(size, 8);}else if (size <= 1024) {return groups[0]+ _Index(size-128, 16);}else if (size <= 8 * 1024){return groups[0] + groups[1]+ _Index(size-1024, 128);}else if (size <= 64 * 1024){return groups[0] + groups[1] +groups[2]+_Index(size- 64 * 1024, 1024);}else if (size <= 256 * 1024){return groups[0] + groups[1] + groups[2]+groups[3] + _Index(size- 256 * 1024,8* 1024);}else{assert(false);return -1;}}
求出占了当前桶集的多少freelist:
//计算落在对齐数为alignnum的那些哈希桶中具体的哈希桶即freelist下标:static size_t _Index(size_t size, size_t alignnum) {size_t index;if (size % alignnum == 0) index = size / alignnum - 1;else index = size / alignnum;return index;}
当然这里也是有优化的(按位操作):
static inline size_t _Index(size_t bytes, size_t alignnum){size_t _2_top = static_cast<size_t>(std::log2(alignnum));//求alignnum是2的哪个指数次结果return ((bytes + (1 << _2_top) - 1) >>_2_top) - 1;}🔍解释下:
bytes是落在某个对齐数这个区间内的多余的字节(假设对齐数就是16),那么此时bytes(假设是16-31)+15一定落在 16 32 48 两个区间内, 其中要么bytes为16落在16 -32 剩下的就是在32-48 区间内,此时,进行除 对齐数,此时-1后,当bytes为16就是0,其余就是1;注意下标:因为第一种桶已经计算了是16个,这里-1就是多少个桶与下标之间的对应关系映射好!
⏳一句话总结:
(bytes + (1 << _2_top) - 1)为了给不足一个对齐数倍数的进位 ;>>_2_top 获得真正是哪个桶 - 1 完成是多少个桶与下标之间的对应关系映射。
🛠️Allocate实现
- 通过对应的
size获取实际内存块大小,并定位到哪个freelsit然后进行pop;如果freelist为空,那就去CentralCache对应大小块里面去申请,取出一个使用,剩下的挂回去(之后会结合CentralCache实现下,这里先不实现了)。
void* ThreadCache:: Allocate(size_t size) {assert(size <= MAX_BYTES);//小于256kbsize_t index=Calculate::Index(size);//工具类里的函数必须设置静态才能访问否则由于this指针不能直接访问if (!_freelists[index].empty()) {return _freelists[index].Pop();}else {//一定字节内存块的哈希桶空了,向中心缓存申请:size_t block_size = Calculate::Real_Size(size);return FetchFromCentralCache(block_size, index);}}
FetchFromCentralCache: 从中心缓存获取内存块,这里暂不实现了,之后结合CentralCache原理实现!
🛠️Deallocate实现
- 直接拿到这块不用的内存块,挂回对应的
freelist(记住千万不要释放掉,后续还可能用到,它也没用这个权利)
void ThreadCache::Deallocate(void* ptr, size_t size) {assert(ptr);assert(size);size_t index = Calculate::Index(size);_freelists[index].Push(ptr);
}
🚀基于多线程私有ThreadCache设计
- 首先,后期我们使用这个高并发内存池的时候,是多线程使用的,因此每个线程都要独立拥有一个
ThreadCache,它们互相在这里面索取内存块,不用加锁,互不干扰。
因此我们进行这样的操作:
_declspec(thread) ThreadCache* TLSThreadCache = nullptr;
解释下:
其次就是
_declspec(thread) win专属的,修饰的类型的对象是线程本地储存,也就是线程看到这个对象(被修饰的)就会把它搬到线程局部存储每个线程就不在共享这个全局变量而是私自占有不同的—>就产生了线程缓存(无锁)。
但是这里还会出现个问题:重定义问题!
解决方法:
- 这里需要搞成
static;否则多个cpp包含这个头文件链接obj的时候每个cpp都有这个定义,互相能看到就重定义了,因此static一下只在本cpp有效互相不能看到了,避免重定义!
static _declspec(thread) ThreadCache* TLSThreadCache = nullptr;
⚠️书写代码时值得注意的几个地方
-
之前基于Linux,我们采取的是
hpp(直接把h和cpp合并了,故类内直接写函数声明与定义即可)格式完成对类的分块处理,这里采取的是h和cpp的形式(h里声明,cpp里定义):因此可以考虑在cpp写定义的时候需要声明这个函数的类名,剩下的就想象成在这个类内定义都是一样的! -
其次就是把
多个模块经常用到的函数等封装成一个类(可以叫工具类),然后放在一个公共头文件里(common头文件);这样就大大简化了麻烦,直接包含这个文件,调用这个类函数就行;我们直接把它搞成静态成员函数,这样每次使用都不需要定义对象,直接声明类,使用这个函数即可[静态成员函数属于类本身,而不是类的某个特定对象。因此,你可以通过类名直接调用静态成员函数,而不需要创建类的实例。]
三· ✨ThreadCache的多线程测试
- 下面我们简单搞出两个线程来测试下,看是否它们都能拿到各自的
ThreadCache,也就是看每个线程的TLSThreadCache是否是不同的即可(如果是不同的也就是每个线程都拿到了不同的ThreadCache这个类对象的地址,此时也就保证了它们各自有各自的线程缓存空间了,达成了互不干扰)。
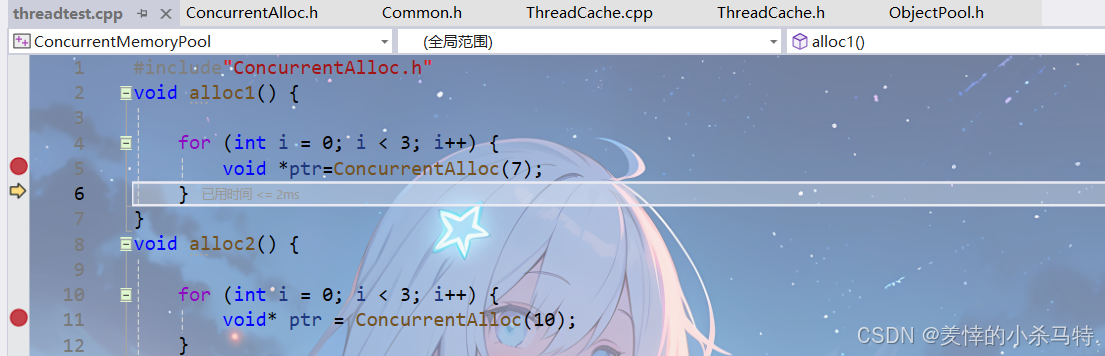
搞出两个线程走从自己的ThreadCache申请内存:
void alloc1() {for (int i = 0; i < 3; i++) {void *ptr=ConcurrentAlloc(7);}
}
void alloc2() {for (int i = 0; i < 3; i++) {void* ptr = ConcurrentAlloc(10);}
}int main() {std::thread t1(alloc1);t1.join();std::thread t2(alloc2);t2.join();
}
这两个线程都会走ConcurrentAlloc这个函数,但是由于TLSThreadCache是线程局部存储,每个线程看到的都是自己的,当访问Allocate的时候,也是访问线程独有的(这里可以认为new的时候把这个函数已经保存在线程自己的局部储存里面了),因此此种情况下,Allocate是个可重入函数,多线程访问不会出现问题:
void* ConcurrentAlloc(size_t size) {if(TLSThreadCache==nullptr) TLSThreadCache = new ThreadCache;//TLSThreadCache为线程局部自己的,因此每个线程都不一样,每次线程拿到的都是自己局部储存里面的TLSThreadCache,// 实现每个线程管理自己的ThreadCache,非共享的,无锁化cout << std::this_thread::get_id() << ":" << TLSThreadCache << endl;return TLSThreadCache->Allocate(size);
}
👍测试效果
第一步先打断点在进行调试:
首先进行调试:
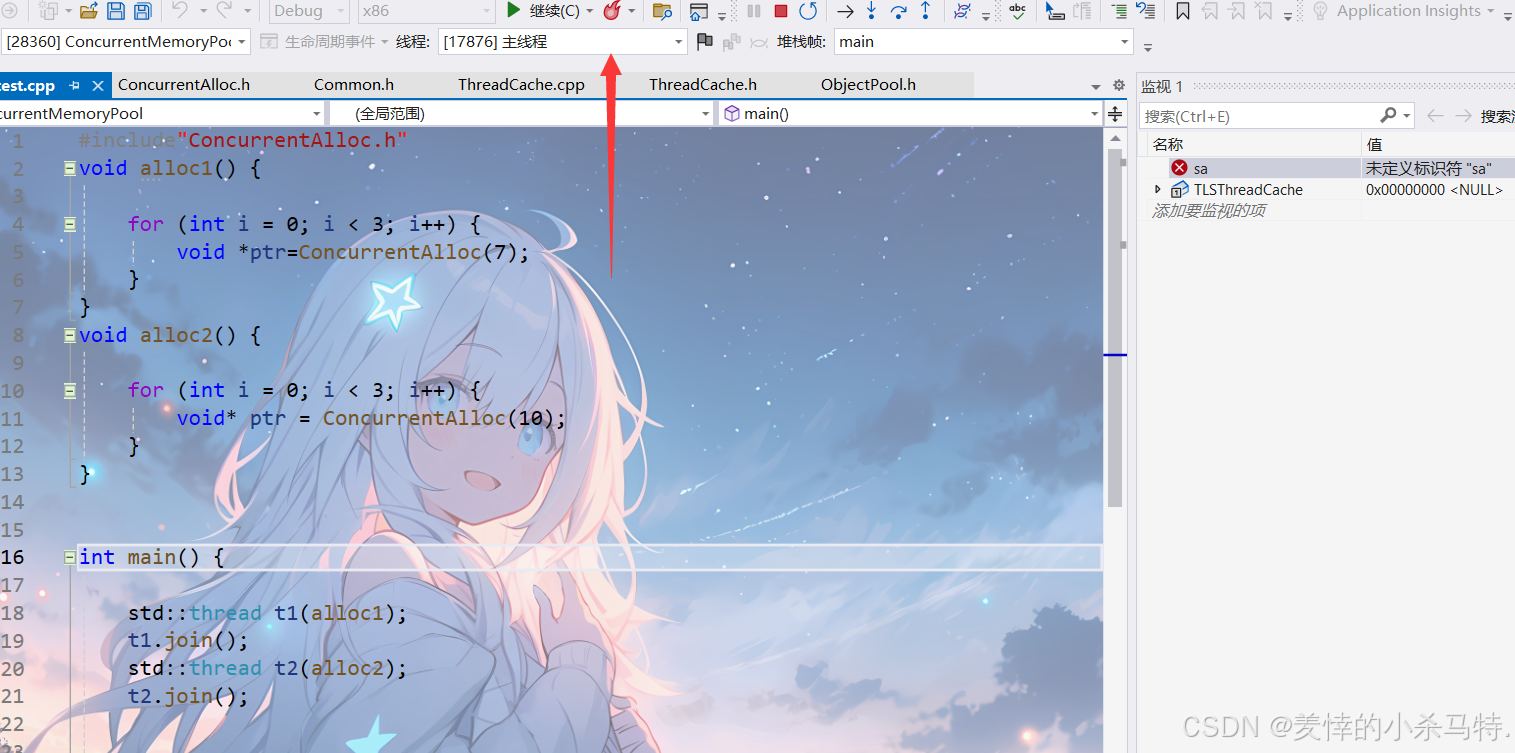
打开并行监视对TLSThreadCache指针进行并行监视:
然后观察对应的线程是否可以拿到只属于自己的threadcache对象指针,也就是验证是否每个线程有自己独立的threadcache
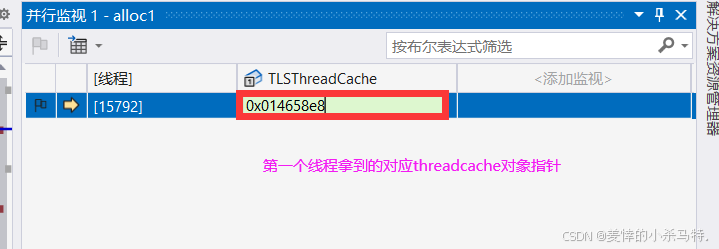
第一个线程走第二次申请内存块:
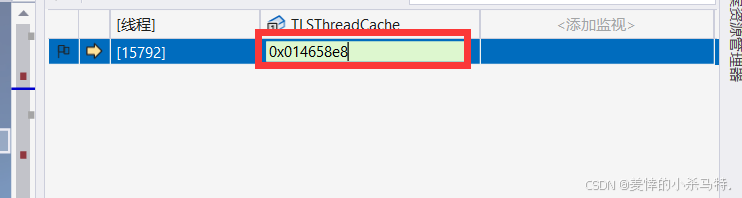
发现获取的和第一次创建的地址一样!
下面换到第二个线程 ,对应的线程tid是不同的,拿到的对应的threadcache对象地址也不同:
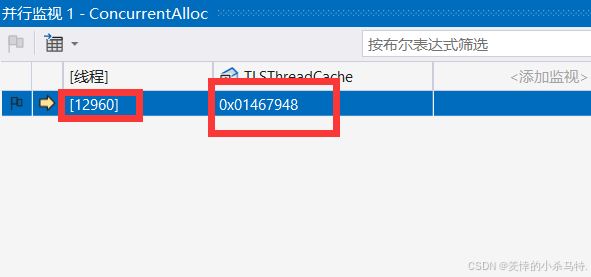
之后当第二个线程下一次再去threadcache申请内存拿到的仍是创建的那个对象地址,同上面,这里就不演示了!
看一下最后的效果:两个不同线程对应两个不同threadcache指针,因此验证了每个线程有自己独立的threadcache !
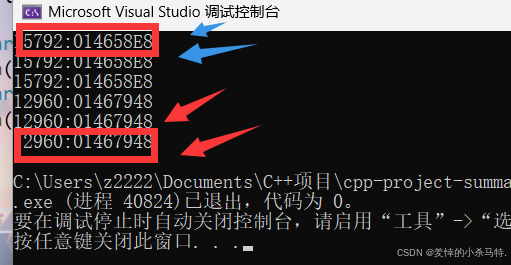
- 本次测试成功证明了每个线程都可以拿到自己独立的
ThreadCache,之后我们就可以直接给他们分配内存块,实现多线程各自向自己的线程缓存去申请空间使用。
四· 📧本篇ThreadCache暂时的源码
🚀🚀点击跳转gitee速看源码🚀🚀
五· 🎨本篇小结
- 通过本篇,学习到这个高并发内存池的整体框架,以及之间的相互联系,然后简单的实现了线程独有的
ThreadCache这个模块的一小部分(后续还需要继续补充,这里便对它有了个认识),之后会更新关于CentralCache,PageCache的设计实现等等,欢迎订阅!
究竟是什么样的终点才配的上这一路的颠沛流离!