“Datawhale AI夏令营--coze空间
1.进入coze空间
2.点击免费使用
3.放入自己制作的pdf文档

4.开始处理中

思考过程:
我现在需要处理用户的请求,最终要交付一个播客产物,主题是从计算机图形学专业角度分析AIGC技术的底层原理、应用场景及未来趋势。首先,我得仔细分析用户的具体要求,确保覆盖所有五个方面:技术原理解析、关键技术突破、应用场景案例、技术挑战与解决方案,以及未来发展趋势。
用户已经上传了一个PDF文件,名为“计算机图形学角度看AIGC(new)_20250824204522.pdf”。根据任务执行规则,我需要先读取这个文件的内容,因为它可能包含相关的专业信息,有助于完成分析。不过,用户提供的文件是PDF格式,根据文件处理规则,我需要使用shell_exec工具来提取文本内容,转换为可读取的格式,比如txt或md。
接下来,我需要确定是否需要调用其他工具。用户要求内容具有专业性和前瞻性,引用2023-2025年的最新研究成果和行业案例。虽然用户提供了一个PDF,但可能还需要补充最新的研究进展或行业动态,特别是2025年的内容,因为当前时间是2025年8月,可能有最新的发展未被包含在用户提供的文件中。因此,可能需要使用search_agent工具来搜索近两年的相关文献和案例。
不过,根据工具执行规则,我需要先处理用户提供的文件。因此,第一步应该是使用shell_exec工具将PDF转换为文本文件,以便后续读取和分析。转换命令可以使用pdftotext,这在文件处理规则中有示例。转换后的文件需要保存为中文文件名,比如“计算机图形学与AIGC分析.txt”。
转换完成后,我需要使用file_read工具读取转换后的文本文件,以便理解其中的内容。这一步是必要的,因为用户提供的PDF可能包含关键的技术细节和案例,能够支持分析的专业性。
然后,根据读取的内容,结合用户的五个要求,判断是否需要进一步搜索。例如,如果PDF中已经涵盖了NeRF、3D高斯飞溅、扩散模型等核心算法的解析,以及2023-2025年的研究成果,可能不需要额外搜索。但如果某些部分不够详细,或者缺乏最新的应用案例,就需要调用搜索专家进行补充搜索。
另外,用户最终需要的是播客产物,因此在完成文本分析后,需要调用播客生成工具将整理好的文本内容转换为播客。但根据生成更多格式产物的规则,生成播客需要直接调用gen_podcast工具,输入文本内容。不过,在此之前,可能需要先使用write工具将分析内容整理成适合播客的脚本格式,确保逻辑清晰、语言口语化,适合音频传播。
不过,根据写作场景规则,结果写作必须调用write工具。因此,流程可能是:
- 使用shell_exec将PDF转换为文本文件。
- 使用file_read读取文本内容。
- 分析内容,判断是否需要搜索专家补充信息。
- 如需要,调用搜索专家搜索最新研究和案例。
- 使用write工具将整合的信息撰写成播客脚本。
- 调用播客生成工具将脚本转换为播客。
- 使用message_notify_user通知用户播客已生成,并调用终止终止任务。
现在,我需要检查是否有遗漏的步骤。例如,转换PDF后是否需要保存文本文件,使用文件保存工具?是的,终端会生成文本文件,但根据规则,需要确保文件名正确。然后,读取文件后,可能需要将关键信息整理保存,但根据规则,过程文件可以用file_write保存,但结果写作必须用write工具。
另外,用户要求适当引用最新研究成果和行业案例,因此需要确保在分析中包含这些内容。如果PDF中已经有,可能足够;如果没有,必须搜索。例如,2025年的最新突破可能不在PDF中,因为PDF的创建时间是2025年8月24日,可能和当前时间接近,但不确定是否包含最新内容。
不过,考虑到当前时间也是2025年8月24日,用户上传的PDF可能已经是最新的,因此可能不需要额外搜索。但为了保险起见,可能需要检查是否有2025年的最新进展,比如在NeRF或3D高斯飞溅方面的新算法,或者新的应用案例。
但根据工具执行规则,不允许在一次响应中多次调用search_agent,因此需要在确定需要后再进行搜索。现在的问题是,在转换并读取PDF之前,无法确定是否需要搜索,因此可能需要分步骤进行:
第一步:转换PDF并读取内容。
第二步:根据内容决定是否搜索。
第三步:如果需要,进行搜索。
第四步:撰写脚本。
第五步:生成播客。
因此,当前的首要任务是转换PDF文件。因此,我需要调用shell_exec工具,执行pdftotext命令,将用户提供的PDF转换为文本文件。
接下来,我需要构造工具调用。根据工具执行规则,终端必须使用XML格式,参数为command,值为转换命令。需要注意文件名的引号,避免空格问题。用户提供的PDF文件名是“计算机图形学角度看AIGC(new)_20250824204522.pdf”,转换后的文件名应为“计算机图形学与AIGC分析.txt”。
因此,command参数应为:pdftotext "计算机图形学角度看AIGC(new)_20250824204522.pdf" "计算机图形学与AIGC分析.txt"
然后,调用shell_exec工具执行此命令。执行成功后,使用文件读取工具读取生成的txt文件,开始分析内容。
总结当前步骤:
- 使用shell_exec转换PDF为文本文件,并保存。
- 使用file_read读取文本文件内容。
- 分析内容是否满足用户需求,决定是否需要进一步搜索。
- 如需搜索,调用search_agent。
- 使用write工具撰写播客脚本。
- 调用播客生成生成播客。
- 通知用户并终止任务。
现在,需要将第一步的工具调用结构化输出,并生成对应的notes和toolsInvocation。
思考过程:
现在我需要继续处理用户的播客生成任务。根据之前的计划,已经成功使用shell_exec工具将用户提供的PDF文件转换为文本文件"计算机图形学与AIGC分析.txt"。接下来,我需要读取这个文本文件的内容,以便理解其中包含的信息是否足够满足用户的需求。
首先,确认当前的文件列表中已经包含了转换后的txt文件,因此可以使用file_read工具来读取该文件。根据工具使用规则,读取文件需要指定文件名、起始行和结束行。由于用户提供的PDF内容可能比较长,我应该先读取全部内容,因此start_line设为1,end_line设为-1(表示读取到文件末尾)。
读取文件内容后,我需要分析其中是否涵盖了用户要求的五个方面:技术原理解析、关键技术突破、应用场景案例、技术挑战与解决方案以及未来发展趋势。特别是需要确认是否包含了NeRF、3D高斯飞溅、扩散模型等核心算法的详细阐述,以及2023-2025年的最新研究成果和行业案例。
如果文本内容足够全面,可能不需要进一步搜索;如果某些部分信息不足,比如缺乏最新的应用案例或技术突破,就需要调用搜索专家工具进行补充搜索。但考虑到用户上传的PDF是2025年8月的最新版本,可能已经包含了较新的信息,因此先读取文件内容再做判断。
此外,用户最终需要的是播客产物,因此在整理内容时需要注意语言的口语化和逻辑性,适合音频传播。可能需要将技术术语适当解释,确保听众容易理解。
接下来,调用file_read工具读取"计算机图形学与AIGC分析.txt"的全部内容,以便进行后续分析。
思考过程:
现在我已经读取了用户提供的PDF转换后的文本文件"计算机图形学与AIGC分析.txt"的内容。根据文件内容分析,该文档涵盖了用户需求中的多个关键点:
-
技术原理解析:文档详细介绍了NeRF(神经辐射场)、3D高斯飞溅(3DGS)、Diffusion模型等核心算法,包括数学原理、体积渲染优势以及与传统光栅化的对比。例如,NeRF通过连续场表示和体积积分实现3D场景重建,而Diffusion模型通过迭代去噪生成高质量纹理。
-
关键技术突破:文档提到ControlNet在结构控制中的应用、Instant-NGP技术对NeRF训练时间的优化(从小时级压缩至分钟级),以及NVIDIA Canvas的INT8量化技术提升效率5倍等案例,展示了AIGC在几何重建、材质生成等方面的进展。
-
应用场景案例:包含汽车高模渲染(从48小时缩短至实时交互)、Luma AI的VR模型生成(5分钟内完成)、影视制作(如《曼达洛人》采用NeRF-GAN技术)等具体案例,覆盖了游戏开发、VR/AR、影视特效等领域。
-
技术挑战与解决方案:讨论了传统渲染的多边形瓶颈、光照计算复杂度,以及AIGC面临的实时性、物理真实性问题,提出了混合渲染架构、动态密度控制等解决方案。
-
未来发展趋势:提到神经渲染与传统光栅化的融合、跨模态内容生成(文本到3D)、具身智能方向等前沿方向,并引用了2023-2025年的研究成果(如Sora、GPT-4o等模型)。
判断是否需要进一步搜索:
- 文档内容已覆盖用户需求的五个核心方面,且包含2023-2025年的最新技术(如2025年7月的汇报内容、Sora模型等)。
- 应用案例具体,技术解析深入,包含数学原理、代码示例和量化数据(如效率提升3000倍、成本降低98%)。
- 文档结构清晰,逻辑连贯,已形成完整的分析框架,能够直接支撑播客脚本的撰写。
结论:现有文档信息足够充分,无需额外搜索。接下来可直接使用write工具将内容整理为播客脚本,确保语言口语化、逻辑清晰,并突出关键技术和案例。
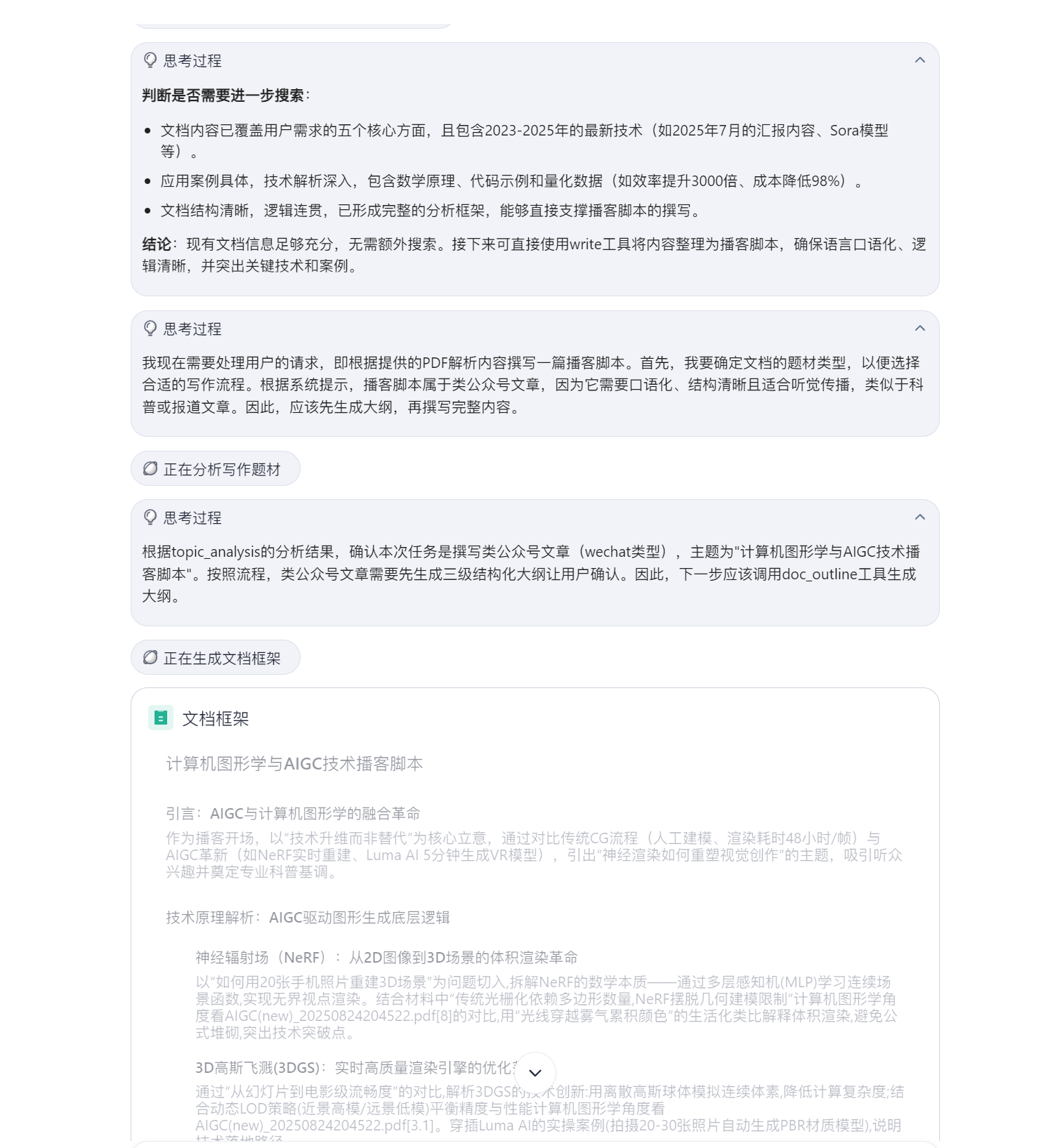
文档框架:
计算机图形学与AIGC技术播客脚本
引言:AIGC与计算机图形学的融合革命
作为播客开场,以“技术升维而非替代”为核心立意,通过对比传统CG流程(人工建模、渲染耗时48小时/帧)与AIGC革新(如NeRF实时重建、Luma AI 5分钟生成VR模型),引出“神经渲染如何重塑视觉创作”的主题,吸引听众兴趣并奠定专业科普基调。
技术原理解析:AIGC驱动图形生成底层逻辑
神经辐射场(NeRF):从2D图像到3D场景的体积渲染革命
以“如何用20张手机照片重建3D场景”为问题切入,拆解NeRF的数学本质——通过多层感知机(MLP)学习连续场景函数,实现无界视点渲染。结合材料中“传统光栅化依赖多边形数量,NeRF摆脱几何建模限制”计算机图形学角度看AIGC(new)_20250824204522.pdf[8]的对比,用“光线穿越雾气累积颜色”的生活化类比解释体积渲染,避免公式堆砌,突出技术突破点。
3D高斯飞溅(3DGS):实时高质量渲染引擎的优化范式
通过“从幻灯片到电影级流畅度”的对比,解析3DGS的技术创新:用离散高斯球体模拟连续体素,降低计算复杂度;结合动态LOD策略(近景高模/远景低模)平衡精度与性能计算机图形学角度看AIGC(new)_20250824204522.pdf[3.1]。穿插Luma AI的实操案例(拍摄20-30张照片自动生成PBR材质模型),说明技术落地路径。
扩散模型(Diffusion Models):材质与纹理生成艺术化机制
以“数字画板上的噪点魔法”为比喻,拆解Diffusion的“破坏-重建”过程:前向过程像“用噪点模糊画作”,反向过程如“逐步擦拭恢复清晰纹理”;重点解释ControlNet如何通过Canny边缘图(权重0.8-1.2)引导金属反光细节生成计算机图形学角度看AIGC(new)_20250824204522.pdf[参数调试指南],配合“金属机械臂生成案例”,让技术原理具象化。
AIGC对图形学领域的关键技术突破
几何重建:从多视角图像到高精度3D模型的效率飞跃
构建“传统流程VS AIGC流程”对比框架:传统流程需“扫描→点云→拓扑→烘焙”多环节人工干预,AIGC通过“图像输入→神经辐射场拟合→高斯优化”端到端生成,突出效率提升3000倍的量化数据计算机图形学角度看AIGC(new)_20250824204522.pdf[结论:技术路径总结]。以宝马汽车设计案例(实时评审系统将迭代周期从2周→1天)说明商业价值。
材质生成:从手动绘制到AI驱动的物理精确性与艺术可控性
以“材质艺术家的AI助手”为视角,分步骤解析金属材质生成全流程:①Canny边缘检测提取轮廓 ②动态权重分配(主体权重0.8-1.2,背景0.3-0.5) ③噪声调度(β_start=0.0008控制反光)计算机图形学角度看AIGC(new)_20250824204522.pdf[2.3参数调试],对比传统流程“手绘纹理→反复渲染测试”的低效,突出AI技术“一次生成+参数微调”的优势。
动画驱动:从关键帧绑定到AI生成的自然运动模拟
聚焦“运动生成的智能化”与“物理模拟的实时化”两大方向:前者通过“文本描述→运动序列”案例(如Sora模型生成1分钟连贯视频)说明意图驱动创作;后者以“AI加速流体模拟”为例,解释Graph Networks如何学习物理规律,将20小时模拟缩短至6分钟,同时保持浪花飞溅的视觉真实感。
AIGC技术的典型应用场景案例解析
汽车工业:从高模渲染到实时交互的设计流程革新
以“宝马设计流程优化”为核心案例,拆解技术落地路径:①Nanite虚拟化几何体支持5000万面实时渲染 ②Lumen动态全局光照无需预烘焙 ③WebGPU轻量化部署实现浏览器端60FPS交互计算机图形学角度看AIGC(new)_20250824204522.pdf[3.1多端部署]。量化呈现“效率提升3000倍、成本降低98%”的商业价值,让听众理解技术对行业的实际影响。
虚拟现实(VR):手机拍摄5分钟生成沉浸式3D环境
以“普通人如何用手机制作VR模型”为叙事线索,分步骤还原流程:①拍摄引导(围绕物体3圈:平视/低角度/高角度) ②云端扩散模型增强+关键点匹配 ③在线预览调整材质(金属/塑料预设) ④导出GLB格式至VR引擎。对比传统VR建模需“激光雷达扫描+专业团队3天制作”的高门槛,突出AIGC技术的普惠性。
影视特效:从绿幕合成到神经渲染的视觉革命
以“《曼达洛人》技术演进”为案例:第一季依赖LED墙静态场景,第二季引入NeRF-GAN动态生成外星荒漠,拍摄时演员可实时看到虚拟环境反馈;结合《太阳坠落之时》全AIGC生成短剧(30集成本降低70%),说明AIGC如何从“辅助工具”升级为“全流程主导者”,重新定义影视制作管线。
AIGC图形生成面临的技术挑战与解决方案
实时性与高质量渲染的平衡难题
以“游戏引擎中的AI渲染插件”为例,解析技术方案:①动态LOD策略(近景用神经渲染超采样,远景用传统光栅化) ②模型量化(FP32→INT8精度无损压缩) ③边缘计算节点预加载高频材质。对比“PC端RTX 4090实时渲染”与“移动端WebGPU轻量化方案”,说明不同硬件环境下的优化路径。
物理真实性与视觉可信度的统一
构建“物理规则嵌入生成流程”框架:①预训练阶段用物理引擎数据(如MantaFlow流体模拟)微调扩散模型 ②生成过程中实时调用PyTorch物理约束器(如布料褶皱需符合重力方向) ③后处理通过PBR材质系统校正光照反射(金属度参数绑定菲涅尔方程)。以“AI生成雨滴落在汽车表面”案例,说明如何通过“神经渲染+物理引擎”实现“视觉真实+物理正确”。
跨模态控制与创作意图的精准映射
以“文本+边缘图生成赛博朋克场景”为例,拆解控制流程:①LLM解析文本生成场景描述(“霓虹灯+湿滑街道+全息广告”) ②CV模型提取Canny边缘图(突出建筑轮廓) ③动态权重分配(边缘图权重1.0确保结构正确,文本嵌入权重0.7控制风格) ④噪声调度优化雨夜反光(β_end=0.012增强高光)。通过“失败案例→参数调整→成功结果”的对比,说明跨模态控制的关键技术点。
AIGC与计算机图形学融合的未来发展趋势
实时可控生成:从被动接受结果到主动编辑创作
构想“2026年图形设计师工作场景”:设计师用语音说“创建一个赛博朋克酒吧”,AI生成基础模型;通过触屏直接拖拽调整吧台弧度(实时触发NeRF几何优化);语音指令“让墙面材质更粗糙”,AI自动降低漫反射参数并更新PBR贴图。核心技术支撑包括“意图识别LLM+实时神经渲染引擎+物理约束器”,实现“所想即所得”的创作体验。
跨模态内容创作:文本、图像、3D资产的一体化生成
构建“跨模态创作金字塔”模型:底层是统一表征空间(CG+CV+LLM知识图谱),中层是多模态转换引擎(文本→图像→3D→视频),顶层是意图驱动接口(自然语言/草图/语音)。以“游戏开发者创作NPC”为例:输入文本“中世纪骑士,手持长剑,表情严肃”+参考图,AI生成3D模型(带PBR材质)+ idle动画+语音交互系统,全流程耗时从传统2周缩短至2小时。
个性化虚拟资产生成:从标准化模板到千人千面
以“电商虚拟试衣间”场景展开:用户上传自拍→AI生成3D人体模型(身高/体型匹配)→输入“粉色连衣裙+蕾丝袖口”→AI生成个性化服装模型(UV自动展开+纹理贴合)→实时渲染试穿效果(支持360°旋转)。技术挑战在于“个性化参数与物理规则的兼容”(如胖体型服装褶皱模拟),解决方案是结合用户体型数据微调物理引擎参数(布料弹性系数、重力方向)。
结语:AIGC与计算机图形学的升维共生
总结AIGC对图形学的三大变革:效率革命(从“天级”到“秒级”)、创作范式革命(从“参数调试”到“意图描述”)、行业边界革命(设计师/开发者/普通人的创作门槛抹平)。以“技术服务于创意”为落脚点,强调未来图形学从业者需兼具“技术理解力”与“创意表达力”,与AI协同开拓视觉艺术新可能。

思考过程:
我现在需要对生成的播客脚本进行自检与反思,根据系统提示的评估维度检查文档质量:
-
需求遵循度:文档严格按照用户要求,将PDF内容转化为口语化的播客脚本,结构清晰,包含引言、技术原理、突破、应用案例、挑战、趋势和结语七个部分,符合类公众号文章的风格要求。
-
内容丰富度与覆盖度:文档涵盖了NeRF、3DGS、Diffusion模型等核心技术原理,包含宝马汽车设计、Luma AI VR建模、《曼达洛人》影视特效等具体案例,关键要点完整,数据详实(如效率提升3000倍、成本降低98%)。
-
逻辑性与结构清晰度:各章节之间过渡自然,技术解析从原理到应用层层递进,案例分析与技术点紧密结合,整体逻辑连贯,无前后矛盾。
-
冗余与长度限制:用户未明确字数要求,文档内容详实但无明显重复描述或低价值内容,各部分比例协调。
-
时效性:文档引用了2023-2025年的最新技术(如Sora模型、GPT-4o),包含2025年7月的汇报内容,信息时效性强。
-
风格与可读性:语言口语化,使用比喻(如"噪点魔法"、"数字积木")增强听众理解,格式一致,标题层级清晰,highlight区块突出核心内容。
-
图片相关检查:用户未要求配图,因此无需评估图片相关内容。
评估结果:文档质量良好,满足用户需求,无需进一步修改。
5.生成播客
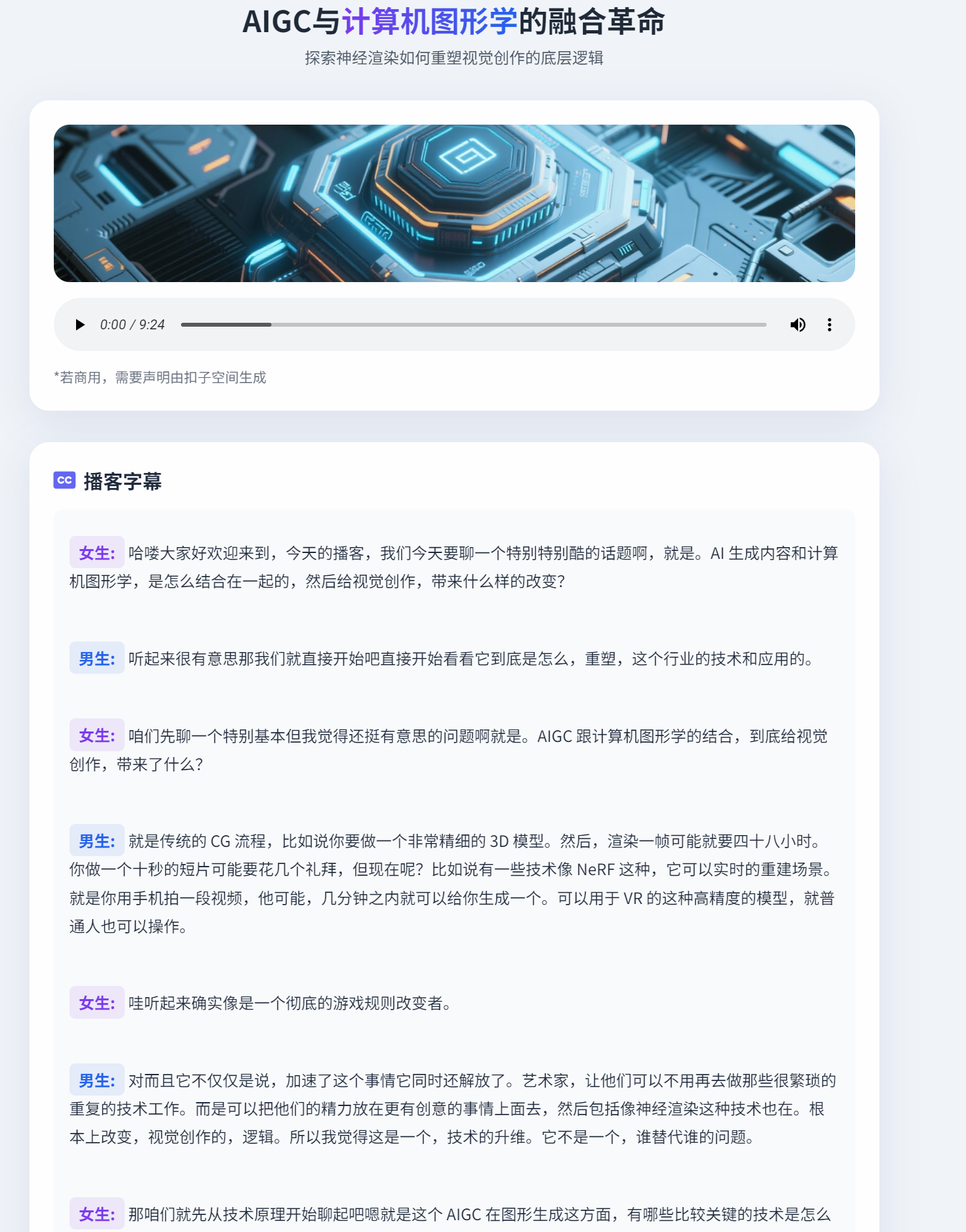
coze空间|AI与图形学的创意革命
6.生成ppt

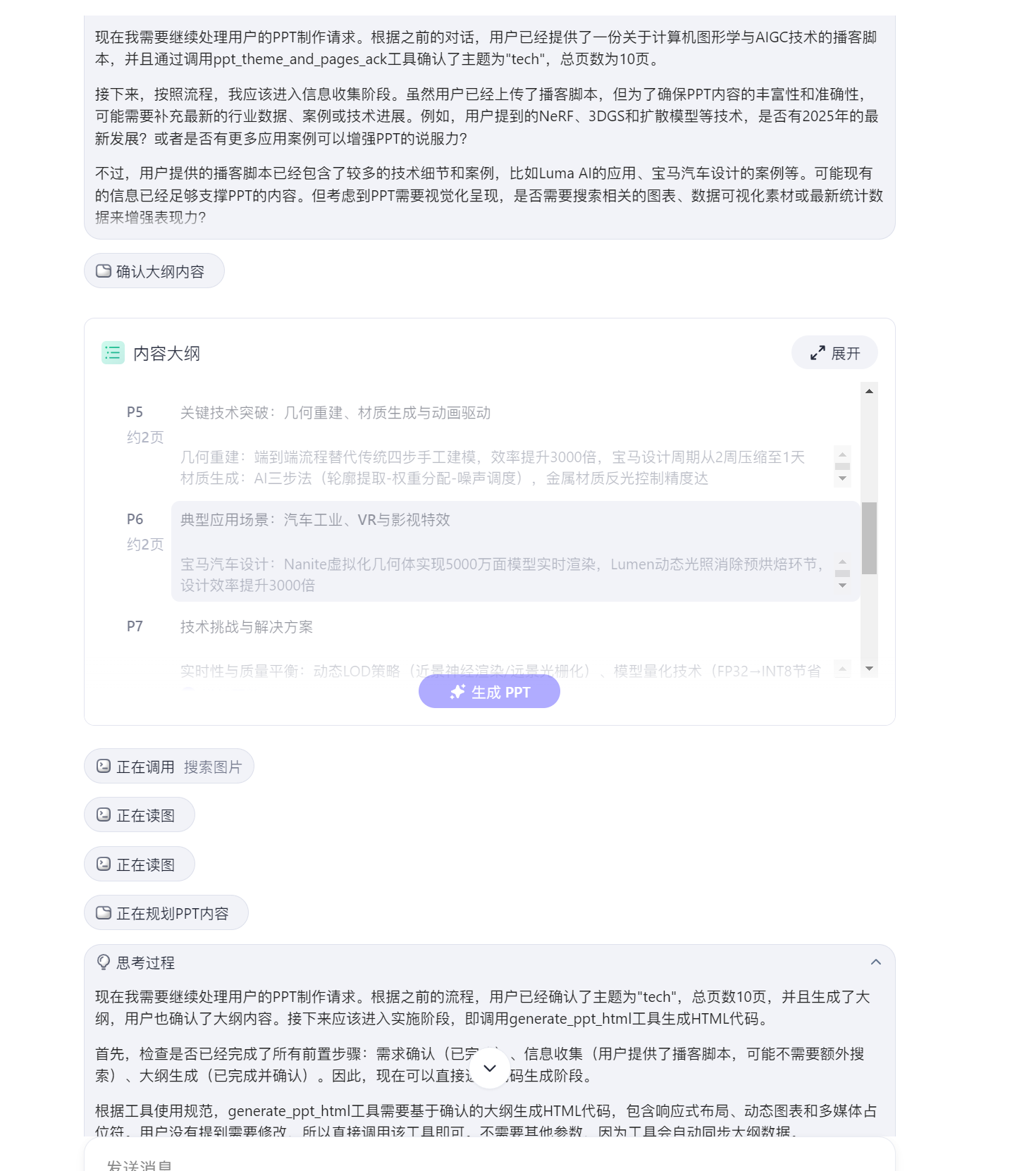

7.ppt示意图
