工业异常检测大模型(1)数据集、方法
任务描述:利用VL大模型对工业图像进行异常检测,尤其是在zero-shot和one-shot方面的应用,zero-shot是指只给一张异常图像,让VL大模型判断异常并输出描述和建议,one-shot是给一张正常图像和异常图像,具体技术路线涉及到agent、强化学习、专家知识。
一、数据集
MMAD数据集:整合开源的工业异常数据集,并基于GPT添加了文本标注,生成工业异常检测的文本标签,数据集制作流程非常有参考价值:
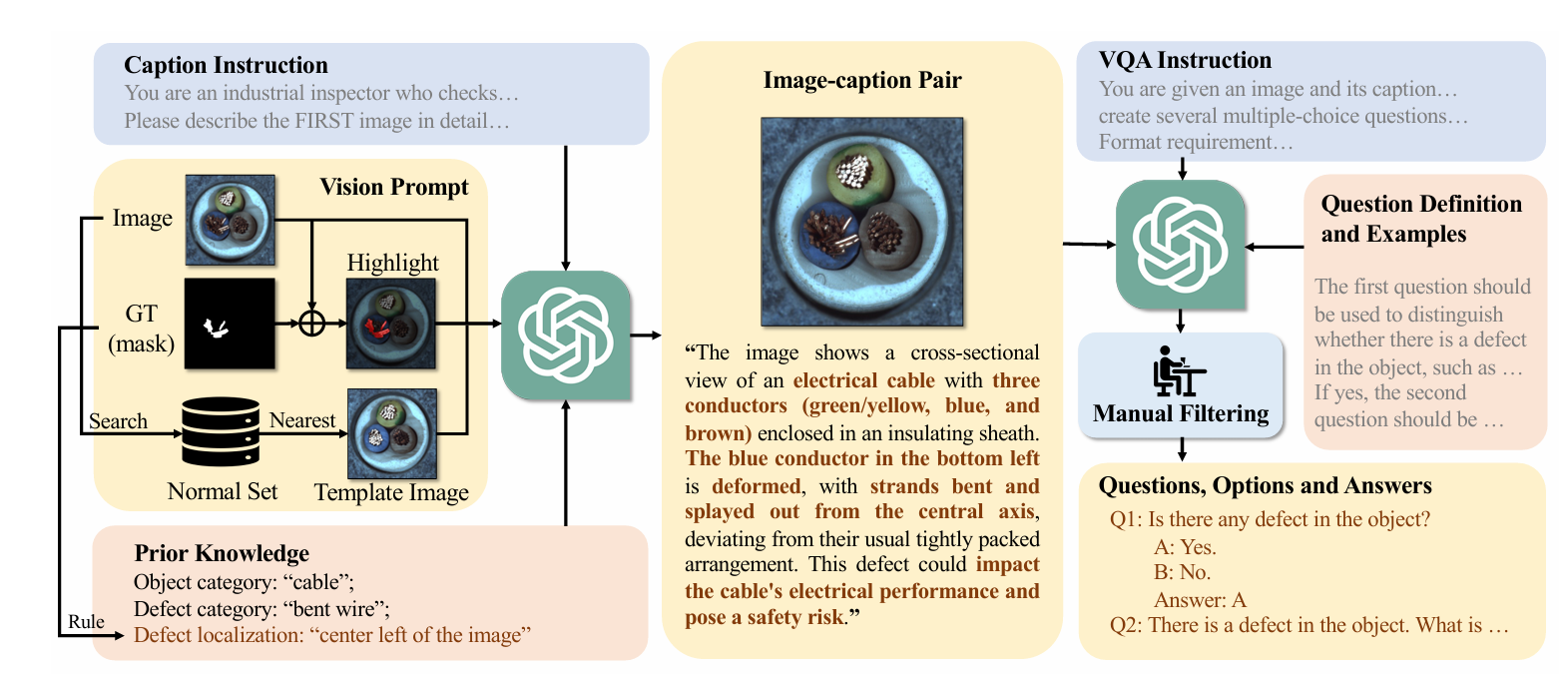
第一步:整合工业异常数据集的检测分割标签,生成Vision Prompt和Prior Knowledge。
第二步:输入GPT,得到GPT的文本描述
第三步:基于文本描述改写异常检测的文本标注
具体任务包括是否存在异常、异常类别、异常位置、异常描述、异常分析、工业品分类
数据集格式及内容:
每张图像都有其对应的txt文本描述,真正的测试标签在mmad.json,一张图像的标签如下:
{"DS-MVTec/bottle/image/broken_large/000.png": {"image_path": "image/broken_large/000.png","conversation": [{"Question": "Is there any defect in the object?","Answer": "A","Options": {"A": "Yes.","B": "No."},"type": "Anomaly Detection","annotation": true},{"Question": "There is a defect in the object. What is the type of the defect?","Answer": "C","Options": {"A": "Foggy appearance.","B": "Color fading.","C": "Broken large.","D": "Scratched surface."},"type": "Defect Classification","annotation": true},{"Question": "There is a defect in the object. Where is the defect?","Answer": "D","Options": {"A": "Top right.","B": "Top left.","C": "Center.","D": "Bottom right."},"type": "Defect Localization","annotation": true},{"Question": "There is a defect in the object. What is the appearance of the defect?","Answer": "A","Options": {"A": "A jagged irregular break.","B": "A smooth crack.","C": "A round hole.","D": "A small chip."},"type": "Defect Description","annotation": true},{"Question": "There is a defect in the object. What is the effect of the defect?","Answer": "B","Options": {"A": "It enhances the bottle's aesthetics.","B": "It presents a safety hazard.","C": "It changes the color of the glass.","D": "It has no effect on the bottle's function."},"type": "Defect Analysis","annotation": true}],"mask_path": "rbg_mask/broken_large/000_rbg_mask.png","similar_templates": ["MVTec-AD/bottle/train/good/001.png","MVTec-AD/bottle/train/good/061.png","MVTec-AD/bottle/train/good/199.png","MVTec-AD/bottle/train/good/124.png","MVTec-AD/bottle/train/good/149.png","MVTec-AD/bottle/train/good/147.png","MVTec-AD/bottle/train/good/089.png","MVTec-AD/bottle/train/good/066.png"],"random_templates": ["MVTec-AD/bottle/train/good/004.png","MVTec-AD/bottle/train/good/032.png","MVTec-AD/bottle/train/good/093.png","MVTec-AD/bottle/train/good/095.png","MVTec-AD/bottle/train/good/104.png","MVTec-AD/bottle/train/good/121.png","MVTec-AD/bottle/train/good/177.png","MVTec-AD/bottle/train/good/191.png"]},二、增强方法
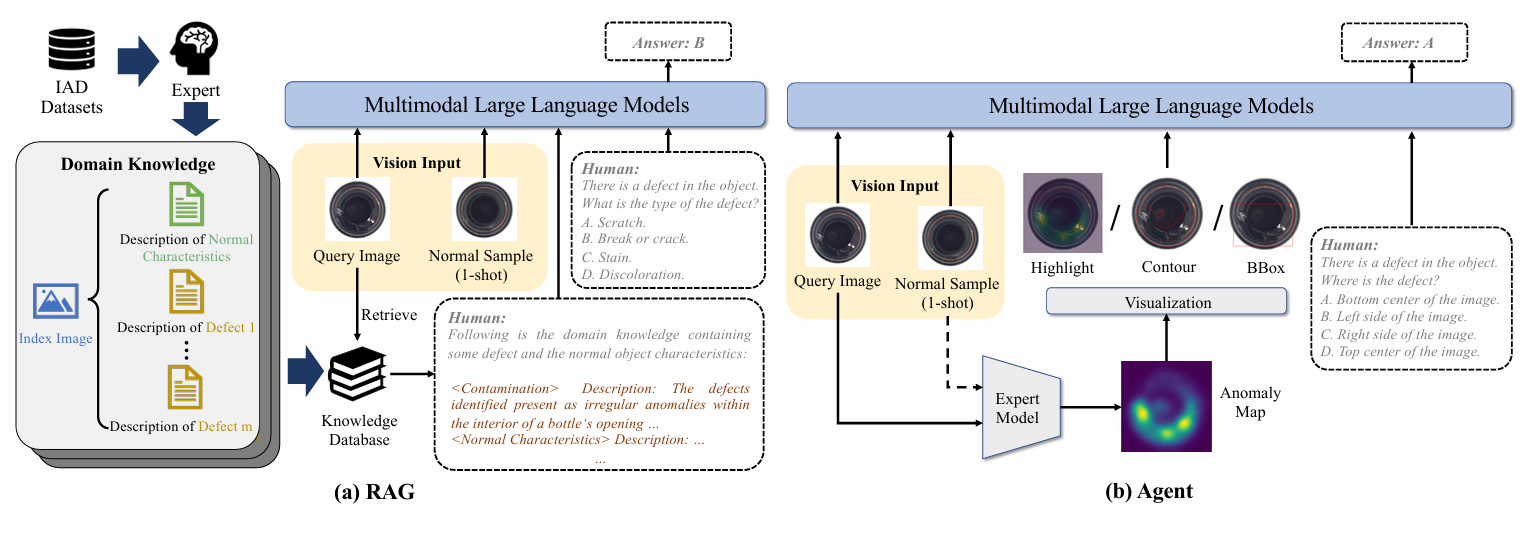
Retrieval-Augmented Generation (RAG)
按MMAD作者的解释,RAG是a method that combines information retrieval and generation to enhance the performance of language models, particularly for tasks requiring external knowledge
用人话来讲,就是提前构筑一个领域知识库,输入待检测图像时,从领域知识库里检索出相关信息,合并成prompt输入大模型,代码实现:
if args.similar_template:few_shot = text_gt["similar_templates"][:args.few_shot_model]else:few_shot = text_gt["random_templates"][:args.few_shot_model]rel_image_path = os.path.join(args.data_path, image_path)rel_few_shot = [os.path.join(args.data_path, path) for path in few_shot]if args.domain_knowledge:dataset_name = image_path.split("/")[0].replace("DS-MVTec", "MVTec")object_name = image_path.split("/")[1]domain_knowledge = '\n'.join(all_domain_knowledge[dataset_name][object_name].values())else:domain_knowledge = NoneAgent
用一个检测模型提前得到一些关于异常的信息,然后结合输入大模型
代码实现:
首先定义agent模型
if args.agent:model_name += "_Agent-" + args.agent_model + "-with-" + args.agent_notationif args.agent_model == "GT":agent = "GT"elif args.agent_model == "PatchCore":from SoftPatch.call import call_patchcore, build_patchcore, call_ground_truthagent = build_patchcore()elif args.agent_model == "AnomalyCLIP":from AnomalyCLIP.test_one_example import call_anomalyclip, load_model_and_features, anomalyclip_args, \anomalyclip_args_visaanomalyclip_args_visa.checkpoint_path = os.path.join("../AnomalyCLIP", anomalyclip_args_visa.checkpoint_path)agent = load_model_and_features(anomalyclip_args_visa)elif args.agent_model == "AnomalyCLIP_mvtec":from AnomalyCLIP.test_one_example import call_anomalyclip, load_model_and_features, anomalyclip_argsanomalyclip_args.checkpoint_path = os.path.join("../AnomalyCLIP", anomalyclip_args.checkpoint_path)agent = load_model_and_features(anomalyclip_args)生成prompt时调用
if self.agent:if args.agent_model == "GT":anomaly_map = call_ground_truth(self.image_path, self.mask_path, notation=self.args.agent_notation, visualize=self.visualization)elif args.agent_model == "PatchCore":anomaly_map = call_patchcore(self.image_path, self.few_shot, self.agent, notation=args.agent_notation, visualize=self.visualization)elif "AnomalyCLIP" in args.agent_model:anomaly_map = call_anomalyclip(self.image_path, self.agent, notation=args.agent_notation, visualize=self.visualization)images = images + [load_image(anomaly_map, max_num=1).to(torch.bfloat16).cuda()] if self.agent:if self.args.agent_notation == "bbox":payload = payload + f"Following is the reference image where some suspicious areas are marked by red bounding boxes. Please note that even if the query image does not have any defects, the red boxes still highlight some areas. Therefore, you still need to make a judgement by yourself. <image>"elif self.args.agent_notation == "contour":payload = payload + f"Following is the reference image where some suspicious areas are marked by red contour. Please note that even if the query image does not have any defects, the image still highlight some areas. Therefore, you still need to make a judgement by yourself. <image>"elif self.args.agent_notation == "highlight":payload = payload + f"Following is the reference image where some suspicious areas are highlight. Please note that even if the query image does not have any defects, the image still highlight some areas. Therefore, you still need to make a judgement by yourself. <image>"elif self.args.agent_notation == "mask":payload = payload + f"Following is the mask of some suspicious areas. But you still need to make a judgement by yourself. <image>"CoT
思维链方法论文里没提,但是代码里有实现
if self.CoT:chain_of_thought = []chain_of_thought.append({# "type": "text","text": f"Before answering the following questions, we need to understand the query image. \n"f"First, identify the objects in the template image and imagine the possible types of defects. \n"f"Second, simply describe the differences between the query image with the template sample. \n"f"Third, if exist, judge whether those differences are defect or normal. \n"f"Output a simple thoughts in 100 words. Notice that slight movement of objects or changes in image quality fall within the normal range.\n"# f"First, summary the normal and defect samples and answer why defect sample abnormal. \n"# f"Second, simply describe the differences between the test image with the normal and defect sample. \n"# f"Third, judge whether those differences are defect or normal. \n"},)三、实验结果
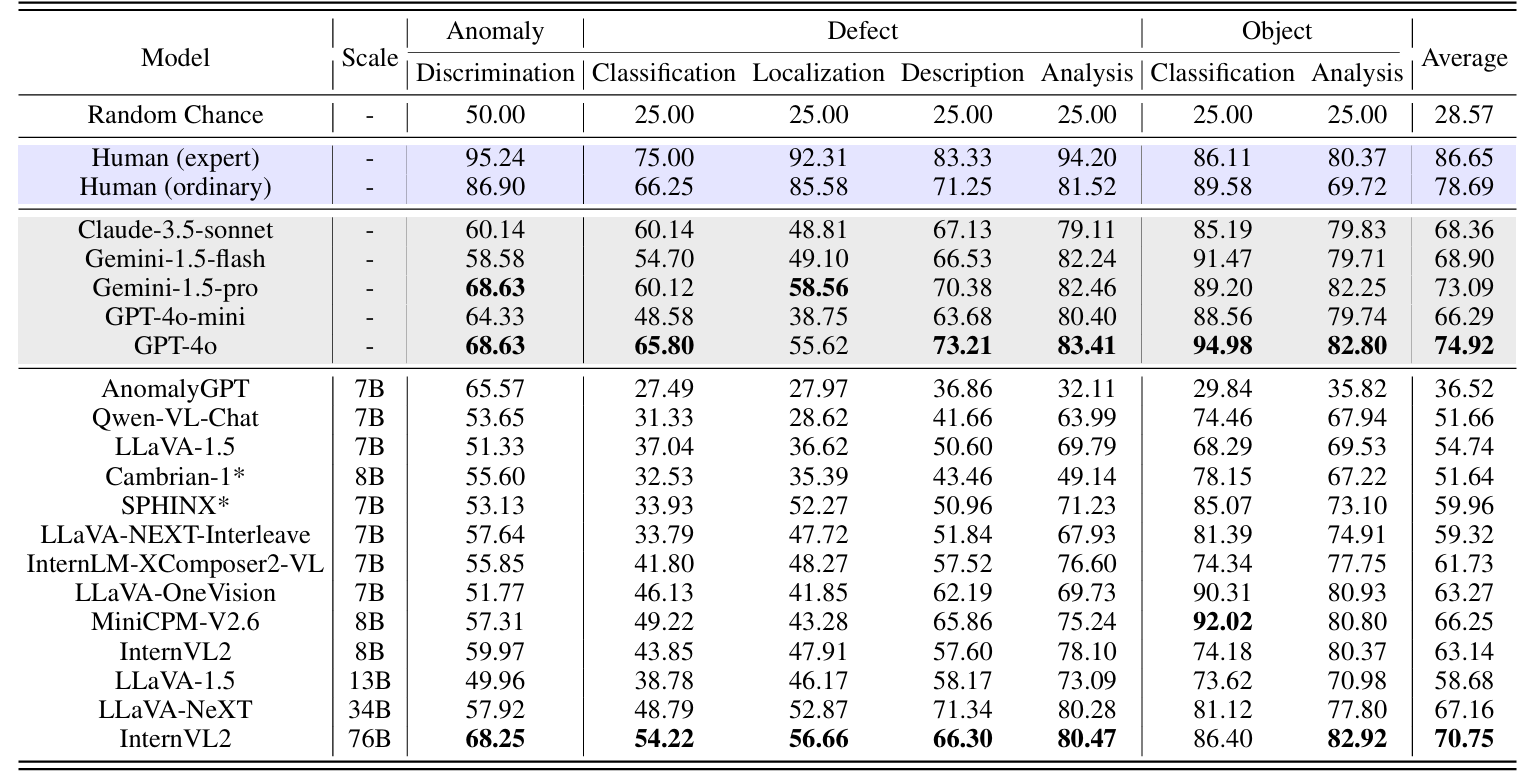
模型效果对比
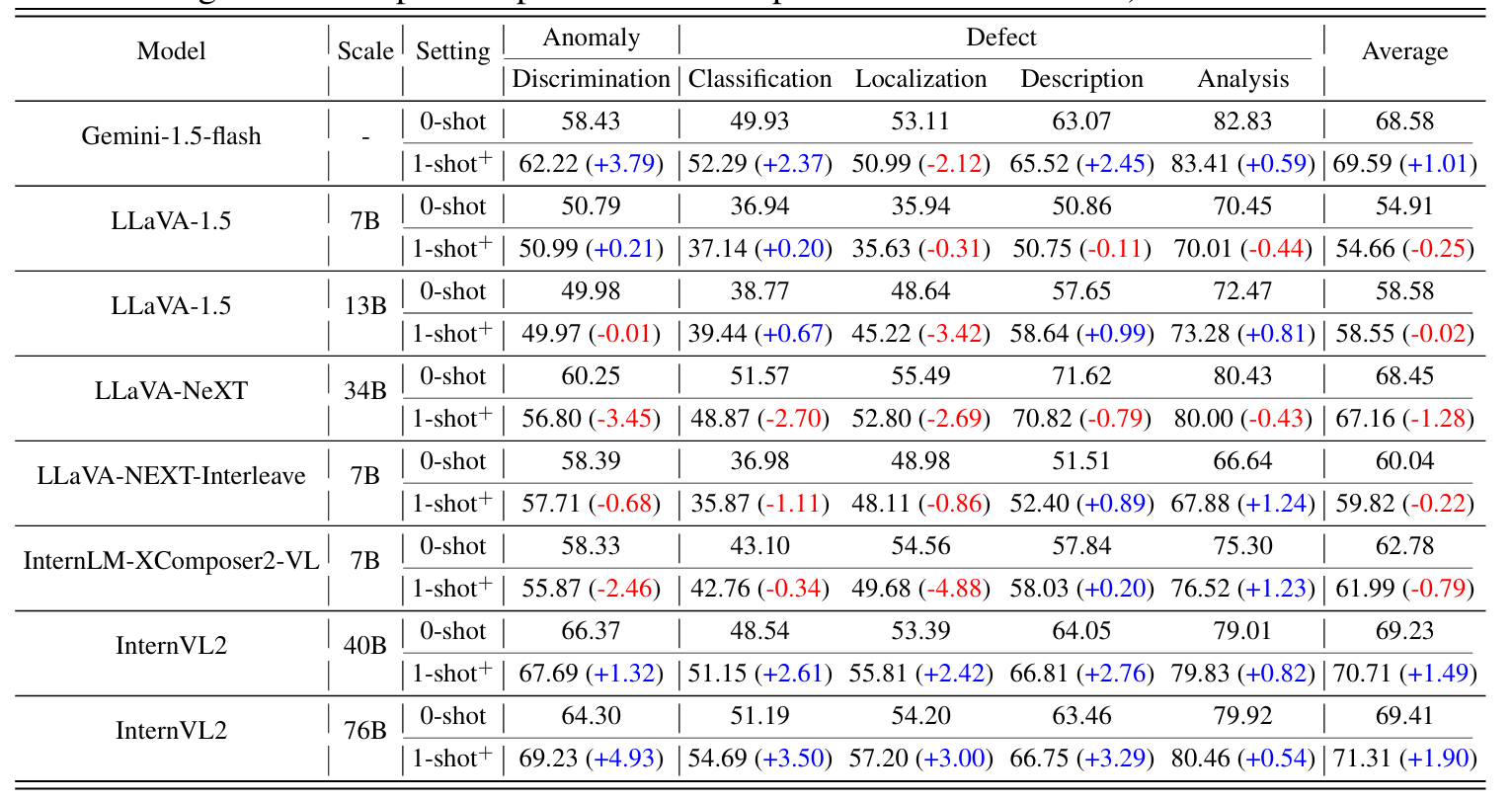
one-shot的效果增强
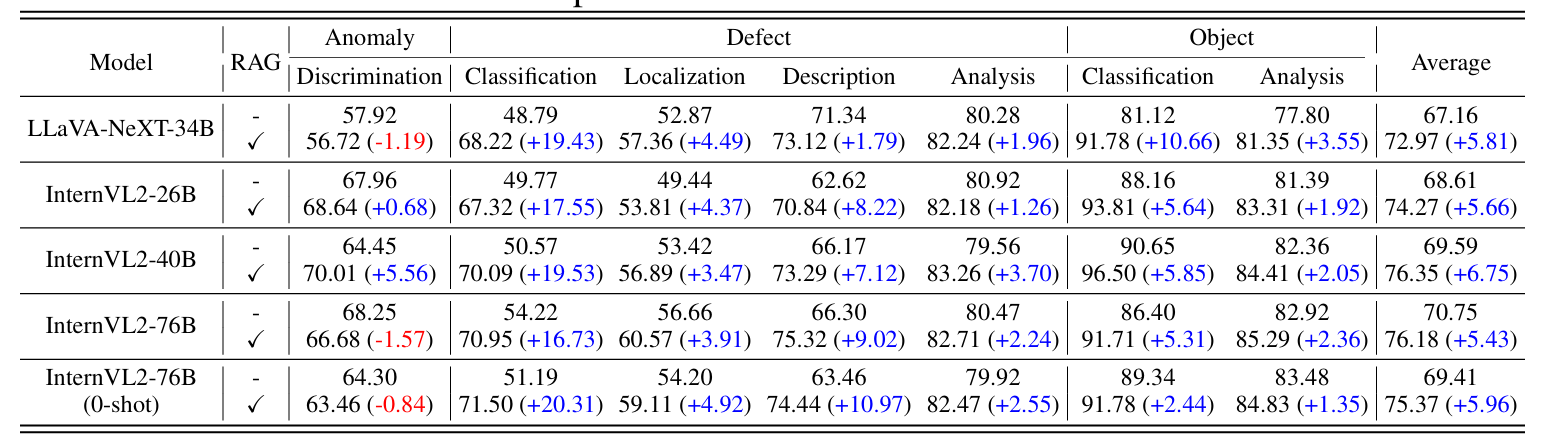
RAG的效果增强,RAG的增强效果非常明显,但是异常描述有部分效果退化,作者未解释
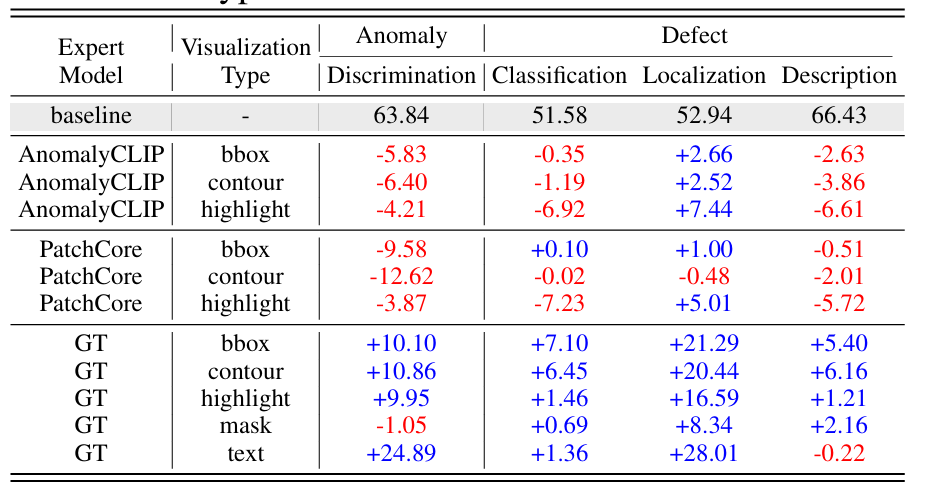
agent的效果增强,agent反而没有什么效果,但用GT的效果很好,说明是模型不够准确
四、代码复现
jam-cc/MMAD: The Codes and Data of A Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection [ICLR'25]
作者的开源还是非常不错的,我使用cuda12.4的windows系统复现,记录一些常见的问题:
1、HF模型下载不下来
用魔搭把模型下载到本地
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-VL-3B-Instruct',cache_dir='./model/')然后把模型初始化改为初始本地文件
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(str(model_path),torch_dtype="auto",attn_implementation="flash_attention_2",device_map="auto",local_files_only=True,)2、FlashAttention安装
不推荐自己编译或者pip安装
windows系统可以在下面链接直接下载wheel,pip install即可
Releases · kingbri1/flash-attention
linux系统的:
bgithub.xyz/Dao-AILab/flash-attention/releases/tag/v2.8.3