[Vid-LLM] 创建和训练Vid-LLMs的各种方法体系
第3章:Vid-LLM方法分类体系
在前一章中,我们探讨了**视频大语言模型(Vid-LLMs)**能够执行的各种激动人心的任务,从描述视频内容到回答复杂问题。现在我们已经知道这些神奇AI模型能做什么。
但这些Vid-LLMs实际上是如何构建和训练以实现这些壮举的?就像厨师需要不同的烹饪技法(烘焙、煎炸、烧烤)来制作不同菜肴,开发者使用多种策略来创建和训练Vid-LLMs。
本章将介绍Vid-LLM开发中使用的不同"配方"或方法体系。
"方法分类体系"解决什么问题?
假设我们要开发一个能作为烹饪视频"智能助手"的Vid-LLM
- 不仅需要它列出食材
- 还要能规划后续步骤
- 甚至擅长识别面团是否发酵充分等特定任务。该如何教会它这些能力?
Vid-LLM方法分类体系帮助我们理解实现这些能力的不同核心策略。
它分类整理了研究人员和工程师设计和训练这些模型的方式——从赋予广泛通用知识到针对特定任务的专业化训练。
(实现专业化训练后,之后再各司所长,拼接组装)
让我们深入探索创建Vid-LLMs的不同方法~
1. 基于LLM的视频代理:智能规划者
描述:这种方法赋予Vid-LLM规划行动的能力。模型在此不仅是回答问题,更充当"管理者"或"代理"。它观察视频,使用外部工具(如物体检测器或动作识别器)理解具体细节,然后运用语言推理能力决定后续行动或回答需要多步思考的复杂查询。
类比:就像一位不仅懂食谱,还能查看食材、决定使用什么工具,然后指导烹饪过程的人类厨师。Vid-LLM不直接"观看"所有内容,而是将特定视觉任务委托给小型专业"视觉工具",然后利用结果进行规划。
概念示意:
- 输入:视频和查询(如"根据这个视频我该如何做蛋糕?")
- LLM角色:接收查询,分解为子问题(如"找出食材"、“识别烘焙步骤”)
- 视觉工具:处理视频以识别食材和动作
- LLM行动:组合工具结果,规划步骤序列,提供连贯回答
解决烹饪用例:
如果我们的烹饪助手需要根据视频规划食谱,基于LLM的视频代理方法就很适合。
# 基于LLM的视频代理概念示例
class VideoAgentChef:def __init__(self):print("厨师代理准备规划!")# 这些是LLM的专业辅助工具self.object_detector = {"video_id": "面粉,鸡蛋,糖"} # 简化工具self.action_recognizer = {"video_id": "混合,烘焙"} # 简化工具self.llm_planner = LLM_Core() # 代理的"大脑"def plan_recipe(self, video_id: str, goal: str):print(f"代理正在观察视频{video_id},目标:{goal}")# LLM使用其"眼睛"(视觉工具)ingredients = self.object_detector.get(video_id, "ingredients")actions = self.action_recognizer.get(video_id, "main actions")# LLM使用其"大脑"规划plan = self.llm_planner.generate_plan(goal, ingredients, actions)return plan# 初始化我们的代理
chef_agent = VideoAgentChef()
# 要求它根据视频规划食谱
recipe_plan = chef_agent.plan_recipe("cooking_tutorial.mp4", "制作巧克力蛋糕")
print(f"\n厨师代理的规划:{recipe_plan}")
概念性输出:
厨师代理准备规划!
代理正在观察视频cooking_tutorial.mp4,目标:制作巧克力蛋糕
厨师代理的规划:[步骤1:准备面粉、鸡蛋、糖、巧克力豆。步骤2:如视频所示混合食材。步骤3:在推荐温度下烘焙。]
这里LLM_Core作为中央规划者,利用其他简单组件收集的信息实现复杂目标。
2. Vid-LLM预训练:学习通用知识
描述:这就像送学生去综合性大学。
Vid-LLM预训练涉及在*海量*多样化视频和文本数据(如数十亿个配有描述的视频片段)上训练模型。目标是让模型学习视觉概念、声音和语言之间关联的广泛通用理解。它尚未专精任何特定任务,但从视频中发展出基础"世界知识"。
类比:儿童通过观看无数视频和阅读大量书籍来理解世界。他们还没有特定工作,但理解物体运动、人际互动和不同语境下词语含义等许多知识。
概念示意:
- 输入:大量
(视频,描述文本)配对数据集 - 训练目标:学习视频内容与其文本描述间的强大映射(关联),使模型能以语言兼容的方式表示视频信息
解决烹饪用例:
预训练的Vid-LLM会对烹饪动作(切菜、混合、烘焙)和物体(刀具、平底锅、食材)有通用理解,因为它看过大量相关视频。
# Vid-LLM预训练概念示例
class VidLLMPretrainer:def __init__(self):self.video_text_mapper = LargeNeuralNetwork() # Vid-LLM模型本身print("Vid-LLM预训练器已初始化")def pretrain(self, huge_video_text_dataset):print("开始在庞大数据集上预训练...")# 模拟模型学习连接视频和文本# 为简化,我们仅从几个示例"学习"for video, text in huge_video_text_dataset:# 模型学习通用模式:"这个视频展示X,这段文字描述X"print(f"从关于'{text}'的视频学习")self.video_text_mapper.process_pair(video, text) print("预训练完成。模型已具备通用视频理解能力!")# 大规模数据集的占位符
massive_dataset = [("cat_playing.mp4", "一只猫在玩玩具"),("chef_cooking.mp4", "厨师在烤蛋糕"),("city_street.mp4", "繁忙街道上的车辆")
]pretrainer = VidLLMPretrainer()
pretrainer.pretrain(massive_dataset)
概念性输出:
Vid-LLM预训练器已初始化
开始在庞大数据集上预训练...
从关于'一只猫在玩玩具'的视频学习
从关于'厨师在烤蛋糕'的视频学习
从关于'繁忙街道上的车辆'的视频学习
预训练完成。模型已具备通用视频理解能力!
现在video_text_mapper对各种场景和活动有了广泛理解。
LaViLa和Vid2Seq等模型就采用这种方法获取通用理解能力。
3. Vid-LLM指令微调:任务专业化
描述:当Vid-LLM通过预训练获得通用知识后,指令微调就像给它进行特定工作培训。模型在较小的高质量数据集上进行微调,这些数据将视频与特定指令配对(如"描述这个视频"、“回答问题’发生了什么?'”)。这教会模型遵循指令并准确执行特定视频理解任务。
类比:就像我们的厨师助手在完成通用烹饪学校学习后,参加"糕点制作"或"酱汁调制"专业课程。他们学习准确响应"制作舒芙蕾"或"浓缩高汤"等具体指令。
概念示意:
- 输入:较小的
(视频,指令,期望回答)三元组数据集 - 训练目标:调整预训练模型以更好遵循指令,为各种任务生成准确输出
解决烹饪用例:
预训练后,我们的Vid-LLM可能对烹饪有通用理解。通过指令微调,我们可以教会它具体回答"主要食材有哪些?"或"总结这个食谱"等问题。
# Vid-LLM指令微调概念示例
class VidLLMInstructionTuner:def __init__(self, pretrained_vid_llm_model):self.model = pretrained_vid_llm_model # 从具备通用知识的模型开始print("指令微调器准备进行专业化训练")def instruction_tune(self, task_specific_dataset):print("开始针对特定任务进行指令微调...")# 每个条目是(视频,指令,正确答案)for video, instruction, correct_answer in task_specific_dataset:# 模型学习根据'视频'为'指令'生成'正确答案'print(f"教导模型回答关于视频的'{instruction}'")self.model.fine_tune_on_example(video, instruction, correct_answer)print("指令微调完成。模型已专业化!")# 假设我们预训练得到的通用Vid-LLM
general_vid_llm = VidLLMPretrainer().video_text_mapper # 来自前述概念步骤# 用于特定烹饪问题的小型数据集
cooking_qa_dataset = [("cooking_tutorial.mp4", "主要食材有哪些?", "面粉、鸡蛋、糖、牛奶"),("pizza_making.mp4", "总结这个视频", "从零开始制作家庭披萨")
]tuner = VidLLMInstructionTuner(general_vid_llm)
tuner.instruction_tune(cooking_qa_dataset)
概念性输出:
指令微调器准备进行专业化训练
开始针对特定任务进行指令微调...
教导模型回答关于视频的'主要食材有哪些?'
教导模型回答关于视频的'总结这个视频'
指令微调完成。模型已专业化!
现在模型能专门回答烹饪问题了!Video-LLaMA和Video-ChatGPT等模型就采用指令微调。

4. 混合方法:强强联合
描述:顾名思义,混合方法结合多种策略。可能包括既经过广泛预训练又采用LLM代理的模型,或是整合预训练、指令微调和工具专用训练要素的模型。
目标是利用不同方法的优势,创建更强大、多功能的Vid-LLM。
类比:我们的厨师助手可能上过通用烹饪学校(预训练),然后接受专业糕点培训(指令微调),还学会使用高级厨房设备(基于代理的工具)——结合所有这些技能使其成为真正多才多艺的厨师!
概念示意:
- 结合:预训练、指令微调和基于代理方法的要素
- 目标:创建能处理更广泛任务和复杂性的强大模型
解决烹饪用例:
混合型Vid-LLM厨师助手可以拥有广泛理解能力、擅长特定任务,还能智能规划多步骤食谱。VideoChat等模型常使用混合策略。
5. 免训练方法:智能复用
描述:有时不需要大量新训练!免训练方法通过巧妙组合现有的强大预训练模型(如强大的图像理解模型和文本LLM),无需显著额外训练。它们可能使用特定方式格式化输入或小型"适配器"等技术来"桥接"不同模型的信息,使其协同工作。
类比:就像我们的厨师拥有食谱书(LLM)和识别食材的能力(视觉模型),但需要一张食谱卡来告诉它如何为食谱书解释食材列表。不需要新的"厨师培训",只需巧妙连接现有知识。
概念示意:
- 利用:现有的强大视觉模型(VLM)和大语言模型(LLM)
- 最小/无训练:专注于"连接"或"提示"现有模型
解决烹饪用例:
我们可以采用现有的食材识别图像理解模型和现有的食谱知识文本LLM
创建一个能*同时使用两者*回答烹饪视频问题的系统,而无需从头训练任一模型。SlowFast-LLaVA就是免训练方法的例子。
Vid-LLM方法体系总结
以下是创建和训练Vid-LLMs不同方法的快速概览:
| 方法体系 | 核心理念 | 目标/优势 | 类比(厨师助手) |
|---|---|---|---|
| 基于LLM的视频代理 | LLM作为规划者,使用外部工具(如物体检测器) | 实现复杂多步推理、规划和工具使用 | 主厨将任务(如切菜)分配给初级厨师然后规划整餐 |
| Vid-LLM预训练 | 在海量视频-文本数据上训练以获得通用理解 | 发展对视频及其语言描述的广泛基础认知 | 上通用烹饪学校学习食品和烹饪基础知识 |
| Vid-LLM指令微调 | 在任务特定指令上微调预训练模型 | 使模型擅长遵循特定命令和执行专门任务 | 烹饪学校毕业后参加专业课程(如"糕点制作") |
| 混合方法 | 组合多种策略(预训练、微调、代理) | 综合不同方法的优势,实现鲁棒性和多功能性 | 具备通用知识、专业技能和高效工具使用能力的主厨 |
| 免训练方法 | 复用和连接现有强大模型而无需新训练 | 快速实施、成本效益高,利用现有最先进组件 | 厨师使用知名食谱和食材识别指南而无需新培训 |
内部机制:基于LLM的视频代理
让我们快速展示基于LLM的视频代理的操作流程,看看它如何"思考"和交互。这有助于区分它与单纯的预训练或指令微调——那些是关于模型如何初始构建的。
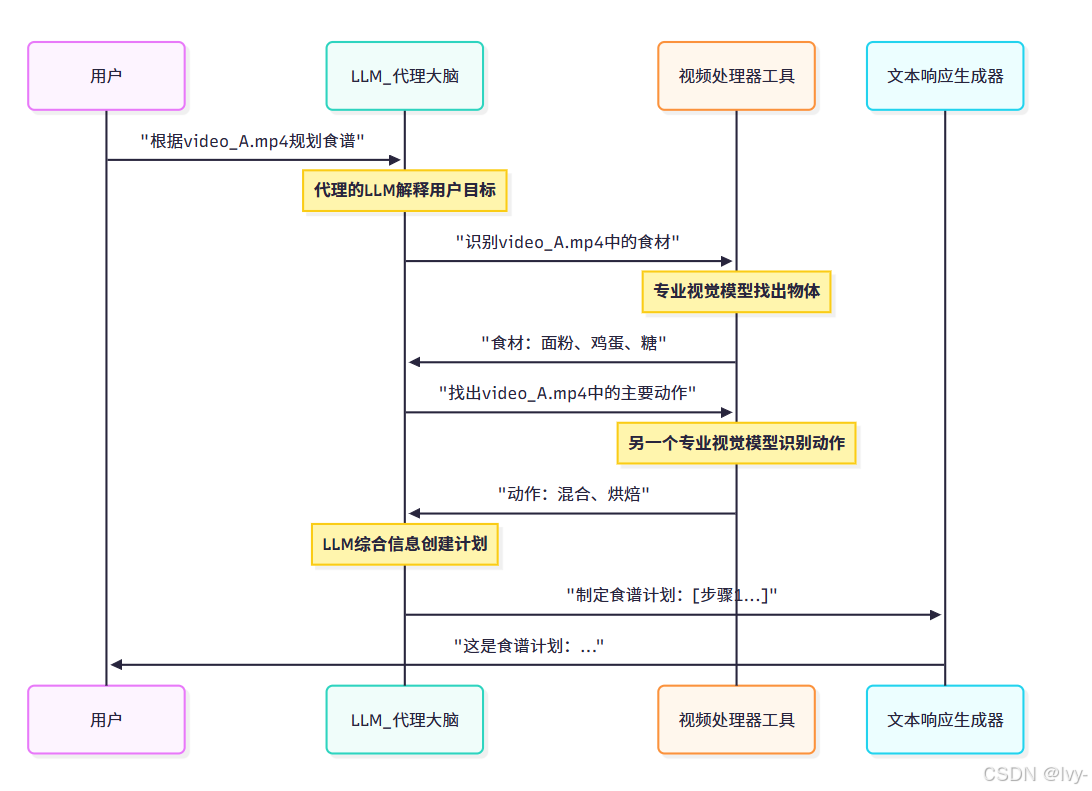
在这个概念流程中:
- 用户给出复杂指令
- LLM代理大脑(核心LLM)接收指令并充当协调者,不直接"观看"视频
- 它要求视频处理器工具(专业视觉模型)从视频中提取特定信息(如食材或动作)
- 视频处理器工具将请求的信息提供给LLM
- LLM代理大脑结合这些信息和其丰富的语言知识制定详细计划或回答
- 文本响应生成器格式化最终输出给用户
这展示了代理方法如何通过独立的专业工具进行动态交互和规划,而不是单一模型处理所有事情。
结语
本章我们深入理解了创建和训练Vid-LLMs的各种方法体系。
从赋予通用世界认知(预训练)到针对精确任务的专业化(指令微调),使它们能够规划和利用工具(基于LLM的视频代理),或组合这些方法实现强大解决方案(混合方法)乃至智能复用(免训练方法)——每种方法在构建当今强大的Vid-LLMs中都扮演着关键角色。
了解这些不同方法,有助于我们欣赏研究人员连接语言与动态视频世界的多样化途径。既然我们已经理解Vid-LLMs如何构建和训练,接下来让我们探索它们部署后的不同功能——能扮演什么角色。
下一章:Vid-LLM功能分类体系