《C++起源与核心:版本演进+命名空间法》
😘个人主页:@Cx330❀
👀个人简介:一个正在努力奋斗逆天改命的二本觉悟生
📖个人专栏:《C语言》《LeetCode刷题集》《数据结构-初阶》《C++知识分享》
🌟人生格言:心向往之行必能至

前言:我们在前面已经学习了C语言和数据结构初阶这两大块的知识了,后续就进入了C++的学习中,C++的学习过程并不简单,它难学难精,但是大家有了前面学习的基础后在前期可以轻松上手,后续只要大家坚持,就一定可以掌握,那么第一篇C++的博客给大家介绍一下C++的起源与发展历史,在入门期间讲到的一些语法也是为了弥补C语言中存在的不足
目录
一、C++的发展历史
关键节点:
版本演进:
C++参考文档:
C++参考书籍:
二、C++的第一个程序
三、命名空间
namespace的价值:
namespace的定义:
命名空间的使用:
一、C++的发展历史
-我们将C++的发展史归纳为节点的形式展示
关键节点:
- 起源(1979–1983):丹麦科学家本贾尼·斯特劳斯特卢普在贝尔实验室开发“带类的 C 语言”,旨在为 C 语言添加面向对象特性,1983 年正式命名为 C++。
- 标准化起步(1983–1998):1985 年首本权威著作发布,逐步加入虚函数、模板等核心特性;1998 年 ISO 发布首个标准 C++98,确立语言规范。
- 功能完善(2003–2017):2003 年 C++03 修正技术缺陷;2011 年 C++11 开启“现代 C++”,引入 auto、lambda 等重要特性;2014/2017 年标准进一步优化易用性。
- 现代演进(2020 至今):2020 年 C++20 新增概念、模块、协程等重大特性;2023 年 C++23 完善现有功能,持续平衡性能与抽象能力。
版本演进:
-我们通过表格来了解C++的版本更新过程
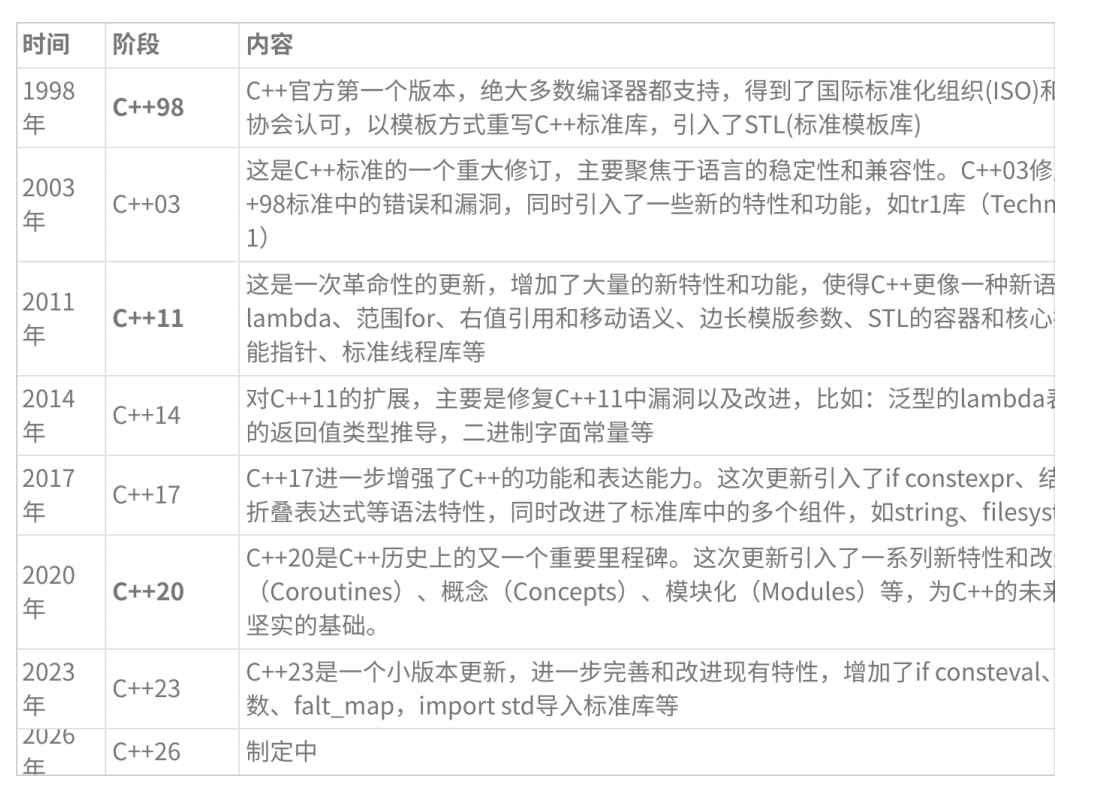
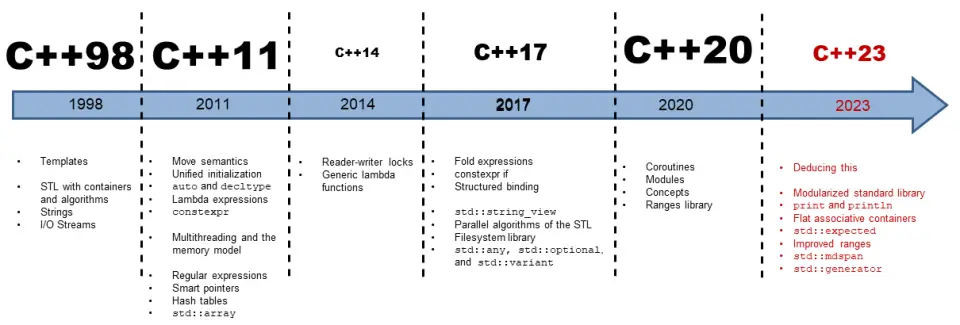
C++参考文档:
Reference - C++ Reference
cppreference.com
注意:第一个链接不是C++官方文档,标准只更新到了C++11,但是以头文件的形式呈现,内容比较容易看懂。后面一个是C++官方的文档,信息很全,更新也是最新的,但是对比第一个就没那么容易看了,另外两者都是英文版的。这两个文档建议大家结合起来使用。
C++参考书籍:

- C++ Primer:主要讲解语法,经典的语法书籍,前后中期都可以看,前期如果自学看可能会有点晦涩难懂,能看懂多少看懂多少,就当预习,中后期作为语法字典,非常好用。
- STL源码剖析:主要从底层实现的角度结合STL源码,庖丁解牛式剖析STL的实现,是侯捷老师的经典之作。可以很好的帮助我们学习别人用语法是如何实现出高效简洁的数据结构和算法代码,如何使用泛型封装等。让我们不再坐井观天,闭门造车,本书课程上⼀半以后,中后期可以看。
- Effctive C++:本书也是侯捷老师翻译的,本书有的⼀句评价,把C++程序员分为看过此书的和没看过此书的。本书主要讲了55个如何正确高效使用C++的条款,建议中后期可以看⼀遍,工作1-2年后再看⼀遍,相信会有不⼀样的收获。
二、C++的第一个程序
-C++兼容大多数的C,C语言中实现打印操作在C++中依然可以运行,但是C++有自己的一套输入输出方式,我们对比来看一下
C版本:
#include<stdio.h>
int main()
{printf("Hello World\n");return 0;
}C++版本:大家看不懂后续会讲解
#include<iostream>
using namespace std;
int main()
{cout << "Hello World" << endl;cout << "Hello World" << '\n';return 0;
}三、命名空间
namespace的价值:
- 在C/C++中,变量、函数和后面要学到的类都是⼤量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
C语言项目类似下面程序这样的命名冲突是普遍存在的问题,C++引入namespace就是为了更好的解决这样的问题
#include<stdio.h>
#include<stdlib.h>int rand = 10;
int main()
{printf("%d\n", rand);//因为rand是stdlib的个库函数,重定义了return 0;
}![]()
namespace的定义:
- 定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接⼀对{ }即可,{}中 即为命名空间的成员。命名空间中可以定义变量/函数/类型等。
- namespace本质是定义出⼀个域,这个域跟全局域各自独立,不同的域可以定义同名变量,所以下面的rand不在冲突了。
- C++中域有函数局部域,全局域,命名空间域,类域;域影响的是编译时语法查找⼀个变量/函数/ 类型出处(声明或定义)的逻辑,所有有了域隔离,名字冲突就解决了。局部域和全局域除了会影响 编译查找逻辑,还会影响变量的⽣命周期,命名空间域和类域不影响变量生命周期。
- namespace只能定义在全局,当然他还可以嵌套定义。
- 项目工程中多文件中定义的同名namespace会认为是⼀个namespace,不会冲突。
- C++标准库都放在⼀个叫std(standard)的命名空间中。
正常的命名空间定义: (注意看注释)
#include<stdio.h>
#include<stdlib.h>namespace Cx330
{int rand = 10;int Add(int x,int y){return x + y;}struct Node{struct Node* next;int data;};}//无分号
int main()
{//默认访问的是全局的rand函数指针printf("%p\n", rand);//编译器语法查找确认规则是默认先局部查找->全局查找->没有找到就报未声明的标识符这个错误//::域作用限定符,这里指定作用域,就直接按这个域去找->没有找到就报未声明的标识符这个错误printf("%d\n", Cx330::rand);//这底下的就不详细讲述了,很好理解printf("%p\n", Cx330::Add);printf("%d\n", Cx330::Add(5, 3));//8struct Cx330::Node node;return 0;
}
命名空间的嵌套使用:
//命名空间的嵌套使用
#include<stdio.h>
#include<stdlib.h>namespace Cx330
{namespace A{int rand = 10;int Sub(int x, int y){return x - y;}}namespace B{int rand = 20;int Sub(int x, int y){return x - y;}}
}int main()
{printf("%d\n", Cx330::A::rand);//10printf("%d\n", Cx330::B::rand);//20printf("%d\n", Cx330::A::Sub(5, 3));//2printf("%d\n", Cx330::B::Sub(6, 2));//4return 0;
}
我们在项目经常可以使用到命名空间的嵌套,大家可以看下面这个图片来理解一下:

-多文件中可以定义同名namespace,他们会默认合并在一起,就像同一个namespace一样,这里演示起来逻辑简单但是代码量还是比较多的。大家有兴趣的可以拿之前的栈和队列自己试一下
命名空间的使用:
编译查找一个变量的声明/定义时,默认只会在局部或者全局查找,不会到命名空间里面去查找。我们使用命名空间中定义的变量/函数,有以下三种方式:
- 指定命名空间访问,这种形式在项目中比较推荐
- using将命名空间中某个成员展开,项目中经常访问的不存在冲突的成员推荐使用这种方式
- 展开命名空间中的全部成员,项目中不推荐,冲突风险很大,日常刷题中比较方便推荐使用
-我们下面先拿std库里的几个函数来举例说明一下,后续会详细讲述
#include<iostream>
#include<algorithm>
//命名空间中成员部分展开
using std::cout;int main()
{int a, b;std::cin >> a >> b;//输入cout << a << " " << b << '\n';//输出return 0;
}-可以观察到部分展开了之后cout就不需要在前面加东西了,但是cin还是要的
命名空间中成员全部展开:
#include<iostream>
#include<algorithm>
//命名空间中成员全部展开
using namespace std;int main()
{int a, b;cin >> a >> b;//输入cout << a << " " << b << '\n';//输出return 0;
}-这里就都不需要指定命名空间去访问了,平常刷题时使用起来确实是很方便的,大的项目还是推荐大家不要这样用
往期回顾:
【数据结构初阶】--排序(一):直接插入排序,希尔排序
【数据结构初阶】--排序(二):直接选择排序,堆排序
【数据结构初阶】--排序(三):冒泡排序、快速排序
总结:这篇博客到这里就结束了,后续博主还会更新两篇博客来讲解C语言中语法不足的地方才会进入后续的C++学习中,C++的学习难度是很平滑的,难度逐渐上升,而不是一下子上升很大,如果文章对你有帮助的话,欢迎评论,点赞,收藏加关注,感谢大家的支持。