94. 城市间货物运输 I, Bellman_ford 算法, Bellman_ford 队列优化算法
94. 城市间货物运输 I
Bellman_ford 算法
Bellman_ford 算法 与 dijkstra算法 相比通用性更强。
dijkstra算法解决不了负权边的问题,因为Dijkstra基于贪心策略,一旦一个节点被从队列中取出(标记为已解决),它就假定已经找到了到达该节点的最短路径。如果存在负权边,可能会有一条通过负权边的路径去到达该节点,这个负权边可以让一个已经被标记为已解决的节点的距离变得更小,但算法不会再回头去检查它,从而导致错误的结果。
Bellman_ford 算法的核心思想是 对所有边进行松弛n-1次操作(n为节点数量),从而求得目标最短路。
什么是松弛?
松弛是Bellman_ford 算法的实现基础。
松弛就是一个“检查并更新”的过程:检查是否存在一条通过某个中间节点的更短路径,如果存在,就更新当前的最短路径估计。其实就是更新min_List数组,来判断从起点出发到达下一个点是否有更短的路径。
代码实现:
# 对边 (u, v) 进行松弛操作
if dist[u] + weight(u, v) < dist[v]:dist[v] = dist[u] + weight(u, v)prev[v] = u # 可选:记录v是从u来的为什么是n-1次?
因为任何不包含负权环的最短路径最多包含 n-1 条边。n-1 次松弛足以保证找到所有可能的最短路径。 即n个点的话,从起点出发到终点的最短路径只需要经过n-1条边。
Bellman_ford 算法为什么能解决负权边的问题?
为什么dijkstra算法不能解决负权边的问题,关键是visited数组的设置导致了即使有负权边通向某个结节点,但由于visited中该节点之前被访问过了,因此无法更新。
Bellman-Ford 算法不依靠visited数组,其实现就是从每个点出发去松弛n-1次,来得到从起点出发经过该节点到达下一个节点时的最短路径。如下
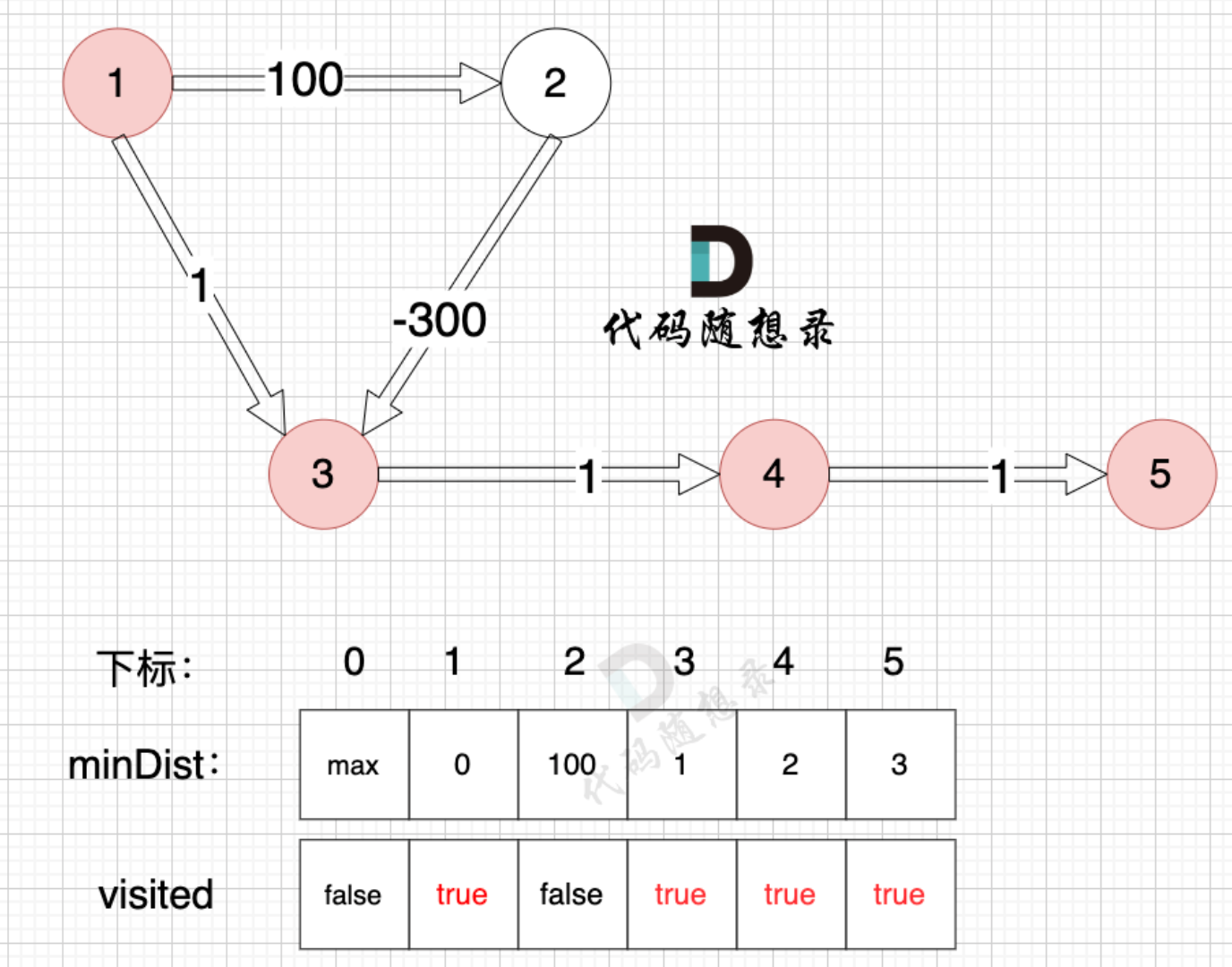
dist 初始化为 [ ∞, 0, ∞, ∞, ∞, ∞ ],n=5,因此需要松弛4次。
第一次松弛:
- 边
1→2(100): dist[1] + 100 = 0 + 100 = 100 < ∞ → 更新 dist[2] = 100 - 边
1→3(1): dist[1] + 1 = 0 + 1 = 1 < ∞ → 更新 dist[3] = 1 - 边
2→3(-300): dist[2] + (-300) = 100 - 300 = -200 < 1 → 更新 dist[3] = -200 - 边
3→4(1): dist[3] + 1 = -200 + 1 = -199 < ∞ → 更新 dist[4] = -199 - 边
4→5(1): dist[4] + 1 = -199 + 1 = -198 < ∞ → 更新 dist[5] = -198
第二次松弛
- 边
1→2(100): 0 + 100 = 100 = 100 → 无变化 - 边
1→3(1): 0 + 1 = 1 > -200 → 无变化 - 边
2→3(-300): 100 - 300 = -200 = -200 → 无变化 - 边
3→4(1): -200 + 1 = -199 = -199 → 无变化 - 边
4→5(1): -199 + 1 = -198 = -198 → 无变化
......
经过4次松弛后就得到了更新后的min_List数组。从树的生成角度来理解这两个算法,如下: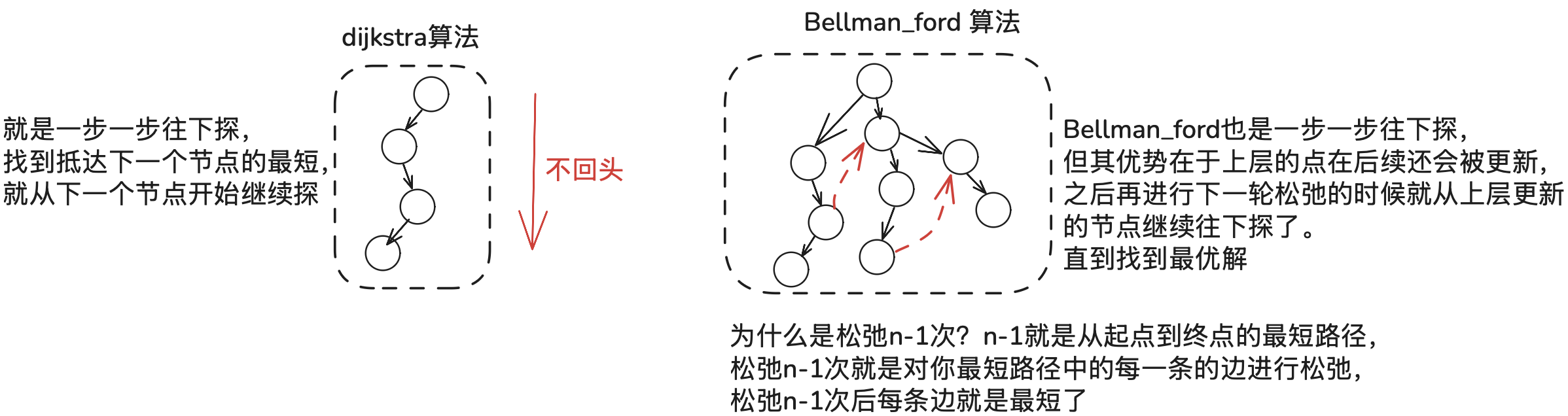
Code
if __name__ == "__main__":city_size, road_size = map(int, input().split())length = city_size + 1graph = [[] for _ in range(length)] ##graph 存储了length个空数组min_List = [float('inf')] * lengthmin_List [1] = 0for _ in range(road_size):s, t, v = map(int, input().split())graph[s].append([t,v])for _ in range(city_size): ## 松弛n-1次updated = False ## 不一定要松弛完n-1次,如果发现不再更新了,那就可以退出了for i in range(1, length): ## 遍历每个点cur_node = i if len(graph[i]) == 0: ## 没有下一个节点 continuefor j in range(len(graph[i])): ## 每个节点进行了n-1次循环。即n-1次松弛next_node = graph[i][j][0]value = graph[i][j][1]dis = min_List[cur_node] + value # 从起点出发经历当前节点到下一个节点if min_List[cur_node] != float('inf') and dis < min_List[next_node]:min_List[next_node] = disupdated = Trueif updated == False: # 在一次松弛过程中,遍历完所有节点后发现min_List没有更新break if min_List[-1] == float('inf'):print("unconnected")else:print(min_List[-1])注意:非常重要的点:
- 松弛是外循环,遍历节点在内循环。
- 一次松弛是对每个节点之间的边关系进行松弛,而不是一次松弛对当前节点下的所有边关系进行松弛,要搞清楚这二者的区别。
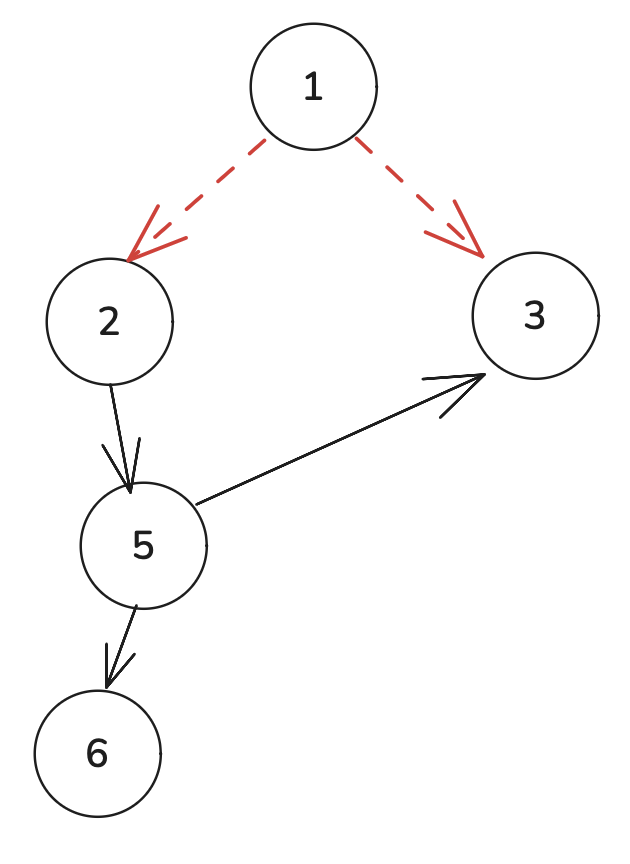
前者才是在找最优解,后者问题很大,看似像dijkstra算法,但dijkstra算法是每次选当前离起点距离最小的未访问节点去进行遍历,后者现在的问题是最短路径一定要是按编号顺序走去到吗?如下图:
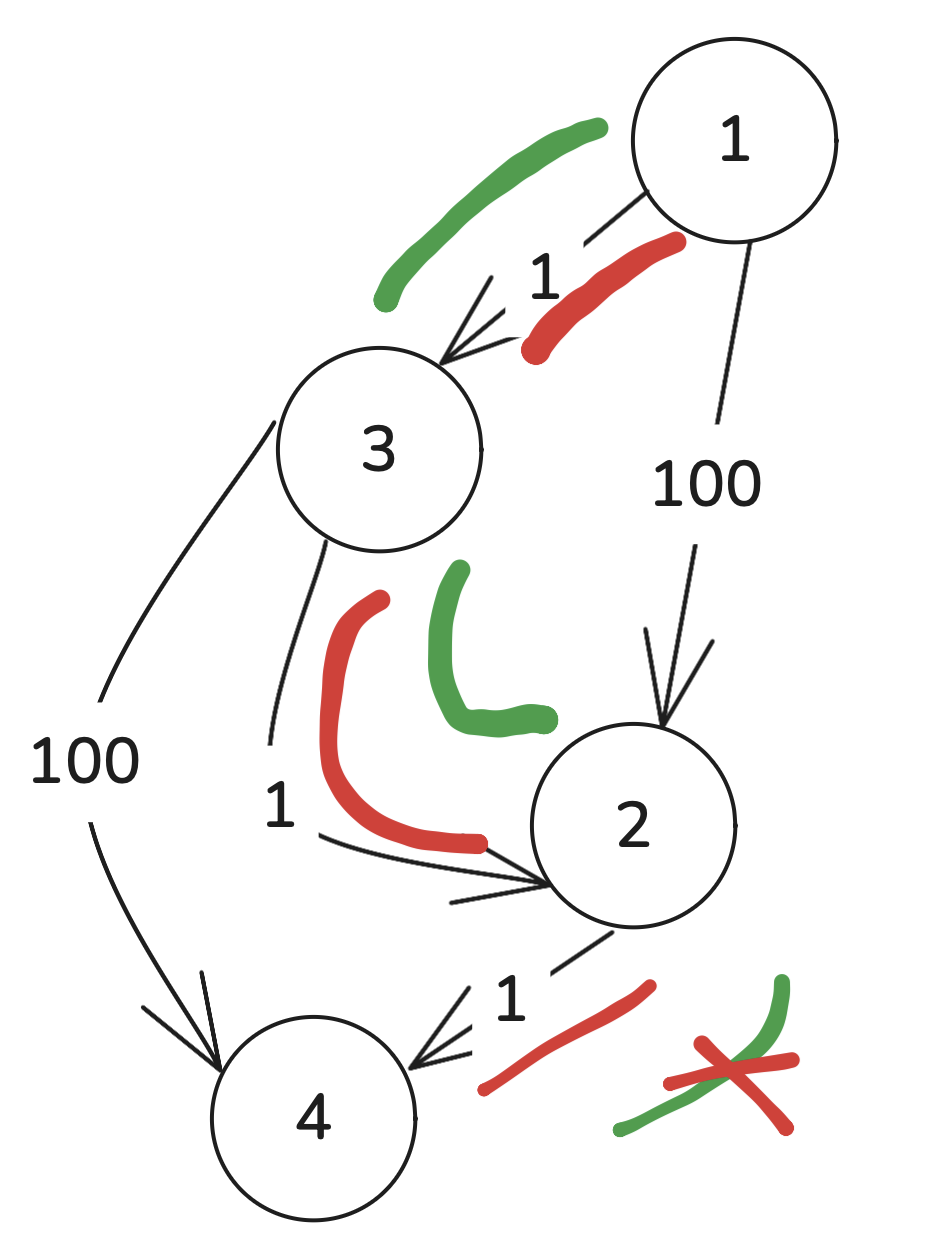
正确路径应该是1-3-2-4,后者是顺序遍历节点,当遍历到3时,此时虽然能更新节点2的min_List值,但由于后续你不会再去遍历节点2了,因此找不到最优解。
Bellman_ford 队列优化算法
优化思路:
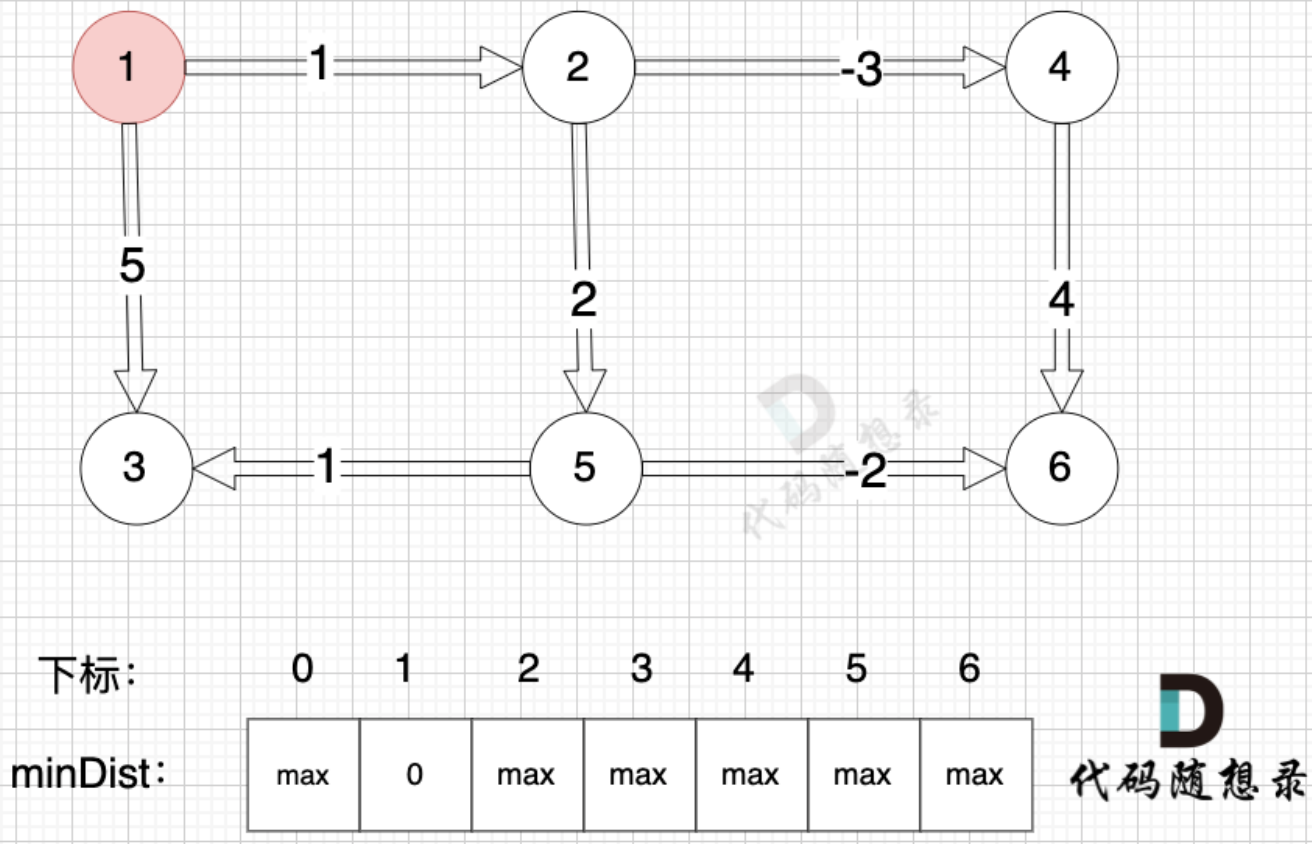
没用队列优化的Bellman_ford算法时间复杂度是O(N*E), N是松弛次数,E是节点数目。由于上述Bellman_ford算法我们通过数组来有序地存储了节点从小到大的边的关系,因此本身也算是优化了。
如果没有用数组有来序存储了节点从小到大的边的关系,而是直接根据题意提供的边的顺序进行松弛,那就会出现一个问题。当我们遍历当前节点如5时,想要松弛得到min_List[6],但当前min_List[5] 为 max,因为 1 -> 2 这条边的关系放在后面,因此还没松弛到,此时那你松弛5 -> 6这条边就是在做无用功。边的提供顺序如下:
| 2 | 5 | 2 |
| 5 | 6 | -2 |
| 5 | 3 | 1 |
| 1 | 2 | 1 |
| 1 | 3 | 5 |
此时,你在根据这个顺序进行松弛操作就做了很多无用功,因为你要算下一个节点到起点的最短距离,但距离起点更近的点此时候都不知道,那松弛就是在做无用功。如下,你要求5,3,6到1的最近距离,那关键边1-2, 1-3 都没传进来,此时松弛就是无用功。
Code
from collections import dequeif __name__ == "__main__":city_size, road_size = map(int, input().split())length = city_size + 1graph = [ [] for _ in range(length)]min_List = [float('inf')] * lengthmin_List [1] = 0for _ in range(road_size):s, t, v = map(int, input().split())graph[s].append([t,v]) ## 直接按提供的边的顺序进行存储queue = deque()queue.append(1) ## 先将起点存入,queue的顺序为从起点开始到终点的经过过的节点顺序visited = [False] * lengthvisited[1] = Truefor i in range(city_size): ## 松弛n-1次 updated = Falsewhile queue:cur_node = queue.popleft()visited[cur_node] = False ## 方便下次松弛时,visited数组更改为False了,这样你才能对上层节点的边进行更新。如果上层节点松弛后更新了,那后续就添加到队列中继续进行松弛操作了。for t, v in graph[cur_node]: ## 直接从上一个节点下的链表进行查找下一个点if min_List[cur_node] + v < min_List[t]:min_List[t] = min_List[cur_node] + v ## 对边进行松弛if visited[t] == False: ## 下一个点不在队列里面visited[t] = True ## 对松弛后更新的边进行标记,让其只在队列中出现一次,以确保后续不重复松弛queue.append(t) ## A -> B, 现在是从A去处理B之前的节点边关系,后面就是从B出发去处理下一个节点之前的边的节点关系updated = Trueif updated == False: ## 松弛后发现min_List不变了,那后续没必要松弛了breakif min_List[-1] == float('inf'):print("unconnected")else:print(min_List[-1])注意:
- visited的设置是为了队列中每一个元素都是唯一的,保证不重复添加相同的元素,比如当前队列中已经有6这个节点,如果你没有visited数组,后续在松弛的过程又对6的min_list数组进行了更新,又往队列中添加了一次节点6,导致队列中出现两次节点6,后续就对节点6进行了重复的松弛的操作。visited的设置主要是为了优化,屏蔽掉的话也可以通过,但当边的关系很多很复杂时,此时可能就会存在超时的情况。
- 在时间复杂度上,该优化方法的时间复杂度为O(N*k),N表示节点数量,k表示每个节点的出度。