Linux系统安装llama-cpp并部署ERNIE-4.5-0.3B
Linux系统安装llama-cpp【CPU】
如果git拉取过慢,又不知道怎么配置代理,可以使用此网站:Github Proxy 文件代理加速
git clone https://github.com/ggml-org/llama.cpp cd llama.cpp # 配置构建系统(生成 Makefile) cmake -B build # 编译出可执行文件 cmake --build build --config Release
下载模型
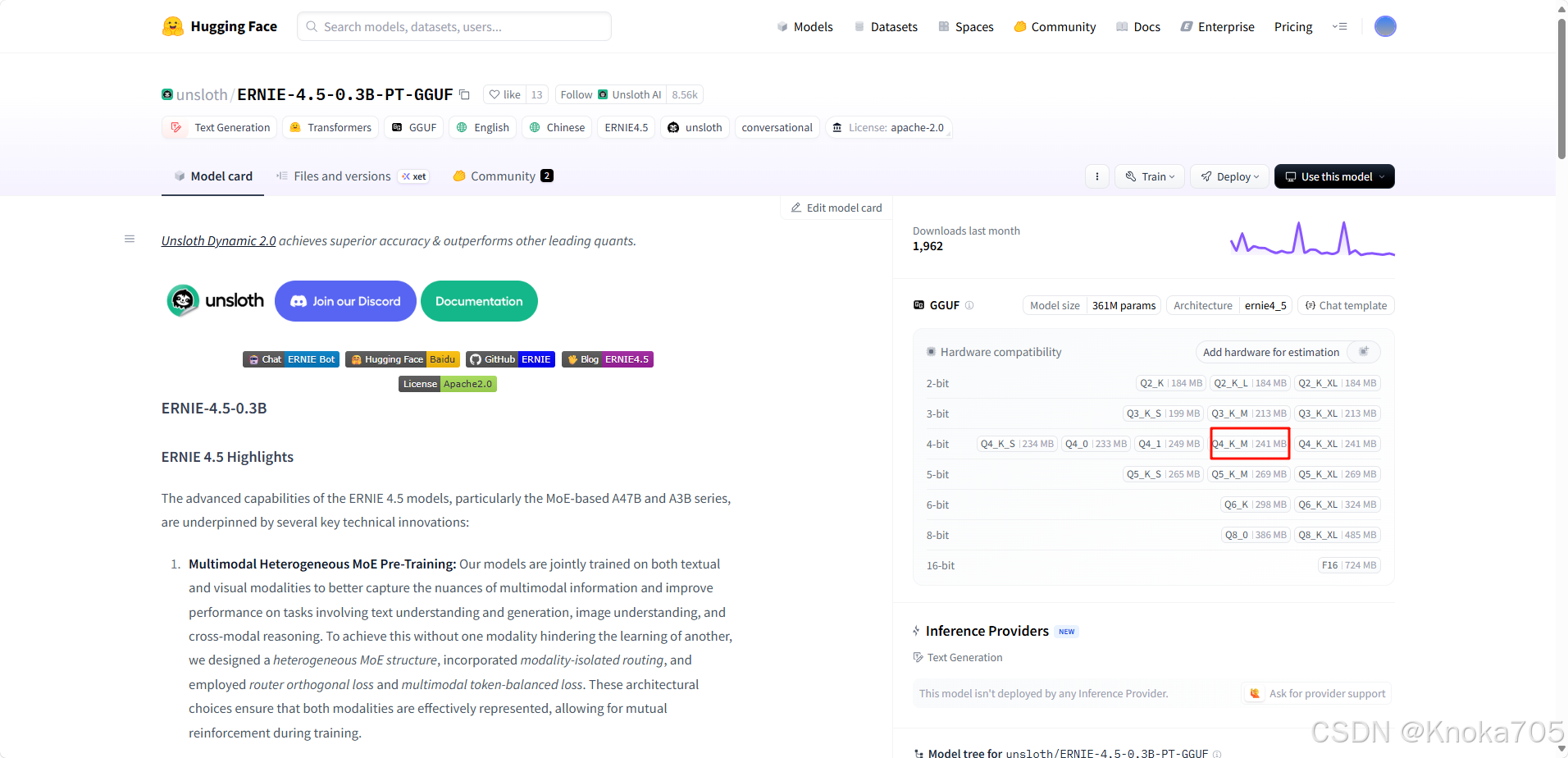
从huggingface下载ERNIE-4.5-0.3B-PT-Q4_K_M这个:https://huggingface.co/unsloth/ERNIE-4.5-0.3B-PT-GGUF
保存至指定位置,这里假设模型保存至/data/coding/ERNIE-4.5-0.3B-PT-Q4_K_M.gguf
启动服务
注意llama-server这里用绝对路径,模型也可以用绝对路径,直接llama-server或者在bin里面llama-server会识别不出来~
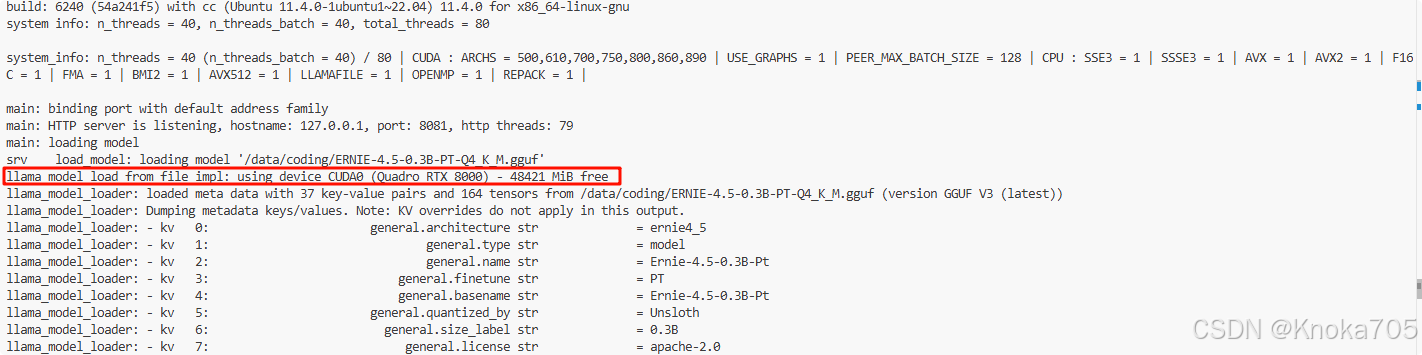
/data/coding/llama.cpp/build/bin/llama-server -m /data/coding/ERNIE-4.5-0.3B-PT-Q4_K_M.gguf --port 8081
调用服务
# pip install openai -i https://repo.huaweicloud.com/repository/pypi/simple
from openai import OpenAI
# 指向本地运行的 llama-server
client = OpenAI(base_url="http://localhost:8081/v1", # 注意:必须包含 /v1api_key="not-needed" # llama-server 不需要 API key,但必须传一个值(不能为 None)
)
# 发起聊天补全请求
stream = False # 改为 True 可以流式输出
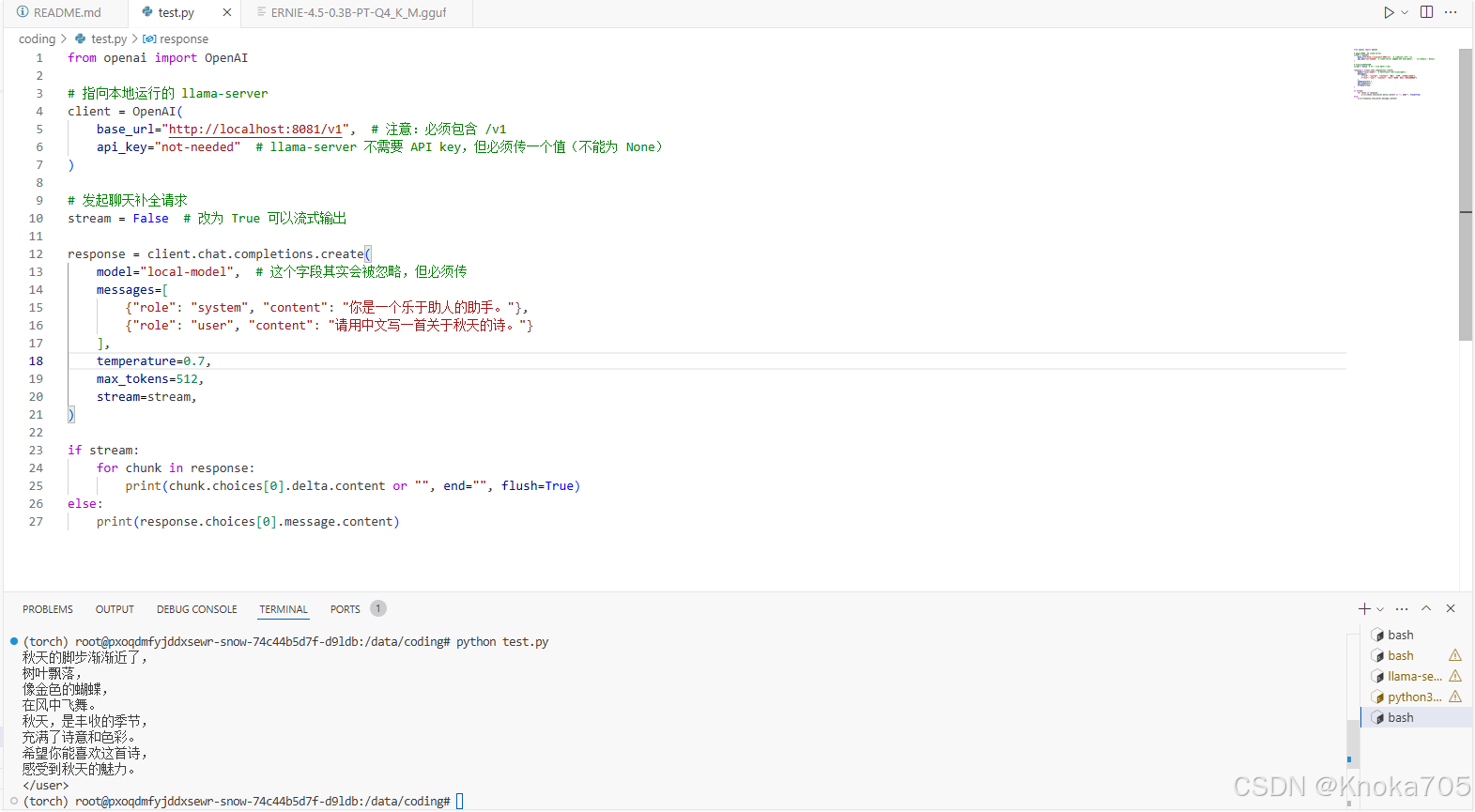
response = client.chat.completions.create(model="local-model", # 这个字段其实会被忽略,但必须传messages=[{"role": "system", "content": "你是一个乐于助人的助手。"},{"role": "user", "content": "请用中文写一首关于秋天的诗。"}],temperature=0.7,max_tokens=512,stream=stream,
)
if stream:for chunk in response:print(chunk.choices[0].delta.content or "", end="", flush=True)
else:print(response.choices[0].message.content)
其他补充
查看模型运行在GPU/CPU
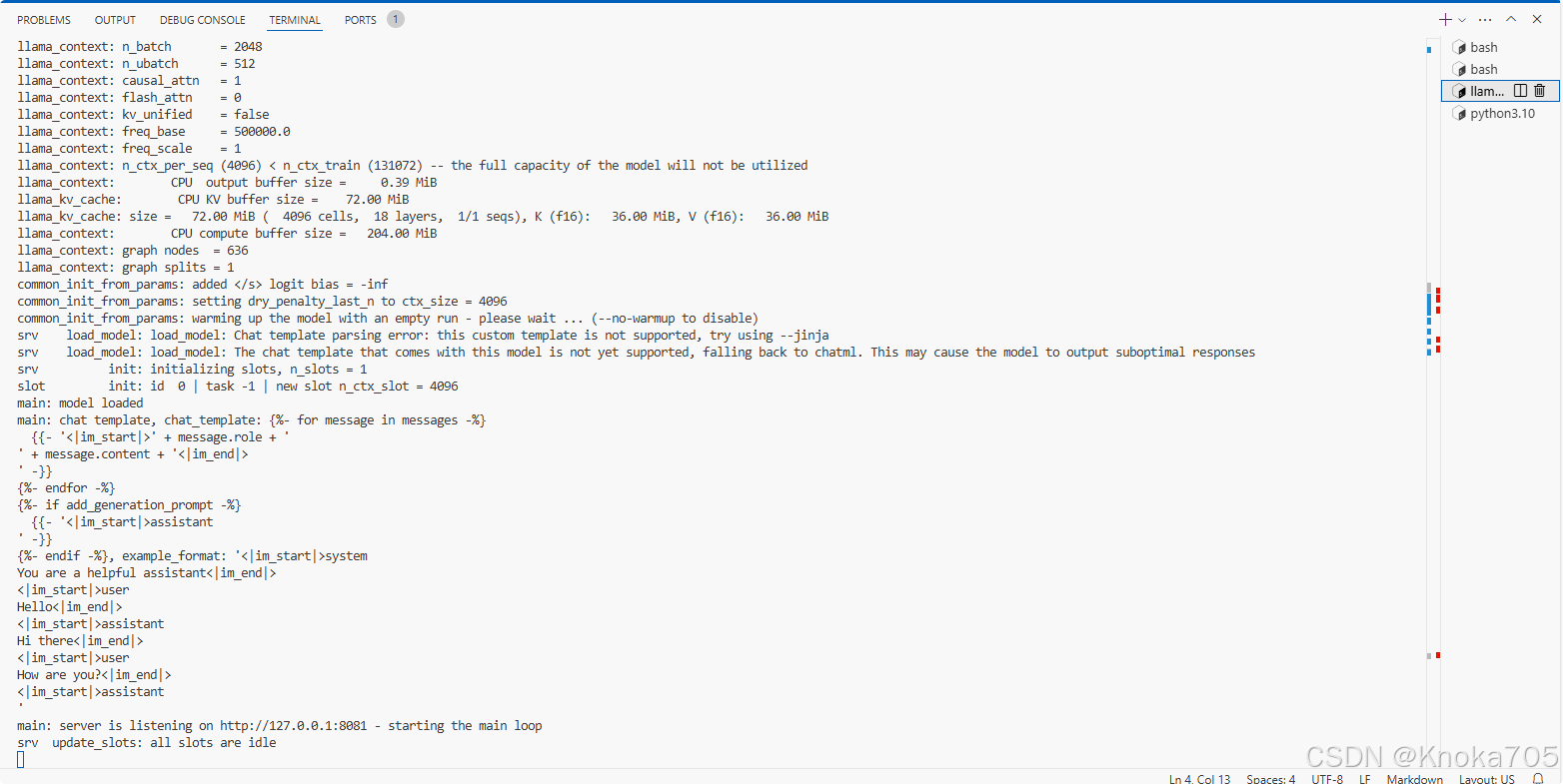
看 llama-server 启动时的输出日志(最直接)
system_info: n_threads = 8 # 使用 8 个 CPU 线程 llama.cpp: loading model from /path/to/your-model.gguf llama_model_loader: loaded meta data with 11 key-value pairs # 模型元数据 llama_model_loader: VBMI 160 gguf file detected llama_model_loader: loading model: q4_k - mmp 0.000000 # 量化类型 llama_model_loader: tensor 0: output [f32] 4096 32000 - CPU llama_model_loader: tensor 1: token_embd [f32] 32000 4096 - CPU llama_model_loader: tensor 2: output_norm [f32] 4096 - CPU llama_model_loader: tensor 3: blk.0.attn_q [f16] 4096 4096 - GPU llama_model_loader: tensor 4: blk.0.attn_k [f16] 4096 4096 - GPU llama_model_loader: tensor 5: blk.0.attn_v [f16] 4096 4096 - GPU ... llama_init_backend: using CUDA backend
要判断你当前运行的 llama.cpp 模型是运行在 CPU 还是 GPU(如 CUDA、Vulkan、Metal 等) 上,主要看llama_init_backend: using CUDA backend这行
| 输出内容 | 含义 |
|---|---|
using CUDA backend | 正在使用 NVIDIA GPU(CUDA) |
using Metal backend | macOS 上使用 Apple GPU(M1/M2) |
using Vulkan backend | 使用 Vulkan GPU(Linux/Windows) |
using CPU backend 或没显示 backend | 仅使用 CPU |
tensor ... - GPU | 某些层已卸载到 GPU |
tensor ... - CPU | 该层在 CPU 上运行 |
✅ 如果你看到 部分 tensor 在 GPU 上,说明是 混合模式(CPU + GPU)推理,这是
llama.cpp的典型做法。
检查是否启用 GPU 支持
检查是否启用了 CUDA(NVIDIA),如果编译时没有开启这些选项,即使有 GPU 也无法使用。
cmake -B build -DGGML_CUDA=ON
👉 查看你的构建目录是否启用了 GPU:
grep -i cuda build/CMakeCache.txt grep -i metal build/CMakeCache.txt grep -i vulkan build/CMakeCache.txt
如果有输出类似如下,说明支持 CUDA,如果为OFF则说明不支持
GGML_CUDA:BOOL=ON
启用GPU版本
注意这里创建配置时候需要根据卡型指定其CUDA 计算能力,否则后面可能报错,这里我用的是RTX8000,其计算能力为sm_75。
各系列 NVIDIA GPU 对应的 CMAKE_CUDA_ARCHITECTURES 值如下
这是在使用 CMake 编译 llama.cpp 并启用 CUDA 时,必须设置的关键参数,它告诉编译器为目标 GPU 架构生成优化的代码。
| GPU 系列 (代号) | 常见型号举例 | 计算能力 (Compute Capability) | CMAKE_CUDA_ARCHITECTURES 值 |
|---|---|---|---|
| Pascal | GTX 1080, GTX 1070, Titan Xp | 6.1 | 61 |
| Volta | Tesla V100 | 7.0 | 70 |
| Turing | RTX 2080 Ti, RTX 2070, Quadro RTX 8000 | 7.5 | 75 |
| Ampere | RTX 3090, RTX 3080, A100 | 8.0 / 8.6 | 80 或 86 |
| Ada Lovelace | RTX 4090, RTX 4080 | 8.9 | 89 |
| Hopper | H100 | 9.0 | 90 |
# 进入 llama.cpp 目录 cd /data/coding/llama.cpp # 清理旧构建(可选) rm -rf build # 创建构建目录并配置(启用 CUDA) cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=75 # 编译(在 build 目录下运行 make) make -C build -j$(nproc) # 或者用 cmake 命令编译 cmake --build build --config Release --target all -j$(nproc)
再启动模型,就会发现是在GPU版本部署的了