第7章 区分鸟和飞机:从图像学习
主要内容:
构建前馈神经网络。
使用
Dataset和DataLoader加载数据。了解分类损失。
在本章中,将继续构建神经网络。这一次,将把注意力转向图像。
7.1 微小图像数据集
CIFAR-10由60000张微小的(32像素×32像素)RGB图像组成,用一个整数对应10个级别中的1个:飞机(0)、汽车(1)、鸟(2)、猫(3)、鹿(4)、狗(5)、青蛙(6)、马(7)、船(8)和卡车(9)。

7.1.1 下载 CIFAR-10
# In:
from torchvision import datasetsdata_path = '../data-unversioned/p1ch7/'
cifar10 = datasets.CIFAR10(data_path, train=True, download=True) ⇽--- 实例化一个数据集用于训练数据,如果数据集不存在,则TorchVision将下载该数据集
cifar10_val = datasets.CIFAR10(data_path, train=False, download=True) ⇽--- 使用train=False,获取一个数据集用于验证数据,并在需要时再次下载该数据集就像CIFAR-10一样,数据集子模块为我们提供了对最流行的计算机视觉数据集的预存储访问,如MNIST、Fashion-MNIST、CIFAR-100、SVHN、COCO和Omniglot等。在每种情况下,数据集都作为torch.utils.data.Dataset的子类返回。
# In[4]:
type(cifar10).__mro__# Out[4]:
(torchvision.datasets.cifar.CIFAR10,torchvision.datasets.vision.VisionDataset,torch.utils.data.dataset.Dataset,object)7.1.2 Dataset类
Dataset内容,它是一个需要实现2种函数的对象:__len__()和__getitem__(),前者返回数据中的项数,后者返回由样本和与之对应的标签(整数索引)组成的项。
# In[5]:
len(cifar10)# Out[5]:
50000# In[6]:
img, label = cifar10[99]
img, label, class_names[label]# Out[6]:
(<PIL.Image.Image image mode=RGB size=32x32 at 0x7FB383657390>,1,'automobile')# In[7]:
plt.imshow(img)
plt.show()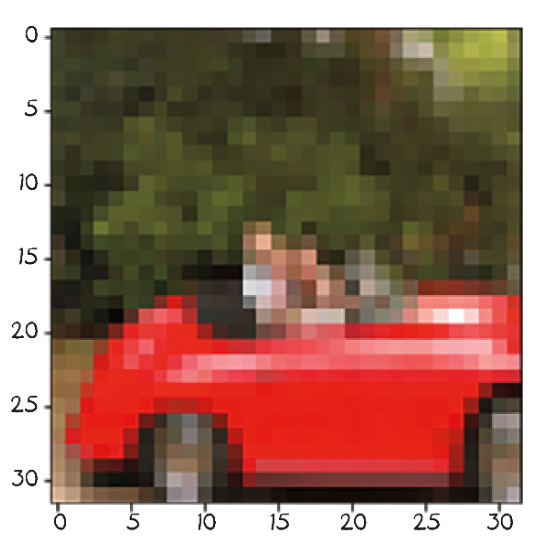
7.1.3 Dataset变换
我们需要一种方法来将PIL图像变换为PyTorch张量,然后才能使用它做别的事情,因此引入了torchvision.transforms模块。
# In[8]:
from torchvision import transforms
dir(transforms)# Out[8]:
['CenterCrop','ColorJitter',
...'Normalize','Pad','RandomAffine',
...'RandomResizedCrop','RandomRotation','RandomSizedCrop',
...'TenCrop','ToPILImage','ToTensor',...
]在这些变换对象中,我们可以看到ToTensor对象,它将NumPy数组和PIL图像变换为张量。它还将输出张量的尺寸设置为C * H* W(通道、高度、宽度;正如我们在第4章中所描述的)。
# In[9]:
from torchvision import transformsto_tensor = transforms.ToTensor()
img_t = to_tensor(img)
img_t.shape# Out[9]:
torch.Size([3, 32, 32])可以将变换直接作为参数传递给dataset.CIFAR10:
# In[10]:
tensor_cifar10 = datasets.CIFAR10(data_path, train=True, download=False,transform=transforms.ToTensor())此时,访问数据集的元素将返回一个张量,而不是PIL图像:
# In[11]:
# 对于CIFAR-10数据集来说通常是 (image, label) 的形式),而你只关心第一个元素(图像数据),不关心第二个元素(标签)
# 第一个值(图像张量)被赋给 img_t,第二个值(标签)被赋给 _,表示你明确地忽略这个值
img_t, _ = tensor_cifar10[99]
type(img_t)# Out[11]:
torch.Tensor# In[12]:
img_t.shape, img_t.dtype# Out[12]:
(torch.Size([3, 32, 32]), torch.float32)原始PIL图像中的值为0~255(每个通道8位),而ToTensor变换将数据变换为每个通道的32位浮点数,将值缩小为0.0~1.0。让我们来验证一下:
# In[13]:
img_t.min(), img_t.max()# Out[13]:
(tensor(0.), tensor(1.))验证一下得到的图像是否相同:
# In[14]:
plt.imshow(img_t.permute(1, 2, 0)) ⇽--- 将轴的顺序由C×H×W改为H×W×C
plt.show()# Out[14]:
<Figure size 432x288 with 1 Axes>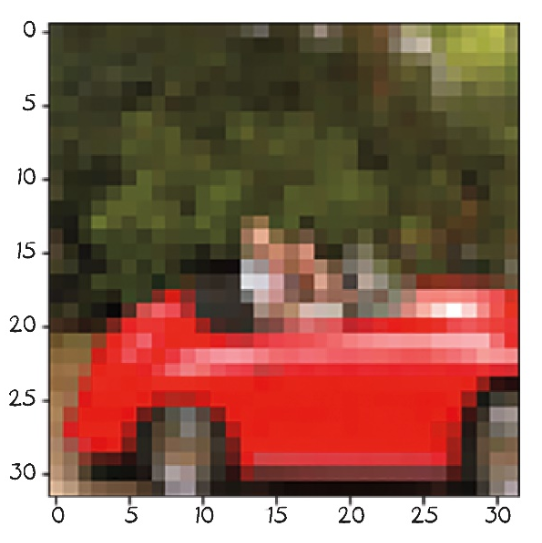
7.1.4 数据归一化
1. 数据堆叠与形状分析
由于CIFAR-10数据集很小,我们将完全能够在内存中操作它。让我们将数据集返回的所有张量沿着一个额外的维度进行堆叠:
# In[15]:
imgs = torch.stack([img_t for img_t, _ in tensor_cifar10], dim=3)
imgs.shape# Out[15]:
torch.Size([3, 32, 32, 50000])作用:将
CIFAR-10的所有图像(50,000 张)堆叠成一个 4D 张量,形状为[3, 32, 32, 50000],其中:3是 RGB 通道(CIFAR-10 是彩色图像)。
32, 32是图像的高和宽。
50000是样本数量(
dim=3表示在第 4 维度堆叠)。
问题:
dim=3的堆叠方式不太常见(通常dim=0更合理,得到 [50000, 3, 32, 32]),但这里是为了后续计算通道均值和标准差。
2.计算通道均值和标准差
imgs.view(3, -1).mean(dim=1) # tensor([0.4915, 0.4823, 0.4468])
imgs.view(3, -1).std(dim=1) # tensor([0.2470, 0.2435, 0.2616])imgs.view(3, -1):将
[3, 32, 32, 50000]重塑为[3, 5120000](3 通道 × 32×32×50000 像素)。这样每行代表一个通道(R、G、B)的所有像素值。
.mean(dim=1):计算每个通道的全局均值(R: 0.4915, G: 0.4823, B: 0.4468)。
.std(dim=1):计算每个通道的全局标准差(R: 0.2470, G: 0.2435, B: 0.2616)。
这些值将用于归一化,使数据分布接近标准正态分布(均值 0,标准差 1)。
图像堆叠举例
假设我们只有 2 张图像(而不是 50,000 张),每张图像是 2×2 像素(而不是 32×32),以简化说明:
原始数据(未堆叠)
图像 1(R、G、B 通道):
R = [[1, 2], [3, 4]]
G = [[5, 6], [7, 8]]
B = [[9, 10], [11, 12]]- 图像 2(R、G、B 通道):
R = [[13, 14], [15, 16]]
G = [[17, 18], [19, 20]]
B = [[21, 22], [23, 24]]堆叠后 [3, 2, 2, 2] 的结构
# dim=0: 通道 (R/G/B)
# dim=3: 图像索引 (0=图像1, 1=图像2)
tensor = [# Red 通道 (dim=0=0)[[[1, 2], [3, 4]], # 图像1的R通道 (dim=3=0)[[13, 14], [15, 16]] # 图像2的R通道 (dim=3=1)],# Green 通道 (dim=0=1)[[[5, 6], [7, 8]], # 图像1的G通道[[17, 18], [19, 20]] # 图像2的G通道],# Blue 通道 (dim=0=2)[[[9, 10], [11, 12]], # 图像1的B通道[[21, 22], [23, 24]] # 图像2的B通道]
]3.定义 Normalize 变换
transforms.Normalize((0.4915, 0.4823, 0.4468), (0.2470, 0.2435, 0.2616))作用:对每个通道执行归一化:
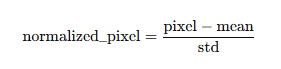
问题:归一化后的像素值可能超出 [0, 1] 范围,甚至为负值(例如,若原始像素是 0,归一化后是 (0 - 0.4915)/0.2470 ≈ -1.99)。
并将其连接到ToTensor变换:
# In[19]:
transformed_cifar10 = datasets.CIFAR10(data_path, train=True, download=False,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4915, 0.4823, 0.4468),(0.2470, 0.2435, 0.2616))
]))注意,此时,从数据集绘制的图像不能为我们提供实际图像的真实表示:
# In[21]:
img_t, _ = transformed_cifar10[99]plt.imshow(img_t.permute(1, 2, 0))
plt.show()这是因为归一化对RGB超出0.0~1.0的数据进行了转化,并且调整了通道的总体大小,所有的数据仍然存在,只是Matplotlib将其渲染为黑色。
7.2 区分鸟和飞机
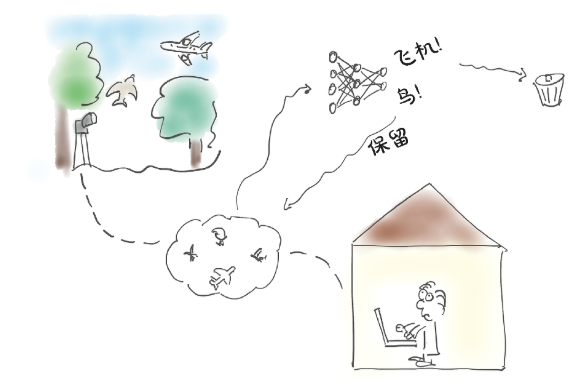
我们在观鸟俱乐部的朋友Jane,在机场南面的树林里布置了一组相机。当有东西进入镜头画面时,这些相机会拍摄并保存照片,将其上传到俱乐部的实时观鸟博客上。问题是很多飞机进出机场都会触发摄像头拍照,所以Jane花了很多时间从博客上删除飞机照片。她需要的是一个图7.6所示的自动化系统。她需要的不是人工删除,而是一个神经网络,依靠人工智能实现立刻自动剔除飞机的照片。
我们将从CIFAR-10数据集中选出所有的鸟和飞机,并建立一个神经网络来区分鸟和飞机。
1. 数据集构建
从CIFAR-10中筛选出标签为0(飞机)和2(鸟)的样本,并重新映射标签:
label_map = {0: 0, 2: 1} # 飞机→0,鸟→1
class_names = ['airplane', 'bird']# 训练集和验证集
cifar2 = [(img, label_map[label]) for img, label in cifar10 if label in [0, 2]]
cifar2_val = [(img, label_map[label]) for img, label in cifar10_val if label in [0, 2]]2. 全连接模型设计
图像只是一组在空间结构中排列的数字。我们现在还不知道如何处理空间结构部分,但理论上如果我们把图像像素拉成一个长的一维向量,就可以把这些数字当作输入特征。
把图像当作一个长的一维向量,在它上面训练一个完全连通的分类器:
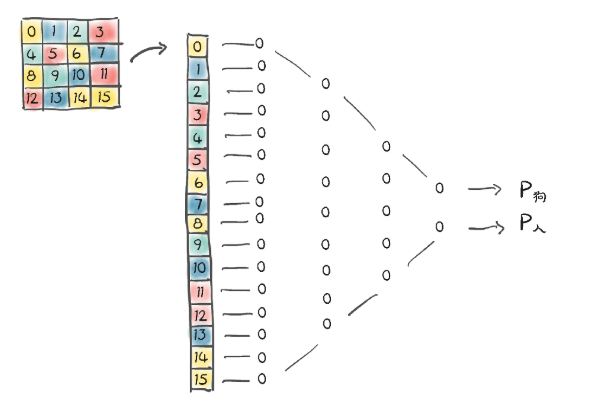
构建一个多层感知机(MLP),将展平的图像作为输入:
# In[6]:
import torch.nn as nnmodel = nn.Sequential(nn.Linear(3072, 512), # 输入层→隐藏层nn.Tanh(), # 激活函数nn.Linear(512, 2), # 隐藏层→输出层(2类)nn.LogSoftmax(dim=1) # 输出对数概率
)任意选择512个隐藏特征。为了能够学习任意函数,一个神经网络至少需要一个隐藏层(激活层,也就是两个模块),否则它将只是一个线性模型。
关键点:
使用
Tanh激活函数引入非线性。LogSoftmax确保输出为对数概率,便于后续计算负对数似然损失(NLL)。
3. 损失函数选择
目标:最大化正确类别的概率。
负对数似然损失(NLL):
loss = nn.NLLLoss()输入需为对数概率(因此使用
LogSoftmax)。公式:
NLL = -sum(log(out[class_index]))。
4. 训练流程
(1) 单样本训练(初始版本)
for epoch in range(n_epochs):for img, label in cifar2:out = model(img.view(-1).unsqueeze(0)) # 展平并添加batch维度loss = loss_fn(out, torch.tensor([label]))optimizer.zero_grad()loss.backward()optimizer.step()问题:单样本梯度估计不稳定,收敛慢。
(2) 小批量训练(改进版)
使用DataLoader组织批量数据:
train_loader = DataLoader(cifar2, batch_size=64, shuffle=True)for epoch in range(n_epochs):for imgs, labels in train_loader:batch_size = imgs.shape[0]outputs = model(imgs.view(batch_size, -1)) # 批量展平loss = loss_fn(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()优势:
批量梯度更稳定。
shuffle=True打乱数据,避免顺序偏差。
5. 模型评估
在验证集上计算准确率:
val_loader = DataLoader(cifar2_val, batch_size=64, shuffle=False)
correct, total = 0, 0with torch.no_grad():for imgs, labels in val_loader:outputs = model(imgs.view(imgs.shape[0], -1))_, predicted = torch.max(outputs, 1) # 取概率最大的类别total += labels.size(0)correct += (predicted == labels).sum().item()print(f"Accuracy: {correct / total:.4f}")结果:初始模型准确率约`79.4%`。
6. 模型优化
(1) 增加深度
添加更多隐藏层提升容量:
model = nn.Sequential(nn.Linear(3072, 1024), nn.Tanh(),nn.Linear(1024, 512), nn.Tanh(),nn.Linear(512, 128), nn.Tanh(),nn.Linear(128, 2),nn.LogSoftmax(dim=1)
)问题:参数量激增(如3,737,474个参数),可能过拟合。
(2) 改用交叉熵损失
直接使用CrossEntropyLoss(内部包含LogSoftmax):
model = nn.Sequential(nn.Linear(3072, 1024), nn.ReLU(),nn.Linear(1024, 512), nn.ReLU(),nn.Linear(512, 2)
)
loss_fn = nn.CrossEntropyLoss() # 无需手动LogSoftmax优势:数值更稳定,代码更简洁。
7. 关键问题与改进
(1) 全连接模型的局限性
参数量爆炸:高分辨率图像(如
1024×1024×3)会导致30亿参数,无法训练。解决方案:使用卷积神经网络(CNN),通过局部连接和权重共享减少参数。
(2) 激活函数选择
Tanh可能导致梯度消失,现代网络常用ReLU及其变体(如LeakyReLU)。
8. 总结
数据准备:从CIFAR-10筛选两类并展平图像。
模型设计:全连接层+
Tanh+LogSoftmax。损失函数:
NLLLoss或CrossEntropyLoss。训练优化:小批量梯度下降+数据打乱。
评估:验证集准确率约80%,可通过CNN进一步改进。
下一步建议
改用CNN:处理图像的空间结构,显著减少参数量。
数据增强:旋转/翻转图像提升泛化能力。
正则化:添加Dropout或权重衰减防止过拟合。