LMAD:用于可解释自动驾驶的集成端到端视觉-语言模型
25年8月来自复旦大学、悉尼大学和伦敦帝国理工学院 ICL 的论文“LMAD: Integrated End-to-End Vision-Language Model for Explainable Autonomous Driving”。
大型视觉-语言模型 (VLM) 在场景理解方面表现出色,可增强驾驶行为的可解释性和与用户的交互性。现有方法主要根据车载多视图图像和场景推理文本对 VLM 进行微调,但这种方法往往缺乏自动驾驶所需的整体细致的场景识别和强大的空间感知,尤其是在复杂情况下。为了弥补这一差距,提出一种专为自动驾驶量身定制的新型视觉-语言框架 LMAD。该框架通过将全面的场景理解和针对 VLM 的任务专门结构结合起来,模拟了现代端到端驾驶范式。具体而言,在相同的驾驶任务结构中引入初步的场景交互和专门的专家适配器,这使 VLM 更好地与自动驾驶场景相结合。此外,该方法旨在与现有的 VLM 完全兼容,同时与面向规划的驾驶系统无缝集成。在 DriveLM 和 nuScenes-QA 数据集上进行的大量实验表明,LMAD 显著提升现有 VLM 在驾驶推理任务上的性能,为可解释的自动驾驶树立了新的标准。
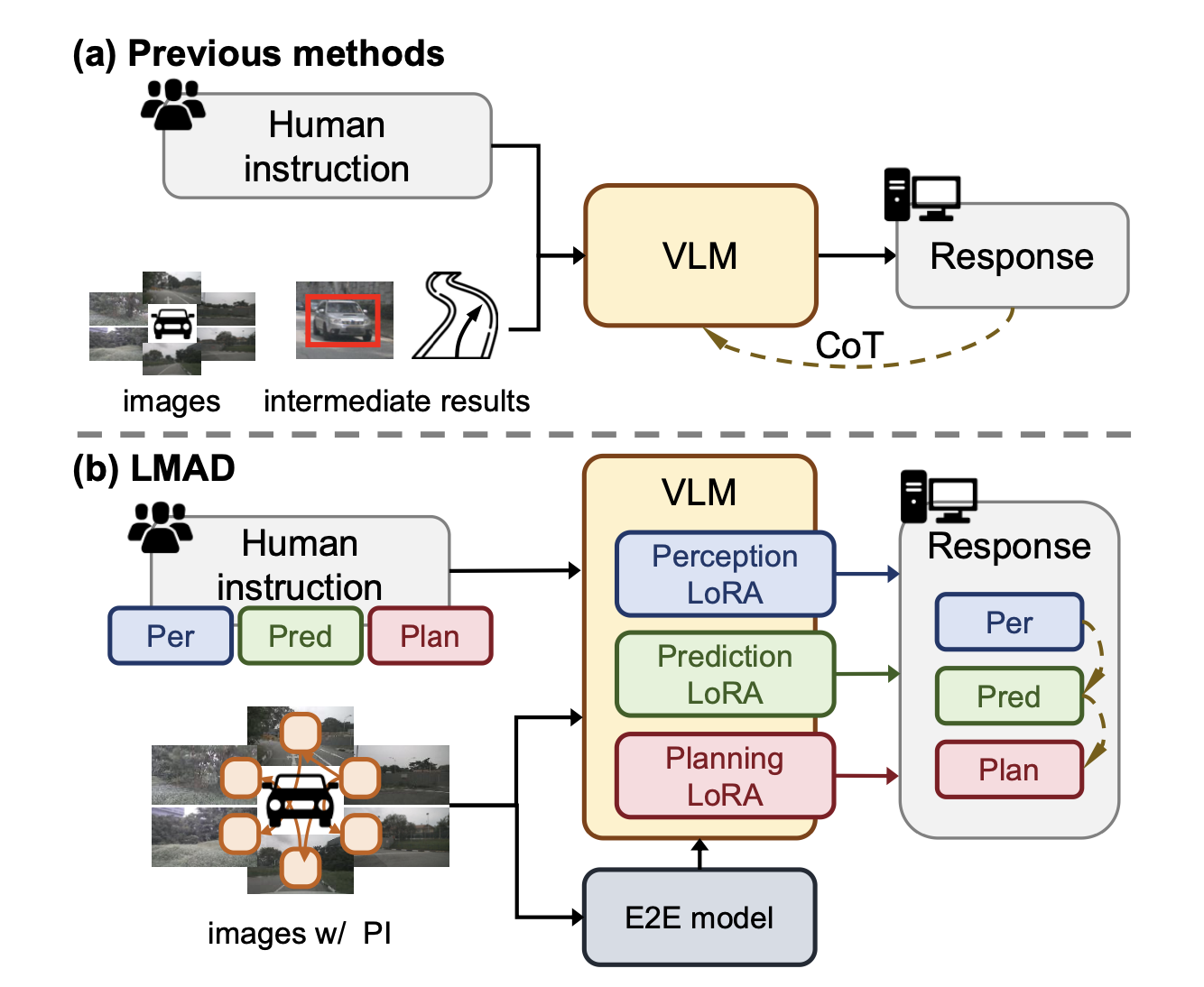
受自动驾驶框架的启发,近期方法使用简单的视觉表征和驾驶系统的中间结果来提供场景信息,并直接使用或微调带有可选的 Chain-of-Though (CoT) 的 VLM 进行推理 (Sima et al. 2024; Ma et al. 2023; Sha et al. 2023; Qian et al. 2025),如图 (a) 所示。然而,直接使用这些信息使得模型难以捕捉交通要素之间的关系,从而阻碍了对驾驶场景的整体理解。此外,VLM 在定位和运动估计方面仍然存在困难,而这两项技术对于自动驾驶行为分析至关重要。在渐进推理过程中,这可能会导致严重的累积误差,从而导致现有方法在驾驶任务中的表现不佳。
针对这些局限性,本文提出一个针对自动驾驶场景的新型框架 LMAD(图(b)所示),该框架利用了现代端到端驾驶范式的整体场景理解和优化的任务专用结构。其引入一种用于先前场景关系建模的初步交互(PI)机制,并将 VLM 与一组专门的专家适配器(例如,LoRA(Hu,2022a))集成在相同的驾驶任务结构中,该结构依次包含感知、预测和规划。PI 机制可以提供交通参与者的粗略关系信息并减轻 VLM 的学习复杂性,而适配器则协同工作以解决不同复杂度的问题,这是通过它们有针对性地从驾驶场景中获取特定于任务的驾驶知识来实现的。此外,LMAD 还促进了端到端驱动系统的先验知识的无缝整合,进一步补充了 VLM 并增强了后续推理。
如图 LMAD 的示意图,它将端到端驾驶流程与视觉语言模型集成在一起。文本和图像标记由token化器提取,然后通过 PI 编码器进行交互。端到端 token 源自中间特征和相应的提示,随后由相应的适配器进行处理并聚合。语言模型使用并行 LoRA 对所有这些 tokens 进行微调,使其与端到端自动驾驶更加契合。
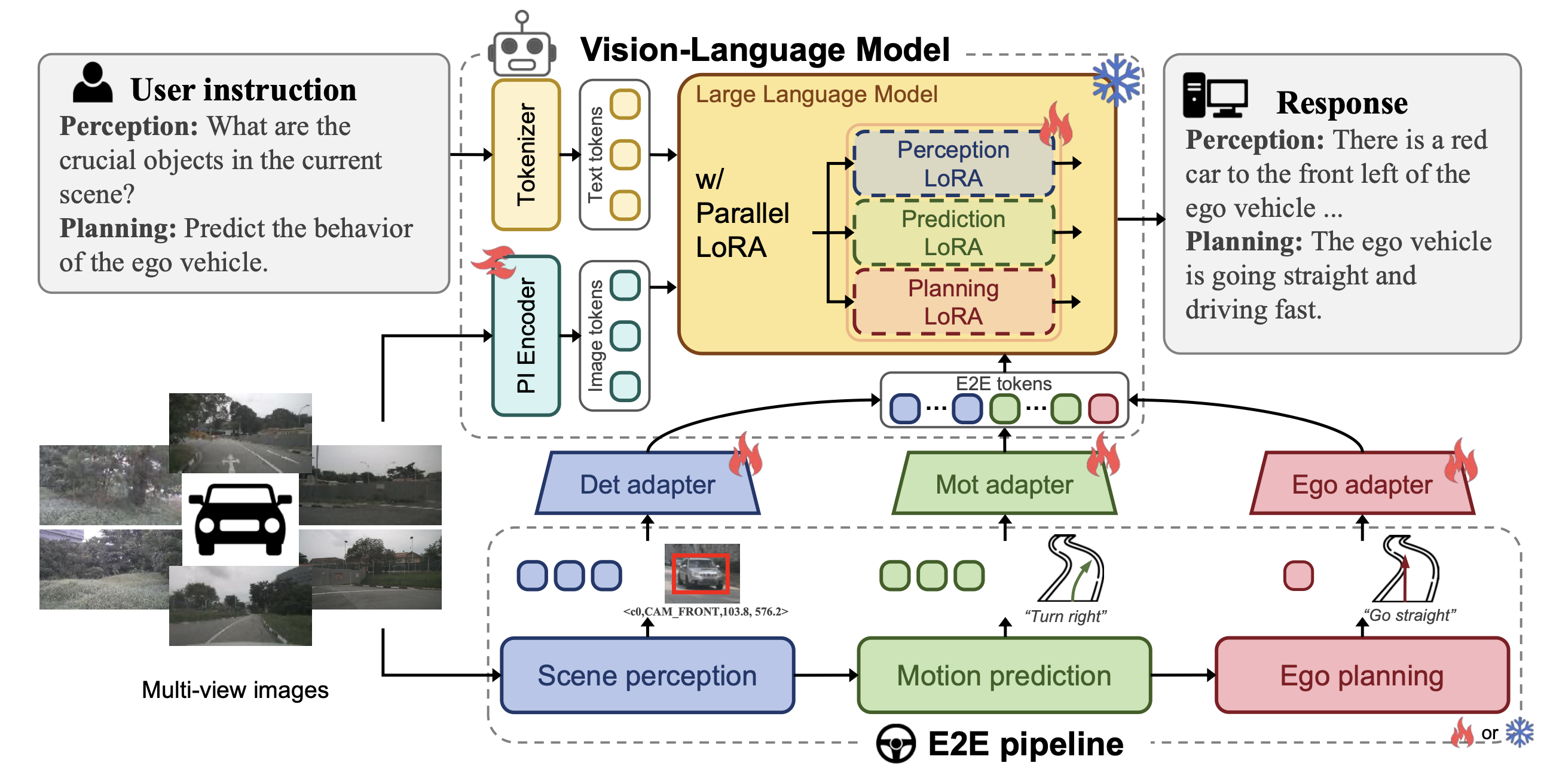
端到端视觉-语言模型
采用通用的视觉-语言模型 (VLM) 框架作为基础模型,该框架包含一个用于提取视觉tokens的视觉编码器、一个用于编码文本token的 token 化器以及一个基于这些视觉和文本输入生成响应的语言解码器。为了有效应对广泛且渐进式的端到端问答任务 (Sima et al. 2024; Nie et al. 2024),进一步调整 VLM,使其适用于端到端自动驾驶模型。该模型以多视角周围图像作为输入,并处理各种驾驶任务。为此,本文提出场景的初步交互 (PI) 编码器和并行 LoRA 模块,分别用于高效聚合交通要素的场景关系和集成特定任务的驾驶知识。
初步交互编码器。在自动驾驶场景中,多视角图像经常用于促进对整个场景的全面关注。然而,像 VLM 中常见的那样独立处理每幅图像,会生成大量相关性较低的跨视角图像token,从而由于复杂的空间关系而增加了学习负担。为了缓解这个问题,最近以驾驶为中心的 VLM (Qian et al. 2024; Shao et al. 2024) 采用 BEV 特征图作为整体表示。虽然有效,但它严重依赖于专门的预训练 BEV 编码器,并且经常忽略详细的交通信息(例如交通标志),最终限制了场景理解任务的性能。因此,本文保留多视图输入并提出 PI 编码器来建模初步场景关系,这引入了解耦查询和交替注意机制,如图 (a) 所示。具体而言,用解耦查询来收集场景信息,包括 Nq 个通用视觉查询 Q 和 Nc 个摄像头查询 Qc。视觉查询 Q 用于捕捉图像上下文,而相机查询 Qc 则作为不同相机视角的标识符,有助于解决特定于视角的问题并构建空间关系。随后,视觉查询和相机查询通过广播加法集成在一起,形成总体 Nq × Nc 个查询,然后传播到交替的注意块,以促进视图级和场景级的信息交互。在奇数块中,将所有查询划分为每个相机的 Nc 个特定组,并且只允许在每个组内以及与其对应的图像特征进行交互,从而完全保留每个图像的独特信息。在偶数块中,所有查询组合在一起,彼此之间进行场景级自注意,并与所有多视角图像对基于 Qformer 的模型(Gao,2023)和直接输入模型(Bai,2023;Chen,2024b)应用了略有不同的策略。对于前者,引入额外的可学习相机查询并修改交互关系,以确保与强大的预训练权重兼容。相比之下,对于原本缺乏额外视觉压缩编码器的直接输入方法,用多视角图像token替换相机查询 Q,并使用轻量级交替自注意模块来实现交互。
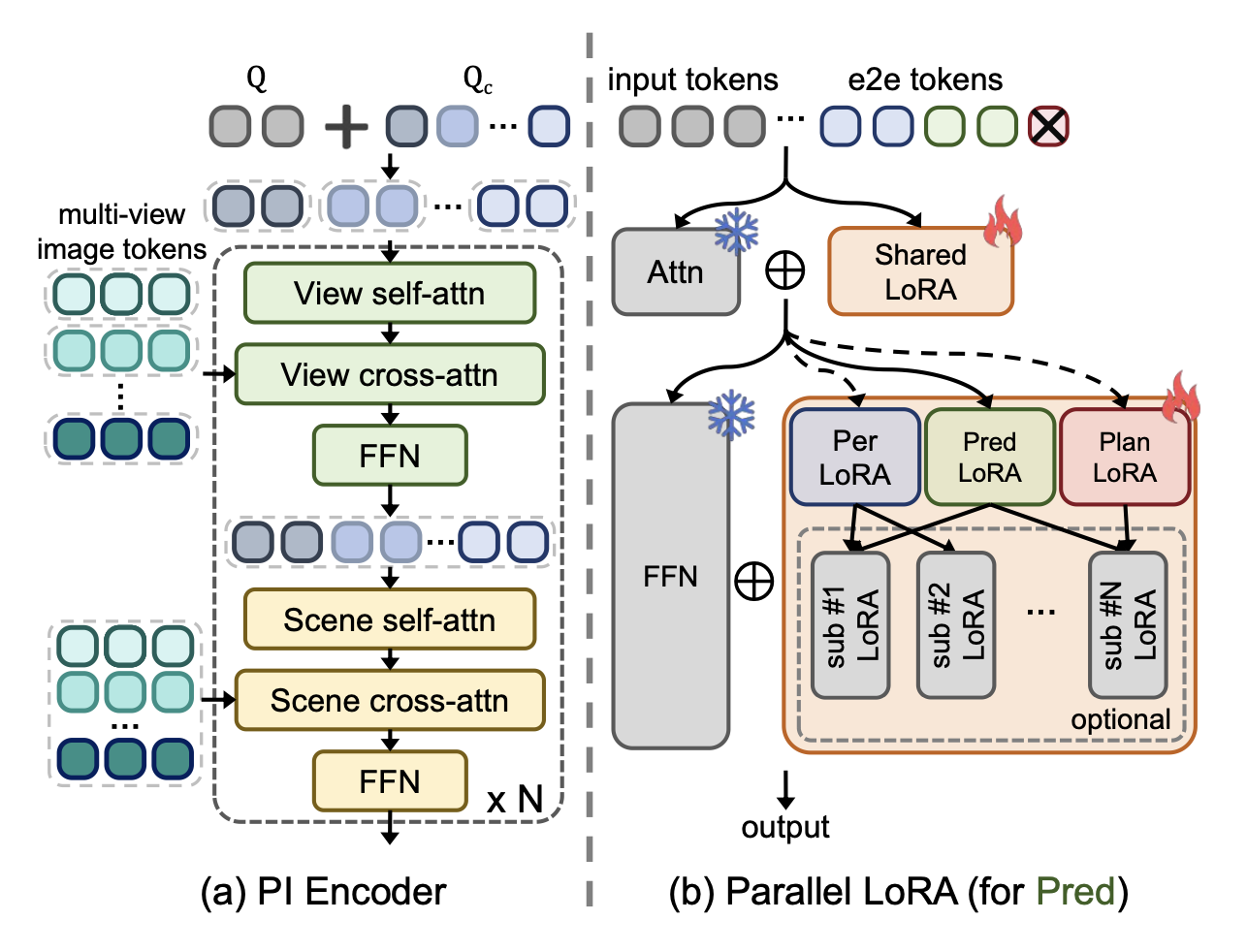
使用并行 LoRA 进行微调。为了赋予 VLM 自动驾驶领域的推理能力,还采用 LoRA(Hu,2022a)模块进行高效的微调,这可以保留预训练 VLM 的泛化能力和世界知识。在端到端设置中,模型必须处理各种与规划相关的驾驶任务,每个任务都侧重于驾驶过程的不同方面。因此,提出并行 LoRA(P-LoRA)模块来处理各种任务并提高任务熟练度,模仿现有的多任务驾驶范式。如上图 (b) 所示,P-LoRA 模块的实现方式是将 FFN 块中的原始 LoRA 模块替换为多个并行的 LoRA 分支,每个分支负责一项任务以收集特定于任务的知识。然而,对于配备在注意模块中的 LoRA,要求保持不变并共享,以保留一般的驾驶知识。在实现中,分别为感知、预测和规划设置单独的 LoRA 分支,并根据输入问题的任务类型激活相应的分支和端到端 tokens。例如,解码器只能访问检测和预测 token 来处理预测任务。这种设计允许将单个语言解码器转换为多个专门的任务头,同时添加最少的可训练参数。此外,还提供一种可选的分层格式,旨在适应各种类型的驾驶任务和问答任务,为涉及复杂指令的数据集提供专业化。在推理阶段,将 CoT 推理技术融入 P-LoRA 模块,遵循端到端方法逐步输出结果。
与端到端驾驶集成
端到端自动驾驶框架的特性可以为 VLM 提供丰富的物体位置和运动先验信息,从而增强其空间感知和推理能力。为此,本文将感知、预测和规划的输出特征分别收集为特征token F_det、F_mot 和 F_ego。具体而言,根据检测置信度选择排名前 N 的物体来生成 F_det 和 F_mot,而规划则采用唯一的 token F_mot。此外,还为每个 token 提供数字和文本提示,以方便模型理解。对于预测和规划的数字提示,采用多层感知器 (MLP) 将场景物体的预测轨迹 T_mot 和自我规划轨迹 T_ego 投影到高维特征 Fn_mot 和 Fn_ego。
此外,根据转向和速度的变化,导出相应的文本提示,形成诸如“直行,加速”,“右转,匀速”等文本。然后,将文本提示输入到一个简单的多头注意模块中,并附加一个查询来生成文本提示特征。
对于检测提示,将检测的 3D 边框投影到 2D 图像上,得到归一化的 2D 边框和深度。数值提示特征 Fn_det 直接由 MLP 模块根据这些属性计算得出;同时,根据不同数据集的定义格式构建文本提示,并使用与上述相同的方法进行处理。获取所有提示特征后,通过加法运算将它们合并到相应的 token 中。随后,使用多个适配器 A 分别处理这三种 token 特征,并将它们与语言上下文对齐,最终将特征的连接输出为整体的端到端 token F_e2e。
然后,将端到端 token 附加在视觉 token 之后,并将它们传递到语言解码器。值得注意的是,针对此特征传输采用不同的实现方法,具体取决于具体的语言模型。具体而言,端到端 token 被视为适配器,类似于LLaMA-Adapter 模型中的视觉 token (Gao et al. 2023),而在其他主流模型(例如 LLaVA (Liu et al. 2024) 和 InternVL (Chen et al. 2024b))中则用作输入 token。
模型训练
在本框架中,针对端到端驾驶和语言分支采用两种训练策略。对于第一种策略,冻结整个端到端驾驶分支,同时对语言分支进行微调,期望通过此策略增强自动驾驶领域语言模型的推理和理解能力。在这种情况下,端到端 token 被分离,模型仅通过文本生成监督进行训练,其中使用自回归交叉熵损失 L_txt。
此外,旨在探索语言模型是否有助于提升端到端规划的性能。然而,VLM 通常在问答任务中生成高级文本命令,很难为端到端框架提供精确的轨迹信息。为了解决这个问题,激活从语言分支到端到端分支的梯度流,并训练端到端任务的解码器头。这鼓励端到端框架学习更多地关注影响自我规划的关键元素。
另外一个损失项 L_e2e 由检测损失、运动预测损失和规划损失与端到端模型训练设置中的默认权重聚合而成。
实验设置
数据集和评估指标。用 DriveLM (Sima et al. 2024) 和 nuScenes-QA (Qian et al. 2024) 数据集评估该方法的语言推理性能,这两个数据集都是基于 nuScenes (Caesar et al. 2020) 自动驾驶数据集的 VQA 基准测试。DriveLM 数据集包含从整个数据集中选取的一些关键场景的 377,956 个 QA 对。对于每个场景,都包含从感知、预测到规划和行为的渐进式 QA 对,从而提供对端到端驾驶行为的全面解释。nuScenes-QA 数据集包含约 46 万个 QA 对,主要侧重于感知任务。除了 QA 对之外,与 nuScenes 一样,数据集也采用了六个视角的周围图像。
实施细节。对于基线,将 LMAD 与三种类型的 VLM 集成,包括 LLaMA-Adapter-V2(Gao,2023)、LLaVA-v1.5(Liu,2024)和 InternVL2(Chen,2024b),以确保多功能性。对于端到端规划分支,采用 VAD-base(Jiang,2023)框架,该框架既可靠又相对轻量级。此外,对于 nuScenes-QA 数据集上的实验,采用 LLaMA-Adapter 作为基础,遵循竞争方法。对于模型训练,利用 AdamW(Loshchilov & Hutter,2018)优化器,权重衰减为 0.01。用余弦学习率衰减调度程序,预热率为 0.03。在 8 块 A6000 GPU 上以 16 批次大小对模型进行 2 个 epoch 的微调。此外,两个损失之间的平衡因子 λ 设置为 1.0。在推理阶段,尝试采用 CoT 来充分利用模块设计的优势,并提高推理的一致性。