SpringCloud学习
文章目录
- 1,Spring Cloud 简介
- 1.1架构分类对比
- 1.2分布式架构具体实现与组件作用
- 1.3准备工作
- 2,Nacos
- 2.1Nacos 简介
- 2.2安装
- 2.3注册中心
- 服务注册
- 服务发现
- 远程调用
- 2.4配置中心
- 在nacos服务端进行配置
- 动态更新
- 配置优先级
- 数据隔离
- 3,OpenFeign
- 3.1简介
- 3.2远程调用
- 3.3相关配置
- (1)日志
- (2)超时配置
- (3)重试机制
- 3.4拦截器
- 3.5兜底返回
- 4,Sentinel
- 4.1简介
- 4.1.1介绍
- 4.2.2安装 & 连接
- 4.2异常处理
- 4.2.1资源 & 规则
- 4.2.2Web接口
- 4.2.3@SentinelResource 注解
- 4.2.4openFeign & SphU 硬编码
- 4.3流量控制
- 流控模式
- (1)直接模式(默认)
- (2)关联模式
- (3)链路模式
- 流控效果
- (1)快速失败(默认)
- (2)Warm Up
- (3)排队等待
- 4.4熔断降级
- (1)慢调用比例
- (2)异常比例 & 异常数
- 4.5热点参数
- 5,gateway
- 5.1介绍
- 5.1.2环境配置
- 5.2基础原理
- 5.3路由
- 5.4Predicate(断言)
- 5.4.1长短写法
- 5.4.2Query
- 5.4.3自定义predicates
- 5.5Filter(过滤器)
- 5.5.1基本使用
- 5.5.2默认Filter
- 5.5.3GlobalFilter
- 5.5.4自定义过滤器
- 5.5.6CORS 配置
- 6,Seata
- 6.1介绍
- 6.2环境搭建
- 基础服务&测试
- 整合Seata
- 6.3二阶提交协议
- 6.3.1阶段1
- 6.3.2阶段2
- 情况 1:全局事务提交
- 情况 2:全局事务回滚
- 6.3.3细节与保障
- 6.3.4代码辅佐
- 6.4四种事务模式
1,Spring Cloud 简介
Spring Cloud 是一套基于 Spring Boot 的分布式系统一站式解决方案,它整合了众多优秀的开源组件,为开发者提供了一系列用于构建分布式系统的工具和框架,涵盖了服务治理、配置管理、负载均衡、容错处理等多个方面,帮助开发者快速、高效地构建稳定可靠的分布式应用。
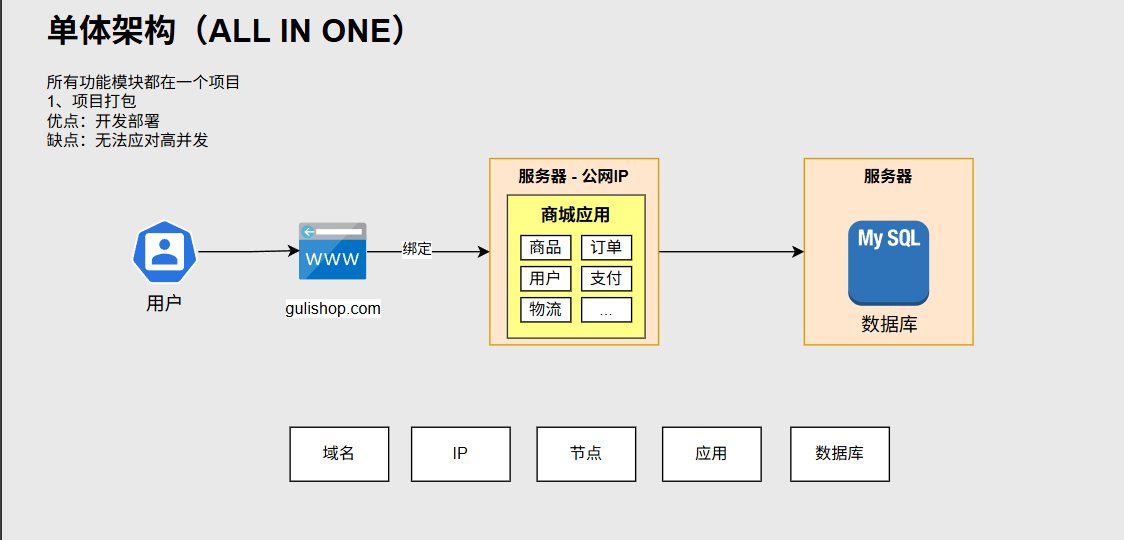
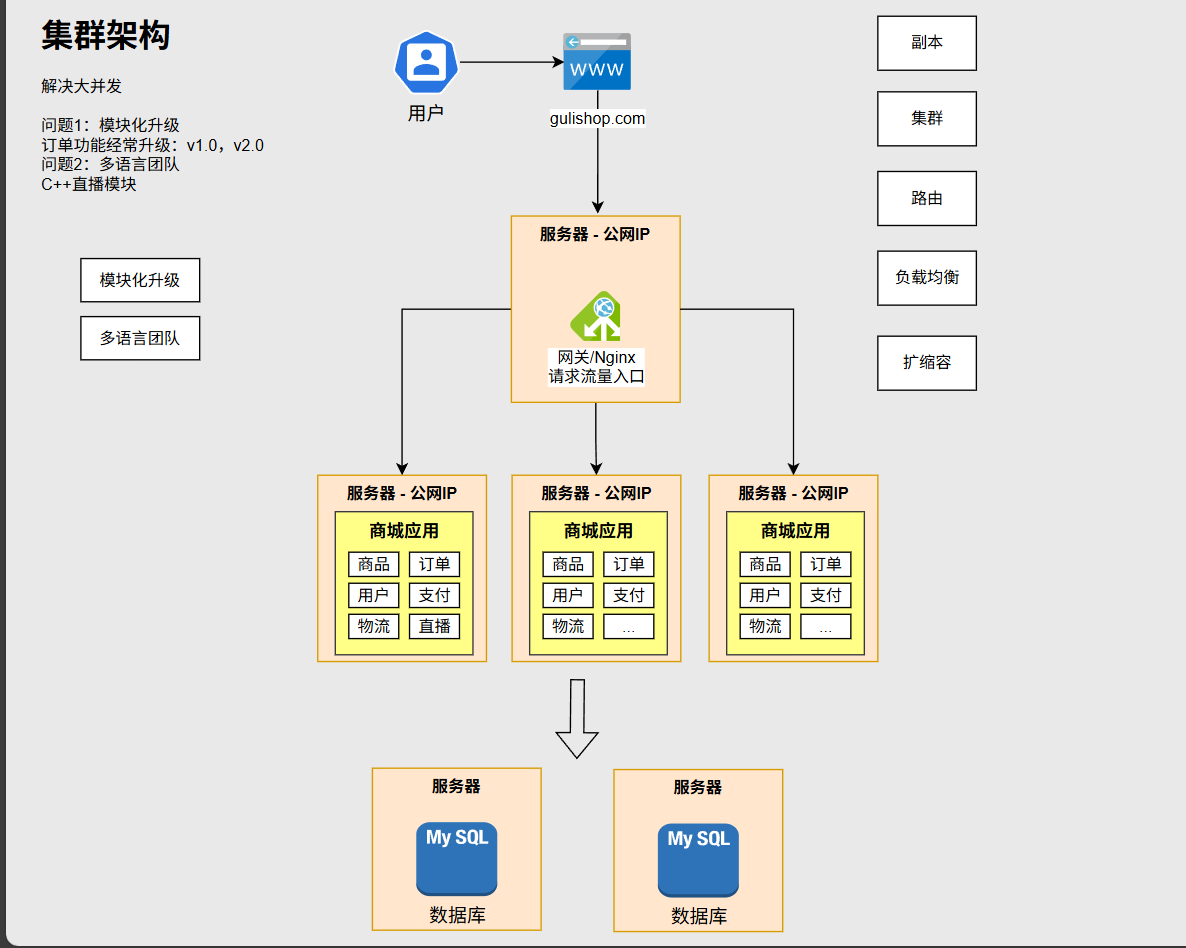
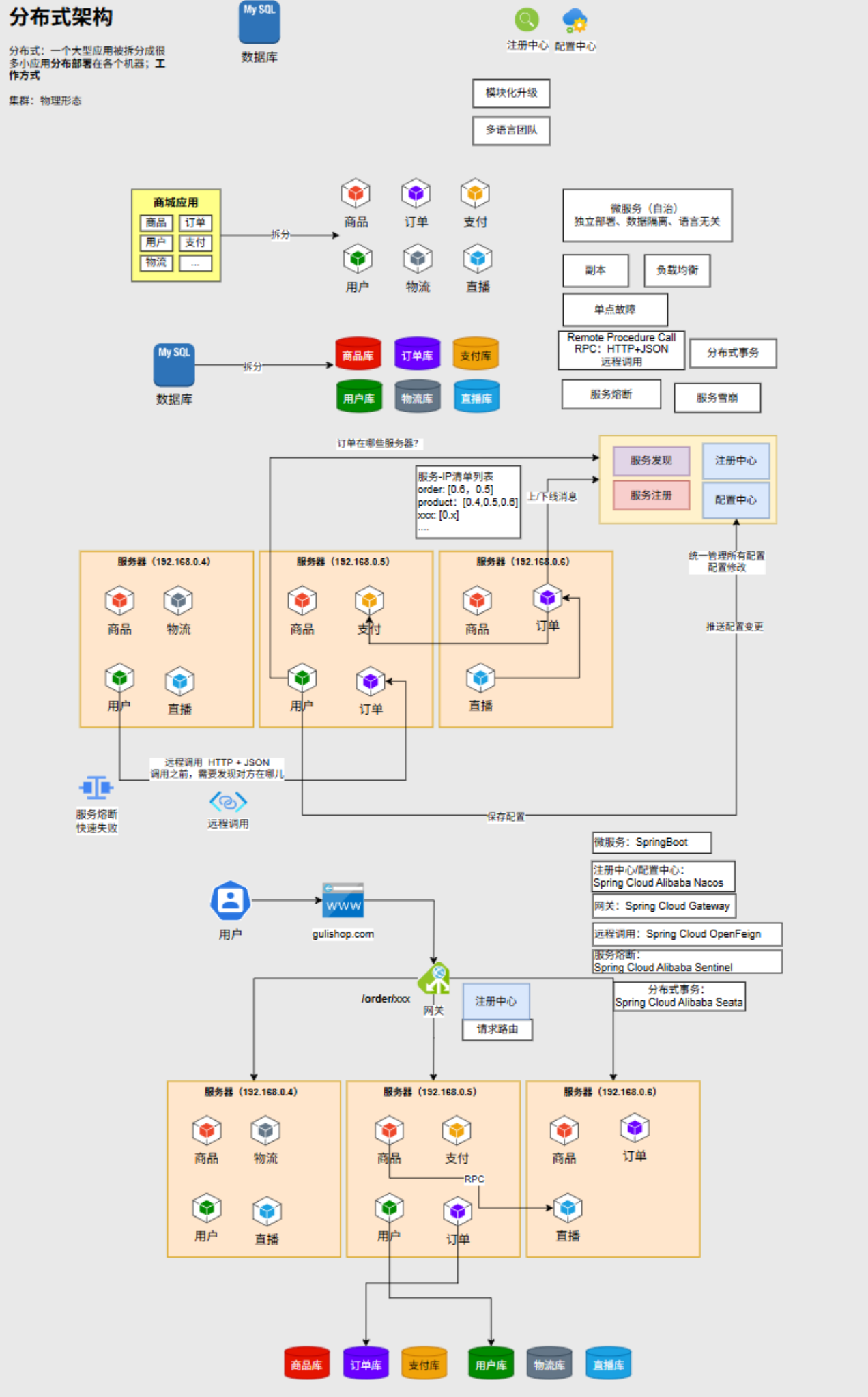
1.1架构分类对比
- 单体架构:所有功能模块都集中在一个项目里,打包成一个可执行程序运行。开发和部署相对简单,适合小型应用或项目初期快速迭代。但随着业务的增长,代码量会迅速膨胀,维护难度增大,且难以应对高并发场景,因为一个模块出现问题可能影响整个应用,而且对特定模块的升级、扩展都比较麻烦。
- 集群架构:本质上是单体应用的多服务器版本,通过将单体应用部署到多台服务器上,利用负载均衡器将请求分发到不同服务器,以解决大并发访问问题。然而,它并没有改变单体应用的本质,仍然存在代码耦合度高、扩展性差等问题,例如当需要对某个功能模块进行升级时,可能需要停掉整个集群。
- 分布式架构:将一个大型应用拆分成多个小应用(微服务),并分布部署在不同的机器上。每个微服务都可以独立开发、部署和扩展,具有自治性、数据隔离、语言无关等特点。这种架构能更好地应对高并发和复杂业务场景,解决了单体架构和集群架构存在的诸多问题,如模块升级困难、多语言团队协作不便等。
1.2分布式架构具体实现与组件作用
- 网关(Gateway):作为整个分布式系统的入口,负责接收所有外部请求,并根据请求的目标和路由规则,将请求分发到对应的微服务上。为了能准确地将请求路由到可用的微服务,网关需要注册到注册中心,实时获取微服务的地址和状态信息。
- 微服务:分布式系统的核心组成部分,每个微服务专注于实现特定的业务功能,可独立部署和运行。为避免单点故障,每个微服务通常会部署多个副本,分布在不同服务器上,确保即使部分服务器出现故障,系统仍能正常提供服务。
- 注册中心(如 Nacos):具备两大核心功能。一是服务注册,微服务启动时会将自己的信息(如服务地址、端口、服务名等)注册到注册中心,注册中心会实时监控这些服务的上下线状态;二是服务发现,当一个微服务需要调用其他微服务时,会先向注册中心查询目标微服务的地址信息,从而实现远程调用。
- 配置中心(如 Nacos 也可作为配置中心):用于统一管理分布式系统中各个微服务的配置文件,避免在每个微服务中单独维护配置。当配置发生变更时,配置中心可以将变更后的配置信息实时推送给相关微服务,确保所有微服务使用的是最新的配置。
- 远程调用(Nacos + OpenFeign):在分布式系统中,微服务之间需要相互通信和调用。OpenFeign 是 Spring Cloud 提供的一种声明式的 Web 服务客户端,通过简单的注解配置,就可以实现微服务之间的远程调用。在调用前,结合 Nacos 注册中心获取目标微服务的地址信息。
- 服务熔断(如 Sentinal):在微服务调用过程中,当某个微服务出现故障或响应超时,可能导致调用方一直等待,进而使整个服务调用链阻塞,甚至引发雪崩效应,即一个服务的故障扩散到整个系统。Sentinal 提供了服务熔断机制,当检测到服务调用失败率超过一定阈值时,会快速触发熔断,让调用方立即得到失败响应,释放资源,避免因等待故障服务而耗尽系统资源。
- 分布式事务(如 Seata):当一个业务操作涉及多个微服务,且每个微服务都操作不同的数据库时,传统的本地事务无法满足一致性要求。Seata 提供了分布式事务解决方案,通过二阶段提交协议等机制,协调各个微服务的事务,确保在分布式环境下数据的一致性和完整性。
1.3准备工作
项目架构,创建项目
spring-cloud-study/ # 项目根目录
├── model/ # 公共模型模块
│ └── pom.xml # 模块依赖配置
├── services/ # 服务模块父目录
│ ├── service-order/ # 订单服务
│ │ └── pom.xml # 订单服务依赖配置
│ ├── service-product/ # 商品服务
│ │ └── pom.xml # 商品服务依赖配置
│ └── pom.xml # 服务模块父依赖配置
├── pom.xml # 项目根依赖配置
引入依赖
------------ 项目根依赖配置---------<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.3.4</version></parent><dependencyManagement><dependencies><!-- 子模块需用的 Web 依赖,由子模块自行引入 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>3.3.4</version></dependency></dependencies></dependencyManagement><!-- 父工程不引入具体依赖,避免传递冲突 --><dependencies><!-- 若有公共依赖(如 lombok),可放这里,否则留空 --></dependencies>
------------------服务模块父依赖配置--------
<dependencies><!-- Web 开发依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--spring-boot-starter-test--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- 测试依赖(仅测试时需要) --><dependency><groupId>org.junit.platform</groupId><artifactId>junit-platform-launcher</artifactId><scope>test</scope></dependency><!--model--><dependency><groupId>com.luxiya</groupId><artifactId>model</artifactId><version>1.0-SNAPSHOT</version></dependency>
</dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-dependencies</artifactId><version>${spring-cloud.version}</version><type>pom</type><scope>import</scope></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><version>${spring-cloud-alibaba.version}</version><type>pom</type><scope>import</scope></dependency></dependencies>
</dependencyManagement>
---------------model模块-------------
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>
2,Nacos
2.1Nacos 简介
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service的首字母简称,Nacos 是阿里巴巴开源的一款动态服务发现、配置管理和服务管理平台,旨在帮助开发者更简单地构建云原生应用。它整合了注册中心和配置中心的功能,提供了简单易用的接口和丰富的特性,广泛应用于微服务架构中。
2.2安装
1,引入依赖(services模块)
<!--alibaba-nacos-discovery-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
2,下载nacos
发布历史 | Nacos 官网
下载相应版本,正常解压即可
3,启动
在bin目录下执行命令
#启动,-m standalone 是指定程序启动模式的参数“单机模式”
startup.cmd -m standalone#关闭
shutdown.cmd
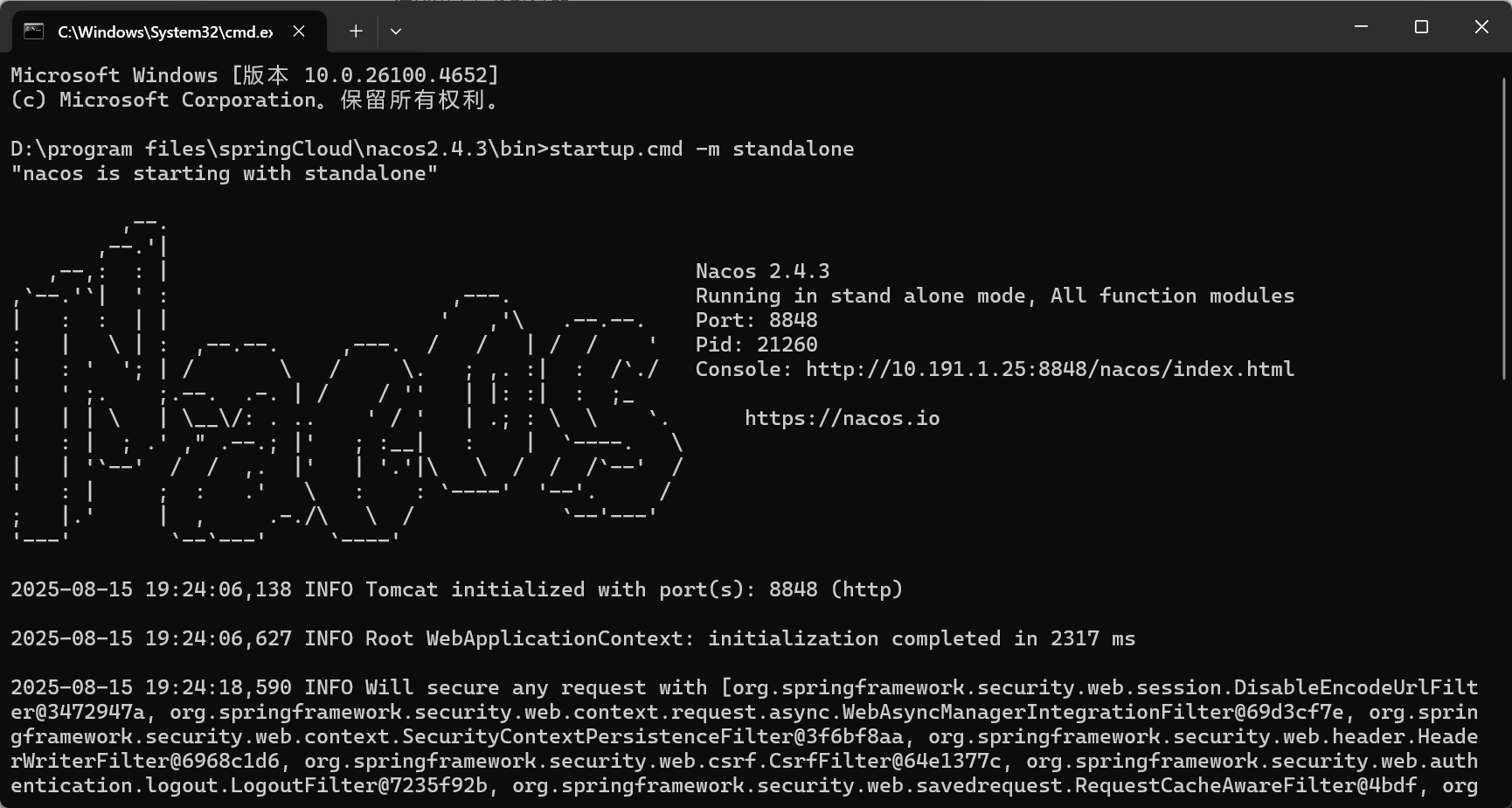
成功后可访问Nacos 客户端http://localhost:8848/nacos/
2.3注册中心
服务注册
举个例子,在service-product中配置yml
server:port: 8090
spring:application:name: service-productcloud:nacos:server-addr: 127.0.0.1:8848
配置了如上 Nacos 相关参数时,这既代表了 “连接 Nacos 服务器”,也会触发 “自动注册服务”。
当满足以下条件时,服务会自动注册到 Nacos:
- 正确配置了
server-addr且能连接到 Nacos 服务器。 - 配置了
spring.application.name(服务名,Nacos 以此标识服务)。 - 引入了 Nacos 服务发现依赖(如
spring-cloud-starter-alibaba-nacos-discovery)。
可手动关闭自动注册
spring:cloud:nacos:discovery:register-enabled: false # 关闭自动注册(仅连接,不注册)
启动多个服务实例,用不同端口,不再展示后面过程。这里启动了2个service-order和三个service-product。
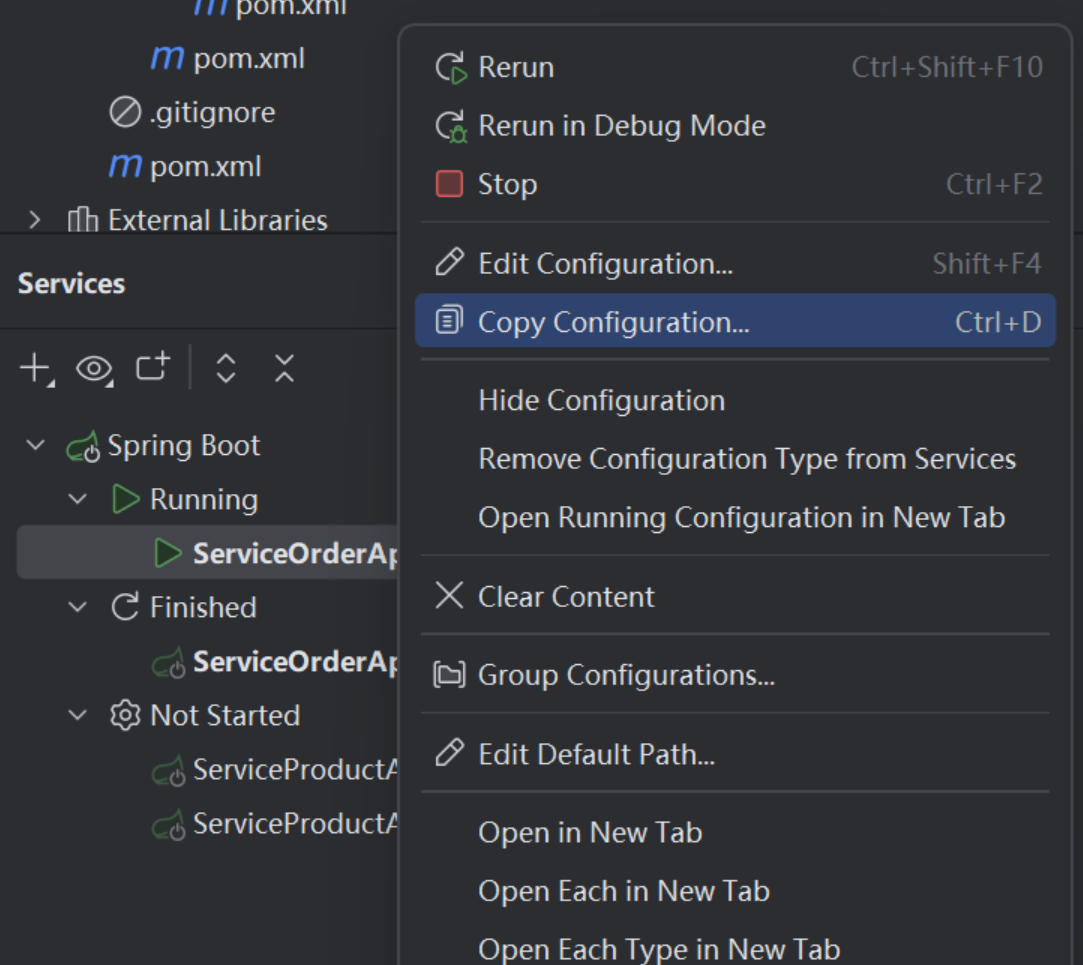
访问http://localhost:8848/nacos 可以看到服务已经注册上来(实例数已改变);
服务发现
- 开启发现功能
- 测试服务发现API
在启动类上加上@EnableDiscoveryClient注解,开启服务发现功能。
@Autowired
private DiscoveryClient discoveryClient;@Test
public void test() {List<ServiceInstance> instances = discoveryClient.getInstances("service-product");for (ServiceInstance instance : instances) {System.out.println(instance.getServiceId()+":"+instance.getHost()+":"+instance.getPort()+":"+instance.getUri()+":"+instance.getMetadata());}
}
@EnableDiscoveryClient 是 Spring Cloud 提供的一个注解,用于开启服务发现功能,使当前应用能够注册到服务注册中心(如 Nacos、Eureka、Consul 等),并能发现其他服务。该注解是 Spring Cloud 的 “抽象层” 注解,故当引入nacos依赖后,而这一致,自动注入的DiscoveryClient其实就是实现类NacosDiscoveryClient。
public interface DiscoveryClient.......public class NacosDiscoveryClient implements DiscoveryClient
远程调用
基于 RestTemplate 的远程调用
RestTemplate 是 Spring 提供的 HTTP 客户端工具,可直接发起 HTTP 请求调用远程服务,配合 Nacos 服务发现可实现动态地址调用。
且将 RestTemplate 配置为单例模式(全局唯一)是推荐的做法,因为它线程安全。
@Configuration
public class RestTemplateConfig {@Beanpublic RestTemplate restTemplate() {return new RestTemplate();}
}@Autowiredprivate DiscoveryClient discoveryClient;@Autowiredprivate RestTemplate restTemplate;@Testpublic void test() {List<ServiceInstance> instances = discoveryClient.getInstances("service-product");ServiceInstance instance = instances.get(0);Product forObject = restTemplate.getForObject(instance.getUri() + "/product/get/1", Product.class);System.out.println(forObject);}
而WebClient 是 Spring Framework 5 引入的非阻塞、响应式 HTTP 客户端,RestTemplate 是同步阻塞的HTTP客户端。WebClient 是 Spring 推荐的新一代 HTTP 客户端,尤其适合需要高性能和异步处理的场景。
使用远程调用的案例不再写了,在service-order写一个生成订单的接口,然后在该接口内远程调用service-product的查看商品信息的接口。
负载均衡(只能均衡到已注册Nacos服务)
第一种:使用 LoadBalancerClient
LoadBalancerClient 是 Spring Cloud 提供的一个核心接口,用于实现客户端负载均衡,帮助微服务从服务注册中心(如 Nacos、Eureka 等)获取服务实例,并根据负载均衡策略选择合适的实例进行调用。
LoadBalancerClient 的默认实现(RibbonLoadBalancerClient)依赖 Ribbon 框架,支持多种负载均衡策略,默认策略为轮询(RoundRobinRule),其他常用策略包括:
RandomRule:随机选择实例。WeightedResponseTimeRule:根据实例响应时间加权,响应越快权重越高,被选中概率越大。RetryRule:重试机制,选择实例失败后重试。
nacos-provider: # 服务名ribbon:NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 随机策略
@Autowiredprivate LoadBalancerClient loadBalancerClient;@Testpublic void test2() {ServiceInstance choose = loadBalancerClient.choose("service-product");System.out.println("choose.getHost()+choose.getPort() = " + choose.getHost() + ":" + choose.getPort());choose = loadBalancerClient.choose("service-product");System.out.println("choose.getHost()+choose.getPort() = " + choose.getHost() + ":" + choose.getPort());choose = loadBalancerClient.choose("service-product");System.out.println("choose.getHost()+choose.getPort() = " + choose.getHost() + ":" + choose.getPort());choose = loadBalancerClient.choose("service-product");System.out.println("choose.getHost()+choose.getPort() = " + choose.getHost() + ":" + choose.getPort());choose = loadBalancerClient.choose("service-product");System.out.println("choose.getHost()+choose.getPort() = " + choose.getHost() + ":" + choose.getPort());}
第二种:使用@LoadBalanced注解
@LoadBalanced 注解是 LoadBalancerClient 的简化使用方式,可直接修饰 RestTemplate,使其具备自动负载均衡能力(底层仍依赖 LoadBalancerClient)
@LoadBalanced 的实现依赖 LoadBalancerInterceptor 拦截器,工作流程如下:
- 当
RestTemplate发送请求时,拦截器会拦截 URL 中包含服务名的请求(如http://service-provider/hello)。 - 拦截器通过
LoadBalancerClient从服务注册中心查询service-provider的所有可用实例。 - 根据负载均衡策略(默认轮询)选择一个实例,将服务名替换为具体的 IP: 端口(如
http://192.168.0.1:8080/hello)。 - 继续执行请求,完成服务调用。
@Configuration
public class RestTemplateConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate() {return new RestTemplate();}
}
思考:注册中心宕机,远程调用还能成功吗?
对于Nacos,客户端默认会缓存服务实例信息,且支持本地配置兜底。若注册中心宕机,短期内可依赖缓存调用,但实例变更后无法调用。
2.4配置中心
导入依赖services
<!--配置中心-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
在nacos服务端进行配置
在客户端添加配置
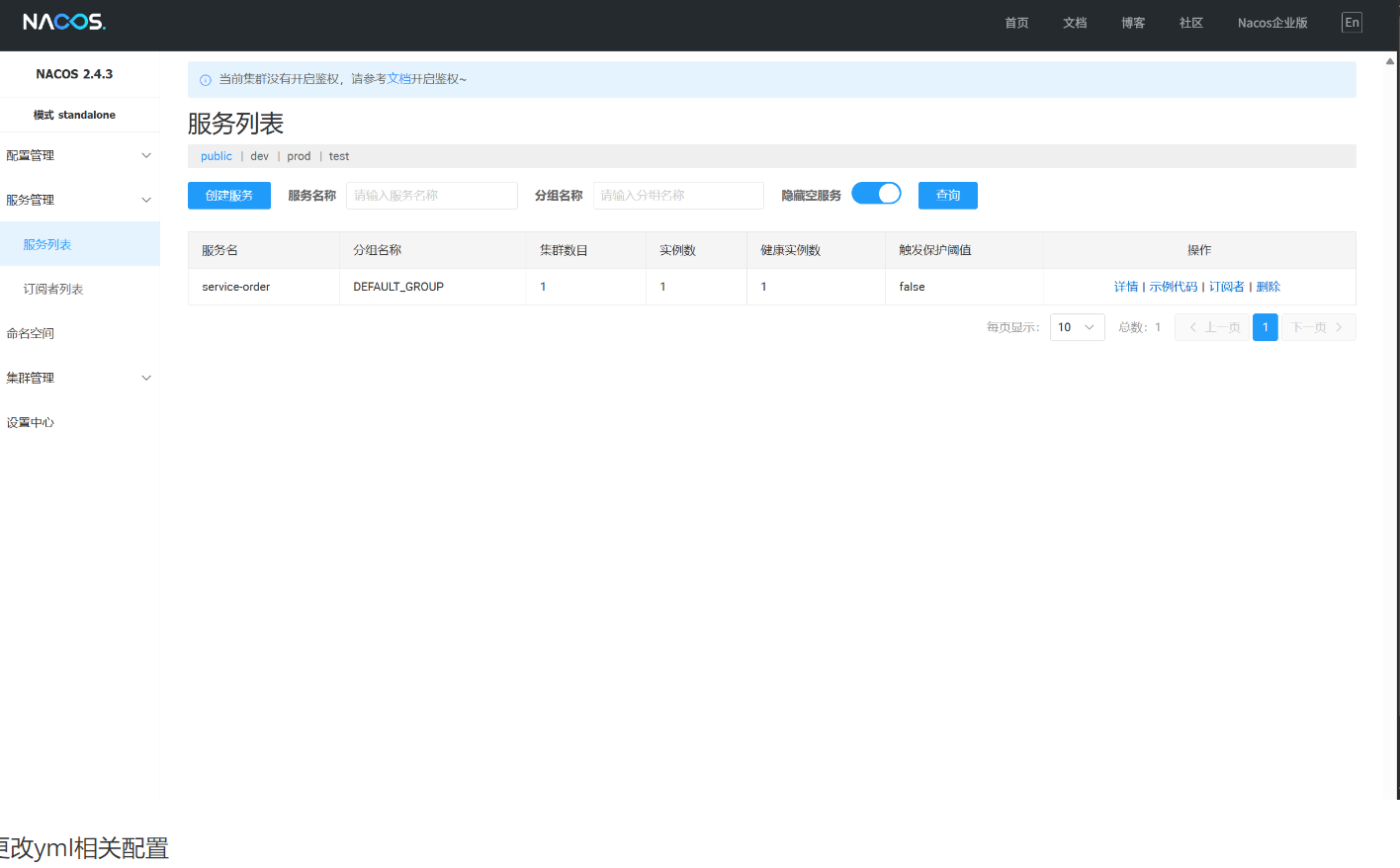
更改yml相关配置
spring:config:import: nacos:service-order.yml
如果没有配置中心的功能/导入配置文件,需要关闭相关配置,默认是开启的,否则报错。
#暂未用到配置中心功能,需要关闭配置检查
spring.cloud.nacos.config.import-check.enabled=false
验证:
@Value("${order.timeout}")
String orderTimeout;
@Value("${order.auto-confirm}")
String orderAutoConfirm;@GetMapping("/config")
public String getConfig() {return "OrderTimeout+OrderAutoConfirm = " + orderTimeout+" : " + orderAutoConfirm;
}
动态更新
动态刷新指的是当配置中心(如 Nacos)中的配置内容发生变更时,无需重启微服务应用,就能自动感知并加载最新配置的机制。
实现原理(以 Nacos 为例)
- 客户端监听配置:微服务启动时,会通过 Nacos 客户端注册对目标配置文件(如
common.yml)的监听。 - 配置中心推送变更:当 Nacos 中的配置被修改后,会主动向监听该配置的客户端推送变更通知(或客户端定期轮询检测变更)。
- 应用更新配置:客户端接收到变更通知后,会重新拉取最新配置,并通过 Spring 的配置刷新机制(如
@RefreshScope或@ConfigurationProperties的绑定逻辑)更新应用中的配置值
1,@Value(“${xx}”) 获取配置 + @RefreshScope 实现自动刷新
@Value("${config.app.name}"):直接从环境变量中读取config.app.name对应的配置值。@RefreshScope:标记类为 “刷新作用域”,当 Nacos 配置变更时,Spring 会销毁当前 Bean 并重新创建一个新实例,新实例会加载最新的配置值,从而实现 “自动刷新”。
只需要在相应的类上添加@RefreshScope注解即可。
@RestController()
@RequestMapping("/order")
@RefreshScope
public class OrderController {@Value("${order.timeout}")String orderTimeout;@Value("${order.auto-confirm}")String orderAutoConfirm;
}
2,@ConfigurationProperties 无感自动刷新
这种方式通过 @ConfigurationProperties 将一组配置项批量绑定到 Java 类中,无需额外注解即可实现自动刷新(Spring Cloud 2022.0.0+ 版本默认支持)
-命名发转驼峰命名法。
@Component
@ConfigurationProperties(value = "auto-database")//配置批量绑定在nacos下,可以无需@RefreshScope就能实现自动刷新
@Data
public class DataBaseProperties {private String url;private String enabled;private String username;
}
自动刷新机制:Spring Cloud 会通过 @ConfigurationPropertiesBinding 机制监听配置变更,当 Nacos 配置更新时,自动调用类的 setter 方法更新字段值,无需销毁 Bean,实现 “无感刷新”。
@ConfigurationProperties 的自动刷新是 Spring 的原生能力,Spring 会通过 @ConfigurationPropertiesBinding 机制监听配置源的变化(无论配置来自 Nacos、本地文件还是其他配置中心)。当配置发生变更时,Spring 会调用配置类的 setter 方法更新字段值。
Nacos 在这个过程中扮演的角色是配置源和变更通知者:
- 当你在 Nacos 控制台修改配置后,Nacos 客户端会通过长连接或轮询感知到变更,并将变更信息同步给 Spring 应用。
- 触发 Spring 刷新:Spring 接收到 Nacos 客户端传来的配置变更信号后,才会启动自身的
@ConfigurationProperties刷新机制,调用setter方法更新字段。
3,NacosConfigManager
NacosConfigManager 是 Nacos 客户端提供的核心类,用于管理配置并主动主动监听配置变更监听 **。通过它可以主动注册监听器,实时感知 Nacos 服务端配置的变化,并在回调中处理最新配置。
核心作用
- 直接与 Nacos 服务端交互,获取配置并管理配置监听。
- 支持为指定的
dataId、group注册监听器,当配置变更时触发回调。 - 相比
@ConfigurationProperties或@Value + @RefreshScope,提供更底层、更灵活的配置变更处理能力(例如自定义配置解析、触发业务逻辑等)
工作原理
- 获取
ConfigService:NacosConfigManager内部持有ConfigService实例,它是 Nacos 客户端与服务端交互的核心接口,负责配置的获取、监听等操作。 - 注册监听器:通过
configService.addListener(...)方法为指定dataId和group的配置注册监听器:- 当 Nacos 服务端的对应配置发生变更时,会主动推送变更通知到客户端。
- 客户端收到通知后,调用监听器的
receiveConfigInfo方法,并传入最新的配置内容。
- 处理配置变更:在
receiveConfigInfo回调中,可根据业务需求处理新配置(如解析、更新缓存、触发业务逻辑等),灵活性极高。
@Component
public class NacosConfigListenerExample {// 注入NacosConfigManager,它是Nacos配置管理的核心类@Autowiredprivate NacosConfigManager nacosConfigManager;// 配置参数:要监听的配置项private final String dataId = "common-config.yml"; // 配置文件名private final String group = "DEFAULT_GROUP"; // 配置分组// 初始化时注册监听器@PostConstructpublic void init() throws NacosException {// 获取Nacos的ConfigService(实际处理配置交互的服务)ConfigService configService = nacosConfigManager.getConfigService();// 注册监听器configService.addListener(dataId, group, new Listener() {// 配置变更时的回调方法@Overridepublic void receiveConfigInfo(String newConfigContent) {System.out.println("配置发生变化,新配置内容:\n" + newConfigContent);// 这里可以添加自定义处理逻辑,例如:// 1. 解析新配置(如JSON/XML/yml)// 2. 更新本地缓存// 3. 触发业务逻辑(如动态调整线程池参数)}// 执行回调的线程池(可自定义,也可返回null使用默认线程池)@Overridepublic Executor getExecutor() {return null; // 使用默认线程池}});// 初始加载配置(可选)String initialConfig = configService.getConfig(dataId, group, 5000);System.out.println("初始配置内容:\n" + initialConfig);}
}
配置优先级
Nacos中的数据集 和 application.properties 有相同的 配置项,哪个生效?二者会合并,如果出现冲突,则以配置中心为准,不然要配置中心干什么。
外部优先,包括你普通springboot项目不也是这样吗,启动jar包时如果携带参数,则携带的参数就会覆盖配置文件的配置。
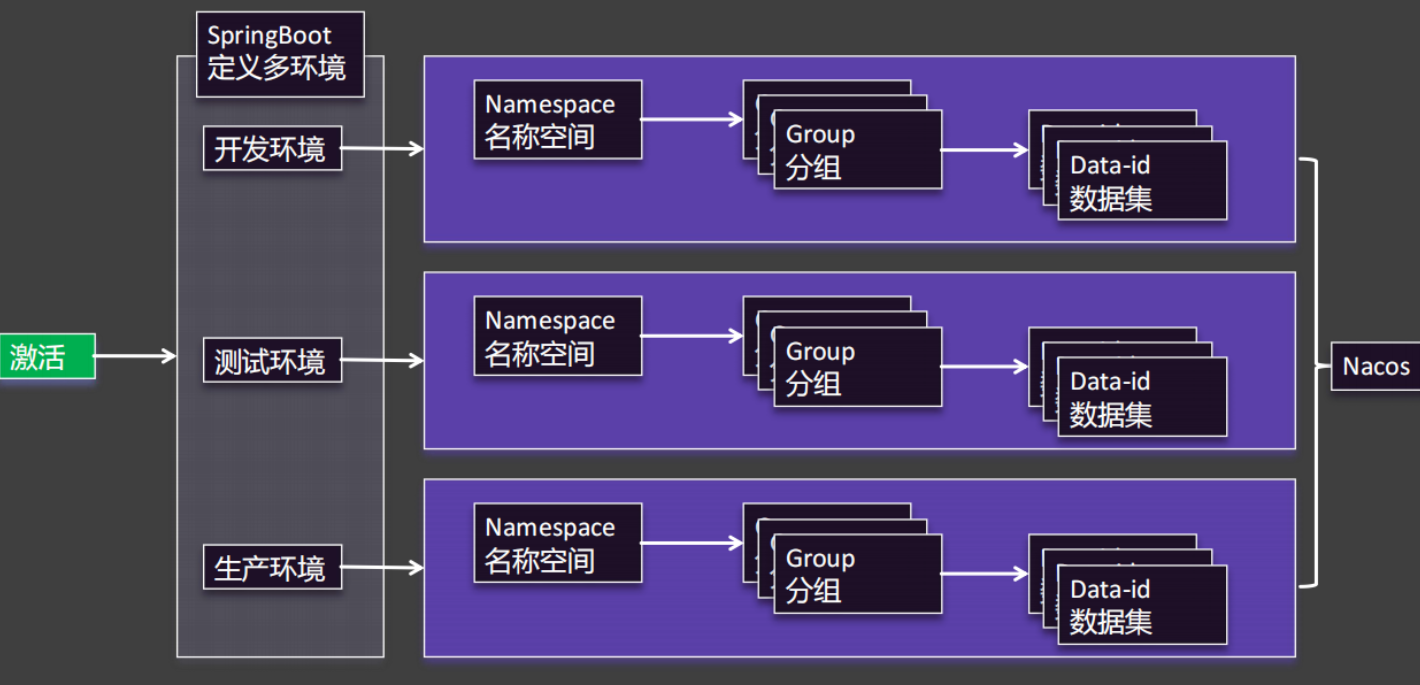
数据隔离
- 需求描述
- 项目有多套环境:dev,test,prod
- 每个微服务,同一种配置,在每套环境的值都不一样。
- 如:database.properties
- 如:common.properties
- 项目可以通过切换环境,加载本环境的配置

创建几个namespace和Group等方便测试
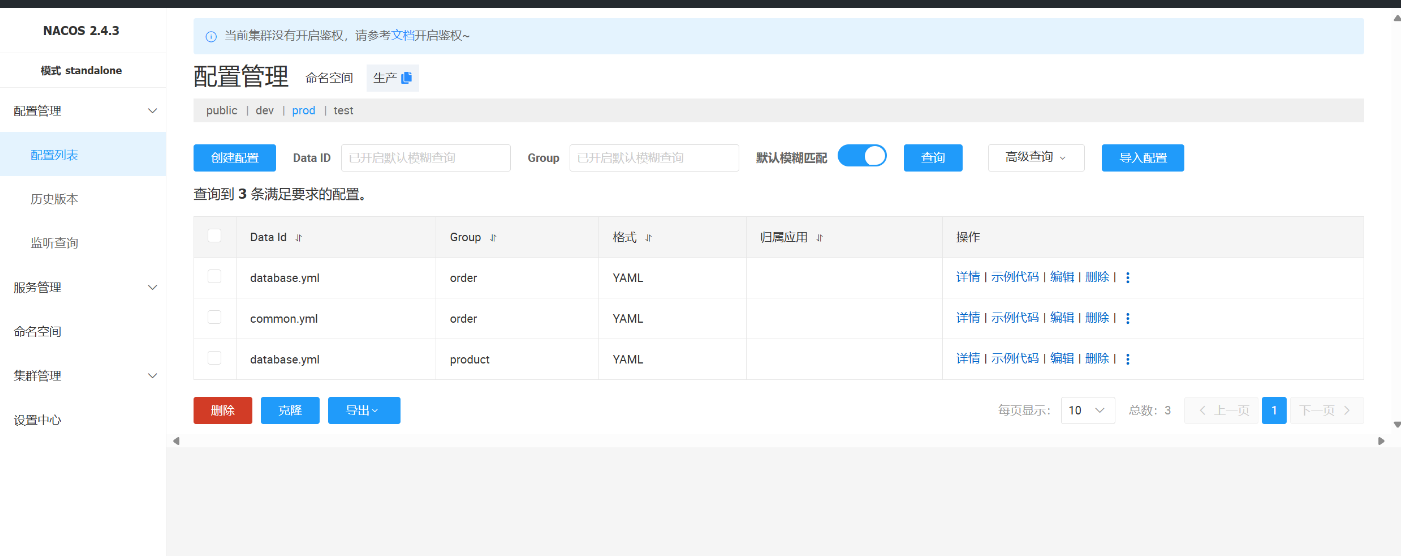
代码
auto-database:enabled: trueurl: auto-produsername: auto-prod
-----------------------
@Component
@ConfigurationProperties(value = "auto-database")//配置批量绑定在nacos下,可以无需@RefreshScope就能实现自动刷新
@Data
public class DataBaseProperties {private String url;private String enabled;private String username;
}
------------------------@Autowiredprivate DataBaseProperties dataBaseProperties;@GetMapping("/databaseConfig")public String getDatabaseConfig() {return "database.url=" + dataBaseProperties.getUrl() + " database.enable=" + dataBaseProperties.getEnabled() + " database.username=" + dataBaseProperties.getUsername();}
----------------------------
server:port: 8080
spring:profiles:active: prodapplication:name: service-ordercloud:nacos:server-addr: 127.0.0.1:8848config:file-extension: yml#命名空间namespace: ${spring.profiles.active:public}
---
spring:config:import:- nacos:common.yml?group=order- nacos:database.yml?group=orderactivate:on-profile: dev
---
spring:config:import:- nacos:common.yml?group=order- nacos:database.yml?group=orderactivate:on-profile: prod
---
spring:config:import:- nacos:common.yml?group=order- nacos:database.yml?group=orderactivate:on-profile: test其中 namespace: ${spring.profiles.active:public}指定命名空间是spring.profiles.active,如果没有则是:之后的public。
YAML 文件中,--- 是分隔符,用于将一个文件分割成多个配置文档块(每个块可以有独立的配置)。
spring.profiles.active指定谁生效,则哪个配置文档快生效。
3,OpenFeign
3.1简介
OpenFeign(曾称 Spring Cloud OpenFeign)是 Spring Cloud 生态中用于声明式 HTTP 客户端的组件,简化了微服务间的 HTTP 远程调用流程。它允许开发者通过定义接口的方式声明远程服务调用,无需手动编写 HTTP 客户端代码(如RestTemplate,RestTemplate是编程式Http客户端组件)。
优势
- 声明式编程:通过接口 + 注解定义远程调用,代码简洁,可读性强。
- 自动集成负载均衡:与 Spring Cloud LoadBalancer 或 Ribbon 无缝集成,自动实现请求负载均衡。
- 简化配置:支持自定义超时时间、重试策略、日志级别等,配置方式灵活。
- 与 Spring 生态兼容:支持 Spring MVC 注解(如
@GetMapping、@RequestParam),学习成本低。
3.2远程调用
1,引入依赖
在services模块引入依赖
<!--openfeign-->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2,添加注解,启用
在 Spring Boot 启动类上添加 @EnableFeignClients 注解,开启 OpenFeign 功能
3, 定义 Feign 接口
还是以service-order调用service-product服务为例。
声明要调用的远程服务名称(对应服务注册中心的服务名)
@FeignClient(value = "service-product")
public interface ProductFeignClient {@GetMapping("/product/get/{productId}")public Product getProduct(@PathVariable("productId") Integer productId);
}
4,调用远程服务
在业务代码中直接注入 Feign 接口并调用,就像调用本地方法一样。
@FeignClient 接口的代码默认已经实现了负载均衡,无需额外配置。OpenFeign 在 Spring Cloud 生态中会自动集成负载均衡组件(Spring Cloud LoadBalancer 或 Ribbon,取决于 Spring Cloud 版本),根据服务名从注册中心获取实例并分发请求。默认策略(轮询)。
@Autowired
private ProductFeignClient productFeignClient;@Overridepublic Order createOrder(Integer productId) {Order order = new Order();order.setId(1L);order.setTotalAmount(BigDecimal.valueOf(5));order.setUserId(6L);order.setNickName("wdwdwd");order.setAddress("xsxxxxxxxxxxxx");order.setProductList(Arrays.asList(productFeignClient.getProduct(productId)));return order;}
3.3相关配置
- 日志
- 超时配置
- 重试机制
(1)日志
@FeignClient 的 configuration 属性指定配置类,就是不需要@Configuration注解了。
这是 Feign 提供的日志级别配置,它控制 Feign 请求和响应的详细日志,Logger.Level.FULL 代表 打印所有请求和响应的详细信息。
Logger.Level.FULL是 Feign 定义的日志级别(控制打印哪些内容,如请求头、响应体等)。logging.level.xxx: debug是 Spring Boot 的日志配置(控制是否允许该包下的debug级别日志输出)。
@FeignClient(value = "service-product", configuration = FeignConfig.class)
// 配置类
public class FeignConfig {// 日志级别(NONE/BASIC/HEADERS/FULL)@BeanLogger.Level feignLoggerLevel() {return Logger.Level.FULL;}// 超时配置(默认单位:毫秒)@BeanRequest.Options options() {return new Request.Options(5000, // 连接超时时间10000 // 读取超时时间);}// 重试策略(使用默认实现,最多重试3次)@BeanRetryer retryer() {return new Retryer.Default(1000, 2000, 3);}
}
修改配置文件,这配置是 Spring Boot 的日志配置,用于设置 com.luxiya.feign 这个包下的 日志级别 为 DEBUG。
logging:level:com.luxiya.feign: debug
测试(随便整一个ProductFeignClient测试接口就行)
@Autowired
private ProductFeignClient productFeignClient;@RequestMapping("/get")
public String getProduct() {return productFeignClient.feign("Bearer 123", "123", "123");
}
访问结果
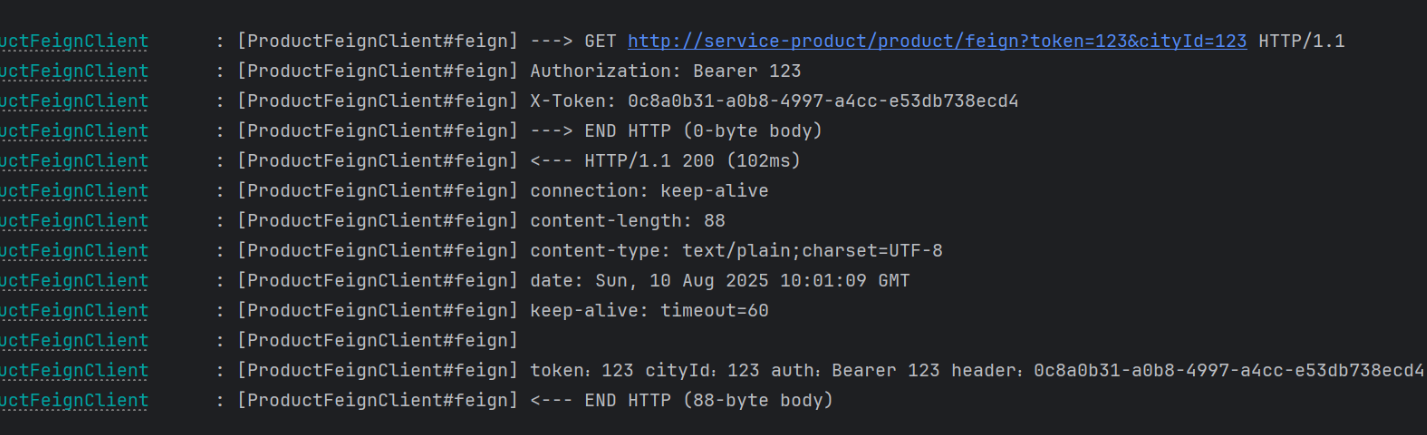
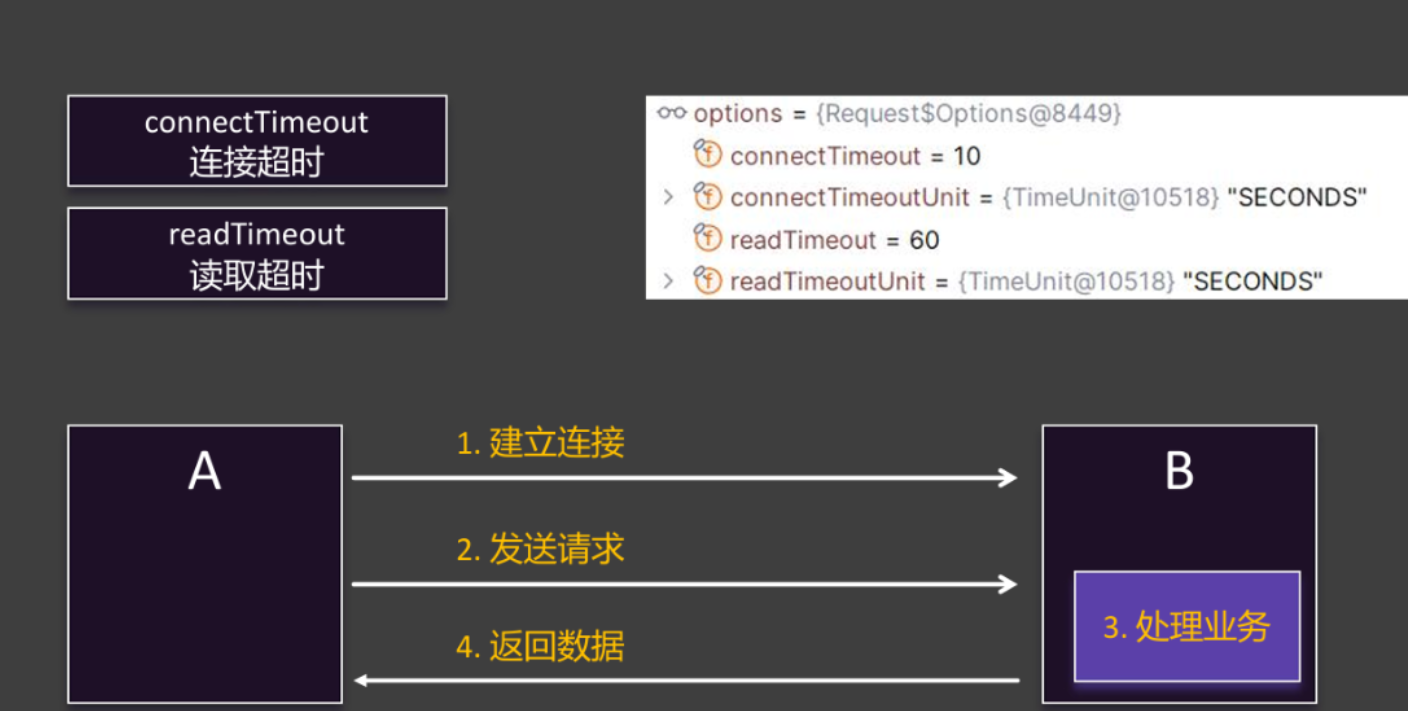
(2)超时配置
**连接超时(connectTimeout)**是指客户端(图中 A)尝试与服务端(图中 B)建立网络连接时的最大等待时长。(1.建立连接)
读取超时(readTimeout)是指客户端与服务端建立连接后,从发送请求到接收完响应数据的最大等待时长。(3.处理业务)
在application.yml引入application-feign.yml,方便管理
spring:profiles:active: prodinclude: feign
添加application-feign.yml
spring:cloud:openfeign:client:config:default:logger-level: fullconnect-timeout: 5000read-timeout: 5000service-product:logger-level: fullconnect-timeout: 5000read-timeout: 5000
默认配置default和指定服务的配置service-product,如果没有指定,则是默认配置。
在service-product中模拟超时。
try {TimeUnit.sleep(6000);
} catch (InterruptedException e) {e.printStackTrace();
}
(3)重试机制
在 OpenFeign 中,重试机制指的是当远程调用出现可重试异常(如网络波动、服务临时不可用)时,客户端自动重新发起请求的策略。
- 可重试异常
只有特定异常才会触发重试,主要包括:- 网络相关异常(如
ConnectException连接失败、SocketTimeoutException读取超时)。 - 服务端返回的 5xx 错误(如 503 服务不可用,代表服务暂时异常)。
- 注意:客户端异常(如 400 Bad Request)、业务异常(如自定义异常)不会触发重试。
- 网络相关异常(如
- 重试策略三要素
- 最大重试次数:最多重试几次(含首次失败的请求)。
- 初始重试间隔:第一次重试前等待的时间(如 1 秒)。
- 最大重试间隔:重试间隔的上限(避免间隔无限增大,如最多等 5 秒)。
OpenFeign 内置了 Retryer.Default 重试器,默认策略:
- 最大重试次数:5 次。
- 初始间隔:100 毫秒,之后每次间隔增加,可能是x1.5。
- 最大间隔:1 秒。
@Bean
Retryer retryer() {return new Retryer.Default();
}
添加即可完成相关配置。
在service-product中模拟超时,然后就会发现执行了5次service-product的方法,即ProductFeignClient的远程调用方法失败后,执行又了5次。
3.4拦截器
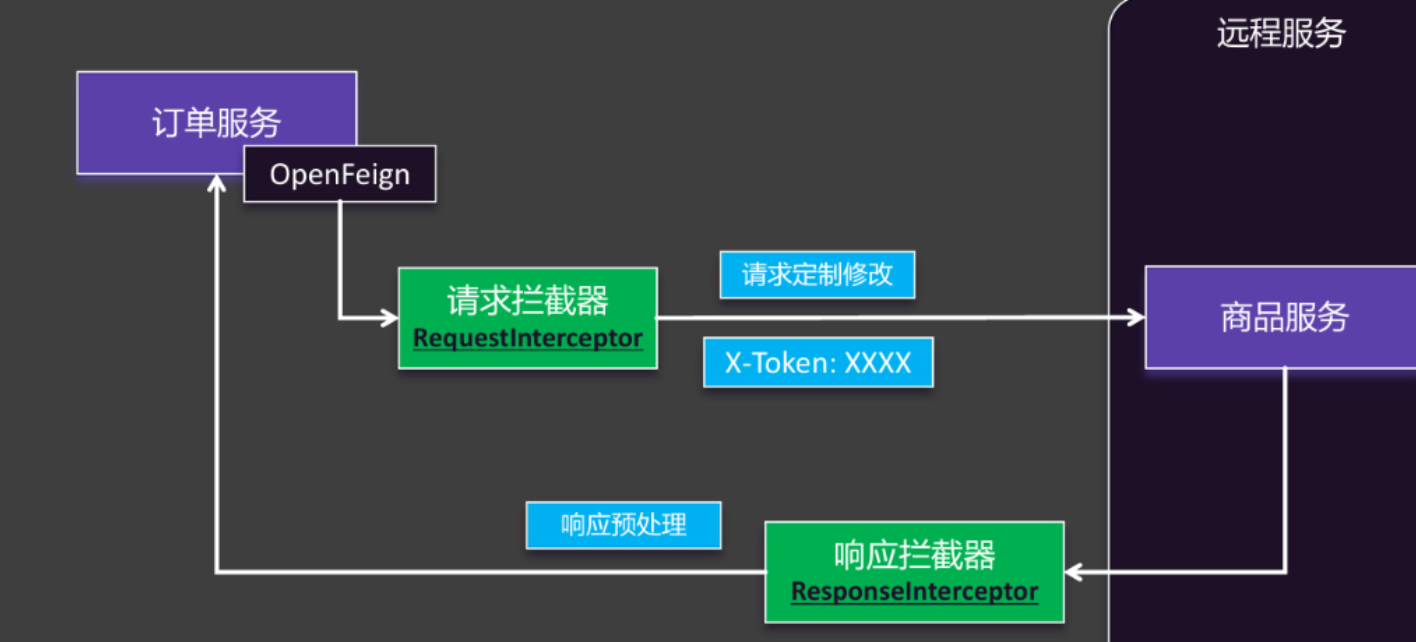
全局拦截器
这里拿请求拦截器举例
@Component
public class XTokenRequestIntercepter implements RequestInterceptor {@Overridepublic void apply(RequestTemplate requestTemplate) {requestTemplate.header("X-Token", UUID.randomUUID().toString());}
}
service-product服务打印拿到X-Token,测试ProductFeignClient远程调用发现可以拿到X-Token
--------------service-product------------@GetMapping("/feign")public String feign(@RequestHeader("Authorization") String auth,@RequestParam("token") String token,@RequestParam("cityId") String cityId,HttpServletRequest request) throws InterruptedException {System.out.println("feign");String header = request.getHeader("X-Token");System.out.println( header);return "token:"+ token+" cityId:"+cityId + " auth:"+auth+" header:"+header;}
---------ProductFeignClient-------------- @GetMapping("/product/feign")public String feign(@RequestHeader("Authorization") String auth,@RequestParam("token") String token,@RequestParam("cityId") String cityId);
局部拦截器
在相应的服务模块引入即可
spring:cloud:openfeign:client:config:default:logger-level: fullconnect-timeout: 5000read-timeout: 5000service-product:logger-level: fullconnect-timeout: 5000read-timeout: 5000request-interceptors:- com.luxiya.interceptor.XTokenRequestIntercepter
3.5兜底返回
在 OpenFeign 中,fallback(兜底 / 降级)机制是当远程服务调用失败(如超时、服务宕机、抛出异常)时,自动执行预设的 “兜底逻辑” 并返回默认结果,避免调用方因等待或异常而崩溃,是微服务容错的重要手段。
核心作用
- 隔离故障:当依赖的服务不可用时,通过 fallback 快速返回默认值,防止故障扩散(如服务雪崩)。
- 保障体验:即使远程服务故障,调用方仍能获得有意义的响应(而非报错),例如返回缓存数据或默认提示。
结合Sentinel实现,测试前可先将重试机制关了,不然会一直重试,无法快速看到兜底结果。
1,引入依赖
<!--sentinel-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2,定义 fallback 兜底类
@Component
public class ProductFeignClientFallback implements ProductFeignClient {@Overridepublic Product getProduct(Integer productId) {return null;}@Overridepublic String feign(String auth, String token, String cityId) {System.out.println("兜底回调");auth = "fallback";cityId = "fallback";token = "fallback";return "auth;"+ auth+" cityId:"+cityId+" token:"+token;}
}
3,在 Feign 接口中关联 fallback
@FeignClient(value = "service-product",fallback = ProductFeignClientFallback.class)
public interface ProductFeignClient {................
}
4,开启熔断支持
fallback 依赖熔断组件(如 Sentinel 或 Hystrix),需在配置中开启:
feign:sentinel:enabled: true
4,Sentinel
4.1简介
4.1.1介绍
Sentinel 是阿里巴巴开源的面向分布式服务架构的轻量级流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来保障服务的稳定性与可用性。
核心功能有流量控制,熔断降级,热点参数,系统规则,热点规则。但是系统规则中的检测(比如cpu)范围太大,没有精度,就算知道cpu占用太高也不知道具体是哪个服务造成的,没什么意义。且有类似k8s更好的监控替代品。至于授权规则则有专门的网关。
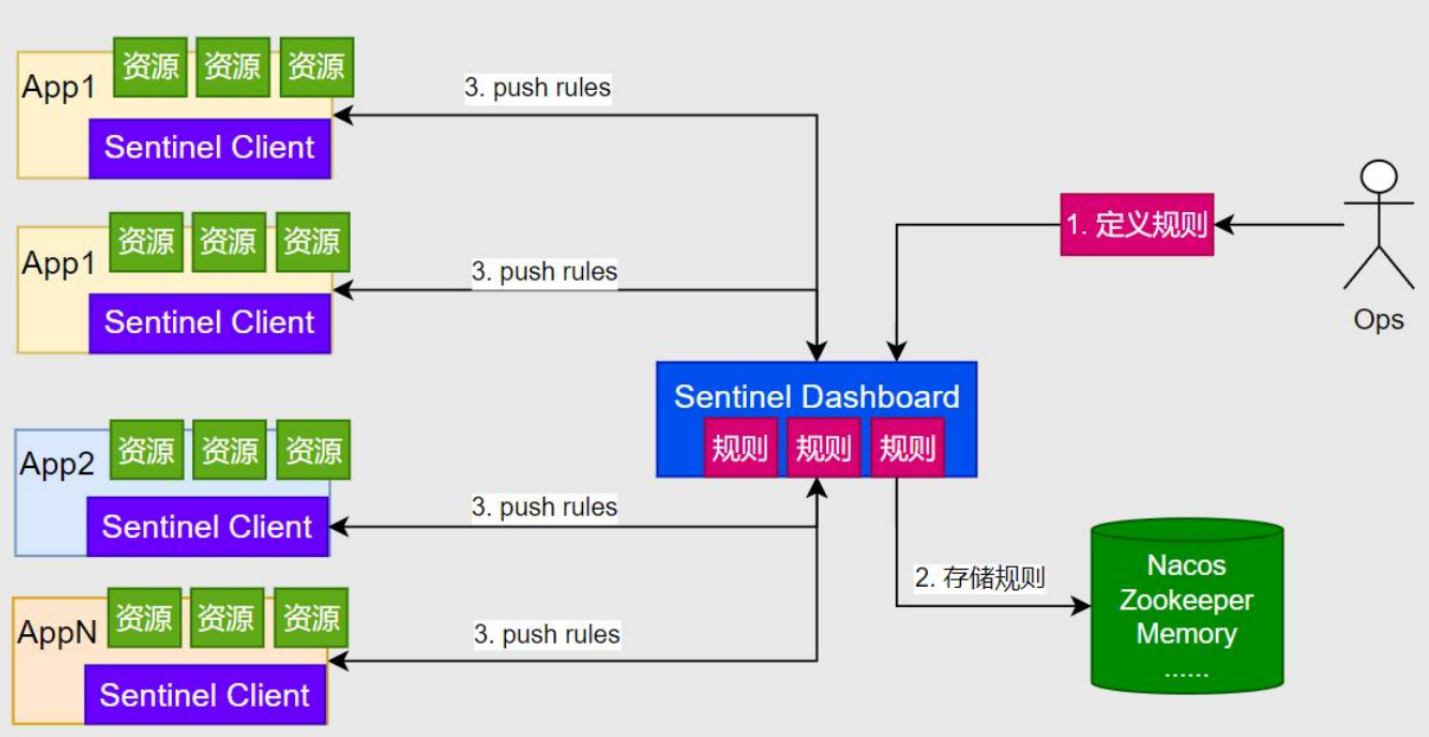
4.2.2安装 & 连接
下载jar包,然后cmd启动即可,这里jar包名就是sentinel-dashboard-1.8.8.jar
//默认是8080.可以指定端口
java -jar sentinel-dashboard-1.8.8.jar --server.port==8070
sentinel下载安装,启动(windows环境)-CSDN博客
然后访问localhost:8070即可,默认的账户密码都是sentinel
服务连接sentinel
1,在services中导入依赖,前面已经导的就不用再导了
<!--sentinel-->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2,在服务模块的yml中(service-product,service-order)配置连接
spring:cloud:sentinel:transport:dashboard: localhost:8070eager: true #热加载
4.2异常处理
4.2.1资源 & 规则
定义资源(Resource)
Sentinel 把 需要保护的对象 称为 “资源”,定义方式:
- 主流框架自动适配:
对 Web 框架(Servlet、Spring Cloud、gRPC 等)、RPC 框架(Dubbo),所有 Web 接口、服务方法会自动被识别为资源,无需手动标记。
例如:一个/order/get的 HTTP 接口,或UserService.getUser()的 Dubbo 方法,会被 Sentinel 自动作为资源监控。 - 编程式(SphU API):
手动用SphU.entry("资源名")标记代码片段为资源,适合非框架场景(如工具类、自定义逻辑)。 - 声明式(@SentinelResource):
用@SentinelResource("资源名")注解标记方法,细粒度控制资源,支持自定义限流、降级逻辑(blockHandler/fallback)。
定义规则(Rule)
规则是 Sentinel 的 “保护策略”,触发规则会执行限流、降级等动作,包含 5 类核心规则:
| 规则类型 | 作用 | 示例场景 |
|---|---|---|
| FlowRule(流量控制) | 限制资源的 QPS(每秒请求数)或并发线程数,防止流量洪峰压垮系统 | 商品秒杀接口,QPS 限制为 1000 |
| DegradeRule(熔断降级) | 当资源调用失败率 / 响应时间过高时,暂时熔断,防止故障扩散 | 支付接口超时率 > 50%,熔断 10 秒 |
| SystemRule(系统保护) | 基于系统负载(CPU、Load、内存)限流,保障机器不被压垮 | CPU 使用率 > 80% 时,拒绝新请求 |
| AuthorityRule(授权规则) | 黑白名单控制,比如只允许内网 IP 访问敏感接口 | 后台接口仅开放给内网 IP |
| ParamFlowRule(热点参数) | 对资源的参数值限流(如某商品 ID 被疯狂请求时单独限流) | 商品搜索接口,热门商品 ID QPS 限制为 500 |
这些规则都可以在Sentinel Dashboard中配置。
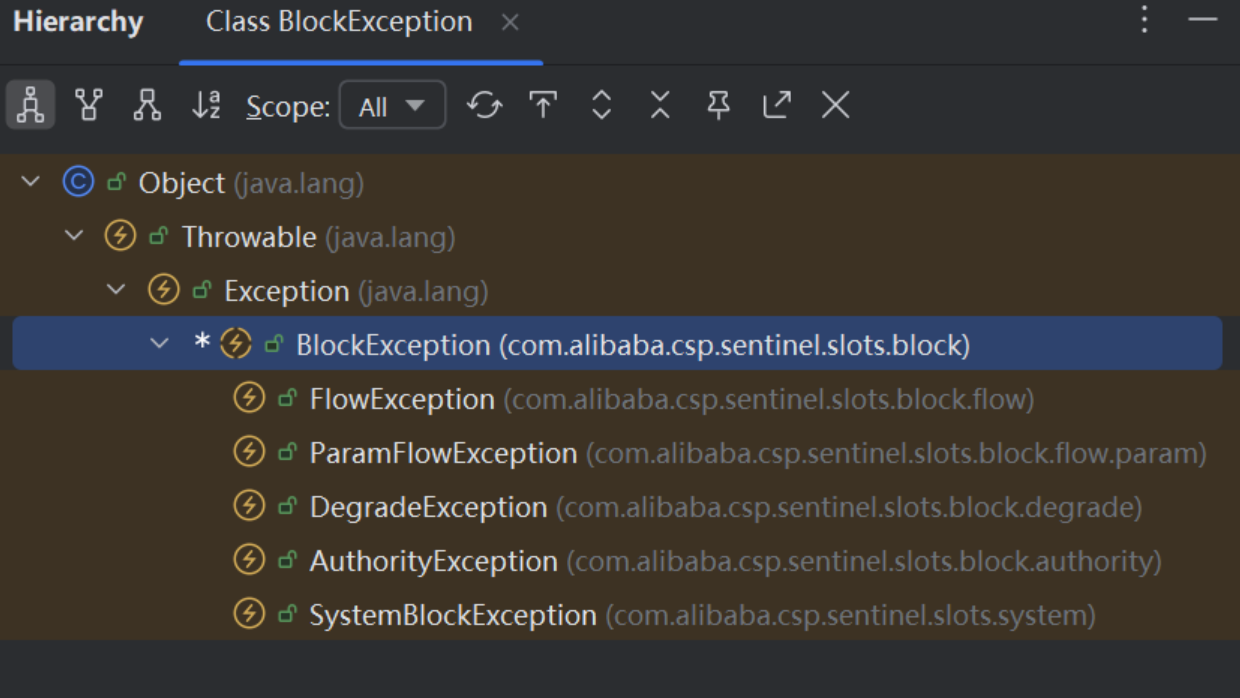
异常体系以 BlockException 为核心,不同子类对应不同规则触发场景。在 Sentinel 中,当访问受保护的资源时,若违反了为该资源配置的对应规则,就会抛出相应的 BlockException 子类异常。
BlockException:所有 Sentinel 限流、熔断等规则触发时抛出的父异常,继承自Exception包含以下子类:FlowException:流量控制(QPS / 并发数超限)ParamFlowException:热点参数限流(特定参数值 QPS 超限)DegradeException:熔断降级(调用失败率 / 响应时间超限触发熔断)AuthorityException:授权规则(如黑白名单不通过)SystemBlockException:系统负载保护(CPU/Load 等系统指标超限)
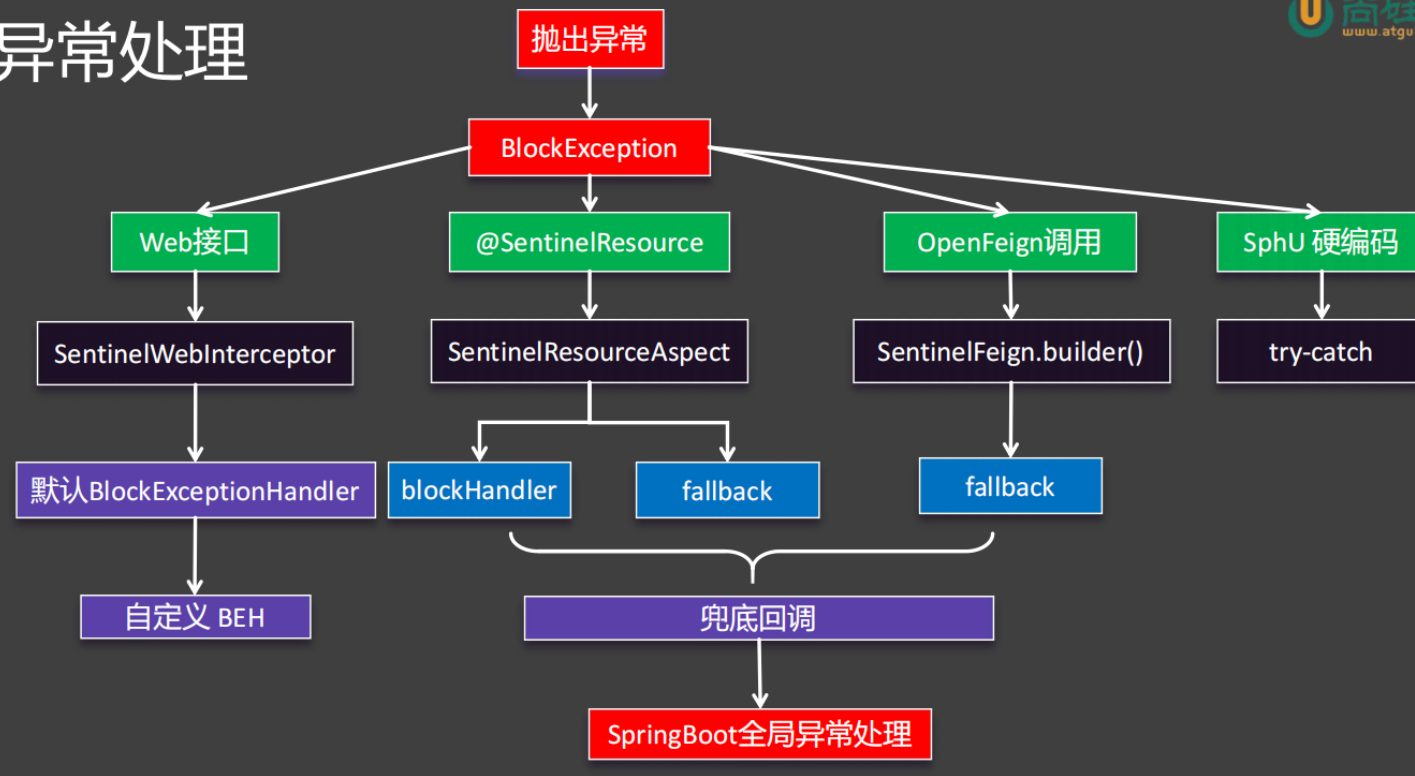
所有场景最终会抛出 BlockException(流量控制、熔断降级等触发时的异常基类 )。
- Web 接口:通过
SentinelWebInterceptor拦截,默认用BlockExceptionHandler处理,也可自定义BEH(异常处理器 )。 - @SentinelResource 注解:由
SentinelResourceAspect切面处理,支持blockHandler(处理 BlockException )和fallback(兜底业务异常 + BlockException )。 - OpenFeign 调用:通过
SentinelFeign.builder()集成,触发规则时走fallback降级。 - SphU 硬编码:手动用
try-catch捕获BlockException,自定义处理逻辑。
4.2.2Web接口
可以给一个web接口添加相应规则,比如流控QPS设置为1(方便测试)。
@RestController
@RequestMapping("/feign")
public class FeignController {@Autowiredprivate ProductFeignClient productFeignClient;@RequestMapping("/get")public String getProduct() {return productFeignClient.feign("Bearer 123", "123", "123");}
连续多次请求这个接口时,就会抛出流控的错误,然后会被SentinelWebInterceptor捕获,默认如下
下面自定义异常处理,返回json数据
//返回类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class R {private Integer code;private String msg;private Object data;public static R ok() {R r = new R(200,"相应成功",null);r.setCode(200);return r;}public static R ok(String msg,Object data) {R r = new R();r.setCode(200);r.setMsg(msg);r.setData(data);return r;}public static R error() {return new R(500, "相应失败", null);}public static R error(Integer code,String msg,Object data) {R r = new R();r.setData(data);r.setCode(code);r.setMsg(msg);return r;}
}
-----------实现SentinelWebInterceptor接口,注入即可--------------
@Component
public class MyBlockExceptionHandler implements BlockExceptionHandler {@Autowiredprivate ObjectMapper objectMapper;@Overridepublic void handle(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse,String s, BlockException e) throws Exception {httpServletResponse.setContentType(MediaType.APPLICATION_JSON);R error = new R(500, "请求被sentinel限流了", e.getClass());httpServletResponse.getWriter().write(objectMapper.writeValueAsString(error));}
}
4.2.3@SentinelResource 注解
value = "getProduct"是给该资源起个名称。blockHandler,fallback还有一个defaultFallback是该资源的异常处理。
捕获到异常后,会先调用blockHandler,如果没有则调用fallback,还没有就会调用defaultFallback,三者都没有就会扔给springboot返回错误页面。
@RequestMapping("/get")
@SentinelResource(value = "getProduct",blockHandler = "getProductBlockHandler",fallback = "getProductFallback"
)
public String getProduct() {return productFeignClient.feign("Bearer 123", "123", "123");
}public String getProductBlockHandler(BlockException e) {System.out.println("SentinelResource之blockHandler");return "SentinelResource之blockHandler"+e.getClass().toString();
}
public String getProductFallback() {System.out.println("SentinelResource之fallback");return "SentinelResource之fallback";
}
4.2.4openFeign & SphU 硬编码
openFeign的远程带调用也会被识别为一个资源,至于它的异常处理则是调用openFeign的兜底返回方法。即ProductFeignClientFallback。
@FeignClient(value = "service-product",fallback = ProductFeignClientFallback.class)
public interface ProductFeignClient {................
}
Sphu手动用 try-catch 捕获 BlockException,自定义处理逻辑。
// 标记 "order-process" 为资源,Sentinel 对这段逻辑有限流给i则
try (Entry entry = SphU.entry("order-process")) { // 业务逻辑:处理订单
} catch (BlockException e) {// 限流/熔断时执行降级log.warn("订单处理被限流", e);
}
4.3流量控制
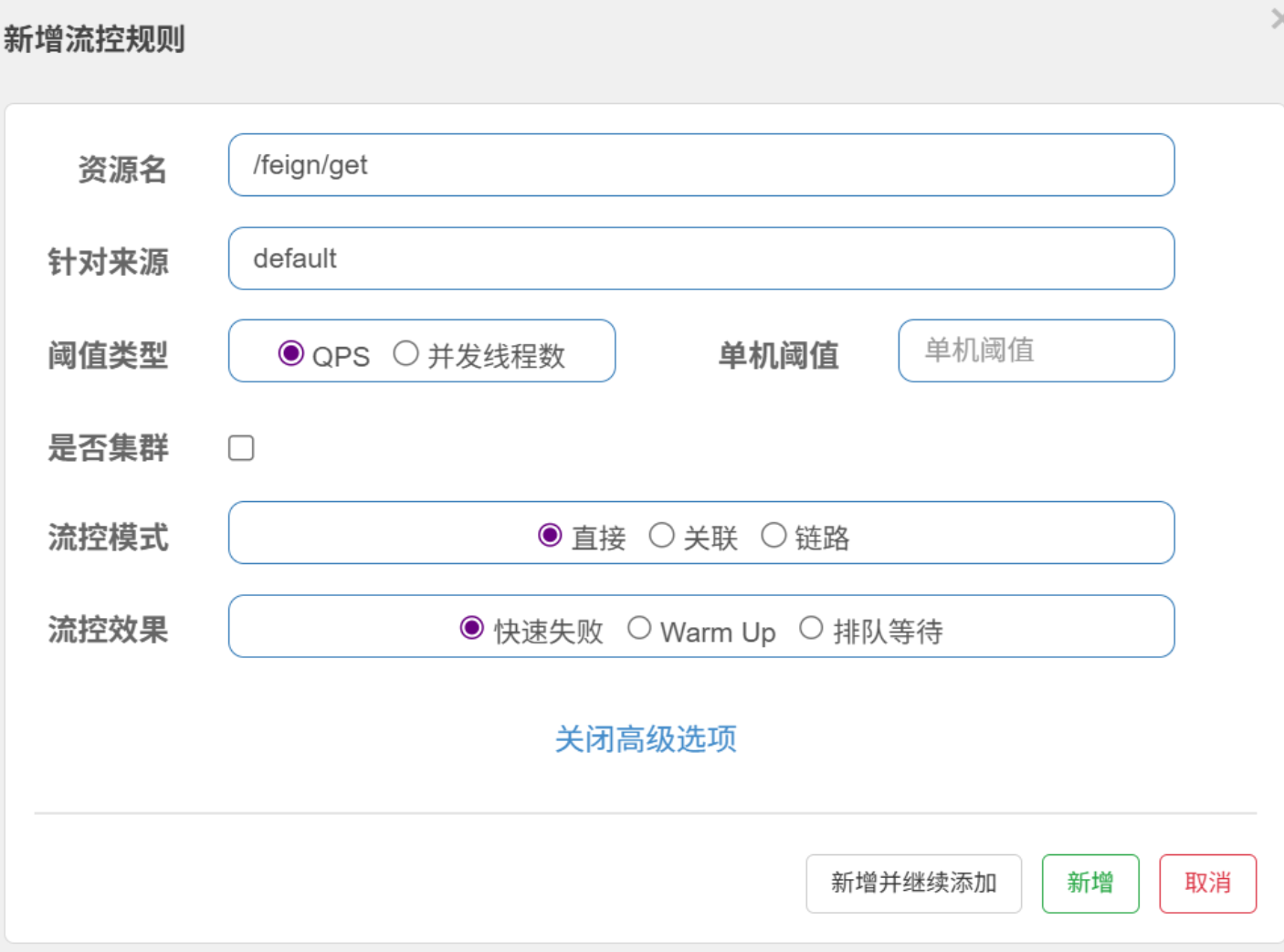
在 Sentinel 中,流控模式和流控效果是流量控制规则的核心配置,分别决定了 “何时触发限流” 和 “触发限流后如何处理请求”。
集群效果有**“单机均摊”和“总体阈值”**两种,字面意思,不在解释。
流控模式
(1)直接模式(默认)
- 含义:当当前资源自身的流量达到阈值时,直接对该资源限流。
- 场景:最常用的模式,用于保护资源自身不被流量压垮。
- 示例:为
/order/pay接口设置 QPS 阈值 1000,当该接口每秒请求数超过 1000 时,直接拒绝超额请求。
(2)关联模式
- 含义:当关联资源的流量达到阈值时,对当前资源限流(“牺牲” 当前资源,保护关联资源)。
- 场景:两个资源存在依赖关系,需优先保障核心资源。
- 示例
- 关联资源:
/order/create(下单接口,核心) - 当前资源:
/order/query(查询接口,非核心) - 配置:当
/order/create的 QPS 超过 500 时,对/order/query限流,确保下单接口有足够资源处理。
- 关联资源:
(3)链路模式
- 含义:只针对特定调用链路的流量限流,不限制其他链路对该资源的访问。
- 场景:同一资源被多个链路调用,需单独限制某条链路的流量。
- 示例
- 资源:
UserService.getUser()(用户查询方法) - 调用链路 1:
/order/get → UserService.getUser()(订单接口依赖) - 调用链路 2:
/comment/get → UserService.getUser()(评论接口依赖) - 配置:只限制 “评论接口 → getUser ()” 这条链路的 QPS 为 100,不影响订单接口的调用。
- 资源:
流控效果
流控效果定义了 “触发限流后,如何处理超额的请求”,Sentinel 提供 3 种效果:
(1)快速失败(默认)
- 含义:触发限流时,直接拒绝请求并抛出
FlowException,适合对响应速度要求高的场景。 - 特点:立即失败,不等待,避免资源浪费。
- 示例:秒杀接口触发限流时,直接返回 “请求过于频繁”。
(2)Warm Up
逐渐到达真阈值,算法会先设置几个假阈值,慢慢升到真阈值。
- 含义:初始时阈值较低,随着时间逐渐提升至目标阈值,避免流量突然激增打垮系统。
- 原理:基于 “令牌桶算法”,通过
coldFactor(默认 3)计算初始阈值 = 目标阈值 /coldFactor,然后逐步恢复。 - 场景:服务刚启动时(资源未预热)、流量长期低峰后突然高峰(如早晨的系统)。
- 示例:目标 QPS 阈值 100,初始阈值 33(100/3),经过预热时间(如 5 秒)后,阈值逐渐升至 100。
(3)排队等待
- 含义:触发限流时,让超额请求排队等待,匀速通过(按阈值速率),避免流量波动。需要配置超时时间,如果超时请求还没有通过则会失败。假设qps设为100,则每10ms通过一个。也因此,qps最大设为1000,因为大于1000无法在一秒内分配毫秒。
- 原理:基于 “漏桶算法”,控制请求通过的间隔(如 QPS 100 → 每 10ms 允许 1 个请求)。
- 场景:需要平滑流量的场景(如秒杀后的数据同步、避免下游服务被突发流量冲击)。
- 限制:仅支持 QPS 阈值类型,且需设置 “超时时间”(排队超过该时间则拒绝)。
4.4熔断降级
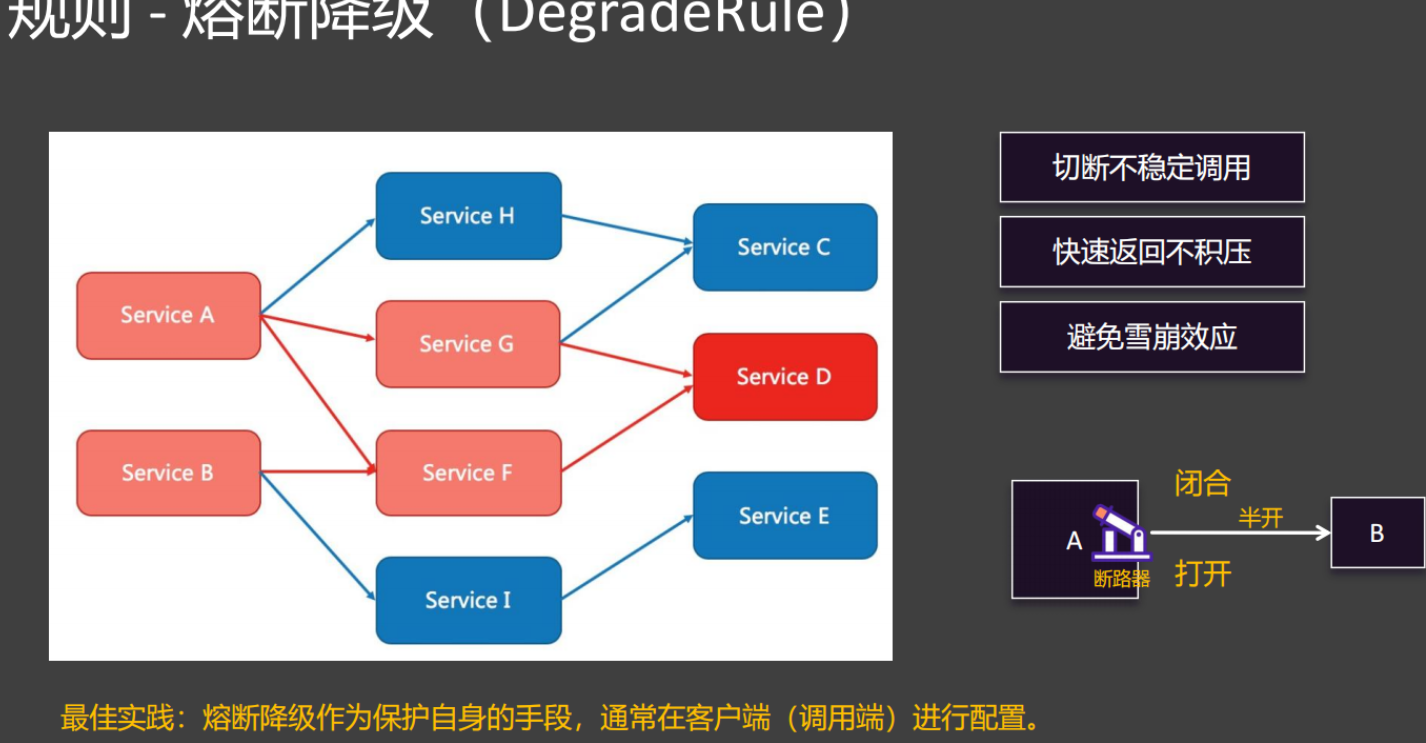
熔断降级是分布式系统中保障服务稳定性的重要机制,用于应对服务调用过程中可能出现的故障或异常,防止故障扩散导致整个系统崩溃。
核心概念
-
熔断(Circuit Breaking)
类似电路中的开关,当服务调用出现连续失败(如超时、异常)达到设定的阈值时,暂时中断对该服务的调用,避免无效请求持续消耗资源。- 状态切换:通常包含三种状态
- 闭合(Closed):正常状态,允许请求调用,持续统计失败率
- 打开(Open):失败率超标时触发,直接拒绝请求,快速返回降级结果
- 半开(Half-Open):熔断一段时间后尝试放行少量请求,若成功则恢复正常(闭合),否则继续熔断(打开)
- 状态切换:通常包含三种状态
-
降级(Degradation)
当服务压力过大、依赖服务不可用或触发熔断时,用预设的 “降级策略” 替代正常业务逻辑,保证核心功能可用。其实就是走快速失败的逻辑。熔断后不会再进入资源内(不会再执行/feign/get内的逻辑),而是直接走各个资源的失败逻辑。比如Web接口的BlockExceptionHandler,@SentinelResource的那三个。
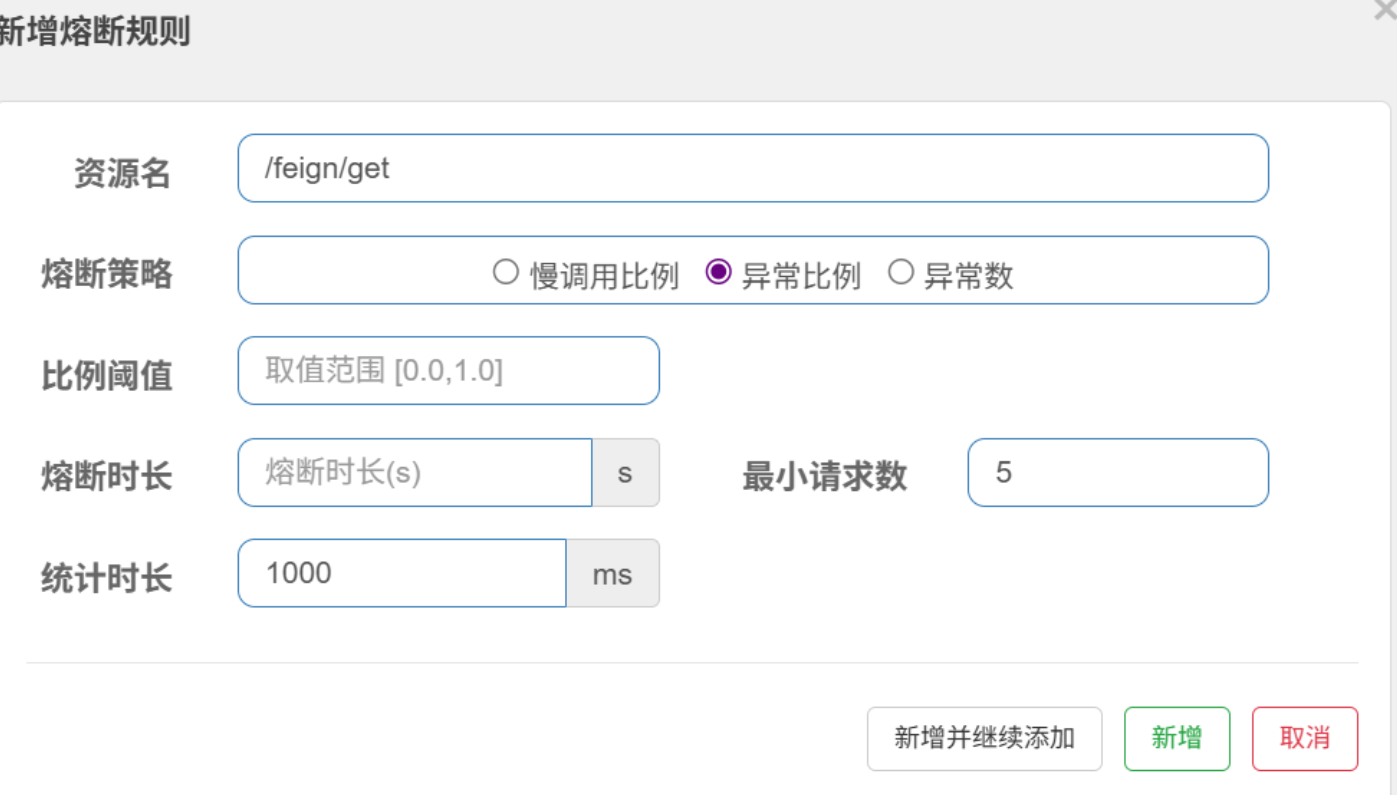
(1)慢调用比例
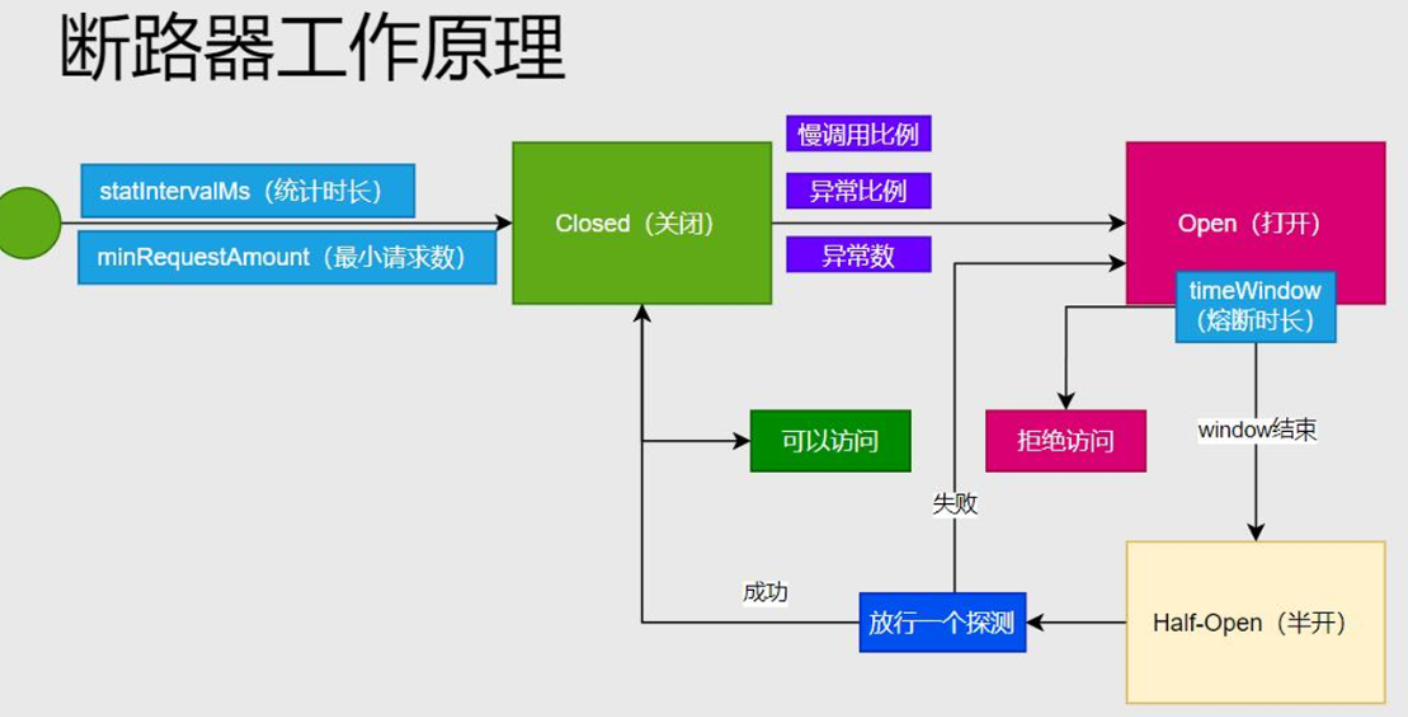
慢调用的判定标准:如果请求响应时间 超过 1000ms,则被标记为 “慢调用”。
触发熔断的比例条件,这里 0.8 表示 80% 。 “慢调用比例”意味着:在一个统计周期(即统计时长)中,慢调用数 / 总调用数 ≥ 80% 时,触发熔断。
熔断后,服务处于 “打开” 状态的时间(单位:秒 )。
这里 30s 表示:熔断触发后,30 秒内对该资源的调用直接降级,30 秒后进入 “半开” 状态,尝试放行少量请求验证服务是否恢复。
统计周期内,至少有 5 次请求 时,才会触发熔断判断。
若请求数不足 5 次,即使全部是慢调用或异常,也不会触发熔断(避免小流量误判 )。
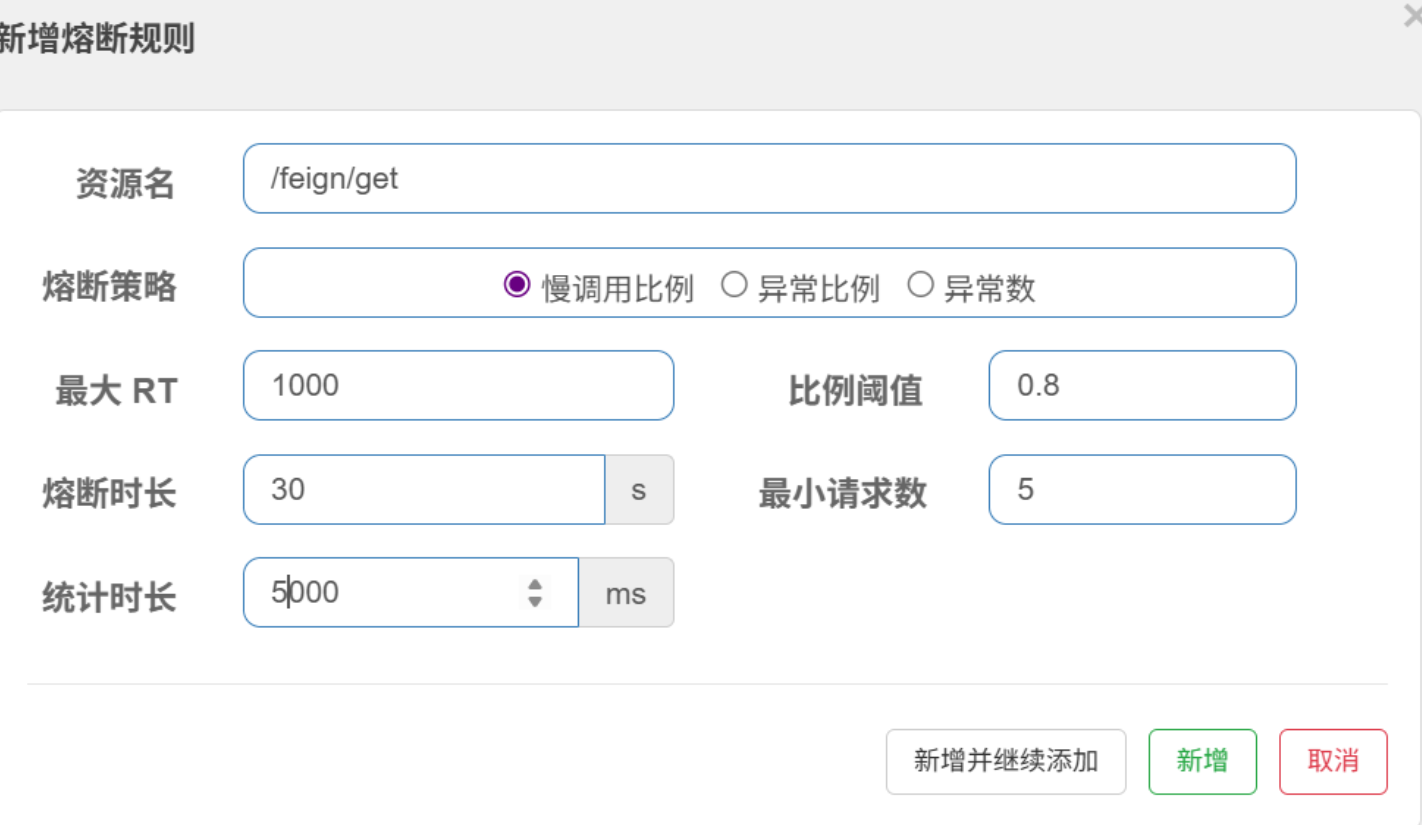
(2)异常比例 & 异常数
在 Sentinel 基于异常比例的熔断规则里,“异常”不是 BlockException,而是指业务代码或远程调用中抛出的业务异常、IO 异常、Feign 调用异常等(如 NullPointerException、FeignException 等 )
BlockException 是熔断触发后,Sentinel 拦截请求时抛出的框架异常,用于执行降级逻辑。
两者是 “统计异常→触发熔断→抛出 BlockException 执行降级” 的流程关系。
选 “异常比例”:异常调用数 / 总调用数 ≥ 80% 时,触发熔断。
至于异常数就字面意思,异常数量达到设置的阈值时,就会熔断。
4.5热点参数
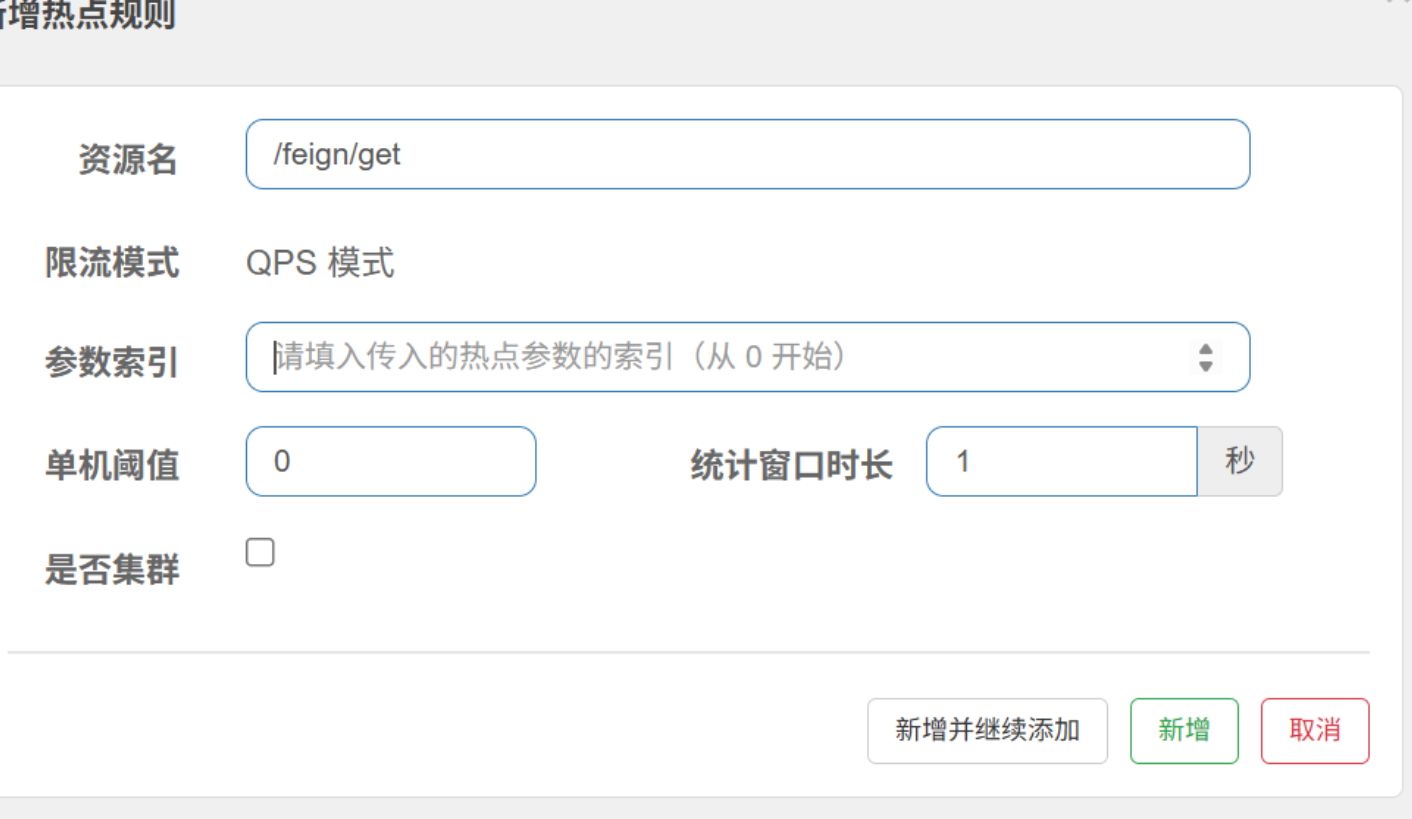
Sentinel 里的热点参数,是指对资源(如 /feign/get 接口 )的入参进行精细化限流的能力。核心作用是:根据参数值的不同,单独设置限流规则,避免 “一限流就全部拦截”,更灵活地保护系统。
参数索引
@SentinelResource("feign/get")
public String getProduct(String paramA, Long paramB) {// 业务逻辑
}
参数索引 0→ 对应paramA参数索引 1→ 对应paramB
统计窗口时长:统计 QPS 的时间范围(单位:秒 )。比如 1 秒 → 统计最近 1 秒内的请求数,判断是否超过 单机阈值。
举个例子:
假设你有个商品详情接口 /feign/get,入参是 productId(参数索引 0 ),代码如下:
@SentinelResource("feign/get")
public String getProduct(String productId) {// 查询商品详情并返回
}
- 普通限流:直接限制
/feign/get的 QPS 为 100 → 所有商品 ID 的请求都会被限流。 - 热点参数限流
- 配置
参数索引 0,单机阈值 10,统计窗口 1 秒→ 对单个productId(比如爆款商品 ID=123 ),限制每秒最多 10 次请求;其他商品 ID 不受影响。 - 这样,爆款商品的高并发请求被精准限流,普通商品仍能正常访问,避免 “一刀切”。
- 配置
5,gateway
5.1介绍
5.1.2环境配置
5.2基础原理
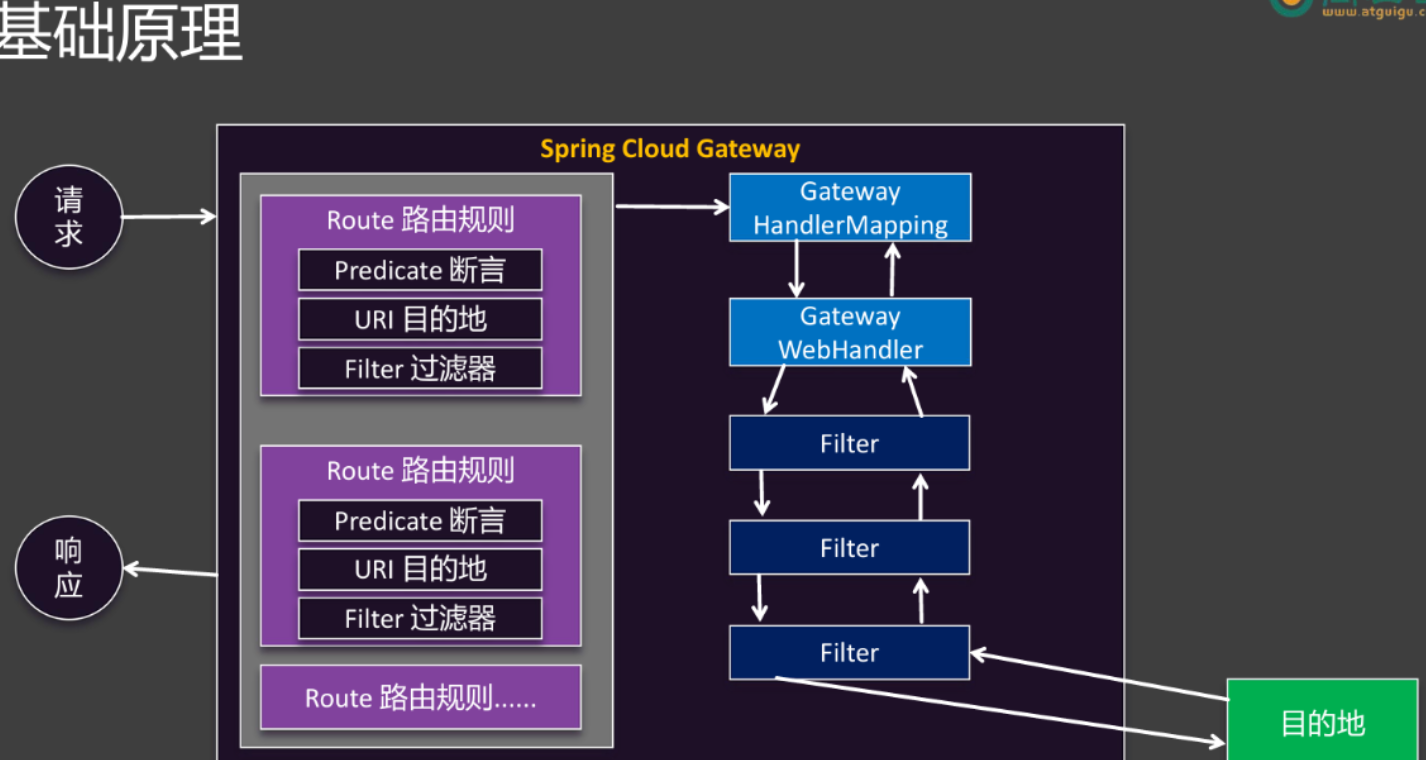
最重要的几个概念
- 路由规则(Route):是 Gateway 的核心,由断言(Predicate)、目标 URI(URI destination)和过滤器(Filter)组成 。
- 断言(Predicate):用于匹配请求的条件,比如请求的路径、请求头、请求参数等 。只有请求满足断言条件,才会被该路由规则处理。例如
Path=/product/**,表示匹配以/product开头的所有路径。 - 目标 URI(URI destination):指定符合断言条件的请求应转发到的后端微服务地址 ,可以是 HTTP、HTTPS、TCP 等协议的地址。
- 过滤器(Filter):对请求和响应进行处理,可以修改请求头、请求体,或者对响应进行处理 。比如添加请求头信息、修改请求路径、限流等操作。
- 断言(Predicate):用于匹配请求的条件,比如请求的路径、请求头、请求参数等 。只有请求满足断言条件,才会被该路由规则处理。例如
- GatewayHandlerMapping:负责将请求与路由规则进行匹配,找到对应的路由 。它会遍历所有的路由规则,根据断言条件判断请求是否符合某个路由,如果匹配成功,就将请求交给对应的 GatewayWebHandler 处理。
- GatewayWebHandler:拿到匹配的路由后,会构建一个过滤器链(Filter Chain) 。按照顺序依次执行过滤器链中的过滤器,对请求进行处理,然后将处理后的请求转发到目标 URI 对应的后端微服务 。当后端微服务返回响应后,过滤器链会反向执行,对响应进行处理,最后将响应返回给客户端。
5.3路由
在 application.yml 文件中配置路由规则示例如下:
spring:cloud:gateway:routes:- id: product_route # 路由的唯一标识uri: lb://product-service # 目标URI,lb表示使用负载均衡,指向product-service微服务predicates:- Path=/product/** # 断言:匹配以/product开头的所有路径filters:- StripPrefix=1 # 过滤器:去掉一级路径前缀- id: order_routeuri: http://localhost:8081 # 直接指定目标URIpredicates:- Method=GET # 断言:只匹配GET请求- Query=type,goods # 断言:请求参数中必须包含type=goodsfilters:- AddRequestHeader=X-Request-From,gateway # 过滤器:添加请求头metadata: # 自定义元数据timeout: 3000 # 超时时间(毫秒)allowCors: true # 是否允许跨域version: v1 # 接口版本
id:每个路由的唯一标识符,用于区分不同的路由规则。uri:请求转发的目标地址,可以是使用负载均衡指向的微服务名称(如lb://product-service),也可以是具体的 URL 地址(如http://localhost:8081)。predicates:断言,是一系列的条件判断,只有请求满足所有断言条件,才会被该路由规则处理。除上述示例外,还支持基于请求头(Header)、Cookie(Cookie)、请求时间(After、Before、Between)等多种断言。filters:过滤器,用于对请求和响应进行处理,可以修改请求头、请求体,或者对响应进行处理。过滤器分为全局过滤器和路由过滤器,上述示例中的是路由过滤器,只作用于当前路由;全局过滤器会对所有路由的请求生效。lb://是 Spring Cloud Gateway 内置的一种 URI 协议,用于标识该路由需要通过负载均衡器获取服务实例。
源码:
@ConfigurationProperties(GatewayProperties.PREFIX)
@Validated
public class GatewayProperties {public static final String PREFIX = "spring.cloud.gateway";private final Log logger = LogFactory.getLog(getClass());@NotNull@Validprivate List<RouteDefinition> routes = new ArrayList<>();private List<FilterDefinition> defaultFilters = new ArrayList<>();private List<MediaType> streamingMediaTypes = Arrays.asList(MediaType.TEXT_EVENT_STREAM,new MediaType("application", "stream+json"), new MediaType("application", "grpc"),new MediaType("application", "grpc+protobuf"), new MediaType("application", "grpc+json"));private boolean failOnRouteDefinitionError = true;
可以看到路由规则routes对应的就是private List<RouteDefinition> routes,进去看一下RouteDefinition
@Validated
public class RouteDefinition {private String id;@NotEmpty@Validprivate List<PredicateDefinition> predicates = new ArrayList<>();@Validprivate List<FilterDefinition> filters = new ArrayList<>();@NotNullprivate URI uri;private Map<String, Object> metadata = new HashMap<>();private int order = 0;
-
order代表的就是顺序优先级,数字越小优先级越高。其他一一对应。这也是一组路由规则。
-
metadata元数据本身不会直接影响路由的转发逻辑,但可以被网关的过滤器、全局逻辑或业务代码读取并使用,实现灵活的自定义功能。
@Component
public class CustomFilter implements GlobalFilter {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {// 获取当前路由的元数据Route route = exchange.getAttribute(ServerWebExchangeUtils.GATEWAY_ROUTE_ATTR);Map<String, Object> metadata = route.getMetadata();// 读取元数据中的 timeout 参数,设置超时逻辑Integer timeout = (Integer) metadata.getOrDefault("timeout", 3000);// ... 基于 timeout 执行超时处理return chain.filter(exchange);}
}
案例:
spring:cloud:gateway:routes:- id: orderuri: lb://service-orderpredicates:- Path=/api/feign/**- id: producturi: lb://service-productpredicates:- Path=/api/product/**
访问:localhost/api/feign/get
5.4Predicate(断言)
5.4.1长短写法
上面的写法- Path=/api/feign/**就是短写法,而长写法就是按照完整的格式写。
可以看到断言的源码。
@Validated
public class PredicateDefinition {@NotNullprivate String name;private Map<String, String> args = new LinkedHashMap<>();
长写法就是写全,那args里有什么参数可以写呢?取决于该类型的断言工厂的Config配置
断言名+RoutePredicateFactory就是该类型断言工厂的源码。
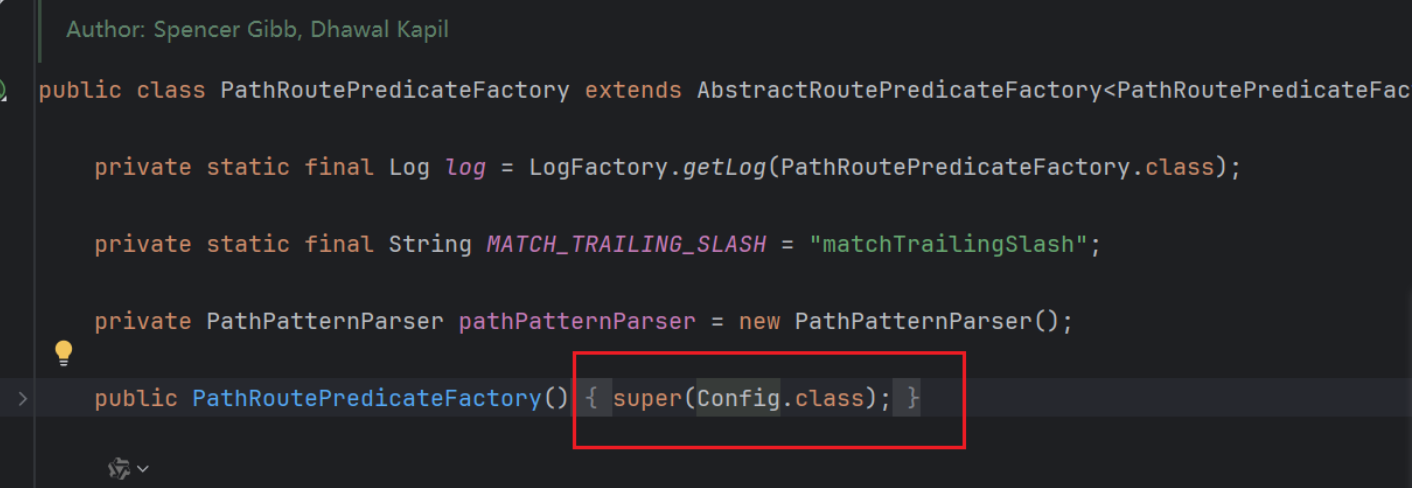
点进去Config源码可以看到,参数的含义不再解释,可去看官方文档。Spring Cloud Gateway 中文文档
@Validated
public static class Config {private List<String> patterns = new ArrayList<>();private boolean matchTrailingSlash = true;public List<String> getPatterns() {return patterns;}public Config setPatterns(List<String> patterns) {this.patterns = patterns;return this;}
5.4.2Query
Query类型的断言,还是和上面一样,找到相应的参数或者参考官方文档。
spring:cloud:gateway:routes:- id: bing-routeuri: https://cn.bing.com/predicates:- name: Pathargs:patterns: /searchmatchTrailingSlash: true- name: Queryargs:param: qregexp: xx
直接访问http://localhost/search失败
只有当携带参数q且值为xx时才会成功
http://localhost/search?q=xx成功
http://localhost/search?q=hh失败
还有很多其它类型的断言,可以进官网看一下Spring Cloud Gateway 中文文档
| 名 | 参数(个数/类型) | 作用 |
|---|---|---|
| After | 1/datetime | 在指定时间之后 |
| Before | 1/datetime | 在指定时间之前 |
| Between | 2/datetime | 在指定时间区间内 |
| Cookie | 2/string,regexp | 包含cookie名且必须匹配指定值 |
| Header | 2/string,regexp | 包含请求头且必须匹配指定值 |
| Host | N/string | 请求host必须是指定枚举值 |
| Method | N/string | 请求方式必须是指定枚举值 |
| Path | 2/List,bool | 请求路径满足规则,是否匹配最后的/ |
| Query | 2/string,regexp | 包含指定请求参数 |
| RemoteAddr | 1/List | 请求来源于指定网络域(CIDR写法) |
| Weight | 2/string,int | 按指定权重负载均衡 |
| XForwardedRemoteAddr | 1/List | 从X-Forwarded-For请求头中解析请求来源,并判断是否来源于指定网络域 |
5.4.3自定义predicates
按照QueryRoutePredicateFactory(随便一个进行仿写不就行了)。
案例需求,只有指挥官才能访问,队员队长等其他人都不行。从请求参数中拿到参数role,并且角色是commander才能访问。
- 自定义类,实现AbstractRoutePredicateFactory
- 定义内部类Config,属性和getset方法
- shortcutFieldOrder短写法的顺序
- apply断言逻辑。
- 注入@Component
@Component
public class RoleRoutePredicateFactory extends AbstractRoutePredicateFactory<RoleRoutePredicateFactory.Config> {private static final String ROLE_KEY = "role";private static final String VALUE_KEY = "value";public RoleRoutePredicateFactory() {super(Config.class);}@Overridepublic List<String> shortcutFieldOrder() {return Arrays.asList(ROLE_KEY,VALUE_KEY);}@Overridepublic Predicate<ServerWebExchange> apply(Config config) {return new GatewayPredicate() {@Overridepublic boolean test(ServerWebExchange serverWebExchange) {String first = serverWebExchange.getRequest().getQueryParams().getFirst(config.getRole());return !Objects.isNull(first) && first.equals(config.getValue());}};}@Validatedpublic static class Config {@NotEmptyprivate String role;@NotEmptyprivate String value;public @NotEmpty String getValue() {return value;}public void setValue(@NotEmpty String value) {this.value = value;}public @NotEmpty String getRole() {return role;}public void setRole(@NotEmpty String role) {this.role = role;}}
}
-------------yml-------------------
spring:cloud:gateway:routes:- id: bing-routeuri: https://cn.bing.com/predicates:- name: Pathargs:patterns: /searchmatchTrailingSlash: true- name: Queryargs:param: qregexp: xx- name: Roleargs:role: commandervalue: saber
访问:http://localhost/search?q=xx&commander=saber成功
5.5Filter(过滤器)
在 Spring Cloud Gateway 中,过滤器(Filter)是实现请求拦截、修改、转发等功能的核心组件,用于在请求到达目标服务之前或响应返回客户端之前进行一系列处理。根据作用范围和执行时机,Gateway 的过滤器可分为两大类:全局过滤器(Global Filter) 和 路由过滤器(Route Filter)。
Spring Cloud Gateway 中文文档同样,这里有很多过滤器,可以参考官方文档。
5.5.1基本使用
这里拿路径重写举例,使用场景很多。向上面5.3路由里的案例,如果给每个service-order里的接口都带/api前缀那也太费劲了。
- id: orderuri: lb://service-orderpredicates:- name: Pathargs:patterns: /api/feign/**matchTrailingSlash: truefilters:- RewritePath=/api/?(?<segment>.*), /$\{segment}
同样,fliter也有长短写法。这是用Java正则表达式来重写请求路径的一种灵活方式。
/api/?(?<segment>.*), /$\{segment}的含义就是将所有以 /api/feign 或 /api/feign/ 开头的请求路径,重写为去掉前缀后的路径。如/api/feign/product → 重写为 /feign/product
controller中@RequestMapping("/api/feign")变为@RequestMapping("/feign")后,访问localhost/api/feign/get也成功了。
5.5.2默认Filter
其应用于所有路由的filter。
spring:cloud:gateway:default-filters:- AddResponseHeader=X-Response-Commander,saber
5.5.3GlobalFilter
在 Spring Cloud Gateway 中,全局过滤器(Global Filter) 是一种特殊的过滤器,它不需要通过配置文件或注解指定作用于哪些路由,而是会对所有路由请求生效。全局过滤器主要用于实现一些通用性的功能,如认证授权、日志记录、请求限流、跨域处理等,是网关层面统一处理请求的重要手段。
自定义一个
@Component
@Slf4j
public class RtGlobalFliter implements GlobalFilter, Ordered {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {ServerHttpRequest request = exchange.getRequest();ServerHttpRequest response = exchange.getRequest();String url = request.getURI().toString();long startTime = System.currentTimeMillis();log.info("请求开始:{},时间:{}", url,startTime);return chain.filter(exchange).doFinally(result -> {long endTime = System.currentTimeMillis();log.info("请求结束:{},耗时:{}", url, endTime - startTime);});}@Overridepublic int getOrder() {return 0;}
}
----------------------请求结果----------
2025-08-13T12:37:40.143+08:00 INFO 21196 --- [gateway] [ctor-http-nio-2] com.luxiya.fliter.RtGlobalFliter : 请求开始:http://localhost/api/feign/get,时间:1755059860143
2025-08-13T12:37:40.742+08:00 INFO 21196 --- [gateway] [ctor-http-nio-5] com.luxiya.fliter.RtGlobalFliter : 请求结束:http://localhost/api/feign/get,耗时:599
5.5.4自定义过滤器
类似断言,随便找一个参考。比如AddResponseHeaderGatewayFilterFactory。
自定义的过滤器要求:添加一个一次性令牌,支持jwt,token等格式。
@Component
public class OnceTokenGatewayFilterFactory extends AbstractNameValueGatewayFilterFactory {@Overridepublic GatewayFilter apply(NameValueConfig config) {return new GatewayFilter() {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {return chain.filter(exchange).then(Mono.fromRunnable(()->{ServerHttpResponse response = exchange.getResponse();HttpHeaders headers = response.getHeaders();String value = config.getValue();if ("uuid".equalsIgnoreCase(value)) {value = UUID.randomUUID().toString();}if ("jwt".equalsIgnoreCase(value)) {value = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9." +"eyJzdWIiOiIxMjM0NTY3ODkiLCJuYW1lIjoiSm9obiBEb2UifQ." +"SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c";}headers.add(config.getName(), value);}));}};}
}
--------------------yml配置-----------
- id: orderuri: lb://service-orderpredicates:- name: Pathargs:patterns: /api/feign/**matchTrailingSlash: truefilters:- RewritePath=/api/?(?<segment>.*), /$\{segment}- OnceToken=X-Response-Token,uuid
5.5.6CORS 配置
@CrossOrigin解决一个Controller的跨域- 配置
CorsFilter配置类,实现项目级别的跨域,但是它也只能解决一个服务的跨域。
在gateway中配置全局跨域,既可以配置一个全局的,也可以给每个服务单独配置,参考官网。
全局配置会应用于所有路由,如果某些路由需要特殊的 CORS 设置,可以在具体路由中单独配置,会覆盖全局配置。
Spring Cloud Gateway 中文文档
这个配置的作用是允许所有来源、所有 HTTP 方法和所有请求头的跨域访问。
allowedOrigins: "*"在生产环境中不安全,建议指定具体的允许来源(如https://example.com)- 同样,
allowedMethods和allowedHeaders也应根据实际需求限制,而非使用通配符
spring:cloud:gateway:globalcors:cors-configurations:'[/**]':allowedOrigins: "*"allowedMethods: "*"allowedHeaders: "*"
-----------配置例子----------------
spring:cloud:gateway:globalcors:cors-configurations:'[/**]':allowedOrigins: - "https://your-frontend-domain.com"allowedMethods: - GET- POST- PUT- DELETEallowedHeaders: - Content-Type- AuthorizationallowCredentials: true # 允许携带凭证(如Cookie)maxAge: 3600 # 预检请求的缓存时间(秒)
6,Seata
6.1介绍
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。它由阿里巴巴开源,目前属于 Apache 孵化器项目,主要解决微服务架构下的分布式事务问题。
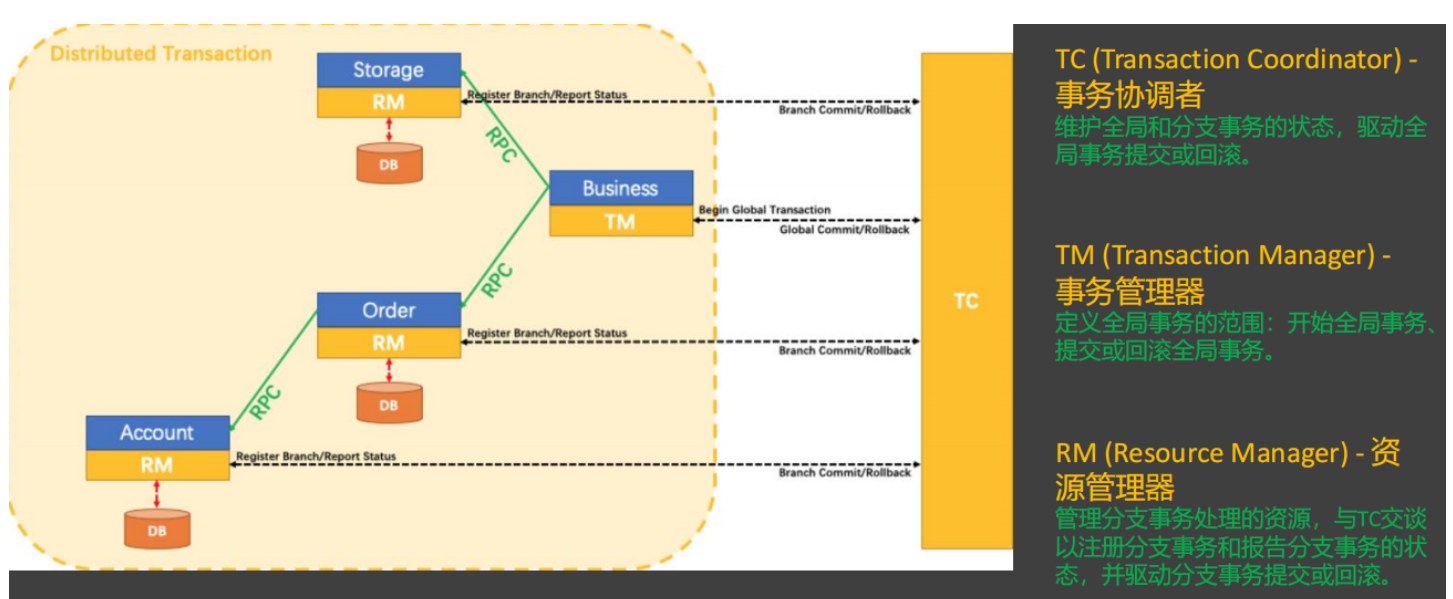
Seata 的核心概念
- TC (Transaction Coordinator) - 事务协调者
维护全局事务和分支事务的状态,协调全局事务提交或回滚。 - TM (Transaction Manager) - 事务管理器
定义全局事务的范围,负责开启、提交或回滚全局事务。 - RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与 TC 通信以注册分支事务和报告分支事务状态,并驱动分支事务的提交或回滚。
Seata 的优势
- 高性能:AT 模式通过 undo log 异步清理和本地事务优化,性能接近本地事务。
- 易用性:AT 模式无需修改业务代码,通过注解即可实现分布式事务。
- 灵活性:支持多种事务模式,适配不同业务场景。
- 生态集成:与 Spring Cloud、Dubbo、Nacos、Eureka 等主流微服务组件无缝集成。
注意事项
- 生产环境需保证 Seata Server 高可用(集群部署)。
- AT 模式需数据库支持主键索引和 undo log 表(需手动创建)。
- 避免长事务,以免占用资源过久影响性能。
6.2环境搭建
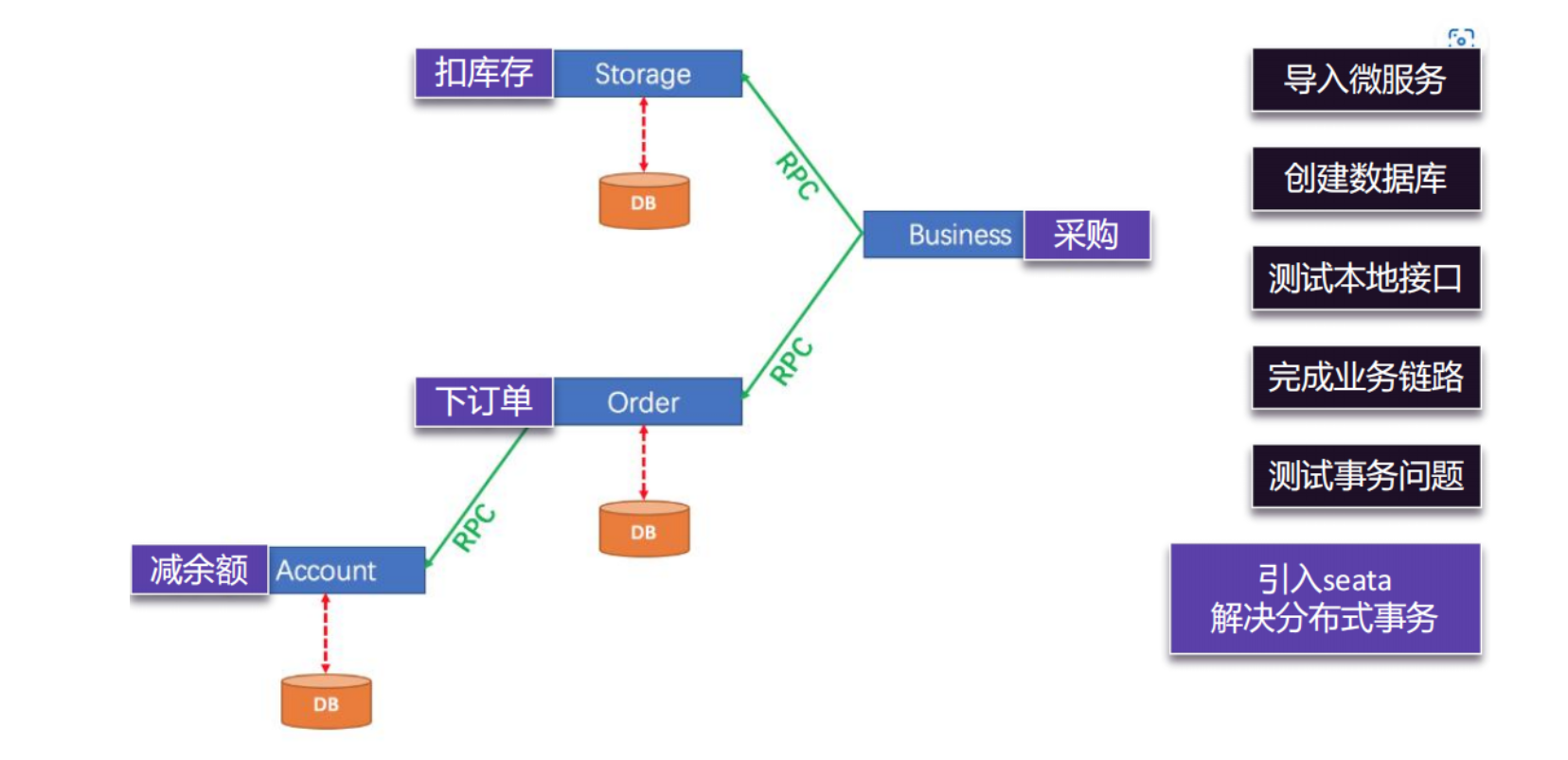
基础服务&测试
这部分不再过多赘述。按照尚硅谷的环境搭建即可。导入四个seata的服务,修改services的moduel。记得修改各个seata的pom中的parent,因为有可能坐标不一样。然后测试一下各个服务是否有问题即可。
- 搭建基础服务环境
- 基础接口测试
- 本地事务测试
- 打通远程链路
SQL语句:
CREATE DATABASE IF NOT EXISTS `storage_db`;
USE `storage_db`;
DROP TABLE IF EXISTS `storage_tbl`;
CREATE TABLE `storage_tbl` (`id` int(11) NOT NULL AUTO_INCREMENT,`commodity_code` varchar(255) DEFAULT NULL,`count` int(11) DEFAULT 0,PRIMARY KEY (`id`),UNIQUE KEY (`commodity_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO storage_tbl (commodity_code, count) VALUES ('P0001', 100);
INSERT INTO storage_tbl (commodity_code, count) VALUES ('B1234', 10);-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` longblob NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL,`ext` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;CREATE DATABASE IF NOT EXISTS `order_db`;
USE `order_db`;
DROP TABLE IF EXISTS `order_tbl`;
CREATE TABLE `order_tbl` (`id` int(11) NOT NULL AUTO_INCREMENT,`user_id` varchar(255) DEFAULT NULL,`commodity_code` varchar(255) DEFAULT NULL,`count` int(11) DEFAULT 0,`money` int(11) DEFAULT 0,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` longblob NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL,`ext` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;CREATE DATABASE IF NOT EXISTS `account_db`;
USE `account_db`;
DROP TABLE IF EXISTS `account_tbl`;
CREATE TABLE `account_tbl` (`id` int(11) NOT NULL AUTO_INCREMENT,`user_id` varchar(255) DEFAULT NULL,`money` int(11) DEFAULT 0,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO account_tbl (user_id, money) VALUES ('1', 10000);
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
DROP TABLE IF EXISTS `undo_log`;
CREATE TABLE `undo_log` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`branch_id` bigint(20) NOT NULL,`xid` varchar(100) NOT NULL,`context` varchar(128) NOT NULL,`rollback_info` longblob NOT NULL,`log_status` int(11) NOT NULL,`log_created` datetime NOT NULL,`log_modified` datetime NOT NULL,`ext` varchar(100) DEFAULT NULL,PRIMARY KEY (`id`),UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
整合Seata
-
下载seata服务端:Seata Java Download | Apache Seata
-
解压并启动:seata-server.bat 访问:http://localhost:7091/ 账号密码都是seata
-
在微服务中导入spring-cloud-starter-alibaba-seata依赖
-
在resources里配置file.conf文件,每个seata服务都配置
在services模块中引入依赖:
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
在各个模块添加file.conf
service {
#transaction service group mapping
vgroupMapping.default_tx_group = "default"
#only support when registry.type=file, please don't set multiple addresses
default.grouplist = "127.0.0.1:8091"
#degrade, current not support
enableDegrade = false
#disable seata
disableGlobalTransaction = false
}
-
在RM分支事务微服务中,方法上加@Transactional
-
在TM全局事务微服务中,方法上要加上@GlobalTransactional。这个注解是核心。
在 Spring Boot 中,不需要 @EnableTransactionManagement 也能回滚数据,因为 Spring Boot 默认开启了事务管理。如果你在 Spring 传统项目里,可能就需要手动启用事务管理。
此时测试发现,如果其中一个分支事务报错,其他都会回滚为之前的数据。分布式事务被seata控制住了。
6.3二阶提交协议
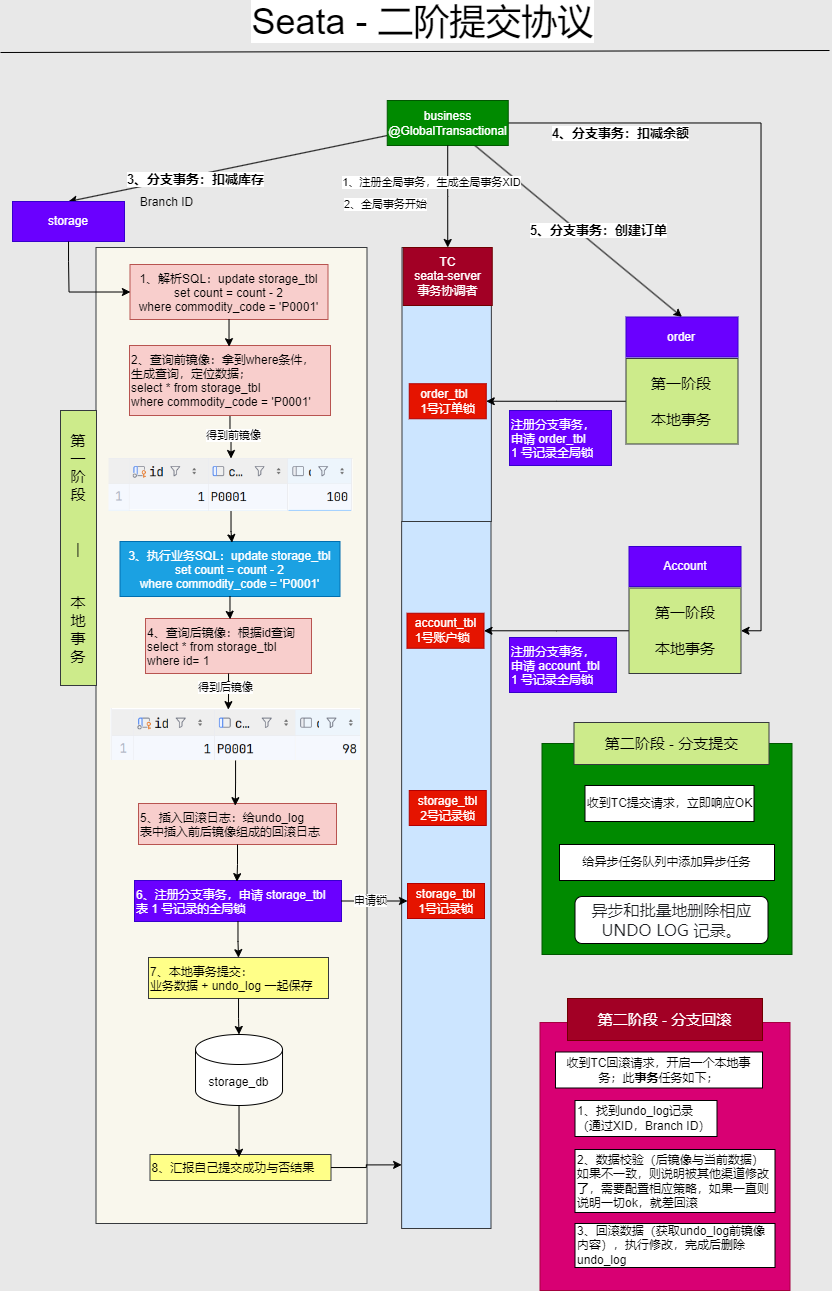
结合图中 Seata 的实现,二阶段提交协议(2PC)流程分 全局事务开启、分支事务执行(第一阶段)、全局事务决议(第二阶段) 三部分,详细拆解如下:
6.3.1阶段1
阶段 1:全局事务开启 + 分支事务执行(“预提交”)
由 TM(事务管理器,即标 @GlobalTransactional 的业务服务) 发起,核心是各分支事务先提交本地事务,但通过 undo_log 保留回滚能力。
1. 全局事务初始化(TM → TC)
- 触发:业务方法标记
@GlobalTransactional,调用时触发。 - 流程
- TM 向 TC(事务协调者) 发送
GlobalBeginRequest,申请开启全局事务。 - TC 生成唯一 XID(全局事务 ID),返回给 TM,贯穿整个分布式事务。
- TM 向 TC(事务协调者) 发送
2. 分支事务执行(各微服务 → RM → TC)
以 “扣减库存(storage)”“扣减余额(account)”“创建订单(order)” 为例,每个分支事务流程:
(1)执行本地业务 + 生成 undo_log
-
业务操作:执行 SQL(如
update storage_tbl set count=count-1 where commodity_code='P0001')。 -
生成
undo_log-
Seata 通过 数据源代理(
DataSourceProxy) 拦截 SQL,自动记录数据的前镜像(修改前的数据)**和**后镜像(修改后的数据),存入undo_log表。 -
示例(库存服务storage_tbl):
-- undo_log 表结构(简化) INSERT INTO undo_log (xid, branch_id, before_img, after_img) VALUES ('全局XID', '分支ID', '{"id":1,"commodity_code":"P0001","count":100}', -- 修改前'{"id":1,"commodity_code":"P0001","count":99}' -- 修改后 );
-
(2)注册分支事务(RM → TC)
- RM(资源管理器,各微服务的数据源代理) 向 TC 发送
BranchRegisterRequest,将本地事务注册为分支事务,绑定到 XID。 - TC 记录分支事务信息(如
storage_tbl分支绑定 XID、分支 ID),用于后续协调。
(3)提交本地事务(RM 操作)
- RM 执行 本地事务提交(业务 SQL +
undo_log写入),但此时数据对其他事务不可见(通过全局锁实现)。 - 目的:先释放本地数据库锁,提升并发;若后续需要回滚,用
undo_log恢复数据。
6.3.2阶段2
阶段 2:全局事务决议(“提交或回滚”)
由 TC 根据各分支事务状态,决定全局事务 “提交” 或 “回滚”,通知所有 RM 执行最终操作。
情况 1:全局事务提交
(所有分支成功)
- 触发:TM 方法正常执行完毕(无异常),向 TC 发送
GlobalCommitRequest。 - 流程
- TC 校验所有分支事务状态(均为 “已提交”)。
- TC 向所有 RM 发送
BranchCommitRequest,通知提交分支事务。 - RM 收到请求后:
- 删除
undo_log(数据已确认提交,无需回滚)。 - 释放全局锁,允许其他事务访问已修改数据。
- 删除
情况 2:全局事务回滚
(任意分支失败)
- 触发:TM 方法执行中抛出异常,或分支事务注册失败,向 TC 发送
GlobalRollbackRequest。 - 流程
- TC 向所有 RM 发送
BranchRollbackRequest,通知回滚分支事务。 - RM 收到请求后:
- 读取
undo_log,根据 “前镜像” 恢复数据(如库存回滚为count=100)。 - 删除
undo_log,释放全局锁。
- 读取
- TC 向所有 RM 发送
6.3.3细节与保障
-
全局锁(数据行级锁)
指的是由 Seata 事务协调者(TC)管理的,用于在分布式事务中保障数据一致性的逻辑锁。在分布式事务场景下,一个全局事务可能涉及多个微服务对不同数据库的操作,不同的全局事务可能会操作同一行数据。全局锁的存在就是为了防止在一个全局事务完成提交或回滚之前,其他全局事务对同一行数据进行修改,从而避免数据不一致的情况发生。
- 分支事务执行时,Seata 会对修改的数据行加全局锁(记录在 TC 中),防止其他事务并发修改,保障数据一致性。
- 例如:库存服务修改
storage_tbl某行后,其他服务需修改同一行时,会被全局锁阻塞,直到当前全局事务提交 / 回滚。
-
undo_log 的作用
- 记录数据修改前后的状态,是回滚的 “凭证”。
- 本地事务提交后,数据看似 “已改”,但因全局锁未释放,其他事务无法访问,保证了 “可回滚性”。
-
幂等性与重试
- TC 通知 RM 时,可能因网络问题导致重试,Seata 通过 XID + 分支 ID 保障操作幂等(重复请求不影响结果)。
6.3.4代码辅佐
两个调用分别打断点。
@GlobalTransactional
@Override
public void purchase(String userId, String commodityCode, int orderCount) {//1. 扣减库存storageFeignClient.deduct(commodityCode, orderCount);//2. 创建订单orderFeignClient.create(userId, commodityCode, orderCount);
}
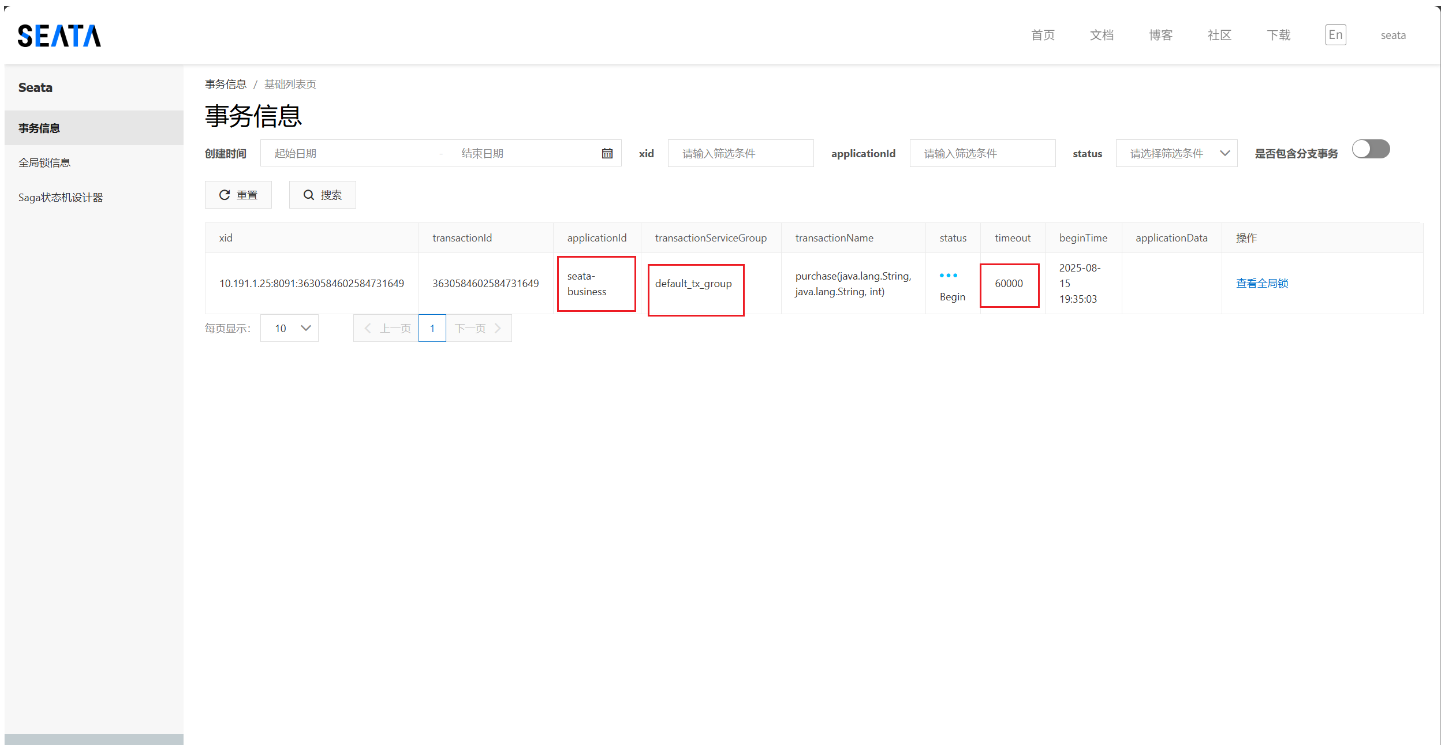
storageFeignClient处的断点。可以看到这里显示了一条事务记录,意味着当前开启了一个全局事务。在 Seata 中,XID(Global Transaction ID,全局事务 ID )。且此时还没有全局锁,因为分支事务还没有执行。
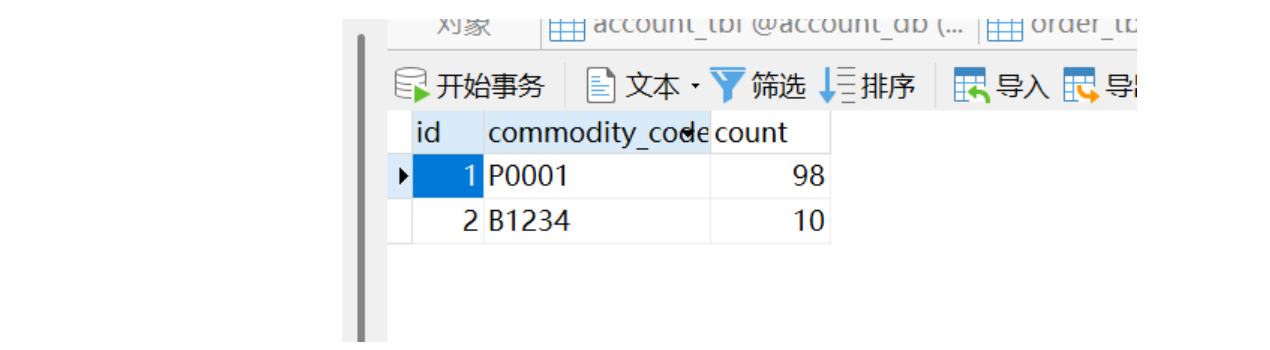
orderFeignClient处的断点,此时storage_db数据库已经修改完数据,也就是提交完本地事务了,且undo_log也应该记录了前后镜像。可以看到数据以变更
这是undo_log表记录的数据,其中信息beforeImage(前镜像)和afterImage(后镜像)就是分别记录了更改前后的数据。并且此时对应的全局锁也出现了。pk=1 表示对应数据库表中数据行的主键值为 1 ,是定位被锁定数据行的关键标识,也就是主键primary key。
{"@class": "org.apache.seata.rm.datasource.undo.BranchUndoLog","xid": "10.191.1.25:8091:3630584602584731652","branchId": 3630584602584731653,"sqlUndoLogs": ["java.util.ArrayList",[{"@class": "org.apache.seata.rm.datasource.undo.SQLUndoLog","sqlType": "UPDATE","tableName": "storage_tbl","beforeImage": {"@class": "org.apache.seata.rm.datasource.sql.struct.TableRecords","tableName": "storage_tbl","rows": ["java.util.ArrayList",[{"@class": "org.apache.seata.rm.datasource.sql.struct.Row","fields": ["java.util.ArrayList",[{"@class": "org.apache.seata.rm.datasource.sql.struct.Field","name": "count","keyType": "NULL","type": 4,"value": 100},{"@class": "org.apache.seata.rm.datasource.sql.struct.Field","name": "id","keyType": "PRIMARY_KEY","type": 4,"value": 1}]]}]]},"afterImage": {"@class": "org.apache.seata.rm.datasource.sql.struct.TableRecords","tableName": "storage_tbl","rows": ["java.util.ArrayList",[{"@class": "org.apache.seata.rm.datasource.sql.struct.Row","fields": ["java.util.ArrayList",[{"@class": "org.apache.seata.rm.datasource.sql.struct.Field","name": "count","keyType": "NULL","type": 4,"value": 98},{"@class": "org.apache.seata.rm.datasource.sql.struct.Field","name": "id","keyType": "PRIMARY_KEY","type": 4,"value": 1}]]}]]}}]]
}
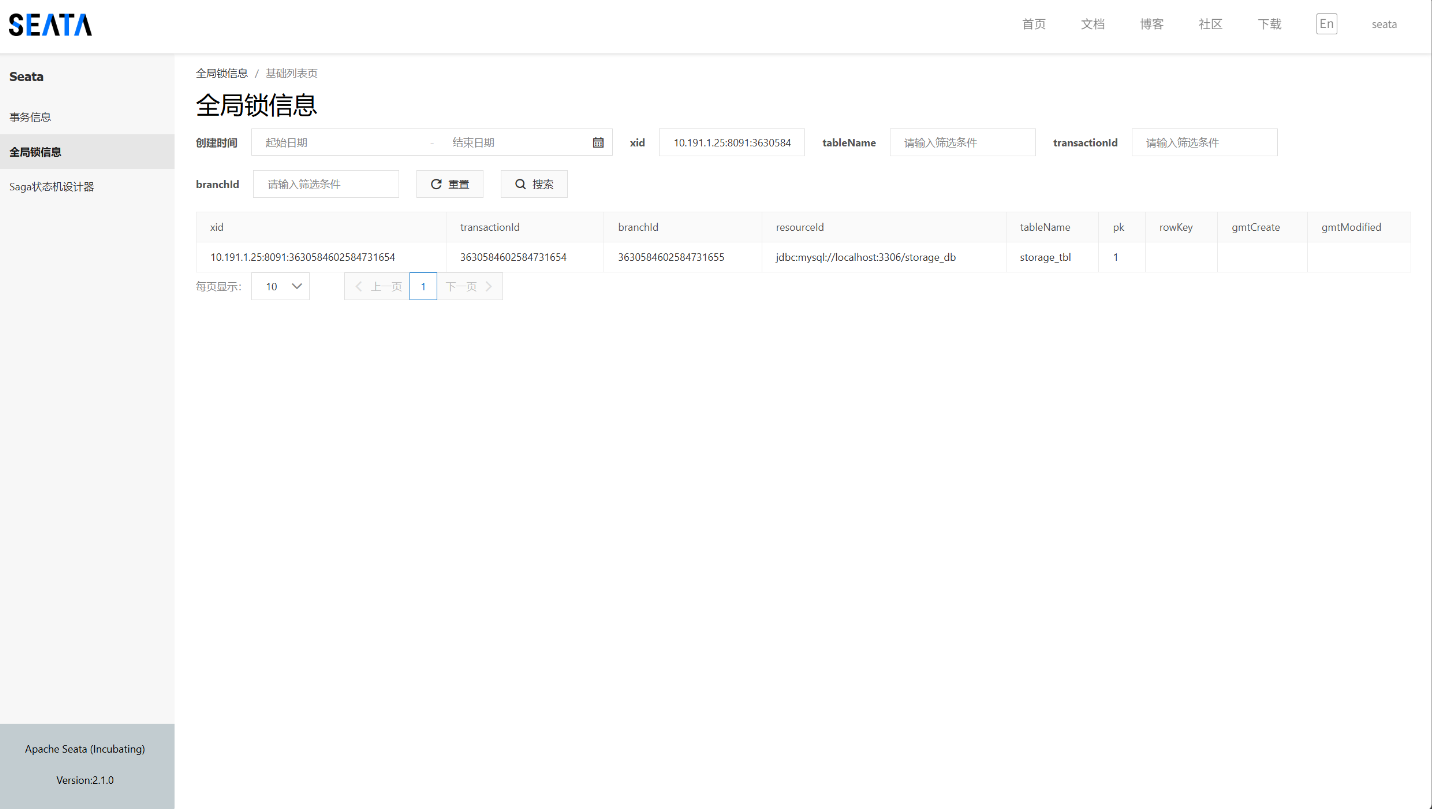
等到全局事务执行完毕,undo_log中记录的信息会被删除,全局锁也会被释放。
6.4四种事务模式
-
AT 模式(默认)
上面的就是AT模式。
无侵入式设计,业务代码无需修改,通过注解
@GlobalTransactional即可开启分布式事务。上面的二阶提交协议的过程就是该模式的过程。
-
XA模式
第一阶段不会提交数据,而是阻塞事务请求,在第二阶段确认提交再提交或者回滚。全局锁+MySQL行锁在第一阶段就开启,事务一开始就用阻塞模式,性能差。AT和XA区别是AT第一阶段执行完SQL释放行锁,XA是到第二阶段才提交SQL导致行锁从开始到最后,阻塞时间长性能差。但二者都是一直持有seata的全局锁的。而且,长时间的锁持有也增加了死锁发生的可能性。对于其他事务而言,虽然在全局事务完成前,受 Seata 全局锁的限制不能修改被锁定的数据,但它们可以进行普通的查询操作(根据隔离级别而定),而且不会因长时间等待 MySQL 行级锁而被阻塞,从而提升了系统整体的并发性能 。
-
TCC模式:
主要是广义上的事务,需要写侵入式的代码。举例业务需要三个事务,一个事务改数据库,一个发短信,一个发邮件,这就用AT和XA行不通了,无法回滚,如果全局事务失败,只能进行补偿性操作,例如再发邮件和短信提醒对方扣款失败或者订单失败等。也就是各阶段的代码自己实现,可已自定义在回滚时再执行额外的代码。
-
saga模式:
用于长事务,一时半会执行不完的事务。例如请假审批,其他模式都用了锁,如果长期锁在那是对系统是非常大的阻塞。saga是基于消息队列做的,后续有替代方案,所以这个几乎不用。
简单说,Seata 不同模式是为了覆盖 “强一致 - 最终一致”“DB 事务 - 异构事务” 的不同需求,实际项目里优先用 AT(适配 80% 场景),特殊场景再选 TCC/XA,。