自定义数据集(pytorchhuggingface)
自定义数据集(pytorch&huggingface)
- 1、Pytorch数据集
- 3.1 加载已有数据集格式
- 3.2 自定义数据集
- 3.3 变换(transforms)
- 3.4 示例
- 2、Hugging face数据集
- 1.与Pytorch数据集相似之处
- 2.示例
- 3. datasets 数据集
- 1.load_dataset 加载数据集
- 2.dataset.map 预处理
- 3. 获取数据集信息
- 4.获取数据集的子集Splits&Configurations
- 5、Stream 迭代对象
- 6、案例
- 7、预处理
- 4.数据/模型下载
- 1 .下载位置(离线/本地加载)
- 缓存设置
- 离线模式
- 2. 镜像下载
1、Pytorch数据集
参考:
https://pytorch.ac.cn/tutorials/beginner/basics/data_tutorial.html
https://pytorch.ac.cn/tutorials/beginner/basics/quickstart_tutorial.html
https://github.com/pytorch/tutorials/blob/main/beginner_source/basics/data_tutorial.py
https://pytorch.ac.cn/tutorials/beginner/nn_tutorial.html#mnist-data-setup
数据集:
https://pytorch.ac.cn/vision/stable/datasets.html
PyTorch 提供特定领域的库,例如 TorchText、TorchVision 和 TorchAudio,所有这些库都包含数据集。在本教程中,我们将使用 TorchVision 数据集。
torchvision.datasets 模块包含许多真实世界视觉数据的 Dataset 对象,例如 CIFAR、COCO(完整列表在此)。在本教程中,我们使用 FashionMNIST 数据集。每个 TorchVision Dataset 都包含两个参数:transform 和 target_transform,分别用于修改样本和标签。
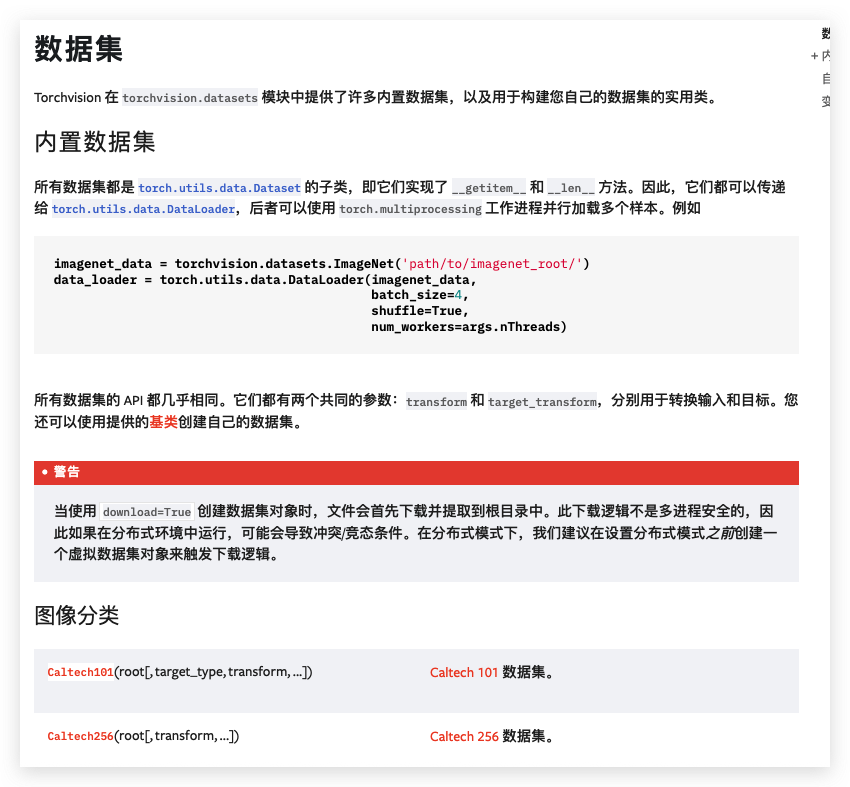
3.1 加载已有数据集格式
处理数据样本的代码可能会变得杂乱且难以维护;理想情况下,我们希望将数据集代码与模型训练代码解耦,以提高可读性和模块化。PyTorch 提供了两种数据原语:torch.utils.data.DataLoader 和 torch.utils.data.Dataset,它们允许您使用预加载的数据集以及您自己的数据。Dataset 存储样本及其对应的标签,而 DataLoader 则在 Dataset 周围封装了一个迭代器,以便于访问样本。
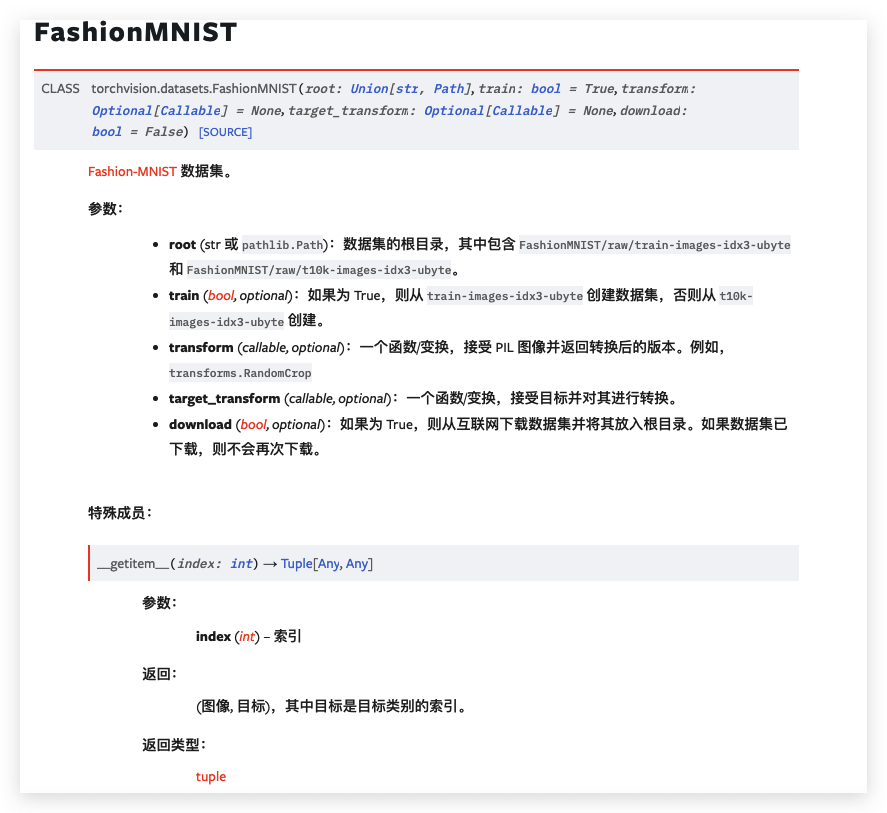
PyTorch 领域库提供了许多预加载的数据集(例如 FashionMNIST),这些数据集继承自 torch.utils.data.Dataset 并实现了特定于特定数据的功能。它们可用于原型设计和模型基准测试。您可以在此处找到它们:图像数据集、文本数据集和音频数据集
代码参考:
-
Dataset
我们使用以下参数加载 FashionMNIST Datasettraining_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(), )例如: import torch from torch.utils.data import Dataset from torchvision import datasets from torchvision.transforms import ToTensor import matplotlib.pyplot as plttraining_data = datasets.FashionMNIST(root="/Users/umr/MyData/vspro/data_set",train=True,download=True,transform=ToTensor() )test_data = datasets.FashionMNIST(root="/Users/umr/MyData/vspro/data_set",train=False,download=True,transform=ToTensor() )# 返回的格式: return image, labelroot是下载到的文件夹
train 是否是训练数据, 否则就是测试数据
download是否要进行下载root 是训练/测试数据存储的路径,
train 指定训练或测试数据集,
download=True 会在 root 路径下数据不存在时从互联网下载。
transform 和 target_transform 指定特征和标签变换使用 DataLoaders 准备数据进行训练
Dataset 一次检索一个样本的数据集特征和标签。在训练模型时,我们通常希望以“迷你批量”的形式传递样本,在每个 epoch 重新打乱数据以减少模型过拟合,并使用 Python 的 multiprocessing 来加速数据检索。DataLoader 是一个迭代器,它通过简单的 API 为我们抽象了这种复杂性。
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True) -
遍历 DataLoader
我们已将数据集加载到 DataLoader 中,并可以根据需要遍历数据集。下面的每次迭代都会返回一批 train_features 和 train_labels(分别包含 batch_size=64 个特征和标签)。因为我们指定了 shuffle=True,所以在遍历所有批量后,数据会被打乱(如需对数据加载顺序进行更精细的控制,请参阅采样器 (Samplers))。# Display image and label. train_features, train_labels = next(iter(train_dataloader)) print(f"Feature batch shape: {train_features.size()}") print(f"Labels batch shape: {train_labels.size()}") img = train_features[0].squeeze() label = train_labels[0] plt.imshow(img, cmap="gray") plt.show() print(f"Label: {label}")
3.2 自定义数据集
为您的文件创建自定义数据集
自定义 Dataset 类必须实现三个函数:init、len 和 getitem。请看这个实现;FashionMNIST 图像存储在目录 img_dir 中,而它们的标签则单独存储在 CSV 文件 annotations_file 中。
在接下来的部分,我们将详细介绍这些函数中的每一个。
#################################################################
# Creating a Custom Dataset for your files
# ---------------------------------------------------
#
# A custom Dataset class must implement three functions: `__init__`, `__len__`, and `__getitem__`.
# Take a look at this implementation; the FashionMNIST images are stored
# in a directory ``img_dir``, and their labels are stored separately in a CSV file ``annotations_file``.
#
# In the next sections, we'll break down what's happening in each of these functions.import os
import pandas as pd
from torchvision.io import read_imageclass CustomImageDataset(Dataset):def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transformdef __len__(self):return len(self.img_labels)def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path)label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, labelinit
init 函数在实例化 Dataset 对象时运行一次。我们初始化包含图像的目录、标注文件以及两个变换(将在下一节详细介绍)。
labels.csv 文件如下所示
tshirt1.jpg, 0
tshirt2.jpg, 0
......
ankleboot999.jpg, 9
len
len 函数返回数据集中样本的数量。
示例
def __len__(self):return len(self.img_labels)
getitem
getitem 函数加载并返回给定索引 idx 处的数据集样本。根据索引,它确定图像在磁盘上的位置,使用 read_image 将其转换为张量,从 self.img_labels 中的 csv 数据检索相应标签,对其调用变换函数(如果适用),并以元组形式返回张量图像和相应标签。
return image, label
3.3 变换(transforms)
数据并不总是以机器学习算法训练所需的最终处理形式出现。我们使用 变换(transforms) 对数据进行一些处理,使其适合训练。
所有 TorchVision 数据集都有两个参数 -transform 用于修改特征,target_transform 用于修改标签 - 它们接受包含变换逻辑的可调用对象。 torchvision.transforms 模块提供了几个常用的现成变换。
FashionMNIST 特征采用 PIL Image 格式,标签是整数。为了训练,我们需要将特征转换为归一化张量,将标签转换为独热编码张量。为了实现这些变换,我们使用 ToTensor 和 Lambda。
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambdads = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
3.4 示例
在 PyTorch 中,自定义数据集通常是通过继承 torch.utils.data.Dataset 来实现的。你需要至少实现两个方法:__len__ 和 __getitem__。我给你一个详细示例,并解释每一步。
1️⃣ 基本模板
import torch
from torch.utils.data import Datasetclass MyDataset(Dataset):def __init__(self, data, labels, transform=None):"""初始化数据集Args:data (array-like 或 tensor): 输入数据labels (array-like 或 tensor): 标签transform (callable, optional): 可选的预处理操作"""self.data = dataself.labels = labelsself.transform = transformdef __len__(self):# 返回数据集大小return len(self.data)def __getitem__(self, idx):# 获取第 idx 个样本sample = self.data[idx]label = self.labels[idx]# 如果有 transform,则应用if self.transform:sample = self.transform(sample)return sample, label
2️⃣ 使用示例
from torch.utils.data import DataLoader
import numpy as np# 构造假数据
X = np.random.randn(100, 10) # 100 个样本,每个样本 10 维
y = np.random.randint(0, 2, size=(100,)) # 0 或 1 标签# 创建数据集
dataset = MyDataset(X, y)# 创建 DataLoader(用于批训练)
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)# 迭代数据
for batch_X, batch_y in dataloader:print(batch_X.shape, batch_y.shape)
输出大概是:
torch.Size([16, 10]) torch.Size([16])
3️⃣ 常见扩展
- 数据增强 / 预处理
可以在transform中使用torchvision.transforms或自定义函数。
from torchvision import transformstransform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=0, std=1)
])dataset = MyDataset(X, y, transform=transform)
- 处理时间序列或序列数据
如果你做股票或文本,可以把每个样本的序列长度固定,然后返回(seq_tensor, label)。
class StockDataset(Dataset):def __init__(self, ohlcv_data, seq_len=30):self.data = ohlcv_dataself.seq_len = seq_lendef __len__(self):return len(self.data) - self.seq_lendef __getitem__(self, idx):x = self.data[idx:idx+self.seq_len]y = self.data[idx+self.seq_len] # 下一个时间点的标签return torch.tensor(x, dtype=torch.float32), torch.tensor(y, dtype=torch.float32)
💡 总结:
Dataset用于定义“如何获取单个样本”DataLoader用于批量读取、打乱和并行加载- 可结合
transform实现数据增强或归一化
如果你愿意,我可以帮你写一个 完整的自定义股票时间序列数据集,直接可以用于训练 PPO 或 LSTM/Transformer 模型的 PyTorch 代码。
你想让我写吗?
2、Hugging face数据集
1.与Pytorch数据集相似之处
下面是 Hugging Face 自定义数据集与 PyTorch 数据集的相似之处对比表格:
| 特性 | PyTorch Dataset | Hugging Face Dataset | 相似点说明 |
|---|---|---|---|
| 数据抽象方式 | 继承 torch.utils.data.Dataset,实现 __len__ 和 __getitem__ | 使用 datasets.Dataset,可以从字典、DataFrame、CSV/JSON 文件创建 | 都将数据封装成“样本集合”,每个样本可通过索引访问 |
| 样本获取 | __getitem__(idx) 返回单个样本 (features, label) | dataset[idx] 返回单个样本字典 {feature: ..., label: ...} | 都允许用户定义如何获取单个样本及样本结构 |
| 批处理与迭代 | 使用 DataLoader 支持批量读取、打乱、并行加载 | 可通过 set_format("torch") 转为 PyTorch Tensor,再用 DataLoader 批量训练 | 都支持批量训练和与 PyTorch 训练循环无缝集成 |
| 数据预处理/变换 | 可通过 transform 对每个样本做变换 | 使用 map() 对数据集批量处理 | 都支持自定义样本级或批量的预处理/特征转换 |
| 灵活性 | 可处理任意类型的数据:图像、文本、时间序列 | 可处理多种类型数据,尤其擅长 NLP、时间序列、Transformer 模型输入 | 都高度灵活,可适应不同类型的深度学习任务 |
| 索引访问 | 支持通过索引访问单个样本 | 支持通过索引访问单个样本 | 样本获取方式一致 |
| 与 PyTorch 集成 | 天然支持 | 可通过 set_format("torch") 完美集成 | 都能无缝结合 PyTorch 训练流程 |
在 Hugging Face 的生态里,自定义数据集主要通过 datasets 库来实现(不是直接用 PyTorch 的 Dataset)。你可以从本地数据、Python 列表、Pandas DataFrame 或 CSV/JSON 文件创建数据集。下面我详细讲几个常用方法。
1️⃣ 从 Python 列表/字典创建数据集
from datasets import Dataset# 假数据
data = {"text": ["Hello world", "I love Hugging Face", "PyTorch is great"],"label": [0, 1, 0]
}# 创建 Dataset 对象
dataset = Dataset.from_dict(data)# 查看数据
print(dataset)
print(dataset[0])
输出示例:
Dataset({features: ['text', 'label'],num_rows: 3
})
{'text': 'Hello world', 'label': 0}
2️⃣ 从 Pandas DataFrame 创建
import pandas as pd
from datasets import Datasetdf = pd.DataFrame({"text": ["sample1", "sample2", "sample3"],"label": [0, 1, 0]
})dataset = Dataset.from_pandas(df)
print(dataset)
3️⃣ 从 CSV/JSON 文件创建
from datasets import load_dataset# CSV
dataset = load_dataset("csv", data_files="data.csv")# JSON
dataset = load_dataset("json", data_files="data.json")
data_files可以是字符串,也可以是字典{"train": "train.csv", "test": "test.csv"}。- 如果文件很大,
datasets会自动支持按需加载。
4️⃣ 自定义处理逻辑(映射 transform)
map类似pytorch transform
Hugging Face 数据集支持 map() 方法做数据处理,例如分词、归一化:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")def tokenize(batch):return tokenizer(batch["text"], padding="max_length", truncation=True)tokenized_dataset = dataset.map(tokenize, batched=True)
5️⃣ 转换为 PyTorch Dataset
如果你要用 PyTorch 训练,可以直接:
import torchtokenized_dataset.set_format("torch", columns=["input_ids", "attention_mask", "label"])# DataLoader
from torch.utils.data import DataLoader
dataloader = DataLoader(tokenized_dataset, batch_size=16, shuffle=True)
💡 总结
- Hugging Face
datasets.Dataset更高层,功能比 PyTorch Dataset 强大:支持批量处理、懒加载、映射、缓存。 - 可以从字典、DataFrame、CSV/JSON 文件创建。
- 通过
map()做自定义预处理。 - 用
set_format("torch")方便与 PyTorch 集成。
如果你需要,我可以帮你写一个 完整的 Hugging Face 自定义股票数据集示例,直接返回 OHLCV 时间序列和标签,并支持批量加载和 PyTorch 训练。
你想让我写吗?
示例:
好的,我帮你写一个 完整的 Hugging Face 自定义股票数据集示例,可以直接用 PyTorch DataLoader 训练 LSTM/Transformer 类模型。假设我们有 OHLCV 数据,每个样本是过去 seq_len 天的序列,标签是下一个时间步的涨跌或价格。
import pandas as pd
import numpy as np
from datasets import Dataset
from torch.utils.data import DataLoader
import torch# -------------------------
# 1️⃣ 构造假股票数据(OHLCV)
# -------------------------
num_days = 200
data = {"open": np.random.rand(num_days) * 100,"high": np.random.rand(num_days) * 100,"low": np.random.rand(num_days) * 100,"close": np.random.rand(num_days) * 100,"volume": np.random.randint(1000, 5000, size=num_days)
}
df = pd.DataFrame(data)# -------------------------
# 2️⃣ 定义序列化函数
# -------------------------
seq_len = 10 # 每个样本用过去 10 天数据
def create_sequences(df, seq_len):sequences = []labels = []for i in range(len(df) - seq_len):seq = df.iloc[i:i+seq_len].values.astype(np.float32)label = df.iloc[i+seq_len]["close"].astype(np.float32) # 下一个收盘价sequences.append(seq)labels.append(label)return {"sequence": sequences, "label": labels}dataset_dict = create_sequences(df, seq_len)# -------------------------
# 3️⃣ 创建 Hugging Face Dataset
# -------------------------
dataset = Dataset.from_dict(dataset_dict)
print(dataset)# -------------------------
# 4️⃣ 转换为 PyTorch 格式
# -------------------------
dataset.set_format(type="torch", columns=["sequence", "label"])# -------------------------
# 5️⃣ DataLoader
# -------------------------
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)# -------------------------
# 6️⃣ 测试迭代
# -------------------------
for batch in dataloader:x, y = batch["sequence"], batch["label"]print(x.shape, y.shape) # x: [batch, seq_len, features], y: [batch]break
✅ 说明
seq_len可调,决定每个样本使用多少天历史数据。sequence是[seq_len, features],适合 LSTM/Transformer 输入。label可以换成涨跌(next_close > today_close)或其他指标。dataset.set_format("torch")后可直接用 PyTorchDataLoader。- 可以用
map()做归一化或特征工程。
我可以帮你升级这个例子,加上 标准化、涨跌标签、以及 train/test 划分,直接可用在 PPO 或 LSTM/Transformer 训练里。
你希望我加吗?
2.示例
下面给你一个 完整的使用示例,展示如何从 Hugging Face 自定义股票时间序列数据集创建 PyTorch DataLoader,然后进行迭代训练。示例中包含数据构造、序列化、Hugging Face Dataset 创建、转换为 PyTorch Tensor、以及 DataLoader 使用。
import pandas as pd
import numpy as np
from datasets import Dataset
from torch.utils.data import DataLoader
import torch# -------------------------
# 1️⃣ 构造假股票数据(OHLCV)
# -------------------------
num_days = 100
data = {"open": np.random.rand(num_days) * 100,"high": np.random.rand(num_days) * 100,"low": np.random.rand(num_days) * 100,"close": np.random.rand(num_days) * 100,"volume": np.random.randint(1000, 5000, size=num_days)
}
df = pd.DataFrame(data)# -------------------------
# 2️⃣ 序列化函数(生成过去 seq_len 天的序列作为样本)
# -------------------------
seq_len = 10
def create_sequences(df, seq_len):sequences = []labels = []for i in range(len(df) - seq_len):seq = df.iloc[i:i+seq_len].values.astype(np.float32) # 过去 seq_len 天数据label = df.iloc[i+seq_len]["close"].astype(np.float32) # 下一个收盘价作为标签sequences.append(seq)labels.append(label)return {"sequence": sequences, "label": labels}dataset_dict = create_sequences(df, seq_len)# -------------------------
# 3️⃣ 创建 Hugging Face Dataset
# -------------------------
dataset = Dataset.from_dict(dataset_dict)
print(dataset) # 查看信息
print(dataset[0]) # 查看第一个样本# -------------------------
# 4️⃣ 转换为 PyTorch Tensor 格式
# -------------------------
dataset.set_format(type="torch", columns=["sequence", "label"])# -------------------------
# 5️⃣ 创建 DataLoader
# -------------------------
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)# -------------------------
# 6️⃣ 测试迭代
# -------------------------
for batch in dataloader:x, y = batch["sequence"], batch["label"]print("x shape:", x.shape) # [batch, seq_len, features]print("y shape:", y.shape) # [batch]break
✅ 输出示例
x shape: torch.Size([16, 10, 5])
y shape: torch.Size([16])
x是[batch, seq_len, features],适合 LSTM/Transformer 输入y是[batch],可以用作回归或分类标签
7️⃣ 可扩展功能
- 特征归一化
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
df[['open','high','low','close','volume']] = scaler.fit_transform(df[['open','high','low','close','volume']])
- 涨跌标签
labels = (df['close'].shift(-1) > df['close']).astype(int)[:-1]
- train/test 划分
train_size = int(0.8 * len(dataset))
train_dataset = dataset.select(range(train_size))
test_dataset = dataset.select(range(train_size, len(dataset)))
如果需要,我可以帮你写一个 完整 Hugging Face 股票数据集类,直接封装成可重复使用的 Python 类,支持序列长度、归一化、涨跌标签和 train/test 划分,一步创建 DataLoader。
你希望我写吗?
好的,我们可以用 Hugging Face 的 transformers 库把上面示例数据训练成一个简单的 GPT-2 回归/预测模型。因为 GPT-2 原本是用于文本生成的,我们需要稍作调整,把序列化的股票 OHLCV 时间序列当作“序列特征”,然后训练 GPT-2 来预测下一个时间步的收盘价。下面给出完整示例:
import torch
from torch.utils.data import DataLoader
from datasets import Dataset
from transformers import GPT2Config, GPT2LMHeadModel, Trainer, TrainingArguments
import pandas as pd
import numpy as np# -------------------------
# 1️⃣ 构造假股票数据
# -------------------------
num_days = 200
data = {"open": np.random.rand(num_days) * 100,"high": np.random.rand(num_days) * 100,"low": np.random.rand(num_days) * 100,"close": np.random.rand(num_days) * 100,"volume": np.random.randint(1000, 5000, size=num_days)
}
df = pd.DataFrame(data)# -------------------------
# 2️⃣ 序列化函数
# -------------------------
seq_len = 10
def create_sequences(df, seq_len):sequences = []labels = []for i in range(len(df) - seq_len):seq = df.iloc[i:i+seq_len].values.astype(np.float32).flatten() # GPT2 输入一维序列label = df.iloc[i+seq_len]["close"].astype(np.float32)sequences.append(seq)labels.append(label)return {"input_ids": sequences, "labels": labels}dataset_dict = create_sequences(df, seq_len)
dataset = Dataset.from_dict(dataset_dict)
dataset.set_format(type="torch", columns=["input_ids", "labels"])# -------------------------
# 3️⃣ GPT-2 配置与模型
# -------------------------
# 定义小型 GPT2 模型
config = GPT2Config(vocab_size=1, # 对数值序列,vocab_size 可以设 1n_embd=64, # embedding sizen_layer=2,n_head=2
)
model = GPT2LMHeadModel(config)# -------------------------
# 4️⃣ DataLoader
# -------------------------
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)# -------------------------
# 5️⃣ 自定义 Trainer Dataset
# -------------------------
class StockDataset(torch.utils.data.Dataset):def __init__(self, hf_dataset):self.dataset = hf_datasetdef __len__(self):return len(self.dataset)def __getitem__(self, idx):return {"input_ids": self.dataset[idx]["input_ids"],"labels": self.dataset[idx]["labels"]}train_dataset = StockDataset(dataset)# -------------------------
# 6️⃣ 定义训练参数
# -------------------------
training_args = TrainingArguments(output_dir="./gpt2-stock",per_device_train_batch_size=16,num_train_epochs=5,logging_steps=5,save_steps=50,learning_rate=1e-3,weight_decay=0.01,remove_unused_columns=False
)# -------------------------
# 7️⃣ Trainer
# -------------------------
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset
)# -------------------------
# 8️⃣ 开始训练
# -------------------------
trainer.train()# -------------------------
# 9️⃣ 测试预测
# -------------------------
model.eval()
sample_seq = torch.tensor(dataset[0]["input_ids"]).unsqueeze(0) # [1, seq_len*features]
with torch.no_grad():output = model(sample_seq)pred = output.logits[0, -1].item()print("预测下一个收盘价:", pred)
⚡ 说明
-
数据处理
- GPT-2 原本处理 token 序列,这里把
[seq_len, 5]的 OHLCV 数据 flatten 成一维序列。
- GPT-2 原本处理 token 序列,这里把
-
模型
- 用小型 GPT-2 (
n_layer=2, n_head=2, n_embd=64) 训练,避免显存过大。
- 用小型 GPT-2 (
-
训练
- 使用 Hugging Face
Trainer简化训练流程。
- 使用 Hugging Face
-
预测
- 输出的
logits最后一个位置对应下一个时间步的预测值。
- 输出的
3️⃣ DataLoader 与 Trainer
你手动写了 StockDataset,其实可以直接用 Hugging Face Dataset 并 set_format("torch"),Trainer 就可以直接使用,不必再封装 PyTorch Dataset。
示例:
dataset.set_format(type="torch", columns=["input_ids", "labels"])trainer = Trainer(model=model,args=training_args,train_dataset=dataset # 直接传 HF Dataset
)
如果你愿意,我可以帮你写一个 更合理的 GPT-2 股票训练版本,
- 支持多维 OHLCV 直接作为 embedding 输入
- 使用回归头而不是 LM Head
- 支持 train/test 划分和归一化
这样训练会更稳定,预测也更准确。
你希望我写吗?
3. datasets 数据集
https://huggingface.co/docs/datasets/package_reference/loading_methods
https://github.com/huggingface/datasets?tab=readme-ov-file
1.load_dataset 加载数据集
设置trust_remote_code=True为使用带有加载脚本的数据集
加载下载好得本地数据集报错:dataset = load_dataset(‘dataid’)
报错:加载本地时报错datasets.exceptions.DatasetGenerationError: An error occurred while generating the dataset
需要使用streaming=True参数,或降低版本。
dataset = load_dataset(‘dataid’,streaming=True)
它适用于 2.13.2 版,之后的版本则不行。
它适用于最后一个版本 (2.14.6),load_dataset 的参数 streaming=true。
它适用于 Colab (2.14.6),但不适用于 jupyter notebook。
希望它能有所帮助。https://blog.csdn.net/weixin_39589455/article/details/136068466
dataset = load_dataset('./local_model',streaming=True)
2.dataset.map 预处理
使用对象的map对个item进行处理,和map,fillter一样。通过函数来进行增强。
创建一个函数用tokenier对数据进行处理,比如截断、填充文本等为整齐的矩形张量。
官方例子:https://huggingface.co/docs/datasets/quickstart#nlp
>>> from datasets import load_dataset>>> ds = load_dataset("rotten_tomatoes")>>> def add_prefix(example):... example["text"] = "Review: " + example["text"]... return example>>> ds = ds.map(add_prefix)>>> ds["train"][0:3]["text"]['Review: the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .','Review: the gorgeously elaborate continuation of " the lord of the rings " trilogy is so huge that a column of words cannot adequately describe co-writer/director peter jackson\'s expanded vision of j . r . r . tolkien\'s middle-earth .',
'Review: effective but too-tepid biopic']# process a batch of examples>>> ds = ds.map(lambda example: tokenizer(example["text"]), batched=True)# set number of processors>>> ds = ds.map(add_prefix, num_proc=4)
3. 获取数据集信息
#stream返回的迭代对象获取不了属性
官方:https://huggingface.co/docs/datasets/v2.20.0/en/package_reference/main_classes#datasets.DatasetDict
-
1 dataset builder不用加载数据集,直接获取信息
https://huggingface.co/docs/datasets/load_hub
https://huggingface.co/docs/datasets/v2.20.0/en/package_reference/loading_methods#datasets.load_dataset_builder
官方使用DatasetBuilder:https://huggingface.co/docs/datasets/package_reference/builder_classes
数据集构建器可用于检查构建数据集所需的一般信息(缓存目录、配置、数据集信息等),而无需下载数据集本身。
dataset builder返回的时DatasetBuilder类。DatasetBuilder有 3 个主要方法:
- DatasetBuilder.info:记录数据集,包括特征名称、类型、形状、版本、分割、引用等。Documents the dataset, including feature names, types, shapes, version, splits, citation, etc.
- DatasetBuilder.download_and_prepare():下载源数据并将其写入磁盘。
- DatasetBuilder.as_dataset():生成数据集。
一些数据集通过定义BuilderConfigDatasetBuilder子类并在构造时接受配置对象(或名称)来公开数据集的多个变体。可配置数据集在中公开一组预定义的配置。DatasetBuilder.builder_configs()from datasets import load_dataset_builder from datasets import load_dataset# ds_builder = load_dataset_builder("rotten_tomatoes") ds_builder = load_dataset_builder('./model/knowledgator/events_classification_biotech')# 数据集,包括特征名称、类型、形状、版本、分割、引用等 print('描述:',ds_builder.info.description) #数据集的描述 print('特点:',ds_builder.info.features) #每个字段的数据类型说明 print('特点:',ds_builder.info.splits) # print('特点:',ds_builder.info.citation) print('特点:',ds_builder.info.dataset_size)
-
2load_dataset加载数据集,并获取信息(推荐)
https://huggingface.co/docs/datasets/load_hub
官方:https://huggingface.co/docs/datasets/v2.20.0/en/package_reference/main_classes#datasets.DatasetDict- Splits分割:Splits加载数据集的子集sub, 比如含有train and test子集,只获取其中某个。加载数据集split将返回一个Dataset对象:
load_dataset(“rotten_tomatoes”, split=“train”) - 如果你未指定split,🤗 Datasets 将返回DatasetDict对象:
load_dataset(“rotten_tomatoes”)ds = dataset = load_dataset('./model/knowledgator/events_classification_biotech',num_proc=8) #stream返回的迭代对象获取不了属性 print('列:',ds.column_names) print('列:',ds.num_columns) print('列:',ds.cache_files) print('列:',ds.num_rows) print('列:',ds.shape)
- Splits分割:Splits加载数据集的子集sub, 比如含有train and test子集,只获取其中某个。加载数据集split将返回一个Dataset对象:
案例:
import os
# os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"#使用国内hf镜像
os.environ["HF_HOME"] = "./model" #模型保存路径
os.environ["HF_HUB_CACHE"] = "./cache"#模型保存路径
# os.environ["CUDA_VISIBLE_DEVICES"] = "2"
# os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"from datasets import load_dataset,load_dataset_builderprint('1、不加载获取信息:')
#不加载获取信息
ds_builder = load_dataset_builder('knowledgator/events_classification_biotech')
# 数据集,包括特征名称、类型、形状、版本、分割、引用等
print('描述:',ds_builder.info.description) #数据集的描述
print('特点:',ds_builder.info.features) #每个字段的数据类型说明
print('特点:',ds_builder.info.splits) #
print('特点:',ds_builder.info.citation)
print('特点:',ds_builder.info.dataset_size) print('2、加载后获取信息:')
# num_proc=8进程数, streaming=True,trust_remote_code=True
dataset = load_dataset('knowledgator/events_classification_biotech',num_proc=8)
#获取信息
#stream返回的迭代对象获取不了属性
# # 数据集,包括特征名称、类型、形状、版本、分割、引用等
print("数据结构:",dataset)
# print('数据:',dataset.data) #所有数据
print('数据1:',dataset['train'][1]) #所有数据
print('列:',dataset.column_names)
print('列:',dataset.num_columns)
print('列:',dataset.cache_files)
print('列:',dataset.num_rows)
print('列:',dataset.shape)print('3、获取分类:')
classes = [class_ for class_ in dataset['train'].features['label 1'].names if class_]
print(classes)
class2id = {class_:id for id, class_ in enumerate(classes)}
print(class2id)
id2class = {id:class_ for class_, id in class2id.items()}
print(id2class)4.获取数据集的子集Splits&Configurations
https://huggingface.co/docs/datasets/load_hub
- Splits分割:Splits加载数据集的子集sub, 比如含有train and test子集,只获取其中某个。加载数据集split将返回一个Dataset对象:
load_dataset(“rotten_tomatoes”, split=“train”) - Configurations不同语言子集:一些数据集包含多个子数据集。例如,MInDS-14数据集有多个子数据集,每个子数据集包含不同语言的音频数据。这些子数据集称为配置,您必须在加载数据集时明确选择一个。如果您不提供配置名称,🤗 数据集将引发ValueError并提醒您选择配置。
5、Stream 迭代对象
https://huggingface.co/docs/datasets/stream
当您在load_dataset()中将流参数设置为True时,将加载IterableDataset:
#stream返回的迭代对象获取不了属性,不能切片等操作
from datasets import load_datasetiterable_dataset = load_dataset("food101", split="train", streaming=True)
for example in iterable_dataset:print(example)break
6、案例
https://huggingface.co/blog/Valerii-Knowledgator/multi-label-classification
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"#使用国内hf镜像
os.environ["HF_HOME"] = "./model" #模型保存路径
os.environ["HF_HUB_CACHE"] = "./cache"#模型保存路径
os.environ["CUDA_VISIBLE_DEVICES"] = "6"
# os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"from datasets import load_dataset,load_dataset_builderprint('1、不加载获取信息:')
#不加载获取信息
ds_builder = load_dataset_builder('knowledgator/events_classification_biotech')
# 数据集,包括特征名称、类型、形状、版本、分割、引用等
print('描述:',ds_builder.info.description) #数据集的描述
print('特点:',ds_builder.info.features) #每个字段的数据类型说明
print('特点:',ds_builder.info.splits) #
print('特点:',ds_builder.info.citation)
print('特点:',ds_builder.info.dataset_size) print('2、加载后获取信息:')
# num_proc=8进程数, streaming=True,trust_remote_code=True
dataset = load_dataset('knowledgator/events_classification_biotech',num_proc=8)
# dataset = load_dataset('knowledgator/events_classification_biotech') #获取信息
#stream返回的迭代对象获取不了属性
# # 数据集,包括特征名称、类型、形状、版本、分割、引用等
print("数据结构:",dataset)
# print('数据:',dataset.data) #所有数据
print('数据1:',dataset['train'][-6:]) #所有数据
print('数据2:',dataset['test'][0:5]) #所有数据
print('列:',dataset.column_names)
print('列:',dataset.num_columns)
print('列:',dataset.cache_files)
print('列:',dataset.num_rows)
print('列:',dataset.shape)print('3、获取分类:')
classes = [class_ for class_ in dataset['train'].features['label 1'].names if class_]
print(classes)
class2id = {class_:id for id, class_ in enumerate(classes)}
print(class2id)
id2class = {id:class_ for class_, id in class2id.items()}
print(id2class)from transformers import AutoTokenizermodel_path = 'microsoft/deberta-v3-small'
tokenizer = AutoTokenizer.from_pretrained(model_path)def preprocess_function(example):
# print('样本',example)text = f"{example['title']}.\n{example['content']}"
# all_labels = example['all_labels'].split(', ')all_labels = example['all_labels']labels = [0. for i in range(len(classes))]for label in all_labels:label_id = class2id[label]labels[label_id] = 1.example = tokenizer(text, truncation=True)example['labels'] = labelsreturn exampletokenized_dataset = dataset.map(preprocess_function)print('预处理:',tokenized_dataset)# 填充padding
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)# 设置评估指标 transformers 4.42.3
import evaluate
import numpy as npclf_metrics = evaluate.combine(["accuracy", "f1", "precision", "recall"])def sigmoid(x):return 1/(1 + np.exp(-x))def compute_metrics(eval_pred):predictions, labels = eval_predpredictions = sigmoid(predictions)predictions = (predictions > 0.5).astype(int).reshape(-1)return clf_metrics.compute(predictions=predictions, references=labels.astype(int).reshape(-1))# references=labels.astype(int).reshape(-1) #方法中的
# print('修改维度:',references)from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainermodel = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=len(classes),id2label=id2class, label2id=class2id,problem_type = "multi_label_classification" )training_args = TrainingArguments(output_dir="my_awesome_model",learning_rate=2e-5,per_device_train_batch_size=3,per_device_eval_batch_size=3,num_train_epochs=1,weight_decay=0.01,evaluation_strategy="epoch",save_strategy="epoch",load_best_model_at_end=True,
)trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_dataset["train"],eval_dataset=tokenized_dataset["test"],tokenizer=tokenizer, data_collator=data_collator,compute_metrics=compute_metrics,
)trainer.train()7、预处理
在您可以在数据集上训练模型之前,数据需要被预处理为期望的模型输入格式。无论您的数据是文本、图像还是音频,它们都需要被转换并组合成批量的张量。🤗 Transformers 提供了一组预处理类来帮助准备数据以供模型使用。在本教程中,您将了解以下内容:
对于文本,使用分词器(Tokenizer)将文本转换为一系列标记(tokens),并创建tokens的数字表示,将它们组合成张量。
对于语音和音频,使用特征提取器(Feature extractor)从音频波形中提取顺序特征并将其转换为张量。
图像输入使用图像处理器(ImageProcessor)将图像转换为张量。
多模态输入,使用处理器(Processor)结合了Tokenizer和ImageProcessor或Processor。
4.数据/模型下载
1 .下载位置(离线/本地加载)
https://huggingface.co/docs/transformers/v4.53.3/zh/installation
https://zhuanlan.zhihu.com/p/663712983?s_r=0
缓存设置
预训练模型会被下载并本地缓存到 ~/.cache/huggingface/hub。这是由环境变量 TRANSFORMERS_CACHE 指定的默认目录。在 Windows 上,默认目录为 C:\Users\username.cache\huggingface\hub。你可以按照不同优先级改变下述环境变量,以指定不同的缓存目录。
环境变量(默认): HF_HUB_CACHE 或 TRANSFORMERS_CACHE。
环境变量 HF_HOME。
环境变量 XDG_CACHE_HOME + /huggingface。
除非你明确指定了环境变量 TRANSFORMERS_CACHE,🤗 Transformers 将可能会使用较早版本设置的环境变量 PYTORCH_TRANSFORMERS_CACHE 或 PYTORCH_PRETRAINED_BERT_CACHE。
Cache a model in a different directory by changing the path in the following shell environment variables (listed by priority).HF_HUB_CACHE or TRANSFORMERS_CACHE (default)
HF_HOME
XDG_CACHE_HOME + /huggingface (only if HF_HOME is not set)
Older versions of Transformers uses the shell environment variables PYTORCH_TRANSFORMERS_CACHE or PYTORCH_PRETRAINED_BERT_CACHE. You should keep these unless you specify the newer shell environment variable TRANSFORMERS_CACHE.
import osos.environ["HF_HUB_CACHE"] = "./hub" # 模型保存路径
os.environ["TRANSFORMERS_CACHE"] = "./hub"#模型保存路径
os.environ["HF_HOME"] = "./hub"#模型保存路径
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"#使用国内hf镜像from datasets import load_dataset
dataset = load_dataset('knowledgator/events_classification_biotech')
snapshot_download
huggingface 官方提供了snapshot_download 方法下载完整模型,参数众多、比较完善。相比下文另两个 python 方法,推荐 snapshot_download 方法来下载模型,支持断点续传、多线程、指定路径、配置代理、排除特定文件等功能。然而有两个缺点:https://zhuanlan.zhihu.com/p/663712983?s_r=0
1))该方法依赖于 transformers 库,而这个库是个开发用的库,对于自动化运维有点重;
2) 该方法调用比较复杂,参数较多,例如默认会检查用户缓存目录下是否已有对应模型,如已有则会创建符号链接,不理解的容易导致问题。外加需要配置代理。常见参数配置如下:
from huggingface_hub import snapshot_download
snapshot_download(repo_id="bigscience/bloom-560m",local_dir="/data/user/test",proxies={"https": "http://localhost:7890"},max_workers=8
)对于需要登录的模型,还需要两行额外代码:import huggingface_hub
huggingface_hub.login("HF_TOKEN") # token 从 https://huggingface.co/setting离线模式
🤗 Transformers 可以仅使用本地文件在防火墙或离线环境中运行。设置环境变量 HF_HUB_OFFLINE=1 以启用该行为。
通过设置环境变量 HF_DATASETS_OFFLINE=1 将 🤗 Datasets 添加至你的离线训练工作流程中。
例如,你通常会使用以下命令对外部实例进行防火墙保护的的普通网络上运行程序:
Copied
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en …
在离线环境中运行相同的程序:
Copied
HF_DATASETS_OFFLINE=1 HF_HUB_OFFLINE=1
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en …
现在脚本可以应该正常运行,而无需挂起或等待超时,因为它知道只应查找本地文件。
https://huggingface.co/docs/hub/datasets-downloading
https://zhuanlan.zhihu.com/p/663712983?s_r=0
2. 镜像下载
镜像下载:有很多数据库不支持镜像下载
使用镜像作为环境变量后部分数据在最新版 datasets 上无法正常下载,用代理。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"#使用国内hf镜像
os.environ["HF_HOME"] = "./model"#模型保存路径
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"from datasets import load_dataset
dataset = load_dataset('knowledgator/events_classification_biotech')
下载到本地:
指定位置可能会出问题,出问题用代理下载到默认路径排查.
方法一:
huggingface-cli设置保存位置位置
huggingface-cli download knowledgator/events_classification_biotech --repo-type dataset --cache-dir ./mycache --local-dir knowledgator/events_classification_biotech方法二:
代码中设置环境变量
os.environ["HF_HOME"] = "./model"#模型保存路径
dataset = load_dataset('knowledgator/events_classification_biotech')
#绝对路径也就可以,最好用相对的
#ds_builder = load_dataset_builder('./model/knowledgator/events_classification_biotech')
方法三:
保存成disk格式加载
import datasets
dataset=datasets.load_dataset("yelp_review_full",cache_dir='mypath\data\huggingfacedatasetscache')
dataset.save_to_disk('mypath\\data\\yelp_review_full_disk')
dataset=datasets.load_from_disk("mypath/datasets/yelp_full_review_disk")异常处理:
-
1、使用镜像作为环境变量后部分数据在最新版 datasets 上无法正常下载
https://github.com/padeoe/hf-mirror-site/issues/22
报错:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x8b in position 1: invalid start byte
把datasets换成2.14.6,还是不行。
用镜像不行,只能用代理下载。 -
2、加载下载好得本地数据集报错:dataset = load_dataset(‘dataid’)
加载本地时报错datasets.exceptions.DatasetGenerationError: An error occurred while generating the dataset
需要使用streaming=True参数,或降低版本。
它适用于 2.13.2 版,之后的版本则不行。
它适用于最后一个版本 (2.14.6),load_dataset 的参数 streaming=true。
它适用于 Colab (2.14.6),但不适用于 jupyter notebook。
希望它能有所帮助。 -
3、报错:datasets.exceptions.DatasetGenerationError: An error occurred while generating the dataset
不知道是哪个包版本问题,dataset版本都一样,换了个环境就可以了。。。可能是conda安装pytorch问题。具体无知。。。。 -
4、conda安装的环境和pip安装的有时不兼容,from transformers import DataCollatorWithPadding 报错:RuntimeError: Failed to import transformers.data.data_collator because of the following error (look up to see its traceback):可能时pytorch安装问题。