AAAI论文速递 | Transformer如何听声辨物,实现像素级分割新突破!
本文选自gongzhonghao【图灵学术SCI论文辅导】
关注我们,掌握更多顶会顶刊发文资讯
1.导读

1.1 论文基本信息
论文标题:AVSegFormer: Audio-Visual Segmentation with Transformer
作者:Shengyi Gao, Zhe Chen, Guo Chen, Wenhai Wang, Tong Lu
作者单位:南京大学新型软件技术国家重点实验室,香港中文大学
发表会议:The Thirty-Eighth AAAI Conference on Artificial Intelligence (AAAI 2024)
论文链接:https://doi.org/10.1609/aaai.v38i11.29104
代码链接:https://github.com/vvvb-github/AVSegFormer
2.论文概述
2.1 核心问题与背景
音频-视觉分割(AVS)是一项新兴的细粒度感知任务,旨在根据视频中的音频信号来定位并分割出对应的发声物体。这项任务要求模型具备像素级别的场景理解能力,将音频和视觉这两种模态的信息紧密结合起来。然而,现有的方法面临诸多挑战如动态关联不足、复杂场景适应性差、简单融合模型的局限、多物体共存的挑战等 多种挑战。
2.2 主要贡献
为了解决上述问题,本文提出了一种名为AVSegFormer的全新框架。该框架基于Transformer架构,旨在为音频-视觉分割任务提供更鲁棒、更精细的解决方案。其主要贡献体现在以下三个方面:
提出全新的AVS框架:本文提出了一个基于Transformer的AVSegFormer框架,专门用于处理音频-视觉分割的三种子任务(S4、MS3、AVSS)。该框架通过结合双向条件跨模态特征融合,为模型提供了更强大的音频-视觉分割表示能力。
设计独特的双向组件:论文设计了两个核心组件——一个稠密音频-视觉混合器(dense audio-visual mixer)和一个稀疏音频-视觉解码器(sparse audio-visual decoder)。这两个组件可以提供像素级和实例级的互补表示,从而有效地适应多声源和多物体的复杂场景。
实现领先的性能:通过在AVS基准数据集上进行广泛实验,AVSegFormer在三个子任务上均取得了最先进(state-of-the-art)的性能,显著优于现有方法。
2.3 关键技术与创新点
VSegFormer框架的核心创新点在于其独特的Transformer架构设计,具体包括:
稠密音频-视觉混合器:该混合器能够根据音频特征动态地调整视觉特征,有选择性地放大或抑制不同的视觉通道,以捕捉复杂的音频-视觉关系。
稀疏音频-视觉解码器:该解码器能够隐式地分离不同的声源,并为不同的查询(queries)自动匹配最佳的视觉特征。
双向条件多模态融合:通过将上述两个组件结合,模型能够获得一种更鲁棒的双向条件多模态表示,从而在不同场景下都能提升分割性能。
查询生成器:该组件负责初始化稀疏的音频条件查询,帮助模型充分理解丰富的音频语义。
辅助混合损失:为了监督混合器生成的跨模态特征,论文设计了一种辅助混合损失(auxiliary mixing loss),以增强模型在复杂场景下的鲁棒性,促使其更准确地定位目标物体。
3.研究背景及相关工作
3.1 多模态任务
近年来,多模态任务在研究界受到了广泛关注。除了文本-视觉任务(如视觉问答和视觉定位)之外,音频-视觉任务也逐渐成为热点。相关任务包括音频-视觉对应、音频-视觉事件定位和声源定位等。许多统一的架构,特别是基于Transformer的架构,已经被提出用于处理多模态输入。这些工作的成功证明了Transformer在跨模态领域强大的能力和可靠性。作为一项新提出的多模态任务,音频-视觉分割(AVS)与上述任务有许多共通之处,这些先驱性的工作为AVSegFormer的研究提供了重要启发。
3.2 视觉Transformer
Transformer架构最初在自然语言处理领域取得了快速发展。随后,Vision Transformer(ViT)的出现将Transformer引入了计算机视觉领域,并取得了令人瞩目的成果。许多研究在此基础上发展,推动了视觉Transformer的成熟,尤其是在目标检测和图像分割任务中。随着视觉Transformer性能的不断提升,它们正逐渐取代卷积神经网络(CNN)成为计算机视觉领域的主流范式。
例如,DETR模型提出了基于Transformer的双边匹配损失,而Deformable DETR和DINO等后续改进框架进一步引入了可变形注意力等机制,将视觉Transformer推向了新的高度。这些卓越的性能表现也激励了本文将这一范式应用于音频-视觉分割任务。
3.3 图像分割
图像分割是一项重要的视觉任务,旨在将图像划分为不同的区域或部分。该任务包括实例分割、语义分割和全景分割等子任务。早期研究针对这些任务提出了专门的模型,如用于实例分割的Mask R-CNN和HTC,以及用于语义分割的FCN和U-Net。随着全景分割的提出,一些研究开始设计能够统一处理多种分割任务的通用模型。近年来,Transformer的引入催生了能够统一所有分割任务的新模型,例如引入掩码注意力机制的Mask2Former、用于检测和分割的统一框架Mask DINO以及通用的图像分割框架OneFormer。这些模型将图像分割提升到了一个新的水平,考虑到AVS任务也涉及分割,这些方法为本文的工作提供了重要的参考。
4.实验设计和方法
4.1 总体架构
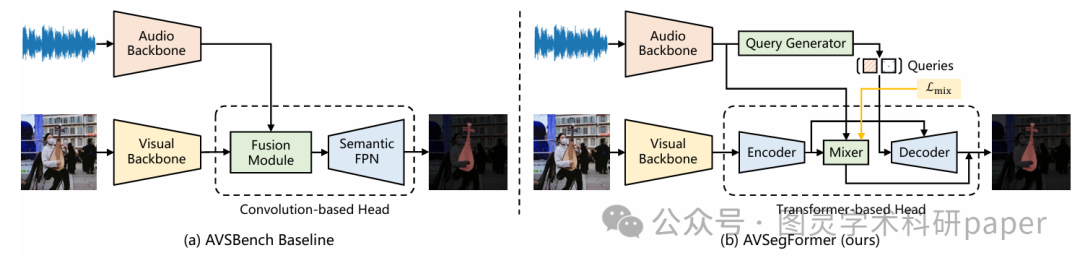
与先前基于CNN的方法不同,AVSegFormer设计了一个基于查询(query-based)的框架,充分利用了Transformer架构的优势。该框架由四个关键组件构成,其整体架构如下所示:
视觉与音频骨干网络:首先,通过视觉骨干网络和音频骨干网络分别提取视频帧和音频的特征。
Transformer编码器:该编码器负责构建初始的掩码特征。
查询生成器:该组件负责初始化稀疏的音频条件查询。
音频-视觉混合器:该混合器会进一步放大相关特征并抑制不相关特征,并受到辅助混合损失的监督。
Transformer解码器:该解码器以多尺度特征作为输入,用于分离潜在的稀疏物体。
4.2 多模态特征表示
视觉编码器:
遵循现有方法的特征提取流程。输入视频帧 xvisual∈RT×3×H×W 通过视觉骨干网络(如ResNet-50)提取出层次化的视觉特征 Fvisual={F1,F2,F3,F4} 。
音频编码器:
遵循VGGish方法进行音频特征提取。首先将音频重新采样为16kHz单声道音频,然后进行短时傅里叶变换以获得梅尔频谱。该频谱随后被输入到VGGish模型中,从而得到音频特征Faudio∈RT×256 。
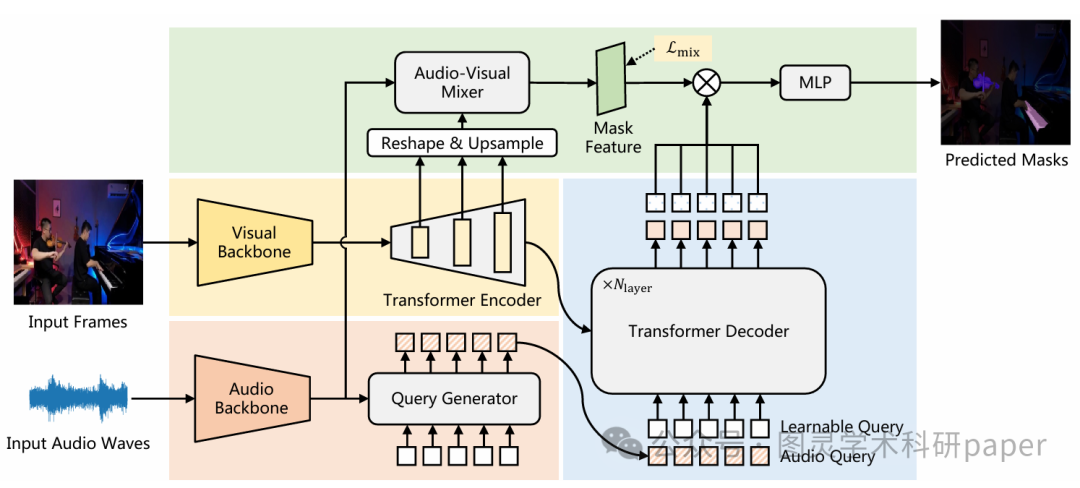
4.3 查询生成器
查询生成器旨在生成稀疏的音频条件查询,以帮助模型充分理解听觉信息。它将一个初始查询Qinit 和音频特征 Faudio 作为输入,通过一个生成器得到音频查询 Qaudio 。随后,将Qaudio 和一个可学习查询 Qlearn 结合成混合查询 Qmixed,作为Transformer解码器的输入。引入可学习查询增强了模型的泛化能力,使其能够学习数据集级别的上下文信息,并调整对不同发声目标的注意力分配。
4.4 Transformer编码器
Transformer编码器负责构建掩码特征。它首先收集视觉骨干网络在三种分辨率(1/8、1/16、1/32)下的特征,并将它们展平后拼接起来作为编码器的输入查询。经过处理后,编码器的输出特征被重新塑形为原始形状,并提取1/8尺度的特征进行2倍上采样。最后,将上采样后的特征与视觉骨干网络的1/4尺度特征相加,得到最终的掩码特征Fmask 。
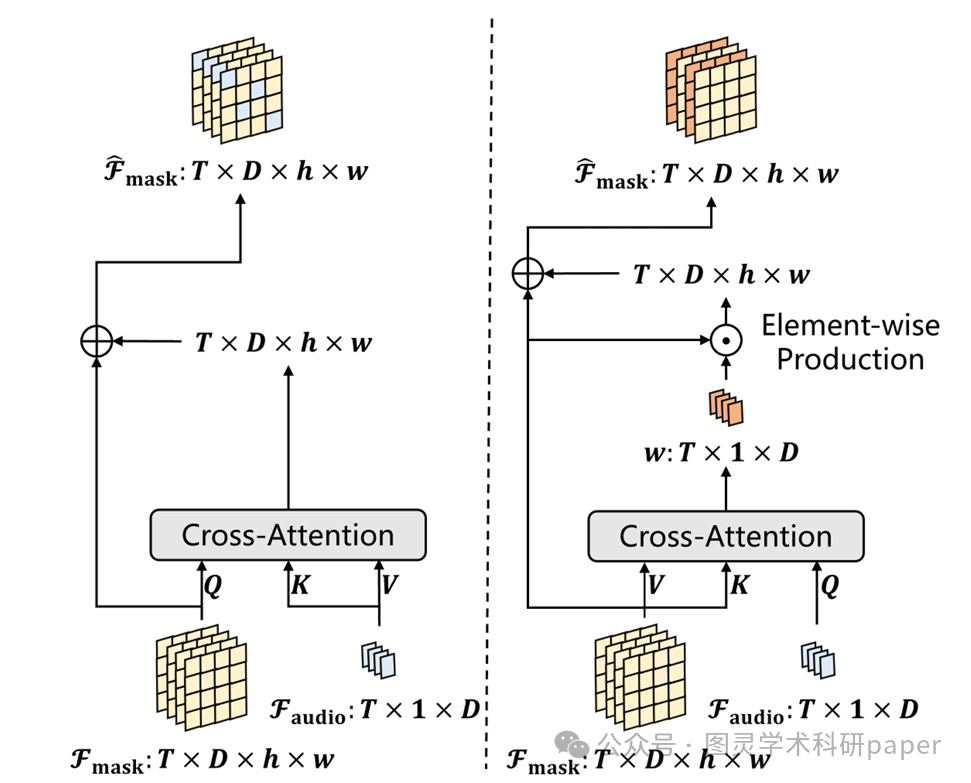
4.5 音频-视觉混合器
由于音频语义的多样性,静态网络可能无法捕获所有相关信息,这会阻碍模型识别不显眼的发声物体。为了解决这个问题,本文提出了一个基于通道注意力(channel attention)的音频-视觉混合器。该混合器能够根据音频特征有选择性地放大或抑制不同的视觉通道,从而提升模型捕捉复杂音频-视觉关系的能力。具体来说,它通过音频-视觉交叉注意力学习一组权重w,并将其应用于突出相关通道。
4.6 Transformer解码器
Transformer解码器的设计目标是构建潜在的稀疏查询,并将它们与视觉特征进行最佳匹配。它使用来自查询生成器的混合查询Qmixed 作为输入,并以多尺度视觉特征作为键和值。在解码过程中,输出查询Qoutput 不断聚合视觉特征,最终将听觉和视觉模态结合起来,并包含各种目标信息。最终的分割掩码是通过将混合器得到的掩码特征Fmask 与解码器的输出查询 Qoutput 相乘,并经过一个MLP层和一个全连接层得到的。
4.7 损失函数
辅助混合损失:
为了在复杂场景下增强模型的鲁棒性,本文设计了辅助混合损失 Lmix 来监督混合器。它将混合掩码特征Fmask 通过一个线性层预测为一个二值掩码,并与地面真值中的前景标签计算Dice损失。
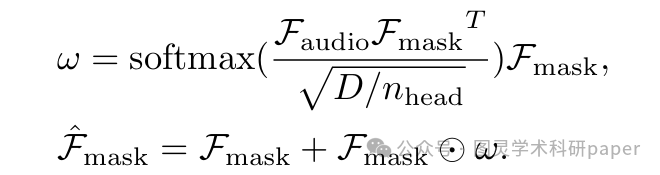
总损失:
总损失函数由IoU损失 LIoU 和混合损失 Lmix 两部分组成。LIoU 是最终分割掩码与地面真值之间的Dice损失。最终的总损失表示为L=LIoU+λLmix,其中 λ 被设置为0.1以达到最佳性能。由于AVS任务中分割对象占图像比例较小,使用Dice损失能让模型更好地关注前景并减少背景干扰。
5. 实验结果分析
5.1 数据集与实施细节
实验在专门为音频-视觉分割任务设计的AVSBench数据集上进行。该数据集包含两个子集:
AVSBench-Object:用于单声源分割(S4)和多声源分割(MS3)任务,提供了像素级标注。S4子集包含4,932个视频,涵盖23个类别。MS3子集包含424个视频。
AVSBench-Semantic:AVSBench-Object的扩展,提供额外的语义标签,用于音频-视觉语义分割(AVSS)任务。该子集视频时长更长,数量约是原始数据集的三倍。

模型使用AdamW优化器,初始学习率为2×10−5,批量大小为2。S4和AVSS子集训练30个epoch,而较小的MS3子集训练60个epoch。

5.2 与现有方法的比较
论文将AVSegFormer与AVS基准上的现有方法进行了全面比较。结果显示,AVSegFormer在所有三个子任务上都显著优于现有最先进的方法,成为新的最先进方法。
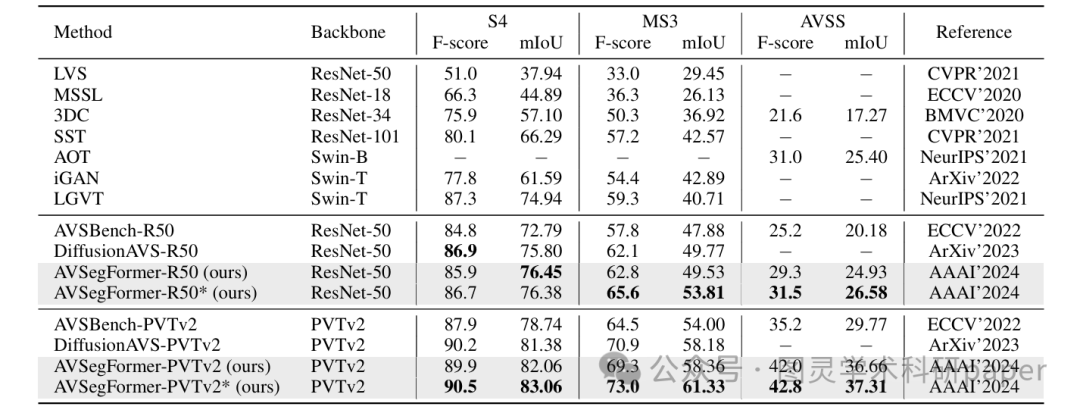
与相关任务方法的比较:AVSegFormer在与来自声源定位、视频对象分割和显著物体检测等相关任务的方法比较中,取得了巨大的领先。例如,在S4子集上,AVSegFormer-R50的mIoU达到了76.45,比性能最佳的LGVT高出1.51个百分点。在MS3和AVSS子集上,AVSegFormer同样取得了显著优势。
与AVSBench基准的比较:与当前的AVSBench基准方法相比,AVSegFormer在所有子任务上都取得了性能提升。例如,在S4子集上,AVSegFormer-R50在mIoU和F-score上分别提高了3.66和1.1。在AVSS子集上,AVSegFormer-R50和AVSegFormer-PVTv2的mIoU分别提高了4.75和6.89。定性分析结果也表明,AVSegFormer能够更准确地定位发声物体并勾勒出其形状。
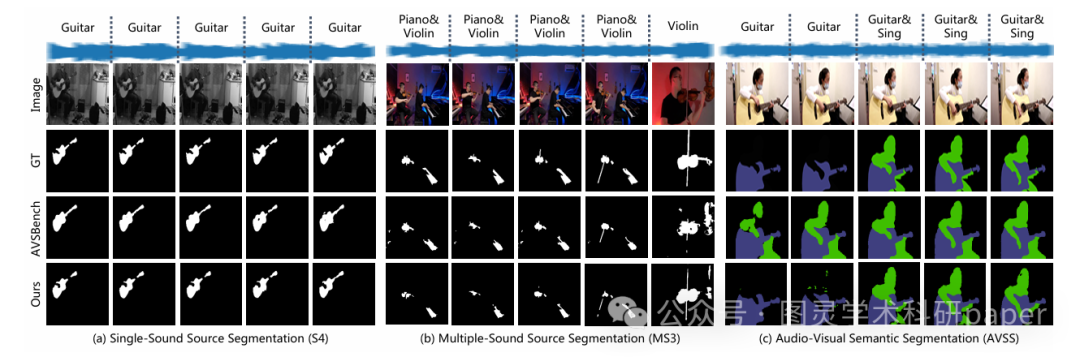
5.3 消融研究
为验证各关键设计组件的有效性,论文进行了多项消融实验。
查询数量的影响:实验分析了查询数量对模型性能的影响,结果表明查询数量与模型性能呈正相关,当查询数量设置为300时,模型性能达到最佳。
可学习查询的影响:引入可学习查询对模型性能有积极影响。在复杂的MS3多声源任务中,这种改进尤为显著,这归因于其能够帮助模型学习数据集级别的上下文信息。
音频-视觉混合器的影响:实验比较了两种混合器设计——交叉注意力混合器(CRA)和通道注意力混合器(CHA)。结果表明,CHA的设计带来了更大的性能提升。通过可视化,可以清楚地看到混合器有效增强了发声物体的特征,同时抑制了非发声物体的特征,证实了其有效性。
辅助混合损失的影响:实验证明,辅助混合损失在最终预测中起到了很大的帮助作用。
6.论文总结展望
6.1 论文总结
本文提出了一种名为AVSegFormer的新型音频-视觉分割框架,该框架巧妙地利用了Transformer架构的强大能力,实现了在AVS基准上领先的性能。AVSegFormer的核心在于其四大关键组件:一个用于构建掩码特征的Transformer编码器、一个用于生成稀疏查询的查询生成器、一个用于动态调整视觉特征的稠密音频-视觉混合器,以及一个用于分离潜在稀疏对象的稀疏音频-视觉解码器。通过结合这些组件,AVSegFormer构建了一种鲁棒的双向条件跨模态特征表示,从而显著提升了在单声源、多声源和语义分割三种子任务上的性能。消融研究也充分验证了这些核心设计和辅助混合损失的有效性。
6.2 论文展望
尽管论文并未直接提出未来的研究方向,但AVSegFormer的成功为音频-视觉领域提供了宝贵的思路。未来的研究可以围绕以下几个方面展开:
更高效的Transformer架构:可以探索更轻量级或更高效的Transformer架构,以进一步降低模型计算成本,使其更易于在边缘设备上部署。
更复杂的场景处理:虽然AVSegFormer在多声源场景下表现出色,但现实世界的复杂性远不止于此。未来可以研究如何处理遮挡、视角变化、低质量音视频等更具挑战性的场景。
多任务学习的扩展:可以将AVSegFormer的架构扩展到其他多模态任务中,例如音频-视觉事件检测、音频-视觉字幕生成等,进一步探索其在更广泛领域的应用潜力。
无监督或半监督学习:音频-视觉分割任务的标注成本较高,未来可以探索利用无监督或半监督方法,减少对大量标注数据的依赖,从而更高效地训练模型。
本文选自gongzhonghao【图灵学术SCI论文辅导】
关注我们,掌握更多顶会顶刊发文资讯