【21-倾斜数据集的误差指标】
倾斜数据集的精确度和召回率
当在开发机器学习程序时,其中正反例子的比例失衡,远非50-50,那么通常的错误度量指标,如准确率,就不会那么有效;
例子:训练一个二元分类,基于实验室测试和其他数据来检测病人身上是否有某种罕见疾病;
假设你发现在测试集上,该模型的错误率是1%,即拥有99%的正确率,但事实上,如果这是罕见病,则y=1的数据例子就非常少,假如只有0.5%的人有这种病,你在程序中只需要写print(“y=0”) 则这个程序就拥有99.5%的准确率,这行代码实际上比你的模型(99%)的准确率还高(手动狗头)。换句话来说,无法判断99%的准确率是好还是不好,假如有三个模型,对于检测这种病有99.2% 99.5% 99.6%的准确率,实际上无法判断哪个模型更有用。

在处理数据集不平衡的问题时,通常使用一个不同的错误指标,而不是仅用分类错误来判断学习效果。
常用的错误指标是精确率precision和召回率recall。
在例子中,y=1是想要检测的稀有类别;特别地,为了评估具有稀有类别的算法的性能,构建《混淆矩阵》confusion matrix 会很有用。
为了评估模型在交叉验证集/测试集上(如25/100)的表现,统计实际类别为1且预测也为1的示例,统计实际类别为0但预测为1的数量,统计实际为1但预测为0的数目,以及统计实际为0预测也为0的数目;
将实际为1预测也为1的称为真正例true positive,将实际为0预测也为0的称为真负例,将实际为0预测为1的称为假正例,将实际为1预测为0的称为假负例false negative;

统计完这四个数目,通常会计算的两个常见指标是精确度和召回率;
精确度:在模型预测为y=1的病人中,有多少病人实际上真有这种病; 精确度 = 真正例的数目 / 被预测为正例的数目 = 15 / 20 = 75%;
召回率:在实际的患病者中,实际上预测出了多少位;召回率 = 真正例的数目 / 实际为正例的数目 = 真正例 / (真正例 + 假负例)= 15 / 25 = 60%;
这两个指标可以帮助检测模型是否一直在预测y=0,即预测正例永远为0,真正例永远为0;
总的来说,一个精确度或者召回率为0的学习算法是不可靠的,不实用的,
计算精确度和召回率,更容易评判一个算法是否相对合理准确,当它预测某人患病时,则他患病的概率有75%;它在患病者人群中能预测出一部分人(60%)患病;
当涉及稀有类别时,计算并确保精准度和召回率都比较高,更能说明模型的有效性;
召回率:衡量的是在所有患病者中,你能诊断出多少比例的人确实患病;
精确度和召回率的权衡
为了优化学习算法的性能,需要权衡精确度和召回率
在通常情况下,对于逻辑回归的输出的阈值判断通常是在0.5处做判断,二元分类;
但对于罕见疾病的例子来说,只有当比较有把握确信时才判断结果为1(因为可能涉及昂贵的治疗等/不是特别确信时就继续保守治疗),这时可能会将阈值从0.5设为更高的值(比如0.7),即当模型预测概率更接近1时才判断为患病;
提高阈值时会使得精确率precision变高,但是recall变低;
(PS:医学上,precision是阳性预测值;recall是敏感度)
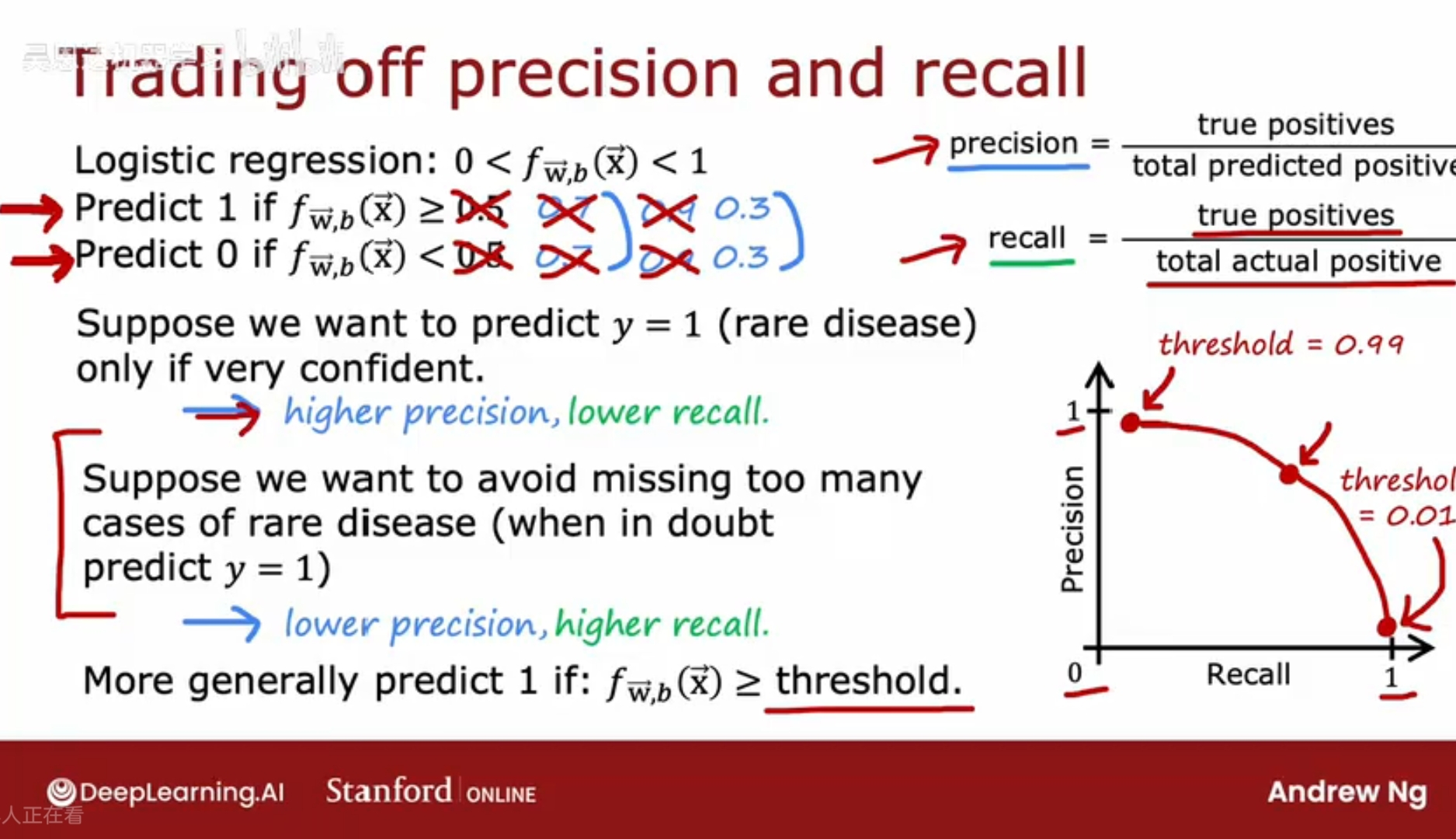
另一方面,又希望避免漏诊患病的病例,考虑到漏诊后续延误治疗带来的严重后果,(当治疗不是非常有侵入性 痛苦和昂贵),出于安全考虑,有些怀疑时就预测患者患病并考虑治疗,这是可以考虑降低阈值0.5,比如0.3;
降低阈值将使精确率precision变低,但是recall变高;
因此,改变阈值就是在精确率和召回率之间做权衡。
以及精确率和召回率之间的曲线关系;尝试在曲线上找一点,以平衡假正例和假负例的代价/后果,或是平衡高精准率和高召回率的收益。
很多情况下,都是手动选择阈值,以平衡精确率和召回率。
自动权衡精确率和召回率

指标 F1 score,有时被用来自动组合精确率和召回率,以帮助选择最佳值或二者之间的权衡;
精确率和召回率:两个不同的指标来评估算法模型;
因此,对于三个有着不同精确率和召回率的算法模型来说,很难去选择或评估哪个模型更优;
找到一种将精准率和召回率组合为一个分数的方法,以便评估和排序不同的模型;
方法1:取平均值(事实证明效果很差);
方法2:计算F1 score;
F1 score: 更关注较低分的计算方法;
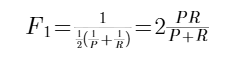
F1 score 提供了一种这种精确率和召回率的方法;
在数学中,这个公式被称为PR调和平均值;调和平均是强调较小值的一种平均计算方法;