金融风控实战:从数据到模型的信用评分系统构建全解析
一、项目背景与目标
在金融信贷领域,准确预测借款人未来两年内是否会发生严重贷款违约(SeriousDlqin2yrs)至关重要。本研究基于"Give Me Some Credit"数据集,通过完整的机器学习流程构建预测模型。数据集包含150,000条训练样本和101,503条测试样本,涵盖12个关键特征:
# 核心特征变量
Attributes = ['RevolvingUtilizationOfUnsecuredLines', 'age', 'NumberOfTime30-59DaysPastDueNotWorse', 'DebtRatio', 'MonthlyIncome','NumberOfOpenCreditLinesAndLoans', 'NumberOfTimes90DaysLate','NumberRealEstateLoansOrLines', 'NumberOfTime60-89DaysPastDueNotWorse','NumberOfDependents']二、数据探索与关键发现
1. 数据分布可视化
# 年龄分布可视化
plt.figure(figsize=(8, 6))
plt.hist(train_data['age'], bins=20)
plt.title('借款人年龄分布')
plt.xlabel('年龄')
plt.ylabel('频数')
plt.show()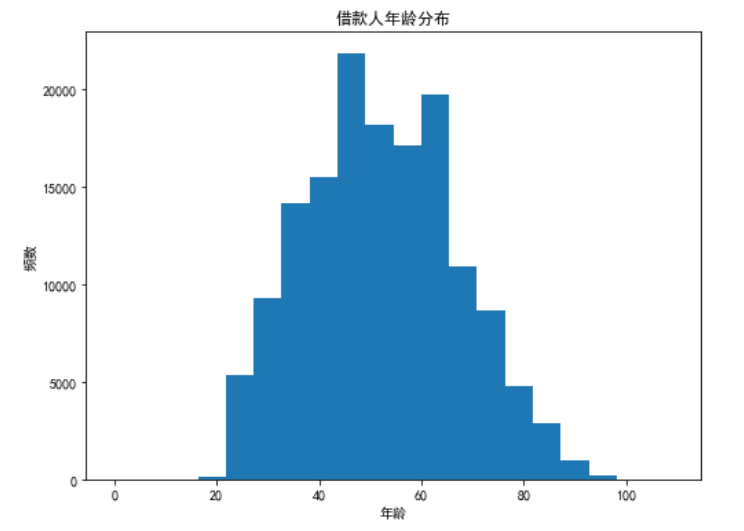
图 借款人年龄分布图
年龄分布:借款人主要集中在30-70岁区间,符合房贷/车贷主力人群特征
2. 目标变量严重不平衡
# 目标变量分布(DOC2)
train_data['SeriousDlqin2yrs'].value_counts()
# 输出:0(正常)占比93.5%,1(违约)占比6.5%解决方案:采用分层下采样技术平衡数据集
# 下采样实现(DOC2)
train0 = train_data[train_data['SeriousDlqin2yrs']==0].sample(frac=0.065)
train1 = train_data[train_data['SeriousDlqin2yrs']==1].copy()
train_df = pd.concat([train0, train1], axis=0)三、数据预处理关键技术
1. 异常值检测与处理
采用三倍标准差法与箱线图法双重检测:
# Create a figure and axes for the subplots
fig, axes = plt.subplots(nrows=4, ncols=3, figsize=(15, 10))# Iterate over the variables and plot the boxplots
for i, column in enumerate(Attributes):sns.boxplot(train_data[column], ax=axes[i//3, i%3])axes[i//3, i%3].set_title(f"Boxplot graph - {column}")axes[i//3, i%3].grid(False)# Adjust the layout
plt.tight_layout()
plt.show()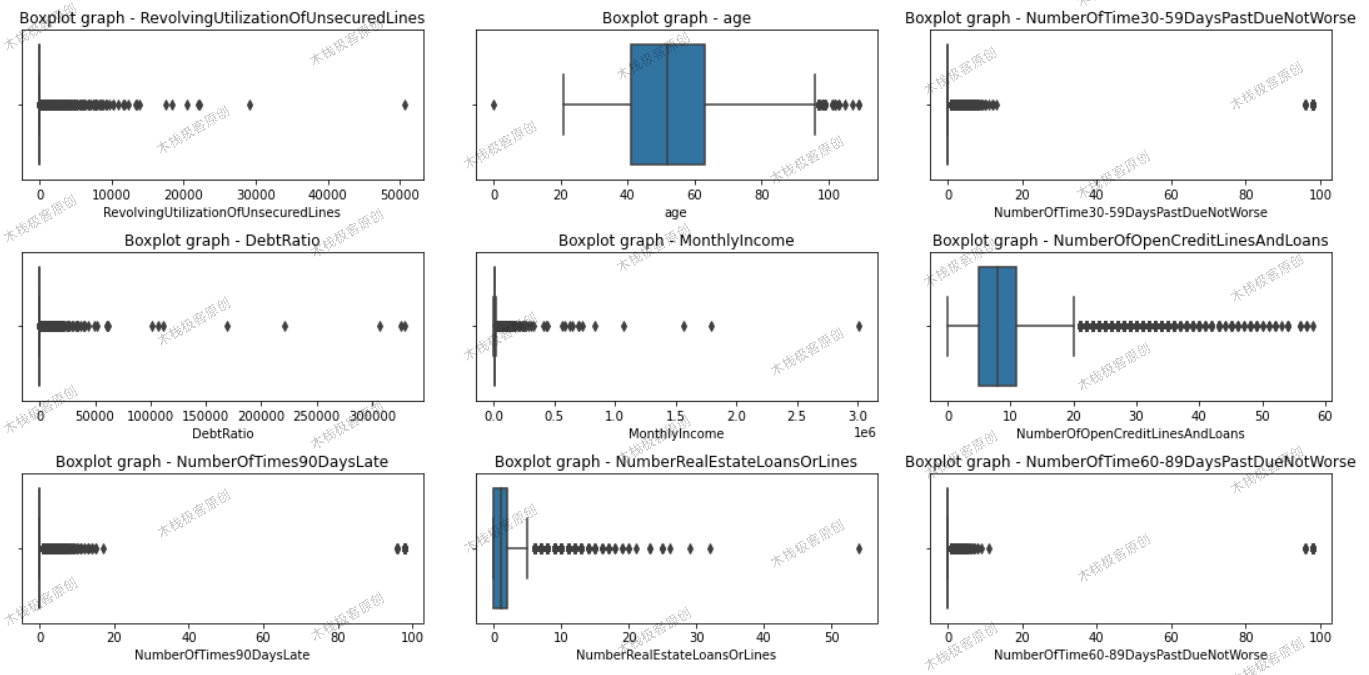
箱线图
处理极端值案例:循环信贷利用率>1000%的异常样本
2. 高级缺失值填补
采用KNNImputer进行多变量协同填补:
# KNN缺失值填补(DOC2)
from sklearn.impute import KNNImputer
imputer = KNNImputer().fit(inputs[input_cols])
inputs[input_cols] = imputer.transform(inputs[input_cols])优势:
保留特征间相关性(如月收入与职业类型的关系)
对异常值鲁棒性强
可处理多个特征同时缺失的情况
3. 数据标准化
使用MinMaxScaler进行归一化:
# 数据标准化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler().fit(inputs[input_cols])
inputs[input_cols] = scaler.transform(inputs[input_cols])四、模型构建与评估
1. 模型选择依据
模型 | 选择理由 | 适用场景 |
|---|---|---|
决策树 | 直观可解释性强,可处理非线性关系 | 需要透明决策规则的场景 |
随机森林 | 高准确性,抗过拟合能力强 | 高精度预测需求 |
SVM | 擅长处理高维特征,泛化能力强 | 小样本复杂分类问题 |
2. 模型训练与评估
# 数据集划分
from sklearn.model_selection import train_test_split
X_train, X_val, train_targets, val_targets = train_test_split(inputs, targets, test_size=0.3, random_state=0
)# 决策树模型训练
from sklearn.tree import DecisionTreeClassifier
model_DT = DecisionTreeClassifier(random_state=0)
model_DT.fit(X_train, train_targets)# 随机森林模型训练
from sklearn.ensemble import RandomForestClassifier
model_RF = RandomForestClassifier(random_state=0)
model_RF.fit(X_train, train_targets)# SVM模型训练
from sklearn.svm import SVC
model_SVM = SVC(random_state=0)
model_SVM.fit(X_train, train_targets)3. 模型评估结果
# 准确率计算(DOC2)
from sklearn.metrics import accuracy_scoreval_predictions_DT = model_DT.predict(X_val)
accuracy_DT = accuracy_score(val_targets, val_predictions_DT)val_predictions_RF = model_RF.predict(X_val)
accuracy_RF = accuracy_score(val_targets, val_predictions_RF)val_predictions_SVM = model_SVM.predict(X_val)
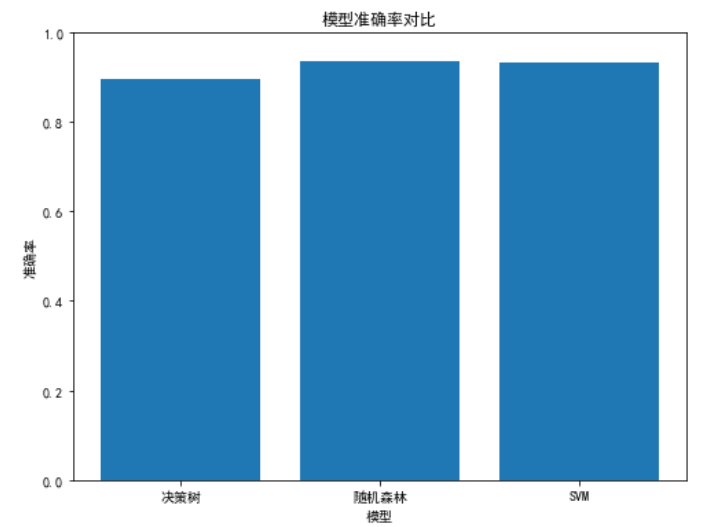
accuracy_SVM = accuracy_score(val_targets, val_predictions_SVM)评估结果:
决策树准确率:89.4%
随机森林准确率:93.4%
SVM准确率:93.2%
五、关键发现与业务洞见
1. 特征重要性分析
importance_df = pd.DataFrame({'feature': X_train.columns,'importance': model_RF.feature_importances_
}).sort_values('importance', ascending=False)
importance_df.head(10)
plt.title('Importance')
sns.barplot(data=importance_df.head(10), x='importance', y='feature')
plt.savefig('特征重要性.png', dpi=300, bbox_inches='tight')
plt.show()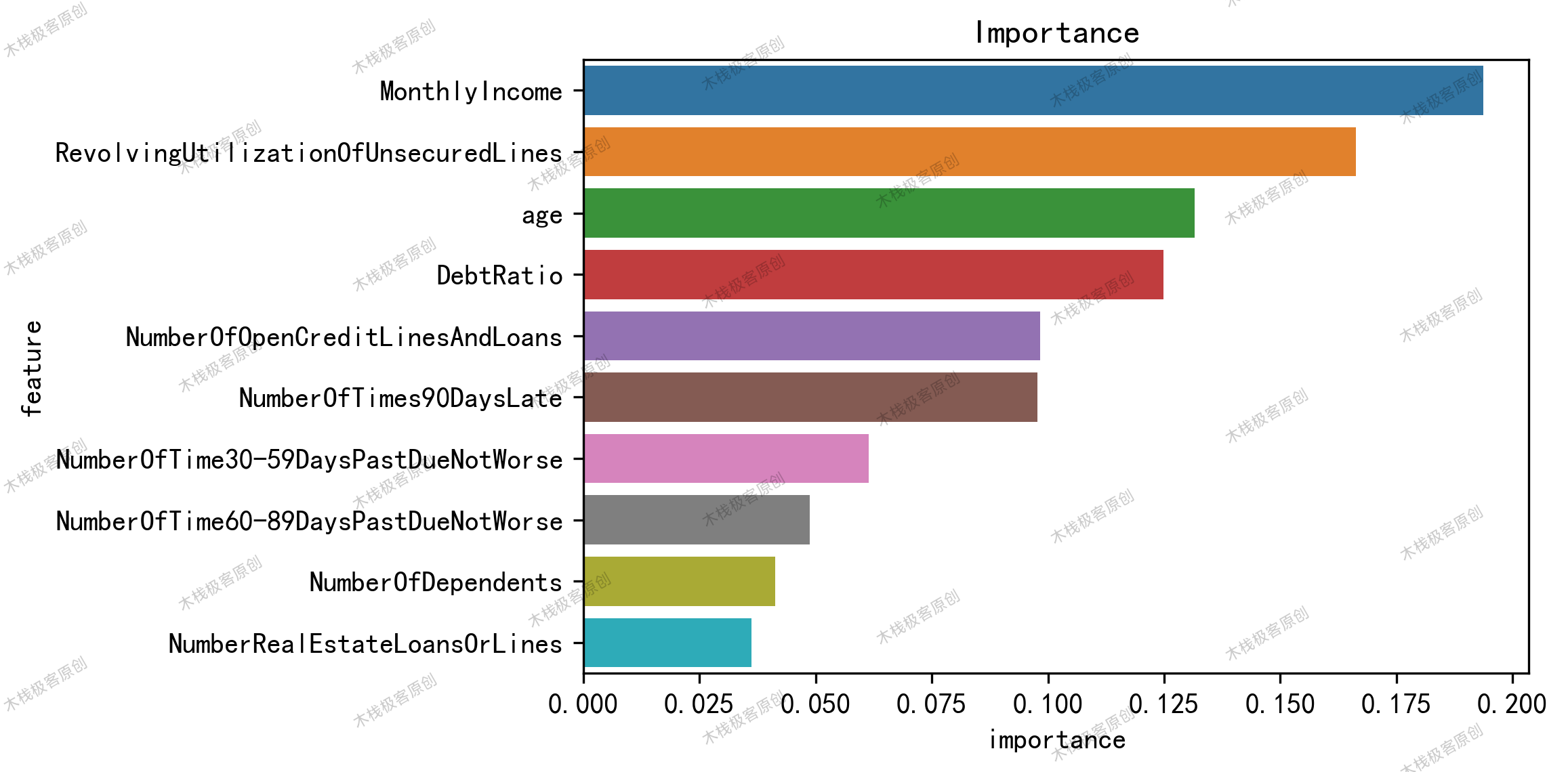
TOP3重要特征:
月收入(MonthlyIncome) - 还款能力核心指标
循环信贷利用率(RevolvingUtilizationOfUnsecuredLines) - 反映资金紧张程度
年龄(age) - 呈U型风险曲线(30岁以下和70岁以上风险更高)
2. 混淆矩阵分析
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC# 随机森林模型
model_RF = RandomForestClassifier(random_state=0)
model_RF.fit(X_train, train_targets)
val_predictions_RF = model_RF.predict(X_val)
accuracy_RF = accuracy_score(val_targets, val_predictions_RF)# 绘制随机森林模型的混淆矩阵
cm_RF = confusion_matrix(val_targets, val_predictions_RF)
plt.figure(figsize=(8, 6))
sns.heatmap(cm_RF, annot=True, fmt="d", cmap="Blues")
plt.title("随机森林模型混淆矩阵")
plt.xlabel("预测值")
plt.ylabel("真实值")
plt.savefig('混淆矩阵-随机森林.png', dpi=300, bbox_inches='tight')
plt.show()# SVM模型
model_SVM = SVC(random_state=0)
model_SVM.fit(X_train, train_targets)
val_predictions_SVM = model_SVM.predict(X_val)
accuracy_SVM = accuracy_score(val_targets, val_predictions_SVM)# 绘制SVM模型的混淆矩阵
cm_SVM = confusion_matrix(val_targets, val_predictions_SVM)
plt.figure(figsize=(8, 6))
sns.heatmap(cm_SVM, annot=True, fmt="d", cmap="Blues")
plt.title("SVM模型混淆矩阵")
plt.xlabel("预测值")
plt.ylabel("真实值")
plt.savefig('混淆矩阵-SVM.png', dpi=300, bbox_inches='tight')
plt.show()# 绘制准确率对比图并保存
models = ['决策树', '随机森林', 'SVM']
accuracies = [accuracy, accuracy_RF, accuracy_SVM]plt.figure(figsize=(8, 6))
plt.bar(models, accuracies)
plt.title("模型准确率对比")
plt.xlabel("模型")
plt.ylabel("准确率")
plt.ylim([0, 1])
plt.savefig('准确率对比图.png', dpi=300, bbox_inches='tight')
plt.show()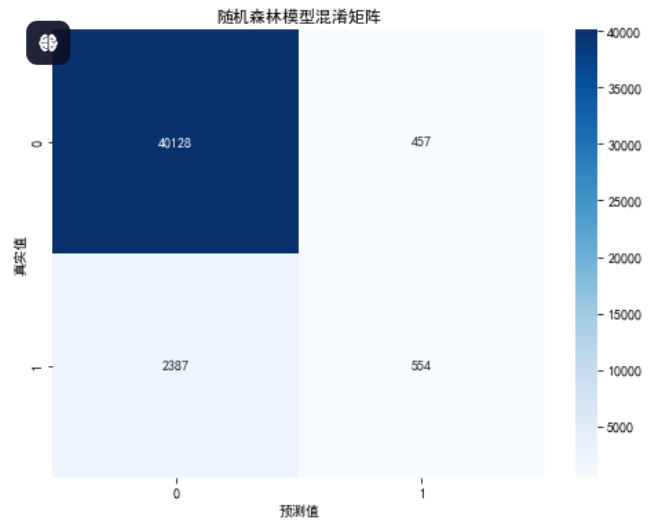
分析显示随机森林对违约样本的召回率显著高于其他模型,这对风险控制至关重要。
六、实施价值与改进方向
1. 业务应用价值
风险定价:基于预测概率差异化定价
授信决策:高风险客户自动触发人工审核
贷后管理:对高概率违约客户提前干预
2. 改进方向
特征工程优化:创建组合特征(如债务收入比)
模型集成:探索投票集成或堆叠集成
实时监控:建立特征漂移监测机制
# 简单集成示例
from sklearn.ensemble import VotingClassifierensemble = VotingClassifier(estimators=[('dt', model_DT),('rf', model_RF),('svm', model_SVM)
], voting='hard')
ensemble.fit(X_train, train_targets)