Stable Diffusion Models are Secretly Good at Visual In-Context Learning
Stable Diffusion Models are Secretly Good at Visual In-Context Learning
Authors: Trevine Oorloff, Vishwanath Sindagi, Wele Gedara Chaminda Bandara, Ali Shafahi, Amin Ghiasi, Charan Prakash, Reza Ardekani
Deep-Dive Summary:
1. 引言
上下文学习(In-context Learning, ICL)是一种范式,其中基础模型利用示例源-目标对(称为提示,prompts)来推断任务,并在输入(称为查询,query)上执行推断出的任务。ICL 是大型语言模型(LLMs)的一种新兴属性,在自然语言处理(NLP)领域已被广泛探索[5, 13, 35, 42]。ICL 使得模型能够适应新颖或领域外的任务,而无需进行微调。
这种方法不仅消除了任务特定的训练,还减少了对任务特定标注数据集的依赖。近期研究,如[3, 22, 38-41, 44],已在尝试利用上下文学习在计算机视觉任务中的潜力。这些工作根据训练数据集的不同可分为两类:(1)未整理的数据集(如 CVF [3], S2CV [44])和(2)整理/标注的任务相关数据集(如 COCO [21], NYUDv2 [32])。
第一类方法,如 Visual Prompting [3] 和 Improv [44],通过在未整理数据集(如 CVF, S2CV)上使用 inpainting 损失进行训练,使基础模型能够执行上下文学习。这些数据集包含从计算机视觉论文中提取的图像,并由源-目标对的网格结构组成。结合这种结构化输入和训练期间的随机掩码,模型能够隐式地学习源图像和目标图像之间的关系。在推理过程中,当模型接收到包含查询图像和示例提示(源-目标对)的网格画布,并且查询图像的输出位置被掩盖时(见图 2a),模型被期望进行预测填充。
第二类方法[22, 38-41] 通过在整理数据集(如 COCO, NYUDv2)上训练,使基础模型能够进行上下文学习。
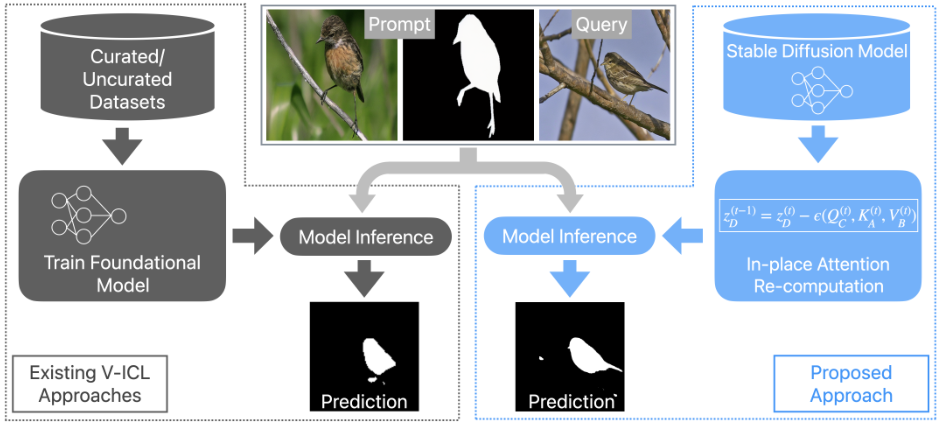
![Figure 2. (a) Existing approaches like Visual Prompting [3] train a foundation model with an inpainting objective on uncurated data. At inference, a grid of query and example prompt are input to the model. (b) Visual Prompting [3] struggles to predict accurately even when the prompt is the same as the query. (c) The proposed approach, when presented with the same prompt as the query, is able to fully leverage the prompt to make accurate predictions.](https://i-blog.csdnimg.cn/img_convert/e9a9b036bcdf66dd9d61973e85db1495.png)
这些方法虽然不使用任务特定的损失函数,但仍然依赖于任务代表性的数据集。例如,为了使 Painter [38] 模型适应开放词汇分割任务(如 FSS-1000 [20]),模型会在相关数据集(如 COCO 分割数据集)上进行训练。换句话说,只要模型在训练期间遇到过某项任务,它就能在未见类别上的查询图像上执行该任务。然而,这意味着模型在训练期间需要访问大型标注数据集,从而削弱了视觉上下文学习(V-ICL)的关键优势。此外,此类模型的泛化能力仅限于训练期间见过的相关任务。尽管这些方法在未见任务上的视觉基础模型显示出初步的成功,但与 NLP 领域的 LLMs 类似,利用现成的视觉基础模型(如 Stable Diffusion [28], ViT [9])取得类似成功仍是一个尚未完全探索的领域。
虽然现有的 V-ICL 方法显示出有前景的结果,但它们涉及额外的训练步骤和/或来自领域外任务的数据,与模型适应的任务相关。不同于现有方法,本研究聚焦于一种更符合 NLP 社区 ICL 方法的策略。具体来说,我们提出了一个问题——是否可以在不进行任何额外训练步骤或数据的情况下,使用现成的基础模型进行视觉上下文学习?为此,我们提出了基于 Stable Diffusion 的视觉上下文学习(SD-VICL)流程,展示了一个现成的 Stable Diffusion 模型可以在不进行任何微调的情况下,适应多个新的领域外任务(见图 1)。为了实现这一点,我们在 Stable Diffusion 架构的自注意力层内制定了一种就地注意力重新计算,明确纳入了查询和示例提示之间的上下文。这种公式化基于现有方法的缺点(如 Visual Prompting [3],见图 2),这些模型无法充分利用示例提示。
此外,我们注意到现有方法(如 Bar 等人 [3] 和 Xu 等人 [44])展示了使用多个示例提示来提升 V-ICL 基础模型预测能力的优势。然而,他们通过在图像空间中创建多个示例的复合来进行集成的方法是以降低每个提示的分辨率为代价的——限制了提示集成的潜力。为了解决这一问题,受 SegGPT [39] 中特征集成的启发,我们在潜在空间中进行提示集成用于上下文学习。需要注意的是,SegGPT 中的特征集成涉及在每个注意力层后对查询特征进行平均,这导致所有提示的权重均匀。相比之下,我们在每个注意力层内进行隐式加权提示集成,从而使模型能够更好地从多个提示中推断信息。
我们进行了广泛的评估以展示所提出方法的有效性。具体来说,我们展示了预训练的 Stable Diffusion 模型有能力适应各种任务,如前景分割、单目标检测、语义分割、关键点检测、边缘检测和着色。
- 第一个无需训练的方法,使基础模型具备视觉上下文学习特性,为视觉上下文学习研究设定了新方向。
- 提出了一种新颖的流程,通过在现成的 Stable Diffusion 模型的自注意力层内引入就地注意力重新计算,明确纳入了查询图像和提示之间的上下文。
- 对所提出方法进行了广泛评估,以展示其泛化到多个领域外任务的能力。
- 隐式加权提示集成,使 V-ICL 能有效利用多个提示。
2. 方法 # 2.1. 动机与初步分析
在上下文学习(ICL)中,基础模型被期望基于少量的源-目标示例提示来推断任务,并为查询图像预测合适的输出。更重要的是,正如自然语言处理(NLP)社区所展示的,上下文学习应是基础模型的一种新兴属性,模型无需额外训练。然而,现有的视觉上下文学习(V-ICL)方法涉及训练和/或使用额外的任务相关数据。此外,当我们通过多个实验研究基于未精选数据集的V-ICL方法(例如Bar等人的研究[3])时,我们观察到以下现象:(1) 模型无法重构输入提示,尽管输入中未对其进行掩码处理,如图2a中基础模型输出的左上角图像所示;(2) 模型在图像中存在多个对象时表现挣扎,如图2a所示,模型错误地将鸟食器预测为前景;(3) 当提供查询及其真实标签作为示例提示时,模型尽管可以访问查询的真实标签,仍难以做出正确预测(参见图2b)。这些观察结果表明,模型无法充分利用提示。我们将模型的这种无能归因于缺乏适当的上下文解释:(1) 示例提示的源和目标之间的上下文解释对于任务推断至关重要;(2) 查询与示例提示的源之间的上下文解释对于准确预测至关重要。
为了缓解这些限制,我们提出了一种新颖的仅推断的基于稳定扩散的视觉上下文学习流程(SD-VICL),与现有方法不同,它不需要额外训练。稳定扩散(Stable Diffusion)[28] 是一种潜在扩散模型,通过迭代地精炼随机噪声来生成高质量图像。去噪过程在给定时间步 ttt 使用去噪U-Net,该网络包含在分辨率 16×1616 \times 1616×16、32×3232 \times 3232×32 和 64×6464 \times 6464×64 上运行的多个自注意力层。在每个自注意力层 (l)(l)(l),中间噪声潜在的输入特征 Φ(zt)\Phi(z_t)Φ(zt) 被转换为查询(Q)、键(K)和值(V)向量,使用线性层计算。自注意力图通过以下公式计算:
KaTeX parse error: Extra } at position 75: …(t)}{\sqrt{d}}}}̲\right),
该公式捕捉图像内的对应关系。参数 ddd 表示 QQQ 向量的特征维度。自注意力图 (α)(\alpha)(α) 用于使用特征更新 △Φ\triangle\Phi△Φ 更新中间特征图,计算公式为:
△ϑ(t)⟶Q(t)⋅V(t).\triangle\vartheta^{\left(t\right)}\ \longrightarrow\ Q^{\left(t\right)}\ \cdot\ \textstyle V^{\left(t\right)}. △ϑ(t) ⟶ Q(t) ⋅ V(t).
这一更新后的特征集与交叉注意力层的更新一起用于计算中间噪声预测。在本文中,我们仅关注自注意力计算。因此,为简化起见,我们将迭代去噪过程写作:
Z(t−1)⟶Z(t)⟶Z(t)⟶ϵ(Θ(t),R(t),V(t)),\mathcal{Z}^{\left(t-1\right)}\longrightarrow\mathcal{Z}^{\left(t\right)}\longrightarrow\mathcal{Z}^{\left(t\right)}\longrightarrow\epsilon\Bigl(\Theta\phantom{\left(t\right)},\,R^{\left(t\right)},\,V^{\left(t\right)}\Bigr), Z(t−1)⟶Z(t)⟶Z(t)⟶ϵ(Θ(t),R(t),V(t)),
其中预测噪声 EEE 是自注意力层的 QQQ、KKK 和 VVV 向量的函数。
2.2. 将稳定扩散模型重新用于视觉上下文学习 (SD-VICL)
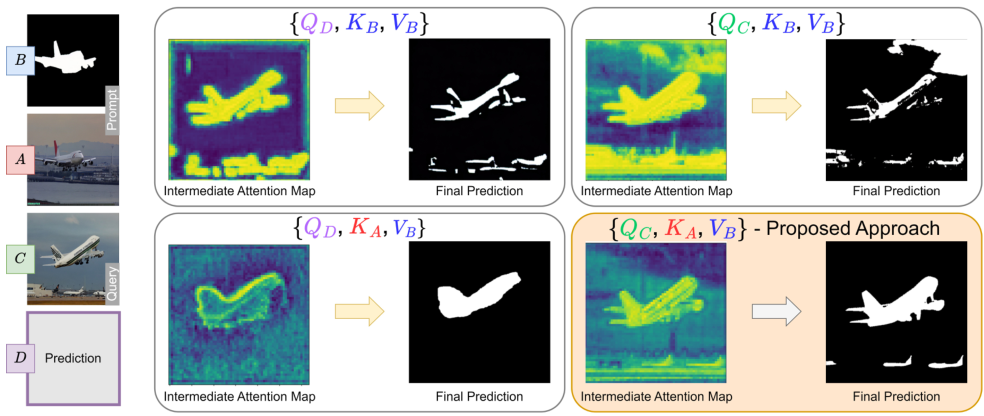
正如之前所讨论的,为了实现成功的上下文学习,模型需要理解两方面的关系:(1) 提示图像 (A) 与提示真值 (B) 之间的关系;(2) 上下文关系,即查询图像 © 与提示图像 (A) 之间的关系。为了确保这些关系能够被有效推断,我们在去噪 U-Net 的上采样层中提出了一种新的注意力计算方法,替代传统的自注意力计算。这种方法受到近期一些研究的启发 [1, 6, 25, 36],这些研究将稳定扩散模型的自注意力层重新用于图像编辑和风格迁移等任务。
我们首先将提示图像 (A)、提示真值 (B) 以及查询图像 © 利用现成的反演模型 [19] 转换到稳定扩散模型的噪声空间,分别得到对应的噪声表示。随后,这些图像在默认去噪流程中并行地进行迭代去噪,公式如下:
Lp(t−1)⟶Lp(t)⟶Lp(t)⟶ϵ(Θp(t),Rp(t),Vp′(t)),\mathcal{L}_{p}^{(t-1)}\longrightarrow\mathcal{L}_{p}^{(t)}\longrightarrow\mathcal{L}_{p}^{(t)}\longrightarrow\epsilon\big(\Theta_{p}^{(t)},\,R_{p}^{(t)},\,V_{p}^{\prime(t)}\big), Lp(t−1)⟶Lp(t)⟶Lp(t)⟶ϵ(Θp(t),Rp(t),Vp′(t)),
其中 p∈{A,B,C}p \in \{A, B, C\}p∈{A,B,C},t∈[T,1]t \in [T, 1]t∈[T,1],t∈Z+t \in \mathbb{Z}^+t∈Z+。
由于输出图像在大多数视觉任务中预期与查询图像在结构上相似,我们在预测流程 D 中使用查询图像 © 的噪声空间来初始化噪声空间。与之前的公式不同,查询预测的去噪过程使用以下公式:
LD(t−1)⟶ZD(t)⟶LD(t)⟶ϵ(ΘC(t),KA(t),ΨB(t)),\mathcal{L}_{D}^{(t-1)}\longrightarrow\mathcal{Z}_{D}^{(t)}\longrightarrow\mathcal{L}_{D}^{(t)}\longrightarrow\epsilon\big(\Theta_{C}^{(t)},K_{A}^{(t)},\Psi_{B}^{(t)}\big), LD(t−1)⟶ZD(t)⟶LD(t)⟶ϵ(ΘC(t),KA(t),ΨB(t)),
其中 t∈[T,1]t \in [T, 1]t∈[T,1],t∈Z+t \in \mathbb{Z}^+t∈Z+。
进一步扩展 D 的特征更新公式如下:
Λ⋆ϕLD(t)⟶QD(t)⋆VB(t),\Lambda\star\phi_{L D}^{(t)}\ \longrightarrow\,{\cal Q}_{{\cal D}}^{(t)}\ \star\,\ V_{{\cal B}}^{(t)}\,, Λ⋆ϕLD(t) ⟶QD(t) ⋆ VB(t),
ΔϕD(t)=softmax(QD(t)⋅KA(t)Tτ⋅d)⋅VB(t).\Delta\phi_{D}^{(t)}=\mathrm{softmax}\left(\frac{\mathcal{Q}_{D}^{(t)}\cdot K_{A}^{(t)^{T}}}{\tau\cdot\sqrt{d}}\right)\cdot V_{B}^{(t)}. ΔϕD(t)=softmax(τ⋅dQD(t)⋅KA(t)T)⋅VB(t).
与传统公式不同,注意力图是通过查询图像 © 的查询向量和提示图像 (A) 的键向量计算得到的。查询向量包含 C 中每个空间位置的语义信息,而键向量提供了 A 中每个查询可以关注到的上下文信息。因此,注意力图中的每个元素与提示图像的特定区域相关联。这种公式化方法明确强化了查询图像与提示图像之间的上下文关系。此外,softmax 计算中的温度超参数 τ\tauτ 控制相关性的锐度。通过调整 τ\tauτ,可以调节模型对 C 和 A 之间注意力/相关性的关注程度:较低的 τ\tauτ 会锐化注意力,强调更强的相关性;较高的 τ\tauτ 会平滑注意力,使关注分布更广泛。
![Figure 3. Latent representations of the query and prompt images from the Stable Diffusion model's VAE encoder are transformed tothe noise space using [19]. Each noisy latent is iteratively denoised using the denoising U-Net. Prediction (D) path is initialized withthe noise space of C, and at each denoising step, the computations within the self-attention layers are modified to enhance visual ICLcapabilities. With the Query (from prompt image-A), the Key (from prompt groundtruth-B), and the Value (from query image-C) vectors,e b sid xa xo ssn n n emodel. This process is iteratively performed for T denoising steps to obtain the denoised prediction latent, which is then fed to the VAEdecoder to obtain the final prediction D.](https://i-blog.csdnimg.cn/img_convert/2357991836d020bde8c9ac905eb2947a.png)
我们还使用了来自不同潜在表示的值向量,这与标准的交叉注意力实现不同,目的是使预测结果与提示真值 B 的领域一致。这种方法替代了稳定扩散模型中标准的自注意力层计算,有助于明确注入查询图像与提示图像之间的上下文,同时改进任务推断。然而,修改默认自注意力计算以及使用从三个不同图像中提取的 Q、K、V 向量会产生领域差距,需要解决以提升预测质量。因此,我们采用了注意力图对比、交换引导和 AdaIN 机制等方法 [1]。
注意力图对比补充了温度超参数的功能,增强了对相关区域(即语义相似区域)的关注,同时减弱了对无关区域(即不相关对象之间的颜色相似性)的关注。此外,这一操作调整了值的尺度以适应预训练的稳定扩散流程。对比操作可表示为:
QD(t)⟶μ(QD(t))+β⋅(QD(t)−μ(QD(t))),Q_{D}^{(t)}\,\longrightarrow\,\mu(Q_{D}^{(t)})\,+\,\beta\cdot\Biggl({\cal Q}_{D}^{(t)}\,-\,\mu({\cal Q}_{D}^{(t)})\Biggr)\,, QD(t)⟶μ(QD(t))+β⋅(QD(t)−μ(QD(t))),
其中 μ\muμ 是均值操作,β\betaβ 是控制尺度的超参数。
交换引导源于 Ho 和 Salimans 提出的无分类器扩散引导实现 [17]。噪声预测的修改逐渐融入去噪进程,引导去噪过程通过稳定扩散生成流程中更密集的区域,从而减少不必要的伪影。噪声预测公式如下:
η(t)=ηdefault(t)+γ⋅(T−t)T⋅(ηmodified(t)−ηdefault(t)),\eta^{(t)}=\eta_{\mathrm{default}}^{(t)}+\frac{\gamma\cdot(T-t)}{T}\cdot\left(\eta_{\mathrm{modified}}^{(t)}-\eta_{\mathrm{default}}^{(t)}\right), η(t)=ηdefault(t)+Tγ⋅(T−t)⋅(ηmodified(t)−ηdefault(t)),
其中 γ\gammaγ 是控制尺度的超参数。
自适应实例归一化 (AdaIN) 由 Huang 和 Belongie 提出 [18],用于对齐预测 (D)(由查询图像 C 的噪声空间初始化)与最终真值/任务颜色空间(即 B 的颜色空间)之间的颜色分布。AdaIN 的实现如下:
LD(t)←LD(t)−μ(zD(t))σ(zD(t))⋅σ(zB(t))+μ(zB(t)),\mathcal{L}_{D}^{(t)}\ \leftarrow\,\frac{\mathcal{L}_{D}^{(t)}\,-\,\mu(\mathcal{z}_{D}^{(t)})}{\sigma(\mathcal{z}_{D}^{(t)})}\,\cdot\,\sigma(\mathcal{z}_{B}^{(t)})+\mu(\mathcal{z}_{B}^{(t)}), LD(t) ←σ(zD(t))LD(t)−μ(zD(t))⋅σ(zB(t))+μ(zB(t)),
其中 μ\muμ 和 σ\sigmaσ 分别是均值和标准差操作。
2.3. 隐式加权提示集成(IWPE)
Bar 等人 [3] 和 Xu 等人 [44] 的研究表明,为模型提供多个源-目标示例提示可以提升视觉上下文学习的预测性能。这些方法通过在输入层面上集成多个提示,将提示图像和对应的真实标签拼接成网格状结构,形成一个复合图像。然后将这个复合图像输入模型,期望模型能够利用多个提示的信息做出比单一提示场景更好的预测。然而,对于固定分辨率的基础模型,随着源-目标示例数量的增加,网格中每张图像的有效尺寸会减小。这会导致性能下降,主要原因是输入中的细节丢失 [44]。
为了解决这一问题,SegGPT [39] 提出了一种特征空间集成方法,而不是通过复合输入在图像空间中集成提示。在这种方法中,多个提示并行处理,并在每个注意力层的末尾通过平均特征进行聚合。这种方法假设所有示例提示的信息量相等,并在平均过程中对它们进行均匀加权。然而,这种均匀加权的提示方式并不是最优的,因为它阻止了模型从更相关的提示中获益。为此,我们提出了一种简单但有效的方法,通过将集成融入注意力计算中,允许提示块根据它们与每个查询块的对应关系进行隐式加权。具体来说,对于 n 个提示,我们重写公式 (7):
ΔϕD(t)=softmax(QC(t)⋅(⨁i=1nKAi(t))Tτ⋅d)⋅(⨁i=1nVBi(t)),\Delta\phi_{D}^{(t)}=\mathrm{softmax}\left(\frac{Q_{C}^{(t)}\cdot\left(\bigoplus_{i=1}^{n}K_{A_{i}}^{(t)}\right)^{T}}{\tau\cdot\sqrt{d}}\right)\cdot\left(\bigoplus_{i=1}^{n}V_{B_{i}}^{(t)}\right), ΔϕD(t)=softmaxτ⋅dQC(t)⋅(⨁i=1nKAi(t))T⋅(i=1⨁nVBi(t)),
其中①表示拼接操作,i 是每个提示的索引。
3. 实验与评估
为了展示所提议方法在不同任务上的泛化能力,我们在六个下游任务上对其进行了评估。对于所有这些任务,我们使用无监督提示检索 [47] 来选择提示图像的候选者。具体来说,该方法选择查询图像的最近邻作为提示候选者。最近邻检索基于 CLIP 视觉编码器 [26] 在查询图像和示例提示图像之间的嵌入余弦相似度。
为了公平比较,我们使用 Visual Prompting [3] 和 IMProv [44] 作为基线。尽管这些方法涉及训练步骤,但与 [38, 41] 不同,它们不依赖于来自相关域外任务的精心挑选或标注数据。此外,由于 IMProv 支持补充文本指导,我们在比较中包含了有文本指导和无文本指导的结果。同时,我们还评估并比较了多个提示的有效性。有关数据集、评估指标和不同超参数的敏感性分析的详细信息,请参阅补充材料。在以下小节的结果中,我们选择了一组为所有任务提供最佳性能的超参数。
3.1. 结果与分析
本文在表1中报告了所有六个任务的定量指标。所提出的方法在所有任务中始终优于现有的未经整理的方法。
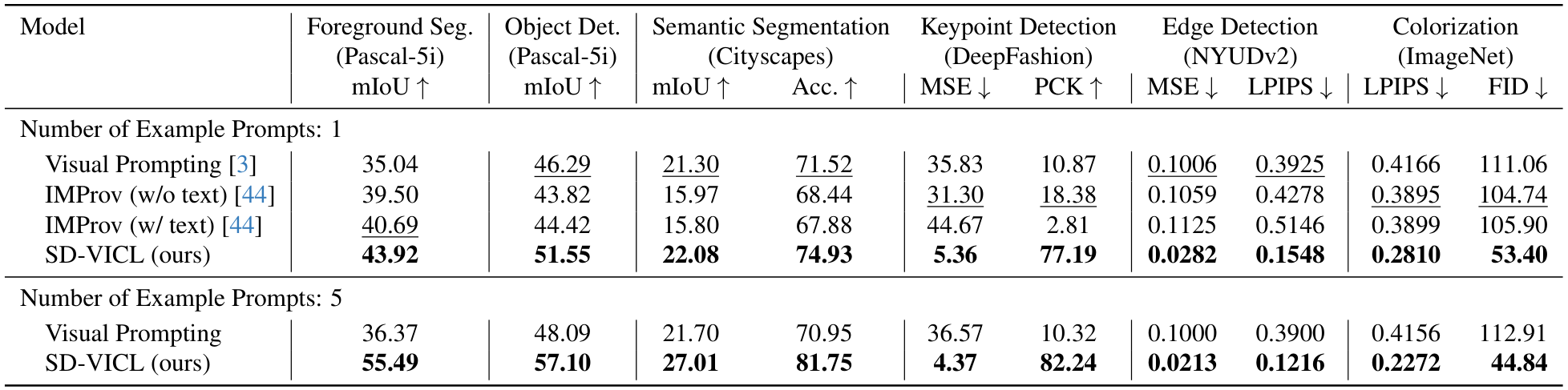
前景分割:使用单个提示,所提出的方法在Pascal-5i数据集[31]的所有分割中平均交并比(mIoU)分别比Visual Prompting和IMProv方法取得了8.9%和3.2%的绝对改进。使用重新调整用途的Stable Diffusion模型并结合五个提示的集成方法进一步将mIoU提高了11.6%(绝对值),相比于单个提示的情况。
单目标检测:与前景分割类似,使用单个提示,所提出的方法在Pascal-5i数据集[31]的所有分割中平均mIoU分别比Visual Prompting和IMProv提高了5.3%和7.1%(绝对值)。集成方法的使用相比单个提示的情况额外提高了5.6%。
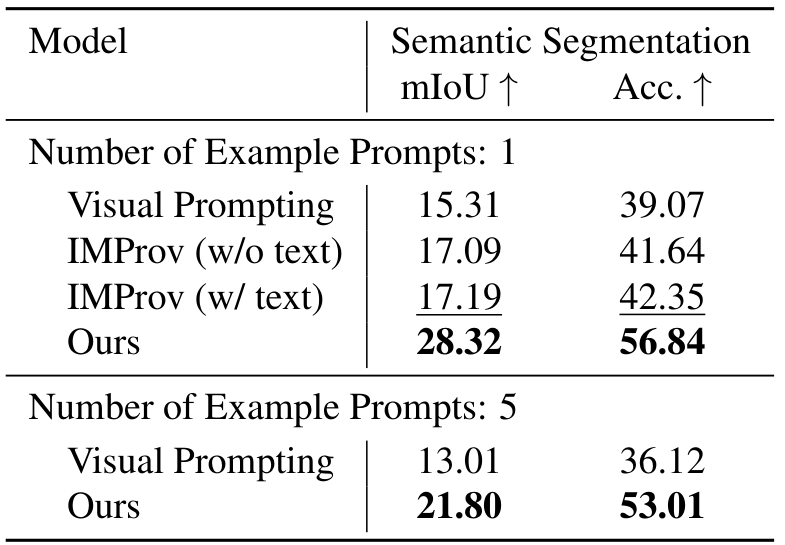
语义分割:在Cityscapes数据集[8]上,我们的单提示方法相比Visual Prompting在mIoU上取得了0.8%的绝对改进,在准确率上提高了3.4%。同样,相比IMProv,我们在mIoU上取得了6.1%的绝对增益,在准确率上提高了6.5%。使用IWPE,mIoU和准确率相比单提示方法进一步提高了4.9%和6.8%(绝对值)。在语义分割任务中,单提示方法相比其他任务(如前景分割和关键点检测)对现有方法的性能改进较低。然而,通过增加提示数量,提出的方法能够实现与其他任务相似的高收益。这种性能提升可以归因于两个关键因素:(1)多个提示通过缓解类间注意力模糊来帮助解决相似或重叠类别之间的冲突;(2)单个提示不太可能包含查询图像中多类别任务中可能存在的所有类别,在这种情况下,多个提示增加了模型获取所有相关类别以进行准确预测的概率。

关键点检测:在DeepFashion数据集[24]上的评估显示,我们的方法大幅改进,均方误差(MSE)降低了6倍,同时在最佳基准方法上实现了7倍的PCK。此外,使用五个提示进一步增强了这些指标,MSE和PCK分别获得了18.5%和6.5%的相对增益。
边缘检测:在NYUDv2数据集[32]上,我们的方法相比最佳现有方法将均方误差(MSE)降低了72.0%,LPIPS[46]降低了60.6%。值得注意的是,通过我们的提示集成方法,这些指标分别额外提高了24.5%和21.4%。
图像上色:在ImageNet数据集[29]上的评估显示,我们的模型相比次优的IMProv方法将LPIPS降低了27.9%,FID[16]降低了49.0%,并且在使用五个提示时分别进一步提高了19.1%和16.0%。
总体而言,我们的方法在所有任务中都以相当大的优势优于Visual Prompting和IMProv。此外,使用IWPE整合多个提示始终带来比单提示方法更高的性能改进。
3.2. 额外评估
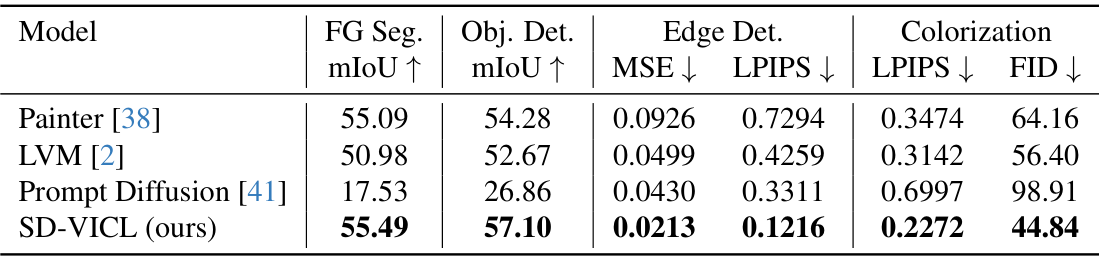
与基于任务相关数据训练的V-ICL模型的比较:为了提供全面的评估,我们将我们的无训练方法与之前明确基于任务相关数据训练的方法进行比较,包括Painter [38]、LVM [2] 和 Prompt Diffusion [41]。定量结果展示在表2中,定性比较展示在补充材料的图7中。尽管我们的方法没有进行任何明确的训练,但它在多个视觉任务中始终优于这三个基准模型。分析结果,我们观察到这三个模型都倾向于过拟合其训练任务,导致在新任务上的泛化能力较差。例如,尽管提示对定义的任务目标是边缘图,Painter 仍然错误地输出了深度图而不是边缘(详见补充材料图7)。此外,虽然 Painter 和 LVM 在前景分割和对象检测任务上表现良好,但当查询图像只包含单一类别时,它们在多类别场景中表现不佳,常常分割出所有类别而不是目标类别(详见补充材料图8a)。另外,LVM 在输出上表现出不一致性,对于给定任务,尽管输入的格式/领域保持不变,生成的输出却属于不同的领域(详见补充材料图8b)。此外,Prompt Diffusion 在大多数任务上表现尤为糟糕,经常生成错误的输出,唯一的例外是边缘检测——这是它在训练过程中接触过的任务。理想情况下,V-ICL 模型应从输入中推断上下文和任务,但这三个模型在这方面均有不足。相比之下,我们的无训练方法展示了卓越的泛化能力和有效的上下文及任务推断能力,符合 V-ICL 的预期,凸显了在无需额外训练的情况下揭示 V-ICL 属性的优势。有关详细讨论和视觉示例,请参阅补充材料的 Sec. E。
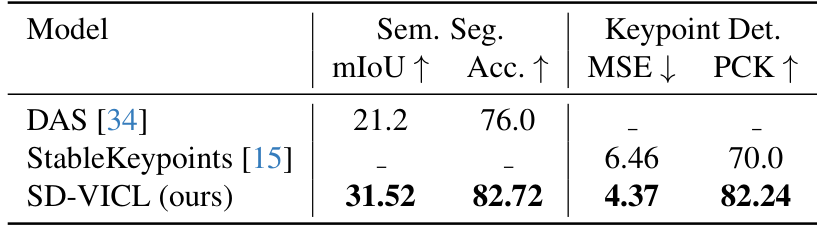
与基于Stable Diffusion的任务特定模型的比较:在这里,我们将我们的方法与适应 Stable Diffusion 以促进特定任务(如语义分割和关键点检测)的方法进行比较。DAS [34] 是一项提出了一种管道的工作,通过迭代聚合 Stable Diffusion 的自注意力层来预测每个类别的分割掩码,从而实现语义分割。类似地,StableKeypoints 通过将交叉注意力图浓缩为给定图像中的地标来实现关键点检测。我们在表3中展示了与这些任务特定模型的性能比较,我们的方法优于 [34] 和 [15]。对于语义分割,我们遵循 DAS 的评估协议(即匈牙利匹配)以确保公平比较,并在 mIoU 上实现了 10.3% 的绝对改进,在准确率上实现了 6.7% 的改进。在关键点检测中,我们超越了 StableKeypoints,MSE 降低了 32.4%,PCK 提高了 12.2%。虽然 DAS 和 StableKeypoints 在各自的任务中取得了强劲的结果,但它们仍然受到任务特定性质的限制。相比之下,我们的方法不仅提供了卓越的性能,而且在无需修改推理的情况下能够跨不同任务进行泛化。此外,与这些从中间特征或注意力图中得出预测的方法不同,我们的模型直接利用生成过程来产生输出,使其本质上更加灵活和有效。
3.3. 消融研究
在这一部分中,我们详细介绍了为展示关键设计选择重要性而进行的各种消融实验。具体来说,我们评估了隐式加权提示集成(Implicitly-Weighted Prompt Ensembling, IWPE)的有效性,并考察了提示数量对性能的影响。对于其他消融实验,包括替代注意力公式、超参数(如注意力温度、自注意力分辨率、对比强度、交换引导尺度以及AdaIN)的敏感性分析等,我们请读者参考补充材料中的第F节。
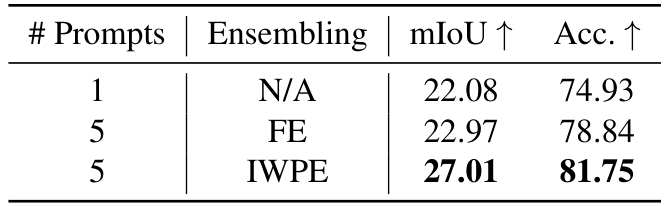
隐式加权提示集成(IWPE)的有效性: 在此,我们将我们提出的集成方法IWPE与SegGPT的特征集成(Feature Ensembling, FE)方法进行比较。对于除语义分割外的所有任务,我们观察到两种方法相较于单一提示场景均取得了相似的性能提升。然而,在语义分割任务中,IWPE显示出显著更好的性能。如表4所示,FE方法在mIoU和准确率上的绝对提升仅为0.9%和3.9%,而IWPE取得了显著的提升,相较于单一提示场景,mIoU提高了4.9%,准确率提高了6.8%。这种显著的改进归因于我们的集成方法能够根据查询图像与每个提示的相关性动态加权每个提示。相比之下,如前所述,特征集成方法假定所有提示的信息量相等,这种假设在涉及多类别任务(如语义分割)时是次优的。例如,一个提示可能与某个特定类别有较强的相关性,而另一个提示与该类别的关联较弱。我们的方法通过根据查询的相关性隐式加权不同提示的影响,更好地捕捉了这些细微差别,从而相较于SegGPT的均匀加权特征集成方法显著提升了性能。因此,尽管在提示信息量相等的简单任务中FE和IWPE表现相当,但我们的方法对于涉及复杂多类别结构的任务更为有益。
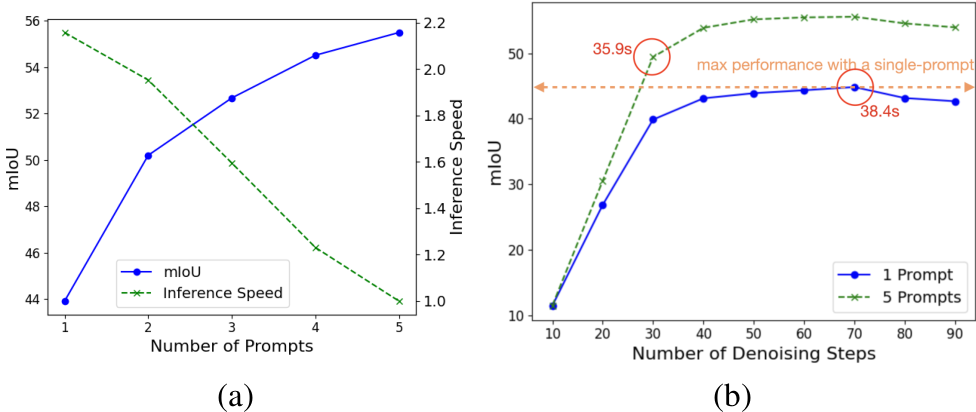
提示数量的影响: 在此,我们研究了提示数量对性能和推理速度的影响。如图5a所示,mIoU分数随着提示数量的增加而提高。这一结果可归因于模型能够有效利用多个提示来更好地推断任务并建立查询与提示之间的对应关系。额外的提示有助于减少使用单一提示时可能出现的歧义。然而,这些性能提升是以推理速度降低为代价的;具体来说,使用五个提示时,推理速度大约是单一提示时的一半。除了提示数量外,Stable Diffusion模型中的去噪步骤数量也是影响推理速度的关键因素。这引发了一个问题:在有多个提示可用时,模型是否需要与单一提示场景下一样多的去噪步骤?换句话说,我们探索了在提供多个提示的额外上下文时,是否可以减少一些去噪步骤而不影响性能。为此,我们进行了实验,评估了SD-VICL方法在不同去噪步骤下的表现。如图5b所示,在五个提示场景下,30个去噪步骤的mIoU已超过单一提示场景的最大性能。此外,单一提示场景的最大性能需要70个去噪步骤,推理时间为38.4秒,而五个提示场景在30个去噪步骤下仅需35.9秒即可实现更高的性能。
4. 结论
在本文中,我们提出了一种新颖的视觉上下文学习(visual in-context learning, V-ICL)流程,明确纳入了查询图像与提示(prompt)之间的上下文关系。与现有的视觉上下文学习方法不同,后者依赖于在精选或非精选数据上训练或微调基础模型以实现上下文学习,而我们的方法完全无需训练。具体来说,我们在现成的Stable Diffusion模型的自注意力层中引入了一种就地注意力重新计算(in-place attention re-computation)。此外,提出的隐式加权提示集成技术(implicitly-weighted prompt ensembling technique)通过基于相对对应关系隐式地对提示进行加权,促进了通过多个提示有效整合上下文。我们所提出方法的多样性通过其在六个不同任务上的成功泛化得到了证明,在这些任务中,它的表现优于在非精选和任务相关数据上训练的V-ICL模型,以及基于Stable Diffusion的任务特定模型。至关重要的是,我们的方法在不需要任何额外训练或标注的任务特定数据集的情况下实现了这些结果,凸显了其发掘和利用Stable Diffusion的V-ICL能力的能力。
A. 概述
本文档结构如下:
· 章节B:相关工作
· 章节C:实现细节
· 章节D:额外定量结果
· 章节E:关于在任务相关数据上训练的V-ICL模型的讨论
· 章节F:额外消融实验
· 章节G:局限性与未来工作
· 章节H:额外定性结果
B. 相关工作
在自然语言处理(NLP)领域,随着GPT-3 [5]及其后续模型 [7, 27, 33, 35] 等大规模语言模型的出现,上下文学习(In-context Learning, ICL)引起了广泛关注。这些模型展示了一种能力,即通过少量的源-目标示例(称为提示)进行条件化,无需梯度更新或微调即可执行任务,从而能够即时适应新任务 [13, 42]。ICL 在 NLP 中的成功激发了将其能力扩展到其他领域的兴趣,特别是在计算机视觉领域。
然而,将上下文学习的概念从 NLP 转移到计算机视觉面临独特挑战,这是由于图像的多样性以及视觉任务的固有复杂性所致。这导致了两种主要思想流派的出现,试图将 ICL 适应到计算机视觉中,称为视觉上下文学习(Visual In-context Learning, V-ICL)。
第一种方法是通过在未经整理的数据集上训练视觉基础模型来进行上下文学习,这些数据集由可能包含源图像及其对应目标的随机裁剪组成(例如,计算机视觉论文中的图形)。诸如 Visual Prompting [3] 和 IMProv [44] 的研究是这种方法的代表,它们基于 ViT 的 MAE-VQGAN 架构 [10, 14] 训练掩码补全任务。在推理过程中,这些方法通过将查询图像与提示示例拼接在一起,创建复合图像,形成带有预测占位符掩码的网格结构,供补全模型处理。虽然这些方法取得了令人瞩目的结果,但这种方法常常面临查询图像与提示之间的上下文推断较弱、预测分辨率较低以及整体预测质量较差的问题。
第二种思想流派旨在通过在经过整理/标注的任务相关数据集上训练视觉基础模型来提升预测性能。这种方法涉及训练或微调模型,但使用多个任务的成对源-目标图像作为训练数据。值得注意的例子包括 Painter [38]、Prompt Diffusion [41]、SegGPT [39]、Skeleton-In-Context [40] 和 Point-In-Context [11]。虽然 Painter 和 Prompt Diffusion 等模型针对相对多样的任务,但其他模型则专注于构建通用模型以适应特定任务,如分割、骨架序列建模或 3D 点云估计。尽管这些模型取得了改进的结果并为视觉上下文学习的未来研究提供了重要见解,但它们需要使用与域外任务相关的数据集更新模型权重。这反过来又意味着需要与我们试图适应的域外任务相关的训练数据。我们认为,这种理念偏离了 ICL 的核心原则,因为它们往往无法很好地泛化到与训练集无关的新任务,并且依赖于大量标注数据集。因此,这种方法在某种程度上削弱了 ICL 的基本理念,即强调无需重新训练或依赖大量标注数据集即可适应新任务的能力。
C. 实现细节
SD-VICL 实验设置
SD-VICL 实验基于现成的 Stable Diffusion 模型 [28],具体使用的是 v1.5 检查点。除非另有说明,我们在所有评估中使用了以下超参数:去噪时间步长 (T) = 70,注意力温度 (τ) = 0.4,对比强度 (β) = 1.67,以及交换引导尺度 (γ) = 3.5。此外,我们将 Stable Diffusion 管道的文本条件设置为一个空字符串,因此除了输入提示外不提供额外的引导。
比较基准
我们使用了公开的 Visual Prompting [3]、IMProv [44]、Painter [38]、LVM [2] 和 Prompt Diffusion [41] 的代码库和检查点来生成所有实验的结果。对于 IMProv 的文本引导变体,根据其论文中的说明,我们为模型提供一个包含位置和任务信息的字符串(例如“左 - 输入图像,右 - 前景/背景黑白分割”)。为了确保公平比较,包括我们的方法在内,所有方法都使用从 Zhang 等人 [47] 获得的相同提示集进行评估。
任务与数据集
以下是我们实验中用于评估的任务和数据集的详细信息:
- 前景分割:这是一个二值分割任务,预测图像中感兴趣对象(即前景)的二值掩码。提示的真实值是一张黑白图像,前景为白色,背景为黑色。评估使用 Pascal-5i 数据集 [31],该数据集包含 1864 张图像,分为 20 个对象类别。图像被分为四个子集,每个子集包含五个独特的类别。我们使用平均交并比 (mIoU) 作为评估指标。
- 单对象检测:此任务与前景分割任务类似,但预测的是感兴趣对象的边界框,而不是精确边界的掩码。对于此任务,提示的真实值是一张黑白图像,边界框为白色。我们使用与前景分割相同的数据集,但仅包括具有单个对象实例的图像,遵循 [3, 44]。选定的子集包含 1312 张图像,我们报告 mIoU 分数。
- 语义分割:此任务预测给定图像的每个像素的语义标签。我们遵循文献中的方法 [缺失引用],为每个类别分配等间距的独特颜色作为提示真实值。我们使用 Cityscapes 数据集 [8],该数据集包含 19 个类别(不包括空类别)。我们报告 mIoU 和像素准确率分数作为评估指标。
- 关键点检测:关键点检测任务涉及定位对象的关键点或标志点。在本研究中,我们专注于人体姿态关键点检测,预测 COCO [21] 中定义的 17 个关键点位置。由于提示真实值需要以图像形式呈现,我们创建了一张图像,以热图形式描绘关键点,如图 4 所示。每个热图通过在每个关键点中心叠加高斯分布创建。为了适应不同的空间尺度,我们对面部关键点(相对较细)应用较小方差的高斯分布,对身体关键点应用较大方差的高斯分布。这些关键点在两个颜色通道中可视化:面部关键点为红色,身体关键点为绿色,便于解码。评估时,遵循 Hedlin 等人 [15],我们使用 DeepFashion 数据集 [24],并报告均方误差 (MSE) 和正确关键点百分比 (PCK) 指标。
- 边缘检测:此任务的目标是预测图像中的边界和边缘。评估使用 NYUDv2 数据集 [32] 的验证集,包含 654 张图像。由于验证集没有真实值,我们使用 HED [43] 生成的软边缘图作为伪真实值。评估时,我们计算 HED 预测的边缘图与 V-ICL 预测之间的均方误差 (MSE) 和 LPIPS 损失 [46]。
- 图像上色:此任务的目标是为给定的灰度图像上色。类似于 [3, 44],我们从 ImageNet [29] 验证集中随机抽取 1000 张图像进行评估。我们计算原始彩色图像与上色预测之间的 LPIPS 损失和 FID 分数 [16],以评估感知相似性。
D. 附加定量结果
在表1中,我们展示了在Pascal-5i数据集的所有分割上,针对前景分割和单目标检测的平均性能,而在表5中,我们报告了每个分割的具体指标。
此外,在表1中,我们展示了在整个数据集上评估单目标检测的结果,以进行更全面的评估。然而,在表6中,我们遵循Bar等人[3]的方法,在Pascal-5i数据集的一个子集上评估单目标检测,排除了目标覆盖图像超过50%的图像。虽然我们观察到所有方法的绝对分数整体下降,但性能趋势与表1保持一致。正如Bar等人[3]所指出的,这种性能下降可以归因于较大目标通常比较小目标更容易检测。
此外,我们在COCOStuff数据集[21]上评估了语义分割,并在表7中报告了结果。与表2中观察到的趋势相反,在表2中,与单一提示相比,使用五个示例提示时性能有所提高,而在这种情况下,使用五个提示时性能却出现下降。经过分析,我们发现这种性能下降是由数据集中标签的不一致性引起的,这在推断多个提示的上下文时造成了混淆,从而对结果产生了负面影响。
E. 关于在任务相关数据上训练的V-ICL模型的讨论
正如主论文中所强调的,我们的工作首次提出了一种完全无需训练的范式,揭示了视觉基础模型的V-ICL(视觉上下文学习)特性。为了公平起见,主论文的第3.1节将我们的方法与视觉提示(Visual Prompting)[3] 和 IMProv [44] 进行了评估,因为它们在方法论上最为接近。虽然这些模型涉及训练,但它们是在未经整理的数据集上进行训练的,与Painter [38]、LVM [2] 和 Prompt Diffusion [41] 等在任务相关标注数据上训练的模型不同。
为了确保评估的完整性,我们扩展了对这些在任务相关数据上训练的V-ICL模型的评估。Painter 利用了基于ViT-Large [9] 的骨干网络,在多个标注数据集(如COCO [21]、ADE20K [48] 和 NYUv2 [32])上进行训练。LVM 基于OpenLLaMA的7B模型 [12] 构建,并在UVD-V1 [2] 数据集上训练,这是一个包含50个数据集的大型视觉语料库(例如LAION5B [30]),涵盖了标注、非标注和序列图像。Prompt Diffusion 是一种基于Stable Diffusion的生成模型,在三个前向任务(即图像到深度、图像到边缘、图像到分割)及其逆向变体上进行联合微调,使用视觉语言提示搭配图像和文本指导。训练是在Brooks等人 [4] 适配的数据集上进行的。

定量和定性比较结果分别在表2和图6中呈现。总体而言,我们观察到我们的方法在多个任务上优于所有三个基准模型。
我们注意到,这三个模型经常出现对训练任务的过拟合问题,导致在新任务上的泛化能力较差。尽管视觉上下文学习理想上应该从提示图像与其真实标签之间的关系中推断任务,但这些模型在这方面表现出了不足。
Painter 在简单任务(如前景分割和目标检测)上表现良好,尤其是在查询图像仅包含单一前景类别时(图6,第1行)。然而,在多类别场景中(图7a),Painter 会分割整个前景,而非专注于提示图像与其真实标签之间关系所定义的特定兴趣区域。此外,对训练任务的过拟合在图6的第3和第4行中表现明显,Painter 在语义分割中输出的分割图颜色方案与提示真实标签中定义的不同。同样,在关键点检测任务中,Painter 输出的是分割图而非关键点的热力图。此外,Painter 在图像上色任务中表现挣扎,常常直接输出灰度图像。在边缘检测任务中,Painter 输出的是深度图而非预期的边缘图(图6,第2行)。这种行为表明其对NYUv2数据集的过拟合,因为边缘图查询/提示图像与其训练期间用于深度估计的图像存在重叠。
LVM 也表现出类似限制,包括在多类别前景分割任务上的较差表现(图7a)、对训练任务的过拟合(图6,第4行)以及缺乏泛化能力。此外,LVM 的输出显示出不一致性,如图7b所示。具体来说,对于给定任务,尽管输入的格式/领域保持不变,但生成的输出属于不同的领域。例如,在前景分割中,虽然部分输出与前景分割一致,但其他输出却意外地属于不相关的领域,如关键点、分割图或RGB图像。这种不一致性凸显了LVM 尽管任务和输入格式不变,仍无法产生一致预测的缺陷。
Prompt Diffusion 虽然旨在通过视觉语言提示解锁上下文能力,但仍受限于其明确训练的六个任务。尽管它在边缘检测和分割等训练任务中表现相对较强,但在超出此范围的任务上表现挣扎。例如,Prompt Diffusion 在关键点检测、目标检测和图像上色任务中产生结构不一致的输出,无法与提示对所示的语义对齐。它还偶尔会产生错误的颜色、纹理或布局,尤其是在面对新任务类型或提示-查询领域细微变化时。
这些观察结果突显了Painter、LVM 和 Prompt Diffusion 在仅从输入提示中推断任务和上下文方面的共同局限性。它们对任务特定训练数据的依赖导致了过拟合,从而在新任务上的泛化能力较差。相比之下,我们提出的无需训练的方法展现了强大的泛化能力和有效的任务推断,凸显了在不进行额外训练的情况下揭示V-ICL特性的优势,以及所提出方法在明确从输入中推断上下文和任务方面的优越性,正如V-ICL的初衷。
F. 额外消融研究
在本文主要内容讨论的消融实验之外,我们还探索了替代注意力公式的影响以及其他几个因素的效果,包括温度超参数、自注意力层的分辨率、对比强度参数、交换引导尺度以及自适应实例归一化(AdaIN)。
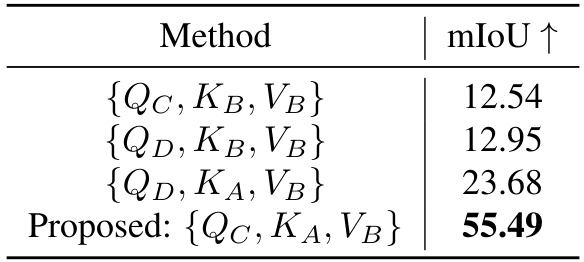
替代注意力公式:关于查询和提示之间的注意力公式,除了Eq. (7) 中描述的方法外,还可能存在多种替代方案。这些候选公式可以通过将 Eq. (7) 中的 QQQ 和 KKK 替换为以下集合中的对应元素来推导:{QD,KB}\{Q_D, K_B\}{QD,KB}、{QC,KB}\{Q_C, K_B\}{QC,KB} 和 {QD,KA}\{Q_D, K_A\}{QD,KA}。由于预测需要与提示的真实特征相对应,值向量 VVV 必须来自 BBB,不能替换为其他选项。图 8 展示了一部分替代公式的子集及其预测结果。表 8 中给出了这些候选公式的定量性能。然而,由于提示的真实值缺乏语义,这些公式(例如 {QD,KB,VB}\{Q_D, K_B, V_B\}{QD,KB,VB}、{QC,KB,VB}\{Q_C, K_B, V_B\}{QC,KB,VB})倾向于关注颜色相似性,而非推断潜在的语义关联。另一方面,我们可以像 Alaluf 等人 [1] 的方法一样,使用预测 DDD 自身的查询向量来构建注意力。在这种情况下,在早期去噪阶段的中间预测与我们公式的结果非常相似。然而,在后期去噪阶段,性能逐渐下降,因为预测逐渐趋向于缺乏语义的提示真实值,从而损害了预测性能。如图 8 和表 8 所示,提出的公式通过在每个去噪步骤中确保过程由查询和提示的潜在特征引导,表现出色,保留了更好的上下文和任务推断所需的必要语义。

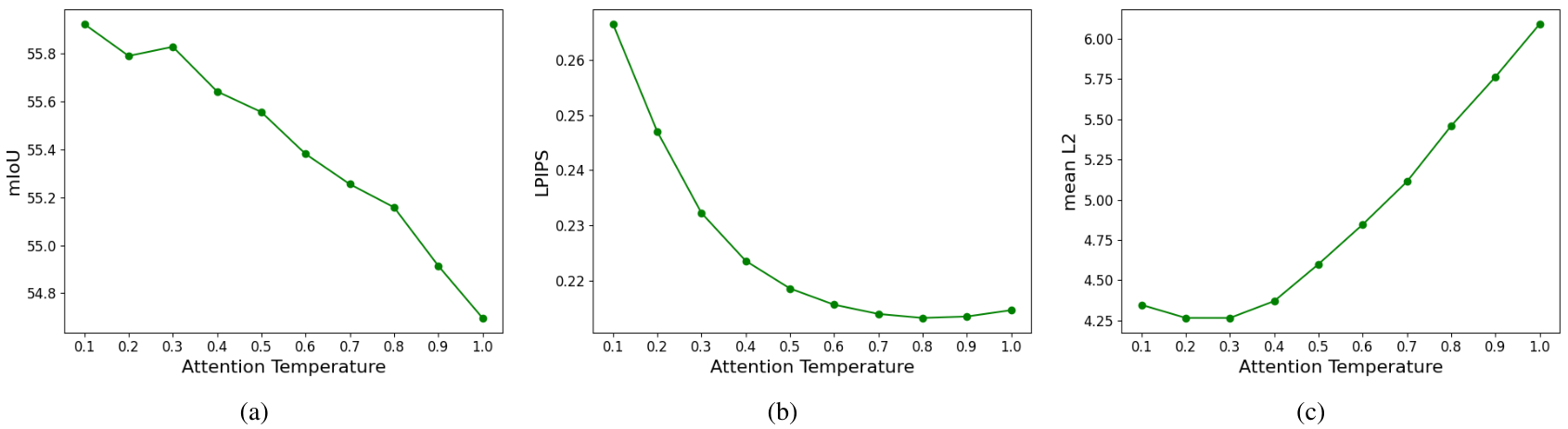
温度超参数 TTT:如 Eq. (7) 所示,我们在注意力计算中引入了温度超参数 TTT,以控制查询图像和提示图像之间patch对应关系的锐度。虽然我们对所有任务使用恒定的温度超参数(即 T=0.4T = 0.4T=0.4)以保持泛化能力,但我们研究了 TTT 对一些代理任务性能的影响。我们观察到最优温度参数随任务而异,具体结果如图 9 所示。
对比强度 β\betaβ 和交换引导尺度 γ\gammaγ 超参数:我们从 Alaluf 等人 [1] 的方法中改进了注意力图对比(Eq. (8))和交换引导(Eq. (9))方法,以解决使用来自不同域的多张图像(即源图像和目标图像属于不同域)所引入的域差距。虽然我们使用了 [1] 中提出的超参数值(即 β=1.67\beta = 1.67β=1.67,γ=3.5\gamma = 3.5γ=3.5),但我们以前景分割为代理任务研究了它们对性能的影响。图 10 展示了性能随对比强度和交换引导尺度的变化情况。当对比强度大于 1.0 并启用交换引导时,性能有显著提升。
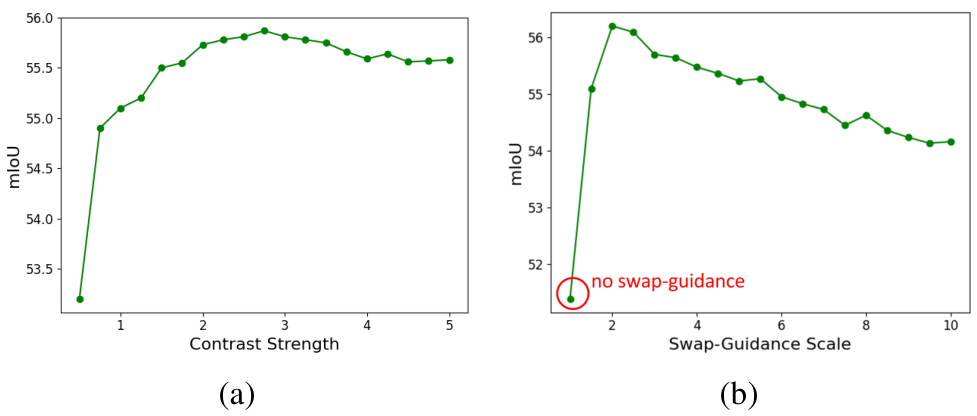

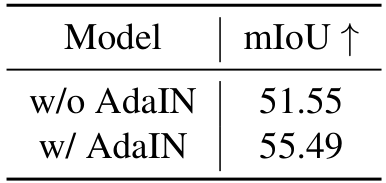
自适应实例归一化(AdaIN):如第 2.2 节所述,我们使用 AdaIN 来对齐预测 DDD(由查询图像 CCC 的噪声空间初始化)与期望的真实颜色空间(即 BBB 的颜色空间)之间的颜色分布。图 11 展示了有无 AdaIN 的对比示例,表 9 列出了前景分割的整体性能。引入 AdaIN 后性能有明显提升。
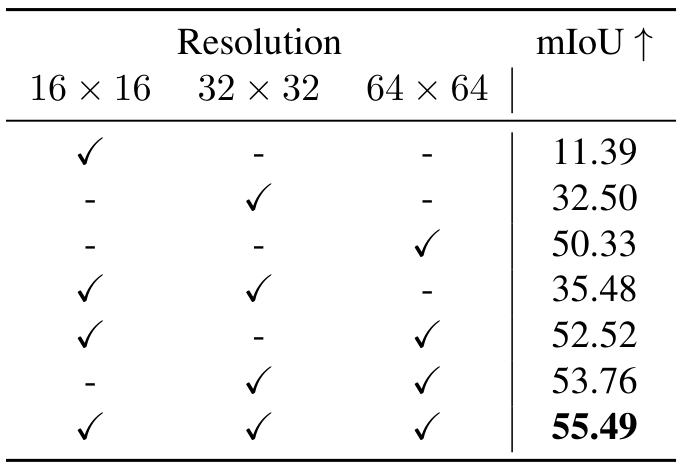
注意力层分辨率:Stable Diffusion 管道中的去噪 U-Net 在多个分辨率下包含自注意力层:16×1616 \times 1616×16、32×3232 \times 3232×32 和 64×6464 \times 6464×64。因此,我们可以将提出的就地注意力重构应用于这些层的任意组合。我们评估了这些分辨率的各种组合,结果列于表 10。此外,图 12 提供了每种组合的定性性能比较。在所有分辨率下修改自注意力层时取得了最佳性能。这是直观的,因为它在多个粒度上聚合了对应关系,从而形成了更全面的表示。在我们的所有实验中,除非特别说明,否则我们使用所有分辨率的自注意力层。
G. 局限性与未来工作
我们的方法与其他基于扩散的方法一样,主要局限在于推理时间较长。在本研究中,我们的重点在于探索稳定扩散(Stable Diffusion)的V-ICL属性,而对计算效率的关注较少。我们认为,首先建立一个稳健且可泛化的框架至关重要,而效率优化则是未来工作的重要方向。特别是,集成更快的扩散技术(如文献[23, 45]所述),这些技术可以在不牺牲输出质量的情况下实现高达100倍的加速,可能显著降低推理成本。

另一个局限性是,与其他V-ICL方法相同,我们的方法对噪声提示(noisy prompts)较为敏感。由于V-ICL方法依赖少量的视觉示例来推断上下文和任务,提示对的不准确可能会导致性能下降。尽管我们通过隐式加权提示集成(implicitly-weighted prompt ensembling)和注意力温度调节(attention temperature scaling)部分缓解了这一问题,但如何进一步提高对噪声或模糊提示的鲁棒性仍是一个开放性挑战。
最后,将我们的方法扩展到时间域,通过将其适应于视频生成模型,是一个有前景的方向。这样的扩展可能实现无需训练的视频任务视觉上下文学习(visual in-context learning),从而进一步拓宽我们框架的适用性。
解决这些局限性可以显著提升视觉上下文学习系统的实用性和通用性。
H. 额外的定性结果
我们为每个任务提供了额外的定性示例,包括前景分割、单个对象检测、语义分割、关键点检测、边缘检测和着色,分别展示在图13至图18中。






Original Abstract: Large language models (LLM) in natural language processing (NLP) have
demonstrated great potential for in-context learning (ICL) – the ability to
leverage a few sets of example prompts to adapt to various tasks without having
to explicitly update the model weights. ICL has recently been explored for
computer vision tasks with promising early outcomes. These approaches involve
specialized training and/or additional data that complicate the process and
limit its generalizability. In this work, we show that off-the-shelf Stable
Diffusion models can be repurposed for visual in-context learning (V-ICL).
Specifically, we formulate an in-place attention re-computation within the
self-attention layers of the Stable Diffusion architecture that explicitly
incorporates context between the query and example prompts. Without any
additional fine-tuning, we show that this repurposed Stable Diffusion model is
able to adapt to six different tasks: foreground segmentation, single object
detection, semantic segmentation, keypoint detection, edge detection, and
colorization. For example, the proposed approach improves the mean intersection
over union (mIoU) for the foreground segmentation task on Pascal-5i dataset by
8.9% and 3.2% over recent methods such as Visual Prompting and IMProv,
respectively. Additionally, we show that the proposed method is able to
effectively leverage multiple prompts through ensembling to infer the task
better and further improve the performance.
PDF Link: 2508.09949v1
部分平台可能图片显示异常,请以我的博客内容为准
