【RL第七篇】PPO训练策略,如何使PPO训练稳定?
一、前言
PPO的基础可以在前面看一下:
从基础概念->策略梯度->RLOO->GAE->TRPO->PPO
之后如何让PPO训练稳定,也是个巨大的命题。会有很多trick,这次聊一下。
主要读这个,写的很全面:
- https://arxiv.org/pdf/2307.04964

这个博客不会把论文中的各种交融实验花太多的篇幅来讲,主要是把各种策略都列出来,具体的结果,可以直接训练中感受~
二、训练可能出现的问题
RL训练非常常见的一个问题是:训练崩溃。
Policy Model被过度优化,通过一些特殊策略去欺骗reward系统,拿到高分,实际上且和我们的需求不符。
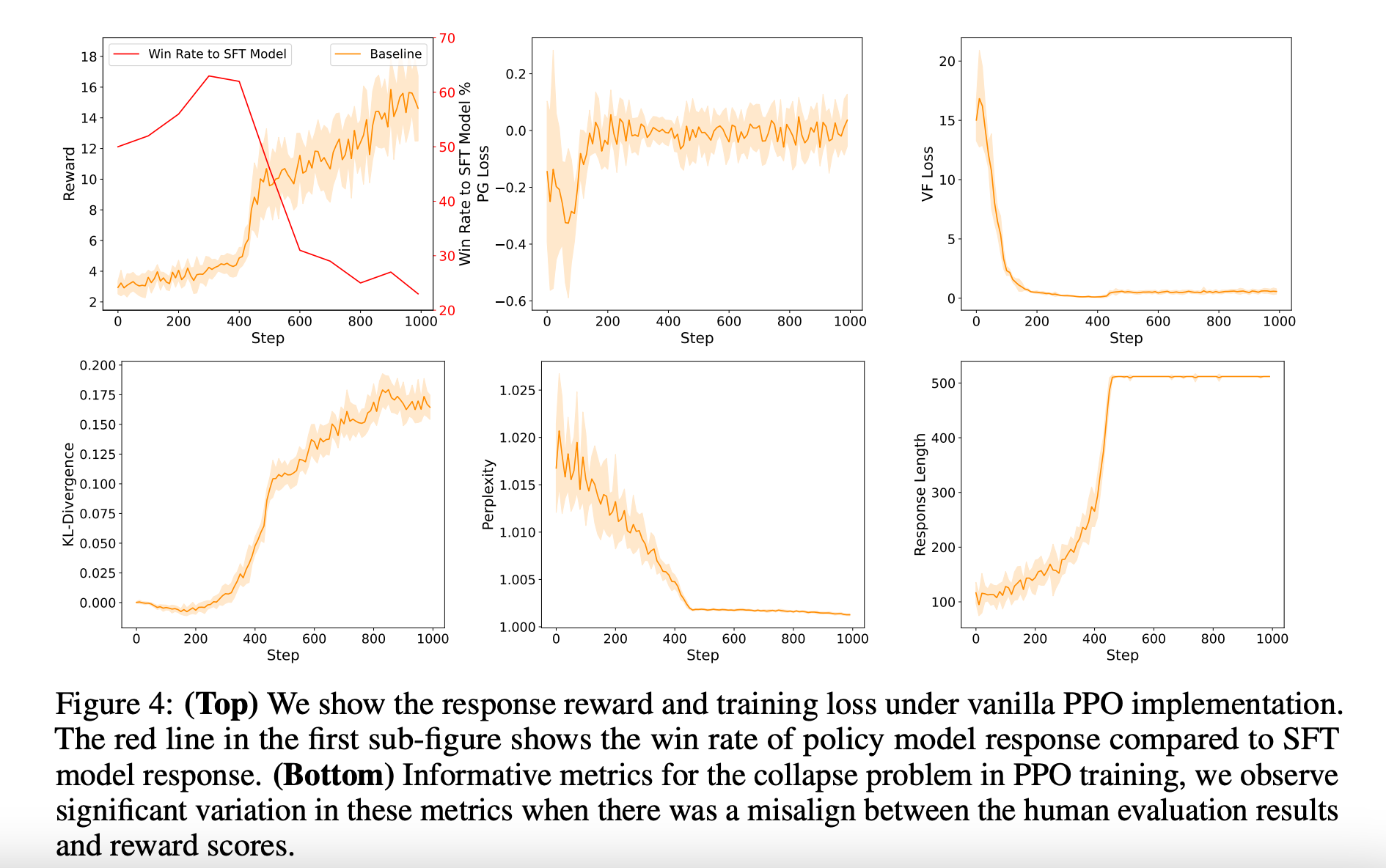
红色线表示winrate sft模型,sft模型就是我们要优化的policy模型,这里展现的是winrate在降低而reward持续提升,表示当前的评估和reward score趋势表现的不一致,就可能是目前这种情况导致的。
其实从使用一个随机的子训练集的reward score分布也可以看出一些端倪,会出现和之前old policy模型不一样的特征情况:
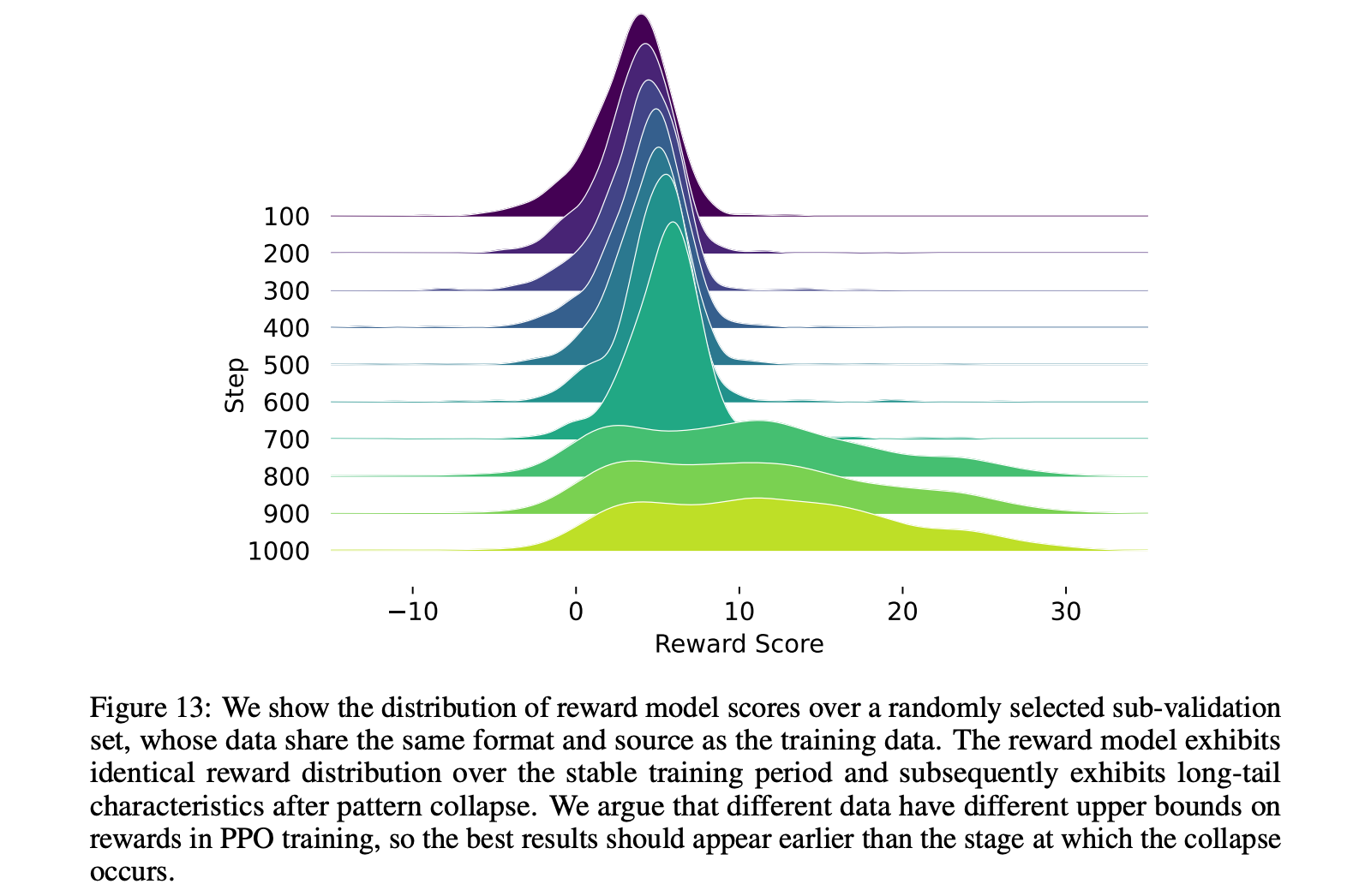
所以大概RL训练出现崩溃的步数在700左右的位置。
三、PPO-MAX
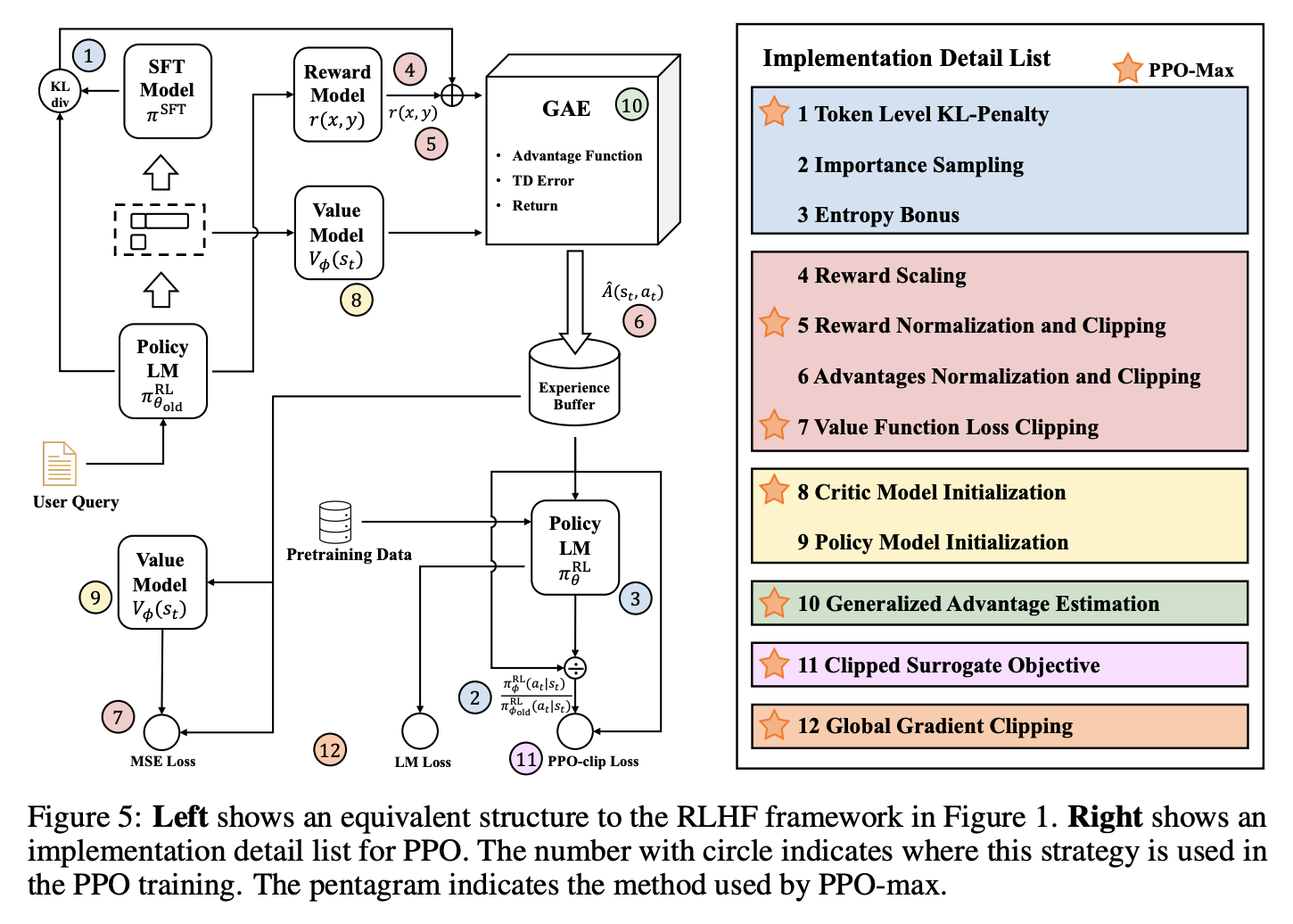
其中右侧的表示各种PPO训练稳定性的trick。其中PPO-MAX是包含了带五角星的trick的架构,可以提供一组支持稳定优化的实现情况
3.1 参数重置
用 {r(x,y)}≜{rn(x,y)}n=1B\{ r(x,y)\} \triangleq \{ r_n(x,y)\} _{n = 1}^{\mathcal{B}}{r(x,y)}≜{rn(x,y)}n=1B 表示训练中的奖励序列,rn(x,y)r_n(x,y)rn(x,y) 表示每批奖励的结果。
σ(A)\sigma(A)σ(A) 和 Aˉ\bar{A}Aˉ 分别表示变量 AAA 的均值和标准差
奖励缩放(Reward Scaling)
rn(x,y)=rn(x,y)/σ(r(x,y))
r_n(x,y) = r_n(x,y)/\sigma(r(x,y))
rn(x,y)=rn(x,y)/σ(r(x,y))
奖励归一化与裁剪(Reward Normalization and Clipping)
r~(x,y)=clip(rn(x,y)−r(x,y)‾σ(r(x,y)),−δ,δ)
\tilde{r}(x, y)=\operatorname{clip}\left(\frac{r_n(x, y)-\overline{r(x, y)}}{\sigma(r(x, y))},-\delta, \delta\right)
r~(x,y)=clip(σ(r(x,y))rn(x,y)−r(x,y),−δ,δ)
优势归一化与裁剪(Advantages Normalization and Clipping)
A~=clip(A−A‾σ(A),−δ,δ) \tilde{A}=\operatorname{clip}\left(\frac{A-\overline{A}}{\sigma(A)},-\delta, \delta\right) A~=clip(σ(A)A−A,−δ,δ)
区别在于 优势函数只在minibatch范围
消融实验
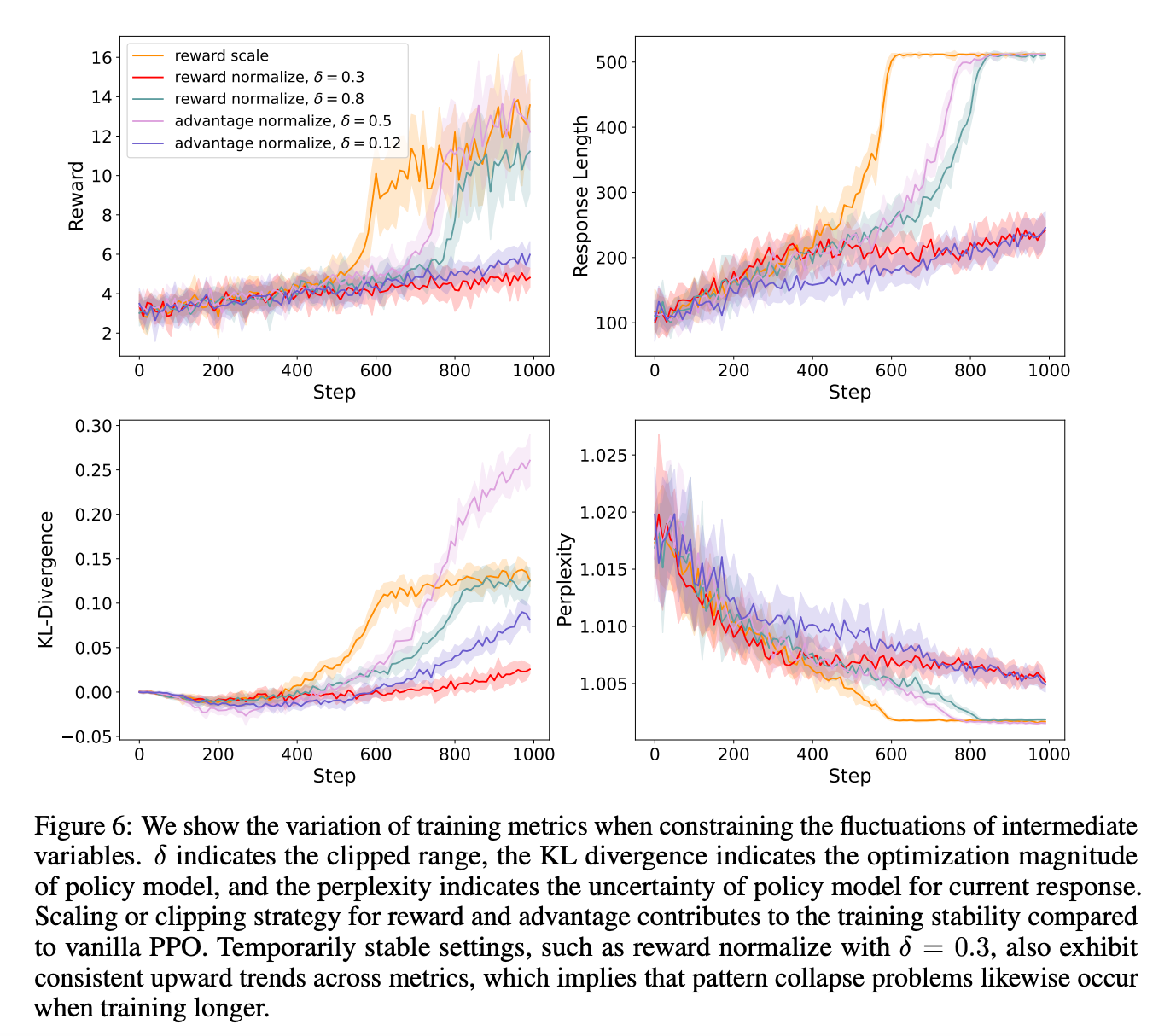
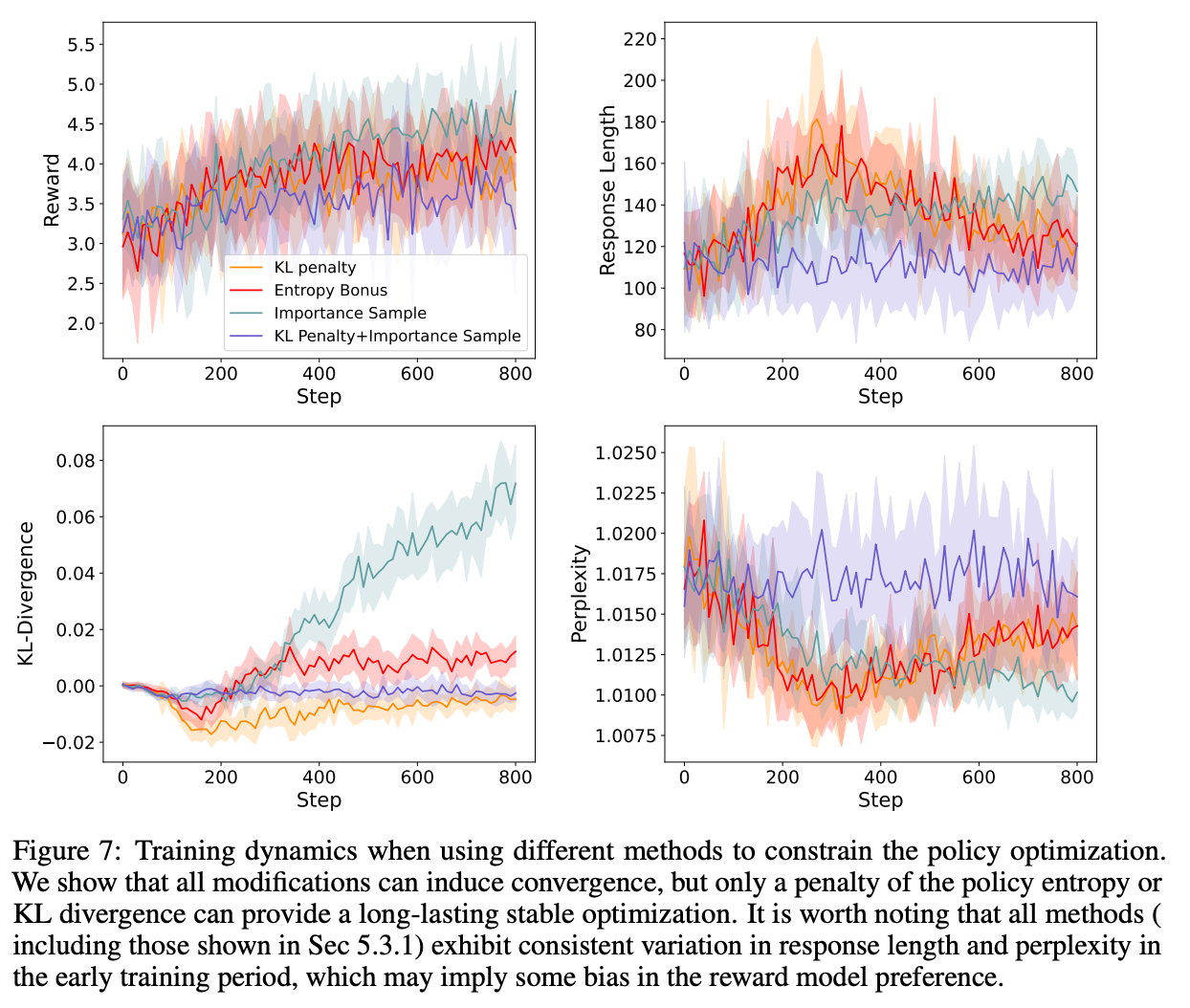
3.2 策略限制
token level的KL散度惩罚:
rtotal(x,yi)=r(x,yi)−ηKL(πθRL(yi∣x),πRef(yi∣x)), r_{\text{total}}(x, y_i) = r(x, y_i) - \eta \text{KL} \big( \pi_\theta^{\text{RL}}(y_i \mid x), \pi^{\text{Ref}}(y_i \mid x) \big), rtotal(x,yi)=r(x,yi)−ηKL(πθRL(yi∣x),πRef(yi∣x)),
Entropy Bonus
利用交叉熵的loss来代表策略的探索性
LENTROPY=−∑xp(x)logp(x) L_{\text{ENTROPY}} = -\sum_{x} p(x) \log p(x) LENTROPY=−x∑p(x)logp(x)
消融实验
3.3 预训练初始化
一个常见的设置是用参考模型和奖励模型初始化策略和评论家模型。
直接看结果:
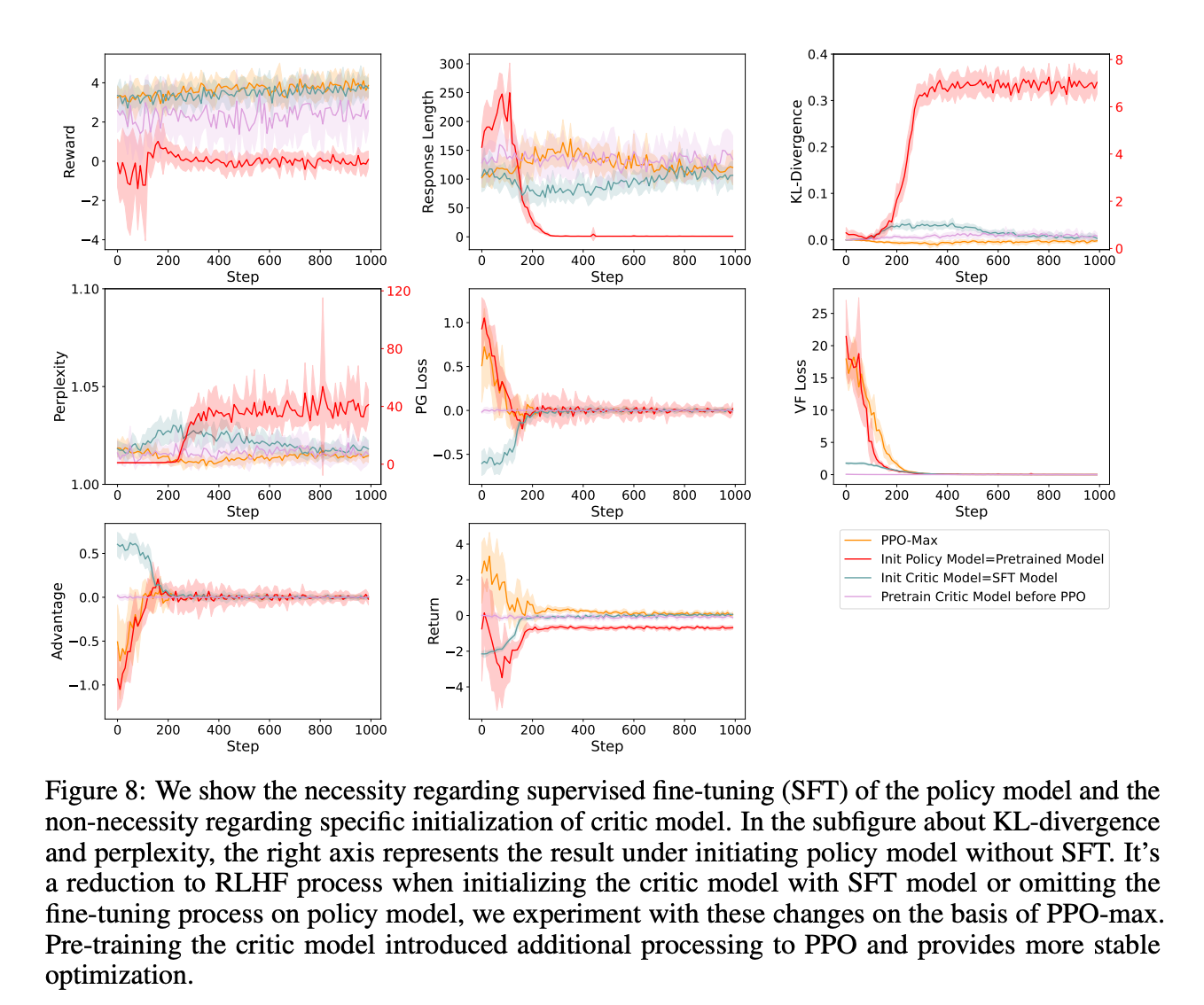
Critic Model Initialization
- 用SFT模型初始化critic模型,并随机初始化其奖励头。
- 只优化奖励模型,直到值损失预测函数接近零。
基于实验结果,论文认为critic预训练提供更好的优势估计,有助于提高训练的稳定性。用reward model或SFT model作为critic将收敛到类似的结果,这意味着PPO可以自适应地提供拟合优势函数的能力。
Policy Model Initialization
Policy用pretrain的模型,而不是sft后的模型,效果可以看到非常差,相当于没用微调,直接从pretrain到与人类偏好对齐了。