从策略梯度到 PPO
在强化学习中,常用参数化策略 πθ(a∣s)\pi_\theta(a\mid s)πθ(a∣s) 来表示智能体的行为策略。目标是最大化策略下的期望回报。
1. 轨迹与策略的概率分布
定义一个(随机)轨迹
τ=(s0,a0,r0,s1,a1,r1,…,sT) \tau=(s_0,a_0,r_0,s_1,a_1,r_1,\dots,s_{T}) τ=(s0,a0,r0,s1,a1,r1,…,sT)
轨迹在参数化策略下的概率为
pθ(τ)=p(s0)∏t=0T−1πθ(at∣st) p(st+1∣st,at). p_\theta(\tau)=p(s_0)\prod_{t=0}^{T-1}\pi_\theta(a_t\mid s_t)\,p(s_{t+1}\mid s_t,a_t). pθ(τ)=p(s0)t=0∏T−1πθ(at∣st)p(st+1∣st,at).
其中环境动力学 p(st+1∣st,at)p(s_{t+1}\mid s_t,a_t)p(st+1∣st,at) 与初始态分布 p(s0)p(s_0)p(s0) 不依赖于 θ\thetaθ。
定义轨迹的回报:
R(τ)=∑t=0T−1γtrt, R(\tau)=\sum_{t=0}^{T-1}\gamma^{t} r_t, R(τ)=t=0∑T−1γtrt,
策略的目标(期望回报)为:
J(θ)=Eτ∼pθ[R(τ)]. J(\theta)=\mathbb{E}_{\tau\sim p_\theta}[R(\tau)]. J(θ)=Eτ∼pθ[R(τ)].
2. 对参数的梯度
对 J(θ)J(\theta)J(θ) 求梯度:
∇θJ(θ)=∇θ∫pθ(τ)R(τ) dτ=∫R(τ)∇θpθ(τ) dτ=∫R(τ)pθ(τ)∇θlogpθ(τ) dτ=Eτ∼pθ[R(τ)∇θlogpθ(τ)]. \begin{aligned} \nabla_\theta J(\theta) &=\nabla_\theta \int p_\theta(\tau) R(\tau)\,d\tau = \int R(\tau)\nabla_\theta p_\theta(\tau)\,d\tau\\ &= \int R(\tau) p_\theta(\tau)\nabla_\theta\log p_\theta(\tau)\,d\tau = \mathbb{E}_{\tau\sim p_\theta}\big[R(\tau)\nabla_\theta\log p_\theta(\tau)\big]. \end{aligned} ∇θJ(θ)=∇θ∫pθ(τ)R(τ)dτ=∫R(τ)∇θpθ(τ)dτ=∫R(τ)pθ(τ)∇θlogpθ(τ)dτ=Eτ∼pθ[R(τ)∇θlogpθ(τ)].
该积分是勒贝格积分。展开 logpθ(τ)\log p_\theta(\tau)logpθ(τ):
logpθ(τ)=logp(s0)+∑t=0T−1(logπθ(at∣st)+logp(st+1∣st,at)). \log p_\theta(\tau)=\log p(s_0)+\sum_{t=0}^{T-1}\big(\log\pi_\theta(a_t\mid s_t)+\log p(s_{t+1}\mid s_t,a_t)\big). logpθ(τ)=logp(s0)+t=0∑T−1(logπθ(at∣st)+logp(st+1∣st,at)).
因为 p(s0)p(s_0)p(s0) 和 p(st+1∣st,at)p(s_{t+1}\mid s_t,a_t)p(st+1∣st,at) 不依赖 θ\thetaθ,它们的梯度为零,于是
∇θlogpθ(τ)=∑t=0T−1∇θlogπθ(at∣st). \nabla_\theta\log p_\theta(\tau)=\sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t). ∇θlogpθ(τ)=t=0∑T−1∇θlogπθ(at∣st).
代入上式得:
∇θJ(θ)=Eτ∼pθ[R(τ)∑t=0T−1∇θlogπθ(at∣st)]=∑t=0T−1Eτ∼pθ[R(τ)∇θlogπθ(at∣st)]. \nabla_\theta J(\theta) = \mathbb{E}_{\tau\sim p_\theta}\Big[R(\tau)\sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\Big] = \sum_{t=0}^{T-1}\mathbb{E}_{\tau\sim p_\theta}\big[R(\tau)\nabla_\theta\log\pi_\theta(a_t\mid s_t)\big]. ∇θJ(θ)=Eτ∼pθ[R(τ)t=0∑T−1∇θlogπθ(at∣st)]=t=0∑T−1Eτ∼pθ[R(τ)∇θlogπθ(at∣st)].
3. 用 reward-to-go / baseline 减少方差(REINFORCE→策略梯度定理)
把整个轨迹的总回报 R(τ)R(\tau)R(τ) 替换为从时间 ttt 开始的reward-to-go
Gt≜∑t′=tT−1γt′−trt′.
G_t \triangleq \sum_{t'=t}^{T-1}\gamma^{t'-t} r_{t'}.
Gt≜t′=t∑T−1γt′−trt′.
那么:
∇θJ(θ)=Eτ∼pθ[∑t=0T−1∇θlogπθ(at∣st) Gt].
\nabla_\theta J(\theta)=\mathbb{E}_{\tau\sim p_\theta}\Big[\sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,G_t\Big].
∇θJ(θ)=Eτ∼pθ[t=0∑T−1∇θlogπθ(at∣st)Gt].
这是 REINFORCE 的无偏估计器,使用 GtG_tGt(而非整条轨迹回报)通常能显著降低方差,因为 GtG_tGt 与在时间 ttt 之前的动作无关。
为了进一步降低方差,可以引入 baseline b(st)b(s_t)b(st)(只依赖状态),利用恒等:
Ea∼πθ[∇θlogπθ(at∣st) b(st)]=b(st)Ea∼πθ[∇θlogπθ(at∣st) ]=b(st)∫πθ(at∣st)∇θlogπθ(at∣st) =b(st)∫∇θπθ(at∣st) =b(st)∇θEa∼πθπθ(at∣st)=0. \begin{aligned} &\mathbb{E}_{a\sim \pi_\theta}\Big[\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,b(s_t)\Big] \\ &=b(s_t)\mathbb{E}_{a\sim \pi_\theta}\Big[\nabla_\theta \log\pi_\theta(a_t\mid s_t)\,\Big] \\ &=b(s_t) \int\pi_\theta(a_t\mid s_t) \nabla_{\theta} log\pi_\theta(a_t\mid s_t)\,\\ &=b(s_t) \int \nabla_{\theta} \pi_\theta(a_t\mid s_t)\,\\ &=b(s_t)\nabla_{\theta}\mathbb{E}_{a\sim \pi_\theta}\pi_\theta(a_t\mid s_t) \\ &=0. \end{aligned} Ea∼πθ[∇θlogπθ(at∣st)b(st)]=b(st)Ea∼πθ[∇θlogπθ(at∣st)]=b(st)∫πθ(at∣st)∇θlogπθ(at∣st)=b(st)∫∇θπθ(at∣st)=b(st)∇θEa∼πθπθ(at∣st)=0.
加入该项后:
∇θJ(θ)=Eτ∼pθ[∑t=0T−1∇θlogπθ(at∣st) (Gt−b(st))]. \nabla_\theta J(\theta)=\mathbb{E}_{\tau\sim p_\theta}\Big[\sum_{t=0}^{T-1}\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,(G_t - b(s_t))\Big]. ∇θJ(θ)=Eτ∼pθ[t=0∑T−1∇θlogπθ(at∣st)(Gt−b(st))].
常见的选择是b(st)=Vπθ(st)b(s_t)=V^{\pi_\theta}(s_t)b(st)=Vπθ(st),定义优势函数:
Aπθ(st,at)=Gt−b(st)
A^{\pi_\theta}(s_t,a_t)=G_t-b(s_t)Aπθ(st,at)=Gt−b(st)
将对轨迹τ\tauτ的采样转换为对每个时间步ttt对应的(st,at)(s_t,a_t)(st,at)的采样,那么:
∇θJ(θ)=∑tEst∼dπθ, at∼πθ[∇θlogπθ(at∣st) Aπθ(st,at)], \nabla_\theta J(\theta) =\sum_t\mathbb{E}_{s_t\sim d^{\pi_\theta},\,a_t\sim\pi_\theta}\big[\nabla_\theta\log\pi_\theta(a_t\mid s_t)\,A^{\pi_\theta}(s_t,a_t)\big], ∇θJ(θ)=t∑Est∼dπθ,at∼πθ[∇θlogπθ(at∣st)Aπθ(st,at)],
其中 dπθd^{\pi_\theta}dπθ 是策略 πθ\pi_\thetaπθ 下的状态访问分布.
4. 重要性采样(off policy)
在强化学习中,训练数据依赖于当前策略 πθ\pi_\thetaπθ,参数更新后需要重新采样。为了复用旧策略 πθ′\pi_{\theta'}πθ′ 收集的轨迹,可用重要性采样修正分布。
一般重要性采样公式:
Ex∼p(x)[f(x)]=∫f(x)p(x)dx=∫f(x)p(x)q(x)q(x)dx=Ex∼q(x)[f(x)p(x)q(x)]
E_{x\sim p(x)}[f(x)]=\int f(x)p(x)dx=\int f(x)\frac{p(x)}{q(x)}q(x)dx=E_{x\sim q(x)}[f(x)\frac{p(x)}{q(x)}]
Ex∼p(x)[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q(x)[f(x)q(x)p(x)]
替换θ\thetaθ为θ′\theta^{\prime}θ′:
Est∼dπθ, at∼πθ[Aθ(st,at)∇logpθ(atn∣stn)]=∫pθ(st,at)[Aθ(st,at)∇logpθ(atn∣stn)]=∫pθ′(st,at)[pθ(st,at)pθ′(st,at)Aθ(st,at)∇logpθ(atn∣stn)]=∫pθ′(st,at)[pθ(at∣st)pθ′(at∣st)pθ(st)pθ′(st)Aθ(st,at)∇logpθ(atn∣stn)]
\begin{aligned}
&\mathbb{E}_{s_t\sim d^{\pi_\theta},\,a_t\sim\pi_\theta}[A^{\theta}(s_{t},a_{t})\nabla logp_{\theta}(a_{t}^{n}|s_{t}^{n})] \\
&=\int p_{\theta}(s_{t},a_{t})[A^{\theta}(s_{t},a_{t})\nabla logp_{\theta}(a_{t}^{n}|s_{t}^{n})] \\
&=\int p_{\theta^{\prime}}(s_{t},a_{t})[\frac{p_{\theta}(s_{t},a_{t})}{p_{\theta^{\prime}}(s_{t},a_{t})}A^{\theta}(s_{t},a_{t})\nabla logp_{\theta}(a_{t}^{n}|s_{t}^{n})] \\
&=\int p_{\theta^{\prime}}(s_{t},a_{t})[\frac{p_{\theta}(a_{t}|s_{t})}{p_{\theta^{\prime}}(a_{t}|s_{t})}\frac{p_{\theta}(s_{t})}{p_{\theta^{\prime}}(s_{t})}A^{\theta}(s_{t},a_{t})\nabla logp_{\theta}(a_{t}^{n}|s_{t}^{n})] \\
\end{aligned}
Est∼dπθ,at∼πθ[Aθ(st,at)∇logpθ(atn∣stn)]=∫pθ(st,at)[Aθ(st,at)∇logpθ(atn∣stn)]=∫pθ′(st,at)[pθ′(st,at)pθ(st,at)Aθ(st,at)∇logpθ(atn∣stn)]=∫pθ′(st,at)[pθ′(at∣st)pθ(at∣st)pθ′(st)pθ(st)Aθ(st,at)∇logpθ(atn∣stn)]
由于奖励函数的取值不会变化,即Aθ(st,at)=Aθ′(st,at)A^{\theta}(s_{t},a_{t})=A^{\theta^{\prime}}(s_{t},a_{t})Aθ(st,at)=Aθ′(st,at),此外,假设dπθd^{\pi_\theta}dπθ与dπθ′d^{\pi_\theta^{\prime}}dπθ′很接近,有pθ(st)≈pθ′(st)p_{\theta}(s_t)\approx p_{\theta^{\prime}}(s_t)pθ(st)≈pθ′(st),那么,
∫pθ′(st,at)[pθ(at∣st)pθ′(at∣st)pθ(st)pθ′(st)Aθ(st,at)∇logpθ(atn∣stn)]≈∫pθ′(st,at)[pθ(at∣st)pθ′(at∣st)Aθ′(st,at)∇logpθ(atn∣stn)]=∫pθ′(st,at)[∇pθ(at∣st)pθ′(at∣st)Aθ′(st,at)]
\begin{aligned}
&\int p_{\theta^{\prime}}(s_{t},a_{t})[\frac{p_{\theta}(a_{t}|s_{t})}{p_{\theta^{\prime}}(a_{t}|s_{t})}\frac{p_{\theta}(s_{t})}{p_{\theta^{\prime}}(s_{t})}A^{\theta}(s_{t},a_{t})\nabla logp_{\theta}(a_{t}^{n}|s_{t}^{n})] \\
&\approx \int p_{\theta^{\prime}}(s_{t},a_{t})[\frac{p_{\theta}(a_{t}|s_{t})}{p_{\theta^{\prime}}(a_{t}|s_{t})}A^{\theta^{\prime}}(s_{t},a_{t})\nabla logp_{\theta}(a_{t}^{n}|s_{t}^{n})] \\
&= \int p_{\theta^{\prime}}(s_{t},a_{t})[\frac{\nabla p_{\theta}(a_{t}|s_{t})}{p_{\theta^{\prime}}(a_{t}|s_{t})}A^{\theta^{\prime}}(s_{t},a_{t})] \\
\end{aligned}
∫pθ′(st,at)[pθ′(at∣st)pθ(at∣st)pθ′(st)pθ(st)Aθ(st,at)∇logpθ(atn∣stn)]≈∫pθ′(st,at)[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)∇logpθ(atn∣stn)]=∫pθ′(st,at)[pθ′(at∣st)∇pθ(at∣st)Aθ′(st,at)]
此时对应的优化目标是:
Jθ′(θ)=∑tEst∼dπθ′, at∼πθ′[pθ(at∣st)pθ′(at∣st)Aθ′(st,at)]
\begin{aligned}J^{\theta^{\prime}}(\theta)&=\sum_t\mathbb{E}_{s_t\sim d^{\pi_{\theta'}},\,a_t\sim\pi_\theta'}[\frac{p_{\theta}(a_{t}|s_{t})}{p_{\theta^{\prime}}(a_{t}|s_{t})}A^{\theta^{\prime}}(s_{t},a_{t})] \end{aligned}Jθ′(θ)=t∑Est∼dπθ′,at∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]
5. PPO 的目标函数
设 θk\theta^kθk 为收集数据时的旧参数,优势估计为 Aθk(st,at)A^{\theta^k}(s_t,a_t)Aθk(st,at)。
(A)带 KL 惩罚的形式
一种做法是在 surrogate 上加 KL 惩罚:
LKL(θ)=∑tEst∼dπθ, at∼πθ[πθ(at∣st)πθk(at∣st)Aθk(st,at)]−β Es∼dπθk[KL(πθk(⋅∣s) ∥ πθ(⋅∣s))]
L^{\text{KL}}(\theta)=\sum_t\mathbb{E}_{s_t\sim d^{\pi_\theta},\,a_t\sim\pi_\theta}\Big[ \frac{\pi_\theta(a_t\mid s_t)}{\pi_{\theta^k}(a_t\mid s_t)} A^{\theta^k}(s_t,a_t)\Big]- \beta\,\mathbb{E}_{s\sim d^{\pi_{\theta^k}}}\big[\mathrm{KL}\big(\pi_{\theta^k}(\cdot\mid s)\,\|\,\pi_{\theta}(\cdot\mid s)\big)\big]
LKL(θ)=t∑Est∼dπθ,at∼πθ[πθk(at∣st)πθ(at∣st)Aθk(st,at)]−βEs∼dπθk[KL(πθk(⋅∣s)∥πθ(⋅∣s))]
通过调节 β\betaβ 控制新旧策略的距离.
(B)裁剪(clipped)形式
PPO 中最常用的是裁剪目标(不显式计算 KL):
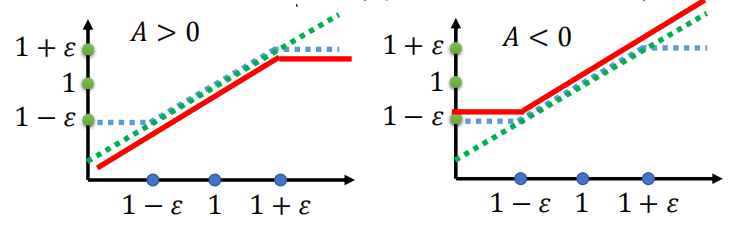
LCLIP(θ)=∑tEst∼dπθ, at∼πθ[min(rt(θ)At, clip(rt(θ),1−ϵ,1+ϵ) At)], L^{\text{CLIP}}(\theta) = \sum_t\mathbb{E}_{s_t\sim d^{\pi_\theta},\,a_t\sim\pi_\theta}\Big[ \min\big( r_t(\theta) A_t,\ \ \mathrm{clip}(r_t(\theta),1-\epsilon,1+\epsilon)\,A_t \big) \Big], LCLIP(θ)=t∑Est∼dπθ,at∼πθ[min(rt(θ)At, clip(rt(θ),1−ϵ,1+ϵ)At)],
其中 rt(θ)=πθ(at∣st)πθk(at∣st)r_t(\theta)=\dfrac{\pi_\theta(a_t\mid s_t)}{\pi_{\theta^k}(a_t\mid s_t)}rt(θ)=πθk(at∣st)πθ(at∣st),AtA_tAt 为 Aθk(st,at)A^{\theta^k}(s_t,a_t)Aθk(st,at)的简写。
裁剪的直观意义:当 rt(θ)r_t(\theta)rt(θ) 在 [1−ϵ,1+ϵ][1-\epsilon,1+\epsilon][1−ϵ,1+ϵ] 内,目标就和原始 surrogate 一致;当 rtr_trt 超出范围时,裁剪会限制它带来的收益,从而惩罚过大的策略更新,保证更新“近端”。