Words or Vision Do Vision-Language Models Have Blind Faith in Text
Words or Vision: Do Vision-Language Models Have Blind Faith in Text?
Authors: Ailin Deng, Tri Cao, Zhirui Chen, Bryan Hooi
Deep-Dive Summary:
视觉还是文字:视觉-语言模型是否对文本有盲目信任?
摘要
视觉-语言模型(Vision-Language Models, VLMs)在整合视觉和文本信息以完成以视觉为中心的任务方面表现出色,但它们在处理模态间不一致性时的表现尚未被充分探索。我们研究了当视觉数据与不同的文本输入在以视觉为中心的场景中出现不一致时,VLMs 的模态偏好。通过对四个以视觉为中心的任务引入文本变化,并评估了十个视觉-语言模型(VLMs),我们发现了一种“对文本的盲目信任”现象:当出现不一致时,VLMs 过度信任文本数据而非视觉数据,导致在文本受损的情况下性能显著下降,并引发了安全隐患。我们分析了影响这种文本偏见的因素,包括指令提示、语言模型规模、文本相关性、词序以及视觉和文本确定性之间的相互作用。虽然某些因素,如扩大语言模型规模,可以稍微缓解文本偏见,但其他因素,如词序,可能由于继承自语言模型的位置偏见而加剧这种现象。为了解决这一问题,我们探索了带文本增强的监督微调,并证明了其在减少文本偏见方面的有效性。此外,我们提供了一个理论分析,表明对文本的盲目信任现象可能源于训练过程中纯文本数据与多模态数据的不平衡。我们的发现强调了在 VLMs 中需要平衡训练和仔细考虑模态交互,以增强其在处理多模态数据不一致性时的鲁棒性和可靠性。
1. 引言
随着视觉-语言模型(Vision-Language Models, VLMs)的兴起[4, 9, 24],这些模型越来越多地被应用于复杂的多模态任务中,例如检索增强生成(Retrieval-Augmented Generation, RAG)[41]和多模态代理(Multi-Modal Agents)[12, 17, 19]。在这些实际场景中,模型需要处理大量、上下文丰富的跨模态输入。然而,视觉和文本输入之间常常存在不一致性,因为额外的文本数据可能无关甚至具有误导性[35]。尽管VLMs在以视觉为中心的基准测试中表现出色[15, 44, 45],但它们在处理此类不一致性方面的能力仍未被充分探索。这一差距促使我们开展研究,因为理解和解决VLMs在这些条件下的倾向对于它们在现实世界多模态环境中的安全可靠应用至关重要。
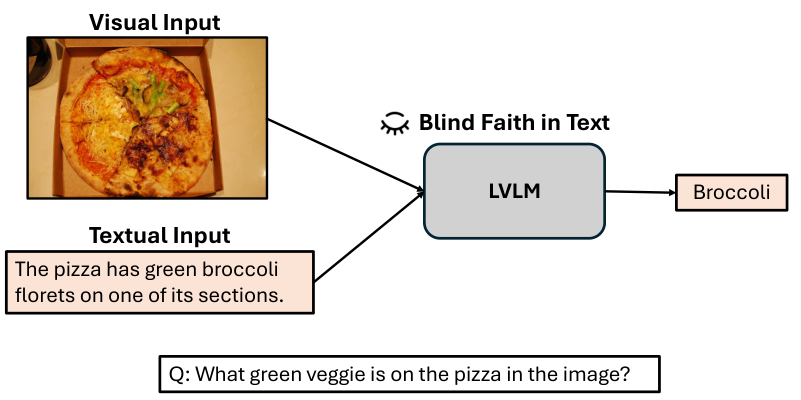
在本研究中,我们探讨了一个开放但未被充分研究的问题:VLMs如何处理视觉和文本输入之间的不一致性?这一问题驱动我们调查以下几个方面:
- 模态偏好:当视觉和语言数据之间存在不一致时,VLMs更倾向于哪种模态?
- 对文本扰动的鲁棒性:面对损坏的文本数据时,这些模型能否在以视觉为中心的任务中保持性能?
- 影响因素:哪些因素会影响VLMs的模态偏好?
为解决这些问题,我们通过对四项以视觉为中心的任务引入文本变体,构建了一个全面的基准测试,并评估了十个VLMs,包括专有模型和开源模型。我们的研究结果揭示了一个我们称之为“对文本的盲目信任”(Blind Faith in Text)的现象:当视觉和文本输入之间出现不一致时,VLMs倾向于过度信任文本数据,即使这些数据与视觉证据相矛盾。这种文本偏见不仅在文本损坏时导致显著的性能下降,还在实际应用中引发了潜在的安全问题。
我们进一步通过研究影响文本偏见的因素深入探讨了这一问题:
- 指令提示:虽然指令可以适度调整模态偏好,但其效果有限。
- 语言模型规模:扩大语言模型规模可以略微缓解文本偏见,但在更大模型中效果趋于饱和。
- 文本相关性:随着文本相关性的增加,对文本数据的偏好也会增强。
- 词序:将文本token置于图像token之前会加剧文本偏见,这可能是由于语言模型继承的位置偏见。
- 单模态确定性:视觉和文本确定性之间的相互作用会影响模态偏好。
为了缓解文本偏见,我们探索了通过文本增强进行监督微调的方法,并证明了即使在数据有限的情况下也具有有效性。此外,我们提供了一个理论分析,表明“对文本的盲目信任”现象可能源于训练过程中纯文本数据和多模态数据的不平衡,因为VLMs是建立在主要以文本数据训练的大型语言模型之上的。我们的贡献总结如下:
- 我们揭示了“对文本的盲目信任”现象,即当上下文中出现不一致时,VLMs更倾向于语言数据而非视觉数据。
- 我们证实,这种文本偏见在文本损坏的情况下会导致显著的性能下降,即使是在VLMs通常表现出色的以视觉为中心的任务中。
- 我们确定了影响文本偏见的关键因素,包括指令提示、语言模型规模、文本相关性、词序和单模态确定性。
- 我们证明了通过文本增强进行监督微调可以有效减少文本偏见。
- 我们提供了一个理论分析,指出训练过程中纯文本数据和多模态数据的不平衡可能是导致“对文本的盲目信任”现象的原因。
2. 预备知识
在本文中,给定一个由参数 θ\thetaθ 参数化的模型 fvlm(⋅;θ)f_{\mathrm{vlm}}(\cdot;\theta)fvlm(⋅;θ),一个样本 X:=(I,T,Q)X := (I, T, Q)X:=(I,T,Q) 包含图像 III、文本信息 TTT 和问题 QQQ,对应的真实答案为 YYY。我们可以在三种条件下获取答案:(1) 仅基于图像;(2) 仅基于文本信息;(3) 同时基于图像和文本信息:
Y^img:=fvlm(Q,I;θ),Y^txt:=fvlm(Q,T;θ),Y^mix:=fvlm(Q,I,T;θ).\begin{array}{l} {\hat{Y}_{\mathrm{img}} := f_{\mathrm{vlm}}(Q, I; \theta),} \\ {\hat{Y}_{\mathrm{txt}} := f_{\mathrm{vlm}}(Q, T; \theta),} \\ {\hat{Y}_{\mathrm{mix}} := f_{\mathrm{vlm}}(Q, I, T; \theta).} \end{array} Y^img:=fvlm(Q,I;θ),Y^txt:=fvlm(Q,T;θ),Y^mix:=fvlm(Q,I,T;θ).
生成确定性:响应生成的确定性可以通过响应序列的长度归一化预测似然来估计。形式化地表示为:
P~(Y˙∣X;θ):=(∏i=1∣Y˙∣p(Y˙i∣X,Y˙<i;θ))1∣Y˙∣,\tilde{P}(\dot{Y} \mid X; \theta) := \left( \prod_{i=1}^{|\dot{Y}|} \mathrm{p}(\dot{Y}_{i} \mid X, \dot{Y}_{<i}; \theta) \right)^{\frac{1}{|\dot{Y}|}}, P~(Y˙∣X;θ):=i=1∏∣Y˙∣p(Y˙i∣X,Y˙<i;θ)∣Y˙∣1,
其中 Y˙i\dot{Y}_iY˙i 表示 Y˙\dot{Y}Y˙ 的第 iii 个 token,Y˙<i\dot{Y}_{<i}Y˙<i 表示在 Y˙\dot{Y}Y˙ 中第 iii 个 token 之前生成的 token。通过分别考虑每个模态的确定性,我们可以计算单模态确定性(Uni-Modal Certainty)来量化每个模态的生成不确定性。具体来说,仅基于图像或文本计算如下:
Pimg:=P~(Y^img∣Q,I;θ),Ptxt:=P~(Y^txt∣Q,T;θ).\begin{array}{l} {P_{\mathrm{img}} := \tilde{P}(\hat{Y}_{\mathrm{img}} \mid Q, I; \theta),} \\ {P_{\mathrm{txt}} := \tilde{P}(\hat{Y}_{\mathrm{txt}} \mid Q, T; \theta).} \end{array} Pimg:=P~(Y^img∣Q,I;θ),Ptxt:=P~(Y^txt∣Q,T;θ).
2.1. 文本变体
为了全面研究文本变体的影响,我们考虑了三种类型的变体:匹配(Match)、损坏(Corruption)和无关(Irrelevance)的情况,给定问题 QQQ 和原始真实答案 YYY:
- 匹配(Match):我们将匹配文本记为 TmT_mTm,使得 (Tm,Q)(T_m, Q)(Tm,Q) 的真实答案为 YYY,表明文本提供了充分且相关的信息,仅基于文本即可正确回答问题。
- 损坏(Corruption):我们将损坏文本记为 TcT_cTc,使得 (Tc,Q)(T_c, Q)(Tc,Q) 的真实答案为 Yc≠YY_c \neq YYc=Y,表明文本是相关的且足以回答问题,但仅依赖文本时会导致不同的答案。
- 无关(Irrelevance):我们将无关文本记为 TirrT_{irr}Tirr(即 Tirr⊥I,QT_{irr} \perp I, QTirr⊥I,Q),表明文本信息与图像和问题均无关,因此仅依赖文本时不足以回答问题。
从基础集合 B={(I,Q)}B = \{(I, Q)\}B={(I,Q)} 开始,我们通过添加每种文本类型作为上下文,衍生出三个变体集合:Qm={(I,Tm,Q)}Q_m = \{(I, T_m, Q)\}Qm={(I,Tm,Q)},Qc={(I,Tc,Q)}Q_c = \{(I, T_c, Q)\}Qc={(I,Tc,Q)},以及 Qirr={(I,Tirr,Q)}Q_{irr} = \{(I, T_{irr}, Q)\}Qirr={(I,Tirr,Q)}。
这些情况的动机是考察模型如何处理不同类型的文本:匹配文本评估模型对相关信息的使用,损坏文本评估模型对误导信息的处理能力,无关文本则检查模型忽略干扰信息的能力。包含匹配文本还可以防止模型简单地拒绝所有文本,这种情况在之前的研究 [40] 中可能发生(如果仅使用无关或损坏文本)。这些情况共同提供了视觉语言模型(VLM)在不同文本输入下的全面性能视图。
2.2. 模型行为
在同时提供视觉和语言信息的情况下,我们将模型行为分为三种情况:(1) 与图像答案一致(Y^mix=Y^img\hat{Y}_{\mathrm{mix}} = \hat{Y}_{\mathrm{img}}Y^mix=Y^img);(2) 与文本答案一致(Y^mix=Y^txt\hat{Y}_{\mathrm{mix}} = \hat{Y}_{\mathrm{txt}}Y^mix=Y^txt);(3) 其他情况(Y^mix∉{Y^img,Y^txt}\hat{Y}_{\mathrm{mix}} \notin \{\hat{Y}_{\mathrm{img}}, \hat{Y}_{\mathrm{txt}}\}Y^mix∈/{Y^img,Y^txt})。为了更好地理解模型在视觉和语言数据不一致时的行为,我们在实证分析中仅考虑图像答案与文本答案不同的情况(即 Y^img≠Y^txt\hat{Y}_{\mathrm{img}} \neq \hat{Y}_{\mathrm{txt}}Y^img=Y^txt,基于精确匹配)。形式化地,对于问题集合 Q∈{Qm,Qc,Qirr}Q \in \{Q_m, Q_c, Q_{irr}\}Q∈{Qm,Qc,Qirr},图像答案、文本答案和其他答案的比例分别为 pimgp_{\mathrm{img}}pimg、ptxtp_{\mathrm{txt}}ptxt 和 pop_opo,计算如下:
pimg:=∣{X∈S∣Y^mix=Y^img}∣∣S∣,ptxt:=∣{X∈S∣Y^mix=Y^txt}∣∣S∣,po:=∣{X∈S∣Y^mix∉{Y^img,Y^txt}}∣∣S∣,\begin{array}{c} {p_{\mathrm{img}} := \displaystyle\frac{|\{X \in S \mid \hat{Y}_{\mathrm{mix}} = \hat{Y}_{\mathrm{img}}\}|}{|S|},} \\ {p_{\mathrm{txt}} := \displaystyle\frac{|\{X \in S \mid \hat{Y}_{\mathrm{mix}} = \hat{Y}_{\mathrm{txt}}\}|}{|S|},} \\ {p_{\mathrm{o}} := \displaystyle\frac{|\{X \in S \mid \hat{Y}_{\mathrm{mix}} \notin \{\hat{Y}_{\mathrm{img}}, \hat{Y}_{\mathrm{txt}}\}\}|}{|S|},} \end{array} pimg:=∣S∣∣{X∈S∣Y^mix=Y^img}∣,ptxt:=∣S∣∣{X∈S∣Y^mix=Y^txt}∣,po:=∣S∣∣{X∈S∣Y^mix∈/{Y^img,Y^txt}}∣,
其中 S={X∈Q∣Y^img≠Y^txt}S = \{X \in Q \mid \hat{Y}_{\mathrm{img}} \neq \hat{Y}_{\mathrm{txt}}\}S={X∈Q∣Y^img=Y^txt},因为我们仅考虑图像答案与文本答案不一致的情况。
2.3. 指标
文本偏好比率 (TPR)。我们定义 TPR 来量化模型对文本回答相对于图像回答的偏好。其计算公式如下:
TPR:=ptxtptxt+pimg.\mathrm{TPR}:=\frac{p_{\mathrm{txt}}}{p_{\mathrm{txt}}+p_{\mathrm{img}}}. TPR:=ptxt+pimgptxt.
TPR 通过展示模型在文本和视觉信息不一致时选择文本的可能性来指示文本偏见。较高的 TPR 反映出更强的文本偏见。
准确率 (Accuracy)。对于任意问题集 QQQ,我们有:
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: …\rfloor_{}^{}.
宏准确率 (Macro Accuracy)。宏准确率 Macro(f)Macro(f)Macro(f) 是模型 fff 在不同文本变体问题集上的平均准确率:
Macro(fvlm):=13(Acc(fvlm;Qm)+Acc(fvlm;Qc)+Acc(fvlm;Qir)).\mathrm{Macro}(f_{\mathrm{vlm}}):=\frac{1}{3}(\mathrm{Acc}(f_{\mathrm{vlm}};Q_{m})+\mathrm{Acc}(f_{\mathrm{vlm}};Q_{c})+\mathrm{Acc}(f_{\mathrm{vlm}};Q_{\mathrm{ir}})). Macro(fvlm):=31(Acc(fvlm;Qm)+Acc(fvlm;Qc)+Acc(fvlm;Qir)).
归一化准确率 (Normalized Accuracy)。归一化准确率 Norm(fvlm;Q)Norm(f_{vlm}; Q)Norm(fvlm;Q) 衡量模型受文本变异影响的程度,与基础准确率(即模型在基础问题集 BBB 上的准确率)进行比较。对于任意文本变体下的问题集 QQQ,我们通过以下公式计算相应的归一化准确率:
KaTeX parse error: Undefined control sequence: \mit at position 10: \mathrm{\̲m̲i̲t̲{N}(s t r n}(s_…
文本构建
给定图像、问题和答案,您的任务是:
- 生成一个准确的描述(描述 1),可以在不使用图像的情况下正确回答问题。
- 生成一个错误的描述(描述 2),可以在不使用图像的情况下回答问题时给出完全错误的答案(答案 2)。
- 确保两个描述都合理且简洁。
- 错误描述的句子结构应与正确描述相似。
以下是问题和答案:
问题:{question}
答案:{answer}
请按以下格式输出两个描述:
描述 1:<Description 1>
描述 2:<Description 2>
答案 2:(answer 2)

图 2:给定图像、问题和真实答案,生成匹配和损坏文本的提示。我们将 {question} 和 {answer} 替换为具体样本。
3. 实证分析
在本节中,我们旨在回答以下研究问题:
- (模态偏好)模型在不同文本条件下的行为如何?模型是否存在模态偏好偏差?
- (性能影响)文本偏见在多大程度上会影响模型的性能,特别是在上下文中有损坏文本的情况下?
- (影响因素)文本偏见是否受到指令、语言模型大小或 token 位置的影响?
3.1 设置
任务与数据集
我们在涵盖四个领域的VQA数据集上评估模型性能,包括:(1) 通用VQA:从VQAv2 [15]验证集抽取1,000个样本;(2) 文档VQA:从DocVQA [29]验证集抽取1,000个样本,用于图表和表格理解;(3) 数学推理:从MathVista [28]的minitest集抽取1,000个样本;(4) 品牌识别:从钓鱼检测数据集测试集 [22]抽取2,500个样本,使用HTML文本和网页截图,专注于识别网站品牌。需要注意的是,每个问题都扩展为三种文本变体,总共生成16,500个测试样本,来源于5,500个独特问题。我们的研究包括10个视觉语言模型(VLM),涵盖专有模型 [2, 3] 和开源模型 [1, 10, 26, 38]。温度设置为0以确保确定性生成。所有实验细节、示例和结果均包含在附录中。
文本变体构建
我们使用GPT-4o模型生成匹配文本和损坏文本。给定图像 III、问题 QQQ 和答案 YYY,我们提示模型生成支持性描述作为匹配文本 TmT_mTm,以及矛盾描述作为损坏文本 TcT_cTc,从而使模型在没有图像输入的情况下能够产生正确答案和错误答案。
用于文本生成的提示如图2所示。我们提取“描述1”和“描述2”分别作为匹配文本和损坏文本。
为了构建无关文本,我们从WikiText数据集 [30] 中随机抽取段落,该数据集包含来自维基百科文章的文本。这些抽取的文本作为无关案例,因为它们是事实性的,但与图像和问题无关。具体示例请参见附录。
查询指令
当信息不一致时,人类可能不确定应信任哪些信息。为了减少歧义,遵循先前工作 [35],我们在文本信息前添加一句话,提醒模型可能存在错误,并鼓励谨慎使用文本信息。提示如下:“以下是一些额外的文本描述信息。请注意,这些信息可能无关、缺少部分内容或不准确,请谨慎使用。”
** sanity检查**
我们通过仅提供文本上下文来评估构建的文本变体与模型性能的关系。我们预期匹配文本提供足够信息以得出正确答案,损坏文本会误导模型得出错误答案,而无关文本缺乏相关信息,导致模型随机回答或表现出不确定性(例如回答“我不知道”)。
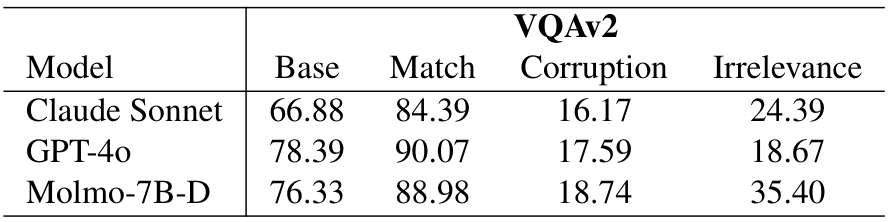
3.2. 对文本的盲目信任
在图3和图4中,我们观察到两个关键发现,展示了“对文本的盲目信任”现象。首先,当文本数据与视觉数据不一致但相关时,模型倾向于偏向文本,这一点在匹配和损坏情况下均表现为较高的文本偏好比例。例如,Claude Haiku 在 VQAv2 数据集中的文本偏好比例分别在匹配和损坏情况下达到 87%
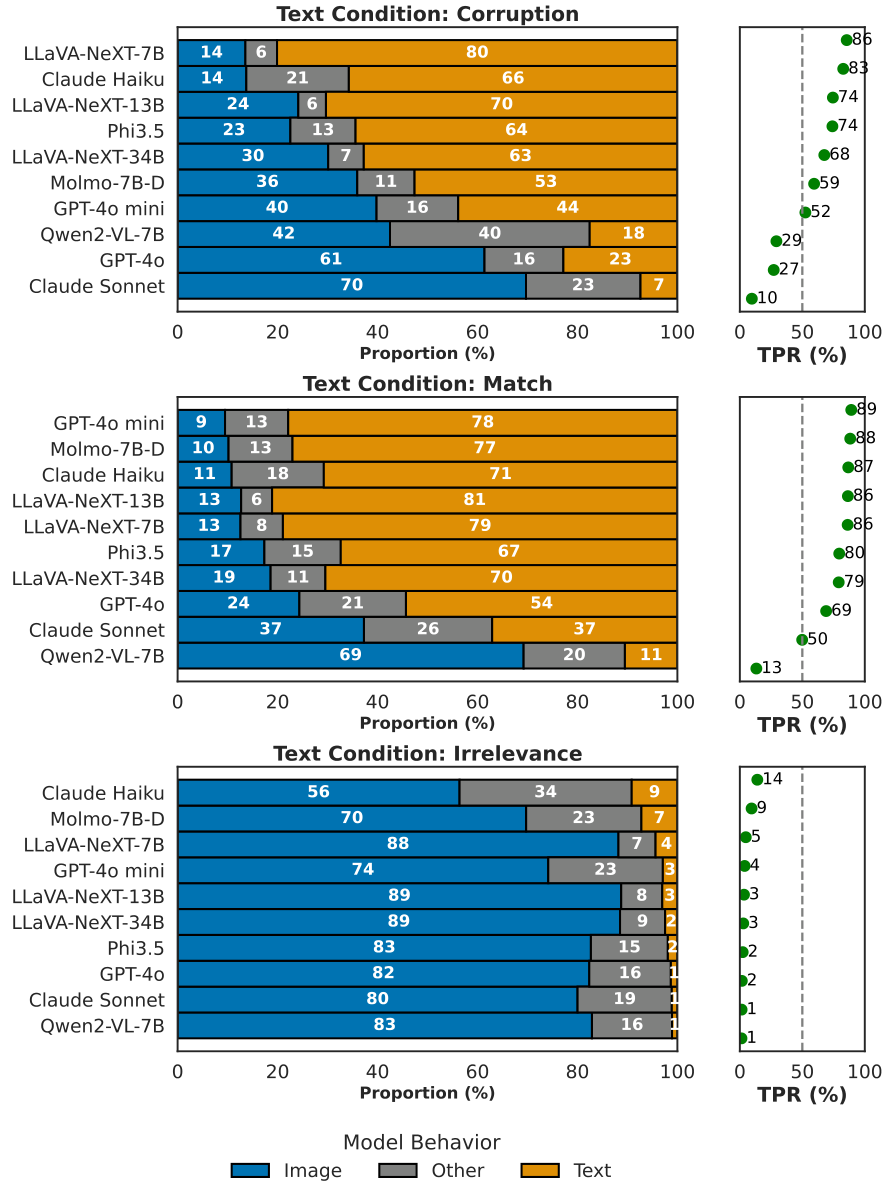
和 83%。总体而言,观察到较高的偏好比例(通常超过 50%),尤其是在开源模型中。其次,某些模型,如 Qwen2-VL-7B,在损坏情况下的文本偏好(29%)甚至高于匹配情况(13%),表明即使文本不正确,模型也倾向于依赖文本,显示出对准确和不准确文本信息辨别能力的局限性。这些结果凸显了模型中普遍存在的“对文本的盲目信任”现象。
开源模型相较于专有模型表现出更强的文本偏见。尽管开源模型在标准 VQA 基准测试中的表现与专有模型相当甚至超过后者,但我们的结果显示,开源模型在我们的基准测试中表现出更高的文本偏好,即使文本不正确也是如此。即使在专有模型的高效版本(如 GPT-4o mini 和 Claude Haiku)中,这种文本偏见仍然显著。总体来看,Claude Sonnet 在评估模型中在面对基于文本的干扰时表现出最强的鲁棒性。这一问题在开源模型的开发中至关重要,特别是在将其部署到现实世界中的复杂应用(如多模态代理或在线购物平台)时 [19, 39]。
3.3. 性能影响

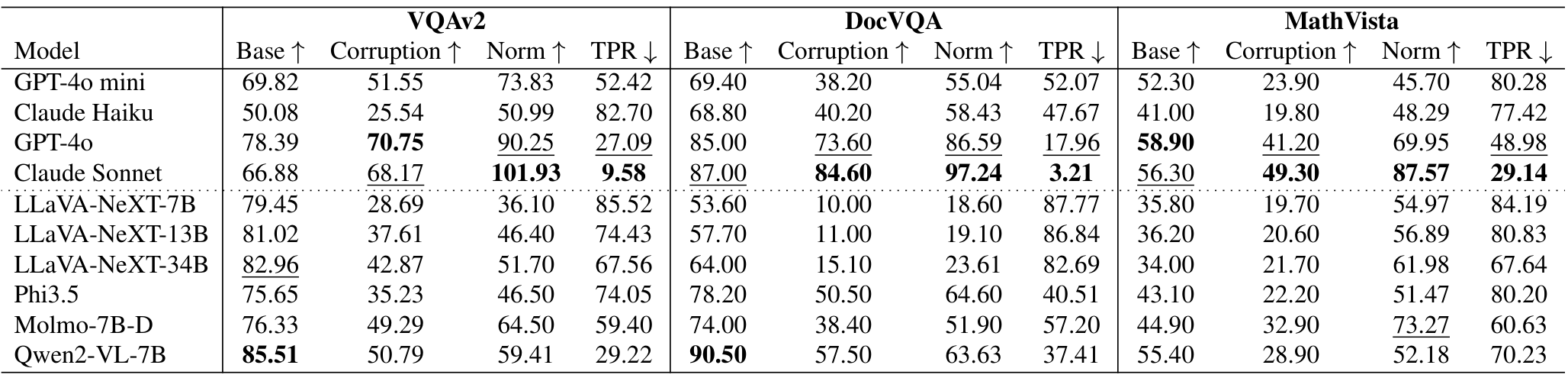
强烈的文本偏见导致在文本损坏的情况下性能显著下降。鉴于“盲目相信文本”的现象,评估其对性能的影响至关重要,特别是在处理损坏文本时。如表2所示,在存在损坏文本的情况下,性能急剧下降。例如,Qwen2-VL-7B 在 VQAv2、DocVQA 和 MathVista 上的准确率分别下降至原始水平的 59%、63% 和 52%,大约减少了 50%。虽然专有模型表现出更大的稳定性,下降幅度较小,但这些模型的高效变体也经历了显著的性能下降。这凸显了在安全关键应用中部署专有模型的高效变体时需要谨慎。
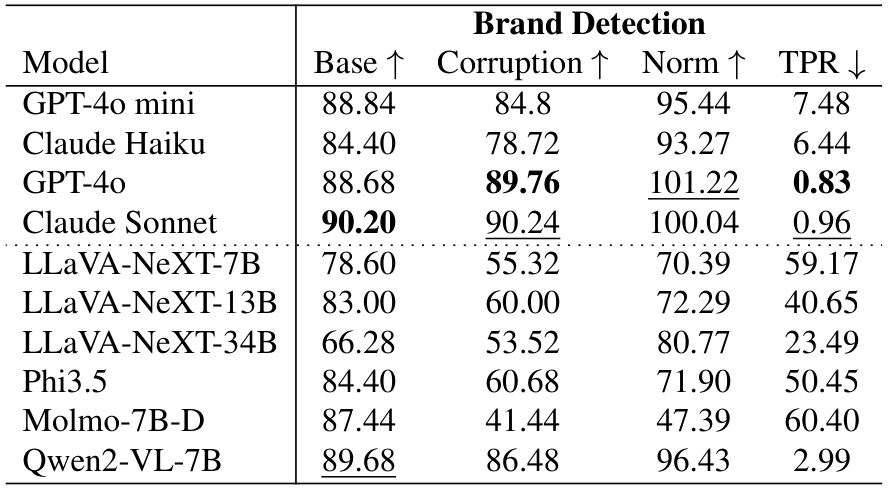
文本偏见可能在现实应用中引入安全风险。除了常规的视觉问答(VQA)任务外,我们还考察了文本偏见在现实场景中的安全影响:网页理解中的品牌识别。在这项任务中,模型通常使用 HTML 字符串和网页截图来识别网站的品牌。然而,HTML 内容很容易被操纵,包含错误或误导性信息;例如,钓鱼网站可能在 HTML 中注入目标品牌名称以规避检测系统,这被视为损坏情况。有关此设置的更多细节在附录中提供。
如表3所示,在损坏条件下,大多数开源模型(如 Molmo-7B-D)表现出显著的性能下降,准确率相较于原始性能降低了近 50%。相比之下,专有模型表现出轻微的抗性,可能是因为它们能够利用 HTML 字符串中的信息,同时较少受到注入内容的影响。
3.4 影响因素
在本节中,我们探讨了导致视觉语言模型(VLMs)中文本偏差的因素,并识别了关键的影响因素。除非另有说明,结果均基于 VQAv2 数据集。
指令可以减少文本偏差,但效果有限。 我们进一步研究了通过明确指示模型关注图像信息并减少对文本的依赖是否能缓解文本偏差。受到先前工作 [35] 的启发,我们在问题前添加指令,引导模型优先考虑哪种模态。具体来说,我们比较了“关注文本”和“关注图像”两种指令。在修改后的提示中,我们分别添加了“请关注文本以回答问题”和“请关注图像以回答问题”的短语。如图 5(左)所示,指令对模态偏好的影响有限。在 QwenVL-2-7B 模型中,当指令从“关注文本”变为“关注图像”时,平均文本偏好比例仅从 16.8% 下降到 14.2%。这种有限的效果可能也表明模型在跨模态交互中的指令遵循能力较弱。
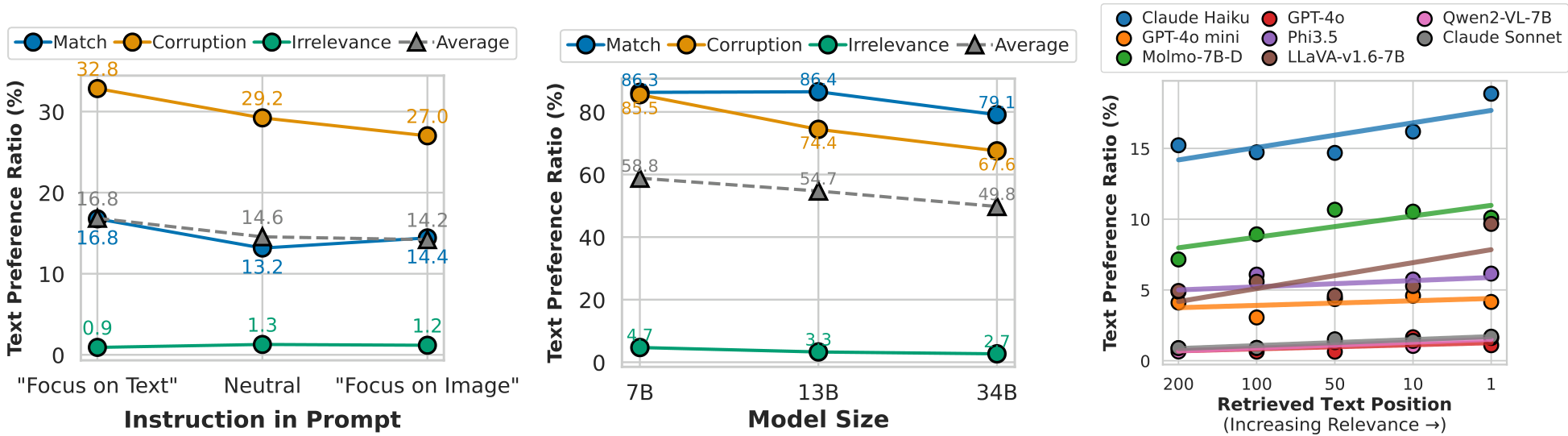
使用更大的语言模型进行训练可以减少文本偏差,但效果趋于饱和。 语言模型是当前 VLM 架构中的核心组件 [9, 24]。在 VLMs 中扩展语言模型通常会提升模型能力 [18, 36]。因此,我们使用 LLaVA-NeXT 模型研究了模型规模对文本偏差的影响。如图 5(中)所示,将模型规模从 7B 增加到 34B 总体上减少了文本偏差。7B 模型在匹配和损坏情况下表现出较高的文本偏好比例(分别为 86.3% 和 85.5%)。当规模扩展到 14B 时,匹配和损坏文本偏好之间的差距达到 12%,表现出显著改善。进一步扩展到 34B 继续减少了整体文本偏好,但匹配和损坏文本偏好比例之间的差距保持稳定。
相关文本更容易影响视觉语言模型。 在类似 RAG 的应用中,检索到的文本可能看似与查询相关,但最终对准确回答无帮助。为了检验文本相关性如何影响 VLMs 中的文本偏差,我们使用 BM25 排名检索 [33],以问题 Q 作为查询,改变 top-k 结果以表示相关性水平。Top-1 结果与问题最相关,但与图像无关,因此对回答问题无帮助。如图 5(右)所示,文本偏差随着文本相关性的增加而增加。在最相关(Top-1)的情况下,Molmo-7B-D 表现出超过 10% 的文本偏好比例,尽管文本对准确预测无帮助。这表明模型不容易被明显无关的文本干扰,但会被看似相关(实则无关)的文本影响,这为多模态 RAG 等应用带来了担忧,因为检索到的文本可能看似相关却会分散模型注意力。
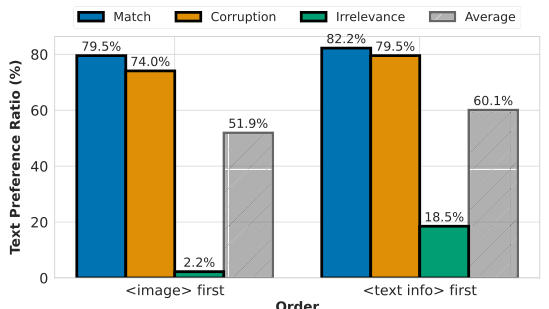
文本偏差与图像和文本令牌的顺序有关。 先前的研究表明,令牌顺序会影响语言模型(LLMs)在语言生成中的偏差 [32, 49]。由于 VLMs 以 LLMs 为核心组件 [8, 37] 并以自回归方式训练,我们检验了文本和图像令牌顺序是否会影响文本偏差。值得注意的是,VLMs 通常包含来自视觉编码器的大量图像令牌。为了测试这一点,我们通过改变 Phi3.5 中文本和图像令牌的顺序来比较文本偏好比例。如图 6 所示,将文本令牌置于图像令牌之前在三种文本变体下均一致增加了文本偏差。虽然先前研究表明 VLMs 中的生成错位或幻觉可能源于对图像令牌的注意力减少 [11, 47],但我们的发现表明初始令牌模态可能会强烈影响模态偏好,从而加剧文本偏差。
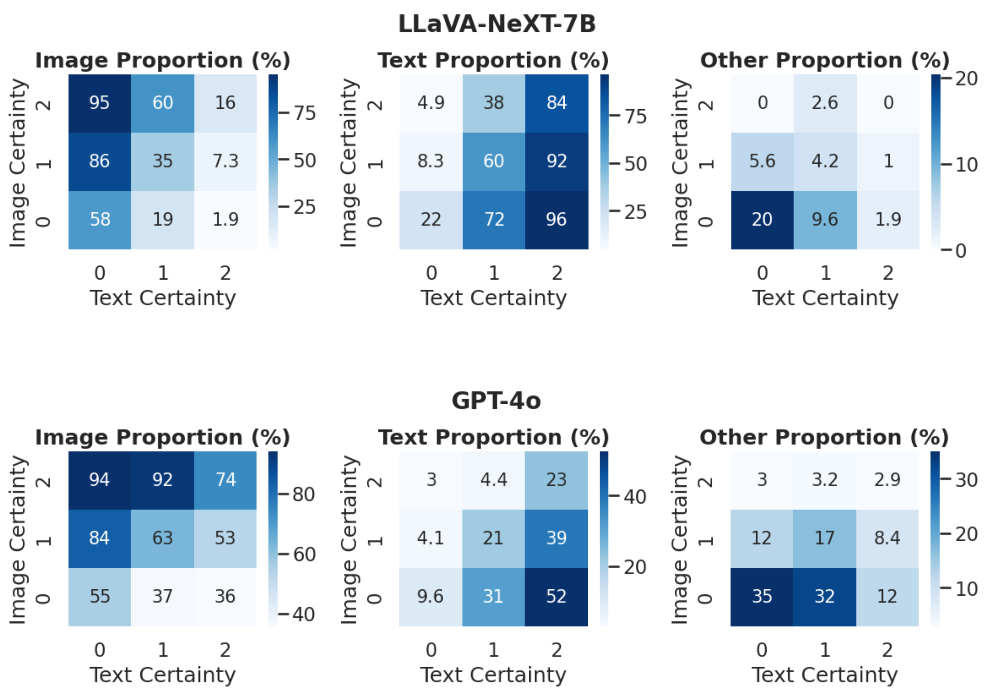
单模态确定性与模型行为的相互作用。 为了探索模型何时依赖视觉或文本,我们将单模态确定性作为塑造模型行为的关键因素进行分析。具体来说,我们分析了按单模态确定性分位数划分的组中图像、文本和其他响应的比例(即 PimgP_{img}Pimg、PtxtP_{txt}Ptxt 和 PoP_oPo)。如图 7 所示,存在一种有趣的相互作用效应:当文本确定性 PtxtP_{txt}Ptxt 高而图像确定性 PimgP_{img}Pimg 低时,模型倾向于选择文本答案,反之亦然。当两种确定性均低时,模型通常会产生其他答案,而不是仅偏好文本或图像。
4. 研究的解决方案
4.1. 指令
在第3.4节中,我们观察到指令提示可以影响模型的模态偏好。例如,在问题前添加指令“请专注于图像来回答问题”可以在一定程度上减少文本偏差。为了进一步探索这一点,我们以这条指令作为基准评估性能,发现宏精度(Macro accuracy)略有提升(1-2%),如表4和表5所示。
4.2. 监督微调(SFT)
数据。训练数据的构成对于有效的视觉语言模型(VLM)训练至关重要[36]。具体来说,我们在微调中同时包含纯文本和图像-文本样本。我们收集了1000个样本,均匀分布在五种数据类型中:纯文本数据、原始VQA数据,以及在匹配、损坏和无关文本条件下的VQA样本作为文本增强样本。种子数据来自VQAv2验证集,与基准评估数据分开。
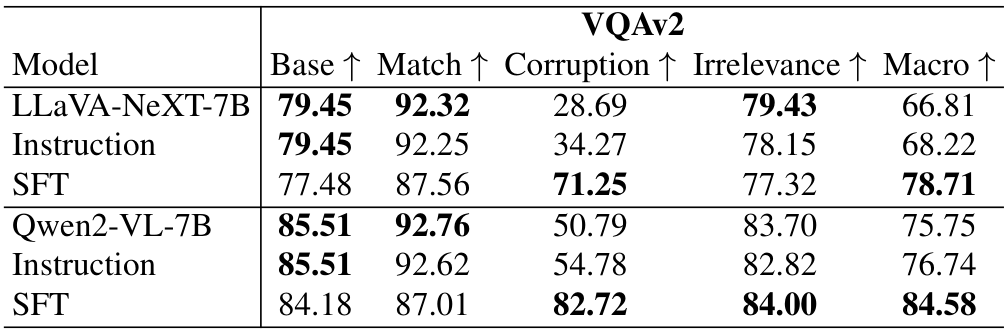
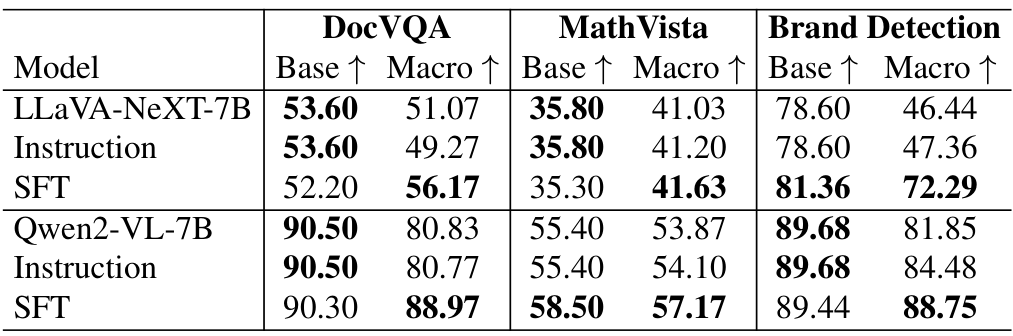
设置。我们遵循标准的监督微调程序,使用学习率为 1.0×10−41.0 \times 10^{-4}1.0×10−4,在3个周期内采用余弦衰减,并设置预热比例为0.1以实现稳定收敛。此外,我们应用LoRA进行高效微调。实验在LLaVA-NeXT-7B和Qwen2-VL-7B模型上进行。
分布内性能。在表4中,我们比较了原始模型、带指令的模型以及经过监督微调后的模型在分布内数据上的性能。结果表明,与指令相比,监督微调可以更好地提高模型精度,特别是在文本损坏条件下,损坏准确率从28.69%提升到71.25%,同时保持了宏精度的整体性能。
泛化能力。我们进一步通过评估微调模型在VQAv2以外的数据集上的性能来检验其泛化能力。如表5所示,微调模型在所有数据集上均表现出一定的改进。然而,在MathVista上的改进最小,可能是由于从一般VQA任务到数学推理任务的分布偏移较大。
纯文本数据的影响。我们进行了一项消融研究,以检验纯文本和跨模态数据在LLaVA-NeXT-7B微调中的作用。为了公平比较,所有实验中的训练数据总量保持不变。如图8(左)所示,微调减少了文本偏差,并增强了模型区分匹配和损坏情况的能力,差距高达40%。此外,纯文本数据对于维持核心语言能力非常重要:没有它,模型可能会不加区分地拒绝文本,导致过于谨慎的行为并限制其对有用文本的利用。
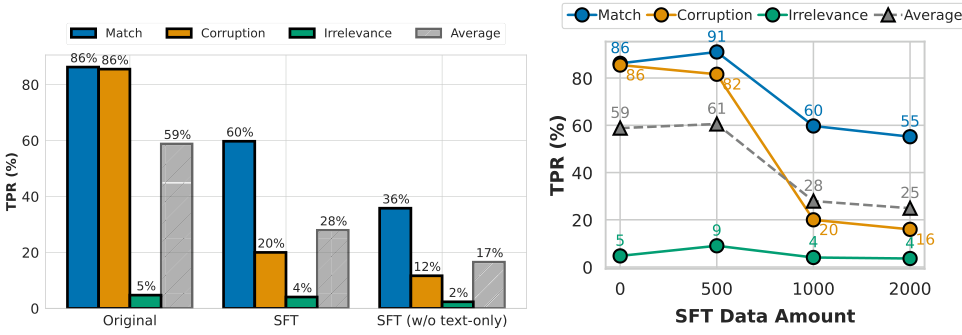
数据量的影响。我们研究了数据量在SFT中的影响,如图8(右)所示。随着SFT数据量的增加,模型在损坏情况下的文本依赖性显著降低(从58%降至25%),而在匹配情况下保持相对稳定。这一趋势表明,增加SFT数据量可以减少对损坏或无关文本的依赖,同时保持模型对匹配文本的有效性。
5. 理论分析
在这一部分中,我们提供了理论分析,以解释为什么大多数视觉语言模型(VLMs)表现出对文本的盲目信任的固有倾向。设 NNN 和 MMM 分别表示训练集中纯文本数据和多模态数据的大小,这些数据分别从分布 DtxtD_{txt}Dtxt 和 DmulD_{mul}Dmul 中独立同分布(i.i.d)采样。我们的非正式结果如下,更多细节请参见附录 A。
定理 15.1(非正式;定理 A.5 的简化版):在特定假设下,以至少某一概率,纯文本数据的期望损失 E(X,Y)∼Dtxtl(fvlm(X;θERM),Y)E_{(X,Y)\sim D_{txt}} l(f_{vlm}(X; \theta_{ERM}), Y)E(X,Y)∼Dtxtl(fvlm(X;θERM),Y) 达到如下结果:
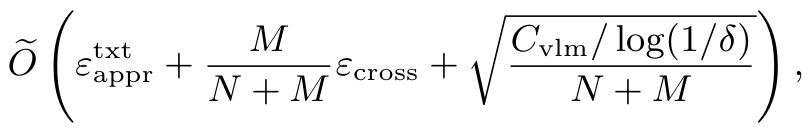
同样,多模态数据的期望损失 E(X,Y)∼Dmull(fvlm(X;θERM),Y)E_{(X,Y)\sim D_{mul}} l(f_{vlm}(X; \theta_{ERM}), Y)E(X,Y)∼Dmull(fvlm(X;θERM),Y) 达到如下结果:
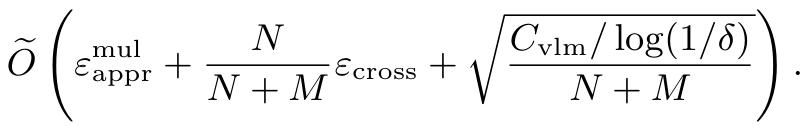
其中,l(⋅,⋅)l(\cdot, \cdot)l(⋅,⋅) 是一个有界损失函数,θERM\theta_{ERM}θERM 是通过经验风险最小化(ERM)学习得到的参数;txtapprtxt_{appr}txtappr 表示纯文本数据的近似误差(对于多模态数据也是类似),以及跨模态误差,这些误差仅依赖于分布 DtxtD_{txt}Dtxt、DmulD_{mul}Dmul 以及模型的假设;CvlmC_{vlm}Cvlm 是一个与模型假设的覆盖数相关的量。更多细节请参见附录 A。
备注 5.2:观察到纯文本数据和多模态数据的期望损失分别受到 N+McrossN+M_{cross}N+Mcross 和 M/N⋅EcrossM/N \cdot E_{cross}M/N⋅Ecross 的影响。我们的理论分析在特定假设下表明,对文本信息的盲目信任倾向可能源于 NNN 和 MMM 之间的显著不平衡。特别是在大多数 VLMs 中,N>MN > MN>M,因为这些模型往往严重依赖纯文本数据,而对多模态数据的依赖较少,这可能导致模型更偏向于文本而非图像。
6. 相关工作
对 VLMs 的评估:当前针对 VLMs 的评估基准包括单任务基准 [15, 28, 29, 34] 和多模态基准 [20, 27, 44, 45],旨在评估模型在多样化任务中的通用能力。一些研究还评估了特定问题,如幻觉 [11, 21]、灾难性遗忘 [46] 和鲁棒性 [43]。然而,这些基准主要以视觉为中心,通常将文本视为问题输入而没有额外的上下文,这限制了对模型应对文本变化的鲁棒性评估。虽然在特定任务(如数学推理)中文本可以作为额外提示,但当前数据集 [28] 更关注评估推理技能,而非模型处理多样化文本输入的能力。因此,VLMs 是否能可靠地处理多模态不一致性仍是一个未解之谜。这一差距对于现实世界的应用(如多模态 RAG)至关重要,因为模型会遇到多变的文本输入。为此,我们的研究探讨了 VLMs 在不同文本变化下的表现,发现了影响模型可靠性的文本偏见。
输入扰动的基准:文本扰动在自然语言任务中被广泛用于评估模型对干扰或误导性上下文的鲁棒性和稳定性 [6, 16, 23, 31, 35, 42]。在计算机视觉领域,类似的工作集中在向图像输入添加不可察觉的扰动,以评估模型对噪声的敏感性 [14, 48]。我们的工作将重点从图像扰动转向探索文本变化对 VLMs 的影响,这些模型在以视觉为中心的基准中已经表现出色。近期研究 [7] 通过研究缺失模态下的表现,揭示了 VLM 基准中的数据泄露问题。与之不同,我们的目标是研究 VLMs 如何处理视觉和文本数据之间的不一致性,评估其在跨模态交互中的鲁棒性。
7. 结论与讨论
在重新审视我们的核心问题——视觉语言模型(VLMs)能否可靠地处理多模态不一致性?——我们的研究结果表明,仍然存在重大挑战。在这项工作中,我们观察到VLMs中存在“对文本的盲目信任”现象,当出现不一致性时,模型往往依赖文本而非视觉输入,导致性能下降和潜在的安全风险。我们的分析显示,指令、模型规模、文本相关性、token顺序和模态确定性等因素都会影响文本偏差。值得注意的是,单纯增加模型规模或改变提示词并不能解决这一问题。虽然通过文本增强的监督微调有所帮助,但在跨模态设置中平衡鲁棒性和有效性仍然具有挑战性。我们希望这项工作能够凸显在多模态检索增强生成(RAG)等应用中部署VLMs的风险,提供见解并促进开发更可靠、更鲁棒的VLMs以实现跨模态交互。
致谢
本研究得到新加坡教育部学术研究基金一级(FY2023)(资助号A-8001996-00-00)的支持。
A. 理论分析细节
为了为我们的理论分析提供严谨的基础,我们首先正式概述视觉语言模型的训练过程。为了清晰和简洁,以下是标准训练过程的简化改编。AVLM是一个函数 fvlm:X→Jf_{vlm} : X \rightarrow Jfvlm:X→J,其中 X:=Rr×dX := \mathbb{R}^{r \times d}X:=Rr×d 表示 ddd 维特征向量序列的集合(为简单起见,假设 X:=RX := \mathbb{R}X:=R)。
A.1. 结构
根据Edelman等人[13]的研究,我们考虑具有 LLL 层的变换器结构 fvlmf_{vlm}fvlm,其形式如下。第 iii 层的参数表示为 W(i):=VQ,VCSW^{(i)} := V_Q, V_{CS}W(i):=VQ,VCS。
KaTeX parse error: Expected 'EOF', got '\right' at position 320: …ght)W_{C}^{(i)}\̲r̲i̲g̲h̲t̲)\;\mathrm{for}…
其中 X∈RT×dX \in \mathbb{R}^{T \times d}X∈RT×d 是模型的输入,HnormH_{norm}Hnorm 是层归一化函数,σ\sigmaσ 是非线性激活函数。
f(Z;{WQ,WK,WV}):=Softmax(ZWQ(ZWK)⊤)ZWVf\left(Z;\left\{W_{Q},W_{K},W_{V}\right\}\right):={\mathrm{Softmax}}\left(Z W_{Q}\left(Z W_{K}\right)^{\top}\right)Z W_{V} f(Z;{WQ,WK,WV}):=Softmax(ZWQ(ZWK)⊤)ZWV
其中 Softmax(⋅)\mathrm{Softmax}(\cdot)Softmax(⋅) 是标准softmax函数。最后,标量输出定义为:
fvhm(X;W1;L,w):=wT[gthblock(L+1)(X;W1;L)]τ,forsomew∈Rd,f_{\mathrm{vhm}}(X;W^{1;L},w):=w^{\textsf{T}}[g_{\mathrm{thblock}}^{(L+1)}\left(X;W^{1;L}\right)]_{\tau},\;\mathrm{for~some~}w\in\mathbb{R}^{d}, fvhm(X;W1;L,w):=wT[gthblock(L+1)(X;W1;L)]τ,for some w∈Rd,
其中 [G]τ∈Rd[G]_{\tau} \in \mathbb{R}^{d}[G]τ∈Rd 表示矩阵 G∈RT×dG \in \mathbb{R}^{T \times d}G∈RT×d 的第 τ\tauτ 行。此外,我们在结构中做出以下假设:
假设 A.1:对于所有 i=1,…,Li = 1, \dots, Li=1,…,L,我们有 W(i),WQ(i),WK(i),WV(i)≤C2W^{(i)}, W^{(i)}_Q, W^{(i)}_K, W^{(i)}_V \leq C_2W(i),WQ(i),WK(i),WV(i)≤C2。
假设 A.2:对于所有 i=1,…,Li = 1, \dots, Li=1,…,L,我们有 ∣W(i)∣2,∣WQ(i)∣2,∣WK(i)∣2,∣WV(i)∣2≤C2,1|W^{(i)}|_2, |W^{(i)}_Q|_2, |W^{(i)}_K|_2, |W^{(i)}_V|_2 \leq C_{2,1}∣W(i)∣2,∣WQ(i)∣2,∣WK(i)∣2,∣WV(i)∣2≤C2,1。
假设 A.3:激活函数 σ(⋅)\sigma(\cdot)σ(⋅) 在 l2l_2l2 范数下是 LσL_\sigmaLσ-Lipschitz的。
假设 A.4:损失函数 l(⋅)l(\cdot)l(⋅) 是有界为 bbb 的,并且在其参数上为 LlossL_{loss}Lloss-Lipschitz的。
A.2. 训练过程
本文介绍了两种训练数据集及其训练过程。首先,纯文本训练集定义为 Xtxt=[(Xtxt,ytxt),…,(Xtxt,ytxt)]X_{\text{txt}} = [(X_{\text{txt}}, y_{\text{txt}}), \dots, (X_{\text{txt}}, y_{\text{txt}})]Xtxt=[(Xtxt,ytxt),…,(Xtxt,ytxt)],数据集大小为 NNN,其中 Xtxt∈RT×dX_{\text{txt}} \in \mathbb{R}^{T \times d}Xtxt∈RT×d 是长度为 TTT 的文本特征向量序列,ytxt=ftxt(Xtxt)∈Ry_{\text{txt}} = f_{\text{txt}}(X_{\text{txt}}) \in \mathbb{R}ytxt=ftxt(Xtxt)∈R 是其真实标签,ftxt(⋅)f_{\text{txt}}(\cdot)ftxt(⋅) 表示纯文本数据的真实函数。假设 Xtxt1,…,XtxtNX_{\text{txt}}^1, \dots, X_{\text{txt}}^NXtxt1,…,XtxtN 是从未知分布 DtxtD_{\text{txt}}Dtxt 中独立同分布(i.i.d.)采样的。
此外,多模态训练集定义为 Xmul=[(Xmul,ymul),…,(Xmul,ymul)]X_{\text{mul}} = [(X_{\text{mul}}, y_{\text{mul}}), \dots, (X_{\text{mul}}, y_{\text{mul}})]Xmul=[(Xmul,ymul),…,(Xmul,ymul)],数据集大小为 MMM,其中 Xmul∈RT×dX_{\text{mul}} \in \mathbb{R}^{T \times d}Xmul∈RT×d 是长度为 TTT 的多模态(例如文本和图像)特征向量序列,ymul=fmul(Xmul)∈Ry_{\text{mul}} = f_{\text{mul}}(X_{\text{mul}}) \in \mathbb{R}ymul=fmul(Xmul)∈R 是其真实标签,fmul(⋅)f_{\text{mul}}(\cdot)fmul(⋅) 表示多模态数据的真实函数。同样,假设 Xmul1,…,XmulMX_{\text{mul}}^1, \dots, X_{\text{mul}}^MXmul1,…,XmulM 是从未知分布 DmulD_{\text{mul}}Dmul 中独立同分布采样的。
多模态范式的训练过程表示为:
θ^ERM∈argminθ∈Θ1N+M(∑i=1Nl(fvim(Xitxt;θ),yitxt)+∑i=1Ml(fvim(Ximul;θ),yimul))\hat{\theta}_{\mathrm{ERM}} \in \arg \min_{\theta \in \Theta} \frac{1}{N+M} \left( \sum_{i=1}^{N} l\left(f_{\mathrm{vim}}(X_{i}^{\mathrm{txt}};\theta), y_{i}^{\mathrm{txt}}\right) + \sum_{i=1}^{M} l\left(f_{\mathrm{vim}}(X_{i}^{\mathrm{mul}};\theta), y_{i}^{\mathrm{mul}}\right) \right) θ^ERM∈argθ∈ΘminN+M1(i=1∑Nl(fvim(Xitxt;θ),yitxt)+i=1∑Ml(fvim(Ximul;θ),yimul))
我们的主要理论结果将在下一小节 # A.3. 结果 中给出。
现在我们提供定理 A.5 的正式表述。
定理 A.5:设 Θ\ThetaΘ 为满足假设 A.1、A.2、A.3 和 A.4 的参数集合。对于任意 θ∈Θ\theta \in \Thetaθ∈Θ,设 fvlm(⋅;θ)f_{\text{vlm}}(\cdot; \theta)fvlm(⋅;θ) 为如公式 1 中定义的具有 LLL 层的视觉语言模型(VLM)。以至少 1−δ1 - \delta1−δ 的概率,
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at position 61: …rac{\mathrm{g}}\̲m̲a̲t̲h̲r̲m̲{g}^{\mathrm{f}…
KaTeX parse error: Invalid delimiter type 'ordgroup' at position 569: …ad\qquad(\biggl{̲f̲_̲{̲\̲m̲a̲t̲h̲r̲m̲{̲s̲u̲s̲}̲}̲(̲X̲)̲\̲p̲h̲i̲}̲\phi\biggl)\big…
其中,
Cvlm∼<(C2Lσ)O(L)⋅BX2Bw2C2,12⋅log(dτ(N+M))C_{\mathrm{vlm}}\mathrm{~\stackrel{<}{\sim}}\left(C_{2}L_{\sigma}\right)^{O(L)}\cdot B_{X}^{2}B_{w}^{2}C_{2,1}^{2}\cdot\log(d\tau(N+M)) Cvlm ∼<(C2Lσ)O(L)⋅BX2Bw2C2,12⋅log(dτ(N+M))
是与函数类 {fvlm(⋅;θ)∣θ∈Θ}\{f_{\text{vlm}}(\cdot;\theta) | \theta \in \Theta\}{fvlm(⋅;θ)∣θ∈Θ} 的覆盖数相关的常数,符号 <<< 隐藏了除 NNN、MMM 和 TTT 之外的全局常数和对数因子。
A.4. Theorem A.5 的证明
在正式证明 Theorem A.5 之前,我们首先介绍了一些来自先前工作的有用引理。对于任何实值函数类 FFF,我们用 N(F;ϵ;x(1),…,x(m))N(F; \epsilon; x^{(1)}, \ldots, x^{(m)})N(F;ϵ;x(1),…,x(m)) 表示函数类 FFF 关于半径 ϵ\epsilonϵ 和样本 {x(1),…,x(m)}\{x^{(1)}, \ldots, x^{(m)}\}{x(1),…,x(m)} 的覆盖数。
引理 A.6(改编自 Bartlett 和 Mendelson [5, Theorem 8] 以及 Edelman 等人 [13, Lemma A.4]):考虑一个实值函数类 FFF,使得对于所有 f∈Ff \in Ff∈F,有 ∣f∣≤A|f| \leq A∣f∣≤A,且对于所有 x(1),…,x(m)∈Xx^{(1)}, \ldots, x^{(m)} \in Xx(1),…,x(m)∈X,有 logN(F;ϵ;x(1),…,x(m))≤C/ϵ2\log N(F; \epsilon; x^{(1)}, \ldots, x^{(m)}) \leq C/\epsilon^2logN(F;ϵ;x(1),…,x(m))≤C/ϵ2。设 l(⋅,⋅)l(\cdot, \cdot)l(⋅,⋅) 是一个有界为 bbb 的损失函数,且在其参数上满足 LlossL_{\text{loss}}Lloss-Lipschitz 条件,gt:X→Rg_t: X \rightarrow \mathbb{R}gt:X→R 是一个真实函数。那么对于任何 δ>0\delta > 0δ>0 和任何分布 DDD,对于独立同分布样本 x(1),…,x(m)∈Xx^{(1)}, \ldots, x^{(m)} \in Xx(1),…,x(m)∈X,以至少 1−δ1 - \delta1−δ 的概率,对所有 f∈Ff \in Ff∈F 同时成立:
∣Ex∼D[l(f(x),ggr(x))]−1m∑i=1ml(f(x(i)),ggr(x(i)))∣≤4cLlossCFm(1+log(AmCF))+2blog(1/δ)2m\left| \mathbb{E}_{x \sim D} \left[ l(f(x), g_{\text{gr}}(x)) \right] - \frac{1}{m} \sum_{i=1}^{m} l\left(f(x^{(i)}), g_{\text{gr}}(x^{(i)})\right) \right| \leq 4c L_{\text{loss}} \sqrt{\frac{C_F}{m}} \left(1 + \log\left(A \sqrt{\frac{m}{C_F}}\right)\right) + 2b \sqrt{\frac{\log(1/\delta)}{2m}} Ex∼D[l(f(x),ggr(x))]−m1i=1∑ml(f(x(i)),ggr(x(i)))≤4cLlossmCF(1+log(ACFm))+2b2mlog(1/δ)
其中 c>0c > 0c>0 是一个常数。
引理 A.7(改编自 Edelman 等人 [13, Theorem A.17]):假设对于 i∈[m]i \in [m]i∈[m],有 ∥x(i)∥2,∞≤BX\|x^{(i)}\|_{2, \infty} \leq B_X∥x(i)∥2,∞≤BX。设 Θ\ThetaΘ 是满足假设 A.1、A.2、A.3 和 A.4 的参数集合。对于任何 θ∈Θ\theta \in \Thetaθ∈Θ,设 fvlm(⋅;θ)f_{\text{vlm}}(\cdot; \theta)fvlm(⋅;θ) 是如方程 1 中定义的具有 LLL 层的 vlm 模型。我们有:
logN∞({fvlm(⋅;θ)∣θ∈Θ};ϵ;x(1),…,x(m))≲(C2Lσ)O(L)⋅BX2Bw2C2,12ϵ2⋅log(dmT).\log \mathcal{N}_{\infty} \left( \{ f_{\text{vlm}}(\cdot; \theta) \mid \theta \in \Theta \}; \epsilon; x^{(1)}, \ldots, x^{(m)} \right) \lesssim (C_2 L_{\sigma})^{O(L)} \cdot \frac{B_X^2 B_w^2 C_{2,1}^2}{\epsilon^2} \cdot \log(d m T). logN∞({fvlm(⋅;θ)∣θ∈Θ};ϵ;x(1),…,x(m))≲(C2Lσ)O(L)⋅ϵ2BX2Bw2C2,12⋅log(dmT).
Theorem A.5 的证明:根据引理 A.6,以至少 1−δ1 - \delta1−δ 的概率,对所有 θ∈Θ\theta \in \Thetaθ∈Θ 同时成立:
∣EX∼Dtxt[l(fvlm(X;θ),fgttxt(X))]−1N∑i=1Nl(fvlm(Xitxt;θ),fgttxt(Xitxt))∣\left| \mathbb{E}_{X \sim D^{\text{txt}}} \left[ l\left(f_{\text{vlm}}(X; \theta), f_{\text{gt}}^{\text{txt}}(X)\right) \right] - \frac{1}{N} \sum_{i=1}^{N} l\left(f_{\text{vlm}}(X_i^{\text{txt}}; \theta), f_{\text{gt}}^{\text{txt}}(X_i^{\text{txt}})\right) \right| EX∼Dtxt[l(fvlm(X;θ),fgttxt(X))]−N1i=1∑Nl(fvlm(Xitxt;θ),fgttxt(Xitxt))
logN∞({fvlm(⋅;θ)∣θ∈Θ};ϵ;x(1),…,x(m))≤Cϵ2.\log \mathcal{N}_{\infty} \left( \{ f_{\text{vlm}}(\cdot; \theta) \mid \theta \in \Theta \}; \epsilon; x^{(1)}, \ldots, x^{(m)} \right) \leq \frac{C}{\epsilon^2}. logN∞({fvlm(⋅;θ)∣θ∈Θ};ϵ;x(1),…,x(m))≤ϵ2C.
同样地,以至少 1−δ1 - \delta1−δ 的概率,对所有 θ∈Θ\theta \in \Thetaθ∈Θ 同时成立:
∣EX∼Dmul[l(fvlm(X;θ),fgtmul(X))]−1M∑i=1Ml(fvlm(Ximul;θ),fgtmul(Ximul))∣≤4cLlossCM(1+log(AMC))+2blog(1/δ)2M.\left| \mathbb{E}_{X \sim D^{\text{mul}}} \left[ l\left(f_{\text{vlm}}(X; \theta), f_{\text{gt}}^{\text{mul}}(X)\right) \right] - \frac{1}{M} \sum_{i=1}^{M} l\left(f_{\text{vlm}}(X_i^{\text{mul}}; \theta), f_{\text{gt}}^{\text{mul}}(X_i^{\text{mul}})\right) \right| \leq 4c L_{\text{loss}} \sqrt{\frac{C}{M}} \left(1 + \log\left(A \sqrt{\frac{M}{C}}\right)\right) + 2b \sqrt{\frac{\log(1/\delta)}{2M}}. EX∼Dmul[l(fvlm(X;θ),fgtmul(X))]−M1i=1∑Ml(fvlm(Ximul;θ),fgtmul(Ximul))≤4cLlossMC(1+log(ACM))+2b2Mlog(1/δ).
注意到对于任何 θ∈Θ\theta \in \Thetaθ∈Θ,我们有后续的推导和不等式成立(具体细节省略以保持摘要简洁)。
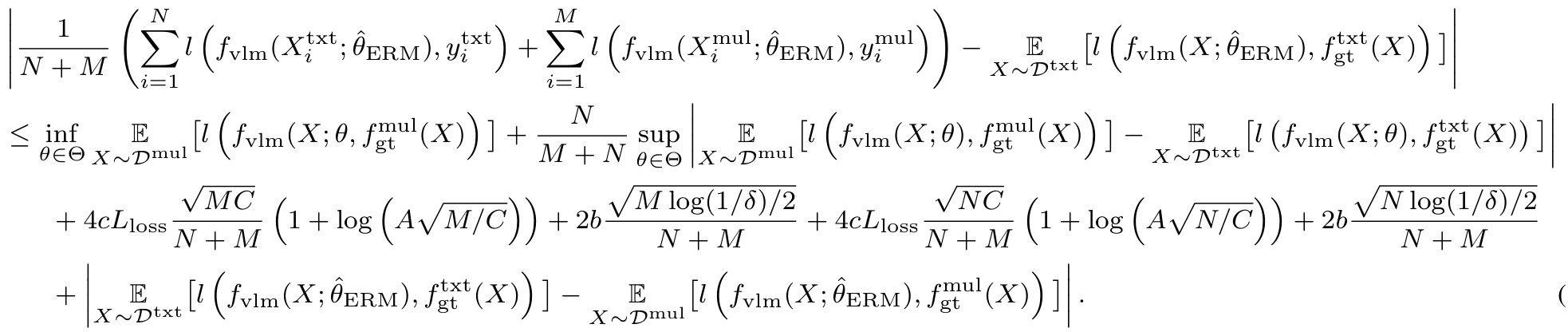
最后,基于引理 A.7 并隐藏全局常数和除 NNN、MMM 和 TTT 以外的量的对数因子,以 1−δ1 - \delta1−δ 的概率得到最终结论(具体公式省略以保持摘要简洁)。
至此,Theorem A.5 的证明完成。
B. 实验设置
本节概述了实验设置,包括构建的文本变体示例、品牌检测任务的详细信息[22] 以及采用的评估协议。我们展示了三种文本变体的示例,并附上相应的图像、原始问题和真实答案,以提供清晰的背景和上下文。
B.1. 示例
本小节在表6至表9中提供了不同数据集中匹配、损坏和无关文本的示例。
B.2. 品牌识别
从网页中识别品牌是检测钓鱼网站的重要步骤。钓鱼网页旨在通过模仿知名品牌相关合法网站的外观来欺骗用户。准确识别与网页相关的品牌,可以将输入网页的URL与识别品牌的官方URL进行比较,从而帮助检测钓鱼尝试。
在我们的实验中,我们使用了来自TR-OP数据集[22]的钓鱼网页样本。每个样本包括一个屏幕截图及其对应的HTML代码。根据不同场景,HTML内容要么反映屏幕截图中显示的目标品牌,要么被修改以评估模型的鲁棒性。我们评估了以下三种具体场景:
- 匹配:原始HTML包含屏幕截图中可见的目标品牌信息。这种场景为模型提供一致的输入,帮助其正确识别品牌。
- 损坏:在这种情况下,我们在HTML中插入一个虚构的品牌名称(例如,“The official webpage of MobrisPremier”),以误导模型识别一个不存在的品牌。由于此类品牌没有对应的URL,钓鱼检测对于这些输入变得不可行。
- 无关:HTML内容被替换为从Wiki数据集[]中随机选择的句子,确保新内容与任何品牌无关。这种场景测试模型处理不含品牌特定信息输入的能力。
为了标准化输入,我们对HTML内容进行了预处理,移除了所有标签,并将其截断至最大长度为5000个字符。

B.3. 评估
我们遵循每个数据集指定的评估协议。为了减少模型生成开放式答案的情况(这会使评估变得复杂),我们采用了与LLaVA-1.5 [25]评估设置类似的方法。对于某些数据集,我们在问题后附加了额外的格式化提示,如表10所示。
对于使用基于GPT评估的MathVista [28],我们不包含格式化提示,而是直接使用GPT来评估输出。
C. 实验结果
为了严格评估不同文本上下文对性能的影响,我们在四个不同的数据集上记录了全面的结果。这些结果通过多个指标进行量化:准确率(Accuracy)、归一化准确率(Normalized Accuracy)以及文本偏好比率(Text Preference Ratio, TPR),针对匹配(Match)、损坏(Corruption)和无关(Irrelevance)三种文本变体,同时还包括宏观准确率(Macro Accuracy)。详细结果总结在表11中。

为了全面评估所研究的方法,包括基础模型、指令提示和监督微调(Supervised Fine-Tuning, SFT),我们在四个数据集上展示了结果,同样以准确率(Accuracy)、归一化准确率(Normalized Accuracy)、文本偏好比率(TPR)为指标,针对匹配(Match)、损坏(Corruption)和无关(Irrelevance)三种文本变体,以及宏观准确率(Macro Accuracy)。这些实验使用了LLaVA-NeXT-7B和Qwen2-VL-7B模型进行。详细结果列于表12中。



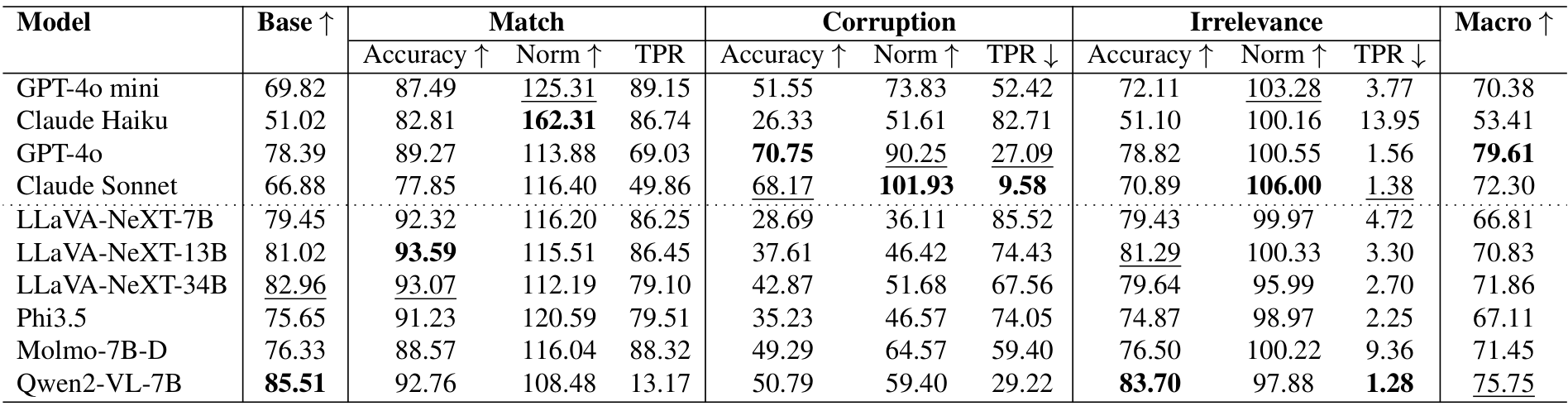
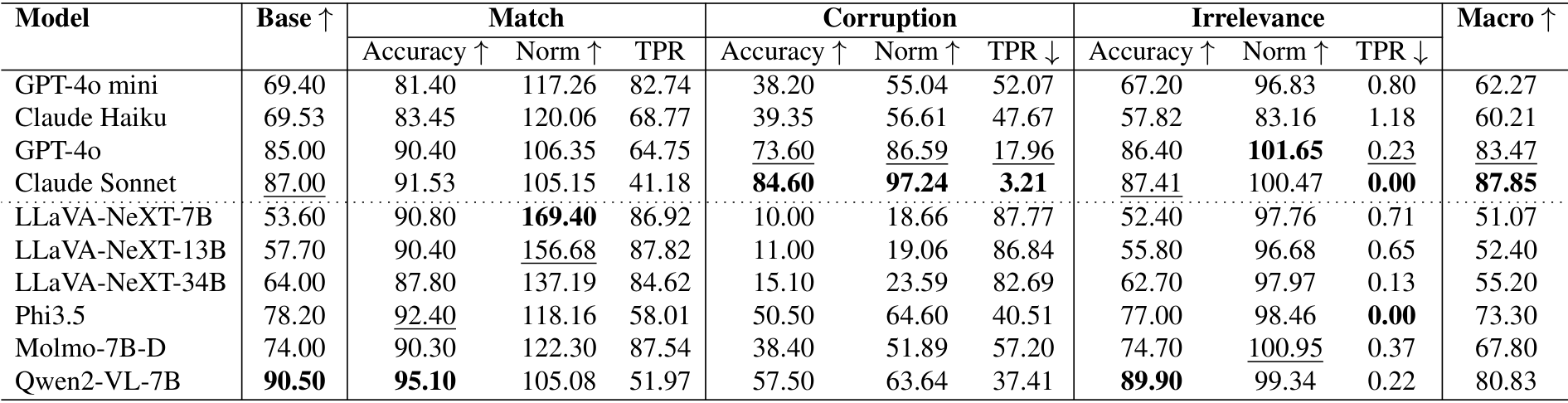
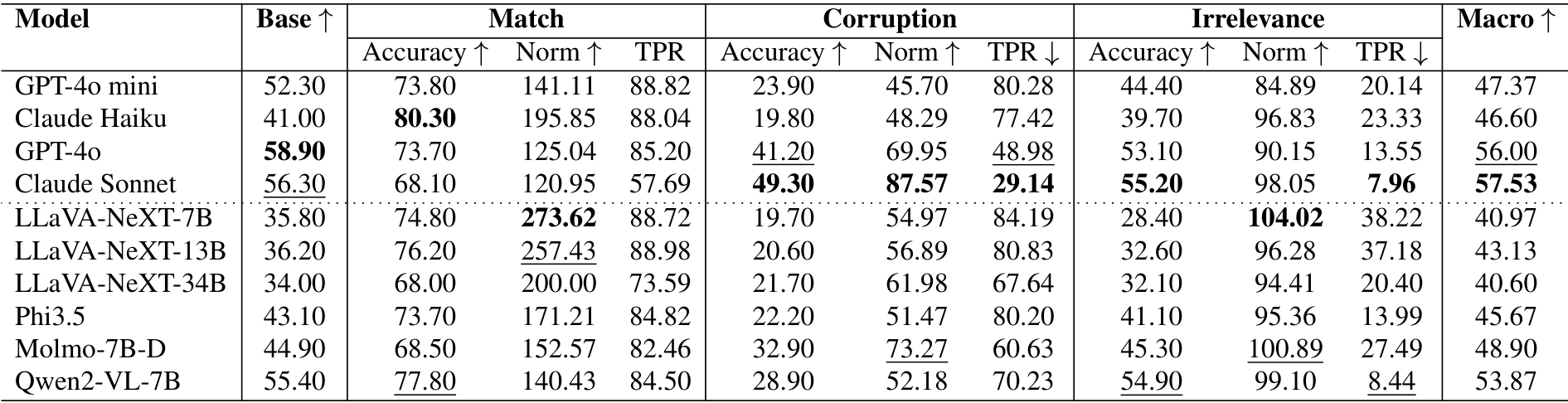
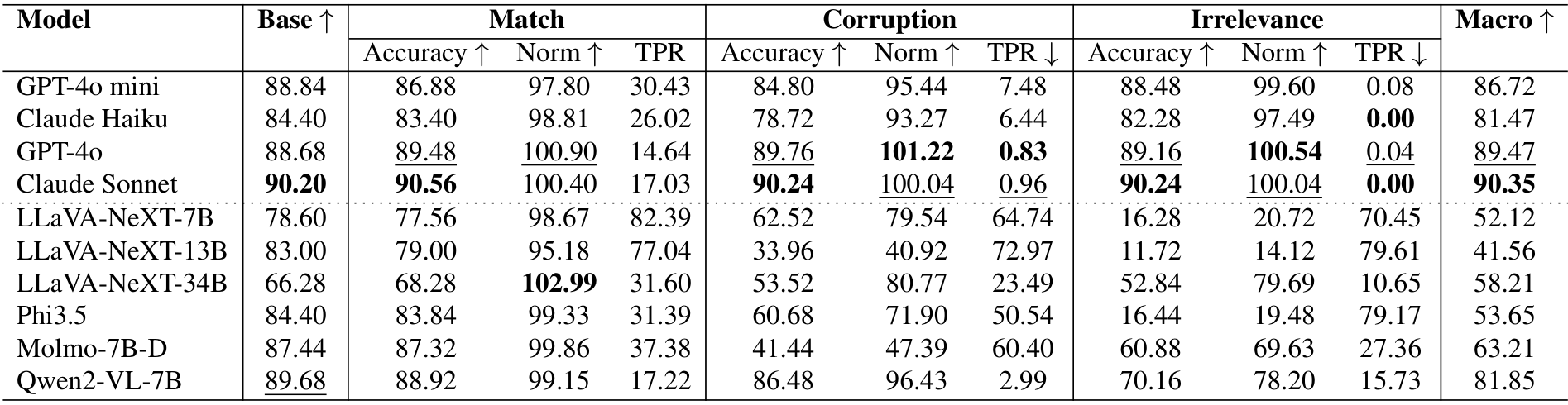
表11. 在四个数据集上,针对匹配(Match)、损坏(Corruption)和无关(Irrelevance)三种文本变体的准确率(Accuracy)、归一化准确率(Norm)和文本偏好比率(TPR)的性能表现。宏观(Macro)列表示每个模型在匹配、损坏和无关准确率的平均值,计算方式与基础准确率(Base Accuracy)可比。
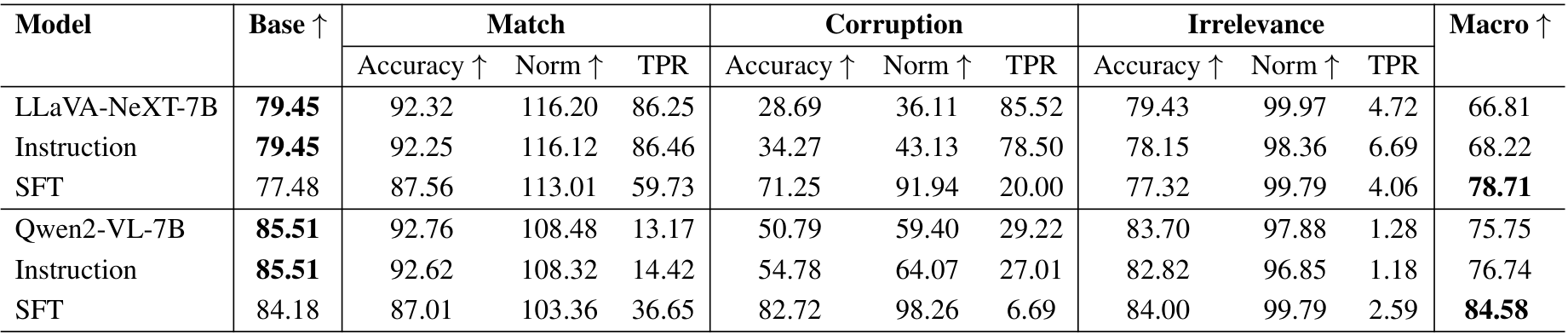
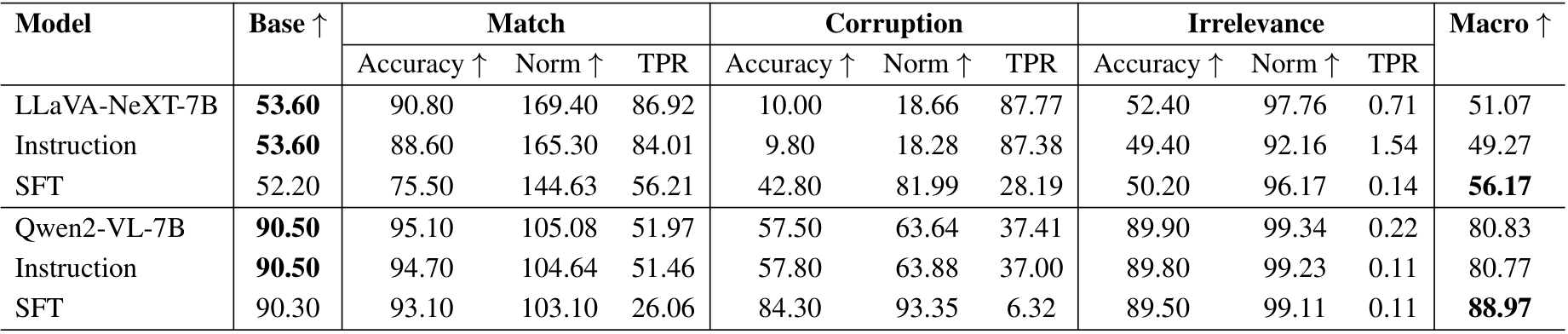
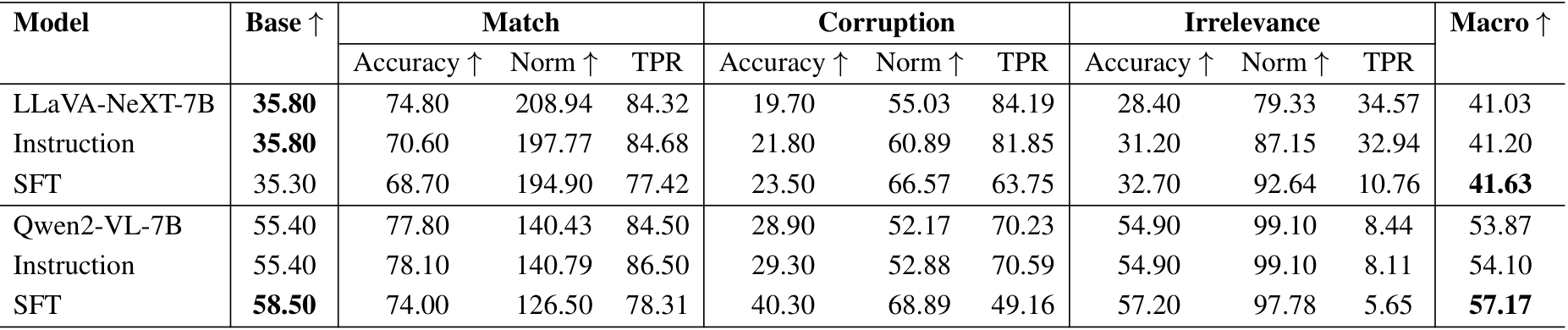
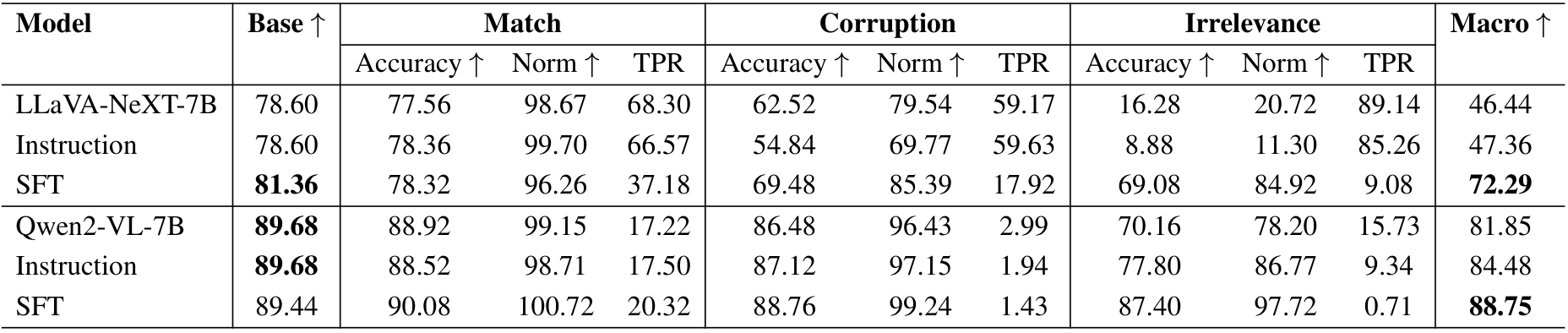
表12. 所研究解决方案在四个数据集上的准确率(Accuracy)、归一化准确率(Norm)和文本偏好比率(TPR)性能表现,针对匹配(Match)、损坏(Corruption)和无关(Irrelevance)三种文本变体。宏观(Macro)列表示每个模型在匹配、损坏和无关准确率的平均值,计算方式与基础准确率(Base Accuracy)可比。
Original Abstract: Vision-Language Models (VLMs) excel in integrating visual and textual
information for vision-centric tasks, but their handling of inconsistencies
between modalities is underexplored. We investigate VLMs’ modality preferences
when faced with visual data and varied textual inputs in vision-centered
settings. By introducing textual variations to four vision-centric tasks and
evaluating ten Vision-Language Models (VLMs), we discover a \emph{``blind faith
in text’'} phenomenon: VLMs disproportionately trust textual data over visual
data when inconsistencies arise, leading to significant performance drops under
corrupted text and raising safety concerns. We analyze factors influencing this
text bias, including instruction prompts, language model size, text relevance,
token order, and the interplay between visual and textual certainty. While
certain factors, such as scaling up the language model size, slightly mitigate
text bias, others like token order can exacerbate it due to positional biases
inherited from language models. To address this issue, we explore supervised
fine-tuning with text augmentation and demonstrate its effectiveness in
reducing text bias. Additionally, we provide a theoretical analysis suggesting
that the blind faith in text phenomenon may stem from an imbalance of pure text
and multi-modal data during training. Our findings highlight the need for
balanced training and careful consideration of modality interactions in VLMs to
enhance their robustness and reliability in handling multi-modal data
inconsistencies.
PDF Link: 2503.02199v1
部分平台可能图片显示异常,请以我的博客内容为准
