【Task3】【Datawhale AI夏令营】多模态RAG
科大讯飞AI大赛(多模态RAG方向)
夏令营:让AI读懂财报PDF(多模态RAG)
目前正在尝试在autodl平台上使用4090显卡,将原来baseline使用的fitz改进为MinerU,目前遇到了的错误:
ModuleNotFoundError: No module named ‘image_utils’
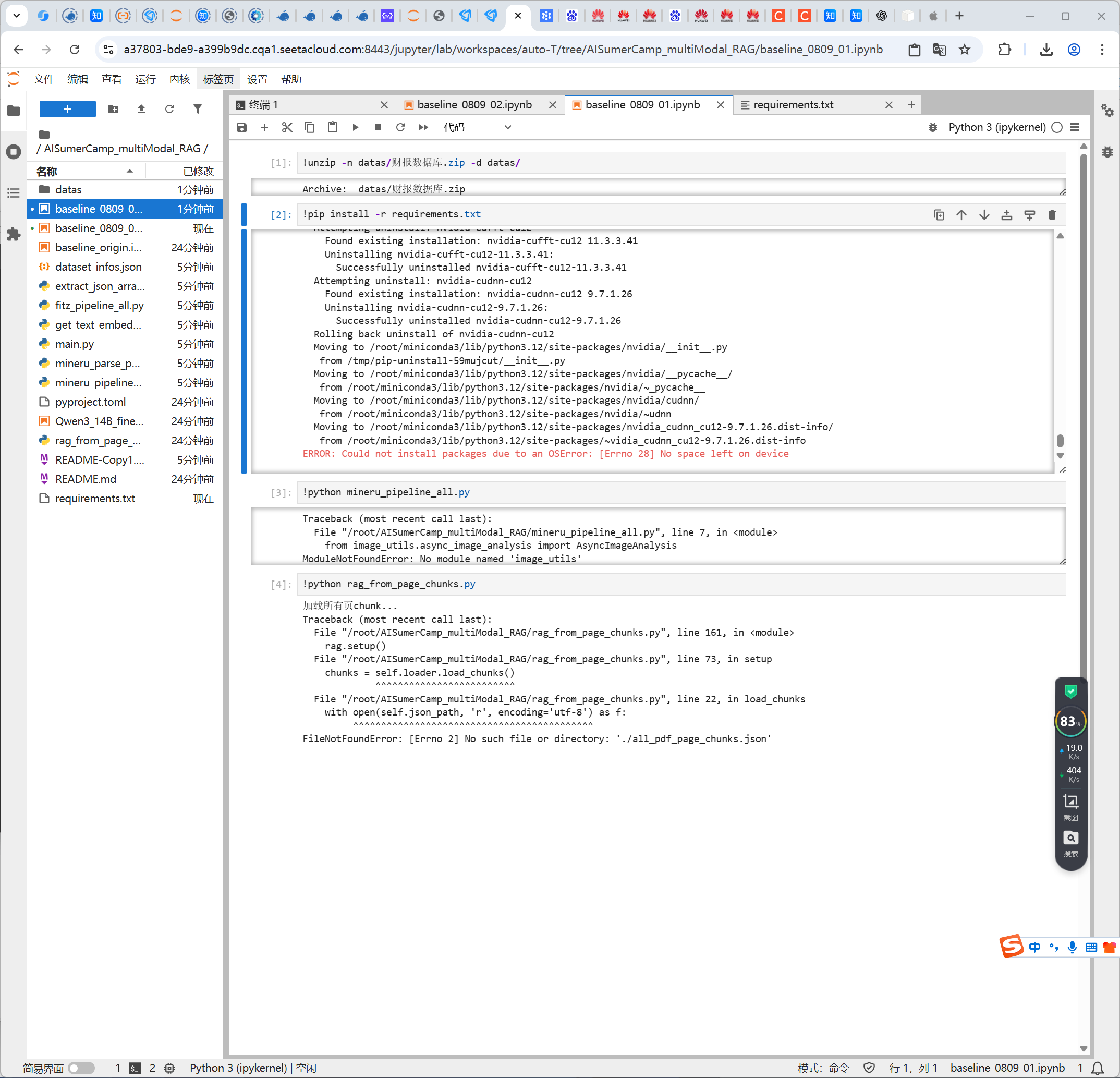
一开始以为是要安装image_utils包,结果安装后发现仍然缺少调用函数。
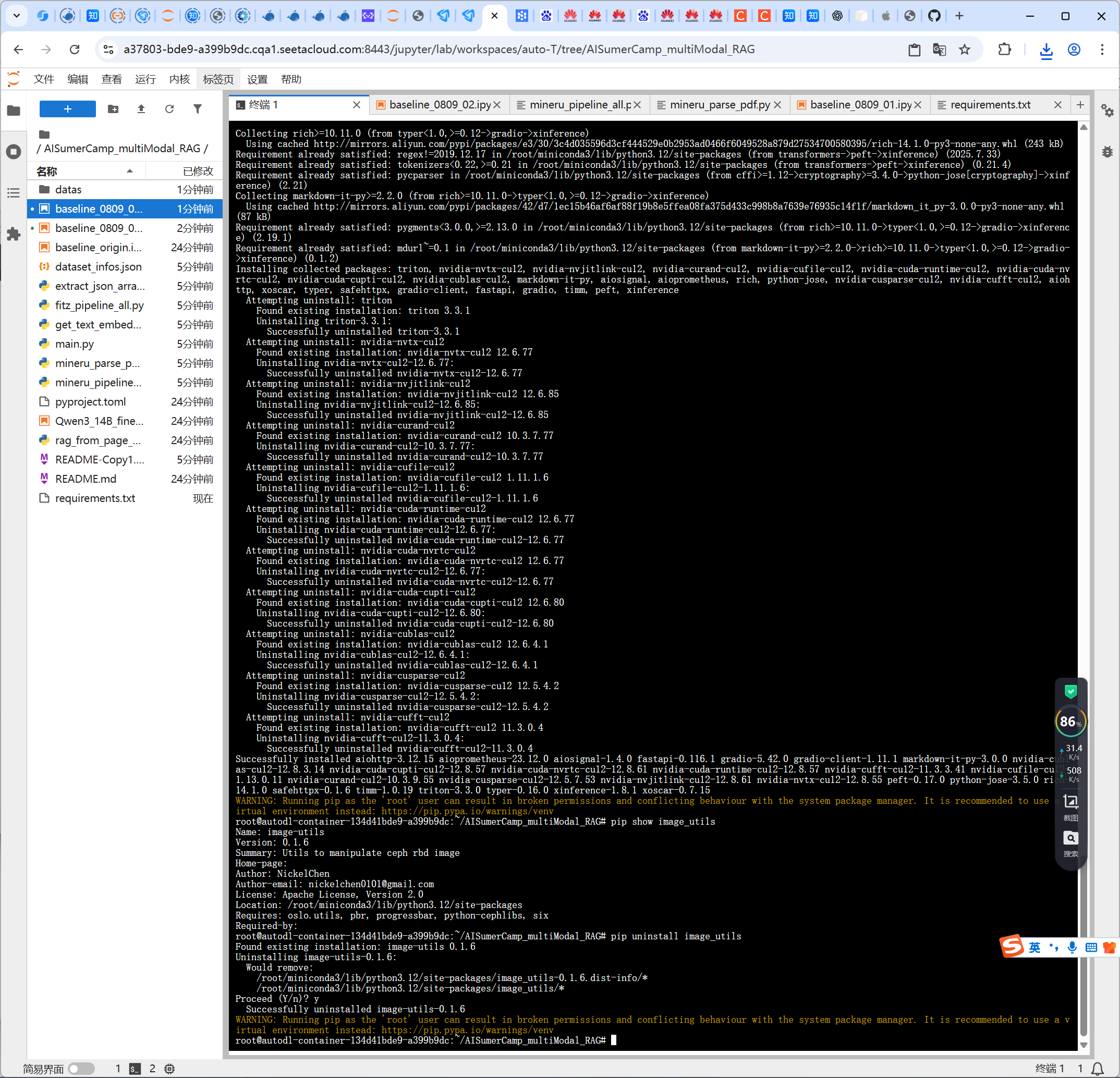
从开源仓库下载好正确的image_utils后,目前仍然在继续尝试中。
下面是教程:
copy from 侵删
💡
欢迎回到Datawhale AI夏令营第三期,多模态RAG 方向的学习~
我们将聚焦在「多模态RAG图文问答挑战赛」的赛事项目实践。
作为此次项目实践的最后一个Task,我们将—— 了解更多上分思路!
恭喜你已经完成了Baseline的跑通和赛题理解!这已经超越了80%的参赛者。
在跑通 Baseline 之后,相信我们已经对多模态RAG有了一个基本的认识和实践。
Baseline 方案提供了一个完整的流程,解决了从零到一的问题。接下来,我们要讨论的是如何在这个基础上做得更好。
在这个部分,我们将一起分析 Baseline 的局限性,从几个方面来考虑设计和优化RAG系统,学习三个核心的进阶方向:
使用 MinerU 实现高保真文档解析 :从源头上提升我们知识库的质量。
微调 Embedding 模型 :让我们的检索模块更懂金融领域的专业表达。
微调大语言模型 :训练一个更听话、更专业的问答生成器。
这部分内容会更有挑战性,但掌握了它们,你将能真正深入这个赛题的核心,并具备独立设计和优化高级RAG系统的能力。我们开始吧!
一、我们先回顾一下赛题任务
赛题背景
我们面对的不是干净的纯文本,而是信息量巨大、格式复杂的真实财报PDF。这些文件里文字、图表、表格交织在一起,传统的文本处理技术难以有效利用全部信息,因此需要引入多模态处理能力。
赛题目标
构建一个基于给定PDF知识库的、可溯源的多模态问答系统。简单来说,系统需要“读懂”这些图文混排的PDF,并能准确回答相关问题,同时必须明确指出答案来自哪个文件的哪一页。
评估标准
最终分数由三部分构成,总分为1分。这个评分机制强调了 答案准确性 和 来源可追溯性 并重:
答案内容相似度 (0.5分)
文件名匹配准确率 (0.25分)
页码匹配准确率 (0.25分)
数据集
我们手上有三份材料:
知识库 (财报数据库.zip) : 唯一的、封闭的信息来源,包含多个图文混排的PDF文件。
训练集 (train.json) : 提供“问题-答案-来源”的标注样本,用于系统开发和验证。
测试集 (test.json) : 只包含问题,是我们需要处理并提交结果的目标。
挑战与难点
多模态信息融合 :如何让系统理解文本与图表之间的关联。
检索的信噪比 :如何在海量信息中精准召回最相关的上下文,避免无关信息干扰。
生成的可控性 :如何让大模型忠实于原文作答,并准确溯源,而不是自由发挥。
细粒度信息抽取 :答案可能隐藏在某个表格的单元格或图表的特定部分,对文档解析的精度要求很高。
二、了解一下Baseline方案的优点和不足
在开始之前,确保你的代码内容是最新的,作者更新最快的代码仓库在:https://github.com/li-xiu-qi/spark_multi_rag上
我们先来看看 Baseline 方案。它的好处是逻辑清晰,遵循了“解析-分块-检索-生成”的流程,让我们能快速上手。同时,它的各个部分相对独立,方便我们替换和修改。
优点
逻辑清晰 :整个流程遵循“解析-分块-检索-生成”的经典RAG范式,简单易懂。
端到端完整 :提供了一个可以完整跑通并提交结果的框架,是很好的学习起点。
模块化 :各个组件相对独立,方便我们对其中任一部分进行替换和升级。
不足
文档解析粗糙 :这是最核心的短板。Baseline 使用的 PyMuPDF 只能提取纯文本,完全 丢失了表格、图片 等关键的多模态信息,同时也破坏了原有的版面布局。财报中的大量核心数据都在图表中,这一损失是致命的。
分块策略单一 :按“页”分块过于粗暴。一个完整的表格或逻辑段落可能被硬生生切开,破坏了信息的上下文完整性。
检索精度有限 :仅靠基础的向量相似度检索,对于包含特定术语或需要精确匹配的问题效果不佳,且容易引入噪音。
模型泛用性 :无论是 Embedding 模型还是 LLM,我们用的都是通用预训练模型,它们并没有针对“金融财报”这个垂直领域进行优化,理解上会存在偏差。
针对以上不足,我们可以规划出一条清晰的优化路径,对baseline方案进行修改,这也是我们进阶教程的核心脉络:
升级数据解析核心 :放弃 PyMuPDF, 切换到 MinerU 。利用 MinerU 强大的版面分析能力,提取出包含表格(转为Markdown)、图片、以及带有层级结构(标题、段落)的文本内容。这是提升分数上限关键的一步。
优化分块与索引策略 :有了 MinerU 精细化的解析结果,我们可以进行对 图片进行进一步的内容解释,添加图片的描述信息。
引入重排(Re-ranking) :在检索(Retrieve)环节后增加一个 重排步骤,选出最相关的几个结果,提高给到大语言模型的上下文质量。
先用向量检索召回一个较粗泛的候选集(如Top 20),
再用一个更精准的重排模型对这20个候选项进行打分排序,
选取真正的Top K(如Top 3-5)喂给LLM,大幅提升信噪比。
实施模型微调 :让模型更适应财报问答的场景。
微调Embedding模型 :利用 train.json 中的问答对构造训练数据,让模型学习财报领域的语义关系,提升检索召回的准确率。
微调LLM :利用 train.json 构造“指令-上下文-回答”格式的数据,对LLM进行指令微调。主要目的是让LLM更“听话”,能更忠实地根据我们提供的上下文作答,并严格按照要求的格式输出答案和来源。
运行全量测试数据:
💡
baseline里面的代码默认只运行了10条测试数据,只需要修改一个变量就能在baseline的基础上得到较大的分数提升
修改rag_from_page_chunks.py文件里面的变量TEST_SAMPLE_NUM,将原来的10改成None,运行全量的测试数据会消耗比较久的时间,大概会消耗20分钟左右。
图片
三、一起分析赛题的进阶要点
这个赛题的核心,是考察构建一个信息完整、结果精确的RAG系统的能力。系统的表现好坏,取决于知识库的构建、检索的准确性和生成的可控性这几个环节。
进阶要点1:提取文档的多模态内容
一个重要的部分是文档解析和多模态内容的理解。
RAG的效果很大程度上依赖于知识库的质量。如果源头就是有信息损失的,后续再怎么处理效果也有限。
像 MinerU 这样的工具能帮助我们进行版面分析,区分出标题、段落、表格和图片,并且能把表格转换成 Markdown 这种结构化格式。
这样处理后,知识库的内容就比纯文本丰富多了。
对于解析出来的图片,我们可以用多模态大模型,比如 Qwen-VL,来生成文字描述,把图片信息也文本化,方便后续的检索。
相关的资料可以查看 MinerU 和 Qwen-VL 在 GitHub 上的项目仓库。
加入mineru进行解析,我们的项目流程图就会变成这样:
图片
其中使用mineru进行解析内容的版本在我们的github仓库内是有提供的,文件名字叫做mineru_pipeline_all.py,
感兴趣的同学可以直接使用他进行生成all_pdf_page_chunks.json提供给后续的知识库构建使用。
图片
具体的参考代码如下:
💡
(点击右侧◀展开查看 mineru_pipeline_all.py 参考代码)
这段代码的核心目标是搭建一个自动化的数据预处理流水线。
它的作用是接收原始的 PDF 文件,然后通过一系列步骤,最终生成一个结构化的 JSON 文件( all_pdf_page_chunks.json )。
这个 JSON 文件就是我们构建 RAG 知识库所需要的最终材料,里面的每一项都是一个知识块,可以直接用于后续的向量化和索引。
我们可以把整个过程理解成一个三步走的流水线。
💡
第一步:用 MinerU 解析 PDF ( parse_all_pdfs 函数)
💡
第二步:将解析结果整理成 Markdown 格式 ( process_all_pdfs_to_page_json 函数)
💡
第三步:汇总所有内容,生成最终的知识库文件 ( process_page_content_to_chunks 函数)
进阶要点2:“粗召回”与“精召回”的检索策略
另一个要点是检索策略。
当知识库内容更丰富后,如何精确查找就变得更重要。
我们可以采用一个两步走的检索策略,也就是先“召回”再“重排”。
第一步“召回”,用向量检索或者关键词检索(比如BM25算法),快速地找到一个比较大的候选范围,目的是把相关的都找出来。
第二步“重排”,用一个更精准的重排模型,比如 FlagEmbedding 仓库里的 BGE-ReRanker 模型,来给这些候选项和问题的相关性打分,然后选出分数最高的几个。
这种方式能有效地提升检索结果的信噪比。
其中rerank的模型可以使用FlagEmbedding进行推理:
from FlagEmbedding import FlagReranker
model = FlagReranker(
‘BAAI/bge-reranker-large’,
use_fp16=True,
devices=[“cuda:0”], # 如果没有 GPU,可以使用 “cpu”
)
pairs = [
[“法国的首都是什么?”, “巴黎是法国的首都。”],
[“法国的首都是什么?”, “中国的人口超过14亿人。”],
[“中国的人口是多少?”, “巴黎是法国的首都。”],
[“中国的人口是多少?”, “中国的人口超过14亿人。”]
]
scores = model.compute_score(pairs)
scores
运行上面的代码后会输出:
[7.42578125, -9.2421875, -9.484375, 5.51953125]
四、还可以尝试尝试这些进阶方法和思路
还有哪些创新性的 方案和方向 可以去思考?
如何想出、实现更多创新、多元的方案?
进阶思路1:多路召回与融合
除了上面提到的优化点,我们还可以看看其他一些方案。
我们还可以尝试多路召回与融合的思路。这个方法的核心是同时使用多种不同的检索方式,从不同角度去寻找相关的知识块,然后再把找到的结果合并起来。
比如,我们可以并行运行两种检索:一种是基于关键词的检索,像 BM25 算法,它擅长匹配问题中出现的具体词语;另一种是基于向量的语义检索,使用 embedding 模型来查找意思相近但用词可能不同的内容。这样,两条通路可以形成优势互补。
图片
在从不同通路拿到各自的召回结果列表后,接下来的问题就是如何把它们融合成一个更高质量的排序。
这里通常有两种处理思路:
第一种是使用重排模型(Re-ranker)。
我们可以把所有通路召回的结果汇总到一起,然后用一个重排模型,比如基于 FlagEmbedding 的模型,来对这个大集合进行统一的、更精细的相关性打分,最后选出分数最高的几个结果。
第二种是使用无需训练模型的融合算法,
一个常见的例子是倒数排名融合(Reciprocal Rank Fusion, RRF)。
这种方法会根据每个文档在不同召回列表中的排名位置,来计算出一个综合分数,然后根据这个综合分数生成一个新的排序。
无论采用哪种融合方式,最终的目标都是得到一个排序更优的上下文列表,再将这个列表交给大语言模型去生成答案。
进阶思路2:构建知识图谱
还有一个方向是构建知识图谱。现在我们的知识库里的知识块是相互独立的,但原文中它们是有结构联系的。
我们可以把一份文档表示成一个知识图谱,里面的节点可以是段落、表格、图表、公司名等实体,边则表示它们之间的关系,比如“位于”、“描述”或者“属于”。
这样,在回答一些需要多步推理的问题时,就可以通过图谱的查询来找到答案。
图片
进阶思路3:让RAG系统拥有自我修正的能力
我们甚至可以考虑让RAG系统拥有自我修正的能力。
具体来说,就是让系统在检索一次之后,能自己判断一下找到的上下文够不够回答问题。
如果不够,它可以自己生成一个新的、更具体的查询语句,再次进行检索,把两次的结果合在一起再生成答案。
这会让整个问答过程更动态一些。
图片
进阶思路4:模型微调
整个微调流程可以分为两大步: 数据准备 和 模型训练 。主要涉及到 spark_data_process.ipynb 和 spark_model_finetune.ipynb 两个文件。
4.1 数据准备 (spark_data_process.ipynb)
模型微调的第一步,也是最关键的一步,是准备高质量的训练数据。
我们的目标是利用官方提供的 train.json ,将其转换为模型能够理解的“指令-输入-输出”格式。
这一过程在 spark_data_process.ipynb 中完成。
核心目标 :将原始的问答数据,转换为符合Alpaca指令格式的 qa_train.json 文件。
💡
点击右侧◀展开 spark_data_process.ipynb参考代码
spark_data_process.ipynb 的核心逻辑是将每个问答对(Q&A pair)包装成一个结构化的字典。
输入与输出 : input 字段对应原始问题,output 字段对应标准答案。模型在训练时会学习到,在收到这样的 instruction 和 input 后,应该生成类似 output 的回答。
最终产物 :执行该脚本后,我们会得到 qa_train.json 文件,这是下一步模型训练的直接输入。
我们通过提供一个固定的 instruction (指令),作为学习材料,通过微调教会模型在我们这个财报任务下的“角色”和“任务”。
这使得模型在面对新的问题时,能更好地按照我们期望的身份和方式来回答。
4.2 模型训练 (spark_model_finetune.ipynb)
有了标准格式的训练数据,我们就可以开始进行模型的有监督微调(Supervised Fine-Tuning, SFT)。
我们在参考代码中使用了 unsloth 框架高效微调 Qwen2.5-7B 。
💡
- 环境配置与模型加载
💡
2. 添加LoRA适配器
💡
3. 加载并格式化数据
💡
4. 配置并启动训练
💡
5. 推理验证与模型保存
通过以上步骤,我们就完成了一次完整的模型微调。得到的 lora_model 文件夹包含了微调后的模型权重,可以在RAG的生成环节加载它。
通过系统的模型微调,我们可以显著提升RAG系统在财报问答任务上的表现。
微调后的模型不仅能更准确地理解财报术语,还能更好地遵循输出格式要求,为最终的评分提升打下坚实的基础。
不过数据量可能需要进一步的扩展,因为训练集可能还是属于比较少的,如果需要真正能提高在排行榜上的分数,还是建议去做一些数据工程。
附录:补充知识点概述
Re-ranking ,中文叫重排。它是在RAG检索流程中,初步召回一批候选内容后,用一个更精准的模型对这些内容与问题的相关性重新排序的步骤。
Hybrid Search ,混合检索。它通常指结合了关键词检索(如BM25)和向量检索两种方式的检索策略,能同时利用两种方法的优点。
Vision-Language Model (VLM) ,视觉语言模型,也就是我们说的多模态大模型。它能同时处理图像和文本信息。
Knowledge Graph ,知识图谱。它是一种用图的结构来表示知识和实体间关系的方法。
更多参考资料推荐
为什么你的RAG效果总差一点?从RankNet到Qwen,一文读懂Rerank模型的演进:
https://mp.weixin.qq.com/s/10Tx71A8SMj4ja_wVoYeTg
RAG系统召回率低? BGE-M3 多语言多功能重塑文本检索:
https://mp.weixin.qq.com/s/1PURiKFP1WBx6VnScszm3A
多模态RAG的三类图文问答实现方式,你知道多少种?:
https://mp.weixin.qq.com/s/FXyjbalyDB21RFOVW1O_RA
搭建RAG系统时,可能会遇到的7个具体问题:
https://arxiv.org/html/2401.05856v1
一种带有“自我修正”能力的RAG方法:
https://arxiv.org/abs/2401.15884
LlamaIndex 是一个专门用来构建RAG应用的框架:
https://docs.llamaindex.ai/en/stable/
Hugging Face 官方提供的模型训练指南:
https://huggingface.co/docs/transformers/training
Unsloth 是一个高效训练模型的框架:
https://docs.unsloth.ai/
LangGraph是用来构建有状态、多步骤应用的程序库:
https://github.com/langchain-ai/langgraph
MinerU是功能强大的文档解析工具,能将PDF精准地转换为结构化的Markdown或JSON:
https://mineru.net/
https://github.com/opendatalab/MinerU