深入理解动态规划算法
1. 引言
在当今复杂多变的软件开发环境中,高效的算法设计与实现对于构建性能卓越的应用系统至关重要。作为Java后端开发者,我们经常面临各种需要最优化解决方案的问题,如资源分配、路径规划、数据处理等。在众多算法技术中,动态规划因其强大的解决复杂问题的能力而备受关注。
动态规划(Dynamic Programming,简称DP)是一种解决复杂问题的强大算法技术,通过将问题分解为相互重叠的子问题并存储子问题的解来避免重复计算。本文将深入探讨动态规划算法的核心概念、设计思想和实现方法,特别针对Java后端开发者的实际需求。
1.1 动态规划算法的重要性和应用场景
动态规划算法最初由美国数学家理查德·贝尔曼(Richard Bellman)在20世纪50年代提出,旨在解决多阶段决策过程中的最优化问题[1]。半个多世纪以来,动态规划已经发展成为计算机科学中最重要的算法设计技术之一,广泛应用于以下场景:
- 资源调度优化:在云计算和分布式系统中,动态规划可以帮助优化资源分配,提高系统吞吐量和响应速度。
- 路径规划:在网络路由、导航系统和物流配送中,动态规划可以计算最短路径或最优配送方案。
- 自然语言处理:在文本分析、语音识别和机器翻译中,动态规划用于序列对齐和模式匹配。
- 生物信息学:在DNA序列比对、蛋白质结构预测等领域,动态规划是核心算法技术。
- 金融决策:在投资组合优化、风险管理和期权定价中,动态规划提供了数学基础。
- 游戏AI:在策略游戏和博弈论中,动态规划用于计算最优策略。
在Java后端开发中,动态规划算法的应用尤为广泛。从数据库查询优化到缓存策略设计,从API限流算法到推荐系统,动态规划都扮演着重要角色。掌握动态规划不仅能帮助开发者解决复杂的业务问题,还能显著提升系统性能和用户体验。
1.2 为什么Java后端开发者需要掌握动态规划
作为Java后端开发者,我们可能会认为算法优化是算法工程师的工作,而我们只需专注于业务逻辑和系统架构。然而,这种观点在当今高度竞争的技术环境中已经不再适用。以下是Java后端开发者需要掌握动态规划的几个关键原因:
-
性能优化:在处理大规模数据和高并发请求时,算法效率直接影响系统性能。动态规划可以显著减少计算复杂度,提高响应速度。
-
解决复杂业务问题:许多业务问题本质上是最优化问题,如资源分配、定价策略、推荐系统等,动态规划提供了解决这类问题的系统方法。
-
提升代码质量:理解动态规划的思想有助于编写更加简洁、高效的代码,减少冗余计算和不必要的资源消耗。
-
技术面试优势:动态规划是技术面试中的常见题型,尤其是在大型科技公司。掌握动态规划可以增加求职竞争力。
-
跨领域应用能力:动态规划的思想不仅限于算法实现,还可以应用于系统设计、架构决策等更广泛的领域。
1.3 文章内容概述
本文将系统地介绍动态规划算法,从基础理论到实际应用,帮助Java后端开发者全面掌握这一强大的算法技术。具体内容包括:
- 动态规划基础理论:深入理解动态规划的核心概念、适用条件和与其他算法的比较。
- 动态规划设计步骤:掌握从问题分析到算法实现的完整流程。
- 经典动态规划问题及Java实现:通过斐波那契数列、最长公共子序列、0-1背包等经典问题,学习动态规划的实际应用。
- 动态规划在实际项目中的应用:探讨动态规划在资源调度、路径规划、缓存策略等实际场景中的应用。
- 动态规划的优化技巧:学习状态压缩、记忆化搜索等高级优化方法。
- 总结与进阶:提供学习方法、面试技巧和进阶资源。
通过本文的学习,读者将能够系统地理解动态规划的原理,掌握动态规划问题的分析和解决方法,并能在实际工作中灵活应用动态规划技术,提升代码质量和系统性能。
让我们开始这段深入理解动态规划算法的旅程,探索这一强大算法技术的奥秘,并将其应用到Java后端开发的实际工作中。
2. 动态规划基础理论
动态规划是一种通过将复杂问题分解为更简单的子问题来解决问题的算法技术。与分治法类似,动态规划也是基于子问题的解构建原问题的解,但不同的是,动态规划适用于子问题重叠的情况,通过存储子问题的解来避免重复计算,从而提高算法效率。
2.1 动态规划的定义和核心思想
动态规划(Dynamic Programming,简称DP)是一种用于解决最优化问题的数学方法和计算机算法。"动态"一词并不是指问题本身具有动态性,而是指算法在求解过程中动态地构建问题的解[2]。
动态规划的核心思想可以概括为以下几点:
- 问题分解:将原问题分解为相互关联的子问题。
- 状态定义:用状态来表示问题的解,状态通常是一个或多个变量的函数。
- 递推关系:建立状态之间的递推关系,即状态转移方程。
- 边界条件:确定初始状态和边界条件。
- 自底向上:从最小的子问题开始,逐步构建更大问题的解。
- 记忆化:存储已解决的子问题的解,避免重复计算。
动态规划的精髓在于"记住过去,影响未来"。通过存储已经计算过的子问题的解,避免重复计算,从而大幅提高算法效率。这种思想在处理具有重叠子问题和最优子结构的问题时特别有效。
2.2 动态规划与其他算法的比较
为了更好地理解动态规划的特点和适用场景,我们将其与几种常见的算法设计技术进行比较:
2.2.1 动态规划 vs 贪心算法
贪心算法在每一步都选择当前看起来最优的解,而不考虑这一选择对未来的影响。贪心算法简单高效,但只适用于具有"贪心选择性质"的问题,即局部最优解可以导致全局最优解。
动态规划则更为全面,它通过考虑所有可能的子问题解来找到全局最优解。动态规划适用范围更广,但计算复杂度通常也更高。
| 特性 | 动态规划 | 贪心算法 |
|---|---|---|
| 决策方式 | 全局最优 | 局部最优 |
| 适用条件 | 最优子结构、重叠子问题 | 贪心选择性质 |
| 时间复杂度 | 通常为O(n²)或更高 | 通常为O(n log n)或O(n) |
| 实现难度 | 较高 | 较低 |
| 解的质量 | 保证最优解 | 不一定是最优解 |
2.2.2 动态规划 vs 分治法
分治法(Divide and Conquer)也是将问题分解为子问题,但分治法处理的子问题通常是相互独立的,而动态规划处理的子问题往往是重叠的。
| 特性 | 动态规划 | 分治法 |
|---|---|---|
| 子问题特性 | 重叠子问题 | 独立子问题 |
| 解决方式 | 自底向上或自顶向下+记忆化 | 自顶向下递归 |
| 存储方式 | 使用表格或数组存储子问题解 | 不存储中间结果 |
| 典型应用 | 最长公共子序列、背包问题 | 归并排序、快速排序 |
2.2.3 动态规划 vs 回溯法
回溯法是一种通过试错来解决问题的方法,它尝试所有可能的解,直到找到满足条件的解。回溯法适用于需要找到所有可能解或满足特定条件的解的问题。
| 特性 | 动态规划 | 回溯法 |
|---|---|---|
| 搜索方式 | 系统地构建解 | 深度优先搜索 |
| 时间复杂度 | 多项式时间(通常) | 指数时间(通常) |
| 适用问题 | 最优化问题 | 组合问题、约束满足问题 |
| 解的类型 | 通常找最优解 | 找所有解或特定解 |
2.3 动态规划的适用条件
并非所有问题都适合用动态规划来解决。动态规划主要适用于具有以下两个关键特性的问题:
2.3.1 最优子结构
最优子结构(Optimal Substructure)是指问题的最优解包含其子问题的最优解。换句话说,可以通过组合子问题的最优解来构造原问题的最优解。
例如,在最短路径问题中,如果从点A到点C的最短路径经过点B,那么从A到B的路径和从B到C的路径都必须是最短的。这就是最优子结构的体现。
最优子结构是动态规划能够工作的基础,它保证了我们可以通过解决子问题来解决原问题。
2.3.2 重叠子问题
重叠子问题(Overlapping Subproblems)是指在求解过程中,同一个子问题会被多次计算。动态规划通过存储已解决的子问题的解,避免重复计算,从而提高效率。
斐波那契数列是重叠子问题的典型例子。计算F(n)需要先计算F(n-1)和F(n-2),而计算F(n-1)又需要计算F(n-2)和F(n-3),这样F(n-2)就被重复计算了。
如果问题没有重叠子问题,那么使用动态规划可能不会比简单的递归更有效率。
2.4 动态规划的实现方式
动态规划有两种主要的实现方式:自顶向下的记忆化搜索和自底向上的表格填充。
2.4.1 自顶向下的记忆化搜索
自顶向下的方法(Top-down Approach)也称为记忆化搜索(Memoization),它从原问题开始,递归地解决子问题,并将子问题的解存储在一个表(通常是数组或哈希表)中。当需要重复计算某个子问题时,直接从表中获取结果,避免重复计算。
记忆化搜索的优点是实现直观,接近问题的递归定义,容易理解和调试。缺点是可能导致栈溢出(对于深度递归),且有一定的函数调用开销。
// 使用记忆化搜索计算斐波那契数列
public class FibonacciMemoization {private Map<Integer, Long> memo = new HashMap<>();public long fibonacci(int n) {if (n <= 1) return n;// 检查是否已经计算过if (memo.containsKey(n)) {return memo.get(n);}// 递归计算并存储结果long result = fibonacci(n - 1) + fibonacci(n - 2);memo.put(n, result);return result;}
}
2.4.2 自底向上的表格填充
自底向上的方法(Bottom-up Approach)从最小的子问题开始,逐步解决更大的子问题,直到解决原问题。这种方法通常使用数组或表格来存储子问题的解。
自底向上的方法避免了递归调用的开销,不会导致栈溢出,通常效率更高。缺点是实现可能不如记忆化搜索直观,有时需要额外的空间来存储中间结果。
// 使用自底向上方法计算斐波那契数列
public class FibonacciTabulation {public long fibonacci(int n) {if (n <= 1) return n;long[] dp = new long[n + 1];dp[0] = 0;dp[1] = 1;for (int i = 2; i <= n; i++) {dp[i] = dp[i - 1] + dp[i - 2];}return dp[n];}
}
在实际应用中,选择哪种实现方式取决于问题的特性、空间复杂度要求以及个人偏好。对于某些问题,自顶向下的方法可能更自然;而对于另一些问题,自底向上的方法可能更高效。
通过理解动态规划的基础理论和适用条件,我们为后续深入学习动态规划的设计步骤和实际应用奠定了基础。在下一节中,我们将详细介绍动态规划问题的解决步骤,帮助读者掌握系统的动态规划问题分析方法。
3. 动态规划设计步骤
成功应用动态规划解决问题需要遵循一系列系统的步骤。这些步骤不仅帮助我们理清问题的结构,还能指导我们构建高效的算法实现。在本节中,我们将详细介绍动态规划问题的解决步骤,并通过实例说明如何应用这些步骤。
3.1 明确状态定义
状态是动态规划中的核心概念,它表示问题在某一阶段的解或特征。明确定义状态是解决动态规划问题的第一步,也是最关键的一步。
3.1.1 什么是状态
状态通常表示为一个或多个变量的函数,它描述了问题在特定条件下的情况。在动态规划中,我们使用状态来表示子问题的解,通过组合这些子问题的解来构建原问题的解。
状态的定义应该满足以下条件:
- 完备性:状态应能完整描述问题在某一阶段的情况。
- 无后效性:当前状态的决策只与当前状态有关,与之前的决策过程无关。
- 有限性:状态的数量应该是有限的,或者至少是可计算的。
3.1.2 如何定义状态
定义状态时,我们需要考虑以下几个方面:
- 问题的目标:明确我们要优化的目标是什么(最大值、最小值、计数等)。
- 问题的约束:考虑问题中的各种限制条件。
- 问题的变化因素:识别问题中会变化的因素,这些通常成为状态变量。
例如,在0-1背包问题中,我们的目标是最大化背包中物品的总价值,约束是背包的容量限制,变化因素是考虑的物品数量和剩余容量。因此,我们可以定义状态dp[i][j]表示考虑前i个物品,背包剩余容量为j时能获得的最大价值。
3.1.3 状态的表示方式
在实际编程中,状态通常表示为数组的索引。根据问题的复杂度,状态可能是一维、二维或多维的:
- 一维状态:如斐波那契数列问题中的dp[i]表示第i个斐波那契数。
- 二维状态:如最长公共子序列问题中的dp[i][j]表示字符串s1的前i个字符和字符串s2的前j个字符的最长公共子序列长度。
- 多维状态:如某些复杂问题可能需要三维或更高维度的状态表示。
3.2 确定状态转移方程
状态转移方程是动态规划的核心,它描述了如何从已知的子问题解构建更大问题的解。确定状态转移方程需要深入分析问题的结构和子问题之间的关系。
3.2.1 什么是状态转移方程
状态转移方程是一个递推式,它表示当前状态与前一个或多个状态之间的关系。通过状态转移方程,我们可以利用已经计算出的子问题的解来计算当前问题的解。
3.2.2 如何推导状态转移方程
推导状态转移方程通常需要以下步骤:
- 分析问题的结构:理解问题的本质和子问题之间的关系。
- 考虑决策选择:在每个状态下,我们可能有多种决策选择,每种选择导致不同的结果。
- 建立递推关系:根据决策选择,建立当前状态与前一个或多个状态之间的递推关系。
例如,在最长递增子序列问题中,如果我们定义dp[i]为以第i个元素结尾的最长递增子序列的长度,那么状态转移方程可以表示为:
dp[i] = max(dp[j] + 1) for all j < i and nums[j] < nums[i]
这个方程表示,对于每个位置i,我们考虑所有在i之前且元素值小于nums[i]的位置j,取dp[j] + 1的最大值作为dp[i]的值。
3.2.3 状态转移方程的验证
推导出状态转移方程后,我们应该通过一些简单的例子来验证其正确性。验证过程包括:
- 手动计算:使用状态转移方程手动计算一些简单例子的结果。
- 边界检查:确保状态转移方程在边界情况下也能正确工作。
- 逻辑分析:分析状态转移方程是否符合问题的逻辑和约束。
3.3 确定初始状态与边界条件
初始状态和边界条件是动态规划算法的起点,它们为状态转移过程提供了基础。正确设置初始状态和边界条件对于算法的正确性至关重要。
3.3.1 初始状态的确定
初始状态通常是问题规模最小时的解。例如,在斐波那契数列问题中,初始状态是F(0) = 0和F(1) = 1。
确定初始状态时,我们需要考虑:
- 问题规模最小时的情况是什么?
- 这种情况下的解是什么?
- 如何在我们的状态表示中表达这个初始解?
3.3.2 边界条件的处理
边界条件是指在状态转移过程中可能遇到的特殊情况,如索引越界、空输入等。正确处理边界条件可以避免运行时错误和逻辑错误。
处理边界条件时,我们需要考虑:
- 状态转移过程中可能遇到哪些特殊情况?
- 这些特殊情况应该如何处理?
- 是否需要在状态数组中预留额外的空间来处理边界情况?
例如,在最长公共子序列问题中,我们通常会定义dp[0][j]和dp[i][0]为0,表示空字符串与任何字符串的最长公共子序列长度为0。
3.4 计算并输出最终答案
一旦我们定义了状态、确定了状态转移方程和初始条件,就可以开始计算问题的解。这一步通常涉及填充状态数组并找到最终答案。
3.4.1 填充状态数组
填充状态数组有两种主要方法:自顶向下的记忆化搜索和自底向上的表格填充。无论使用哪种方法,我们都需要按照状态转移方程的要求,系统地计算每个状态的值。
在自底向上的方法中,我们通常使用嵌套循环来填充状态数组:
// 以最长递增子序列为例
public int lengthOfLIS(int[] nums) {int n = nums.length;int[] dp = new int[n];Arrays.fill(dp, 1); // 初始化每个元素自身构成长度为1的子序列for (int i = 1; i < n; i++) {for (int j = 0; j < i; j++) {if (nums[i] > nums[j]) {dp[i] = Math.max(dp[i], dp[j] + 1);}}}// 找到最大值int maxLength = 0;for (int length : dp) {maxLength = Math.max(maxLength, length);}return maxLength;
}
3.4.2 提取最终答案
在某些问题中,最终答案可能不是状态数组中的某个特定值,而是需要从状态数组中提取或计算得出。例如,在上面的最长递增子序列问题中,最终答案是dp数组中的最大值。
有时,我们可能还需要重构解的路径,即找出导致最优解的具体决策序列。这通常需要额外的数据结构来记录决策过程。
3.5 优化空间复杂度
在许多动态规划问题中,我们可以优化算法的空间复杂度,特别是当状态只依赖于前一个或几个状态时。
3.5.1 滚动数组
滚动数组是一种常用的空间优化技术,它利用状态转移只依赖于前几个状态的特性,使用有限的空间来存储必要的状态。
例如,在斐波那契数列问题中,我们可以只使用两个变量而不是整个数组:
public long fibonacci(int n) {if (n <= 1) return n;long prev = 0;long curr = 1;for (int i = 2; i <= n; i++) {long next = prev + curr;prev = curr;curr = next;}return curr;
}
3.5.2 状态压缩
对于某些二维动态规划问题,如果当前行的状态只依赖于前一行的状态,我们可以将二维数组压缩为一维数组,进一步节省空间。
例如,在0-1背包问题中,我们可以将二维的dp[i][j]压缩为一维的dp[j]:
// 二维DP实现
public int knapsack2D(int[] weights, int[] values, int capacity) {int n = weights.length;int[][] dp = new int[n + 1][capacity + 1];for (int i = 1; i <= n; i++) {for (int j = 0; j <= capacity; j++) {if (weights[i - 1] <= j) {dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weights[i - 1]] + values[i - 1]);} else {dp[i][j] = dp[i - 1][j];}}}return dp[n][capacity];
}// 一维DP实现(状态压缩)
public int knapsack1D(int[] weights, int[] values, int capacity) {int n = weights.length;int[] dp = new int[capacity + 1];for (int i = 0; i < n; i++) {// 注意这里需要从后向前遍历,避免重复使用同一物品for (int j = capacity; j >= weights[i]; j--) {dp[j] = Math.max(dp[j], dp[j - weights[i]] + values[i]);}}return dp[capacity];
}
通过遵循这些系统的动态规划设计步骤,我们可以有条理地分析和解决各种动态规划问题。在下一节中,我们将通过一系列经典的动态规划问题及其Java实现,进一步巩固这些概念和技巧。
4. 经典动态规划问题及Java实现
理解动态规划的最佳方式是通过实际问题的解决。在本节中,我们将详细介绍几个经典的动态规划问题,并提供完整的Java实现。这些问题涵盖了动态规划的不同应用场景和技巧,帮助读者全面掌握动态规划的实际应用。
4.1 斐波那契数列问题
斐波那契数列是动态规划的入门问题,它简单而直观地展示了动态规划的核心思想:通过存储已计算的结果避免重复计算。
4.1.1 问题描述
斐波那契数列定义如下:
- F(0) = 0
- F(1) = 1
- F(n) = F(n-1) + F(n-2),当n > 1时
给定一个非负整数n,计算F(n)的值。
4.1.2 问题分析
斐波那契数列是动态规划的典型应用,因为它具有明显的重叠子问题特性。例如,计算F(5)需要计算F(4)和F(3),而计算F(4)又需要计算F(3)和F(2),这样F(3)就被重复计算了。
使用简单递归会导致指数级的时间复杂度,而使用动态规划可以将时间复杂度降低到线性级别。
4.1.3 动态规划解法
按照我们前面介绍的动态规划设计步骤,我们来解决斐波那契数列问题:
-
明确状态定义:
- 状态dp[i]表示第i个斐波那契数的值。
-
确定状态转移方程:
- dp[i] = dp[i-1] + dp[i-2],当i ≥ 2时。
-
确定初始状态与边界条件:
- dp[0] = 0
- dp[1] = 1
-
计算并输出最终答案:
- 答案为dp[n]。
-
优化空间复杂度:
- 由于每个状态只依赖于前两个状态,我们可以只使用两个变量而不是整个数组。
4.1.4 Java实现
下面是斐波那契数列的三种实现方式:简单递归、记忆化搜索和动态规划。
方法一:简单递归(不推荐,仅作对比)
public class FibonacciRecursive {public long fibonacci(int n) {if (n <= 1) return n;return fibonacci(n - 1) + fibonacci(n - 2);}
}
这种方法的时间复杂度是O(2^n),对于较大的n会导致栈溢出或计算时间过长。
方法二:记忆化搜索(自顶向下的动态规划)
public class FibonacciMemoization {private Map<Integer, Long> memo = new HashMap<>();public long fibonacci(int n) {if (n <= 1) return n;// 检查是否已经计算过if (memo.containsKey(n)) {return memo.get(n);}// 递归计算并存储结果long result = fibonacci(n - 1) + fibonacci(n - 2);memo.put(n, result);return result;}
}
这种方法的时间复杂度是O(n),空间复杂度也是O(n)。
方法三:动态规划(自底向上)
public class FibonacciDP {public long fibonacci(int n) {if (n <= 1) return n;long[] dp = new long[n + 1];dp[0] = 0;dp[1] = 1;for (int i = 2; i <= n; i++) {dp[i] = dp[i - 1] + dp[i - 2];}return dp[n];}
}
这种方法的时间复杂度是O(n),空间复杂度也是O(n)。
方法四:空间优化的动态规划
public class FibonacciOptimized {public long fibonacci(int n) {if (n <= 1) return n;long prev = 0;long curr = 1;for (int i = 2; i <= n; i++) {long next = prev + curr;prev = curr;curr = next;}return curr;}
}
这种方法的时间复杂度是O(n),空间复杂度降低到O(1)。
4.1.5 性能比较
为了直观地比较不同方法的性能差异,我们可以测试计算F(40)所需的时间:
| 方法 | 时间复杂度 | 空间复杂度 | F(40)计算时间 |
|---|---|---|---|
| 简单递归 | O(2^n) | O(n) | >10分钟 |
| 记忆化搜索 | O(n) | O(n) | <1毫秒 |
| 动态规划 | O(n) | O(n) | <1毫秒 |
| 空间优化的动态规划 | O(n) | O(1) | <1毫秒 |
这个例子清晰地展示了动态规划相对于简单递归的巨大性能优势,以及空间优化的重要性。
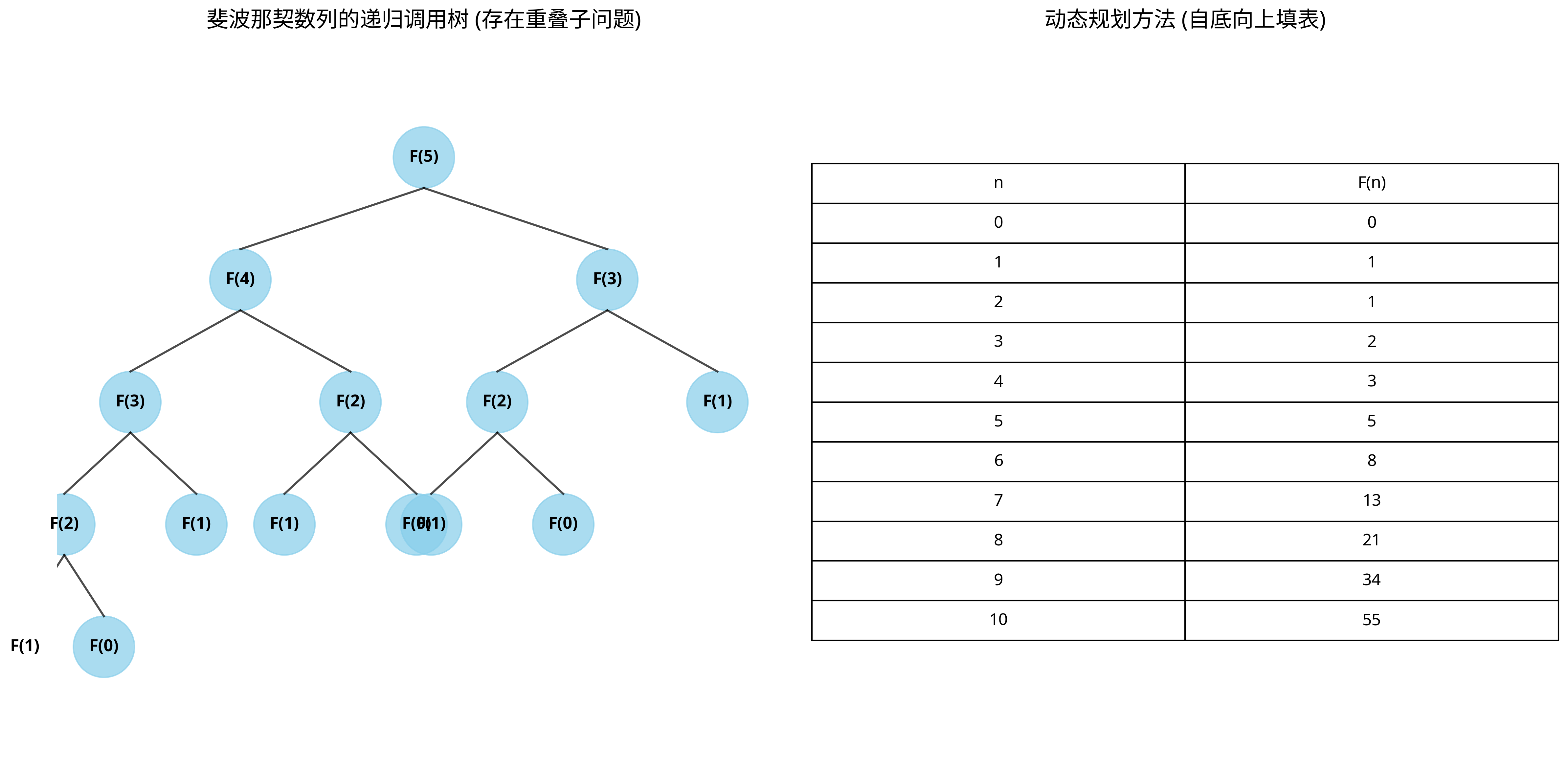
上图展示了斐波那契数列的递归调用树(左)和动态规划表格(右)。递归调用树中存在大量重叠子问题,而动态规划通过表格避免了重复计算。
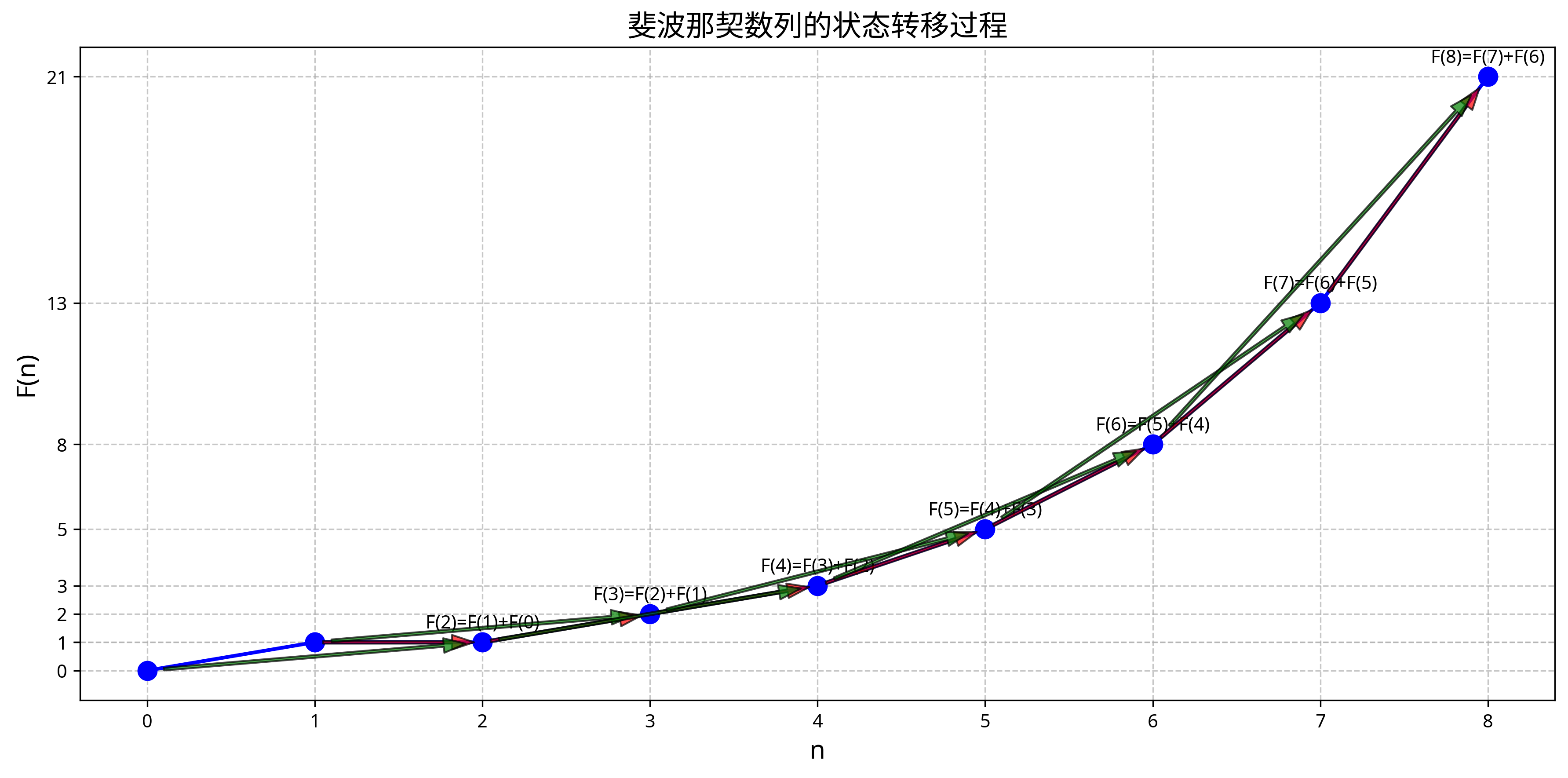
状态转移过程图清晰地展示了每个状态如何从前两个状态计算得出,体现了动态规划的自底向上构建解的特点。
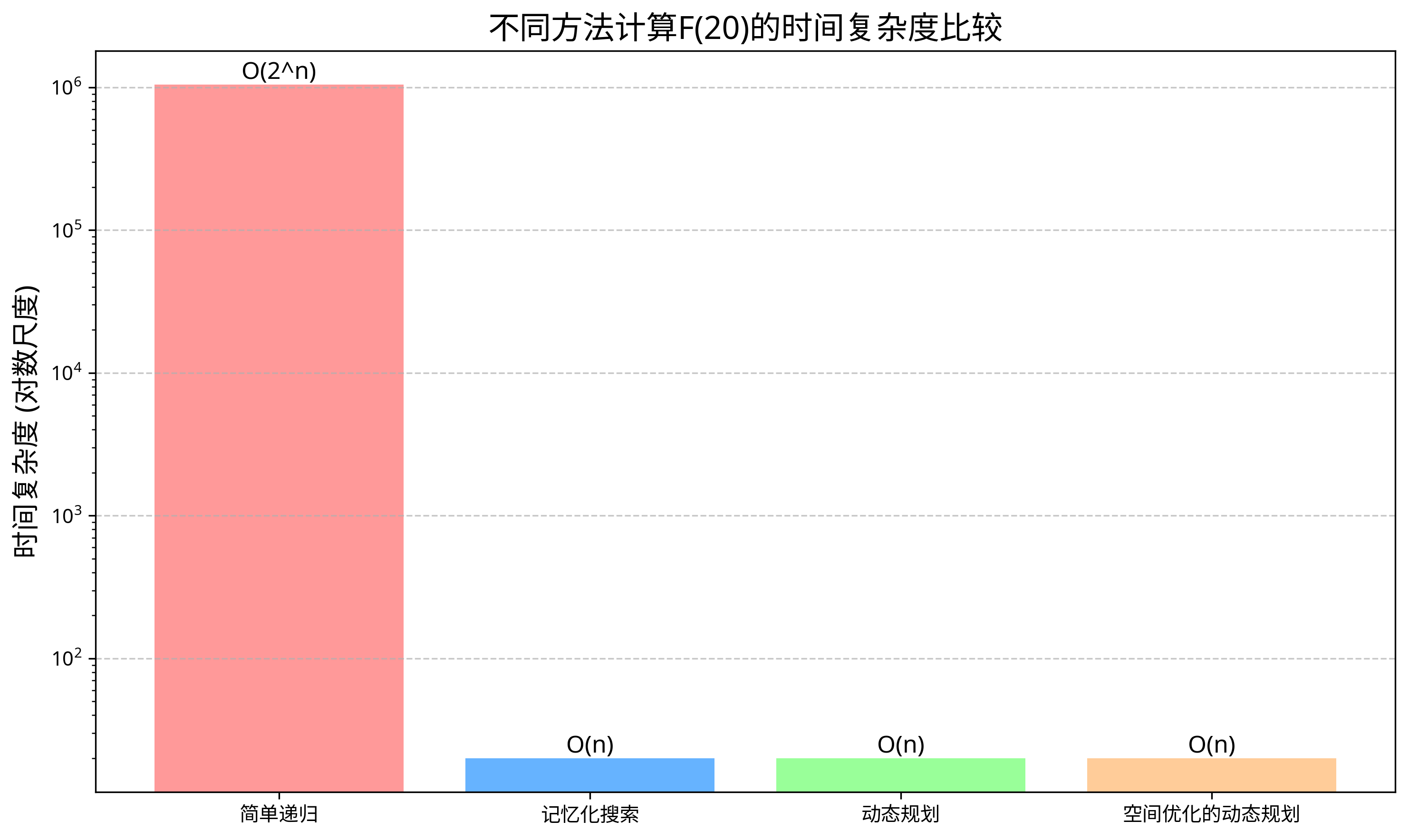
时间复杂度比较图直观地展示了动态规划相对于简单递归的巨大性能优势。
4.2 最长公共子序列问题
最长公共子序列(Longest Common Subsequence,简称LCS)是另一个经典的动态规划问题,它在生物信息学、文件比较、自然语言处理等领域有广泛应用。
4.2.1 问题描述
给定两个字符串text1和text2,返回这两个字符串的最长公共子序列的长度。
子序列是从原字符串中删除一些字符(可以不删除)后得到的新字符串,删除的字符不会改变剩余字符的相对位置。例如,"ace"是"abcde"的一个子序列。
两个字符串的公共子序列是同时是两个字符串的子序列的字符串。例如,"ace"是"abcde"和"acef"的一个公共子序列。
4.2.2 问题分析
最长公共子序列问题具有最优子结构和重叠子问题的特性,非常适合用动态规划来解决。
考虑两个字符串s1和s2,我们可以从后向前思考:
- 如果s1的最后一个字符等于s2的最后一个字符,那么这个字符一定在最长公共子序列中,我们可以将问题转化为求s1去掉最后一个字符和s2去掉最后一个字符的最长公共子序列,然后加1。
- 如果s1的最后一个字符不等于s2的最后一个字符,那么最长公共子序列要么不包含s1的最后一个字符,要么不包含s2的最后一个字符,我们取两种情况的最大值。
4.2.3 动态规划解法
-
明确状态定义:
- 状态dp[i][j]表示字符串s1的前i个字符和字符串s2的前j个字符的最长公共子序列的长度。
-
确定状态转移方程:
- 如果s1[i-1] == s2[j-1],则dp[i][j] = dp[i-1][j-1] + 1
- 如果s1[i-1] != s2[j-1],则dp[i][j] = max(dp[i-1][j], dp[i][j-1])
-
确定初始状态与边界条件:
- dp[0][j] = 0,表示空字符串与任何字符串的最长公共子序列长度为0
- dp[i][0] = 0,表示任何字符串与空字符串的最长公共子序列长度为0
-
计算并输出最终答案:
- 答案为dp[m][n],其中m和n分别是字符串s1和s2的长度。
4.2.4 Java实现
public class LongestCommonSubsequence {public int longestCommonSubsequence(String text1, String text2) {int m = text1.length();int n = text2.length();// 创建DP表格int[][] dp = new int[m + 1][n + 1];// 填充DP表格for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (text1.charAt(i - 1) == text2.charAt(j - 1)) {dp[i][j] = dp[i - 1][j - 1] + 1;} else {dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);}}}return dp[m][n];}// 获取最长公共子序列的具体内容public String getLCS(String text1, String text2) {int m = text1.length();int n = text2.length();int[][] dp = new int[m + 1][n + 1];// 填充DP表格for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (text1.charAt(i - 1) == text2.charAt(j - 1)) {dp[i][j] = dp[i - 1][j - 1] + 1;} else {dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);}}}// 回溯构建最长公共子序列StringBuilder sb = new StringBuilder();int i = m, j = n;while (i > 0 && j > 0) {if (text1.charAt(i - 1) == text2.charAt(j - 1)) {sb.append(text1.charAt(i - 1));i--;j--;} else if (dp[i - 1][j] > dp[i][j - 1]) {i--;} else {j--;}}return sb.reverse().toString();}
}
这个实现的时间复杂度是O(mn),空间复杂度也是O(mn),其中m和n分别是两个字符串的长度。
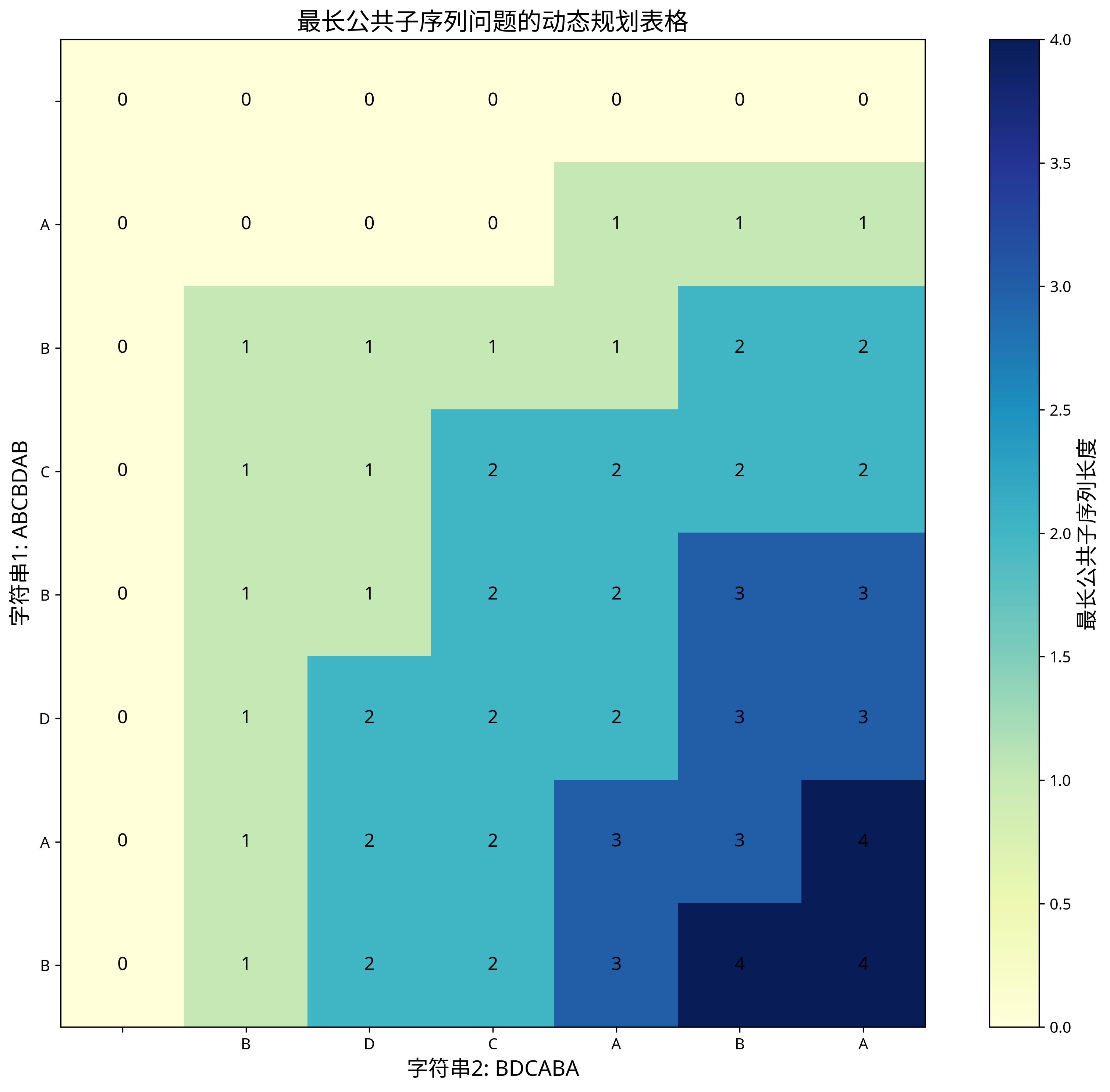
上图展示了最长公共子序列问题的动态规划表格,其中每个单元格的值表示对应子字符串的最长公共子序列长度。
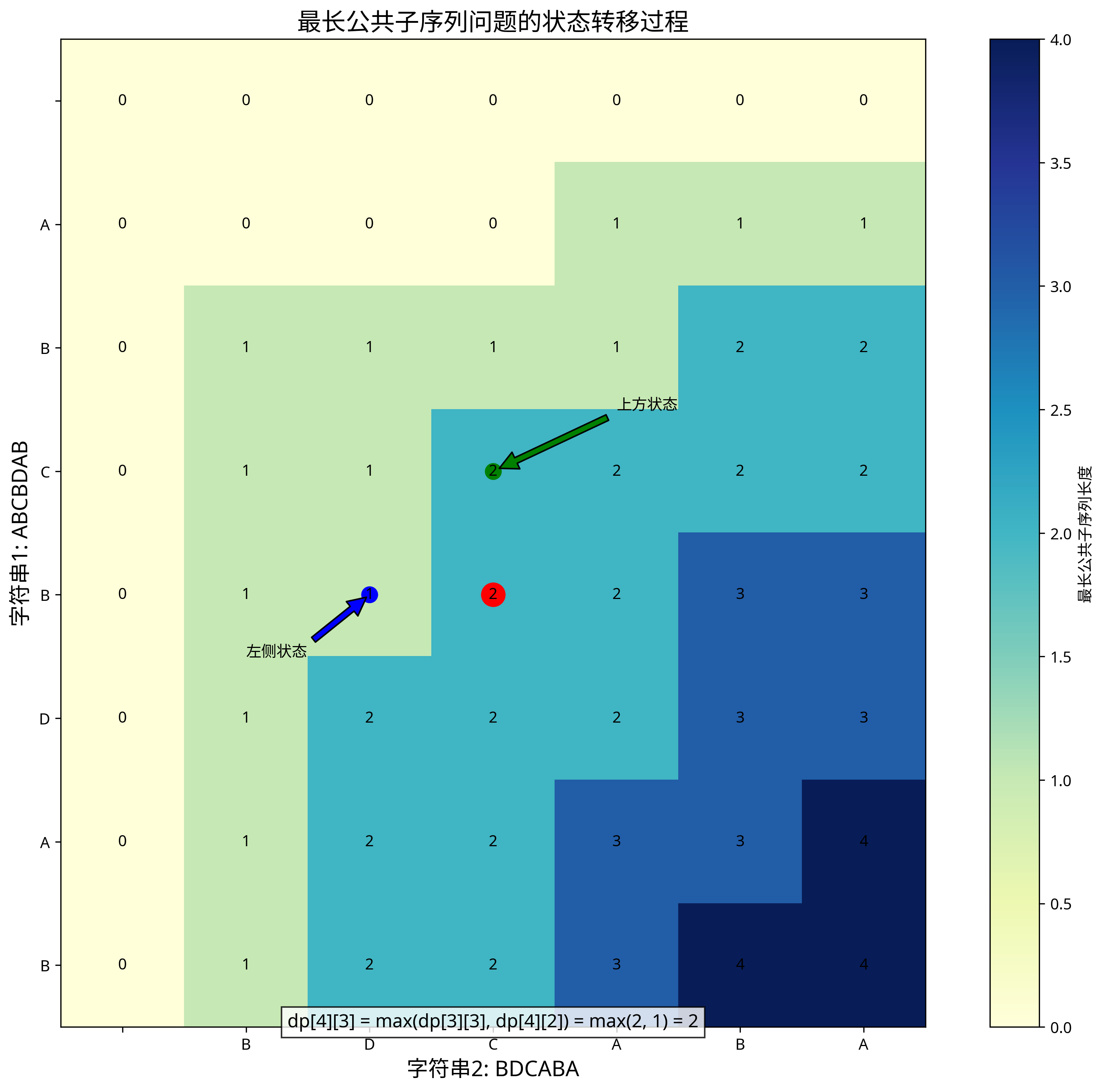
状态转移过程图展示了当字符不相等时,如何从上方和左侧状态中选择最大值作为当前状态的值。
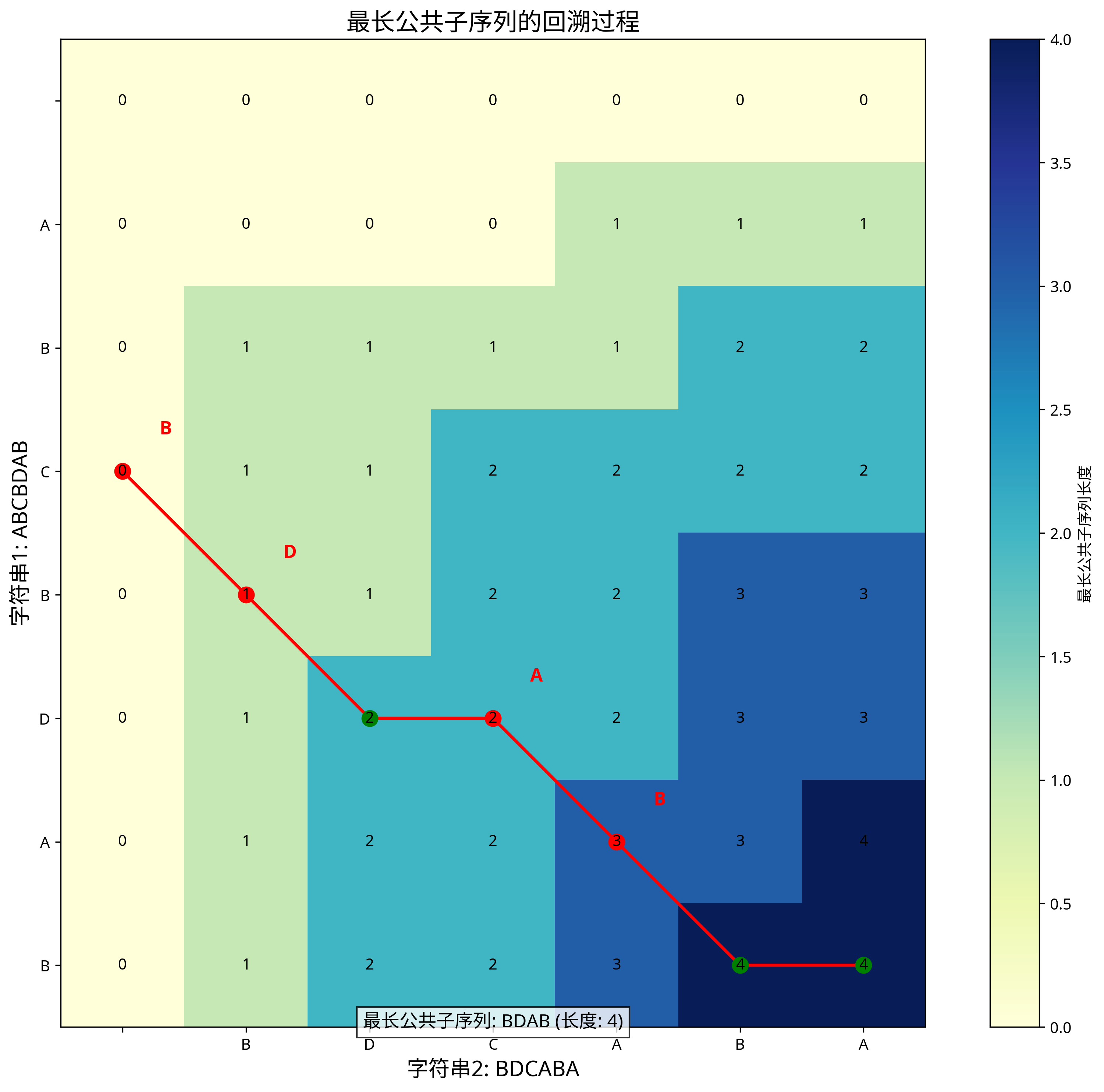
回溯过程图展示了如何从动态规划表格中重构出具体的最长公共子序列。
4.2.5 空间优化
由于每个状态只依赖于当前行的前一个状态和上一行的状态,我们可以将二维数组压缩为一维数组,将空间复杂度降低到O(min(m,n))。
public class LongestCommonSubsequenceOptimized {public int longestCommonSubsequence(String text1, String text2) {// 确保text1是较短的字符串,优化空间复杂度if (text1.length() > text2.length()) {String temp = text1;text1 = text2;text2 = temp;}int m = text1.length();int n = text2.length();// 只使用一维数组int[] dp = new int[m + 1];for (int j = 1; j <= n; j++) {int prev = 0; // dp[i-1][j-1]for (int i = 1; i <= m; i++) {int curr = dp[i]; // 保存dp[i][j-1]if (text1.charAt(i - 1) == text2.charAt(j - 1)) {dp[i] = prev + 1;} else {dp[i] = Math.max(dp[i], dp[i - 1]);}prev = curr;}}return dp[m];}
}
这个优化版本的时间复杂度仍然是O(m*n),但空间复杂度降低到了O(min(m,n))。
4.3 0-1背包问题
0-1背包问题是动态规划中的经典问题,也是许多实际应用问题的基础模型。
4.3.1 问题描述
有n个物品,每个物品有一个重量weight[i]和一个价值value[i]。现在有一个容量为capacity的背包,问如何选择物品放入背包,使得背包中物品的总价值最大。
每个物品只有一个,可以选择放或不放,不能部分放入(因此称为0-1背包问题)。
4.3.2 问题分析
0-1背包问题具有明显的最优子结构和重叠子问题特性。对于每个物品,我们有两种选择:放入背包或不放入背包。我们需要在这两种选择中取价值较大的一种。
4.3.3 动态规划解法
-
明确状态定义:
- 状态dp[i][j]表示考虑前i个物品,背包容量为j时能获得的最大价值。
-
确定状态转移方程:
- 如果第i个物品的重量大于当前背包容量j,则不能放入背包:dp[i][j] = dp[i-1][j]
- 如果第i个物品的重量小于等于当前背包容量j,则有两种选择:放入或不放入,取两者的最大值:dp[i][j] = max(dp[i-1][j], dp[i-1][j-weight[i-1]] + value[i-1])
-
确定初始状态与边界条件:
- dp[0][j] = 0,表示没有物品时,背包价值为0
- dp[i][0] = 0,表示背包容量为0时,无法放入任何物品,价值为0
-
计算并输出最终答案:
- 答案为dp[n][capacity],其中n是物品数量,capacity是背包容量。
4.3.4 Java实现
二维动态规划实现
public class Knapsack01 {public int knapsack(int[] weights, int[] values, int capacity) {int n = weights.length;int[][] dp = new int[n + 1][capacity + 1];// 填充DP表格for (int i = 1; i <= n; i++) {for (int j = 0; j <= capacity; j++) {if (weights[i - 1] <= j) {// 可以放入第i个物品dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weights[i - 1]] + values[i - 1]);} else {// 不能放入第i个物品dp[i][j] = dp[i - 1][j];}}}return dp[n][capacity];}// 获取放入背包的物品public List<Integer> getSelectedItems(int[] weights, int[] values, int capacity) {int n = weights.length;int[][] dp = new int[n + 1][capacity + 1];// 填充DP表格for (int i = 1; i <= n; i++) {for (int j = 0; j <= capacity; j++) {if (weights[i - 1] <= j) {dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weights[i - 1]] + values[i - 1]);} else {dp[i][j] = dp[i - 1][j];}}}// 回溯找出选择的物品List<Integer> selectedItems = new ArrayList<>();int i = n, j = capacity;while (i > 0 && j > 0) {if (dp[i][j] != dp[i - 1][j]) {// 选择了第i个物品selectedItems.add(i - 1);j -= weights[i - 1];}i--;}Collections.reverse(selectedItems);return selectedItems;}
}
一维动态规划实现(空间优化)
public class Knapsack01Optimized {public int knapsack(int[] weights, int[] values, int capacity) {int n = weights.length;int[] dp = new int[capacity + 1];for (int i = 0; i < n; i++) {// 从后向前遍历,避免重复使用同一物品for (int j = capacity; j >= weights[i]; j--) {dp[j] = Math.max(dp[j], dp[j - weights[i]] + values[i]);}}return dp[capacity];}
}
这个优化版本的时间复杂度是O(n*capacity),空间复杂度降低到O(capacity)。
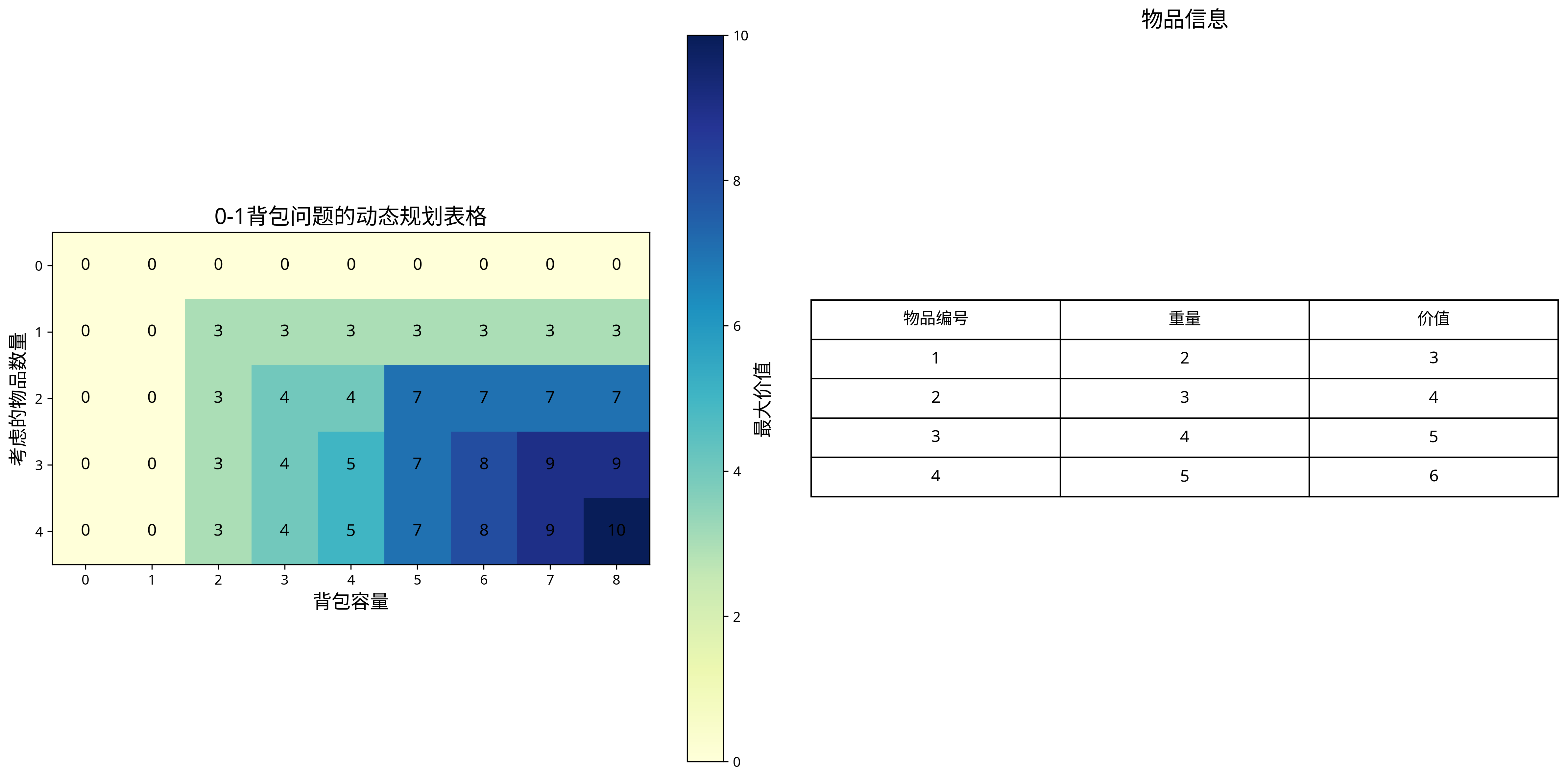
上图展示了0-1背包问题的动态规划表格,其中每个单元格的值表示在对应容量限制下能获得的最大价值。
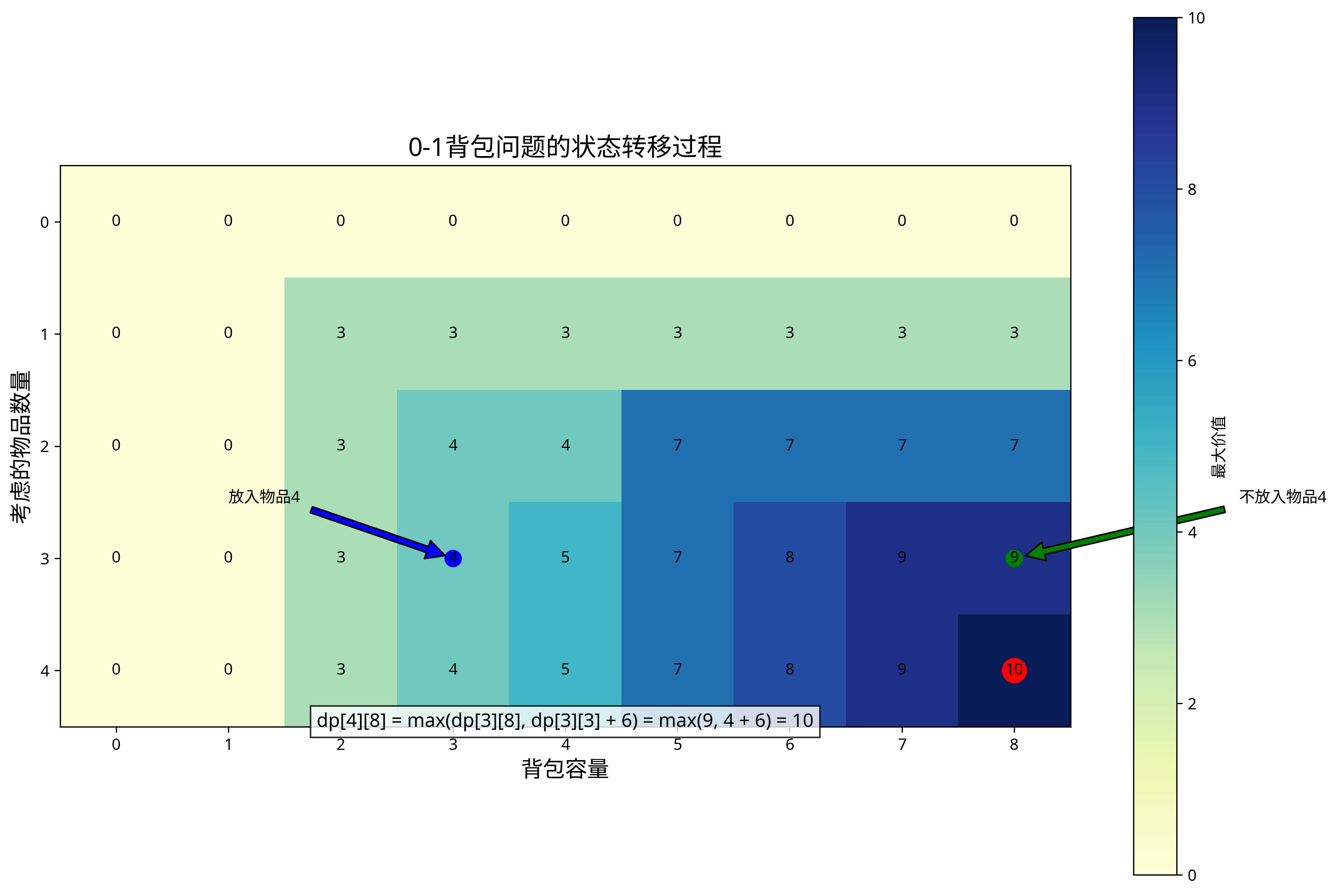
状态转移过程图展示了如何根据是否放入当前物品来选择最优策略。
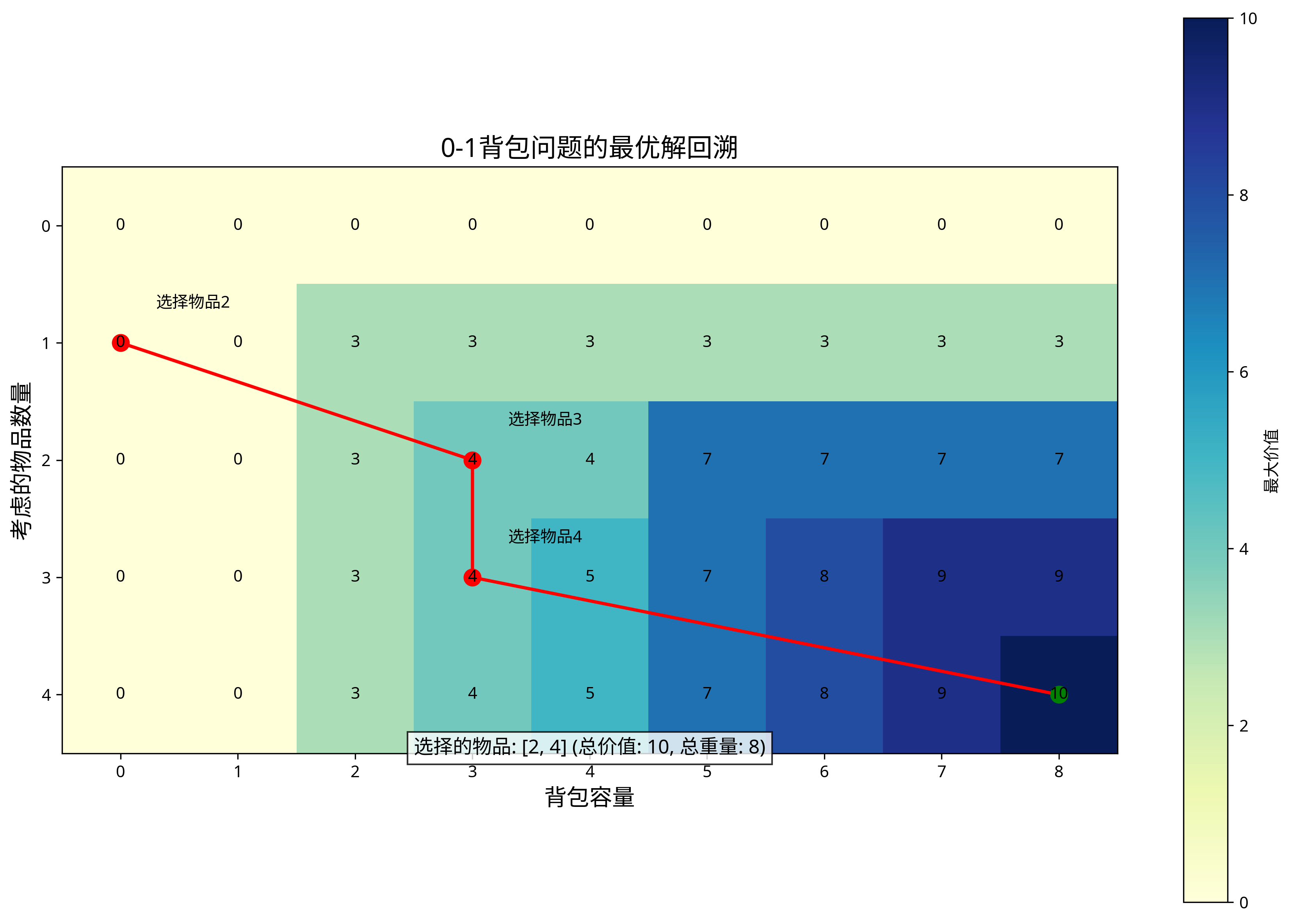
回溯过程图展示了如何从动态规划表格中重构出最优解,即选择哪些物品放入背包。
4.3.5 应用场景
0-1背包问题在实际应用中非常广泛,例如:
- 资源分配:在有限的资源(如内存、CPU时间)下,选择最有价值的任务执行。
- 投资决策:在有限的资金下,选择最有回报的投资组合。
- 物流配送:在有限的车辆载重下,选择最有价值的货物运输。
- 项目选择:在有限的预算下,选择最有价值的项目实施。
4.4 最长递增子序列问题
最长递增子序列(Longest Increasing Subsequence,简称LIS)是另一个经典的动态规划问题,它在数据分析、序列预测等领域有重要应用。
4.4.1 问题描述
给定一个无序的整数数组,找到其中最长上升子序列的长度。
例如,对于数组[10,9,2,5,3,7,101,18],最长的上升子序列是[2,3,7,101]或[2,5,7,101],长度为4。
4.4.2 问题分析
最长递增子序列问题可以用动态规划来解决。我们定义dp[i]为以第i个元素结尾的最长递增子序列的长度,然后对于每个位置i,我们考虑所有在i之前且元素值小于nums[i]的位置j,取dp[j] + 1的最大值作为dp[i]的值。
4.4.3 动态规划解法
-
明确状态定义:
- 状态dp[i]表示以第i个元素结尾的最长递增子序列的长度。
-
确定状态转移方程:
- dp[i] = max(dp[j] + 1) for all j < i and nums[j] < nums[i]
-
确定初始状态与边界条件:
- dp[i] = 1,表示每个元素自身构成长度为1的递增子序列。
-
计算并输出最终答案:
- 答案为max(dp[i]) for all 0 <= i < n。
4.4.4 Java实现
动态规划实现(O(n²))
public class LongestIncreasingSubsequence {public int lengthOfLIS(int[] nums) {int n = nums.length;if (n == 0) return 0;int[] dp = new int[n];Arrays.fill(dp, 1); // 初始化每个元素自身构成长度为1的子序列for (int i = 1; i < n; i++) {for (int j = 0; j < i; j++) {if (nums[i] > nums[j]) {dp[i] = Math.max(dp[i], dp[j] + 1);}}}// 找到最大值int maxLength = 0;for (int length : dp) {maxLength = Math.max(maxLength, length);}return maxLength;}
}
二分查找优化(O(n log n))
public class LongestIncreasingSubsequenceOptimized {public int lengthOfLIS(int[] nums) {int n = nums.length;if (n == 0) return 0;// tails[i]表示长度为i+1的递增子序列的最小结尾元素int[] tails = new int[n];int len = 0;for (int num : nums) {// 二分查找num应该插入的位置int left = 0, right = len;while (left < right) {int mid = left + (right - left) / 2;if (tails[mid] < num) {left = mid + 1;} else {right = mid;}}// 更新tails数组tails[left] = num;if (left == len) len++;}return len;}
}
这个优化版本的时间复杂度是O(n log n),空间复杂度是O(n)。
4.5 编辑距离问题
编辑距离(Edit Distance)是衡量两个字符串相似度的一个指标,也是动态规划的经典应用。
4.5.1 问题描述
给定两个单词word1和word2,计算将word1转换成word2所使用的最少操作数。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
例如,将"horse"转换为"ros"的最少操作数是3:
- horse -> rorse(将’h’替换为’r’)
- rorse -> rose(删除’r’)
- rose -> ros(删除’e’)
4.5.2 问题分析
编辑距离问题可以用动态规划来解决。我们定义dp[i][j]为将word1的前i个字符转换为word2的前j个字符所需的最少操作数。
4.5.3 动态规划解法
-
明确状态定义:
- 状态dp[i][j]表示将word1的前i个字符转换为word2的前j个字符所需的最少操作数。
-
确定状态转移方程:
- 如果word1[i-1] == word2[j-1],则dp[i][j] = dp[i-1][j-1](不需要操作)
- 如果word1[i-1] != word2[j-1],则dp[i][j] = min(dp[i-1][j] + 1, dp[i][j-1] + 1, dp[i-1][j-1] + 1)
- dp[i-1][j] + 1表示删除word1的第i个字符
- dp[i][j-1] + 1表示在word1中插入word2的第j个字符
- dp[i-1][j-1] + 1表示将word1的第i个字符替换为word2的第j个字符
-
确定初始状态与边界条件:
- dp[i][0] = i,表示将word1的前i个字符转换为空字符串需要删除i个字符
- dp[0][j] = j,表示将空字符串转换为word2的前j个字符需要插入j个字符
-
计算并输出最终答案:
- 答案为dp[m][n],其中m和n分别是word1和word2的长度。
4.5.4 Java实现
public class EditDistance {public int minDistance(String word1, String word2) {int m = word1.length();int n = word2.length();// 创建DP表格int[][] dp = new int[m + 1][n + 1];// 初始化边界条件for (int i = 0; i <= m; i++) {dp[i][0] = i;}for (int j = 0; j <= n; j++) {dp[0][j] = j;}// 填充DP表格for (int i = 1; i <= m; i++) {for (int j = 1; j <= n; j++) {if (word1.charAt(i - 1) == word2.charAt(j - 1)) {dp[i][j] = dp[i - 1][j - 1];} else {dp[i][j] = Math.min(Math.min(dp[i - 1][j], dp[i][j - 1]), dp[i - 1][j - 1]) + 1;}}}return dp[m][n];}
}
这个实现的时间复杂度是O(mn),空间复杂度也是O(mn)。
4.5.5 空间优化
与最长公共子序列问题类似,我们也可以将编辑距离问题的空间复杂度优化到O(min(m,n))。
public class EditDistanceOptimized {public int minDistance(String word1, String word2) {// 确保word1是较短的字符串,优化空间复杂度if (word1.length() > word2.length()) {String temp = word1;word1 = word2;word2 = temp;}int m = word1.length();int n = word2.length();// 只使用一维数组int[] dp = new int[m + 1];// 初始化for (int i = 0; i <= m; i++) {dp[i] = i;}for (int j = 1; j <= n; j++) {int prev = dp[0]; // dp[i-1][j-1]dp[0] = j; // dp[0][j] = jfor (int i = 1; i <= m; i++) {int curr = dp[i]; // 保存dp[i][j-1]if (word1.charAt(i - 1) == word2.charAt(j - 1)) {dp[i] = prev;} else {dp[i] = Math.min(Math.min(dp[i - 1], dp[i]), prev) + 1;}prev = curr;}}return dp[m];}
}
这个优化版本的时间复杂度仍然是O(m*n),但空间复杂度降低到了O(min(m,n))。
通过这些经典问题的分析和实现,我们可以看到动态规划在解决各种复杂问题时的强大能力。这些问题涵盖了动态规划的不同应用场景和技巧,为我们在实际工作中应用动态规划提供了宝贵的参考。在下一节中,我们将探讨动态规划在实际项目中的应用,进一步拓展我们对动态规划的理解和应用能力。
5. 动态规划在实际项目中的应用
动态规划不仅仅是一种算法技术,更是解决实际问题的强大工具。在Java后端开发中,动态规划可以应用于各种场景,帮助我们优化系统性能、提升用户体验。本节将探讨动态规划在实际项目中的几个典型应用场景,并提供具体的实现示例。
5.1 资源调度优化
在分布式系统和云计算环境中,资源调度是一个核心问题。如何在有限的资源下,最大化系统吞吐量或最小化响应时间,是资源调度优化的主要目标。动态规划可以有效地解决这类问题。
5.1.1 任务调度问题
考虑一个常见的任务调度问题:有n个任务和m个处理器,每个任务在不同处理器上的执行时间不同,如何分配任务使得所有任务的完成时间最短?
这个问题可以用动态规划来解决:
public class TaskScheduler {public int minCompletionTime(int[][] executionTime, int n, int m) {// executionTime[i][j]表示任务i在处理器j上的执行时间// n是任务数量,m是处理器数量// dp[i][j]表示前i个任务分配给j个处理器的最短完成时间int[][] dp = new int[n + 1][m + 1];// 初始化:只有一个处理器时,任务必须顺序执行for (int i = 1; i <= n; i++) {dp[i][1] = dp[i - 1][1] + executionTime[i - 1][0];}// 填充DP表格for (int i = 1; i <= n; i++) {for (int j = 2; j <= m; j++) {dp[i][j] = Integer.MAX_VALUE;// 尝试不同的任务分配方案for (int k = 0; k < i; k++) {int maxTime = dp[k][j - 1];int currentProcessorTime = 0;for (int l = k; l < i; l++) {currentProcessorTime += executionTime[l][j - 1];}maxTime = Math.max(maxTime, currentProcessorTime);dp[i][j] = Math.min(dp[i][j], maxTime);}}}return dp[n][m];}
}
在实际应用中,任务调度问题可能更加复杂,涉及任务依赖、资源约束等因素。动态规划可以与其他技术(如贪心算法、启发式搜索)结合,构建更加高效的调度系统。
5.1.2 负载均衡
在微服务架构中,负载均衡是确保系统高可用性和性能的关键。动态规划可以帮助我们设计更智能的负载均衡策略。
例如,考虑一个带有权重的负载均衡问题:有n个服务实例,每个实例有不同的处理能力(权重),如何分配请求使得各实例的负载尽可能均衡?
public class WeightedLoadBalancer {private int[] weights; // 各服务实例的权重private int[] currentLoads; // 当前负载private int totalWeight; // 总权重public WeightedLoadBalancer(int[] weights) {this.weights = weights;this.currentLoads = new int[weights.length];for (int weight : weights) {totalWeight += weight;}}// 使用动态规划选择最佳实例public int selectInstance(int requestCost) {int n = weights.length;// dp[i][j]表示使用前i个实例处理负载j的最小不平衡度double[][] dp = new double[n + 1][totalWeight + 1];int[][] choice = new int[n + 1][totalWeight + 1];// 初始化for (int i = 0; i <= n; i++) {for (int j = 0; j <= totalWeight; j++) {dp[i][j] = Double.MAX_VALUE;}}dp[0][0] = 0;// 填充DP表格for (int i = 1; i <= n; i++) {for (int j = 0; j <= totalWeight; j++) {// 不分配给当前实例if (dp[i - 1][j] < dp[i][j]) {dp[i][j] = dp[i - 1][j];choice[i][j] = 0;}// 分配给当前实例for (int k = 1; k <= weights[i - 1] && j >= k; k++) {double newImbalance = calculateImbalance(i - 1, j - k, k);if (dp[i - 1][j - k] + newImbalance < dp[i][j]) {dp[i][j] = dp[i - 1][j - k] + newImbalance;choice[i][j] = k;}}}}// 回溯找出最佳分配方案int remainingLoad = totalWeight;int[] allocation = new int[n];for (int i = n; i >= 1; i--) {allocation[i - 1] = choice[i][remainingLoad];remainingLoad -= allocation[i - 1];}// 根据分配方案选择实例int selectedInstance = -1;double minRatio = Double.MAX_VALUE;for (int i = 0; i < n; i++) {if (allocation[i] > 0) {double ratio = (currentLoads[i] + requestCost) / (double) weights[i];if (ratio < minRatio) {minRatio = ratio;selectedInstance = i;}}}// 更新负载if (selectedInstance != -1) {currentLoads[selectedInstance] += requestCost;}return selectedInstance;}private double calculateImbalance(int instance, int previousLoad, int additionalLoad) {// 计算负载不平衡度的函数double targetRatio = (currentLoads[instance] + additionalLoad) / (double) weights[instance];double avgRatio = previousLoad / (double) (totalWeight - weights[instance]);return Math.abs(targetRatio - avgRatio);}
}
这个负载均衡器使用动态规划来最小化各实例之间的负载不平衡度,从而实现更加公平和高效的请求分配。
5.2 路径规划问题
路径规划是许多应用中的核心功能,如导航系统、网络路由、物流配送等。动态规划在解决各种路径规划问题中发挥着重要作用。
5.2.1 最短路径问题
最短路径问题是路径规划中的基础问题,动态规划(如Floyd-Warshall算法)可以有效地解决所有节点对之间的最短路径问题。
public class FloydWarshall {public int[][] shortestPaths(int[][] graph, int n) {// graph[i][j]表示从节点i到节点j的直接距离,无边则为Integer.MAX_VALUE// n是节点数量int[][] dist = new int[n][n];// 初始化距离矩阵for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {dist[i][j] = graph[i][j];}}// Floyd-Warshall算法核心for (int k = 0; k < n; k++) {for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (dist[i][k] != Integer.MAX_VALUE && dist[k][j] != Integer.MAX_VALUE&& dist[i][k] + dist[k][j] < dist[i][j]) {dist[i][j] = dist[i][k] + dist[k][j];}}}}return dist;}
}
在实际应用中,我们可能需要考虑更多因素,如交通状况、时间窗口约束等。动态规划可以灵活地适应这些复杂需求。
5.2.2 旅行商问题的近似解
旅行商问题(TSP)是一个著名的NP难问题,但对于规模不太大的问题,动态规划可以提供精确解。对于大规模问题,我们可以结合动态规划和其他技术来获得近似解。
public class TravelingSalesmanProblem {public int shortestRoute(int[][] distances, int n) {// distances[i][j]表示城市i到城市j的距离// n是城市数量// dp[mask][i]表示访问过的城市集合为mask且当前在城市i的最短路径长度int[][] dp = new int[1 << n][n];// 初始化for (int i = 0; i < (1 << n); i++) {Arrays.fill(dp[i], Integer.MAX_VALUE);}dp[1][0] = 0; // 从城市0开始// 填充DP表格for (int mask = 1; mask < (1 << n); mask++) {for (int i = 0; i < n; i++) {// 如果城市i不在当前集合中,跳过if ((mask & (1 << i)) == 0) continue;// 前一个集合(不包含城市i)int prevMask = mask ^ (1 << i);// 如果是起始城市且不是单独访问if (i == 0 && prevMask != 0) continue;// 如果是单独访问城市iif (prevMask == 0) {dp[mask][i] = 0;continue;}// 尝试从不同的城市j到达城市ifor (int j = 0; j < n; j++) {if ((prevMask & (1 << j)) != 0 && dp[prevMask][j] != Integer.MAX_VALUE) {dp[mask][i] = Math.min(dp[mask][i], dp[prevMask][j] + distances[j][i]);}}}}// 从最后一个城市返回起始城市int finalMask = (1 << n) - 1;int minDistance = Integer.MAX_VALUE;for (int i = 1; i < n; i++) {if (dp[finalMask][i] != Integer.MAX_VALUE && distances[i][0] != Integer.MAX_VALUE) {minDistance = Math.min(minDistance, dp[finalMask][i] + distances[i][0]);}}return minDistance;}
}
这个实现使用了状态压缩动态规划,通过位运算高效地表示城市访问状态。对于大规模问题,我们可以结合动态规划和启发式搜索、遗传算法等技术来获得近似解。
5.3 数据库查询优化
在数据库系统中,查询优化是提高性能的关键。动态规划可以用于优化复杂查询的执行计划,特别是涉及多表连接的查询。
5.3.1 连接顺序优化
在多表连接查询中,不同的连接顺序可能导致性能差异巨大。动态规划可以帮助我们找到最优的连接顺序。
public class JoinOrderOptimizer {public List<Integer> optimizeJoinOrder(int[][] costMatrix, int n) {// costMatrix[i][j]表示表i和表j连接的代价// n是表的数量// dp[mask][i]表示连接集合mask中的表且最后连接表i的最小代价int[][] dp = new int[1 << n][n];int[][] prev = new int[1 << n][n]; // 记录前一个表// 初始化for (int i = 0; i < (1 << n); i++) {Arrays.fill(dp[i], Integer.MAX_VALUE);}// 单表查询的代价为0for (int i = 0; i < n; i++) {dp[1 << i][i] = 0;}// 填充DP表格for (int mask = 1; mask < (1 << n); mask++) {for (int i = 0; i < n; i++) {// 如果表i不在当前集合中,跳过if ((mask & (1 << i)) == 0) continue;// 前一个集合(不包含表i)int prevMask = mask ^ (1 << i);// 如果是单表查询,已经初始化为0if (prevMask == 0) continue;// 尝试不同的连接顺序for (int j = 0; j < n; j++) {if ((prevMask & (1 << j)) != 0 && dp[prevMask][j] != Integer.MAX_VALUE) {int cost = dp[prevMask][j] + costMatrix[j][i];if (cost < dp[mask][i]) {dp[mask][i] = cost;prev[mask][i] = j;}}}}}// 找到最优的最后一个表int finalMask = (1 << n) - 1;int lastTable = 0;int minCost = Integer.MAX_VALUE;for (int i = 0; i < n; i++) {if (dp[finalMask][i] < minCost) {minCost = dp[finalMask][i];lastTable = i;}}// 重建连接顺序List<Integer> joinOrder = new ArrayList<>();int currentMask = finalMask;int currentTable = lastTable;while (currentMask > 0) {joinOrder.add(currentTable);int nextTable = prev[currentMask][currentTable];currentMask ^= (1 << currentTable);currentTable = nextTable;}Collections.reverse(joinOrder);return joinOrder;}
}
这个优化器使用动态规划来找到最优的表连接顺序,从而减少中间结果的大小,提高查询执行效率。
5.3.2 查询结果缓存策略
在数据库系统中,缓存查询结果可以显著提高性能。但由于缓存空间有限,我们需要决定哪些查询结果应该被缓存,哪些应该被淘汰。动态规划可以帮助我们设计最优的缓存策略。
public class QueryResultCacheStrategy {public List<Integer> optimizeCacheStrategy(int[] querySizes, int[] queryFrequencies, int cacheSize) {// querySizes[i]表示查询i的结果大小// queryFrequencies[i]表示查询i的访问频率// cacheSize是缓存的总大小int n = querySizes.length;// dp[i][j]表示考虑前i个查询,缓存大小为j时的最大收益(频率)int[][] dp = new int[n + 1][cacheSize + 1];boolean[][] choice = new boolean[n + 1][cacheSize + 1];// 填充DP表格for (int i = 1; i <= n; i++) {for (int j = 0; j <= cacheSize; j++) {// 不缓存查询idp[i][j] = dp[i - 1][j];// 缓存查询iif (j >= querySizes[i - 1]) {int newBenefit = dp[i - 1][j - querySizes[i - 1]] + queryFrequencies[i - 1];if (newBenefit > dp[i][j]) {dp[i][j] = newBenefit;choice[i][j] = true;}}}}// 重建缓存策略List<Integer> cachedQueries = new ArrayList<>();int remainingSize = cacheSize;for (int i = n; i >= 1; i--) {if (choice[i][remainingSize]) {cachedQueries.add(i - 1);remainingSize -= querySizes[i - 1];}}return cachedQueries;}
}
这个缓存策略优化器使用动态规划来最大化缓存的收益,即缓存那些访问频率高且大小适中的查询结果。
5.4 缓存策略设计
除了数据库查询结果缓存,动态规划在各种缓存策略设计中也有广泛应用。
5.4.1 LFU缓存实现
LFU(Least Frequently Used)是一种常用的缓存淘汰策略,它会淘汰访问频率最低的缓存项。我们可以使用动态规划思想来优化LFU缓存的实现。
public class LFUCache<K, V> {private final int capacity;private int minFrequency;private final Map<K, V> cache;private final Map<K, Integer> keyFrequency;private final Map<Integer, LinkedHashSet<K>> frequencyKeys;public LFUCache(int capacity) {this.capacity = capacity;this.minFrequency = 0;this.cache = new HashMap<>();this.keyFrequency = new HashMap<>();this.frequencyKeys = new HashMap<>();}public V get(K key) {if (!cache.containsKey(key)) {return null;}// 增加访问频率int frequency = keyFrequency.get(key);keyFrequency.put(key, frequency + 1);// 更新频率集合frequencyKeys.get(frequency).remove(key);frequencyKeys.computeIfAbsent(frequency + 1, k -> new LinkedHashSet<>()).add(key);// 如果当前最小频率的集合为空,增加最小频率if (frequencyKeys.get(minFrequency).isEmpty()) {minFrequency++;}return cache.get(key);}public void put(K key, V value) {if (capacity <= 0) return;// 如果键已存在,更新值和频率if (cache.containsKey(key)) {cache.put(key, value);get(key); // 增加访问频率return;}// 如果缓存已满,淘汰访问频率最低的项if (cache.size() >= capacity) {K evictKey = frequencyKeys.get(minFrequency).iterator().next();frequencyKeys.get(minFrequency).remove(evictKey);cache.remove(evictKey);keyFrequency.remove(evictKey);}// 添加新项cache.put(key, value);keyFrequency.put(key, 1);frequencyKeys.computeIfAbsent(1, k -> new LinkedHashSet<>()).add(key);minFrequency = 1;}
}
这个LFU缓存实现使用了动态规划的思想,通过维护频率信息来优化缓存淘汰策略。
5.4.2 预取缓存策略
在某些场景中,我们可以预测用户的访问模式,提前加载可能需要的数据到缓存中。动态规划可以帮助我们设计最优的预取策略。
public class PrefetchCacheStrategy {public List<Integer> optimizePrefetchStrategy(int[] itemSizes, double[] accessProbabilities, int cacheSize) {// itemSizes[i]表示项i的大小// accessProbabilities[i]表示项i被访问的概率// cacheSize是缓存的总大小int n = itemSizes.length;// dp[i][j]表示考虑前i个项,缓存大小为j时的最大期望收益double[][] dp = new double[n + 1][cacheSize + 1];boolean[][] choice = new boolean[n + 1][cacheSize + 1];// 填充DP表格for (int i = 1; i <= n; i++) {for (int j = 0; j <= cacheSize; j++) {// 不预取项idp[i][j] = dp[i - 1][j];// 预取项iif (j >= itemSizes[i - 1]) {double newBenefit = dp[i - 1][j - itemSizes[i - 1]] + accessProbabilities[i - 1];if (newBenefit > dp[i][j]) {dp[i][j] = newBenefit;choice[i][j] = true;}}}}// 重建预取策略List<Integer> prefetchItems = new ArrayList<>();int remainingSize = cacheSize;for (int i = n; i >= 1; i--) {if (choice[i][remainingSize]) {prefetchItems.add(i - 1);remainingSize -= itemSizes[i - 1];}}return prefetchItems;}
}
这个预取策略优化器使用动态规划来最大化预取的期望收益,即预取那些访问概率高且大小适中的项。
通过这些实际应用示例,我们可以看到动态规划在Java后端开发中的广泛应用。掌握动态规划不仅能帮助我们解决算法问题,还能在系统设计和优化中发挥重要作用,提升系统性能和用户体验。
6. 动态规划的优化技巧
随着问题规模和复杂度的增加,基本的动态规划实现可能面临时间和空间效率的挑战。在本节中,我们将介绍一些高级的动态规划优化技巧,帮助读者在处理大规模或复杂问题时提高算法效率。
6.1 状态压缩
状态压缩是一种使用位运算来表示和操作状态的技术,特别适用于状态数量有限且可以用二进制位表示的情况。状态压缩可以显著减少空间复杂度,并简化状态转移的实现。
6.1.1 位运算基础
在使用状态压缩之前,我们需要了解一些基本的位运算操作:
- 检查第i位是否为1:
(mask & (1 << i)) != 0 - 设置第i位为1:
mask | (1 << i) - 设置第i位为0:
mask & ~(1 << i) - 切换第i位的值:
mask ^ (1 << i) - 获取最低位的1:
mask & -mask - 计算二进制中1的个数:
Integer.bitCount(mask)
6.1.2 状态压缩应用示例
以旅行商问题为例,我们可以使用一个整数的二进制表示来记录已访问的城市集合,大大减少空间复杂度:
public class TSPWithBitMask {public int shortestRoute(int[][] distances, int n) {// distances[i][j]表示城市i到城市j的距离// n是城市数量// dp[mask][i]表示访问过的城市集合为mask且当前在城市i的最短路径长度int[][] dp = new int[1 << n][n];// 初始化for (int i = 0; i < (1 << n); i++) {Arrays.fill(dp[i], Integer.MAX_VALUE);}dp[1][0] = 0; // 从城市0开始// 填充DP表格for (int mask = 1; mask < (1 << n); mask++) {for (int i = 0; i < n; i++) {// 如果城市i不在当前集合中,跳过if ((mask & (1 << i)) == 0) continue;// 前一个集合(不包含城市i)int prevMask = mask ^ (1 << i);// 如果是起始城市且不是单独访问if (i == 0 && prevMask != 0) continue;// 如果是单独访问城市iif (prevMask == 0) {dp[mask][i] = 0;continue;}// 尝试从不同的城市j到达城市ifor (int j = 0; j < n; j++) {if ((prevMask & (1 << j)) != 0 && dp[prevMask][j] != Integer.MAX_VALUE) {dp[mask][i] = Math.min(dp[mask][i], dp[prevMask][j] + distances[j][i]);}}}}// 从最后一个城市返回起始城市int finalMask = (1 << n) - 1;int minDistance = Integer.MAX_VALUE;for (int i = 1; i < n; i++) {if (dp[finalMask][i] != Integer.MAX_VALUE && distances[i][0] != Integer.MAX_VALUE) {minDistance = Math.min(minDistance, dp[finalMask][i] + distances[i][0]);}}return minDistance;}
}
在这个例子中,我们使用一个整数的二进制表示来记录已访问的城市集合,例如,二进制101表示已访问城市0和城市2。这种表示方法不仅节省了空间,还简化了状态转移的实现。
6.1.3 状态压缩的适用场景
状态压缩特别适用于以下场景:
- 状态可以用有限的二进制位表示(通常不超过32位)
- 需要频繁检查、添加或删除状态中的元素
- 状态转移涉及状态的组合或分解
常见的应用包括集合覆盖问题、图的最短路径问题、动态规划中的状态表示等。
6.2 记忆化搜索
记忆化搜索是动态规划的一种实现方式,它结合了递归的自然表达和动态规划的效率。记忆化搜索特别适用于状态转移复杂或状态空间稀疏的问题。
6.2.1 记忆化搜索的基本思想
记忆化搜索的核心思想是:
- 使用递归函数自然地表达问题的解决方案
- 使用缓存(通常是数组或哈希表)存储已计算的子问题的解
- 在递归调用前检查缓存,避免重复计算
6.2.2 记忆化搜索示例
以计算组合数为例,我们可以使用记忆化搜索高效地计算大规模的组合数:
public class CombinationCalculator {private long[][] memo;public long combination(int n, int k) {if (k < 0 || k > n) return 0;if (k == 0 || k == n) return 1;memo = new long[n + 1][k + 1];return combinationMemo(n, k);}private long combinationMemo(int n, int k) {if (k < 0 || k > n) return 0;if (k == 0 || k == n) return 1;if (memo[n][k] != 0) return memo[n][k];memo[n][k] = combinationMemo(n - 1, k - 1) + combinationMemo(n - 1, k);return memo[n][k];}
}
这个实现使用记忆化搜索来避免重复计算组合数,大大提高了计算效率。
6.2.3 记忆化搜索与自底向上动态规划的比较
记忆化搜索(自顶向下)和自底向上动态规划各有优缺点:
| 特性 | 记忆化搜索 | 自底向上动态规划 |
|---|---|---|
| 实现难度 | 通常更简单,接近问题的递归定义 | 可能需要更多的思考来确定填表顺序 |
| 空间效率 | 只计算需要的状态,适合稀疏状态空间 | 计算所有可能的状态,可能包含不必要的计算 |
| 时间效率 | 有函数调用开销,可能导致栈溢出 | 没有函数调用开销,通常更快 |
| 适用场景 | 状态转移复杂或状态空间稀疏的问题 | 状态转移简单且状态空间密集的问题 |
在实际应用中,可以根据问题的特性选择合适的实现方式,或者结合两种方式的优点。
6.3 滚动数组
滚动数组是一种空间优化技术,适用于当前状态只依赖于前几个状态的情况。通过重用数组空间,滚动数组可以将空间复杂度从O(n)降低到O(1)或O(k)(k是依赖的前状态数量)。
6.3.1 一维滚动数组
当状态只依赖于前一个状态时,我们可以使用两个变量代替整个数组:
public class FibonacciRollingArray {public long fibonacci(int n) {if (n <= 1) return n;long prev = 0;long curr = 1;for (int i = 2; i <= n; i++) {long next = prev + curr;prev = curr;curr = next;}return curr;}
}
这个实现将空间复杂度从O(n)降低到O(1)。
6.3.2 二维滚动数组
对于二维动态规划问题,如果当前行只依赖于前几行,我们可以使用滚动数组将空间复杂度从O(mn)降低到O(kn),其中k是依赖的行数:
public class LCSRollingArray {public int longestCommonSubsequence(String text1, String text2) {int m = text1.length();int n = text2.length();// 只使用两行int[][] dp = new int[2][n + 1];for (int i = 1; i <= m; i++) {// 当前行的索引int curr = i % 2;// 前一行的索引int prev = 1 - curr;for (int j = 1; j <= n; j++) {if (text1.charAt(i - 1) == text2.charAt(j - 1)) {dp[curr][j] = dp[prev][j - 1] + 1;} else {dp[curr][j] = Math.max(dp[prev][j], dp[curr][j - 1]);}}}return dp[m % 2][n];}
}
这个实现将空间复杂度从O(m*n)降低到O(n)。
6.3.3 滚动数组的适用场景
滚动数组特别适用于以下场景:
- 当前状态只依赖于有限的前几个状态
- 状态转移是单向的(例如,从左到右,从上到下)
- 不需要回溯重构解的路径
需要注意的是,如果需要回溯重构解的路径,可能需要保留完整的状态数组。
6.4 二进制优化
二进制优化是一种利用二进制特性来加速动态规划的技术,特别适用于需要枚举子集或处理2的幂次的问题。
6.4.1 子集枚举
在某些动态规划问题中,我们需要枚举一个集合的所有子集。使用二进制表示可以高效地实现这一操作:
public class SubsetEnumeration {public void enumerateSubsets(int[] nums) {int n = nums.length;// 枚举所有子集for (int mask = 0; mask < (1 << n); mask++) {System.out.print("Subset: ");// 检查哪些元素在当前子集中for (int i = 0; i < n; i++) {if ((mask & (1 << i)) != 0) {System.out.print(nums[i] + " ");}}System.out.println();}}
}
6.4.2 SOS动态规划
SOS(Sum Over Subsets)动态规划是一种处理子集和问题的高效技术。它可以在O(n*2^n)的时间内计算所有子集的和:
public class SOSDynamicProgramming {public int[] sumOverSubsets(int[] values) {int n = values.length;int[] dp = new int[1 << n];// 初始化for (int mask = 0; mask < (1 << n); mask++) {dp[mask] = values[mask];}// SOS DPfor (int i = 0; i < n; i++) {for (int mask = 0; mask < (1 << n); mask++) {if ((mask & (1 << i)) != 0) {dp[mask] += dp[mask ^ (1 << i)];}}}return dp;}
}
这个实现计算了每个集合及其所有子集的值的和。
6.4.3 快速幂算法
在某些动态规划问题中,我们需要计算大数的幂,快速幂算法可以在O(log n)的时间内完成这一操作:
public class FastPower {public long power(long base, long exponent, long modulus) {if (exponent == 0) return 1;long result = 1;base %= modulus;while (exponent > 0) {if ((exponent & 1) == 1) {result = (result * base) % modulus;}base = (base * base) % modulus;exponent >>= 1;}return result;}
}
这个实现使用了二进制的特性,将幂运算的时间复杂度从O(n)降低到O(log n)。
6.5 区间动态规划优化
区间动态规划是处理区间问题的一种技术,如矩阵链乘法、最优三角剖分等。在某些情况下,我们可以使用特殊的优化技巧来提高区间动态规划的效率。
6.5.1 四边形不等式优化
四边形不等式优化适用于满足特定条件的区间动态规划问题,可以将时间复杂度从O(n³)降低到O(n²):
public class QuadrangleInequalityOptimization {public int optimalMatrixChainMultiplication(int[] dimensions) {int n = dimensions.length - 1; // 矩阵数量int[][] dp = new int[n][n]; // dp[i][j]表示从第i个矩阵到第j个矩阵的最小乘法次数int[][] split = new int[n][n]; // split[i][j]表示最优分割点// 初始化对角线for (int i = 0; i < n; i++) {dp[i][i] = 0;split[i][i] = i;}// 填充DP表格for (int len = 2; len <= n; len++) {for (int i = 0; i <= n - len; i++) {int j = i + len - 1;dp[i][j] = Integer.MAX_VALUE;// 使用四边形不等式优化的搜索范围int optimalK = split[i][j - 1];int end = (j < n - 1) ? split[i + 1][j] : j - 1;for (int k = optimalK; k <= end; k++) {int cost = dp[i][k] + dp[k + 1][j] + dimensions[i] * dimensions[k + 1] * dimensions[j + 1];if (cost < dp[i][j]) {dp[i][j] = cost;split[i][j] = k;}}}}return dp[0][n - 1];}
}
这个实现使用了四边形不等式优化,减少了搜索最优分割点的范围,从而提高了效率。
6.5.2 Knuth优化
Knuth优化是四边形不等式优化的一个特例,适用于某些特定的区间动态规划问题:
public class KnuthOptimization {public int optimalBinarySearchTree(int[] keys, int[] frequencies) {int n = keys.length;int[][] dp = new int[n + 1][n + 1]; // dp[i][j]表示从第i个键到第j个键的最优二叉搜索树的代价int[][] root = new int[n + 1][n + 1]; // root[i][j]表示最优根节点// 初始化for (int i = 0; i < n; i++) {dp[i][i] = frequencies[i];root[i][i] = i;}// 计算前缀和int[] prefixSum = new int[n + 1];for (int i = 0; i < n; i++) {prefixSum[i + 1] = prefixSum[i] + frequencies[i];}// 填充DP表格for (int len = 2; len <= n; len++) {for (int i = 0; i <= n - len; i++) {int j = i + len - 1;dp[i][j] = Integer.MAX_VALUE;// 使用Knuth优化的搜索范围int optimalR = root[i][j - 1];int end = root[i + 1][j];for (int r = optimalR; r <= end; r++) {int cost = (r > i ? dp[i][r - 1] : 0) + (r < j ? dp[r + 1][j] : 0) + prefixSum[j + 1] - prefixSum[i];if (cost < dp[i][j]) {dp[i][j] = cost;root[i][j] = r;}}}}return dp[0][n - 1];}
}
这个实现使用了Knuth优化,减少了搜索最优根节点的范围,从而提高了效率。
通过这些高级优化技巧,我们可以显著提高动态规划算法的效率,解决更大规模和更复杂的问题。在实际应用中,根据问题的特性选择合适的优化技巧,可以达到最佳的性能效果。
7. 总结与进阶
在本文中,我们系统地介绍了动态规划算法的理论基础、设计步骤、经典问题、实际应用和优化技巧。通过这些内容,我们希望读者能够全面理解动态规划的核心思想,并能在实际工作中灵活应用这一强大的算法技术。在本节中,我们将总结动态规划的学习方法和思维训练,分析常见的面试题,并推荐一些进阶学习资源。
7.1 动态规划的学习方法和思维训练
学习动态规划不仅是掌握一种算法技术,更是培养一种解决问题的思维方式。以下是一些有效的学习方法和思维训练:
7.1.1 从基础到进阶的学习路径
- 掌握基础概念:理解最优子结构、重叠子问题等核心概念。
- 学习经典问题:从斐波那契数列、最长公共子序列等简单问题开始,逐步过渡到更复杂的问题。
- 分析状态定义和转移:重点关注如何定义状态和推导状态转移方程,这是动态规划的核心。
- 实践和总结:通过大量练习,总结不同类型问题的解决模式。
- 学习优化技巧:掌握空间优化、状态压缩等高级技巧,提高算法效率。
7.1.2 动态规划的思维训练
- 分解问题:学会将复杂问题分解为子问题,识别子问题之间的关系。
- 寻找最优子结构:分析问题是否具有最优子结构,即原问题的最优解是否包含子问题的最优解。
- 识别重叠子问题:判断在求解过程中是否会重复计算某些子问题,这是使用动态规划的关键条件。
- 自底向上思考:尝试从最小的子问题开始,逐步构建更大问题的解。
- 状态转移可视化:通过图表或表格可视化状态转移过程,帮助理解算法的执行流程。
7.1.3 常见误区和解决方法
- 过度依赖模板:不要只是记忆模板,而是理解每个问题的特点和解决思路。
- 状态定义不清晰:确保状态定义能完整描述问题,避免遗漏关键信息。
- 忽略边界条件:仔细处理边界条件,这往往是动态规划实现中的错误来源。
- 未考虑优化空间:在解决大规模问题时,考虑使用空间优化技巧,避免内存溢出。
- 缺乏系统练习:动态规划需要大量练习才能掌握,系统地练习不同类型的问题。
7.2 常见面试题解析
动态规划是技术面试中的常见题型,特别是在大型科技公司的面试中。以下是一些常见的面试题及其解析:
7.2.1 股票买卖问题
股票买卖问题是一类经典的动态规划问题,有多种变体,如限制交易次数、有冷冻期等。以下是最基本的版本:
问题:给定一个数组prices,其中prices[i]表示股票在第i天的价格,设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
解析:
public int maxProfit(int[] prices) {int maxProfit = 0;for (int i = 1; i < prices.length; i++) {if (prices[i] > prices[i - 1]) {maxProfit += prices[i] - prices[i - 1];}}return maxProfit;
}
这个问题可以用贪心算法解决,但更复杂的变体通常需要动态规划。例如,如果限制最多进行k次交易,我们可以定义状态dp[i][k][0/1]表示第i天,最多进行k次交易,手上没有/有股票的最大利润。
7.2.2 打家劫舍问题
问题:你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。
解析:
public int rob(int[] nums) {int n = nums.length;if (n == 0) return 0;if (n == 1) return nums[0];int[] dp = new int[n];dp[0] = nums[0];dp[1] = Math.max(nums[0], nums[1]);for (int i = 2; i < n; i++) {dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);}return dp[n - 1];
}
这个问题的关键是理解状态转移方程:对于每个房屋,我们有两种选择,偷或不偷。如果偷当前房屋,就不能偷前一个房屋;如果不偷当前房屋,最大金额就是前一个房屋的最大金额。
7.2.3 最大子数组和
问题:给定一个整数数组nums,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
解析:
public int maxSubArray(int[] nums) {int n = nums.length;int[] dp = new int[n];dp[0] = nums[0];int maxSum = dp[0];for (int i = 1; i < n; i++) {dp[i] = Math.max(nums[i], dp[i - 1] + nums[i]);maxSum = Math.max(maxSum, dp[i]);}return maxSum;
}
这个问题的状态定义是dp[i]表示以第i个元素结尾的最大子数组和。状态转移方程考虑两种情况:要么是当前元素自己构成子数组,要么是将当前元素加入前面的最大子数组。
7.2.4 面试技巧
在面试中解决动态规划问题时,可以遵循以下步骤:
- 理解问题:确保完全理解问题的要求和约束。
- 分析问题特性:判断问题是否具有最优子结构和重叠子问题的特性。
- 定义状态:明确定义状态及其含义。
- 推导状态转移方程:分析状态之间的关系,推导出状态转移方程。
- 确定初始状态和边界条件:设置初始值和处理边界情况。
- 实现算法:根据以上分析实现算法,注意代码的简洁性和正确性。
- 优化算法:考虑是否可以优化空间复杂度或时间复杂度。
- 测试算法:使用一些简单的例子测试算法的正确性。
在面试过程中,清晰地表达你的思考过程比直接给出答案更重要。即使一时想不出最优解,也要展示你分析问题的能力和解决问题的思路。
7.3 结语
动态规划是一种强大而优雅的算法设计技术,它通过将复杂问题分解为子问题,并存储子问题的解来避免重复计算,从而大幅提高算法效率。在本文中,我们系统地介绍了动态规划的理论基础、设计步骤、经典问题、实际应用和优化技巧,希望能帮助Java后端开发者全面掌握这一重要的算法技术。
动态规划的学习是一个循序渐进的过程,需要理论学习和实践相结合。通过解决不同类型的问题,总结解决模式,逐步建立对动态规划的直觉和理解。随着经验的积累,你将能够更加自然地应用动态规划解决各种复杂问题,提升代码质量和系统性能。
最后,我们鼓励读者将动态规划的思想应用到实际工作中,不仅限于算法题,还包括系统设计、性能优化等方面。动态规划的核心思想——分解问题、避免重复计算、自底向上构建解——在软件开发的各个领域都有广泛的应用价值。