企业知识库:RAG技术实现流程总览(一)
文章目录
- 0.引言
- 1. 技术实现路径
- 1.1嵌入模型(向量模型)
- 1.2 文本切分
- 1.3 向量数据库
- 1.4 重排序模型
- 1.5 总结模型
- 2.总结
0.引言
随着大模型技术普及,越来越多企业开始注重模型应用于业务服务。更多的企业开始进入到垂直模型的赛道,但模型训练成本巨大,同时垂直领域知识命中精准度有限,于是“企业知识库”和检索增强生成 RAG技术应运而生。
检索增强生成模型结合了语言模型和信息检索技术。简单来讲,就是在向模型检索信息之前,会先想一个知识库数据集中搜索出相关的信息,然后结合这些信息再向模型进行询问,以此提高模型回答的质量和准确性。
1. 技术实现路径
RAG技术,主要包含3个核心技术:检索、增强和生成,其中官方定义如下:
- 检索:根据用户的查询内容,从外部知识库获取相关信息。具体而言,将用户的查询通过嵌入模型转换为向量,以便与向量数据库中存储的相关知识进行比对。通过相似性搜索,找出与查询最匹配的前 K 个数据。
- 增强:将用户的查询内容和检索到的相关知识一起嵌入到一个预设的提示词模板中
- 生成:将经过检索增强的提示词内容输入到大型语言模型中,以生成所需的输出
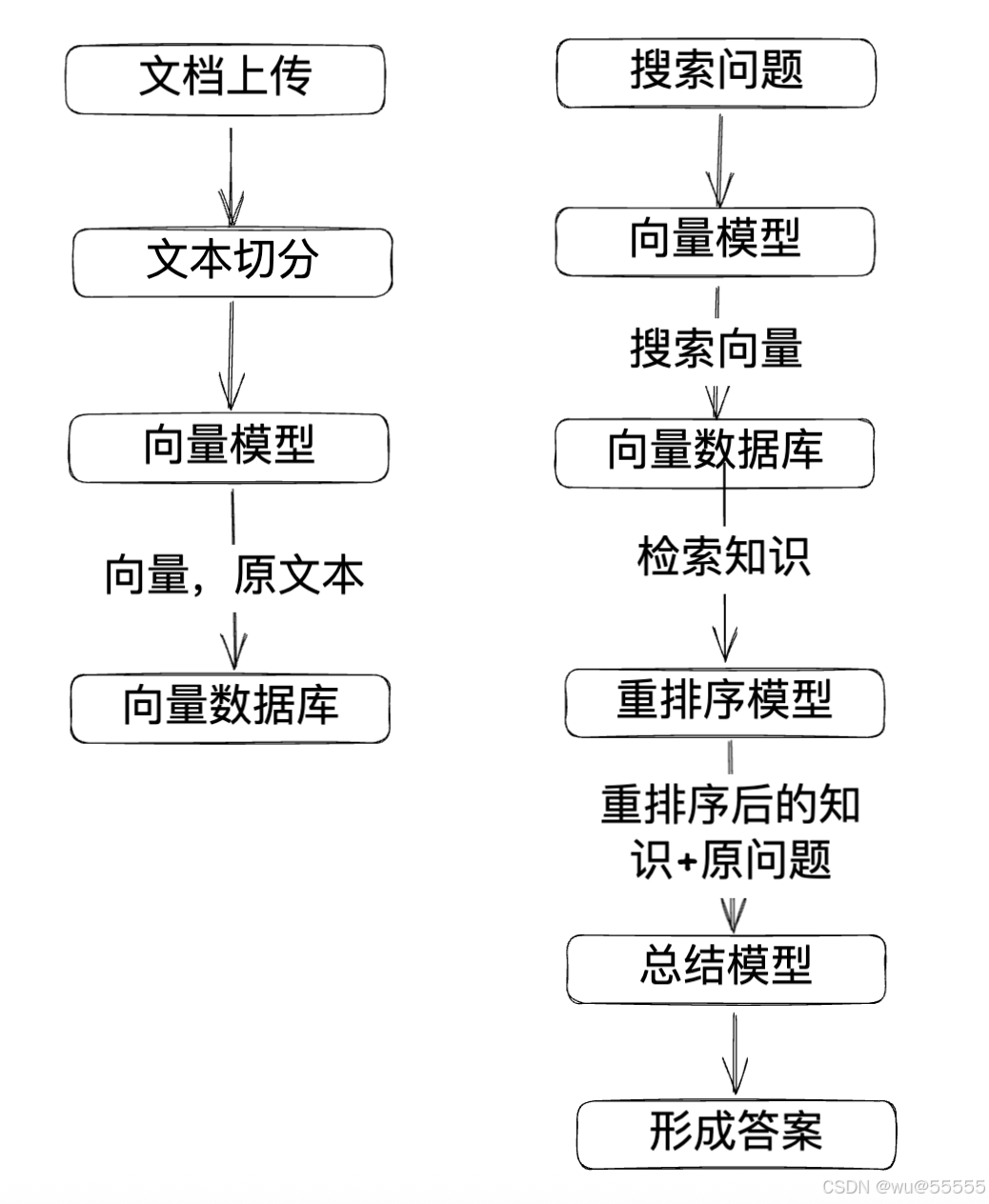
结合上述官方定义,整体实现分为两个主要流程:
一是将相关知识文档通过嵌入模型(向量模型)转换为向量数据和原文本数据,一一对应存储到特殊数据库中,后续搜索时会根据向量值进行搜索
二是将搜索时同样将问题转换为向量,先去数据库中根据向量搜索相关知识,然后结合重排序模型将搜索出的知识重新归纳排序,将最相关、最有用的内容排在最前,以给后续总结模型参考时提供更加精准的知识内容。
这其中比较关键的几个概念,我们一一讲解:
1.1嵌入模型(向量模型)
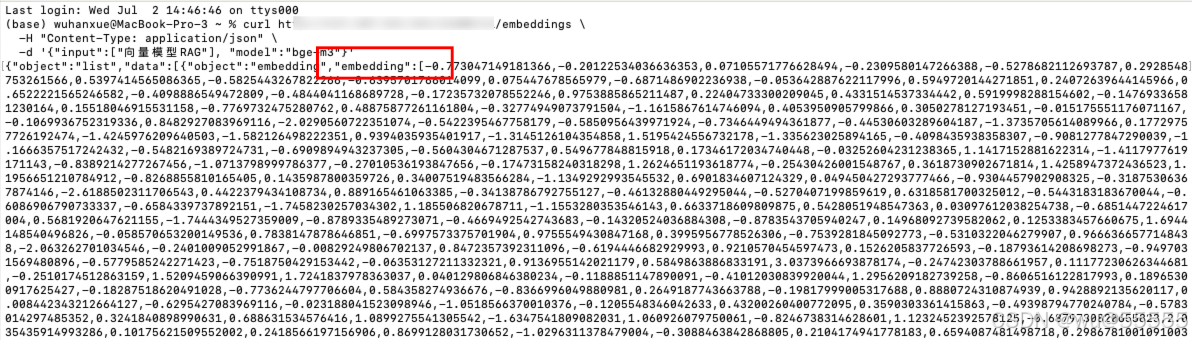
是将高维数据(如文本、图像、音频等)映射为低维稠密向量(嵌入向量)的算法,用于捕捉数据的语义或特征关联。而这个低维稠密向量就是我们说的向量值,实际上就是一个数值数组,如下我调用自部署的嵌入模型生成的“向量模型RAG”文本的向量值
在ollama官网可以看到当前热度较高的嵌入模型包含
nomic-embed-text,mxbai-embed-large,bge-m3,其中专门针对中文的嵌入模型主要以bg3-m3为主
1.2 文本切分
一般我们生产企业知识库时,会将企业内的各种文档上传用于形成知识库,而各种文档中的内容不可能原原本本的存储,就需要根据一定的规则进行切分,切分形成的每个段落再去通过向量模型转换为向量值存到向量数据库中,这里的难点就是通过一定的规则进行切分,比较简单的规则就是按照段落进行切分,但是某些情况下前后几段之间又是有上下文联系的,这时就需要根据语义切分;
同时文档可能也存在各种格式的,比如txt,xlsx,doc,pdf,png等,其中最难处理的就是pdf类型的,因为pdf中可能包含文字和图片,高精度识别pdf内容本身也是目前的技术瓶颈之一,同时图片中的文字就要结合OCR技术来实现,所以我们说文本切分是RAG技术的一个难点,文本切分得当,将大大提高搜索的准确性。
1.3 向量数据库
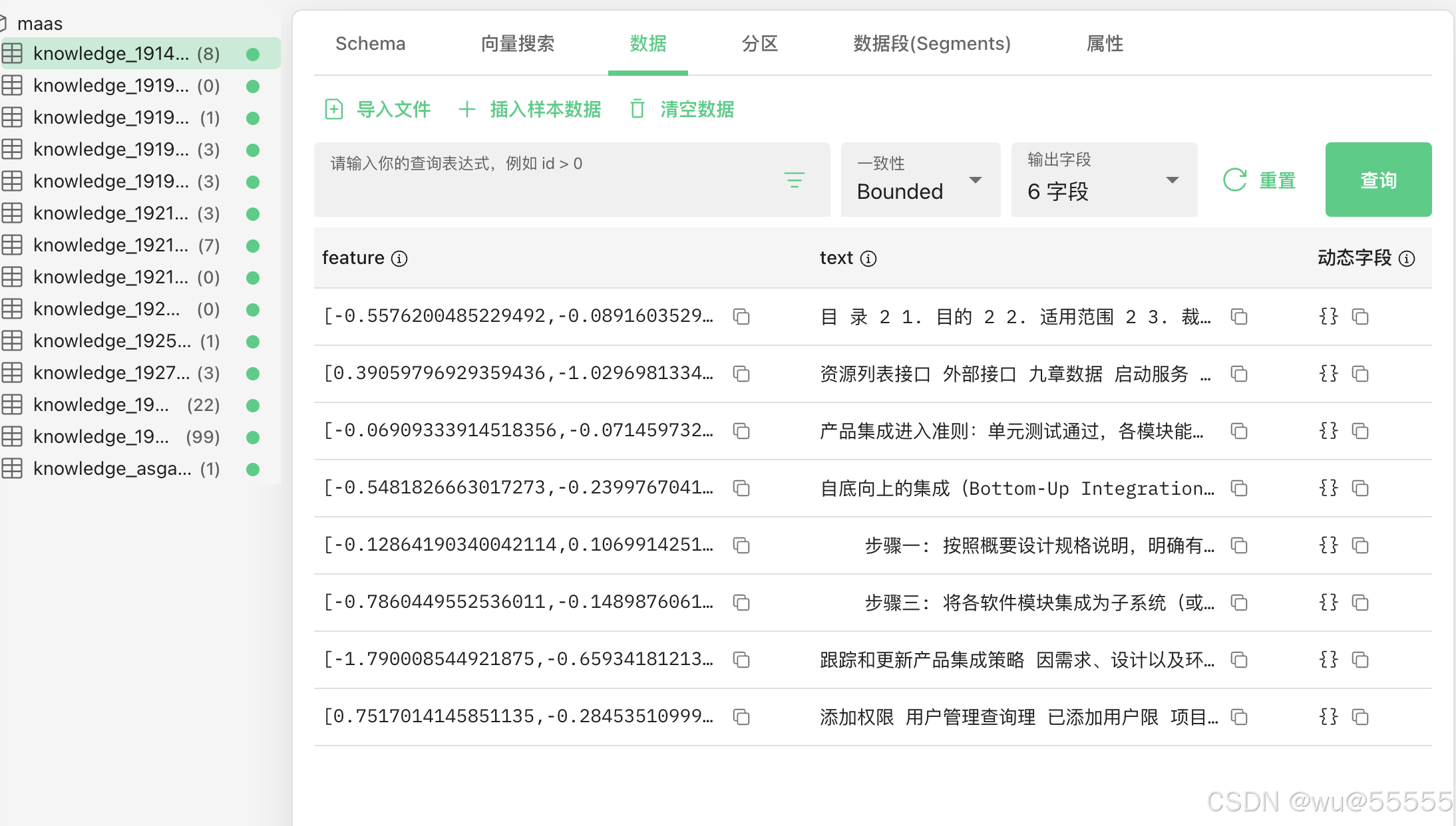
向量数据库专为高维向量设计,支持相似性搜索,擅长处理非结构化数据,基于欧氏距离、余弦相似度等算法执行相似性搜索,支持返回TOP K近似结果;传统数据库基于关系模型,面向结构化数据,依赖精确查询。向量数据库的本质就是将文本原文和其向量值都存储到数据库表中,搜索时通过向量值来计算相似度,然后将相似度高的原本和其他自定义字段返回。
常用的向量数据库包括Milvus, Elasticsearch, Redis, Chroma, Qdrant等,后文我们将重点以Milvus为例进行演示讲解,其他数据库大家可自己拓展学习,下图为milvus数据库的示例
1.4 重排序模型
初步的检索虽然能够返回大量潜在相关文档,但真正符合用户需求的高质量结果往往被淹没在海量数据中,可能分布在返回结果的任意位置,为了解决这个问题,就需要通过重排序模型对初步检索结果进行精确的相关性重新评估和排序。
我们在使用向量数据库时也可以通过向量数据库待的相似度进行排序返回结果。当向量数据库的排序不理想或者获取的文档本身没有基于相似度排序时,就可以考虑引入重排序模型。
1.5 总结模型
总结模型包括千问、deepseek,chatgpt这之类的,算是我们平时用的最多的模型,这类模型具备总结推理能力。当我们通过向量数据库搜索到相似度高的知识库内容后,就可以通过结合提示词来让模型总结内容。比如:根据以下知识库内容回答问题,如果知识库不包含问题相关内容正常回答即可: [知识库内容],问题:[问题内容]
2.总结
如上,我们针对RAG技术的各个具体技术点进行了讲解,下文我们将具体带大家来实现一个基础版的企业知识库