vllm0.8.5:思维链(Chain-of-Thought, CoT)微调模型的输出结果包括</think>,提供一种关闭思考过程的方法
摘要:本文介绍了如何优化DeepSeek-R1-Distill-Qwen-1.5B大语言模型的输出处理方案。该模型经过思维链微调后,会强制输出完整的思考流程(包含<think>标签),给业务系统带来额外处理负担。本文通过在vLLM中配置自定义聊天模板的方法,从根本上避免模型输出<think>标签。
一、环境
vllm:0.8.5
大语言模型:DeepSeek-R1-Distill-Qwen-1.5B
内存:128G
GPU:无
二、说明
DeepSeek-R1-Distill-Qwen-1.5B 是一个经过思维链(Chain-of-Thought, CoT)微调的模型,它在训练时看到的大量样本格式是:
<|Assistant|><think>
我来一步步计算...
</think>最终答案是...
这就导致一个问题,不管你有没有在 prompt 中插入 <think>,模型仍然倾向于“自己生成”完整的思考流程,包括 </think>。
基于大模型的业务系统就需要在拿到 response 后,用代码处理:
import re
def remove_thinking(content):
# 如果包含 </think>,返回其后的内容
if '</think>' in content:
parts = content.split('</think>', 1)
return parts[1].strip()
return content.strip()# 使用
clean_content = remove_thinking(response["choices"][0]["message"]["content"])
如果是流式输出,则处理起来就特别麻烦。有没有一种不需要业务系统调整就能满足要求的办法,答案是有。
三、操作过程
1.拉取vllm代码
get clone https://github.com/vllm-project/vllm.git
2.打成docker
docker buildx build --build-arg VLLM_CPU_DISABLE_AVX512=true -f docker/Dockerfile.cpu -t vllm-cpu:0.10 .
3.启动容器
docker run -dit --name vllm-cpu1 \
--privileged --security-opt seccomp=unconfined \
--ulimit memlock=-1:-1 --cap-add=SYS_PTRACE \
-v /home/tools/llm/2.Embedding:/opt/models \
-p 9400:8000 \
vllm-cpu:0.10 \
--model /opt/models/DeepSeek-R1-Distill-Qwen-1.5B \
--dtype auto \
--enable-chunked-prefill \
--tensor-parallel-size 1 \
--max-num-seqs 16 \
--max-model-len 2048 \
--enable-auto-tool-choice \
--tool-call-parser "hermes" \
--chat-template "/opt/models/qwen_nonthinking.jinja" \
--chat-template-content-format "auto"
注:
qwen_nonthinking.jinja的内容,下一章节详细介绍。
-dit:
d 表示以分离模式(后台)运行容器。
i 保持 STDIN 打开,即使没有附加也保持打开状态。
t 分配一个伪TTY(终端)。
--name vllm-cpu1: 给容器命名为 vllm-cpu1。
--privileged --security-opt seccomp=unconfined: 赋予容器扩展权限,解除安全限制。--privileged 提供了几乎所有的能力,并且去除了容器内的大部分限制。seccomp=unconfined 关闭了默认的安全计算模式过滤。
--ulimit memlock=-1:-1: 设置最大锁定内存地址空间为无限制,允许进程锁定更多的内存到RAM中,这在处理大型模型时可能非常有用。
--cap-add=SYS_PTRACE: 添加了 SYS_PTRACE 能力,允许容器内的进程追踪或调试其他进程。
-v /home/tools/llm/2.Embedding:/opt/models: 将主机上的 /home/tools/llm/2.Embedding 目录挂载到容器内部的 /opt/models 目录下,使得容器可以访问或存储模型文件于指定位置。
-p 9400:8000: 将主机的 9400 端口映射到容器的 8000 端口,使得外部可以通过主机的 9400 端口访问容器内运行的服务。
vllm-cpu:0.10: 使用名为 vllm-cpu 的镜像,并指定标签为 0.10。
传递给容器启动命令的参数:
--model /opt/models/DeepSeek-R1-Distill-Qwen-1.5B: 指定要加载的模型路径。
--dtype auto: 自动选择数据类型(例如,float32, float16),根据硬件自动优化。
--enable-chunked-prefill: 启用分块预填充功能,有助于提高推理效率。
--tensor-parallel-size 1: 设置张量并行大小为1,意味着不使用张量并行策略。
--max-num-seqs 16: 最大序列数量设置为16。
--max-model-len 2048: 设置模型的最大长度为2048。
--enable-auto-tool-choice: 启用工具自动选择功能。
--tool-call-parser "hermes": 指定使用的工具调用解析器为 "hermes"。
--chat-template "/opt/models/qwen3_nonthinking.jinja": 指定聊天模板的位置。
--chat-template-content-format "auto": 自动检测聊天模板的内容格式。
四、效果
请求参数
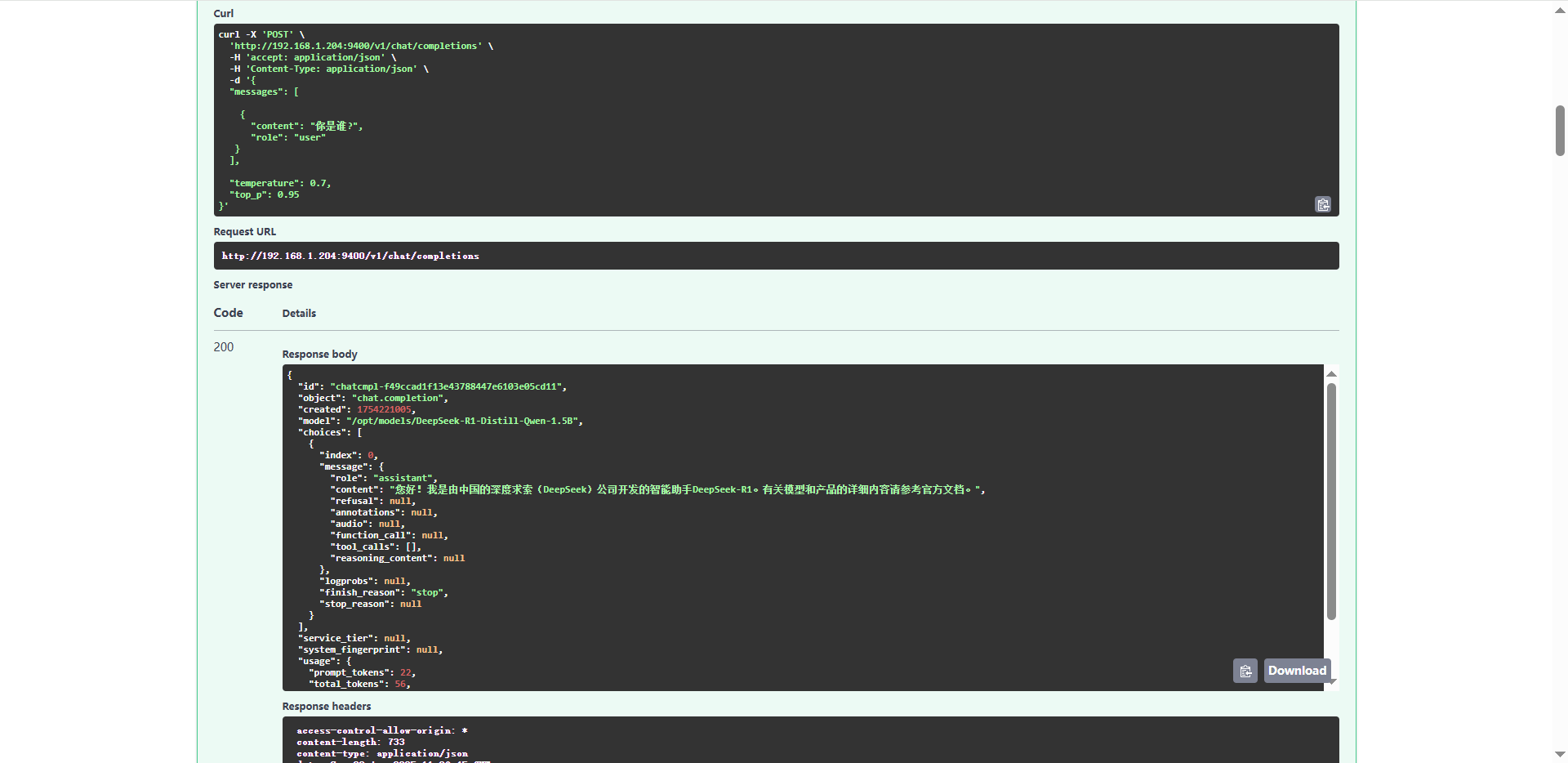
curl -X 'POST' \'http://192.168.1.204:9400/v1/chat/completions' \-H 'accept: application/json' \-H 'Content-Type: application/json' \-d '{"messages": [{"content": "你是谁?","role": "user"}],"temperature": 0.7,"top_p": 0.95 }'
返回结果
{"id": "chatcmpl-f49ccad1f13e43788447e6103e05cd11","object": "chat.completion","created": 1754221005,"model": "/opt/models/DeepSeek-R1-Distill-Qwen-1.5B","choices": [{"index": 0,"message": {"role": "assistant","content": "您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。有关模型和产品的详细内容请参考官方文档。","refusal": null,"annotations": null,"audio": null,"function_call": null,"tool_calls": [],"reasoning_content": null},"logprobs": null,"finish_reason": "stop","stop_reason": null}],"service_tier": null,"system_fingerprint": null,"usage": {"prompt_tokens": 22,"total_tokens": 56,"completion_tokens": 34,"prompt_tokens_details": null},"prompt_logprobs": null,"kv_transfer_params": null }