深入解析:如何在Kafka中配置Source和Sink连接器构建高效数据管道
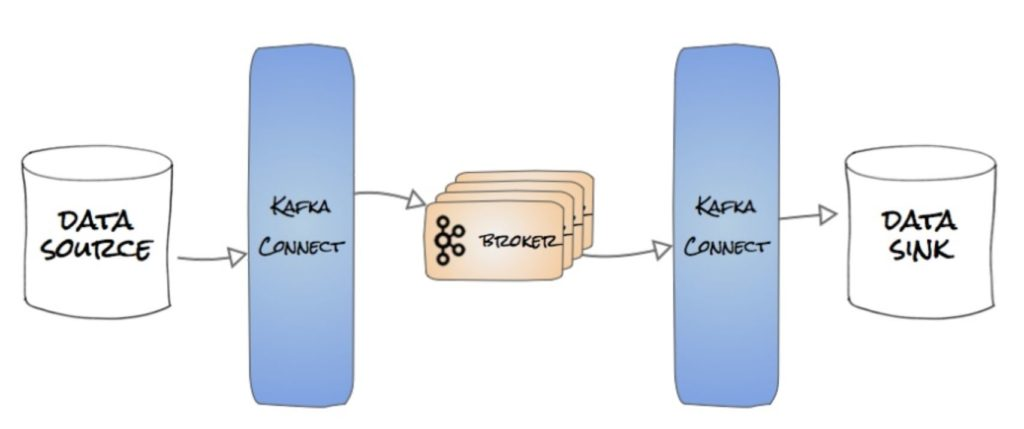
Apache Kafka作为实时事件流处理的行业标准平台,其真正价值在于能够与各种数据系统无缝集成,实现数据的导入导出。这一过程的关键在于Kafka Connectors——一组模块化插件,让我们无需编写额外代码就能将Kafka与数据基础设施连接起来。本文将深入探讨如何在Kafka中设置Source和Sink连接器,从基础配置到高级优化,构建一个健壮的数据管道。
一、Kafka连接器基础概念
在深入配置之前,我们需要明确Kafka连接器的基本类型和工作原理:
- Source连接器:负责从外部系统摄取数据到Kafka主题中
- Sink连接器:负责将Kafka主题中的数据导出到外部存储系统
Kafka Connect作为连接器管理工具,提供了开箱即用的多种连接器支持,同时也允许开发者实现自定义连接器。值得注意的是,Kafka连接器运行在Kafka基础设施之上,因此在开始配置前,必须确保Kafka和Zookeeper服务已经正常运行。
二、基础文件Source连接器配置指南
让我们从一个简单的文件Source连接器开始,将文本文件内容流式传输到Kafka中。
1. 配置文件创建
首先,我们需要创建一个配置文件file-source-connector.properties,内容如下:
connector.class=FileStreamSource
connector.type=source
tasks.max=1
topic=text_lines
file=/tmp/kafka-input.txt
这个配置指定了:
- 使用
FileStreamSource类作为连接器实现 - 设置任务数为1(单线程处理)
- 数据将被发送到
text_lines主题 - 数据源文件位于
/tmp/kafka-input.txt
2. 运行连接器
在Kafka的配置目录下保存上述文件后,我们可以使用以下命令在standalone模式下运行连接器:
bin/connect-standalone.sh config/connect-standalone.properties config/file-source-connector.properties
standalone模式非常适合开发和测试环境,因为它在一个JVM进程中运行所有连接器。
3. 验证结果
要验证数据是否成功流入Kafka,可以使用控制台消费者查看主题内容:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic text_lines --from-beginning
如果一切配置正确,你应该能看到/tmp/kafka-input.txt文件的内容作为消息出现在指定的Kafka主题中。
三、实战案例:自定义MySQL Sink连接器
接下来,让我们构建一个更接近实际业务场景的例子——将Kafka数据写入MySQL数据库的自定义Sink连接器。
1. 环境准备
首先需要安装MySQL JDBC驱动:
- 从MySQL官网下载最新的JDBC驱动jar包
- 将jar包放置在Kafka的
libs目录下
2. 配置文件创建
创建mysql-sink-connector.properties配置文件:
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
connector.type=sink
tasks.max=1
topics=db_changes
connection.url=jdbc:mysql://localhost:3306/kafka_demo
connection.user=kafka_user
connection.password=kafka_password
insert.mode=insert
auto.create=true
auto.evolve=true
这个配置实现了:
- 使用Confluent提供的JDBC Sink连接器
- 从
db_changes主题消费数据 - 连接到本地MySQL的
kafka_demo数据库 - 自动创建表结构(基于Kafka消息的键值)
- 支持表结构自动演进
3. 运行连接器
使用与Source连接器相同的命令运行Sink连接器:
bin/connect-standalone.sh config/connect-standalone.properties config/mysql-sink-connector.properties
成功运行后,db_changes主题中的数据将被写入MySQL数据库。如果目标表不存在,连接器会根据消息结构自动创建。
四、高级配置:错误处理与重试机制
在生产环境中,连接器可能会遇到各种异常情况。合理的错误处理和重试策略对于保证数据管道的可靠性至关重要。
1. 容错配置示例
以下是一个增强了错误处理能力的Source连接器配置:
connector.class=FileStreamSource
connector.type=source
tasks.max=1
topic=text_lines
file=/tmp/kafka-input.txt
errors.tolerance=all
errors.retry.timeout=30000
errors.retry.delay.max.ms=3000
关键参数说明:
errors.tolerance=all:容忍所有错误(包括数据转换错误)errors.retry.timeout=30000:重试超时时间为30秒errors.retry.delay.max.ms=3000:最大重试延迟为3秒
这种配置确保连接器不会因为临时性错误而中断,同时避免了无限重试导致的线程挂起。
2. 错误处理策略选择
根据业务需求,可以选择不同的错误容忍级别:
none:默认值,遇到任何错误立即失败all:容忍所有错误,继续处理后续记录exceptions:仅容忍可恢复的异常(如网络问题)
五、性能优化与扩展性考虑
当Kafka连接器部署在生产环境时,性能和扩展性成为关键考量因素。
1. 水平扩展策略
通过调整tasks.max参数可以实现连接器的水平扩展:
tasks.max=3
注意:并非所有连接器都支持多任务并行处理,这取决于连接器插件的实现。FileStreamSource这类简单连接器通常支持多任务,但某些数据库连接器可能由于事务限制而只能单任务运行。
2. 监控与调优
有效的监控是保证连接器稳定运行的关键。建议关注以下指标:
- 记录处理速率(records/s)
- 处理延迟
- 错误率
- 资源使用率(CPU、内存)
Kafka Connect提供了REST API用于监控连接器状态,也可以集成Prometheus等监控系统实现更全面的观测。
六、总结与最佳实践
通过本文的深入探讨,我们了解了在Kafka中配置Source和Sink连接器的完整流程:
- 从简单开始:先使用基础配置验证功能,再逐步添加复杂特性
- 重视错误处理:生产环境必须配置合理的容错和重试机制
- 考虑扩展性:设计时预留扩展空间,避免后期重构
- 全面监控:建立完善的监控体系,及时发现并解决问题
Kafka连接器的强大之处在于其灵活性和可扩展性。无论是简单的文件传输还是复杂的数据库集成,都可以通过适当的配置实现。随着业务需求的变化,可以逐步引入更高级的特性如Schema注册中心、转换器(Transformation)等,构建更加健壮和智能的数据管道。