FastLLVE:实时低光视频增强新突破
FastLLVE: Real-Time Low-Light Video Enhancement with Intensity-Aware Lookup Table
论文链接:
1简介
近年来低光照视频增强(LLVE)受到了广泛关注。LLVE的关键要求之一是帧间亮度一致性,这对于保持增强视频的时间连贯性至关重要。然而,大多数现有的基于单图像的方法未能解决这个问题,导致闪烁效应,从而降低了增强后的整体质量。此外,基于3D卷积神经网络(CNN)的方法,虽然设计用于视频以保持帧间一致性,但计算成本高昂,使其在实时应用中不切实际。为了解决这些问题,提出了一种名为FastLLVE的高效流程,该流程利用查找表(LUT)技术来有效地保持帧间亮度一致性。设计了一个可学习的强度感知LUT(IA-LUT)模块,用于自适应增强,从而解决了低光照场景中的低动态问题。这使得FastLLVE能够执行低延迟和低复杂度的增强操作,同时保持高质量的结果。在基准数据集上的实验结果表明,我们的方法在图像质量和帧间亮度一致性方面都达到了最先进(SOTA)的性能。FastLLVE可以处理1080p视频,达到50+帧/秒(FPS),这比SOTA基于CNN的方法在推理时间上快2倍,使其成为实时应用的一个有前景的解决方案。
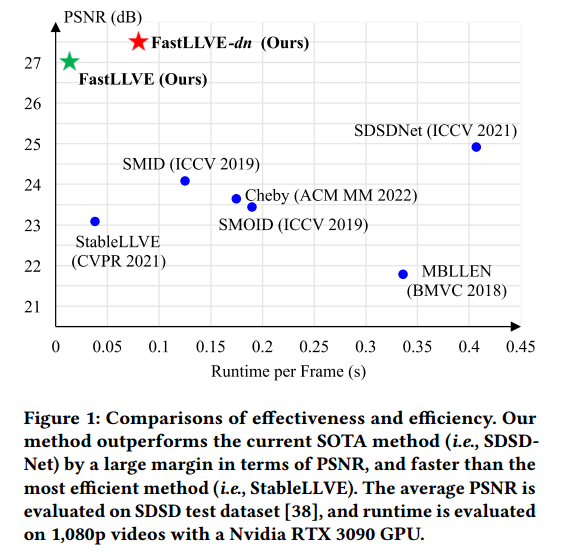
本文提出了一种名为FastLLVE的新型框架。方法建立了一个稳定且自适应的查找表(LUT)以实现实时LLVE。 设计了一个强度感知LUT(IA-LUT)来将RGB颜色从一个颜色空间转换到另一个颜色空间,它可以处理LLVE中常见的一对多映射问题。 与存储颜色值的一对一映射关系的传统LUT不同,我们的IA-LUT存储一对多映射关系,对应于每个像素的可学习增强强度。为了提高方法的泛化能力,遵循参数化方法,并将一组基本LUT与动态权重相结合。我们的方法本质上保持了帧间亮度一致性,因为基于像素的LUT变换与所有具有相同RGB值和增强强度的像素一致。此外方法计算效率高,适合实时视频增强。为了解决LUT可能无法处理的噪声问题,特别是在极低光照条件下,简化了一种常见的去噪方法,以结合一个用于去噪的插件式细化模块,表示为FastLLVE-dn,这以牺牲一些效率为代价进一步提高了性能。值得注意的是,其他去噪方法可以很容易地替换所使用的方法。如图1所示,我们的两个模型在峰值信噪比(PSNR)方面均明显优于现有方法,而FastLLVE实现了超过每秒50帧(FPS)的实时处理速度。
本文的贡献可以概括如下:
⋄ 提出了一个新颖的基于LUT的框架,名为FastLLVE,用于实时弱光视频增强。
⋄ 设计了一种新颖且轻量级的强度感知LUT,它解决了低光照视频增强中的一对多映射问题。
⋄ 大量实验表明,在大多数情况下,FastLLVE在基准测试中取得了SOTA结果,且推理速度超过50 FPS。
2背景
低照度视频增强(LLVE)是一项长期存在的任务,旨在将低照度视频转换为具有更好可见度的正常照度视频,近年来受到了相当大的关注。在低照度条件下,视频通常会受到纹理劣化和低对比度的影响,导致较差的可见度和高级视觉任务的显著退化。与基于更高ISO和曝光的传统方法(可能导致噪声和运动模糊)不同,LLVE提供了一种有效的解决方案,以提高在极低照度条件下拍摄的视频的视觉质量。此外,它可以作为各种应用的基本增强模块,例如,视觉监控、自动驾驶,和无人驾驶飞行器。
与其他典型的视频任务(如视频帧插值和视频超分辨率)一样,LLVE也需要时间稳定性。此外,LLVE固有的病态性质使其成为一项更具挑战性的任务。因此,尽管低光图像增强(LLIE)已经展示了卓越的性能,但递归地将这些基于图像的方法应用于视频帧是不可行的。因为它非常耗时,并且可能导致增强视频中出现闪烁效应。闪烁问题是由相邻帧之间亮度不一致引起的。为了解决这个问题,最近的LLVE方法利用了时间对齐和3D卷积(3D-Conv)来建立视频中的时空关系。他们还采用了自洽性作为辅助损失,以指导网络保持亮度一致性。然而,基于对齐的方法旨在估计相邻帧之间对应的像素,容易出错,并可能导致增强视频中的物体失真。相比之下,3D-Conv能够捕获全面的时空信息,但代价是更高的计算复杂度。因此,以前的方法发现很难在效率和性能之间取得平衡。总而言之,一种周全的LLVE方法应该解决以下具有挑战性的问题:
• 不适定问题。在弱光视频中,色彩空间的低动态范围可能导致相似的颜色输入对应不同的目标颜色。这种现象导致了一对多的映射问题,这在复杂场景中难以解决。为了解决这个问题,先前的方法利用全局上下文信息和局部一致性来增强不同的颜色。尽管它们各自有效,但由于它们严重依赖于上下文提取的精度和可靠性,因此这些方法在颜色处理方面存在不稳定性。
• 亮度一致性。在低光视频增强(LLVE)中,保持亮度一致性对于实现高感知质量至关重要。然而,目前基于对齐的方法通常无法实现相邻帧之间的精确对齐,导致LLVE输出不稳定。此外,用于提高这些方法稳定性的自一致性损失函数也无法解决根本的不稳定性问题。这种局限性阻碍了它们有效提高整体视觉质量的能力。
• 效率。尽管 3D-Conv 方法通过利用全面的时空信息在视频增强任务中表现出显著的改进,但它们也伴随着沉重的计算复杂度。这使得它们对于需要实时增强的现实世界应用来说是不切实际。
3 方法
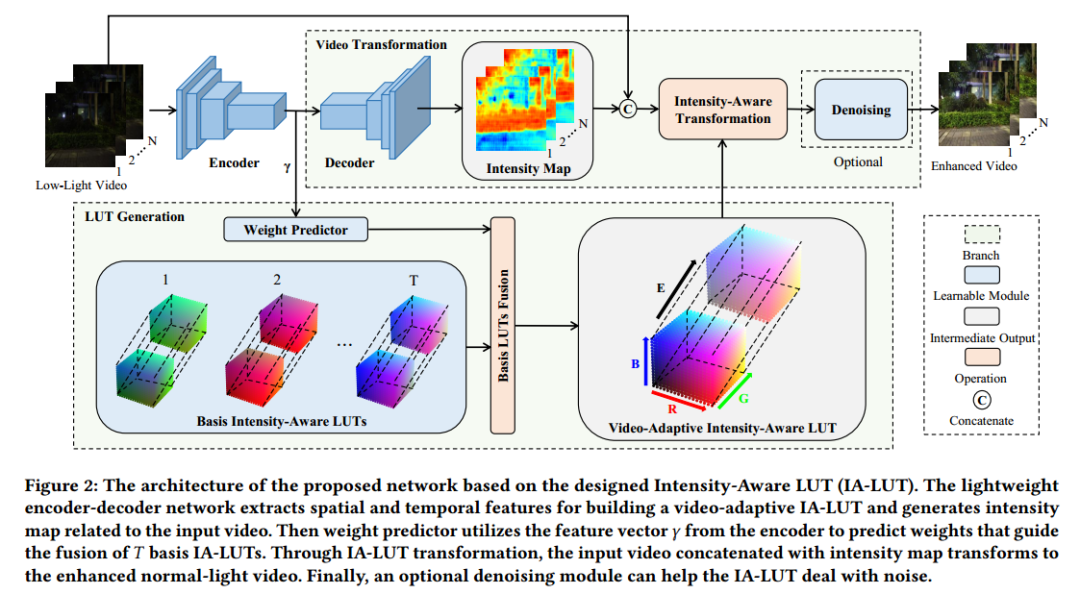
FastLLVE 的结构如图 2 所示。首先,输入视频帧通过轻量级编码器网络被编码成潜在特征。之后,潜在特征被并行馈送到两个模块中,即 LUT 生成模块和视频转换模块。通过 LUT 生成模块生成视频自适应 LUT,同时生成用于视频转换的强度图。然后,每个像素通过 IA-LUT 转换进行增强,其 RGB 值和增强强度作为索引。最后,转换后的视频被馈送到去噪模块以进行进一步增强。
3.1 LUT生成模块
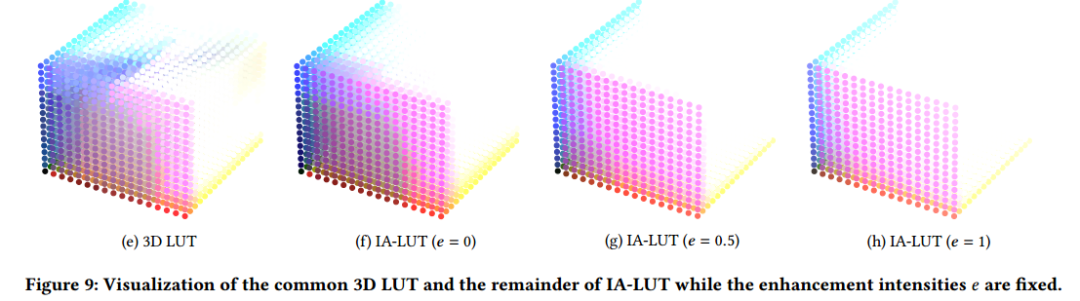
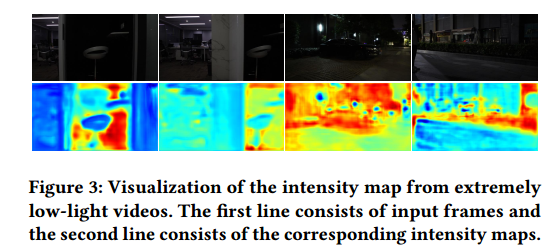
定义。尽管来自不同区域的低光像素在RGB中可能看起来相似,但它们在低光增强过程中对应于不同的增强强度。在图3中,可视化了几种强度图,其中即使是来自极低光视频的像素也具有不同的增强强度。传统的三维LUT仅保存颜色变换的一对一映射关系,这无法解决颜色相似的低光像素的不适定问题。为了解决这个问题,增加了一个表示增强强度的新维度,相应的LUT表示为强度感知LUT。它可以为一个到多的映射关系存储多个颜色空间,并有助于为LLVE进行更精细的颜色转换。值得注意的是,IA-LUT中只保存采样的稀疏离散输入空间,以避免引入大量的参数,这可能导致沉重的内存负担和巨大的训练难度。并且由于稀疏离散的4D输入空间,IA-LUT的LUT变换应该使用四线性插值来实现。





4实验
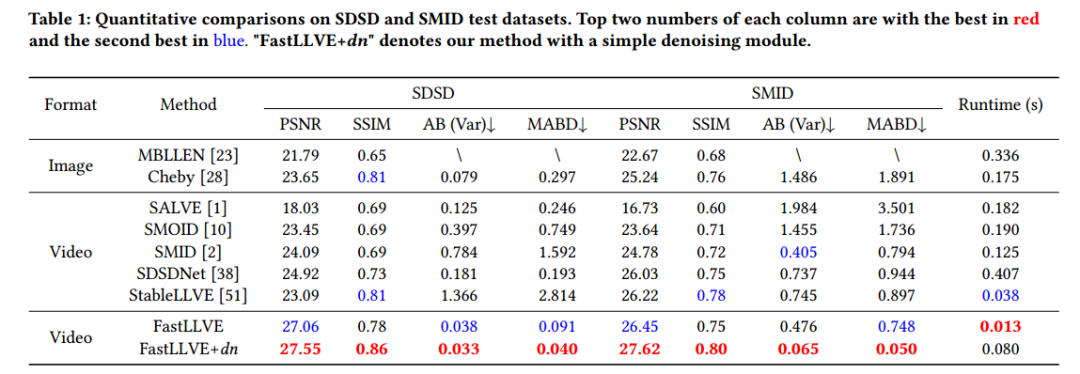
1)SDSD和SMID测试数据集的定量比较
2)SDSD测试数据集的定性比较

3)SMID测试数据集的定性比较。

4)当增强强度固定时,常见3D LUT和IA-LUT的其余部分的可视化