借助 Amazon SageMaker Catalog 功能,简化从数据到洞察的路径
在数据驱动的时代,企业常陷于数据孤岛、特征重复开发、模型溯源困难等困境。Amazon SageMaker Catalog 应运而生,作为统一的数据和特征治理中心,它能打通从原始数据到模型部署的全链路,显著加速数据科学项目落地。
一、痛点:数据科学项目中的常见瓶颈
数据发现困难:数据分散在 S3、Redshift 等不同存储中,缺乏统一视图
特征管理混乱:特征工程脚本散落各处,无法复用和共享
模型溯源缺失:无法追踪模型训练所用的数据和特征版本
协作效率低下:团队间缺乏标准化的数据与特征共享机制
二、SageMaker Catalog 核心功能解析
SageMaker Catalog 是 SageMaker 的元数据管理层,提供两大核心能力:
统一数据源管理
对接 S3、Athena、Redshift 等数据源
自动抽取 Schema 和统计信息
支持自定义标签(如 PII 分类、数据所有者)
# 使用 boto3 注册 S3 数据源
import boto3
sm_client = boto3.client('sagemaker')response = sm_client.create_data_artifact(Source={'SourceUri': 's3://my-bucket/raw-data/','SourceType': 'S3'},ArtifactType='DataSet',ArtifactName='clinical-trials-raw'
)特征工厂(Feature Store)集成
离线特征库:支持大规模批量训练
在线特征库:低延迟实时推理
自动特征版本控制
三、实战:端到端数据科学管道搭建
场景:制药公司临床试验数据分析
数据发现与理解
在 Catalog UI 中搜索
patient_records查看数据分布、缺失值统计
通过血缘图追溯数据来源
特征工程标准化
# 创建可复用的特征处理器
from sagemaker.feature_store.feature_processor import FeatureProcessor@FeatureProcessor(target_stores=["OfflineStore"], output_artifact_name="processed-clinical-features"
)
def process_clinical_data(input_data):df = input_data[0].dropna(subset=['dosage'])df['treatment_effectiveness'] = df['efficacy'] / df['dosage']return df3.模型训练与溯源
训练时自动关联特征版本:
estimator = sagemaker.estimator.Estimator(...,feature_store_data_capture_config=FeatureStoreDataCaptureConfig(enable_capture=True,feature_group_name="clinical-features-v1")
)4.部署与监控
通过 Catalog API 获取生产环境特征
监控特征漂移:
from sagemaker.model_monitor import DataQualityMonitormonitor = DataQualityMonitor(base_job_name='clinical-model-monitor',feature_store_baseline=[('clinical-features', 'v1.2')]
)四、最佳实践:最大化 Catalog 价值
数据治理策略
使用 AWS Lake Formation 设置列级权限
对敏感数据打标
PII=true设置数据保留策略(如临时数据保留7天)
特征复用机制
建立特征命名规范:
<domain>_<entity>_<attribute>创建特征文档模板(包含业务含义、计算逻辑)
CI/CD 集成
# Jenkins 流水线示例
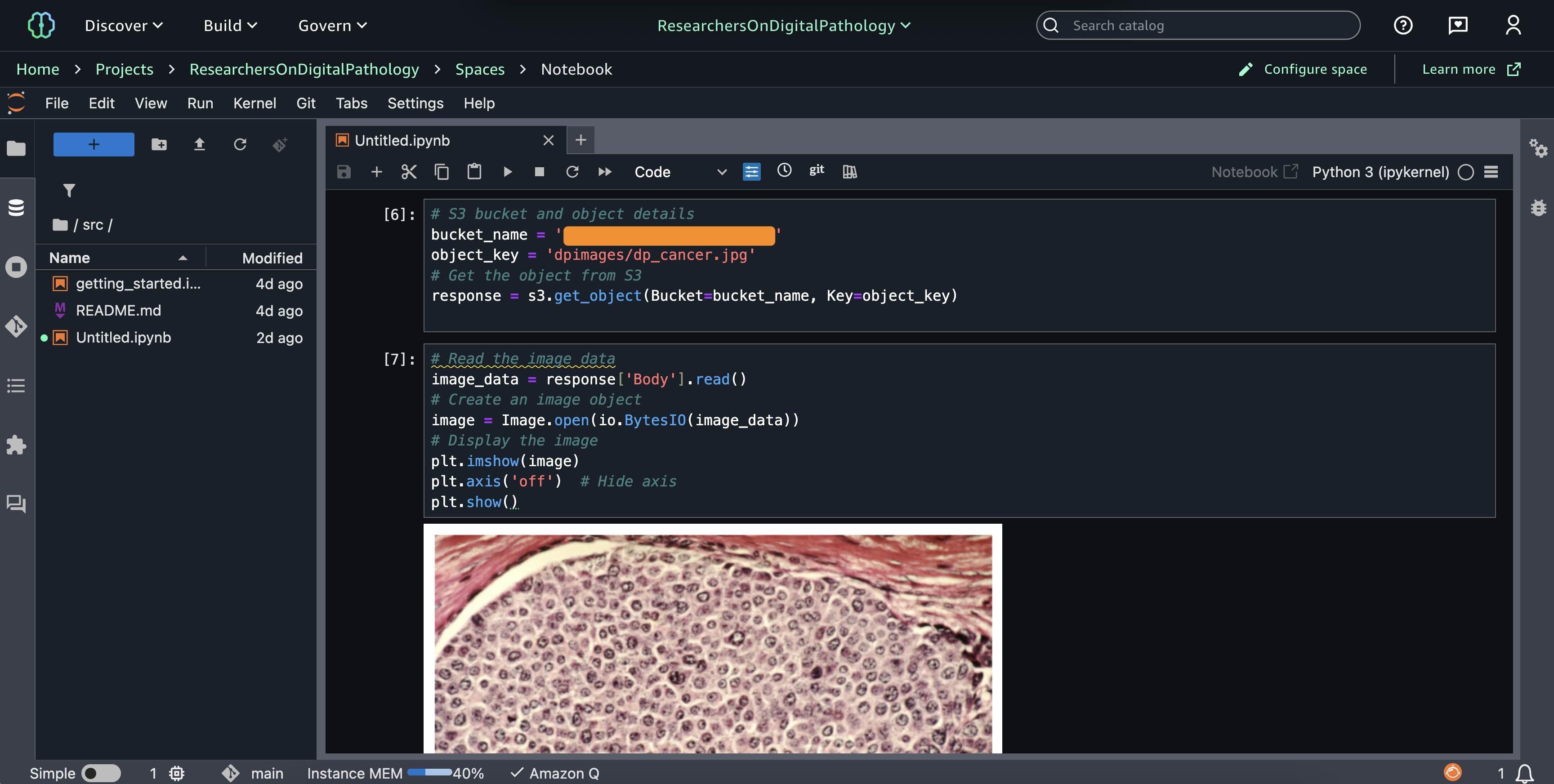
stages:- name: PromoteFeatureaction: type: FeatureStoreDeployversion: ${GIT_COMMIT}approval: DATA_STEWARD当获得访问权限之后,您现在可以在 Amazon SageMaker Jupyter Notebook 中处理非结构化数据。如下屏幕截图显示了一个在医疗使用案例中处理图像的示例。
五、效能对比:传统模式 vs Catalog 驱动模式
| 指标 | 传统模式 | Catalog 模式 | 提升幅度 |
|---|---|---|---|
| 新项目数据准备时间 | 2周 | 2天 | 85%↓ |
| 特征重复开发率 | 40% | <5% | 90%↓ |
| 模型审计时间 | 人工追踪3天 | 自动生成报告5分钟 | 99%↓ |
某生物科技公司案例:通过 Catalog 统一管理 15PB 基因组数据,特征复用率提高至 92%,模型迭代速度从季度发布加速到周级发布。
六、实施路线图
启动阶段(1-2周)
连接主要数据源(S3/Redshift)
注册关键数据集
培训数据工程师使用 Catalog UI
扩展阶段(3-4周)
部署特征工厂
迁移核心特征工程管道
集成模型注册表
成熟阶段(持续迭代)
实现全链路血缘追踪
建立数据质量监控规则
与业务BI工具(如QuickSight)集成
总结:构建企业级数据科学基座
Amazon SageMaker Catalog 通过四大核心价值重塑数据科学工作流:
可发现性:一键定位所需数据资产
可复用性:特征工程一次开发,多次使用
可追溯性:完整记录从数据到模型的转化路径
可协作性:标准化接口打破团队壁垒
技术的最终价值在于推动业务增长。当数据科学家从繁重的数据整理中解放,更多时间将用于解决核心业务问题——这才是真正的高效创新。