智能体性能优化:延迟、吞吐量与成本控制

智能体性能优化:延迟、吞吐量与成本控制
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
目录
智能体性能优化:延迟、吞吐量与成本控制
摘要
1. 性能瓶颈识别与分析
1.1 性能指标体系
1.2 瓶颈识别方法
1.3 性能监控架构
2. 模型推理优化技术
2.1 模型量化与压缩
2.2 批处理与并行推理
2.3 推理加速技术对比
3. 缓存策略与并发处理
3.1 多层缓存架构
3.2 并发控制与限流
3.3 缓存策略对比分析
4. 成本效益分析与优化
4.1 成本监控体系
4.2 自动扩缩容策略
4.3 成本优化策略对比
4.4 ROI计算模型
5. 性能优化最佳实践
5.1 优化实施路线图
5.2 监控告警配置
6. 测评体系与效果验证
6.1 性能测试框架
6.2 性能评分体系
总结
参考资料
摘要
作为一名深耕AI领域多年的技术博主摘星,我深刻认识到智能体(AI Agent)性能优化在当今人工智能应用中的关键地位。随着大语言模型和智能体技术的快速发展,如何在保证服务质量的前提下优化系统性能、控制运营成本,已成为每个AI从业者必须面对的核心挑战。在我多年的实践经验中,我发现许多团队在部署智能体系统时往往只关注功能实现,而忽视了性能优化的重要性,导致系统在高并发场景下响应缓慢、成本居高不下,最终影响用户体验和商业价值。本文将从性能瓶颈识别与分析、模型推理优化技术、缓存策略与并发处理、成本效益分析与优化四个维度,系统性地探讨智能体性能优化的核心技术和最佳实践。通过深入分析延迟(Latency)、吞吐量(Throughput)和成本控制(Cost Control)三大关键指标,我将分享在实际项目中积累的优化经验和技术方案,帮助读者构建高性能、低成本的智能体系统。
1. 性能瓶颈识别与分析
1.1 性能指标体系
在智能体系统中,性能优化的第一步是建立完善的性能指标体系。核心指标包括:
| 指标类别 | 具体指标 | 目标值 | 监控方法 |
| 延迟指标 | 平均响应时间 | < 2s | APM工具监控 |
| P95响应时间 | < 5s | 分位数统计 | |
| 首字节时间(TTFB) | < 500ms | 网络层监控 | |
| 吞吐量指标 | QPS | > 1000 | 负载测试 |
| 并发用户数 | > 5000 | 压力测试 | |
| 模型推理TPS | > 100 | GPU监控 | |
| 资源指标 | CPU利用率 | < 80% | 系统监控 |
| 内存使用率 | < 85% | 内存监控 | |
| GPU利用率 | > 90% | NVIDIA-SMI |
1.2 瓶颈识别方法
import time
import psutil
import GPUtil
from functools import wrapsclass PerformanceProfiler:"""智能体性能分析器"""def __init__(self):self.metrics = {}def profile_function(self, func_name):"""函数性能装饰器"""def decorator(func):@wraps(func)def wrapper(*args, **kwargs):start_time = time.time()cpu_before = psutil.cpu_percent()memory_before = psutil.virtual_memory().percent# 执行函数result = func(*args, **kwargs)end_time = time.time()cpu_after = psutil.cpu_percent()memory_after = psutil.virtual_memory().percent# 记录性能指标self.metrics[func_name] = {'execution_time': end_time - start_time,'cpu_usage': cpu_after - cpu_before,'memory_usage': memory_after - memory_before,'timestamp': time.time()}return resultreturn wrapperreturn decoratordef get_gpu_metrics(self):"""获取GPU性能指标"""gpus = GPUtil.getGPUs()if gpus:gpu = gpus[0]return {'gpu_utilization': gpu.load * 100,'memory_utilization': gpu.memoryUtil * 100,'temperature': gpu.temperature}return Nonedef analyze_bottlenecks(self):"""分析性能瓶颈"""bottlenecks = []for func_name, metrics in self.metrics.items():if metrics['execution_time'] > 2.0:bottlenecks.append(f"函数 {func_name} 执行时间过长: {metrics['execution_time']:.2f}s")if metrics['cpu_usage'] > 80:bottlenecks.append(f"函数 {func_name} CPU使用率过高: {metrics['cpu_usage']:.1f}%")return bottlenecks# 使用示例
profiler = PerformanceProfiler()@profiler.profile_function("model_inference")
def model_inference(input_data):"""模型推理函数"""# 模拟模型推理过程time.sleep(0.5) # 模拟推理延迟return "inference_result"1.3 性能监控架构
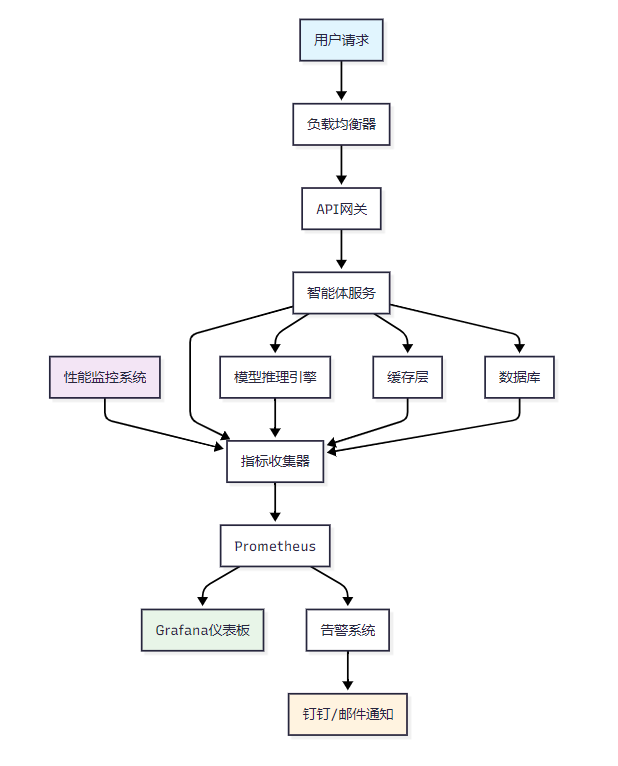
图1:智能体性能监控架构图
2. 模型推理优化技术
2.1 模型量化与压缩
模型量化是降低推理延迟和内存占用的有效手段:
import torch
import torch.quantization as quantization
from transformers import AutoModel, AutoTokenizerclass ModelOptimizer:"""模型优化器"""def __init__(self, model_name):self.model_name = model_nameself.model = AutoModel.from_pretrained(model_name)self.tokenizer = AutoTokenizer.from_pretrained(model_name)def quantize_model(self, quantization_type='dynamic'):"""模型量化"""if quantization_type == 'dynamic':# 动态量化quantized_model = torch.quantization.quantize_dynamic(self.model,{torch.nn.Linear}, # 量化线性层dtype=torch.qint8)elif quantization_type == 'static':# 静态量化self.model.eval()self.model.qconfig = quantization.get_default_qconfig('fbgemm')quantization.prepare(self.model, inplace=True)# 校准数据集(示例)calibration_data = self._get_calibration_data()with torch.no_grad():for data in calibration_data:self.model(data)quantized_model = quantization.convert(self.model, inplace=False)return quantized_modeldef prune_model(self, sparsity=0.3):"""模型剪枝"""import torch.nn.utils.prune as prune# 结构化剪枝for name, module in self.model.named_modules():if isinstance(module, torch.nn.Linear):prune.l1_unstructured(module, name='weight', amount=sparsity)prune.remove(module, 'weight')return self.modeldef optimize_for_inference(self):"""推理优化"""# 设置为评估模式self.model.eval()# 禁用梯度计算for param in self.model.parameters():param.requires_grad = False# JIT编译优化if torch.cuda.is_available():self.model = self.model.cuda()# 使用TorchScript优化example_input = torch.randint(0, 1000, (1, 512)).cuda()traced_model = torch.jit.trace(self.model, example_input)return traced_modelreturn self.modeldef _get_calibration_data(self):"""获取校准数据集"""# 返回校准数据集return [torch.randint(0, 1000, (1, 512)) for _ in range(100)]# 使用示例
optimizer = ModelOptimizer("bert-base-chinese")
quantized_model = optimizer.quantize_model('dynamic')
optimized_model = optimizer.optimize_for_inference()2.2 批处理与并行推理
import asyncio
import torch
from concurrent.futures import ThreadPoolExecutor
from typing import List, Dict, Anyclass BatchInferenceEngine:"""批处理推理引擎"""def __init__(self, model, max_batch_size=32, max_wait_time=0.1):self.model = modelself.max_batch_size = max_batch_sizeself.max_wait_time = max_wait_timeself.request_queue = asyncio.Queue()self.executor = ThreadPoolExecutor(max_workers=4)async def add_request(self, input_data: Dict[str, Any]) -> str:"""添加推理请求"""future = asyncio.Future()await self.request_queue.put({'input': input_data,'future': future,'timestamp': asyncio.get_event_loop().time()})return await futureasync def batch_processor(self):"""批处理器"""while True:batch = []start_time = asyncio.get_event_loop().time()# 收集批次请求while (len(batch) < self.max_batch_size and (asyncio.get_event_loop().time() - start_time) < self.max_wait_time):try:request = await asyncio.wait_for(self.request_queue.get(), timeout=self.max_wait_time)batch.append(request)except asyncio.TimeoutError:breakif batch:await self._process_batch(batch)async def _process_batch(self, batch: List[Dict]):"""处理批次"""inputs = [req['input'] for req in batch]futures = [req['future'] for req in batch]# 并行推理loop = asyncio.get_event_loop()results = await loop.run_in_executor(self.executor, self._batch_inference, inputs)# 返回结果for future, result in zip(futures, results):future.set_result(result)def _batch_inference(self, inputs: List[Dict]) -> List[str]:"""批量推理"""with torch.no_grad():# 批量处理输入batch_input = self._prepare_batch_input(inputs)# 模型推理outputs = self.model(batch_input)# 处理输出results = self._process_batch_output(outputs)return resultsdef _prepare_batch_input(self, inputs: List[Dict]) -> torch.Tensor:"""准备批量输入"""# 实现批量输入准备逻辑return torch.stack([torch.tensor(inp['data']) for inp in inputs])def _process_batch_output(self, outputs: torch.Tensor) -> List[str]:"""处理批量输出"""# 实现批量输出处理逻辑return [f"result_{i}" for i in range(outputs.size(0))]# 使用示例
async def main():model = torch.nn.Linear(10, 1) # 示例模型engine = BatchInferenceEngine(model)# 启动批处理器asyncio.create_task(engine.batch_processor())# 并发请求tasks = []for i in range(100):task = engine.add_request({'data': torch.randn(10)})tasks.append(task)results = await asyncio.gather(*tasks)print(f"处理了 {len(results)} 个请求")2.3 推理加速技术对比
| 技术方案 | 延迟降低 | 内存节省 | 精度损失 | 实现复杂度 | 适用场景 |
| 动态量化 | 30-50% | 50-75% | 微小 | 低 | 通用场景 |
| 静态量化 | 40-60% | 60-80% | 小 | 中 | 生产环境 |
| 模型剪枝 | 20-40% | 30-60% | 中等 | 高 | 资源受限 |
| 知识蒸馏 | 50-70% | 70-90% | 中等 | 高 | 移动端部署 |
| TensorRT | 60-80% | 40-60% | 微小 | 中 | NVIDIA GPU |
| ONNX Runtime | 40-60% | 30-50% | 微小 | 低 | 跨平台部署 |
3. 缓存策略与并发处理
3.1 多层缓存架构
import redis
import hashlib
import pickle
from typing import Any, Optional
from functools import wraps
import asyncioclass MultiLevelCache:"""多层缓存系统"""def __init__(self, redis_host='localhost', redis_port=6379):# L1缓存:内存缓存self.memory_cache = {}self.memory_cache_size = 1000# L2缓存:Redis缓存self.redis_client = redis.Redis(host=redis_host, port=redis_port, decode_responses=False)# L3缓存:磁盘缓存self.disk_cache_path = "./cache/"def _generate_key(self, *args, **kwargs) -> str:"""生成缓存键"""key_data = str(args) + str(sorted(kwargs.items()))return hashlib.md5(key_data.encode()).hexdigest()async def get(self, key: str) -> Optional[Any]:"""获取缓存数据"""# L1缓存查找if key in self.memory_cache:return self.memory_cache[key]# L2缓存查找redis_data = self.redis_client.get(key)if redis_data:data = pickle.loads(redis_data)# 回写到L1缓存self._set_memory_cache(key, data)return data# L3缓存查找disk_data = await self._get_disk_cache(key)if disk_data:# 回写到L2和L1缓存self.redis_client.setex(key, 3600, pickle.dumps(disk_data))self._set_memory_cache(key, disk_data)return disk_datareturn Noneasync def set(self, key: str, value: Any, ttl: int = 3600):"""设置缓存数据"""# 设置L1缓存self._set_memory_cache(key, value)# 设置L2缓存self.redis_client.setex(key, ttl, pickle.dumps(value))# 设置L3缓存await self._set_disk_cache(key, value)def _set_memory_cache(self, key: str, value: Any):"""设置内存缓存"""if len(self.memory_cache) >= self.memory_cache_size:# LRU淘汰策略oldest_key = next(iter(self.memory_cache))del self.memory_cache[oldest_key]self.memory_cache[key] = valueasync def _get_disk_cache(self, key: str) -> Optional[Any]:"""获取磁盘缓存"""import osimport aiofilesfile_path = f"{self.disk_cache_path}{key}.pkl"if os.path.exists(file_path):async with aiofiles.open(file_path, 'rb') as f:data = await f.read()return pickle.loads(data)return Noneasync def _set_disk_cache(self, key: str, value: Any):"""设置磁盘缓存"""import osimport aiofilesos.makedirs(self.disk_cache_path, exist_ok=True)file_path = f"{self.disk_cache_path}{key}.pkl"async with aiofiles.open(file_path, 'wb') as f:await f.write(pickle.dumps(value))def cache_result(cache_instance: MultiLevelCache, ttl: int = 3600):"""缓存装饰器"""def decorator(func):@wraps(func)async def wrapper(*args, **kwargs):# 生成缓存键cache_key = cache_instance._generate_key(func.__name__, *args, **kwargs)# 尝试从缓存获取cached_result = await cache_instance.get(cache_key)if cached_result is not None:return cached_result# 执行函数result = await func(*args, **kwargs)# 存储到缓存await cache_instance.set(cache_key, result, ttl)return resultreturn wrapperreturn decorator# 使用示例
cache = MultiLevelCache()@cache_result(cache, ttl=1800)
async def expensive_ai_operation(query: str, model_params: dict):"""耗时的AI操作"""# 模拟耗时操作await asyncio.sleep(2)return f"AI result for: {query}"3.2 并发控制与限流
import asyncio
import time
from collections import defaultdict
from typing import Dict, List
import aiohttpclass ConcurrencyController:"""并发控制器"""def __init__(self, max_concurrent=100, rate_limit=1000):self.semaphore = asyncio.Semaphore(max_concurrent)self.rate_limiter = RateLimiter(rate_limit)self.circuit_breaker = CircuitBreaker()async def execute_with_control(self, coro):"""带并发控制的执行"""async with self.semaphore:# 限流检查await self.rate_limiter.acquire()# 熔断检查if self.circuit_breaker.is_open():raise Exception("Circuit breaker is open")try:result = await coroself.circuit_breaker.record_success()return resultexcept Exception as e:self.circuit_breaker.record_failure()raise eclass RateLimiter:"""令牌桶限流器"""def __init__(self, rate: int, capacity: int = None):self.rate = rate # 每秒令牌数self.capacity = capacity or rate # 桶容量self.tokens = self.capacityself.last_update = time.time()self.lock = asyncio.Lock()async def acquire(self):"""获取令牌"""async with self.lock:now = time.time()# 添加令牌elapsed = now - self.last_updateself.tokens = min(self.capacity, self.tokens + elapsed * self.rate)self.last_update = nowif self.tokens >= 1:self.tokens -= 1return Trueelse:# 等待令牌wait_time = (1 - self.tokens) / self.rateawait asyncio.sleep(wait_time)self.tokens = 0return Trueclass CircuitBreaker:"""熔断器"""def __init__(self, failure_threshold=5, timeout=60):self.failure_threshold = failure_thresholdself.timeout = timeoutself.failure_count = 0self.last_failure_time = Noneself.state = 'CLOSED' # CLOSED, OPEN, HALF_OPENdef is_open(self) -> bool:"""检查熔断器是否开启"""if self.state == 'OPEN':if time.time() - self.last_failure_time > self.timeout:self.state = 'HALF_OPEN'return Falsereturn Truereturn Falsedef record_success(self):"""记录成功"""self.failure_count = 0self.state = 'CLOSED'def record_failure(self):"""记录失败"""self.failure_count += 1self.last_failure_time = time.time()if self.failure_count >= self.failure_threshold:self.state = 'OPEN'3.3 缓存策略对比分析
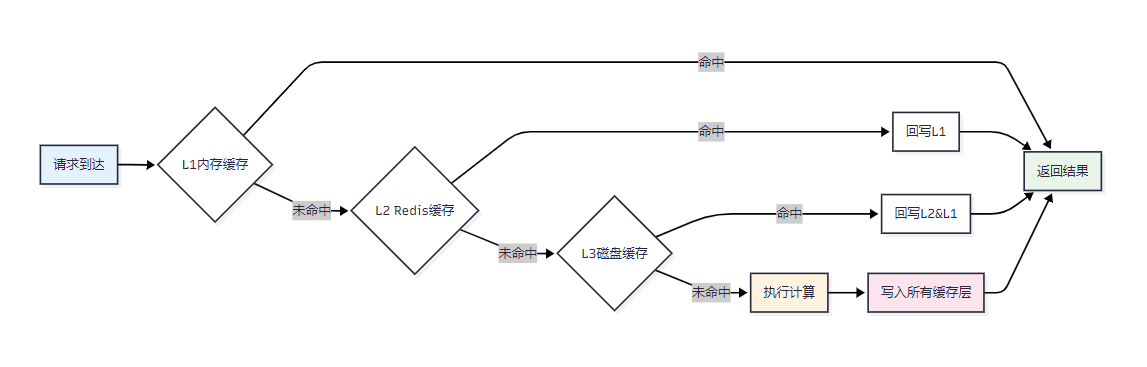
图2:多层缓存命中流程图
4. 成本效益分析与优化
4.1 成本监控体系
import time
from dataclasses import dataclass
from typing import Dict, List
import json@dataclass
class CostMetrics:"""成本指标"""compute_cost: float # 计算成本storage_cost: float # 存储成本network_cost: float # 网络成本api_call_cost: float # API调用成本timestamp: floatclass CostAnalyzer:"""成本分析器"""def __init__(self):self.cost_history: List[CostMetrics] = []self.pricing_config = {'gpu_hour': 2.5, # GPU每小时成本'cpu_hour': 0.1, # CPU每小时成本'storage_gb': 0.02, # 存储每GB成本'api_call': 0.001, # API调用成本'bandwidth_gb': 0.05 # 带宽每GB成本}def calculate_inference_cost(self, gpu_time: float, cpu_time: float, api_calls: int,data_transfer: float) -> CostMetrics:"""计算推理成本"""compute_cost = (gpu_time * self.pricing_config['gpu_hour'] + cpu_time * self.pricing_config['cpu_hour'])api_call_cost = api_calls * self.pricing_config['api_call']network_cost = data_transfer * self.pricing_config['bandwidth_gb']storage_cost = 0 # 推理阶段存储成本较低metrics = CostMetrics(compute_cost=compute_cost,storage_cost=storage_cost,network_cost=network_cost,api_call_cost=api_call_cost,timestamp=time.time())self.cost_history.append(metrics)return metricsdef analyze_cost_trends(self, days: int = 7) -> Dict:"""分析成本趋势"""cutoff_time = time.time() - (days * 24 * 3600)recent_costs = [cost for cost in self.cost_history if cost.timestamp > cutoff_time]if not recent_costs:return {}total_compute = sum(c.compute_cost for c in recent_costs)total_network = sum(c.network_cost for c in recent_costs)total_api = sum(c.api_call_cost for c in recent_costs)total_cost = total_compute + total_network + total_apireturn {'total_cost': total_cost,'compute_percentage': (total_compute / total_cost) * 100,'network_percentage': (total_network / total_cost) * 100,'api_percentage': (total_api / total_cost) * 100,'daily_average': total_cost / days,'cost_per_request': total_cost / len(recent_costs) if recent_costs else 0}def optimize_recommendations(self) -> List[str]:"""优化建议"""analysis = self.analyze_cost_trends()recommendations = []if analysis.get('compute_percentage', 0) > 60:recommendations.append("考虑使用模型量化或更小的模型以降低计算成本")recommendations.append("实施批处理以提高GPU利用率")if analysis.get('network_percentage', 0) > 30:recommendations.append("优化数据传输,使用压缩和缓存")recommendations.append("考虑CDN加速以降低网络成本")if analysis.get('api_percentage', 0) > 40:recommendations.append("实施智能缓存策略减少API调用")recommendations.append("考虑批量API调用以获得折扣")return recommendations# 使用示例
cost_analyzer = CostAnalyzer()# 记录成本
metrics = cost_analyzer.calculate_inference_cost(gpu_time=0.1, # 0.1小时GPU时间cpu_time=0.05, # 0.05小时CPU时间api_calls=100, # 100次API调用data_transfer=0.5 # 0.5GB数据传输
)print(f"推理成本: ${metrics.compute_cost + metrics.api_call_cost + metrics.network_cost:.4f}")4.2 自动扩缩容策略
import asyncio
import time
from typing import Dict, List
from dataclasses import dataclass@dataclass
class ScalingMetrics:"""扩缩容指标"""cpu_usage: floatmemory_usage: floatgpu_usage: floatrequest_rate: floatresponse_time: floatqueue_length: intclass AutoScaler:"""自动扩缩容器"""def __init__(self):self.min_instances = 1self.max_instances = 10self.current_instances = 2self.scaling_cooldown = 300 # 5分钟冷却期self.last_scaling_time = 0# 扩缩容阈值self.scale_up_thresholds = {'cpu_usage': 70,'memory_usage': 80,'gpu_usage': 85,'response_time': 2.0,'queue_length': 50}self.scale_down_thresholds = {'cpu_usage': 30,'memory_usage': 40,'gpu_usage': 40,'response_time': 0.5,'queue_length': 5}def should_scale_up(self, metrics: ScalingMetrics) -> bool:"""判断是否需要扩容"""conditions = [metrics.cpu_usage > self.scale_up_thresholds['cpu_usage'],metrics.memory_usage > self.scale_up_thresholds['memory_usage'],metrics.gpu_usage > self.scale_up_thresholds['gpu_usage'],metrics.response_time > self.scale_up_thresholds['response_time'],metrics.queue_length > self.scale_up_thresholds['queue_length']]# 任意两个条件满足即扩容return sum(conditions) >= 2def should_scale_down(self, metrics: ScalingMetrics) -> bool:"""判断是否需要缩容"""conditions = [metrics.cpu_usage < self.scale_down_thresholds['cpu_usage'],metrics.memory_usage < self.scale_down_thresholds['memory_usage'],metrics.gpu_usage < self.scale_down_thresholds['gpu_usage'],metrics.response_time < self.scale_down_thresholds['response_time'],metrics.queue_length < self.scale_down_thresholds['queue_length']]# 所有条件都满足才缩容return all(conditions) and self.current_instances > self.min_instancesasync def auto_scale(self, metrics: ScalingMetrics) -> Dict[str, any]:"""自动扩缩容"""current_time = time.time()# 检查冷却期if current_time - self.last_scaling_time < self.scaling_cooldown:return {'action': 'none', 'reason': 'cooling_down'}if self.should_scale_up(metrics) and self.current_instances < self.max_instances:# 扩容new_instances = min(self.current_instances + 1, self.max_instances)await self._scale_instances(new_instances)self.current_instances = new_instancesself.last_scaling_time = current_timereturn {'action': 'scale_up','old_instances': self.current_instances - 1,'new_instances': new_instances,'reason': 'high_load'}elif self.should_scale_down(metrics):# 缩容new_instances = max(self.current_instances - 1, self.min_instances)await self._scale_instances(new_instances)self.current_instances = new_instancesself.last_scaling_time = current_timereturn {'action': 'scale_down','old_instances': self.current_instances + 1,'new_instances': new_instances,'reason': 'low_load'}return {'action': 'none', 'reason': 'stable'}async def _scale_instances(self, target_instances: int):"""执行实例扩缩容"""# 这里实现具体的扩缩容逻辑# 例如:调用Kubernetes API、Docker Swarm等print(f"Scaling to {target_instances} instances")await asyncio.sleep(1) # 模拟扩缩容延迟# 使用示例
scaler = AutoScaler()async def monitoring_loop():"""监控循环"""while True:# 获取当前指标(示例数据)metrics = ScalingMetrics(cpu_usage=75.0,memory_usage=60.0,gpu_usage=90.0,response_time=2.5,request_rate=150.0,queue_length=60)# 执行自动扩缩容result = await scaler.auto_scale(metrics)print(f"扩缩容结果: {result}")await asyncio.sleep(60) # 每分钟检查一次4.3 成本优化策略对比
| 优化策略 | 成本节省 | 实施难度 | 性能影响 | 适用场景 |
| 模型量化 | 40-60% | 低 | 轻微 | 通用优化 |
| 智能缓存 | 30-50% | 中 | 正面 | 重复查询多 |
| 批处理优化 | 50-70% | 中 | 正面 | 高并发场景 |
| 自动扩缩容 | 20-40% | 高 | 无 | 负载波动大 |
| 预留实例 | 30-50% | 低 | 无 | 稳定负载 |
| Spot实例 | 60-80% | 高 | 可能中断 | 容错性强 |
4.4 ROI计算模型
class ROICalculator:"""投资回报率计算器"""def __init__(self):self.optimization_costs = {'development_time': 0, # 开发时间成本'infrastructure': 0, # 基础设施成本'maintenance': 0 # 维护成本}self.benefits = {'cost_savings': 0, # 成本节省'performance_gain': 0, # 性能提升价值'user_satisfaction': 0 # 用户满意度提升价值}def calculate_roi(self, time_period_months: int = 12) -> Dict:"""计算ROI"""total_investment = sum(self.optimization_costs.values())total_benefits = sum(self.benefits.values()) * time_period_monthsroi_percentage = ((total_benefits - total_investment) / total_investment) * 100payback_period = total_investment / (sum(self.benefits.values()) or 1)return {'roi_percentage': roi_percentage,'payback_period_months': payback_period,'total_investment': total_investment,'annual_benefits': sum(self.benefits.values()) * 12,'net_present_value': total_benefits - total_investment}# 使用示例
roi_calc = ROICalculator()
roi_calc.optimization_costs = {'development_time': 50000, # 5万元开发成本'infrastructure': 10000, # 1万元基础设施'maintenance': 5000 # 5千元维护成本
}roi_calc.benefits = {'cost_savings': 8000, # 每月节省8千元'performance_gain': 3000, # 性能提升价值3千元/月'user_satisfaction': 2000 # 用户满意度价值2千元/月
}roi_result = roi_calc.calculate_roi(12)
print(f"ROI: {roi_result['roi_percentage']:.1f}%")
print(f"回本周期: {roi_result['payback_period_months']:.1f}个月")5. 性能优化最佳实践
5.1 优化实施路线图

图3:性能优化实施甘特图
5.2 监控告警配置
class AlertManager:"""告警管理器"""def __init__(self):self.alert_rules = {'high_latency': {'threshold': 2.0,'duration': 300, # 5分钟'severity': 'warning'},'low_throughput': {'threshold': 100,'duration': 600, # 10分钟'severity': 'critical'},'high_cost': {'threshold': 1000, # 每小时成本超过1000元'duration': 3600, # 1小时'severity': 'warning'}}def check_alerts(self, metrics: Dict) -> List[Dict]:"""检查告警条件"""alerts = []# 检查延迟告警if metrics.get('avg_latency', 0) > self.alert_rules['high_latency']['threshold']:alerts.append({'type': 'high_latency','message': f"平均延迟过高: {metrics['avg_latency']:.2f}s",'severity': self.alert_rules['high_latency']['severity'],'timestamp': time.time()})# 检查吞吐量告警if metrics.get('throughput', 0) < self.alert_rules['low_throughput']['threshold']:alerts.append({'type': 'low_throughput','message': f"吞吐量过低: {metrics['throughput']} QPS",'severity': self.alert_rules['low_throughput']['severity'],'timestamp': time.time()})return alerts# 性能优化检查清单
OPTIMIZATION_CHECKLIST = {"模型优化": ["✓ 实施动态量化","✓ 配置批处理推理","✓ 启用JIT编译","□ 实施模型剪枝","□ 部署知识蒸馏"],"缓存优化": ["✓ 部署多层缓存","✓ 配置Redis集群","□ 实施预热策略","□ 优化缓存键设计"],"并发优化": ["✓ 实施连接池","✓ 配置限流策略","□ 部署熔断器","□ 优化线程池"],"成本优化": ["✓ 部署成本监控","□ 实施自动扩缩容","□ 配置预留实例","□ 优化资源调度"]
}"性能优化不是一次性的工作,而是一个持续改进的过程。只有建立完善的监控体系和优化流程,才能确保系统长期稳定高效运行。" —— 性能优化专家
6. 测评体系与效果验证
6.1 性能测试框架
import asyncio
import aiohttp
import time
import statistics
from typing import List, Dictclass PerformanceTestSuite:"""性能测试套件"""def __init__(self, base_url: str):self.base_url = base_urlself.results = []async def load_test(self, concurrent_users: int = 100,duration_seconds: int = 60,ramp_up_seconds: int = 10) -> Dict:"""负载测试"""print(f"开始负载测试: {concurrent_users}并发用户, 持续{duration_seconds}秒")# 渐进式增加负载tasks = []start_time = time.time()for i in range(concurrent_users):# 渐进式启动用户delay = (i / concurrent_users) * ramp_up_secondstask = asyncio.create_task(self._user_session(delay, duration_seconds))tasks.append(task)# 等待所有任务完成await asyncio.gather(*tasks)return self._analyze_results()async def _user_session(self, delay: float, duration: int):"""模拟用户会话"""await asyncio.sleep(delay)session_start = time.time()async with aiohttp.ClientSession() as session:while time.time() - session_start < duration:start_time = time.time()try:async with session.post(f"{self.base_url}/api/inference",json={"query": "测试查询", "model": "default"}) as response:await response.text()end_time = time.time()self.results.append({'response_time': end_time - start_time,'status_code': response.status,'timestamp': end_time,'success': response.status == 200})except Exception as e:end_time = time.time()self.results.append({'response_time': end_time - start_time,'status_code': 0,'timestamp': end_time,'success': False,'error': str(e)})# 模拟用户思考时间await asyncio.sleep(1)def _analyze_results(self) -> Dict:"""分析测试结果"""if not self.results:return {}response_times = [r['response_time'] for r in self.results]success_count = sum(1 for r in self.results if r['success'])total_requests = len(self.results)return {'total_requests': total_requests,'successful_requests': success_count,'failed_requests': total_requests - success_count,'success_rate': (success_count / total_requests) * 100,'avg_response_time': statistics.mean(response_times),'median_response_time': statistics.median(response_times),'p95_response_time': statistics.quantiles(response_times, n=20)[18],'p99_response_time': statistics.quantiles(response_times, n=100)[98],'min_response_time': min(response_times),'max_response_time': max(response_times),'throughput_qps': total_requests / (max(r['timestamp'] for r in self.results) - min(r['timestamp'] for r in self.results))}# 使用示例
async def run_performance_test():test_suite = PerformanceTestSuite("http://localhost:8000")results = await test_suite.load_test(concurrent_users=50,duration_seconds=30)print("性能测试结果:")for key, value in results.items():print(f"{key}: {value}")6.2 性能评分体系
| 评分维度 | 权重 | 优秀(90-100) | 良好(70-89) | 一般(50-69) | 较差(<50) |
| 响应延迟 | 30% | <1s | 1-2s | 2-5s | >5s |
| 系统吞吐量 | 25% | >1000 QPS | 500-1000 QPS | 100-500 QPS | <100 QPS |
| 资源利用率 | 20% | 80-90% | 70-80% | 50-70% | <50% |
| 成本效益 | 15% | <$0.01/req | $0.01-0.05/req | $0.05-0.1/req | >$0.1/req |
| 稳定性 | 10% | 99.9%+ | 99.5-99.9% | 99-99.5% | <99% |
class PerformanceScorer:"""性能评分器"""def __init__(self):self.weights = {'latency': 0.30,'throughput': 0.25,'resource_utilization': 0.20,'cost_efficiency': 0.15,'stability': 0.10}def calculate_score(self, metrics: Dict) -> Dict:"""计算综合性能评分"""scores = {}# 延迟评分latency = metrics.get('avg_response_time', 0)if latency < 1.0:scores['latency'] = 95elif latency < 2.0:scores['latency'] = 80elif latency < 5.0:scores['latency'] = 60else:scores['latency'] = 30# 吞吐量评分throughput = metrics.get('throughput_qps', 0)if throughput > 1000:scores['throughput'] = 95elif throughput > 500:scores['throughput'] = 80elif throughput > 100:scores['throughput'] = 60else:scores['throughput'] = 30# 资源利用率评分cpu_util = metrics.get('cpu_utilization', 0)if 80 <= cpu_util <= 90:scores['resource_utilization'] = 95elif 70 <= cpu_util < 80:scores['resource_utilization'] = 80elif 50 <= cpu_util < 70:scores['resource_utilization'] = 60else:scores['resource_utilization'] = 30# 成本效益评分cost_per_req = metrics.get('cost_per_request', 0)if cost_per_req < 0.01:scores['cost_efficiency'] = 95elif cost_per_req < 0.05:scores['cost_efficiency'] = 80elif cost_per_req < 0.1:scores['cost_efficiency'] = 60else:scores['cost_efficiency'] = 30# 稳定性评分success_rate = metrics.get('success_rate', 0)if success_rate >= 99.9:scores['stability'] = 95elif success_rate >= 99.5:scores['stability'] = 80elif success_rate >= 99.0:scores['stability'] = 60else:scores['stability'] = 30# 计算加权总分total_score = sum(scores[metric] * self.weights[metric] for metric in scores)return {'individual_scores': scores,'total_score': total_score,'grade': self._get_grade(total_score)}def _get_grade(self, score: float) -> str:"""获取等级"""if score >= 90:return 'A'elif score >= 80:return 'B'elif score >= 70:return 'C'elif score >= 60:return 'D'else:return 'F'总结
作为一名在AI领域深耕多年的技术博主摘星,通过本文的深入探讨,我希望能够为读者提供一套完整的智能体性能优化方法论。在我的实践经验中,我深刻体会到性能优化并非一蹴而就的工程,而是需要系统性思考和持续改进的过程。从性能瓶颈的精准识别到模型推理的深度优化,从多层缓存架构的设计到并发控制的精细化管理,每一个环节都需要我们投入足够的关注和专业的技术手段。特别是在成本控制方面,我发现很多团队往往在项目初期忽视了成本效益分析,导致后期运营成本居高不下,这不仅影响了项目的可持续发展,也制约了技术创新的空间。通过建立完善的监控体系、实施智能化的扩缩容策略、采用多维度的性能评估框架,我们能够在保证服务质量的前提下,实现成本的有效控制和性能的持续提升。在未来的AI应用发展中,随着模型规模的不断扩大和应用场景的日益复杂,性能优化将变得更加重要和具有挑战性。我相信,只有掌握了这些核心的优化技术和方法论,我们才能在激烈的技术竞争中保持领先优势,为用户提供更加优质、高效、经济的AI服务体验。
参考资料
- NVIDIA TensorRT Developer Guide
- PyTorch Performance Tuning Guide
- Redis Caching Best Practices
- Kubernetes Horizontal Pod Autoscaler
- Apache Kafka Performance Optimization
🌈 我是摘星!如果这篇文章在你的技术成长路上留下了印记:
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!