MySQL强化关键_020_SQL 优化
目 录
一、order by 优化
1.未添加索引
2.添加索引
3.复合索引默认升序排列
4.复合索引降序排列
5.复合索引升序降序排列并用
6.总结
二、group by 优化
1.未添加索引
2.添加索引
3.添加复合索引
三、limit 优化
四、主键优化
1.主键设计原则
五、insert 优化
1.原则
2.load
六、count 优化
七、update 优化
1.说明
2.行级锁
(1)修改同一条记录
(2)修改不同记录
3.表级锁
一、order by 优化
# 初始化
drop table if exists t_workers;
create table t_workers(id int primary key auto_increment,name varchar(10),age int,sal int
);
insert into t_workers(name, age, sal) values('王栋梁', 18, 3000),('李建', 23, 5000),('张昊晟', 31, 2500);
- 使用【explain】查看带有【order by】语句的执行计划时,【Extra】字段会显示 using index 或 using filesort。区别如下:
- using index:表示使用索引,因为索引提前排好序,所以效率很高;
- using filesort:表示使用文件排序,排序时将硬盘中的数据读取到内存中,在内存中排序,效率较低。
- 初始化中的实例如下。
1.未添加索引
-- 未添加索引,根据name进行文件排序,效率较低
explain select id, name from t_workers order by name;

2.添加索引
-- 创建索引,效率提高
create index index_tworkers_name on t_workers(name);
explain select id, name from t_workers order by name;
3.复合索引默认升序排列
-- 若需要通过两个字段排序,建议添加复合索引。按照age升序排,age相同按照sal升序
create index index_tworkers_as on t_workers(age, sal);
explain select id, age, sal from t_workers order by age, sal;
4.复合索引降序排列
B+树叶子结点上所有数据默认升序排列。添加联合索引,若按照 age 降序排列,age 相同则按照 sal 降序排列,会使用索引吗?
explain select id, age, sal from t_workers order by age desc, sal desc;
答案是会的,可以看到进行了 反向索引扫描。
B+树叶子节点之间采用双向指针,可以从左向右升序,也可以从右往左降序。
5.复合索引升序降序排列并用
-- age升序,sal降序
explain select id, age, sal from t_workers order by age asc, sal desc;
可以看到 age 使用了索引,而 sal 没有使用索引。
但是,可以创建对应的指定排序索引解决此问题。
-- 创建指定排序索引
create index index_tworkers_as2 on t_workers(age asc, sal desc);
explain select id, age, sal from t_workers order by age asc, sal desc;
6.总结
排序也遵循最左前缀原则;
使用覆盖索引;
针对不同排序规则,创建不同索引。若所有字段都是升序或都是降序,则不需要创建指定排序索引;
若无法避免 filesort,要注意排序缓存大小,默认缓存大小是 256KB,可以修改系统变量 sort_buffer_size。
二、group by 优化
# 初始化
drop table if exists t_employees;
create table t_employees(id int primary key auto_increment,name varchar(10),age int,gender varchar(2),job varchar(10)
);
insert into t_employees(name, age, gender, job) values('刘佳佳', 21, '女', '业务员'),('王平', 23, '男', '业务员'),('郭东', 37, '男', '业务员'),('张筱雨', 32, '女', '经理'),('马菲燕', 45, '女', '经理'),('张强', 52, '男', '安保'),('寇爱国', 49, '男', '安保'),('邱政琪', 38, '男', '会计');1.未添加索引
explain select job, count(*) from t_employees group by job;
可以看到,使用了临时表,效率较低。
2.添加索引
create index index_temployees_job on t_employees(job);
explain select job, count(*) from t_employees group by job;
3.添加复合索引
create index index_temployees_aj on t_employees(job, age);
explain select age, count(*) from t_employees group by age;
explain select age, count(*) from t_employees where job = '经理' group by age;

可以看到,group by 也遵循最左前缀原则。
三、limit 优化
数据量特别庞大时,使用 limit 读取数据时,越往后效率越低。可以使用【覆盖索引 + 子查询】的方式提升效率。
四、主键优化
1.主键设计原则
- 主键值不要太长,二级索引叶子结点上存储的是主键值。主键值太长会导致索引占用空间较大;
- 尽量使用【auto_increment】生成主键,尽量不使用 uuid 作为主键,因为 uuid 不是顺序插入;
- 插入数据时,主键值尽量顺序插入,因为乱序插入可能会导致 B+树 的叶子结点频繁进行页分裂和页合并操作,效率较低。
- 在 InnoDB 中,主键值对应聚集索引,插入主键值如果是乱序的,B+树叶子结点需要不断重新排序,重新排序过程中频繁涉及页分裂和页合并操作,效率较低;
- B+树每个结点都存储在页中,一个页面中存储一个结点;
- MySQL 的 InnoDB 存储引擎,一个页可以存储 16KB 的数据;
若主键值不是顺序插入,就会导致频繁的页分裂和页合并。在一个B+树中,页分裂和页合并是树自动调整机制的一部分。当一个页已经满了,再插入一个新的关键字时就会触发页分裂操作,将页中的关键字分配到两个新的页中,同时调整树的结构。相反,当一个页中的关键字数量下降到一个阈值以下时,就会触发页合并操作,将两个相邻的页合并成一个新的页。如果主键值是随机的、不是顺序插入的,那么页的利用率会降低,页分裂和页合并的次数就会增加。由于页的分裂和合并是比较耗时的操作,频繁的分裂和合并会降低数据库系统的性能。因此,为了优化B+树的性能,可以将主键值设计成顺序插入的,这样可以减少页的分裂和合并的次数,提高B+树的性能。在实际应用中,如果对主键值的顺序性能要求不是特别高,也可以采用一些技术手段来减少页分裂和合并,例如B+树分裂时采用“延迟分裂”技术,或者通过调整页的大小和结点的大小等方式来优化B+树的性能。
尽量不使用业务主键,因为业务的变化会导致主键值频繁修改。不建议主键值修改,因为主键值修改,聚集索引一定会重新排序。
五、insert 优化
1.原则
- 数据量较大时,可以批量插入。建议一次插入数据不超过 1000 条;
- MySQL 默认自动提交事务,只要执行一条 DML 语句就会自动提交一次。因此,当插入大量数据时,建议手动开启事务和手动提交事务;
- 主键值建议顺序插入,效率较高;
- 超大数据量插入可以考虑使用 load 命令,可以将 csv 文件中的数据批量导入到数据库表中,效率较高。每个字段间使用 “,” 隔开,每条数据另起一行。
2.load
# 1.登录MySQL时指定参数
mysql --local-infile -u[用户名] -p[密码]# 2.开启local_infile功能
set global local_infile = 1;# 3.执行load指令
-- 首先,创建表
load data local infile '文件存放路径' into table [表名] fields terminated by ',' lines terminated by '\n';六、count 优化
- 使用:
- count(主键):将每个主键值取出累加;
- count(常量值):获取每个常量值累加;
- count(字段):取出字段的每个值,判断是否为 NULL,不为 NULL则累加;
- count(*):不取值,直接统计总行数,效率最高。若统计一张表中总行数,建议使用。
- 注意:
- 对于 InnoDB 存储引擎,count 计数实现原理就是将表中每一条数据取出,然后累加。若想真正提高效率,可以使用其他程序实现;
- 对于 MyISAM 存储引擎,当一个 select 语句没有 where 条件时,获取总行数效率极高,不需要统计,因为 MyISAM 存储引擎单独维护了一个总行数。
七、update 优化
1.说明
- 存储引擎是 InnoDB 时,表的行级锁是针对索引添加的锁,若索引失效或不是索引列时,会提升为表级锁;
- 行级锁:有 A、B 两个事务,开启 A 事务后,通过 A 事务修改表中某条记录。修改后未提交,B 事务去修改同一条记录时无法继续,直到 A 事务提交,B 事务才可以继续;
- 为了提高效率,建议为 update 语句中的 where 条件添加索引。
2.行级锁
(1)修改同一条记录
行级锁,A 事务修改未提交,B 事务修改同一条记录,会无法继续执行。
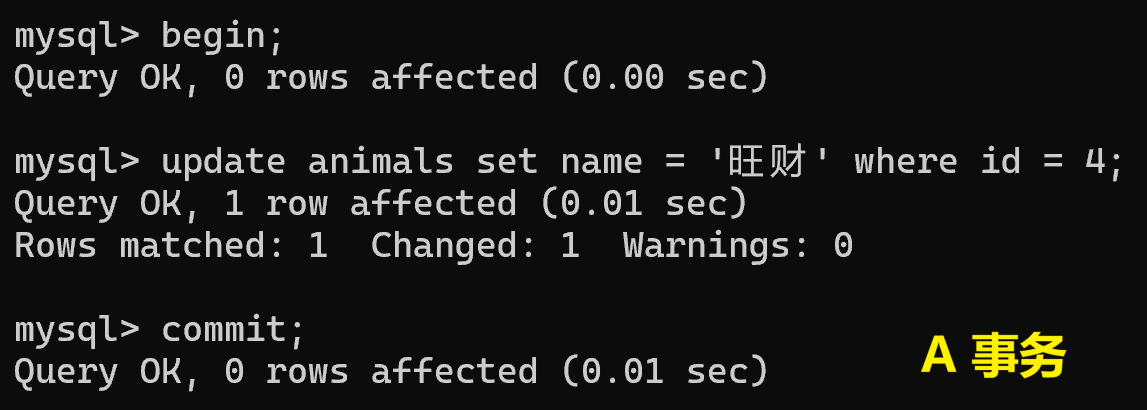

(2)修改不同记录
行级锁,A 事务修改未提交,B 事务修改其他记录,不会影响。


3.表级锁
条件为非索引列或索引失效会升级为表级锁。表级锁,A 事务修改未提交。B 事务无论修改哪一条记录,都不会继续执行。

![]()