每日八股文6.8
每日八股-6.8
- Redis
- 1.Redis的RDB了解过吗?
- 2.你能简单描述一下 RDB 的执行流程是怎样的吗?
- 3.Redis 支持哪些常用的数据类型呢?/ Redis常用的数据结构了解哪些呢?
- 4.Redis 的 Hash数据结构了解吗?
- 5.渐进式扩容了解过吗?/HashTable 是怎么扩容的?
- 6.Redis 的跳表(Skiplist)是一种什么样的结构?
Redis
1.Redis的RDB了解过吗?
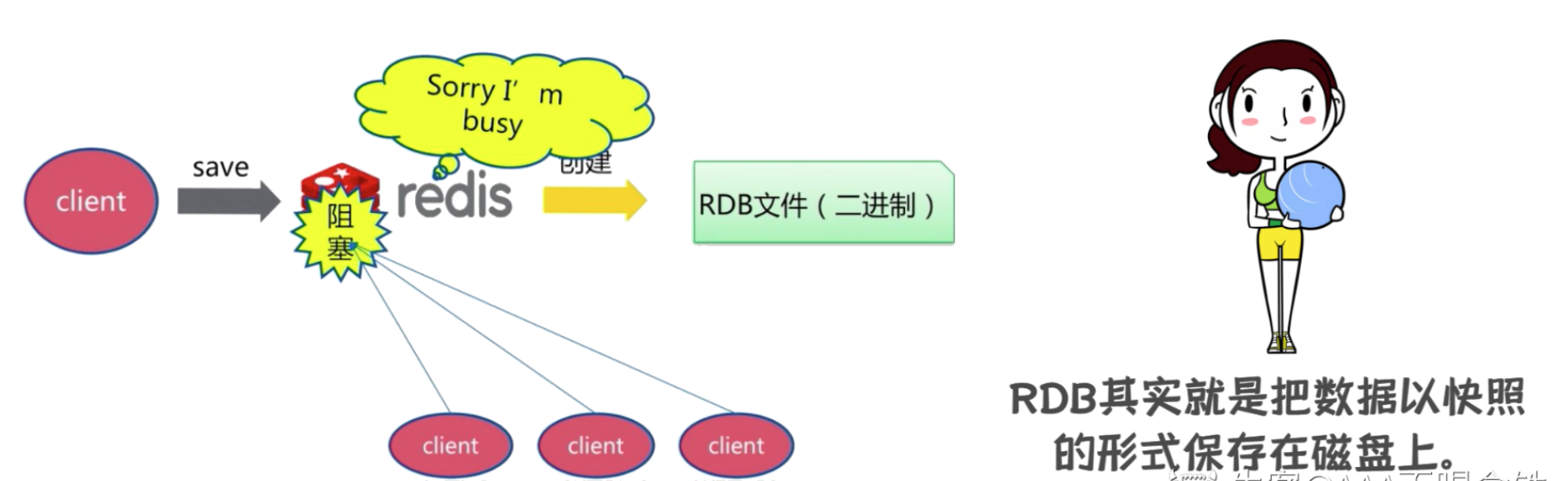
Redis的RDB的本质是一个数据快照,以二进制文件的形式存储,他记录的是某一时刻redis数据库的状态,记录了所有键值对。
生成 RDB 文件主要有两种方式:
-
SAVE (同步保存):
- 触发方式:由客户端直接执行 SAVE 命令。
- 过程:如上图所示,由 Redis 主进程负责写入 RDB 文件,期间会阻塞所有其他请求。
- 适用场景:基本不用于生产环境。只在没有客户端连接,或者可以接受服务暂停时(比如维护、迁移前)手动执行。
-
BGSAVE (异步保存):
- 触发方式:客户端直接执行 BGSAVE 命令。
- 过程:这是 Redis 推荐的方式。Redis 主进程会 fork() 一个子进程,让子进程去负责生成 RDB 文件,而主进程可以继续处理客户端的请求,避免了长时间的阻塞。
- 适用场景:绝大多数生产环境的默认选择。
RDB 的优缺点
-
优点:
- 恢复速度快: RDB 文件是一个紧凑的二进制文件,里面存储的是某个时间点的数据本身。在 Redis 重启时,可以直接将这个文件加载到内存中,恢复速度远快于需要逐条执行命令的 AOF。
- 文件体积小: 经过压缩的二进制格式,相比于记录命令的 AOF 文件,体积更小,便于备份和网络传输。
-
缺点:
- 数据丢失风险高: RDB 是间隔性地进行快照。如果在上一次快照之后、下一次快照之前,Redis 服务器发生宕机,那么这期间所有被修改但尚未保存的数据都将全部丢失。
2.你能简单描述一下 RDB 的执行流程是怎样的吗?
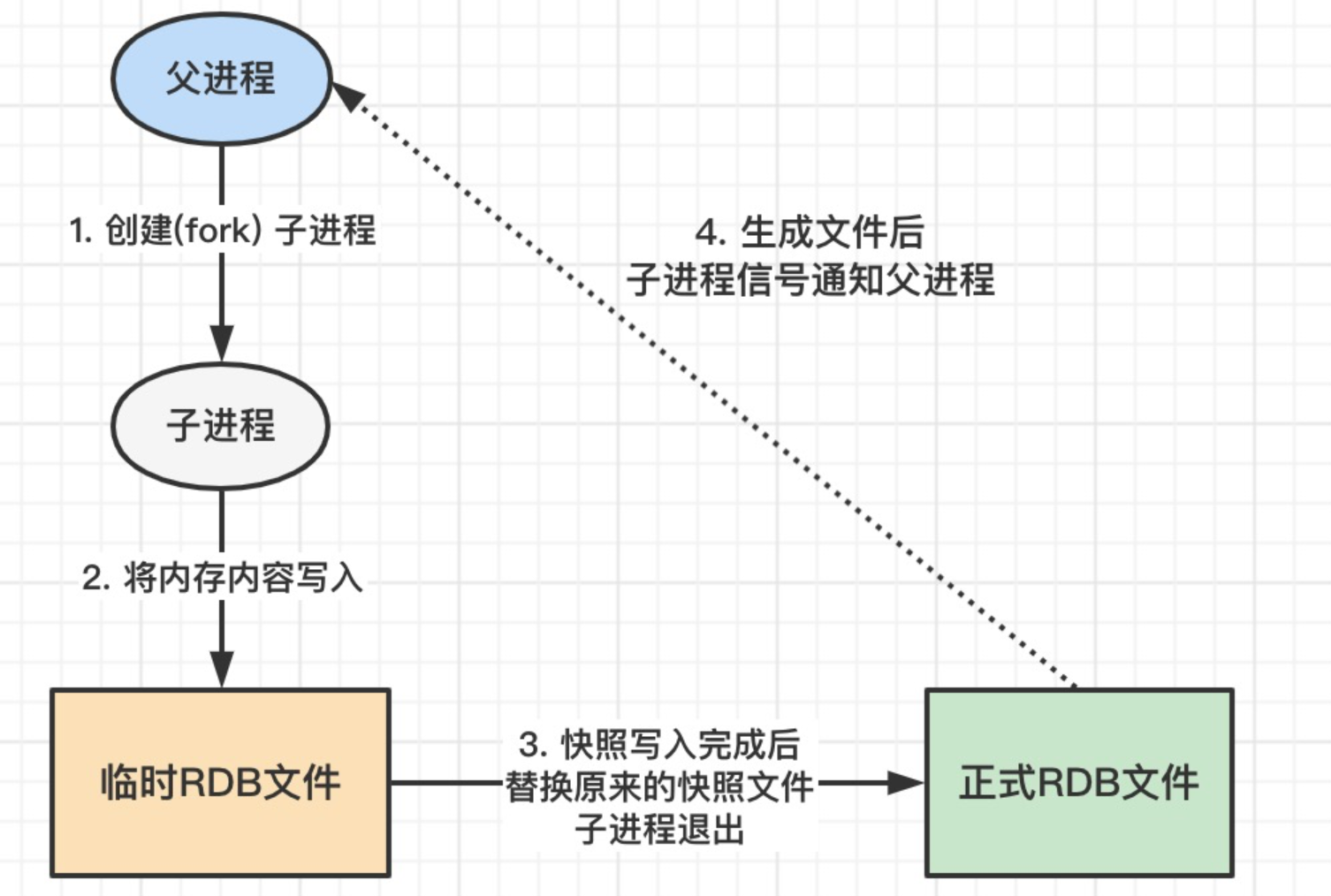
生成rdb文件主要有两种方式,下面分别进行介绍。
SAVE 命令 (同步阻塞)
- Redis 主进程接收到 SAVE 命令,开始执行持久化。
- 在持久化期间,主进程完全阻塞,无法处理任何其他客户端请求。
- 主进程将数据写入 RDB 文件,完成后用新文件替换旧文件。
- 持久化结束,主进程解除阻塞,恢复服务。
BGSAVE 命令 (异步非阻塞)
- Redis 主进程 fork 一个子进程,fork 后主进程继续处理客户端请求。
- 子进程负责将内存数据写入一个临时的 RDB 文件。
- 子进程完成写入后,用这个新的临时文件替换掉旧的 RDB 文件。
- 子进程退出,整个持久化过程结束,全程几乎不影响主进程。
3.Redis 支持哪些常用的数据类型呢?/ Redis常用的数据结构了解哪些呢?
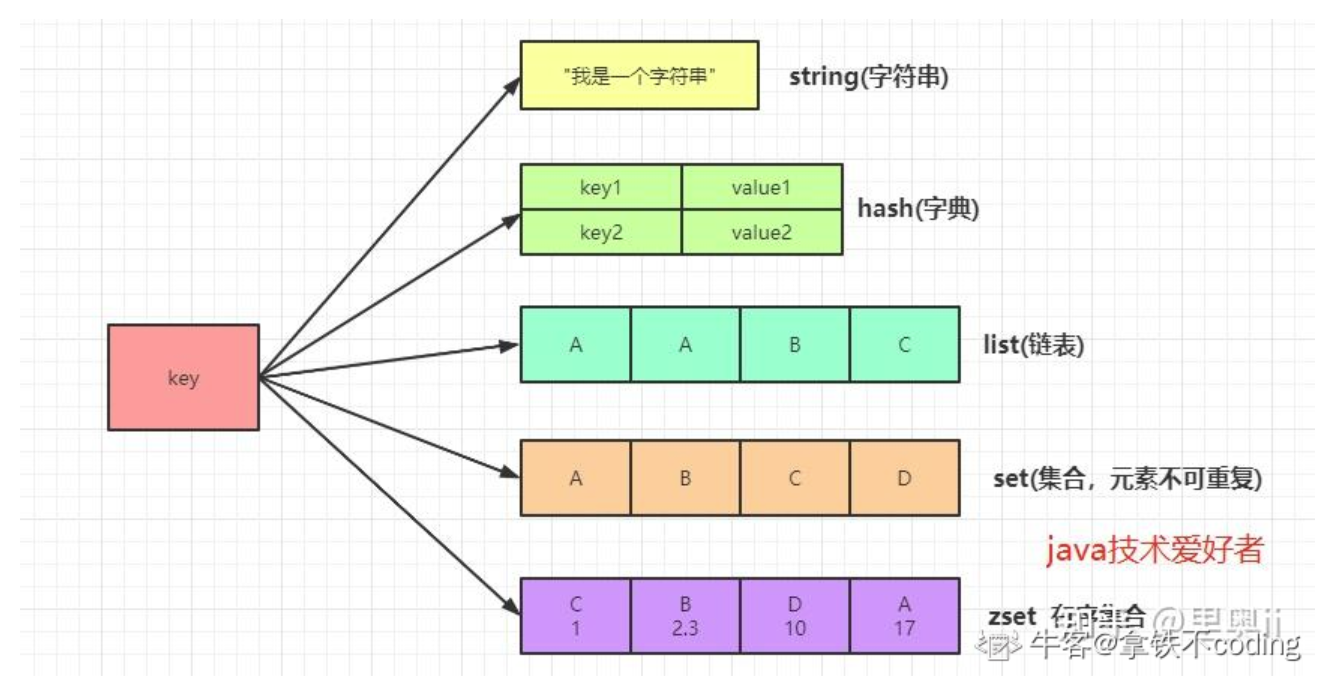
Redis 支持多种数据类型,最常用的有以下五种:
- String(字符串): 这是最基本的数据类型,可以存储文本、数字或者二进制数据,单个 value 的最大容量是 512MB。常用于缓存对象、常规计数、实现分布式锁等。
- Hash(哈希): 类似于 Map,存储键值对的集合,适合存储对象,可以方便地对对象的属性进行修改,常用于缓存对象、实现购物车等。
- List(列表): 是一个有序的字符串列表,支持在列表的两端进行添加和删除操作,常用于实现消息队列等。
- Set(集合): 是一个无序且唯一的字符串集合,常用于做一些集合操作,比如求交集、并集、差集,可以应用于点赞、共同关注等场景。
- Zset(有序集合): 在 Set 的基础上为每个元素关联一个分数,可以根据分数进行排序,常用于实现排行榜等。
补充:在 Redis 中,所有的 key 都是二进制安全的 String 类型
4.Redis 的 Hash数据结构了解吗?
Redis 的 Hash 是一种 键值对集合,但与普通的键值对不同的是,Hash 中 每个键对应的值本身又是一个包含多个字段和值的键值对集合。可以把他想成一本书,外层的键对应的是书的名字,全局唯一,我们需要靠他来找到这本书;内层的键值对就像是书内的各个章节及对应的内容。
Redis 的 Hash 特点如下:
- 适合存储小数据:Hash 特别适合存储具有多个相关属性的小对象。
- 使用哈希表实现:底层通常使用哈希表(或压缩列表)实现,能够在内存中高效地存储和操作。
- 支持快速的字段操作:Redis 提供了针对 Hash 中字段的快速增、删、改、查操作,例如 HGET、HSET、HDEL 等,这使得它非常适合存储和管理对象的属性。
5.渐进式扩容了解过吗?/HashTable 是怎么扩容的?
Redis 的 HashTable 扩容采用了 渐进式 rehash 的策略,这是为了避免一次性扩容带来的性能卡顿,将扩容的开销平摊到后续的操作中。
当 HashTable 的 负载因子(used / size) 超过一定的阈值时,就会触发扩容。具体来说,触发条件有两个:
- 当服务器当前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 1 时。
- 当哈希表的负载因子大于等于 5 时,即使当前正在执行 BGSAVE (用来快照持久化)命令或者 BGREWRITEAOF(用来瘦身AOF文件) 命令,也会强制进行扩容。
补充:BGSAVE 和 BGREWRITEAOF 这两个命令本来就是内存密集型的,fork() 子进程会共享父进程的内存空间,如果此时再进行大规模的 rehash(也会分配新内存),可能会导致物理内存不足(OOM, Out-of-Memory),对系统造成巨大压力。因此,Redis 采取了更保守的策略,在后台持久化期间,将 rehash 的触发阈值从 1 提高到 5
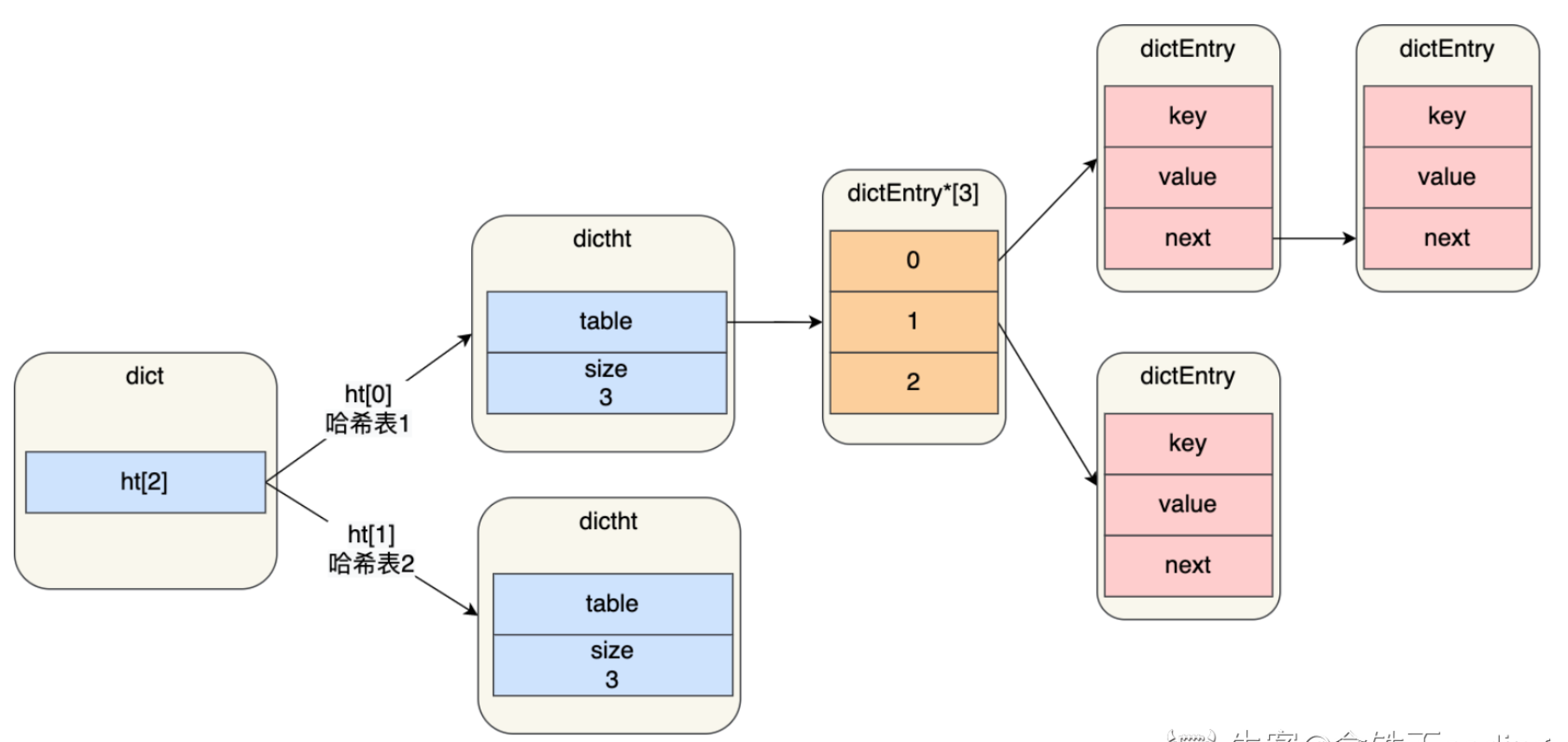
扩容的过程如下:
- Redis 会为 HashTable 的 1 号哈希表分配空间,这个新哈希表的大小通常是 第一个大于等于 0 号哈希表当前已使用节点(used)的两倍的 2 的整数次幂。
- Redis 会将 rehashidx 索引计数器设置为 0,表示开始进行 rehash 操作。
- 在 rehash 进行期间,每次对 HashTable 执行添加、删除、查找或者更新操作时,除了完成正常的操作外,还会顺带将 rehashidx 位置上的所有键值对从 0 号哈希表迁移到 1 号哈希表,并将 rehashidx 的值加 1。
- 随着时间的推移和操作的不断进行,0 号哈希表中的所有键值对都会被迁移到 1 号哈希表中。
- 当所有的键值对都迁移完毕后,Redis 会释放 0 号哈希表的空间,然后将 1 号哈希表设置为新的 0 号哈希表,并创建一个新的空的 1 号哈希表,最后将 rehashidx 的值设置为 -1,表示 rehash 操作完成。
在渐进式 rehash 期间,对 HashTable 的 CRUD 操作会有些特殊:
- 查询操作:会先在 0 号哈希表中查找,如果没找到,会继续在 1 号哈希表中查找。
- 写入操作:新的键值对会直接写入到 1 号哈希表中,这样可以保证 0 号哈希表中的数据只会减少不会增加,最终会变成空表。
- 删除操作:需要在 0 号和 1 号哈希表中都进行查找和删除。
通过这种渐进式 rehash 的方式,Redis 可以平滑地完成哈希表的扩容操作,避免了因为一次性大量数据迁移而导致服务出现明显的卡顿。
6.Redis 的跳表(Skiplist)是一种什么样的结构?
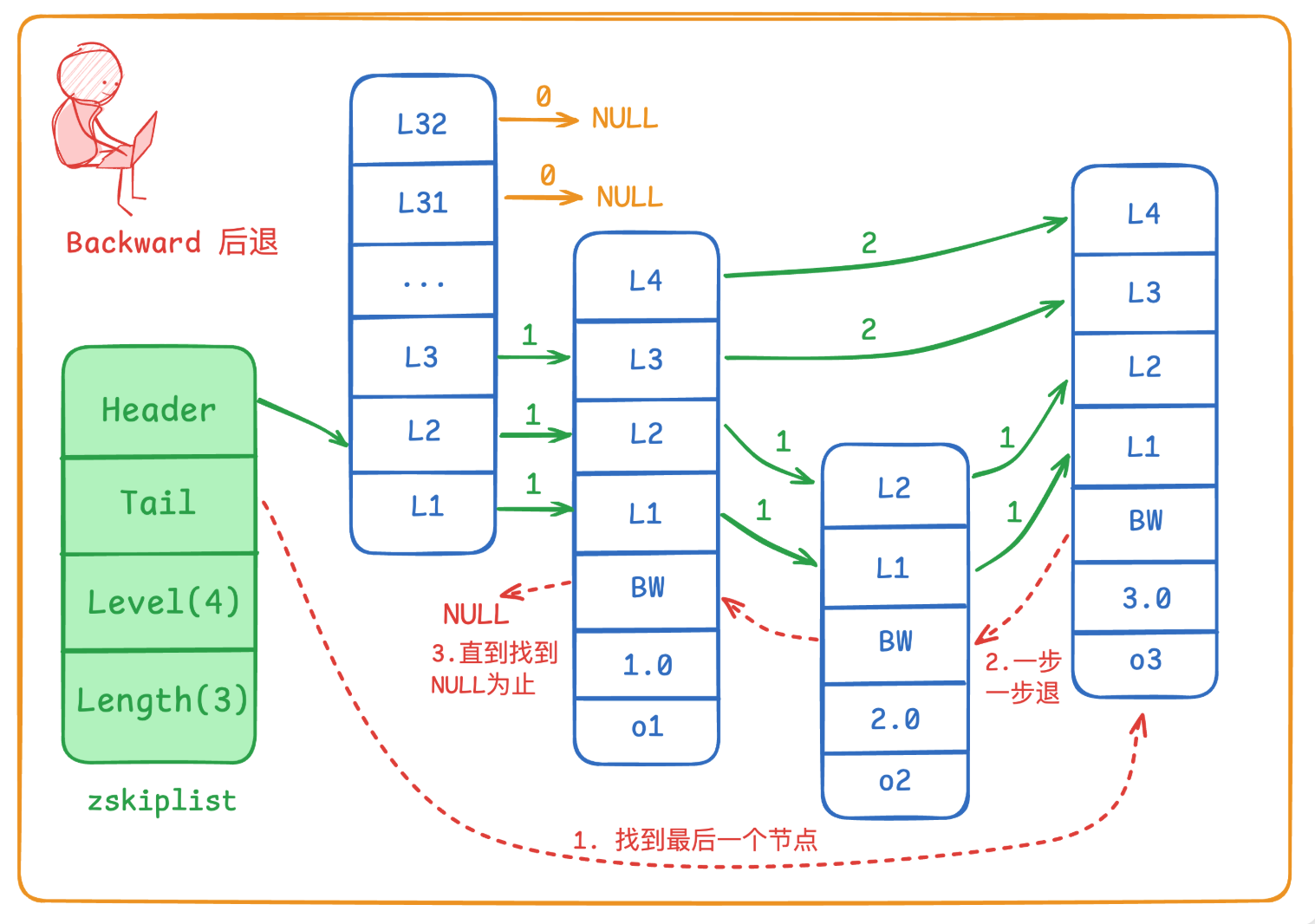
Redis 跳表:多级跳跃的有序链表
- 本质: 一种有序链表的升级版。
- 核心思想: 空间换时间。
- 如何优化: 在普通链表上加了多层“索引”。
- 底层是完整数据(有序链表)。
- 上层是稀疏的、跳跃式的索引。
- 层级越高,跳过的节点越多。
- 查找/增删: 从最顶层索引开始“跳”,快速定位,平均时间复杂度接近 O(logN)。
- 关键组成:
- 节点: 每个节点包含 数据、分值、和最重要的 层 数组(多个向前指针)。
- 层数组长度: 随机生成(决定节点参与多少层索引)。
- Redis 应用: 主要用于实现 ZSet(有序集合)。
补充:
7. zskiplist结构体包含Header、Tail、Level、Length四个属性,其中Header指向该层的第一个节点,Tail指向指向整个跳表中顺序上的最后一个节点,Level表示整个跳表当前的最大层数(不含头结点,在这里是4),Length表示跳表中节点的总个数(同样不包括头结点,这里是3)
- 图中的这些 L1、L2、L3 是跳表中 不同层级的前向指针,也可以理解为 索引层,用于加速搜索。每个节点会随机生成高度(层数)。
- 节点中的BW表示反向指针,除了header外每一个节点都有一个反向指针,支持从后往前遍历,可用来实现ZREVRANGE(倒序输出)。