【Agent零基础入门课程】告别黑盒:HelloAgents架构深度解析
本文目录标题
- 【Agent零基础入门课程】告别黑盒:HelloAgents架构深度解析
- 引言
- 核心架构:一张图看懂 HelloAgents
- 第一层:LLM抽象层 - 万物之基 `HelloAgentsLLM`
- 第二层:核心接口 - 框架的“标准与规范”
- 第三层:Agent逻辑层 - 思想的实现
- 第四层:工具系统 - 能力的延伸
- 总结
【Agent零基础入门课程】告别黑盒:HelloAgents架构深度解析
本文系Datawhale 11月组队学习的学习笔记,笔记内容参考自Datawhale组队学习——Agent零基础入门课程
引言
你是否也曾被 LangChain 等庞大框架的复杂性劝退?看着那层层封装的抽象,想改动一点内部逻辑却无从下手。它们很强大,但有时也像一个“黑盒”,让我们离底层原理越来越远。
如果你渴望真正理解Agent的工作流,想要一个轻量、透明、完全可控的框架作为学习和创新的起点,那么HelloAgents项目就是为你准备的。
这篇博客将基于Datawhale的hello-agents项目第七章,为你进行拆解。
核心架构:一张图看懂 HelloAgents
一个优秀的框架始于清晰的架构。HelloAgents 采用了分层解耦的设计,保证了各模块的高内聚、低耦合。
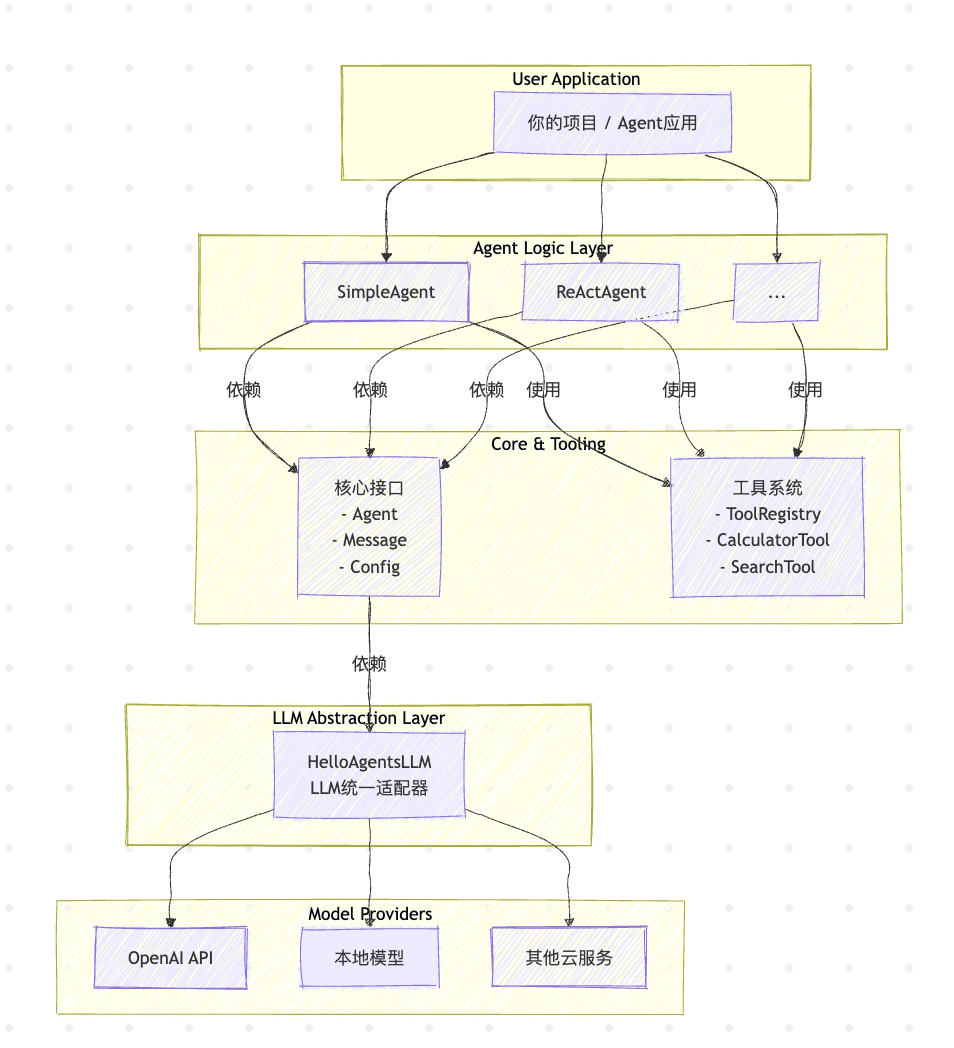
架构解读:
- 自上而下: 你的应用(
User Application)与具体的Agent逻辑(Agent Logic Layer)交互。 - 横向解耦: Agent的逻辑实现与工具系统(
Tool System)是分离的,Agent通过工具注册表(ToolRegistry)按需调用工具。 - 纵向依赖: 所有上层建筑都依赖于
核心接口(Core)提供的规范和LLM抽象层(LLM Abstraction)提供的统一模型调用能力。
接下来,我们将自底向上,逐层拆解这个架构。
第一层:LLM抽象层 - 万物之基 HelloAgentsLLM
一切Agent的智能都源于LLM。但现实是,模型服务五花八门,API各不相同。如果业务代码直接与某个特定API绑定,未来切换模型的成本将是灾难性的。
HelloAgentsLLM 的存在就是为了解决这个问题。它是一个适配器(Adapter),为上层应用提供了一个稳定、统一的调用接口,同时将底层不同模型API的差异完全屏蔽。
它解决了一个非常实际的痛点:环境配置。开发者无需在代码中硬编码Key或URL,框架会智能地根据环境变量决定使用哪个模型。
为了尽可能减少用户的配置负担并遵循“约定优于配置”的原则,HelloAgentsLLM 内部设计了两个核心辅助方法:_auto_detect_provider 和 _resolve_credentials。它们协同工作,_auto_detect_provider 负责根据环境信息推断服务商,而 _resolve_credentials 则根据推断结果完成具体的参数配置。
_auto_detect_provider 方法负责根据环境信息,按照下述优先级顺序,尝试自动推断服务商:
最高优先级:检查特定服务商的环境变量 这是最直接、最可靠的判断依据。框架会依次检查 MODELSCOPE_API_KEY, OPENAI_API_KEY, ZHIPU_API_KEY 等环境变量是否存在。一旦发现任何一个,就会立即确定对应的服务商。
次高优先级:根据 base_url 进行判断 如果用户没有设置特定服务商的密钥,但设置了通用的 LLM_BASE_URL,框架会转而解析这个 URL。
域名匹配:通过检查 URL 中是否包含 "api-inference.modelscope.cn", "api.openai.com" 等特征字符串来识别云服务商。
端口匹配:通过检查 URL 中是否包含 :11434 (Ollama), :8000 (VLLM) 等本地服务的标准端口来识别本地部署方案。
辅助判断:分析 API 密钥的格式 在某些情况下,如果上述两种方式都无法确定,框架会尝试分析通用环境变量 LLM_API_KEY 的格式。例如,某些服务商的 API 密钥有固定的前缀或独特的编码格式。不过,由于这种方式可能存在模糊性(例如多个服务商的密钥格式相似),因此它的优先级较低,仅作为辅助手段。
def _auto_detect_provider(self, api_key: Optional[str], base_url: Optional[str]) -> str:"""自动检测LLM提供商"""# 1. 检查特定提供商的环境变量 (最高优先级)if os.getenv("MODELSCOPE_API_KEY"): return "modelscope"if os.getenv("OPENAI_API_KEY"): return "openai"if os.getenv("ZHIPU_API_KEY"): return "zhipu"# ... 其他服务商的环境变量检查# 获取通用的环境变量actual_api_key = api_key or os.getenv("LLM_API_KEY")actual_base_url = base_url or os.getenv("LLM_BASE_URL")# 2. 根据 base_url 判断if actual_base_url:base_url_lower = actual_base_url.lower()if "api-inference.modelscope.cn" in base_url_lower: return "modelscope"if "open.bigmodel.cn" in base_url_lower: return "zhipu"if "localhost" in base_url_lower or "127.0.0.1" in base_url_lower:if ":11434" in base_url_lower: return "ollama"if ":8000" in base_url_lower: return "vllm"return "local" # 其他本地端口# 3. 根据 API 密钥格式辅助判断if actual_api_key:if actual_api_key.startswith("ms-"): return "modelscope"# ... 其他密钥格式判断# 4. 默认返回 'auto',使用通用配置return "auto"一旦 provider 被确定(无论是用户指定还是自动检测),_resolve_credentials 方法便会接手处理服务商的差异化配置。它会根据 provider 的值,去主动查找对应的环境变量,并为其设置默认的 base_url。其部分关键实现如下:
def _resolve_credentials(self, api_key: Optional[str], base_url: Optional[str]) -> tuple[str, str]:"""根据provider解析API密钥和base_url"""if self.provider == "openai":resolved_api_key = api_key or os.getenv("OPENAI_API_KEY") or os.getenv("LLM_API_KEY")resolved_base_url = base_url or os.getenv("LLM_BASE_URL") or "https://api.openai.com/v1"return resolved_api_key, resolved_base_urlelif self.provider == "modelscope":resolved_api_key = api_key or os.getenv("MODELSCOPE_API_KEY") or os.getenv("LLM_API_KEY")resolved_base_url = base_url or os.getenv("LLM_BASE_URL") or "https://api-inference.modelscope.cn/v1/"return resolved_api_key, resolved_base_url# ... 其他服务商的逻辑
第二层:核心接口 - 框架的“标准与规范”
这一层定义了框架的“语言”和“契约”。
-
Message: 数据标准。它将所有类型的消息(system,user,assistant,tool)都规范为统一的数据结构。这保证了框架内部数据流的清晰性,并且天然兼容OpenAI的API格式。 -
Config: 配置标准。将temperature、debug等可变配置项集中管理,实现了配置与逻辑的分离。 -
Agent(Abstract Base Class): 行为契约。这是整个Agent体系的顶层设计。通过定义一个抽象基类,它强制所有具体的Agent子类(如SimpleAgent,ReActAgent)都必须实现run方法。这不仅仅是代码复用,更是面向对象设计中“依赖倒置原则”的体现。上层应用依赖于
Agent这个抽象,而不是某个具体的Agent实现,这使得框架极易扩展。
Agent基类的设计是框架扩展性的关键。注意@abstractmethod装饰器,它就是那个“契约”。
from abc import ABC, abstractmethod
from typing import List
from ..llm.llm import HelloAgentsLLM
from ..core.message import Messageclass Agent(ABC):"""Agent抽象基类,定义了Agent的核心接口和通用能力。"""def __init__(self, llm: HelloAgentsLLM, system_prompt: str = None, ...):self.llm = llmself.history: List[Message] = []# ... 初始化逻辑 ...if system_prompt:self.add_message("system", system_prompt)def add_message(self, role: str, content: str):# ... 添加消息到history ...@abstractmethoddef run(self, query: str, **kwargs) -> str:"""所有Agent子类必须实现的执行入口。这是框架与Agent交互的唯一契约。"""pass
第三层:Agent逻辑层 - 思想的实现
这里是框架的“大脑”,实现了不同的工作范式。我们以最核心的ReActAgent为例。
ReAct模式的本质,是让LLM通过“Thought -> Action -> Observation”的循环来与外部世界(工具)互动,从而解决复杂问题。
这个模式能否成功的关键,在于Prompt——它相当于我们与LLM之间签订的工作协议(Protocol)。这个协议必须清晰地告诉LLM它的可用工具、工作流程以及输出格式。
ReAct的系统提示词是工程的精髓。与【Agent零基础入门课程】手搓AI智能体:30行代码带你玩转ReAct、Plan-and-Solve与Reflection所设计的提示词不同,框架化的版本采用了通用化设计,使其适用于文本生成、分析、创作等多种场景,并通过custom_prompts参数支持用户深度定制。
MY_REACT_PROMPT = """你是一个具备推理和行动能力的AI助手。你可以通过思考分析问题,然后调用合适的工具来获取信息,最终给出准确的答案。## 可用工具
{tools}## 工作流程
请严格按照以下格式进行回应,每次只能执行一个步骤:Thought: 分析当前问题,思考需要什么信息或采取什么行动。
Action: 选择一个行动,格式必须是以下之一:
- `{{tool_name}}[{{tool_input}}]` - 调用指定工具
- `Finish[最终答案]` - 当你有足够信息给出最终答案时## 重要提醒
1. 每次回应必须包含Thought和Action两部分
2. 工具调用的格式必须严格遵循:工具名[参数]
3. 只有当你确信有足够信息回答问题时,才使用Finish
4. 如果工具返回的信息不够,继续使用其他工具或相同工具的不同参数## 当前任务
**Question:** {question}## 执行历史
{history}现在开始你的推理和行动:
"""第四层:工具系统 - 能力的延伸
如果说LLM是决策者,工具就是执行者。HelloAgents的工具系统设计得非常漂亮,完美体现了**“开闭原则”**——对扩展开放,对修改关闭。
Tool基类: 定义了所有工具的接口规范。任何想接入系统的工具,只需继承这个基类并实现相应方法即可。ToolRegistry: 扮演着 服务调度中心(Dispatcher)**的角色。它负责:- 注册: 在系统启动时,收集所有可用的工具。
- 生成描述: 自动将所有工具的
name和description整合成文本,用于填充上面ReAct提示词中的{tools_text}。 - 执行: 当LLM生成
Action时,ToolRegistry根据tool_name精确地调用对应工具的执行方法,并将结果返回。
class Tool(ABC):"""工具基类"""def __init__(self, name: str, description: str):self.name = nameself.description = description@abstractmethoddef run(self, parameters: Dict[str, Any]) -> str:"""执行工具"""pass@abstractmethoddef get_parameters(self) -> List[ToolParameter]:"""获取工具参数定义"""pass
class ToolRegistry:"""HelloAgents工具注册表"""def __init__(self):self._tools: dict[str, Tool] = {}self._functions: dict[str, dict[str, Any]] = {}def register_tool(self, tool: Tool):"""注册Tool对象"""if tool.name in self._tools:print(f"⚠️ 警告:工具 '{tool.name}' 已存在,将被覆盖。")self._tools[tool.name] = toolprint(f"✅ 工具 '{tool.name}' 已注册。")def register_function(self, name: str, description: str, func: Callable[[str], str]):"""直接注册函数作为工具(简便方式)Args:name: 工具名称description: 工具描述func: 工具函数,接受字符串参数,返回字符串结果"""if name in self._functions:print(f"⚠️ 警告:工具 '{name}' 已存在,将被覆盖。")self._functions[name] = {"description": description,"func": func}print(f"✅ 工具 '{name}' 已注册。")总结
通过这次自底向上的架构拆解,我们应该能清晰地看到HelloAgents如何通过分层、抽象和设计模式,构建出一个简洁而不简单的Agent框架。
现在,你不仅理解了它的工作原理,更掌握了其背后的设计思想。这为你提供了坚实的基础,去进行下一步的探索。真正的掌握源于实践。现在,轮到你来构建了。