ReALM(Retrieval-Augmented Language Model)介绍
概念
ReALM(Retrieval-Augmented Language Model) 是 RAG(Retrieval-Augmented Generation,检索增强生成)领域的核心技术框架之一,本质是「将检索模块与语言模型深度融合」的模型架构。通过先检索外部知识库的相关信息,再让语言模型基于检索结果生成回答,解决了传统大模型「知识过时、事实不准确、缺乏领域专属信息」的核心痛点
ReALM 直译是「检索增强语言模型」,是 RAG 技术的「模型层实现方案」
ReALM 就是一个基于预训练模型的 RAG 系统,使用 BERT 作为词向量模型的基础模型
它并非独立于 RAG 的技术,而是将「检索逻辑」嵌入语言模型的预训练 / 推理过程,让模型具备「主动检索外部知识」的能力,而非单纯依赖模型参数中存储的固定知识
传统大模型是「凭记忆答题」,ReALM 是「先查资料再答题」,且「查资料」的过程与「答题」的过程被统一到一个模型框架中,效率和准确性更高
为何需要 ReALM
传统大模型的知识局限
知识固化:大模型的知识源于训练数据,训练数据截止后(如 2023 年)的新信息(如 2024 年的政策、2025 年的新技术)无法覆盖,导致「知识过时」
事实误差:模型参数无法存储所有细分领域的精准事实(如小众行业数据、企业内部规章),容易生成「幻觉答案」
领域适配难:直接微调大模型适配垂直领域(如医疗、法律),需要大量领域数据,成本高且易污染原有通用知识
早期检索 + 生成方案的缺陷
早期 RAG 多是「分离式架构」:检索模块(如 Elasticsearch)和生成模块(如 GPT-3)是独立的,检索结果的相关性判断、与生成逻辑的衔接不够流畅(比如检索到无关信息,模型无法有效过滤)
交互效率低:检索和生成是「串行两步走」,没有形成闭环,无法根据生成过程的需求动态补充检索(比如生成到一半发现缺少某个细节,无法主动再查)
ReALM 的核心目标
让检索与生成「深度耦合」,让模型本身具备「何时检索、检索什么、如何利用检索结果」能力,而非依赖外部独立检索模块
ReALM 的核心技术逻辑
ReALM 的架构核心是「检索增强预训练」+「动态检索推理」,步骤可简化为:
预训练阶段:让模型学会「检索」
训练数据构造:将「问题 + 外部知识库片段(相关 / 不相关)+ 正确答案」组合成训练样本
预训练任务:让模型学习「根据问题判断是否需要检索」「如何从知识库中筛选相关片段」「如何将检索到的信息与自身知识结合生成答案」
关键设计:
在预训练中引入「检索器模块」(通常是稠密检索模型,如 DPR),并将其与语言模型(如 Transformer)共享参数,让检索和生成形成统一的模型框架,而非两个独立模块
推理阶段:动态检索 + 生成闭环
步骤 1:接收用户问题后,模型先判断「是否需要检索」(比如常识性问题无需检索,专业问题需要检索)
步骤 2:若需要检索,模型生成「检索关键词 / 查询语句」,调用外部知识库(如企业文档库、网络数据)获取相关信息片段
步骤 3:模型将「问题 + 检索到的相关片段」作为输入,结合自身参数中的通用知识,生成最终答案
步骤 4:可选闭环:若生成过程中发现信息不足(如检索结果不完整),模型可再次发起检索,补充信息后继续生成
ReALM 与传统 RAG 的核心区别
很多人会混淆「ReALM」和「RAG」,其实二者是「具体实现」与「技术理念」的关系
RAG 是「检索增强生成」的总称,ReALM 是 RAG 的一种先进实现方案,区别于早期的「分离式 RAG」:
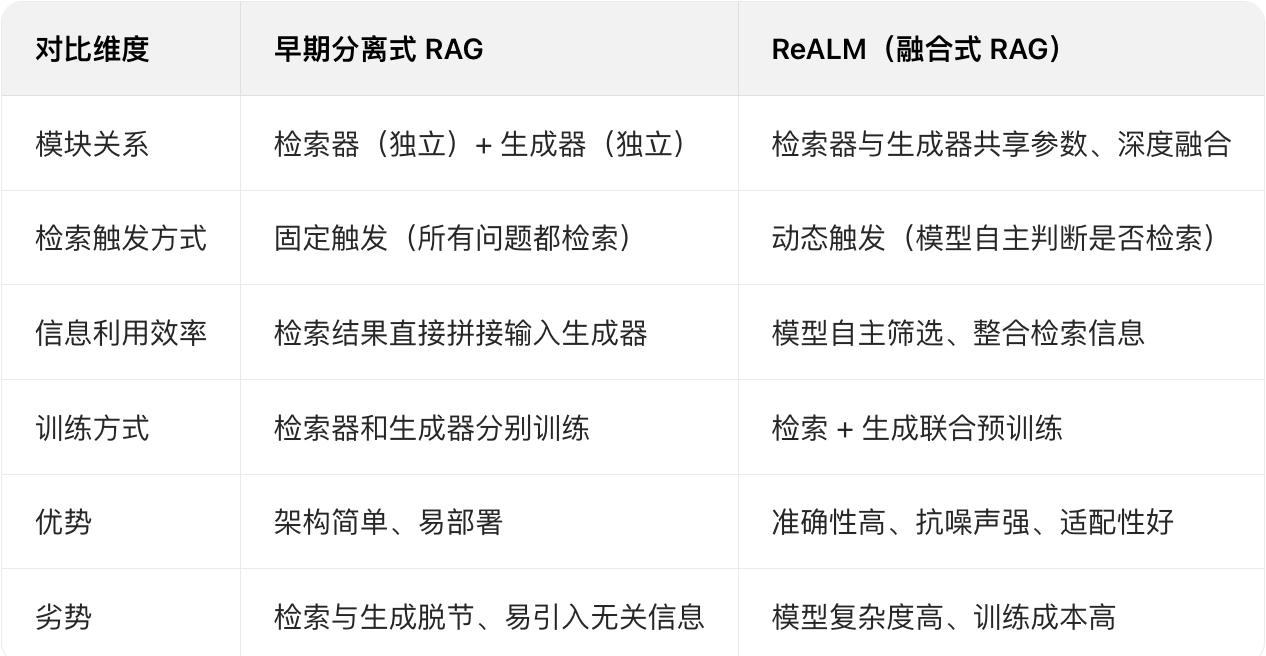
典型应用场景
ReALM 作为 RAG 的核心实现方案,主要用于需要「精准事实、实时知识、领域专属信息」的场景:
企业知识库问答:
如企业内部的员工手册、产品文档、客户案例查询(如 “公司 2025 年的年假政策是什么?”),ReALM 可检索内部文档生成精准答案
实时信息查询:
如新闻资讯、股市行情、政策更新(如 “2025 年最新的个人所得税政策?”),通过检索实时数据解决大模型知识过时问题
垂直领域问答:
如医疗(“某新药的适应症有哪些?”)、法律(“某地区的劳动仲裁流程?”)、金融(“某基金的最新持仓?”),无需大规模微调大模型,仅需接入领域知识库即可
智能客服:
处理用户关于产品功能、售后流程的个性化问题(如 “我的订单为何还未发货?”),检索用户订单信息 + 产品售后规则生成答案
总结
ReALM 是 RAG 技术的「进阶形态」,核心价值是通过「检索与生成的深度融合」
让语言模型既能利用外部知识库的「新鲜、精准、专属知识」,又能保持生成的流畅性和逻辑性
完美解决了传统大模型的知识局限和早期 RAG 的架构缺陷
成为当前企业级 AI 应用(如智能问答、知识库管理)的主流技术方案之一