opencv学习笔记9:基于CNN的mnist分类任务
目录
一.CNN介绍
最简单的 CNN 基本模型结构(以 MNIST 为例)
逐层拆解(附具体尺寸变化)
1. 输入层(Input Layer)
2. 卷积层(Convolutional Layer)
注:16 个卷积核怎么来的?
3. 池化层(Pooling Layer)
4. 全连接层(Fully Connected Layer)
5. 输出层(Output Layer)
总结:最简单 CNN 的工作流程
二.基于CNN的mnist分类 代码详解
1.引入库
2.数据预处理
3.加载数据集
4.卷积层
(1)class MNISTCNN(torch.nn.Module):
(2)def __init__(self):
(3)super
5.池化层
还有第二个卷积层
6.全连接层
(1)自动初始化权重和偏置
(2)全连接层计算过程示例
7.前向传播函数
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 64 * 7 * 7)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
张量x形状变化总览
8.损失函数 criterion
(1)几类损失函数的初步介绍
①回归损失:均方误差(其他的大致了解,主要讲交叉熵损失)
②回归损失:绝对误差
③分类损失
(2)交叉熵损失(Cross Entropy Loss)
①Softmax是什么?(用于输出预测概率)
<1>作用
<2>数学公式
<3>示例
②交叉熵损失详细讲解
<1>作用
<2>数学公式
<3>one-hot编码是啥?(用于类别的真实标签)
<4>交叉熵损失示例
9.optimizer优化器
(1)model.parameters()
(2)lr=0.001
(3)大致介绍
10.训练
(1)for batch_idx, (data, target) in enumerate(train_loader):
(2)optimizer.zero_grad()
(3)output = model(data)
①output = model(data)是如何执行的?
②为什么能自动调用?__call__ 方法是个什么东西?
③为什么 __call__ 能自动调用 forward?call方法的逻辑是什么?
(4)loss = criterion(output, target)
(5) loss.backward()
11.测试
总历程代码
三.激活函数-ReLU函数
1.ReLU函数介绍
2.ReLU 的计算公式
3.对原始特征图应用 ReLU 激活 示例
四.简洁代码输出
五.CNN(卷积神经网络)与传统的特征+分类器方法对比
一.CNN介绍
CNN(Convolutional Neural Network卷积神经网络)的核心思想是 “局部特征提取 + 层级抽象”,最简单的基本模型可以简化为 “输入层→卷积层→池化层→全连接层→输出层” 这 5 个核心模块。下面用 “识别手写数字(MNIST)” 为例,逐个讲解每层的作用和细节:
最简单的 CNN 基本模型结构(以 MNIST 为例)
先引入CNN矩阵的来源,如下图是一个全连接层,三个x分别乘上对应的偏置w再加上一个偏置b,整体再用激活函数g激活,得到y1,y2同理;写成矩阵形式:Y=g(WX+b)
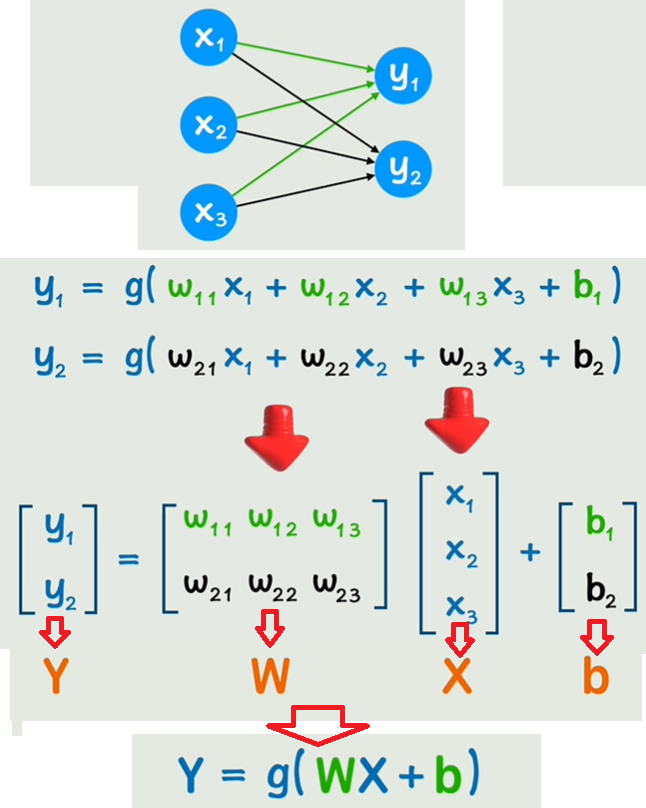
如果中间有隐藏层,即一个或多个卷积层、池化层、全连接层那么x、y就不够表示了,那就都用a来表示,第一层①则L=1,第二层②则L=2、第三层③则L=3
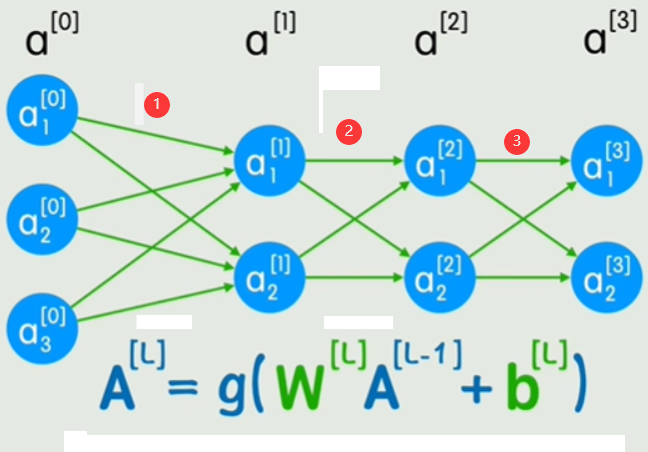
假设输入是一张 28×28 的手写数字灰度图(比如数字 “5”),模型结构如下:
这个图在上面的基础上加入了卷积层,也就是表示了卷积层和全连接层,上面的公式是卷积层的运算,仅仅把矩阵乘法换成了卷积运算W*A
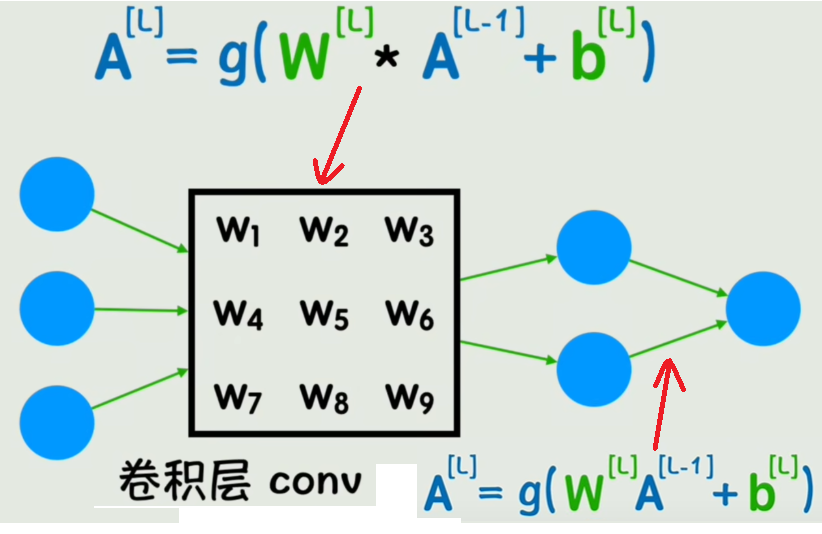
简化后再加上池化层就是下图:
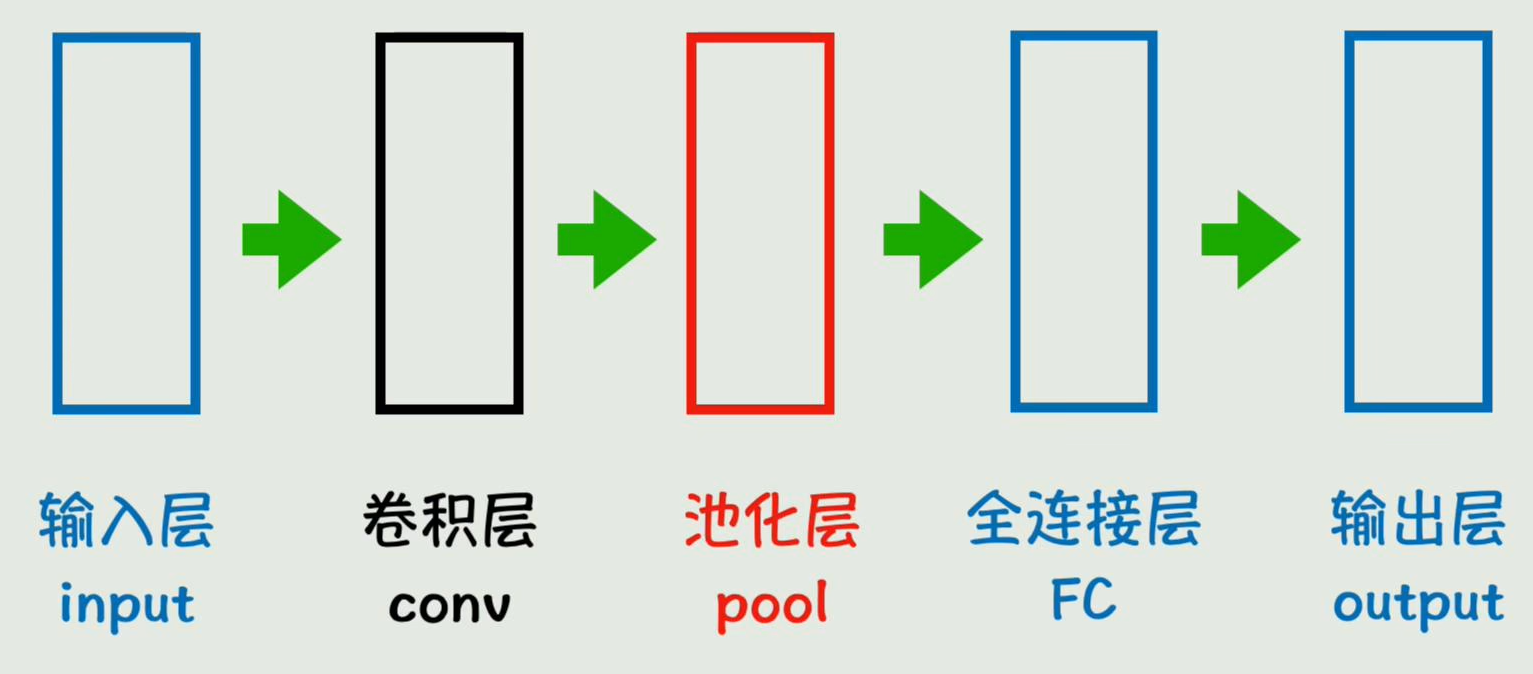
输入层(28×28灰度图) ↓
卷积层(提取边缘/纹理)↓
池化层(压缩尺寸)↓
全连接层(整合特征)↓
输出层(预测0-9类别)卷积层、池化层可以有多个,如下图,这就是CNN
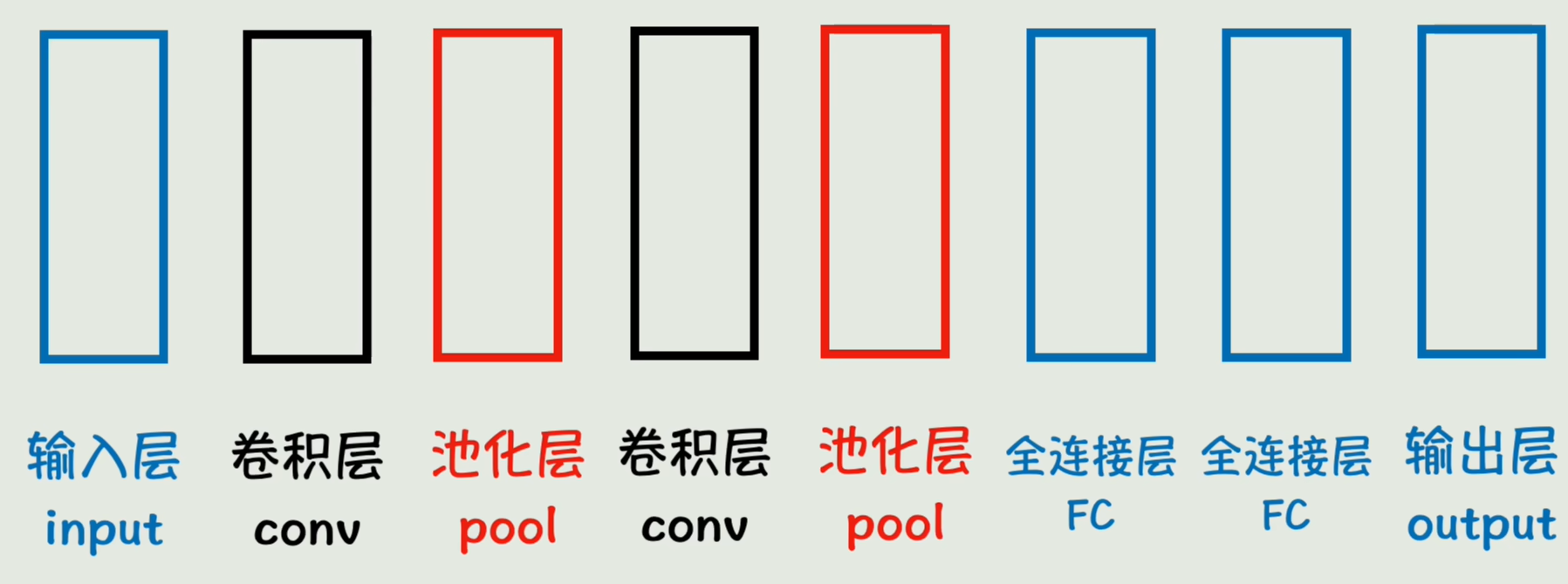
逐层拆解(附具体尺寸变化)
1. 输入层(Input Layer)
- 作用:接收原始图像数据,转换为模型可处理的格式。
- 输入数据:28×28 的灰度图(单通道),在 PyTorch 中表示为张量
(1, 28, 28)([通道数, 高度, 宽度])。注:张量的形状的 “官方表示” 是小括号,自然语言 / 文档中:中括号是 “简化表达”,张量形状用中、小括号都行。 - 为什么这样设计:模型只能处理张量格式的数值,所以需要把图片的像素值(0-255)转换为 0-1 之间的浮点数张量。
2. 卷积层(Convolutional Layer)
- 核心作用:用 “卷积核” 提取图像的局部特征(如边缘、拐角、斑点等)。
- 参数示例:
- 卷积核数量:16 个(提取 16 种不同的局部特征)
- 卷积核大小:3×3(每次观察 3×3 的局部区域)
- 步长(stride):1(每次滑动 1 个像素)
- 填充(padding):1(边缘补 0,保证输出尺寸不变)
- 计算过程:每个 3×3 的卷积核在 28×28 的输入上滑动,与对应区域的像素计算 “乘积和”,生成 1 张特征图。16 个卷积核最终输出 16 张特征图,尺寸仍为 28×28(因 padding=1)。
- 输出:16 张 28×28 的特征图(张量形状
(16, 28, 28))。 - 通俗理解:相当于用 16 个 “滤镜” 分别过滤图像,每个滤镜只保留一种特征(比如有的滤镜只认竖线,有的只认横线)。
注:16 个卷积核怎么来的?
- 初始状态:刚开始训练时,16 个卷积核是随机初始化的(比如用小的随机数填充 3×3 的矩阵),此时它们没有任何 “意义”,就像一张白纸。
- 学习过程:训练时,模型会根据 “预测错误” 不断调整卷积核的数值(通过反向传播)。比如:
- 当模型把 “数字 8” 错认成 “0” 时,会自动调整那些负责识别 “8 的上下两个圈” 的卷积核,让它们更敏感;
- 最终,16 个卷积核会各自擅长捕捉不同特征(有的对竖线敏感,有的对斜线敏感,有的对拐角敏感)。
- 为什么是 16 个:这是人为设定的超参数,类似 “雇多少个侦探去探案”。数量越多,能捕捉的特征越丰富,但计算量也越大(可以设 8、32 等,根据任务调整)。
3. 池化层(Pooling Layer)
- 核心作用:压缩特征图尺寸(减少计算量),同时保留关键特征(抗干扰)。
- 参数示例:
- 池化窗口:2×2(每次看 2×2 的区域)
- 步长:2(每次滑动 2 个像素,无重叠)
- 计算过程:对卷积层输出的 16 张 28×28 特征图,每个 2×2 的区域取最大值(最大池化),尺寸从 28×28 压缩为 14×14(28÷2=14)。
- 输出:16 张 14×14 的特征图(张量形状
(16, 14, 14))。 - 通俗理解:相当于把图像 “缩小” 一半,但保留每个局部区域最明显的特征(比如某个 2×2 区域中最亮的点)。
pooling译为池化/聚集,即抓住主要矛盾;一般是将图像划分为多个小矩阵,在小矩阵中找最大值/平均值,这样就保留了关键特征,进一步放大主要特征。
4. 全连接层(Fully Connected Layer)
- 核心作用:将池化层输出的 “局部特征” 整合为 “全局特征”,映射到最终类别。
- 操作步骤:
- 先将 16 张 14×14 的特征图 “展平” 为一维向量:
16×14×14 = 3136(向量长度 3136)。 - 通过全连接层将 3136 维向量映射到 128 维(中间层,可调整),再映射到 10 维(对应 0-9 共 10 个类别)。
- 先将 16 张 14×14 的特征图 “展平” 为一维向量:
- 输出:10 维向量(每个维度对应一个类别的 “分数”)。
- 通俗理解:相当于把前面提取的 “边缘、纹理” 等细节特征汇总,判断这些特征组合起来更可能是哪个数字。
5. 输出层(Output Layer)
- 作用:将全连接层的 10 维 “分数” 转换为概率(0-1 之间),取概率最大的作为预测结果。
- 常用操作:用 Softmax 函数将分数归一化,得到每个类别的概率(总和为 1)。
- 输出:例如
[0.01, 0.02, 0.95, ...],表示有 95% 的概率是数字 “2”。
总结:最简单 CNN 的工作流程
- 输入层接收 28×28 的手写数字图像;
- 卷积层用 16 个 3×3 卷积核提取 16 种局部特征(如边缘),输出 16×28×28;
- 池化层用 2×2 最大池化压缩尺寸,输出 16×14×14;
- 全连接层将特征展平后整合,输出 10 维类别分数;
- 输出层将分数转为概率,预测数字类别。
这个极简模型虽然简单,但能在 MNIST 上达到 98% 以上的准确率,充分体现了 CNN“局部感知、层级抽象” 的核心优势。
二.基于CNN的mnist分类 代码详解
1.引入库
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch:导入 PyTorch 深度学习框架,用于构建模型、计算损失等核心功能。from torchvision import datasets, transforms:torchvision是 PyTorch 的视觉工具库,datasets包含常用数据集(如 MNIST),transforms用于数据预处理(如转 Tensor、标准化)。from torch.utils.data import DataLoader:用于将数据集按批次加载,支持多线程和随机打乱,方便训练时迭代使用。
2.数据预处理
transforms.Compose([...]):将多个预处理操作组合成一个管道,数据加载时会按顺序执行。transforms.ToTensor():将图像(原本是 PIL 格式,像素值 0-255)转为 PyTorch 的 Tensor 格式,并自动将像素值归一化(我也不懂,大概就是个标注的预处理流程)到 0-1(除以 255)。transforms.Normalize((0.1307,), (0.3081,)):对 Tensor 进行标准化(减均值、除以标准差)。MNIST 数据集的全局均值约为 0.1307,标准差约为 0.3081(提前统计好的值),标准化可加速模型收敛。
# 数据预处理:转为Tensor张量并标准化
transform = transforms.Compose([transforms.ToTensor(),
# 把图像从PIL格式转为PyTorch的Tensor张量格式,像素值缩放到0-1之间transforms.Normalize((0.1307,), (0.3081,))
# 对Tensor做标准化,减去均值、除以标准差,让数据分布更稳定(这两个数值是MNIST数据集的统计均值和标准差)
])
transform是定义好的 “预处理规则”,最终会作用于 数据集中的每一张原始图像(比如 MNIST 里的手写数字图片)。当你用这个transform创建Dataset(如train_dataset = datasets.MNIST(..., transform=transform))时,每次从数据集中读取一张图片(比如一张 28×28 的手写数字),就会自动执行transform里的两个操作:先转成 Tensor,再标准化。- ToTensor使图像变为张量格式:使图像的像素值会从原来的
0-255(整数)缩放到0-1(浮点数),同时维度也会调整:比如一张 28×28 的灰度图,会变成[1, 28, 28]的 Tensor(第一个维度是通道数,灰度图为 1,彩色图为 3)。 - Normalize中参数可简化为0.5、0.5
3.加载数据集
# 加载数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)datasets.MNIST(...):加载 MNIST 数据集。root='./data':数据集保存路径(当前目录下的data文件夹)。train=True:加载训练集(60k 样本);train=False:加载测试集(10k 样本)。download=True:如果本地没有数据集,自动从网上下载。transform=transform:应用上面定义的预处理管道。- train_dataset 的类型不是个简单的数组,这个数组的每个元素是一个元组: “预处理后的图像 Tensor + 标签”,而不是简单的数值。
-
image, label =train_dataset[0]print("图像数据类型:", type(image)) # 输出:<class 'torch.Tensor'> print("图像形状:", image.shape) # 输出:torch.Size([1, 28, 28])(1通道,28×28像素) print("标签值:", label) # 输出:5(比如第0个样本是数字5的手写图)
-
DataLoader(...):将数据集转为可迭代的批次数据。batch_size=64:训练时每次迭代加载 64 个样本(小批次训练更稳定,利用梯度下降优化)。shuffle=True:训练集打乱顺序(避免模型学习样本顺序而非特征);测试集shuffle=False(无需打乱,按顺序评估即可)。- 输出的
train_loader是一个迭代器,每次迭代返回(data, target):data是 64 张图像的 Tensor、形状为(64, 1, 28, 28)、64是每一批次包含的样本数量;target是对应的 64 个标签(0-9)、形状为(64,)。
(深度学习模型通常需要批量处理数据(如batch_size=64表示一次处理 64 张图片),而不是单张处理。DataLoader可以自动将Dataset中的样本按指定批次大小(batch_size)分组,让模型在一次迭代中处理多个样本,充分利用 GPU 的并行计算能力,大幅提升训练速度。
举个例子:如果直接用train_dataset单张训练,6 万张图片需要迭代 6 万次;而用batch_size=64的DataLoader,只需迭代60000÷64≈938次,效率提升明显。 )
4.卷积层
class MNISTCNN(torch.nn.Module):def __init__(self):super(MNISTCNN, self).__init__()# 卷积层:提取局部特征(如边缘、纹理)self.conv1 = torch.nn.Conv2d(in_channels=1, # 输入通道数(灰度图为1)out_channels=32, # 要输出通道数(即要提取出32种特征)kernel_size=3, # 3×3卷积核stride=1, # 步长1padding=1 #padding填充的意思) #边缘填充 1 圈 0 像素,保持输出尺寸与输入一致(28×28)(1)class MNISTCNN(torch.nn.Module):
MNISTCNN这个类继承了torch.nn.Module父类,相当于c++中的class Student : public Person继承,只是写法不同。
(2)def __init__(self):
__init__ 是类的构造函数,用于初始化实例对象的属性(比如代码中的 self.conv1、self.pool 等),他调用父类 torch.nn.Module 的构造函数,确保父类的初始化逻辑。self 代表当前正在创建的实例对象本身,通过 self.属性名 定义的变量,会成为这个实例的 “专属属性”。
(3)super
-
super是 Python 的一个内置函数,用于访问父类(超类)的方法。它的作用是 “跳过当前类,直接调用父类的功能”。调用父类 torch.nn.odule的初始化方法,注册模型参数并启用 PyTorch 的自动求导等功能。 -
必要性:如果省略,模型无法管理参数(如 model.parameters()会失效),反向传播无法正常执行。
-
super是 Python 的一个内置函数,用于访问父类(超类)的方法。它的作用是 “跳过当前类,直接调用父类的功能”。 -
MNISTCNN是当前类的名字(就是我们正在定义的这个神经网络类),self是当前类的实例(代表这个模型对象本身)。 -
__init__()是类的构造函数,用于初始化对象的属性。这里的super(...).__init__()就是明确调用MNISTCNN的父类的__init__方法。 -
super(MNISTCNN, self).__init__()这行代码意思是:调用
MNISTCNN类的父类(即torch.nn.Module)的__init__方法,目的是让父类完成自身的初始化工作
torch.nn.Conv2d:2D 卷积层,通过滑动卷积核提取局部特征(如边缘、纹理);先边缘填充一圈0,然后用随机生成的32个卷积核对图像卷积运算得到32个特征图。
- self.conv1的输出形状:
[batch_size, 32, 28, 28](batch_size为一批数据的样本数,比如代码中batch_size=64,即一次输入 64 张图片)。
5.池化层
torch.nn.MaxPool2d:最大池化层,对特征图降采样,增强鲁棒性。kernel_size=2:池化窗口尺寸(2×2),每次对 2×2 区域取最大值。stride=2:窗口滑动步长(2 像素),无重叠,确保尺寸减半。
# 池化层:降维并增强鲁棒性self.pool = torch.nn.MaxPool2d(kernel_size=2, stride=2) # 输出14×14self.conv2 = torch.nn.Conv2d(32, 64, 3, 1, 1) # 再提取64种特征,输出14×14还有第二个卷积层
- self.conv2 = torch.nn.Conv2d(32, 64, 3, 1, 1) 第二个卷积层
- 第一次卷积(
conv1):提取基础局部特征(如边缘、线条、简单纹理)。 - 第二次卷积(
conv2):在第一次的基础特征上,提取更复杂的组合特征(如数字的轮廓、形状的组合)。 -
conv2的输入不是原始图像,而是经过
conv1和池化层处理后的特征图(64, 32, 14, 14)(14×14,32 通道)。 - 解释一张32通道的图:“1 张原始图片(1 通道)” → 经过 conv1(要输出32个特征,需要32 个卷积核) → 输出 “32 张特征图”。这 32 张特征图被 “捆绑” 在一起,作为 “这张原始图片的 32 个通道”(形状为
(32, 28, 28))。 -
此时,
conv2的每个卷积核会组合低级特征,提取更复杂的中级特征,比如拐角(边缘的组合)、局部轮廓(如数字的 “顶部”“底部” 特征)等。 -
解释如何提取出64种特征:
64组卷积核对64个32通道的图,每组卷积核(一组卷积核有32个)对每一个图的32张特征图卷积得到一张特征图,每个图都得到64张特征图,每一批次64个图,共64×64=4096个特征图,卷积核有64组,每组32个,一共64×32= 2048 个卷积核;实现:由于Conv2d定义的输入通道数 in_channels=32(第一个参数),即输入通道数是32,每组卷积核有32个,每个卷积核的尺寸都是 3×3。这些卷积核与输入的 32 个通道一一对应:第 1 个卷积核负责对输入的第 1 个通道做 3×3 卷积,第 2 个卷积核负责输入的第 2 个通道…… 第 32 个卷积核负责输入的第 32 个通道。最终,这 32 个子核的卷积结果会被相加,得到1 个特征图(对应这个完整卷积核的输出)
-
随着网络加深,特征从 “零散的边缘” 逐渐组合成 “有意义的局部结构”,最终为分类任务(识别 0-9)提供足够的判别信息。
- 第一次卷积(
6.全连接层
-
self.fc1 = torch.nn.Linear(64 * 7 * 7, 128):卷积层和池化层输出的是 64 个 7×7 的特征图(这些特征图是对图像局部特征的抽象,比如边缘、纹理等)。fc1对这个已经展平的一维向量进行线性变换(矩阵乘法 + 偏置)(尺寸为64×7×7 = 3136),将其映射到 128 维的中间特征空间。这一步的作用是把分散的局部特征整合为更抽象的全局特征,为最终分类做准备。 -
self.fc2 = torch.nn.Linear(128, 10):把fc1输出的 128 维全局特征进一步映射到 10 维(对应 MNIST 数据集的 0-9 共 10 个数字类别)。这一步的输出会经过 Softmax 函数(通常在损失函数中隐式处理),转化为每个类别的概率,从而得到模型对输入图像的分类预测结果。
# 全连接层:分类self.fc1 = torch.nn.Linear(64 * 7 * 7, 128) # 池化后尺寸7×7,展平为64×7×7self.fc2 = torch.nn.Linear(128, 10) # 10个类别(0-9)(1)自动初始化权重和偏置
PyTorch 会在创建 Linear 层时自动初始化权重和偏置,无需手动干预:

- 上面的U(-bound,bound)表示权重值在区间 [-bound,bound] 内服从均匀分布。
- 偏置初始化:默认初始化为
0。 
(2)全连接层计算过程示例
我们通过一个极度简化的示例来理解这个过程(将维度从 4 维压缩到 2 维,原理与 3136→128 完全一致):

原本的 4 维输入特征,通过权重矩阵的线性组合 + 偏置,被压缩成了 2 维的抽象特征(实际任务中是 128 维)。把全连接层画出来就如下图所示:
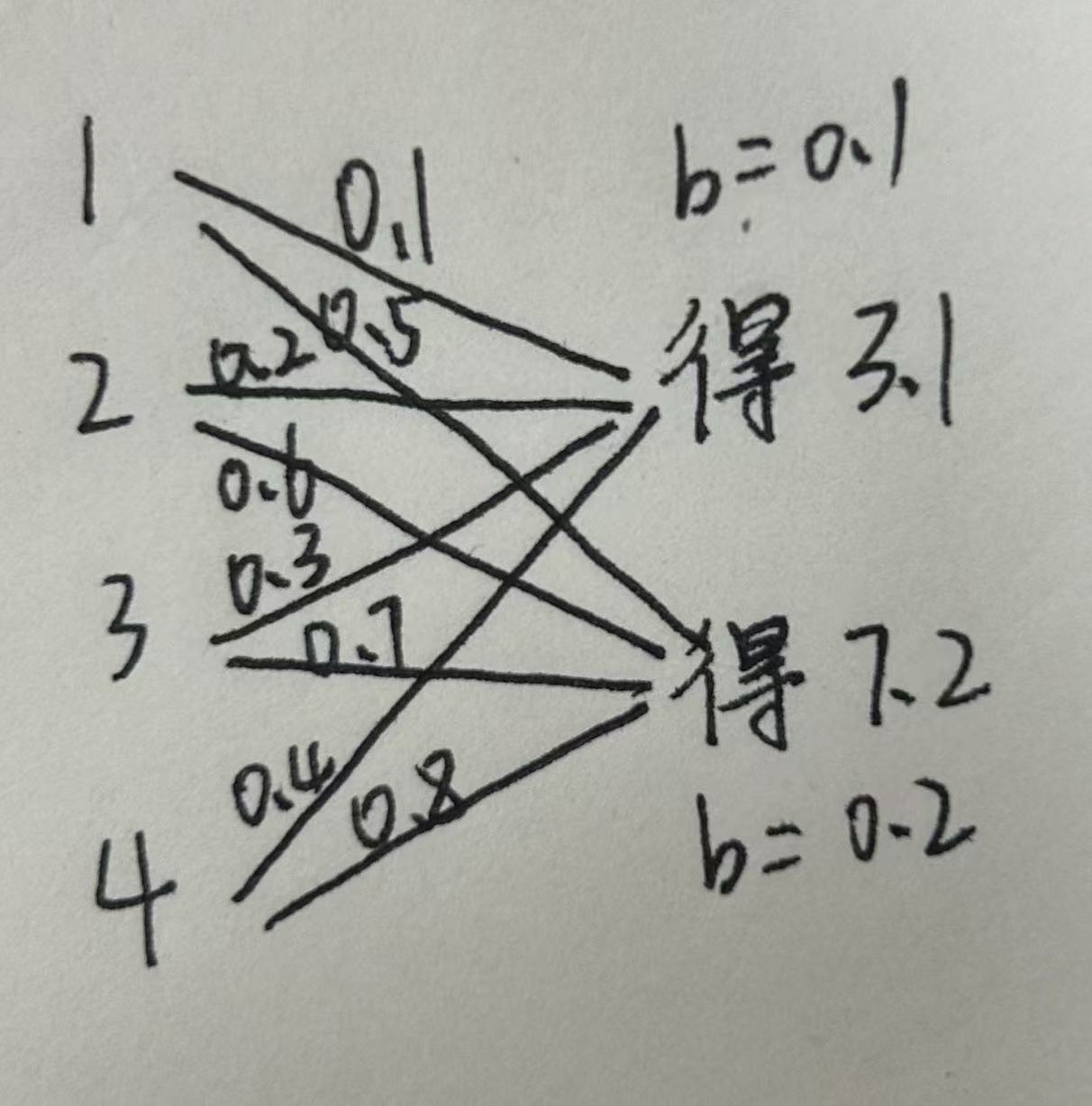
7.前向传播函数
前向传播函数,定义了数据在模型各层之间的流动逻辑,比如 “输入图片→卷积→激活→池化→全连接→输出” 的计算逻辑。在这里就是 “输入图片→卷积→激活→池化 → 卷积→激活→池化 →全连接→输出”
def forward(self, x): #前向传播函数,定义了数据在模型各层之间的流动逻辑x = self.pool(torch.relu(self.conv1(x))) # conv1→激活→池化x = self.pool(torch.relu(self.conv2(x))) # conv2→激活→池化x = x.view(-1, 64 * 7 * 7) # 展平为向量x = torch.relu(self.fc1(x)) #对展平的一维向量进行第一次全连接, 3136维映射为128维向量x = self.fc2(x) #对进行第二次全连接, 128维映射为10维向量return x假设输入 x 是一批 MNIST 图像张量,形状为 (64, 1, 28, 28)(批次大小 × 通道数 × 高度 × 宽度)。
-
x = self.pool(torch.relu(self.conv1(x)))
- self.conv1(x):第一次卷积(
conv1),提取基础局部特征(如边缘、线条、简单纹理)。 - torch.relu(...)对卷积结果应用 ReLU 激活函数,将负数置为 0,保留正数特征(增强非线性表达能力)。输出形状不变:
(batch_size, 32, 28, 28)。 - self.pool(...):第一次池化,压缩尺寸,保留关键特征,同时降低计算量。输出形状:
(batch_size, 32, 14, 14)(高度和宽度各缩小一半)。 - 作用:提取输入图像的底层特征(如边缘、纹理),并通过池化减少数据量,增强特征鲁棒性。
- self.conv1(x):第一次卷积(
-
x = self.pool(torch.relu(self.conv2(x)))self.conv2(x):第二次卷积(conv2),在第一次的基础特征上,提取更复杂的组合特征(如数字的轮廓、形状的组合)。torch.relu(...):再次应用 ReLU 激活,增强非线性。输出形状不变:(batch_size, 64, 14, 14)。self.pool(...):再次池化降维,即第二次池化:进一步压缩,让特征更抽象、更具代表性。输出形状:(batch_size, 64, 7, 7)
-
x = x.view(-1, 64 * 7 * 7)view(-1, ...)是张量形状变换函数,-1表示 “自动计算该维度大小”(由总元素数和其他维度决定)。64 * 7 * 7 = 3136:将上层输出的三维特征图(64 个 7×7)展平为一维向量。- 输出形状:
(batch_size, 3136)(每个图片样本对应一个长度 3136 的向量) - 作用:将卷积层输出的多维特征图转换为一维向量,适配后续全连接层的输入格式(全连接层要求输入为向量)。
-
x = torch.relu(self.fc1(x))self.fc1(x):用第一个全连接层(fc1)对展平后的向量做线性变换。fc1参数:输入维度 3136、输出维度 128(将特征压缩到 128 维)。- 输出形状:
(batch_size, 128)。
torch.relu(...):ReLU 激活,保留非线性,筛选关键特征。- 输出形状不变:
(batch_size, 128)。
- 输出形状不变:
-
x = self.fc2(x)self.fc2(x):用第二个全连接层(fc2)做最终分类映射。fc2参数:输入维度 128、输出维度 10(对应 MNIST 的 10 个类别:0-9)。- 输出形状:
(batch_size, 10)(每个维度对应一个类别的 “未归一化概率”)。 - 作用:将 128 维特征映射到 10 个类别,输出分类结果的 “分数”(后续通过交叉熵损失函数转换为概率)。
- fc2不用relu的原因:保留原始评分,方便损失计算
- 避免截断有效信息:ReLU 会把负数置为 0,但
fc2的输出中,负数可能是有意义的(比如 “当前图片是 5 的可能性低于平均水平”)。如果用 ReLU,会丢失这些 “负向信号”,导致分类评分失真。 - 适配交叉熵损失函数:代码中用
CrossEntropyLoss作为损失函数,它会自动对fc2的输出做 Softmax(转换为概率)。如果fc2后加 ReLU,会导致 Softmax 计算的概率分布偏差(比如强制某些类别的评分不为负),影响损失的准确性。
- 避免截断有效信息:ReLU 会把负数置为 0,但
-
张量x形状变化总览
- 输入
x是一批 MNIST 图像张量:(批次大小 × 通道数 × 高度 × 宽度)。 -
步骤 操作 输入形状 输出形状 说明 1 conv1(x)(64, 1, 28, 28)(64, 32, 28, 28)32 个卷积核,输出 32 个特征图 2 torch.relu(...)(64, 32, 28, 28)(64, 32, 28, 28)激活函数不改变形状 3 self.pool(...)(64, 32, 28, 28)(64, 32, 14, 14)2×2 池化,尺寸减半 4 conv2(x)(64, 32, 14, 14)(64, 64, 14, 14)64 个卷积核,输出 64 个特征图。 5 torch.relu(...)(64, 64, 14, 14)(64, 64, 14, 14)激活函数不改变形状 6 self.pool(...)(64, 64, 14, 14)(64, 64, 7, 7)2×2 池化,尺寸减半 7 x.view(-1, 64*7*7)(64, 64, 7, 7)(64, 3136)展平为一维向量(64×7×7=3136) 8 self.fc1(x)(64, 3136)(64, 128)全连接层,3136 维→128 维 9 torch.relu(...)(64, 128)(64, 128)激活函数不改变形状 10 self.fc2(x)(64, 128)(64, 10)全连接层,128 维→10 维(10 个类别)
- 输入
举个例子:识别手写数字 “8” 时,
conv1可能识别出 “竖线、横线、小圆圈” 等基础特征;conv2则会把这些基础特征组合成 “上下两个圈的形状”,从而精准识别 “8”。
如果只做一次卷积,模型只能学到简单特征,无法区分复杂的数字形态(比如 “8” 和 “0” 的差异)。两次操作能让特征从 “基础→复杂” 逐层抽象,大幅提升分类准确率。
8.损失函数 criterion
model = MNISTCNN()
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)- 创建
MNISTCNN类的实例,初始化整个 CNN 模型;model包含所有定义的层(如model.conv1可访问第一个卷积层)和参数(通过model.parameters()可获取所有待优化的权重和偏置)。 - 定义损失函数,这里用的交叉熵损失(Cross Entropy Loss)
- 定义用于更新模型参数(权重和偏置)的优化算法,目的是最小化损失函数。
(1)几类损失函数的初步介绍
损失函数(Loss Function)是深度学习中用于衡量模型预测结果与真实结果之间差异的函数 ,也称为误差函数。它通过计算模型的预测值与真实值之间的不一致程度,来评估模型的性能。
损失函数按任务类型分为回归损失和分类损失,回归损失主要处理连续型变量,常用MSE、MAE等,对异常值敏感度不同;分类损失主要处理离散型变量,常用Cross Entropy Loss、Dice Loss等,适用于不同分类任务需求。
①回归损失:均方误差(其他的大致了解,主要讲交叉熵损失)
回归损失(Regression Loss)是什么?回归损失是损失函数在回归问题中的具体应用。回归问题是指预测一个或多个连续值的问题,与分类问题(预测离散值)相对。回归损失函数包括均方误差(MSE)和绝对误差(MAE),MSE对异常值敏感,适用于精确预测场景;MAE对异常值鲁棒,适用于异常值可能重要的场景。
-
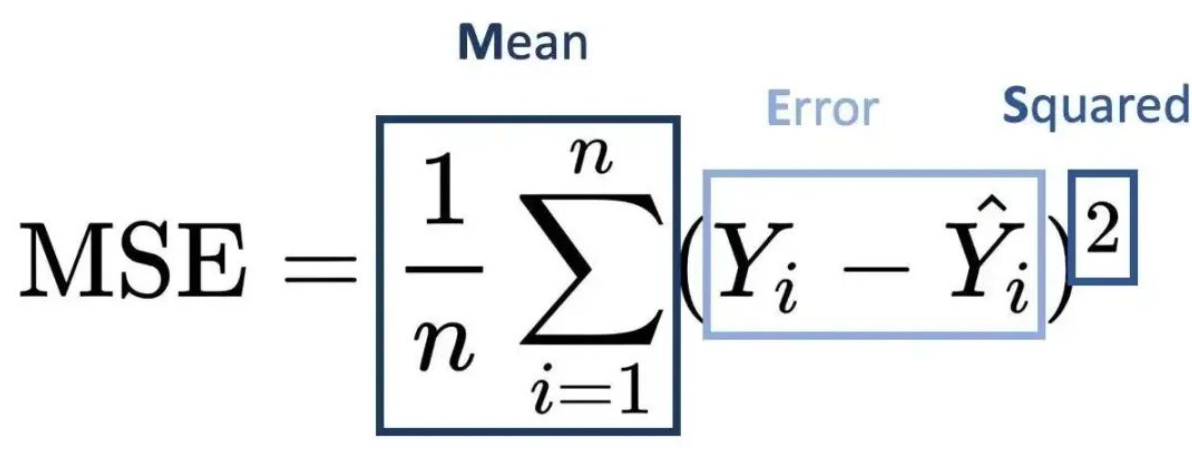
均方误差(Mean Squared Error, MSE)是什么?均方误差(MSE)计算的是预测值与真实值之间差的平方的平均值。
- MSE对异常值非常敏感,因为较大的误差会受到更大的惩罚(误差的平方会放大差异)。它通常用于需要精确预测的场景,但可能不适用于异常值较多的数据集。
②回归损失:绝对误差
- 绝对误差(Mean Absolute Error, MAE)是什么?绝对误差(MAE)计算的是预测值与真实值之间差的绝对值的平均值。
- MAE对异常值的鲁棒性较好,因为无论误差大小,都以相同的权重进行计算(绝对误差不会放大差异)。它通常用于异常值可能代表重要信息或损坏数据的场景。
③分类损失
分类损失(Classification Loss)是什么?分类损失是在训练分类模型时,用于衡量模型预测结果与真实标签之间差异的一种度量。它是一个非负值,反映了模型预测结果的准确性。分类损失越小,意味着模型的预测结果与真实标签越接近,模型的性能也就越好。
- 交叉熵损失(Cross Entropy Loss)是什么?在分类问题中,一个分布是模型的预测概率分布,而另一个分布是真实标签的概率分布(通常以one-hot编码表示)。交叉熵损失通过计算这两个分布之间的差异来评估模型的性能。
- 骰子损失(Dice Loss)是什么?骰子损失基于Dice系数,后者用于评估两个二值图像或二值掩码的重叠情况。Dice系数的值在0到1之间,值越大表示两个集合越相似。
(2)交叉熵损失(Cross Entropy Loss)
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失一个分布是模型的预测概率分布(用softmax得到),而另一个分布是真实标签的概率分布(用one-hot编码表示)。交叉熵损失通过计算这两个分布之间的差异来评估模型的性能。
CrossEntropyLoss是 PyTorch 封装的多分类损失函数,内部包含两个核心步骤:- 对模型输出(10 个类别的得分,10 个类别对应mnist中的0~9十个数字)执行
SoftMax操作,将得分转换为概率分布(所有类别的概率和为 1)。 - 计算该概率分布与真实标签(以整数形式表示,如数字 “3” 对应标签
3)的交叉熵:
其中,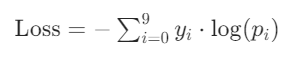
是真实标签的 one-hot 编码(只有对应类别为 1,其余为 0),
是模型预测的第i类概率。
- 对模型输出(10 个类别的得分,10 个类别对应mnist中的0~9十个数字)执行
- 特点:数值越小,说明预测越接近真实标签,模型性能越好。
①Softmax是什么?(用于输出预测概率)
<1>作用
将模型输出的原始得分(如分类任务中的 “类别置信度”)转换为 “概率分布”,使得所有类别的概率之和为 1,便于后续计算损失或解读预测结果。
<2>数学公式
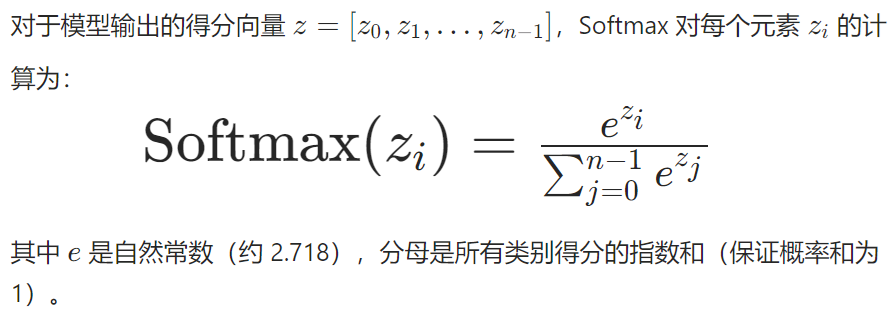
也就是每个得分取指数,除以所有类别得分的总分取指数,可以让得分转换成一个小于一的概率,所有类别的概率总和为1。
<3>示例
这里假设只有三个类别,得分分别是2、1、0.1(手写数字集0~9十个类别太多了,举例简化成三个):

②交叉熵损失详细讲解
<1>作用
衡量 “预测概率分布” 与 “真实标签分布” 之间的差距,是分类任务中常用的损失函数(差距越大,损失值越高;模型越差)。
<2>数学公式

简化后的公式就是表明只计算类别的真实标签的交叉熵损失!因为使用了one-hot编码,只有类别的真实标签的概率是1,其他都是0,比如mnist数据集里面的数字5,即类别5,类别 “5” 的 one-hot 编码:[0, 0, 0, 0, 0, 1, 0, 0, 0, 0],就只需要把类别5第六个位置(画横线位置,因为是从0开始,所以5对应第六个位置)的预测概率带入-log(
),计算得到交叉熵损失
<3>one-hot编码是啥?(用于类别的真实标签)
对于有 n 个类别的任务(如手写数字识别有 10 类:0-9),每个类别会被编码为一个长度为 n 的向量:
- 向量中只有对应类别索引的位置为 1,其余位置为 0;
- 这种 “独热” 的形式,确保了类别之间的 “互斥性”(一个样本只能属于一个类别)。
以手写数字识别(10 类:0-9)为例:
- 类别 “0” 的 one-hot 编码:
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0] - 类别 “5” 的 one-hot 编码:
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0] - 类别 “9” 的 one-hot 编码:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
<4>交叉熵损失示例
沿用上面softmax示例中的三个类别,真实标签是 “类别 0”(one-hot 为 [1,0,0]),模型预测概率是 [0.659, 0.242, 0.099],则交叉熵损失为:
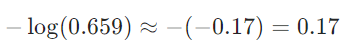
若模型预测概率是 [0.1, 0.8, 0.1](真实类别概率低),则损失为 -log(0.1) = 2.3(损失更高,说明模型预测更差)。
9.optimizer优化器
model = MNISTCNN()
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)Adam 优化器类是目前深度学习中最常用的优化器之一。它结合了 “动量法” 和 “自适应学习率” 的优点,能快速、稳定地更新参数。
(1)model.parameters()
model 是你定义的 MNISTCNN 模型实例,model.parameters() 会返回模型中所有 “可学习参数” 的迭代器,包括:
- 卷积层的权重(
conv1.weight、conv2.weight)和偏置(conv1.bias、conv2.bias); - 全连接层的权重(
fc1.weight、fc2.weight)和偏置(fc1.bias、fc2.bias)。
优化器通过这个参数 “知道” 哪些参数需要在反向传播后被调整。
(2)lr=0.001
lr 是 learning rate(学习率)的缩写,作用是控制参数更新的 “步长”。学习率越大,参数每次更新的幅度越大;学习率越小,更新幅度越小。Adam 优化器的默认推荐值就是0.001。
(3)大致介绍
优化器(optimizer)是模型训练的 “参数调整工具”,核心作用是根据模型预测的误差(损失),自动调整模型中的权重和偏置等可学习参数
模型(如代码中的 MNISTCNN)包含大量可学习的参数:
- 卷积层的卷积核权重(
conv1.weight、conv2.weight)和偏置(conv1.bias、conv2.bias); - 全连接层的权重(
fc1.weight、fc2.weight)和偏置(fc1.bias、fc2.bias)。
这些参数的初始值是随机的,模型一开始无法正确预测数字。优化器的任务就是通过调整这些参数,最小化 “预测结果与真实标签的差距(损失)”。
- 用一阶动量
m累积历史梯度方向(避免震荡); - 用二阶动量
v自适应调整学习率(梯度大则步小,梯度小则步大); - 最终按
w_new = w_old - (学习率系数 × 动量)更新参数,使损失逐渐减小。
10.训练
(1)for batch_idx, (data, target) in enumerate(train_loader):
enumerate是 Python 的内置函数,作用是遍历可迭代对象(如列表、数据加载器)时,同时获取 “元素的索引” 和 “元素本身”。batch_idx:批次索引(从 0 开始计数,标记当前是第几个批次)。data:当前批次的图像数据,形状为[64, 1, 28, 28](64 是batch_size,1 是通道数,28×28 是图像尺寸)。target:当前批次的标签(即图像对应的数字),形状为[64](每个元素是 0-9 的整数)。train_loader:之前定义的数据加载器,每次迭代返回一个批次64个(data, target)。
# 训练
for epoch in range(5): # 训练5轮for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()(2)optimizer.zero_grad()
- 清空优化器中缓存的上一轮参数梯度。
- PyTorch 的梯度计算默认是累积的(即梯度会叠加到上一次计算的结果上),如果不清空,会导致梯度计算错误,影响参数更新。因此,每轮批次训练前必须手动清零。
(3)output = model(data)
将当前批次的图像数据输入模型,得到预测结果。数据data会按照MNISTCNN类中前向传播函数forward方法定义的流程流动:卷积 1→ReLU→池化→卷积 2→ReLU→池化→展平→全连接 1→ReLU→全连接 2,最终输出预测结果。output的形状:[64, 10]——64 是批次大小,10 是类别数(每个元素表示对应类别的得分,数值越大表示摸型越认为该图像属于这个类别)。
①output = model(data)是如何执行的?
model(data) 看似是 “调用对象”,实则是通过 Python 的特殊方法 __call__ 实现的简化调用,具体流程如下:
- 我们的
MNISTCNN类继承自torch.nn.Module(PyTorch 中所有神经网络模块的基类)。 torch.nn.Module内部定义了__call__方法(这是 Python 的特殊方法,允许对象像函数一样被调用)。- 当执行
model(data)时,Python 会自动调用model.__call__(data)。 __call__方法的核心逻辑是:先完成一些预备工作(如记录计算图、启用训练模式下的 dropout 等),然后自动调用我们在MNISTCNN中定义的forward方法,即model.forward(data)。- 最终返回的
output就是forward方法的输出,也就是模型对输入data的预测结果(10 个类别的分数)。
②为什么能自动调用?__call__ 方法是个什么东西?
__call__ 是 Python 的特殊方法(魔术方法),它允许一个类的实例(对象)像函数一样被调用。
举个简单的例子:
class MyClass:def __call__(self, x):print(f"调用了__call__,输入是{x}")return x * 2obj = MyClass()
result = obj(5) # 像调用函数一样调用对象
print(result) # 输出:10在这个例子中,obj(5) 等价于 obj.__call__(5),__call__ 方法让对象具备了 “函数行为”。
③为什么 __call__ 能自动调用 forward?call方法的逻辑是什么?
在 PyTorch 中,所有神经网络模块都继承自 torch.nn.Module,而 torch.nn.Module 内部显式定义了 __call__ 方法,其核心逻辑可以简化理解为:
class Module:def __call__(self, *args, **kwargs):# 步骤1:完成预备工作(如记录计算图、切换训练/测试模式等)self._prepare_forward()# 步骤2:调用用户定义的 forward 方法return self.forward(*args, **kwargs)- 当我们执行
model(data)时,Python 会自动触发model.__call__(data),而__call__方法内部会调用model.forward(data),从而完成前向传播。在历程代码中则是把data传给了forward函数的x,即传入了数据 - 这一设计的目的是封装框架级的底层逻辑(如自动求导、模式切换),让用户只需关注
forward中的数据流动,无需手动处理这些细节
因此,model(data) 本质是通过 __call__ 间接触发了 forward 方法,完成了从输入数据到输出预测的前向传播过程!
(4)loss = criterion(output, target)
计算当前批次的预测结果(output)与真实标签(target)之间的交叉熵损失。例如:把十个数字简化成3个数字举例,一个图真实标签是 “类别 0”(one-hot 为 [1,0,0],这个存储在target标签中),模型预测概率是 [0.1, 0.8, 0.1],则损失为 -log(0.1) = 2.3
对应历程代码中的过程是:CrossEntropyLoss对 output 的每一行(每张图片的 10 个评分)应用 Softmax 函数,将原始评分转换为 “概率”(值在 0-1 之间,且 10 个类别的概率和为 1)。再代入公式CrossEntropyLoss=-log(pk)得到交叉熵损失值,赋值给loss,loss 是一个标量张量(shape 为 ())。
(5) loss.backward()
反向传播函数,通过自动求导(Autograd)计算损失函数对所有可学习参数(权里、偏置)的梯度。
- 过程:(反向传播找父张量以及计算图的详细讲解请看我的文章中https://blog.csdn.net/zhang_si_hang/article/details/147596175?fromshare=blogdetail&sharetype=blogdetail&sharerId=147596175&sharerefer=PC&sharesource=zhang_si_hang&sharefrom=from_link——>十三.张量与元组——>2——>(2) )从损失值(
loss)出发,沿着前向传播构建的计算图,自动计算所有 “可学习参数”(如模型的权重、偏置)的梯度(即损失对参数的偏导数),并将梯度存储在参数的.grad属性中,为后续优化器更新参数提供依据。 - 具体的计算方法:损失对
fc2输出(10 维 logits)的梯度为:梯度 = 预测概率 - 真实标签。比如真实标签是 0,模型预测类别 0 的概率(原始得分)是 0.38、类别 1 是 0.62,那么对应fc2输出中 “类别 0” 的梯度是0.38-1=-0.62(要增大这个输出),“类别 1” 的梯度是0.62-0=0.62(要减小这个输出)。后面的算法我看不懂了,大概就是沿着这个思路进一步计算出梯度,最后结合优化器的动量的算法更新了参数。 - 结果:所有参数的梯度会被存储在各自的.grad属性中(如model.conv1.weight.grad ),供后续优化器更新参数使用。
(6)optimizer.step() 是深度学习训练中参数更新的核心步骤,作用是:根据反向传播计算出的梯度,调整模型的参数(如卷积核权重、全连接层权重等),让模型逐渐 “学会” 正确预测
11.测试
# 测试
model.eval() #将模型从训练模式切换为测试模式,关闭训练特有的层,并因定批归一化后的统计量
correct = 0 #累计测试集中被模型正确分类的样本数量
with torch.no_grad(): #创建一个上下文环境,在该环境中所有操作都不会计算度,也不会存储梯度for data, target in test_loader: #每次加载一个批次样本的数据和标签进行预测和评估。output = model(data) #将测试集图像输入模型,得到预测结果(与训练时的前向传播逻相同)。pred = output.argmax(dim=1, keepdim=True)
#从模型输出的10个类别得分中,选择得分最高的类别作为预测结果
#dim-1:在第1个维度(类别维度,即 10 个类别的得分所在维度)上找最大值
#keepdim=True:保持输出的维度不变
#pred是形状为[1080,1]的 Tensor,每个元系是预测的数字(0-9)。correct += pred.eq(target.view_as(pred)).sum().item() #统计预测正确的样本数。
#target.view_as(pred):将真实标签 target 调整为与 pred 相同的形状((1000, 1))。
#pred.eq(...):比较预测值与真实标签,相同则为 True(1),不同则为 False(0)。
#sum().item():求和并转换为 Python 数值,得到当前批次正确的样本数,累加到 correct 中。print(f"测试准确率: {correct / len(test_dataset):.4f}") # 通常可达99%以上#准确率=正确分类的样本数(correct) / 測试集总样本数(len(test_dataset),即 10000)。
#:.4f 表示保留 4 位小数。correct += pred.eq(target.view_as(pred)).sum().item()
target.view_as(pred):将真实标签target的形状调整为与pred一致(从[1000]变为[1000, 1]),便于比较。pred.eq(...):逐元素比较pred(预测标签)和调整后的target(真实标签),相等则为True(对应数值 1),不等则为False(对应数值 0),返回形状为[1000, 1]的布尔 Tensor。.sum():对布尔 Tensor 求和,得到当前批次中正确分类的样本数(如 500 表示本批次有 500 个样本预测正确)。.item():将 Tensor 类型的求和结果转换为 Python 数值(如将 Tensor (500) 转为 500)。correct += ...:将当前批次的正确样本数累加到correct中。
总历程代码
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 数据预处理:转为Tensor并标准化
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,)) # MNIST的均值和标准差
])# 加载数据集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)#————————————————————————————————————————————————————————————————
class MNISTCNN(torch.nn.Module):def __init__(self): #类的构造函数,定义对象时自动调用super(MNISTCNN, self).__init__()# 卷积层:提取局部特征(如边缘、纹理)self.conv1 = torch.nn.Conv2d(in_channels=1, # 输入通道数(灰度图为1)out_channels=32, # 卷积核数量(提取32种特征)kernel_size=3, # 3×3卷积核stride=1, # 步长1padding=1 #padding填充的意思) #边缘填充 1 圈 0 像素,保持输出尺寸与输入一致(28×28)# 池化层:降维并增强鲁棒性self.pool = torch.nn.MaxPool2d(kernel_size=2, stride=2) # 输出14×14#第二个卷积层self.conv2 = torch.nn.Conv2d(32, 64, 3, 1, 1) # 再提取64种特征,输出14×14# 全连接层:分类self.fc1 = torch.nn.Linear(64 * 7 * 7, 128) # 池化后尺寸7×7,展平为64×7×7self.fc2 = torch.nn.Linear(128, 10) # 10个类别(0-9)def forward(self, x): #前向传播函数,定义了数据在模型各层之间的流动逻辑x = self.pool(torch.relu(self.conv1(x))) # conv1→激活→池化x = self.pool(torch.relu(self.conv2(x))) # conv2→激活→池化x = x.view(-1, 64 * 7 * 7) # 展平为向量x = torch.relu(self.fc1(x)) #对展平的一维向量进行第一次全连接, 3136维映射为128维向量x = self.fc2(x) #对进行第二次全连接, 128维映射为10维向量return x#————————————————————————————————————————————————————————————————
model = MNISTCNN()
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练
for epoch in range(5): # 训练5轮for batch_idx, (data, target) in enumerate(train_loader):optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 测试
model.eval() #将模型从训练模式切换为测试模式,关闭训练特有的层,并因定批归一化后的统计量
correct = 0 #累计测试集中被模型正确分类的样本数量
with torch.no_grad(): #创建一个上下文环境,在该环境中所有操作都不会计算度,也不会存储梯度for data, target in test_loader: #每次加载一个批次样本的数据和标签进行预测和评估。output = model(data) pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()print(f"测试准确率: {correct / len(test_dataset):.4f}") # 通常可达99%以上
三.激活函数-ReLU函数
五分钟秒懂神经网络原理,机器学习入门教程_哔哩哔哩_bilibili
1.ReLU函数介绍
ReLU 是一个简单高效的激活函数,通过 “保留正数、抑制负数” 的操作,即ReLU 将负值置为 0,相当于 “只保留明确的正向响应,忽略模糊或反向的响应”,卷积层的 “求和” 是 “加权求和”(权重可正可负),而非简单的加法,所以会产生负数,而训练过程中会刻意让“正值” 编码表示有用特征,“负值” 编码表示无关特征
2.ReLU 的计算公式
ReLU 的计算公式非常简单:
f(x) = max(0, x)- 当输入
x ≥ 0时,输出等于输入本身(f(x) = x);即:当输入是正数时,开关 “打开”,信号可以通过(原样输出) - 当输入
x < 0时,输出为 0(f(x) = 0)。即:当输入是负数时,开关 “关闭”,信号被阻断(输出 0)。
3.对原始特征图应用 ReLU 激活 示例
假设这个卷积核输出的原始特征图(局部区域)如下(仅展示部分像素,模拟卷积后可能出现的正负值)

四.简洁代码输出
import torch
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
#print(torch.__version__)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))
])train_dataset=datasets.MNIST(root='Y:/pycharm/mnist',train=True,download=True,transform=transform)
test_dataset=datasets.MNIST(root='Y:/pycharm/mnist',train=False,download=True,transform=transform)train_loader=DataLoader(train_dataset,batch_size=64,shuffle=True)
test_loader=DataLoader(test_dataset,batch_size=64,shuffle=False)class MNISTCNN(torch.nn.Module):def __init__(self):super(MNISTCNN,self).__init__()self.conv1=torch.nn.Conv2d(in_channels=1,out_channels=32,kernel_size=3,stride=1,padding=1)self.pool=torch.nn.MaxPool2d(kernel_size=2,stride=2)self.conv2=torch.nn.Conv2d(32,64,3,1,1)self.fc1=torch.nn.Linear(64*7*7,128)self.fc2=torch.nn.Linear(128,10)def forward(self,x):x=self.pool(torch.relu(self.conv1(x)))x=self.pool(torch.relu(self.conv2(x)))x=x.view(-1,64*7*7)x=torch.relu(self.fc1(x))x=self.fc2(x)return xmodel=MNISTCNN()
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.001)for epoch in range(5):for batch_idx,(data,target) in enumerate(train_loader):optimizer.zero_grad()output=model(data)loss=criterion(output,target)loss.backward()optimizer.step()model.eval()
correct=0
with torch.no_grad():for data,target in test_loader:output=model(data)pred=output.argmax(dim=1,keepdim=True)correct+=pred.eq(target.view_as(pred)).sum().item()print(f"测试准确率:{correct/len(test_dataset):.4f}")
输出:
测试准确率:0.9907
五.CNN(卷积神经网络)与传统的特征+分类器方法对比
| 特性 | 传统 “特征 + 分类器” 方法 | CNN |
|---|---|---|
| 特征提取 | 人工设计,依赖领域知识 | 自动学习,层次化特征提取 |
| 参数效率 | 高维数据下参数爆炸 | 局部连接 + 权重共享,参数极少 |
| 鲁棒性 | 对数据变换敏感,需人工处理 | 池化 + 数据增强,天生鲁棒 |
| 适用场景 | 小数据、简单任务、强可解释性 | 大数据、高维结构化数据(图像、语音等) |
| 性能上限 | 受限于人工特征的表达能力 | 随数据量和模型深度持续提升 |
CNN 的核心优势是自动特征学习、高效参数利用、对复杂数据的强适应性,而传统方法在简单任务或小数据场景下仍有其价值。