Gradient Accumulation (梯度累积) in PyTorch
Gradient Accumulation {梯度累积} in PyTorch
- 1. Gradient accumulation improves memory efficiency
- 2. Gradient accumulation with PyTorch
- 3. Gradient accumulation with Accelerator
- 4. Gradient accumulation with Trainer
- References
Gradient accumulation, Gradient checkpointing and local SGD, Mixed precision training
https://projector-video-pdf-converter.datacamp.com/37998/chapter3.pdf
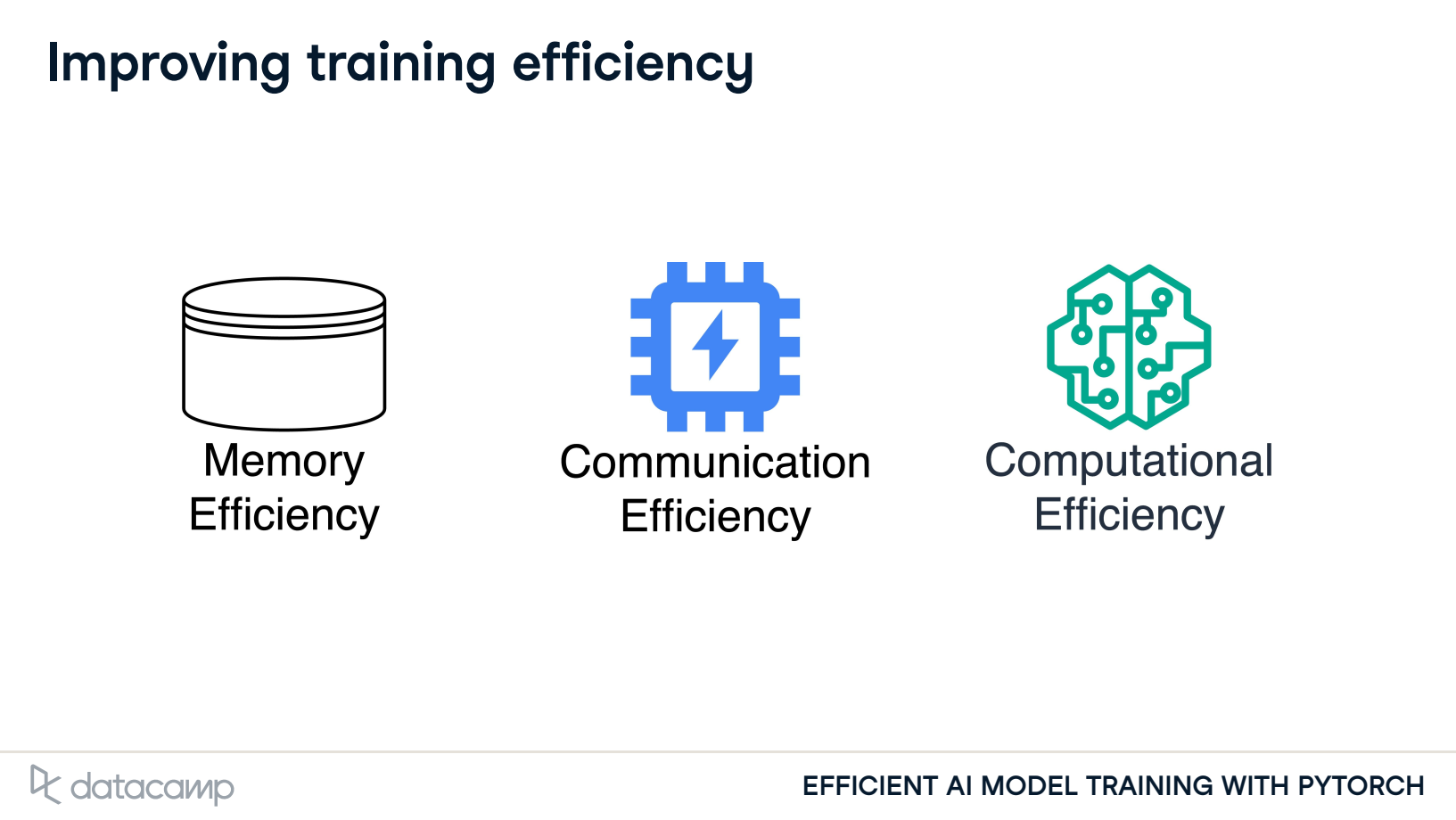
- Improving training efficiency
1. Gradient accumulation improves memory efficiency

- The problem with large batch sizes

- How does gradient accumulation work?
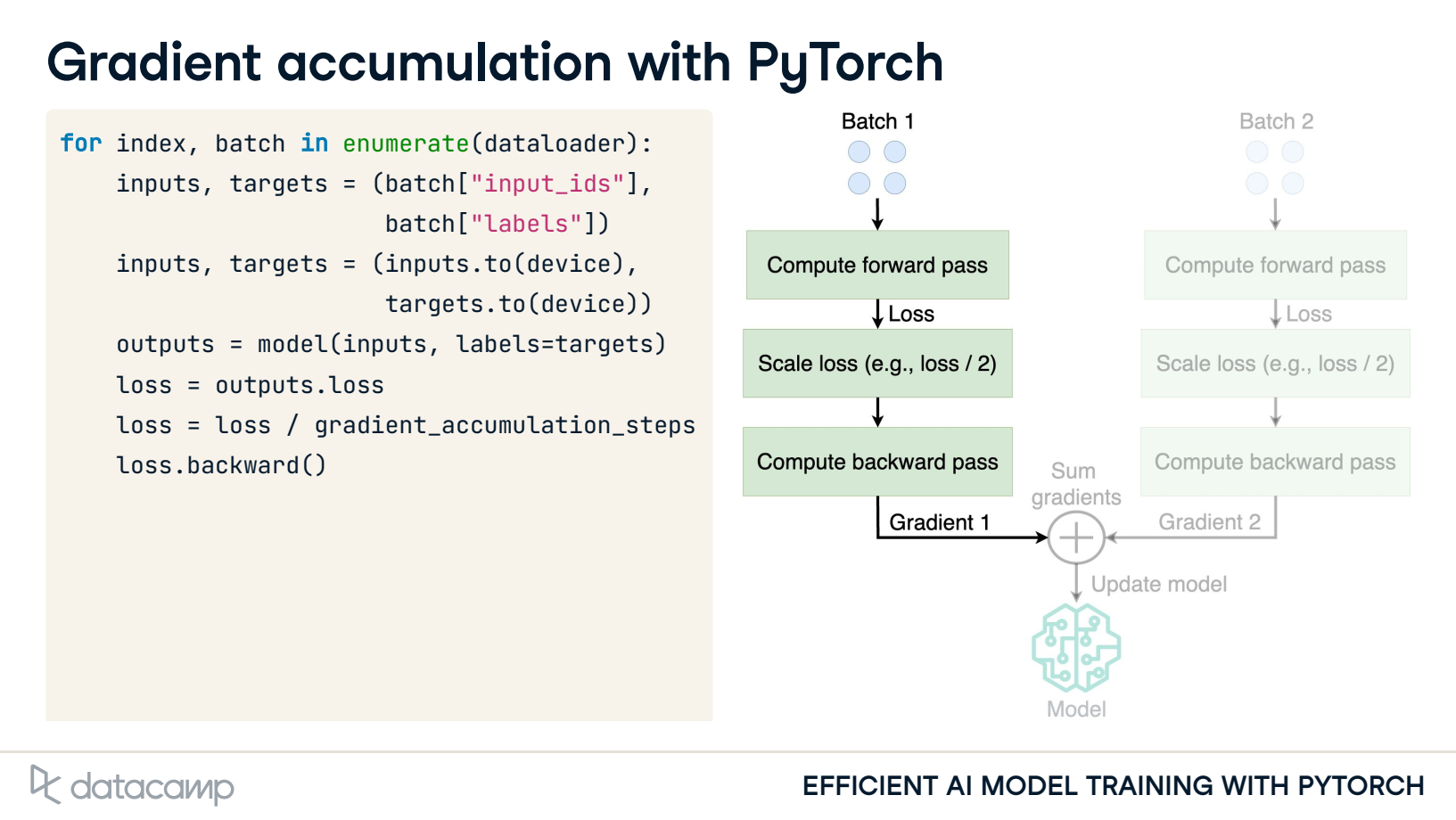
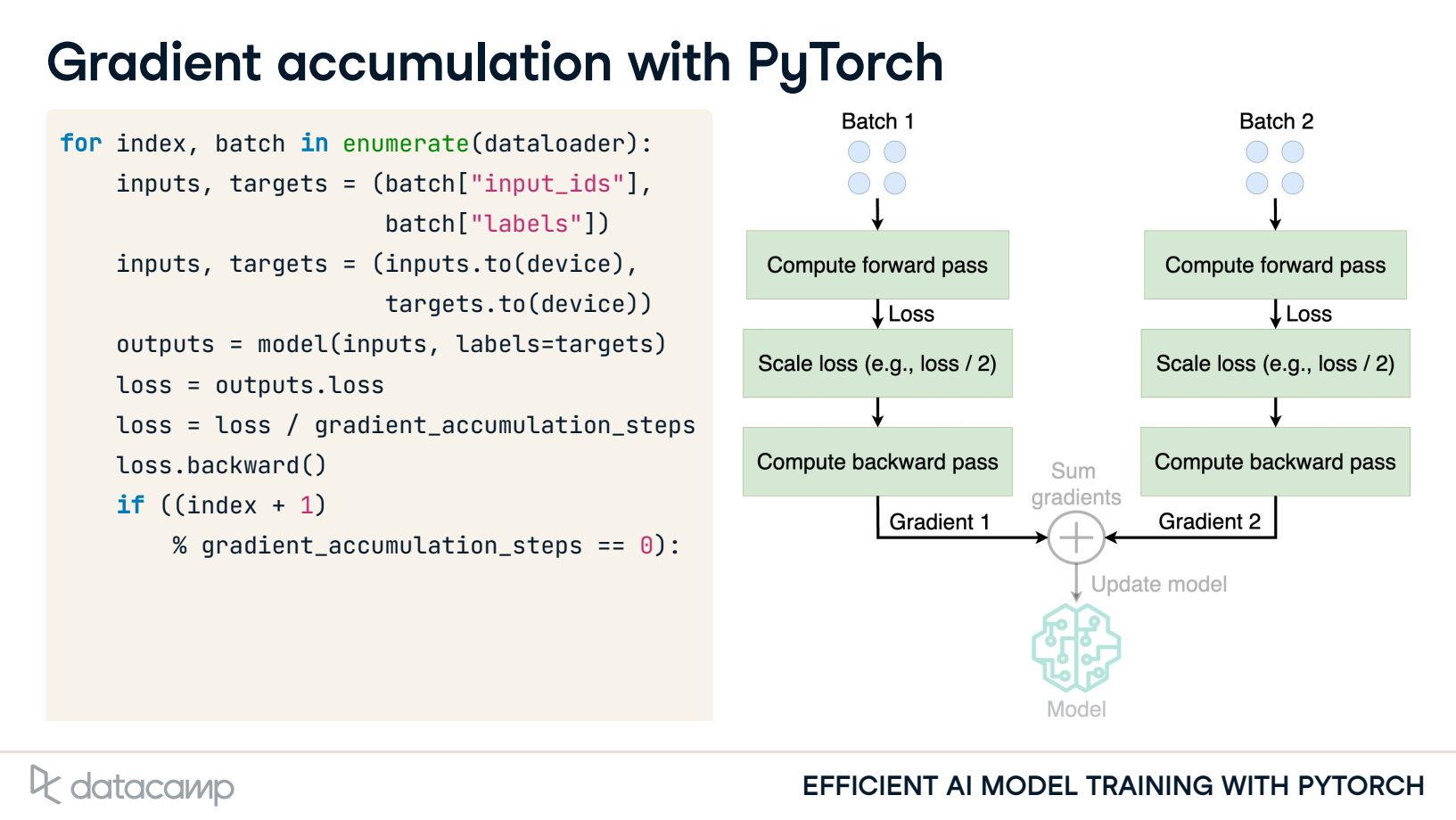
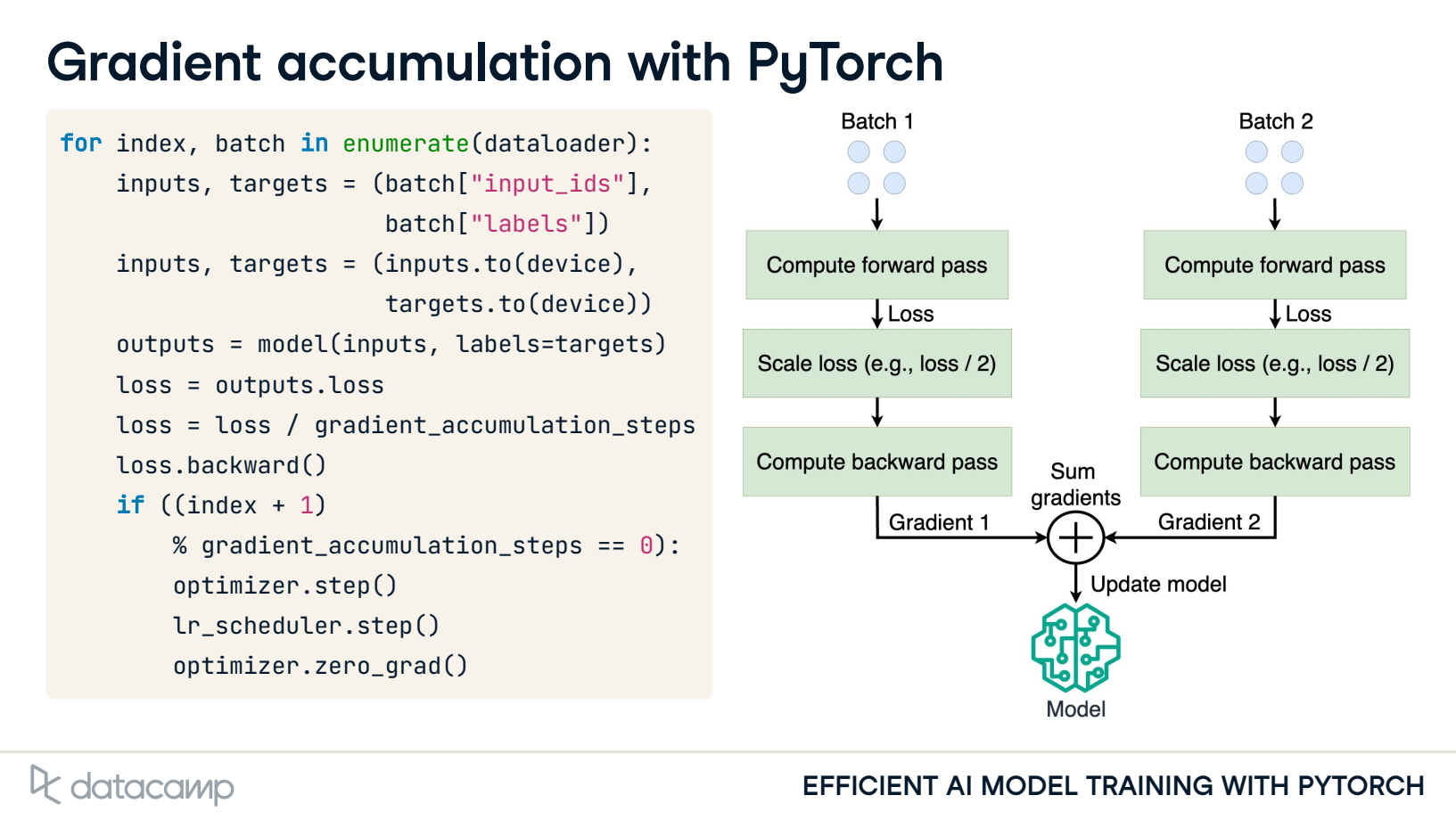
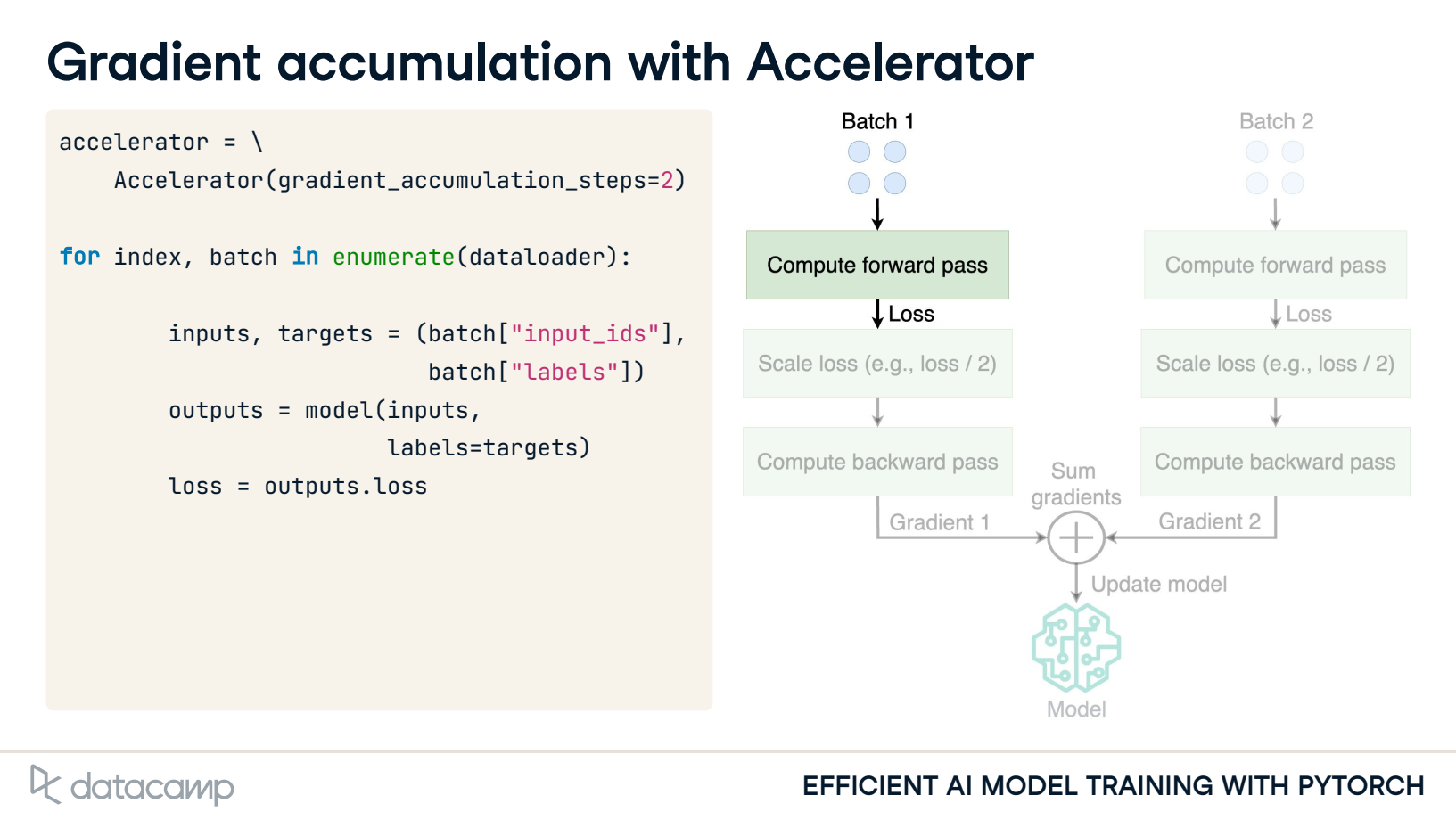
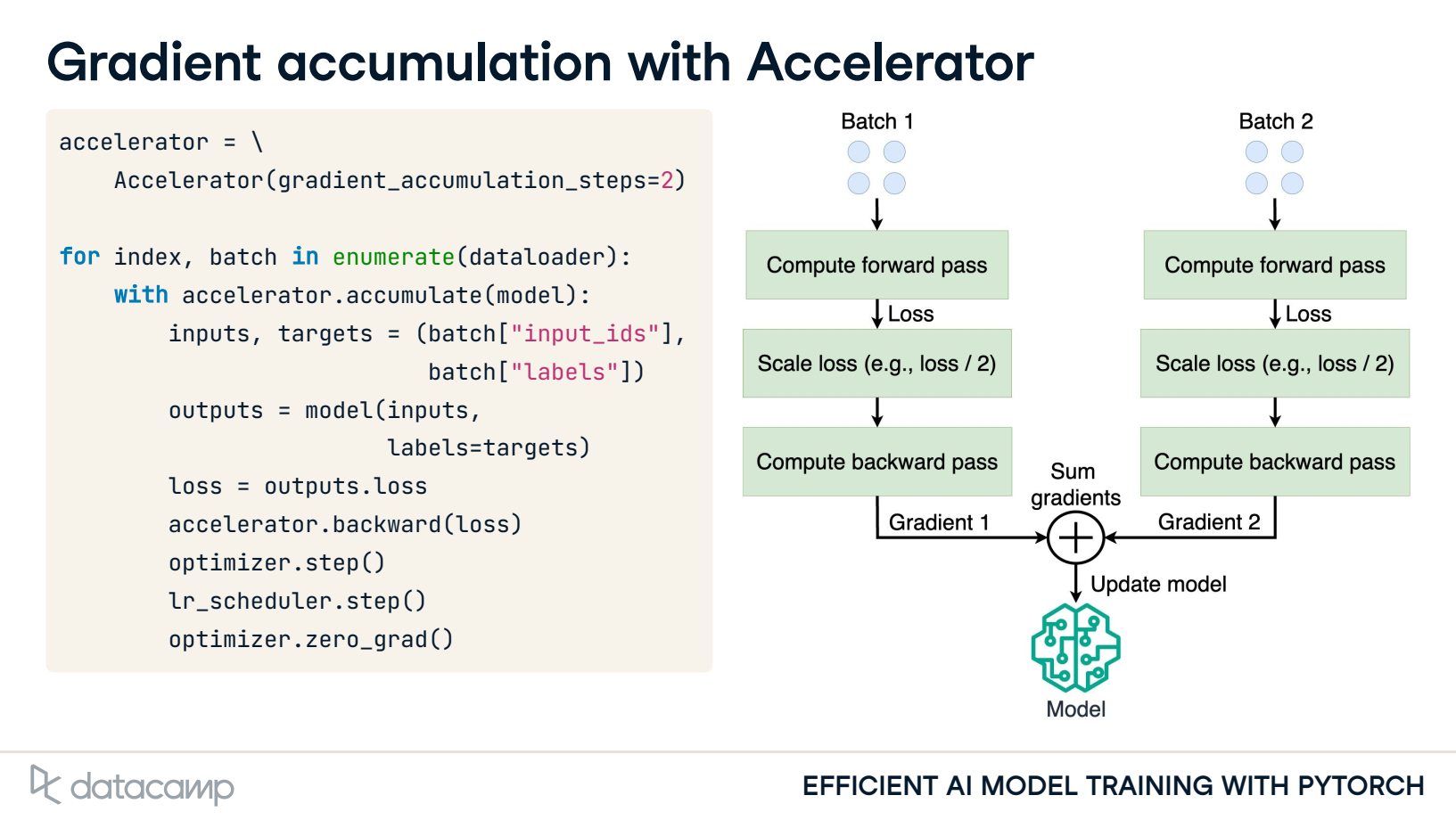
Gradient accumulation: Sum gradients over smaller batches
Update model parameters after summing gradients

- From PyTorch to Accelerator

2. Gradient accumulation with PyTorch
3. Gradient accumulation with Accelerator




4. Gradient accumulation with Trainer

References
[1] Yongqiang Cheng (程永强), https://yongqiang.blog.csdn.net/
[2] Gradient accumulation, Gradient checkpointing and local SGD, Mixed precision training, https://projector-video-pdf-converter.datacamp.com/37998/chapter3.pdf