07-ES分布式搜索引擎高级
学习目标
- 能够使用function_score修改文档得分
- 能够说出深度分页的方案
- 能够使用Java Client实现高亮显示
- 能够使用Java Client测试地理坐标查询
- 能够使用Java Client测试聚合查询
- 能够说出实现同义词的方案
- 能够说出自动补全方案
- 能够完善商城项目商品搜索功能
- 能够实现商城项目自动补全功能
1 搜索高级
1.1. 修改文档得分
1.1.1 function_score
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。例如,我们搜索 "手机",结果如下:
_score:文档与用户搜索的关键字的相关度得分
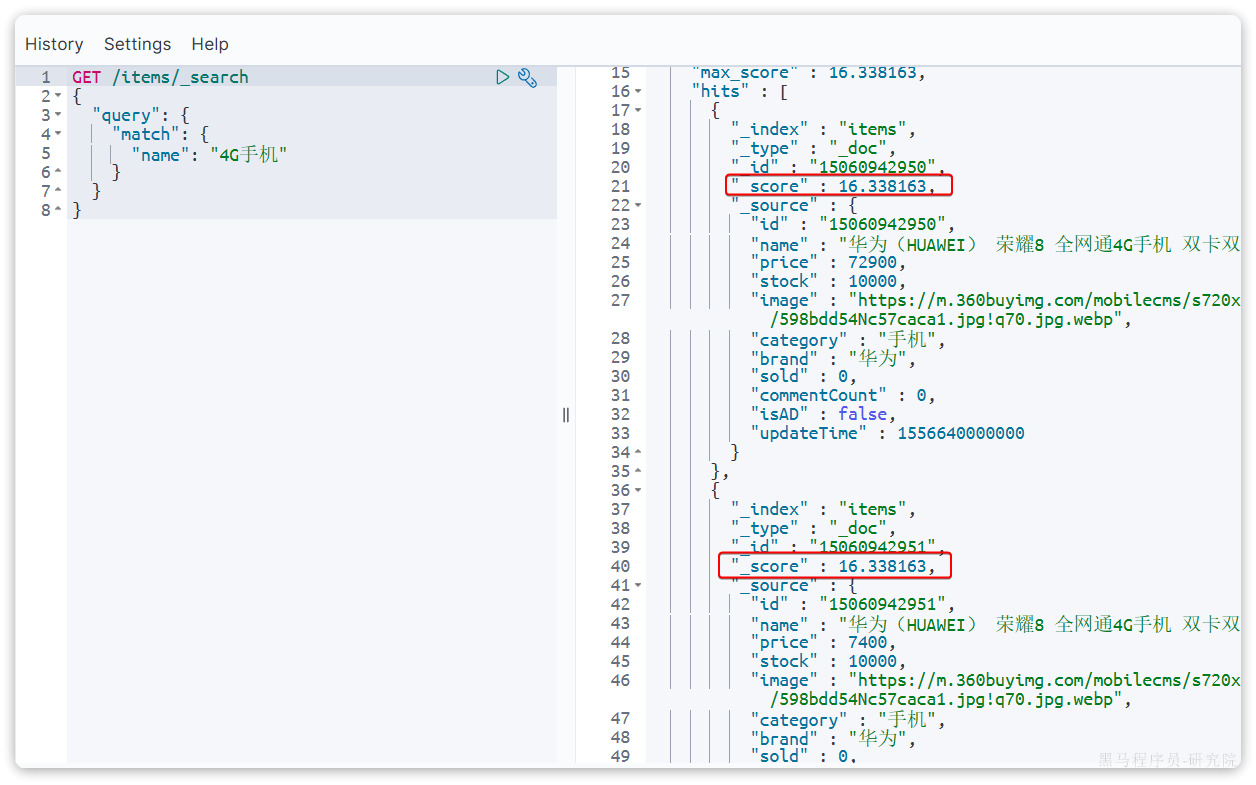
在实际业务需求中,常常会有竞价排名的功能。不是相关度越高排名越靠前,而是掏的钱多的排名靠前。
例如在百度中搜索Java培训,排名靠前的就是广告推广:
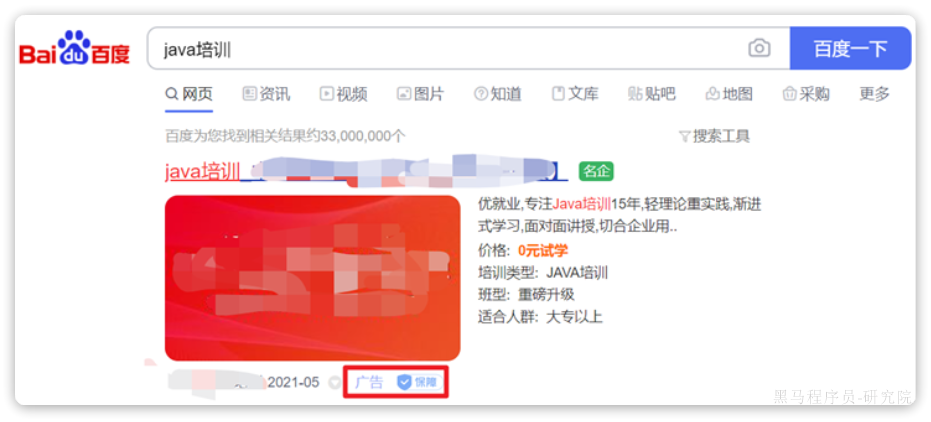
要想人为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
一个例子:给小米这个品牌的手机算分提高十倍,分析如下:
- 过滤条件:品牌必须为小米
- 算分函数:常量weight,值为10
- 算分模式:相乘multiply
GET /items/_search
{"query": {"function_score": {"query": {"match": {"name":"手机"}}, "functions": [{"filter": { "term": {"brand": "小米"}},"weight": 10 }],"boost_mode": "multiply"}},"from": 0,"size": 10
}从结果可以看到小米手机排在前边,因为对品牌为“小米”的文档得分在原有分值基础上乘以10,分值越大越排在前边。function score的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
本例中function_score的语法如下:
function score 查询中包含四部分内容:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
-
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果,适用于那些需要根据某个数值字段来影响文档排序的情况,例如根据产品的价格、文章的阅读量或者用户的活跃度来对结果进行评分。
- random_score:以随机数作为函数结果,用于测试或某些特定的用例,比如创建一个随机排序的效果
- script_score:自定义算分函数算法,允许你在查询时动态地编写脚本来计算每个文档的分数
- boost_mode运算模式:决定了如何将评分函数的结果与基础查询得分相结合,包括:
-
- multiply:评分函数的结果与基础查询的得分相乘。这是默认行为,适用于希望评分函数增强或减弱基础查询得分的情况。
- replace:评分函数的结果将完全替换基础查询的得分。这意味着最终得分将完全基于评分函数的结果,而不考虑基础查询的原始得分。
sum:评分函数的结果与基础查询的得分相加。这使得评分函数的结果直接增加到基础查询得分上,适合于希望累加评分因素的情况。avg:评分函数的结果与基础查询的得分取平均值。这种方式适用于希望平衡基础查询得分与评分函数得分的情况。
算分函数的其它选项,比如:field_value_factor、script_score大家使用AI自学。
示例2:将下边的查询改为算分函数查询,品牌为“爱氏晨曦”排在前边
GET /items/_search
{"from" : 0,"query" : {"multi_match" : {"fields" : [ "name", "category" ],"query" : "脱脂牛奶"}},"size" : 5
}1.1.2 Java Client
使用Java Client实现算分函数查询
@Test
void testFunctionScoreQuery() throws Exception {//构建请求SearchRequest.Builder builder = new SearchRequest.Builder();//设置索引builder.index("items");//设置查询条件SearchRequest.Builder searchRequestBuilder = builder.query(q -> q.functionScore(f -> f.query(q1 -> q1.match(m -> m.field("name").query("手机"))).functions(fn -> fn.filter(f1 -> f1.term(t -> t.field("brand").value("小米"))).weight(10d)).boostMode(FunctionBoostMode.Multiply))).from(0).size(10);SearchRequest build = searchRequestBuilder.build();//执行请求SearchResponse<ItemDoc> searchResponse = esClient.search(build, ItemDoc.class);//解析结果handleResponse(searchResponse);
}1.2. 深度分页
1.2.1 深度分页问题
前边我们学习分页查询是通过修改from、size参数控制返回的分页结果,类似于mysql中的limit ?, ?
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
比如一个索引库中有100000条数据,分别存储到4个分片,每个分片25000条数据。现在每页查询10条,查询第100页。那么分页查询的条件如下:
GET /items/_search
{"from": 990, // 从第990条开始查询"size": 10, // 每页查询10条"sort": [{"price": "asc"}]
}从语句来分析,要查询第990~1000名的数据。
从实现思路来分析,是将所有数据排序,找出前1000名,截取其中的990~1000的部分。但问题来了,我们如何才能找到所有数据中的前1000名呢?
要知道每一片的数据都不一样,第1片上的第900~1000,在另1个节点上并不一定依然是900~1000名。所以我们只能在每一个分片上都找出排名前1000的数据,然后汇总到一起,重新排序,才能找出整个索引库中真正的前1000名,此时截取990~1000的数据即可。如图:
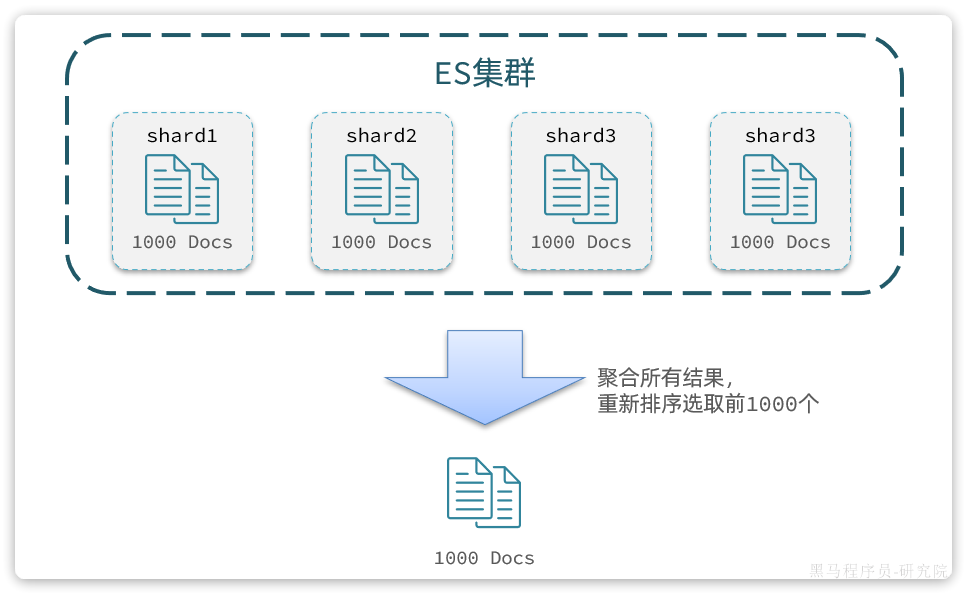
试想一下,假如我们现在要查询的是第1000页数据呢,是不是要找第9990~10000的数据,那岂不是需要把每个分片中的前10000名数据都查询出来,汇总在一起,在内存中排序?如果查询的分页深度更深呢,需要一次检索的数据岂不是更多?
由此可知,当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,特别是在 from 值非常大的情况下。这是因为Elasticsearch需要先跳过前面的所有文档才能获取到所需的文档,这可能导致大量的磁盘I/O操作和CPU使用率。
因此elasticsearch会限制from+ size 请求:
size参数的最大值:- 默认情况下,
size参数的最大值被限制为 10,000。这意味着每次查询最多只能返回 10,000 条记录。 from参数的最大值:- 默认情况下,
from参数的最大值也被限制为 10,000。这意味着您不能请求超过第 10,000 条记录之后的数据。
这意味着,理论上,您可以查询的最大页数是 10,000 / size。例如,如果 size 设置为 100,则最多可以查询 100 页。
1.1.2 search after
针对深度分页,elasticsearch提供了两种解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始查询下一页数据。官方推荐使用。scroll滚动查询:原理将排序后的文档id形成快照,保存下来,基于快照做分页。官方已不推荐使用。
详情见文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/paginate-search-results.html
search after举例:查询第一页:
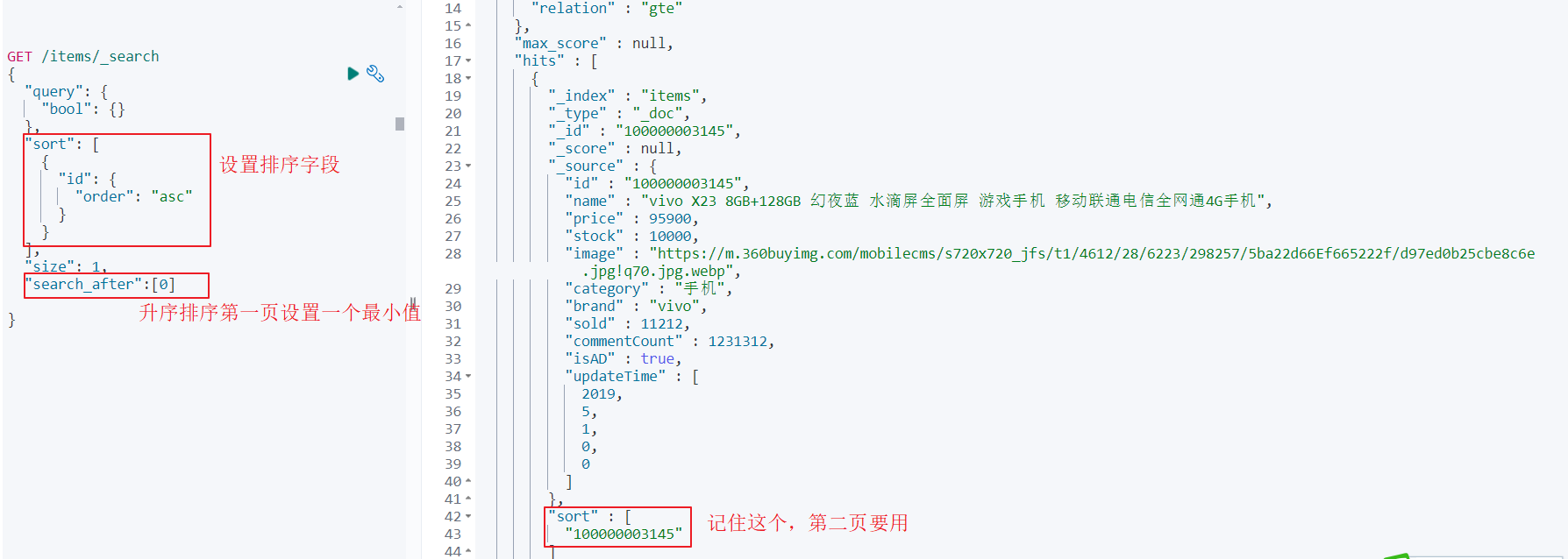
查询第二页:
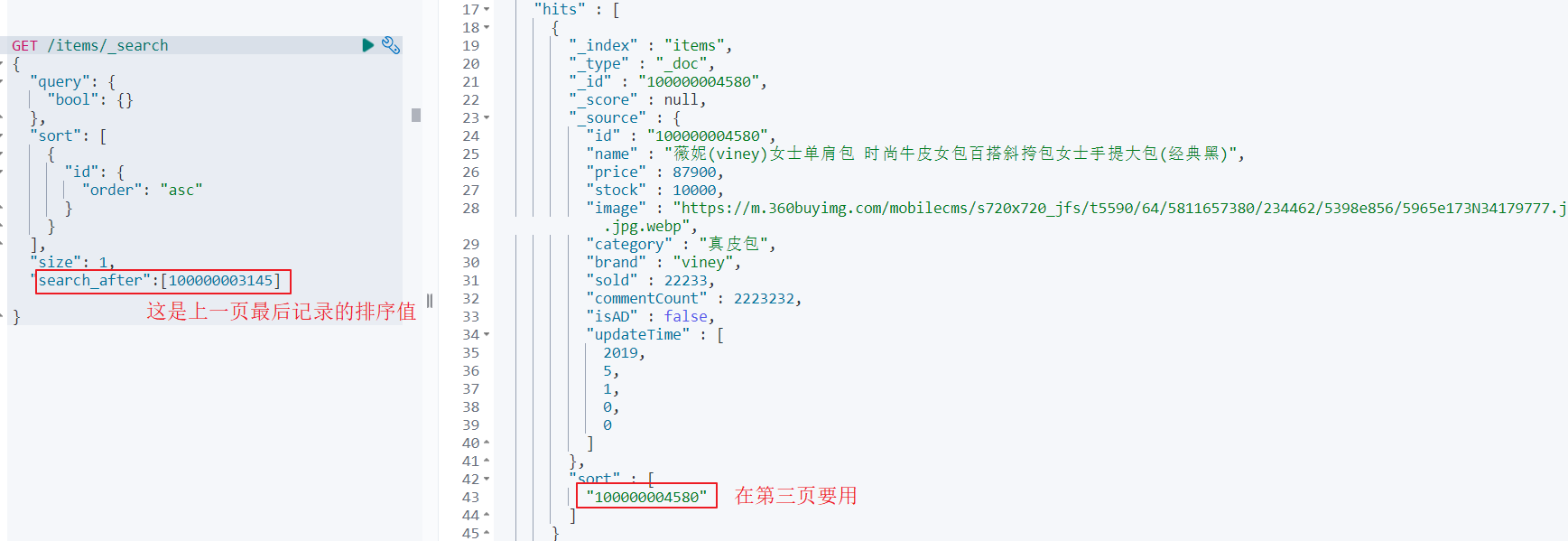
如何使用search_after实现降序排序呢,排序字段是ID?
第一页的search_after值就需要设置一个最大值
GET /items/_search
{"query": {"bool": {}},"sort": [{"id": {"order": "desc"}}],"size": 10, "search_after":[999999999999]
}下边使用Java client实现深度分页,请大家自行测试。
@Test
void testSearchAfter() throws IOException {// 1.创建RequestSearchRequest.Builder builder = new SearchRequest.Builder();builder.index("items");builder.query(q -> q.bool(b -> b)).sort(s1 -> s1.field(f -> f.field("id").order(SortOrder.Asc))).searchAfter("0").size(1);SearchRequest request = builder.build();SearchResponse<ItemDoc> response = esClient.search(request, ItemDoc.class);// 解析响应handleResponse(response);}总结:
大多数情况下,我们采用普通分页就可以了。查看百度、京东等网站,会发现其分页都有限制。例如百度最多支持77页,每页不足20条。京东最多100页,每页最多60条。
因此,一般我们采用限制分页深度的方式即可。
1.3.地理坐标查询
1.3.1 介绍
所谓的地理坐标查询,其实就是根据经纬度查询,官方文档
常见的使用场景包括:
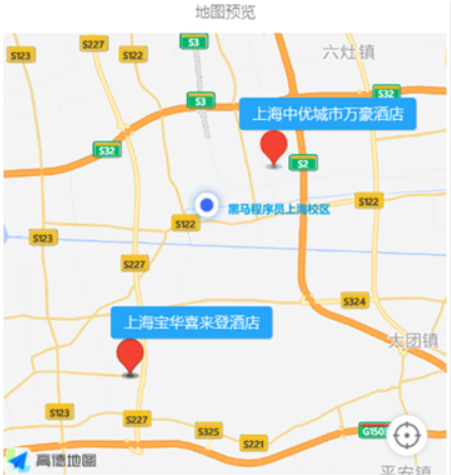
- 携程:搜索我附近的酒店
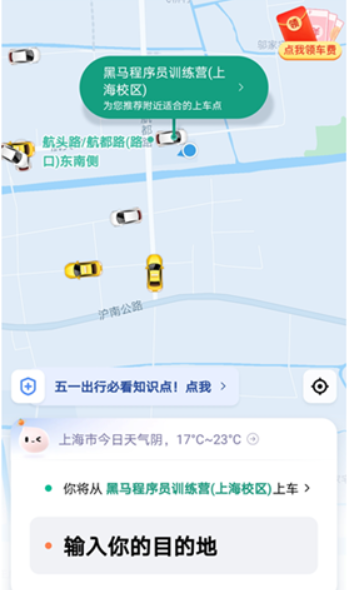
- 滴滴:搜索我附近的出租车
- 微信:搜索我附近的人
找附近的酒店:
打车:
1.3.2. 矩形范围查询
1.3.2.1 语法
矩形范围查询,也就是geo_bounding_box查询,查询坐标落在某个矩形范围的所有文档:
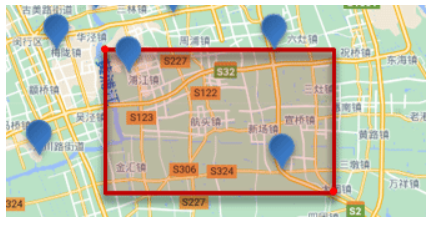
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
语法如下:
// geo_bounding_box查询
GET /indexName/_search
{"query": {"geo_bounding_box": {"FIELD": {"top_left": { // 左上点"lat": 31.1,"lon": 121.5},"bottom_right": { // 右下点"lat": 30.9,"lon": 121.7}}}}
}1.3.2.2 向索引添加坐标值
下边进行测试:
- 首先向索引添加坐标值
添加映射:
PUT /items/_mapping
{"properties": {"location": {"type": "geo_point"}}
}设置坐标值:
首先找到坐标值,我们使用高德地图取坐标点。访问: