让 ETL 更懂语义:DataWorks 支持数据集成 AI 辅助处理能力
在生成式 AI 浪潮下,数据不再只是“被搬运的原料”,更应是“可理解、可推理、可挖掘价值”的智能资产。然而,传统 ETL(Extract-Transform-Load)流程仍停留在结构化数据处理层面,面对海量文本、日志、反馈等非结构化数据时,往往依赖人工标注或复杂开发链路,效率低、成本高、响应慢。
为此,阿里云大数据开发治理平台 DataWorks 数据集成全新智能化升级,以“ AI 释放数据价值”为核心,正式推出 AI 辅助处理能力,并将该功能在阿里云全球所有地域全面开放!将大模型语义理解、AI 智能分析能力深度融入离线同步任务的数据集成任务,真正实现“让每一条数据流都能思考”。
核心能力-开箱即用的智能 ETL 引擎
DataWorks Serverless 资源组全新升级,支持大模型一键部署与高效调用!现已支持 Qwen3 系列、DeepSeek 系列及 Embedding 模型,提供多种 GPU 规格按需选用,按量付费,灵活成本。通过 AI Function 可便捷调用模型服务,小尺寸模型推理性能提升近 10 倍,并支持使用 DataWorks Serverless CU 资源抵扣,助力 AI 应用快速构建与弹性扩展。
DataWorks 数据集成现已支持在离线同步任务中直接调用大模型服务,用户无需部署模型、无需编写代码、无需额外付费,只需通过自然语言提示(Prompt),即可完成复杂的数据清洗、增强与语义结构化操作。
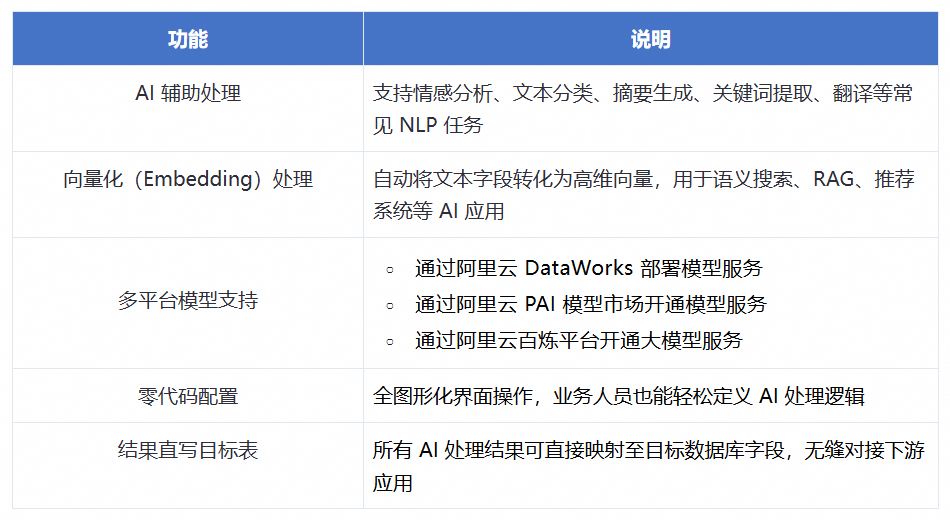
整个过程完全托管,且 AI 处理功能本身不额外收费 —— 您只需为同步任务消耗的计算资源付费,与其他普通离线同步任务计费方式完全一致。
适用场景-多行业多场景赋能企业 AI 落地
智能数据处理在数据同步 ETL 流程中可广泛应用于多个企业场景,通过情感分析、摘要生成、关键词提取、翻译和向量化等能力提升数据处理效率与洞察深度。这些应用可以显著提升了企业的决策支持能力和运营智能化水平。
1、电商客服场景:用户反馈分析与情感分类
示例,客户留言:“快递太慢了,等了半个月还没到!”

👉 自动归类千万级评论,支撑运营决策与服务质量优化。
2、智能汽车场景:设备日志分析与预测性维护
示例,日志内容:“The break pump pressure:abnormal; sensor exceeding : 15%”
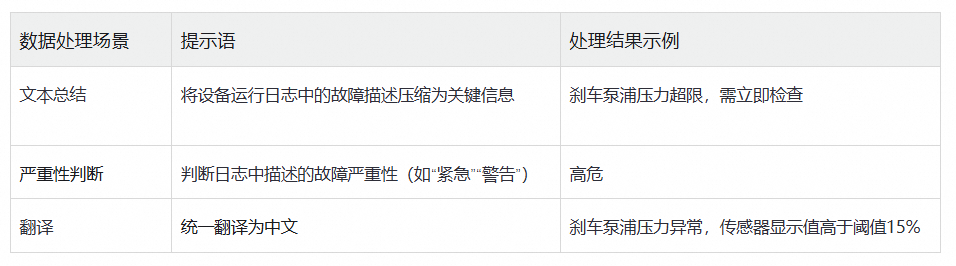
👉 将非结构化日志转为结构化告警信息,助力预测性维护系统快速响应。
3、供应链场景:供应商反馈分析与风险预警
示例,供应商邮件:“We are unable to fulfill the order due to a shortage of raw materials.”
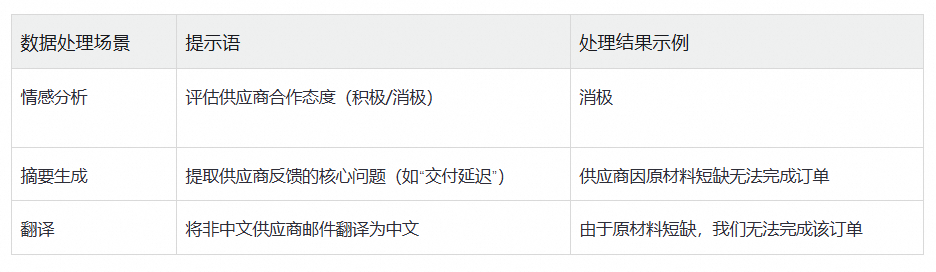
👉 自动识别交付风险,提前触发备选供应商调度机制。
4、法律场景:合同条款分析与风险标注
示例,合同条款:“In the event of force majeure, the delivery deadline may be extended.”

👉 提升法务审查效率,降低合同履约风险。
案例说明
接下来介绍如何使用AI辅助处理功能,将数据来源表中feedback_info列的数据翻译为英文并同步至目标表。
来源表数据准备
CREATE TABLE customer_feedback (id BIGINT PRIMARY KEY,device STRING,feedback_info STRING,pt INT
)
PARTITIONED BY (pt)
DISTRIBUTED BY HASH(id)
WITH (table_type='Duplication');INSERT INTO customer_feedback (id, device, feedback_info, pt)
VALUES
(8, 'Huawei MateBook D14', '价格实惠,适合学生党,性能够用', 2020),
(1, 'iphone', '这个商品还行,我用了1年', 2013),
(10, 'Bose QuietComfort 35 II', '降噪耳机中的经典,舒适度满分', 2021);
一、创建离线同步任务
进入DataWorks工作空间列表页,在顶部切换至目标地域,找到已创建的工作空间,单击操作列的快速进入 > Data Studio,进入Data Studio。
在左侧导航栏单击按钮,进入数据开发页面,在项目目录右侧单击+,选择新建节点 > 数据集成 > 离线同步,进入新建节点对话框。设置节点路径、数据来源去向和节点名称后,单击确认,创建离线同步节点。
本文以Hologres同步至Hologres为例,介绍离线同步任务中的AI辅助处理功能。
二、配置同步任务
创建离线同步节点后,会自动进入任务编辑页面,您需要在此页面配置如下信息:
1、数据源
分别配置数据同步任务的数据来源和数据去向。
类型:创建离线同步任务步骤中已选择的数据来源和去向的数据源类型,不支持修改,如需修改请重新创建离线同步任务。
配置方式:
快速配置:手动配置数据来源与数据去向的连接信息,详细的配置参数解释可在配置界面查看对应参数的文案提示。
使用已有数据源:请在数据源参数后的下拉列表中选择已创建的数据源。
说明
数据源中只展示对应类型的数据源。

2、运行资源
选择同步任务所使用的资源组。如果使用 Serverless 资源组,您还可以为该任务分配资源占用 CU 数。
选择资源组后,数据集成将自动检测资源组与数据来源、数据去向的连通性,您也可以手动单击连通性检查。

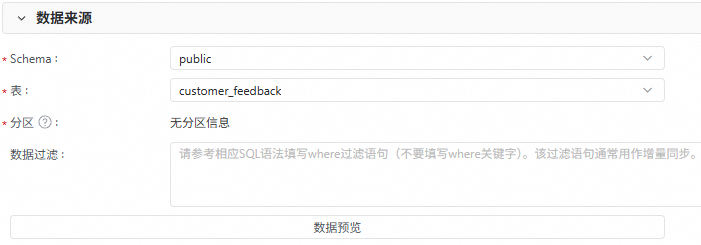
3、数据来源
配置数据来源具体待同步的表信息,如Schema、表、分区和数据过滤条件等。您可以单击数据预览,查看待同步的具体数据。
4、数据处理
在数据处理区域,您可以开启数据处理能力,数据处理能力需要更多的计算资源,会增加任务的资源占用开销。
单击添加节点,当前支持字符串替换和AI辅助处理。本案例以AI辅助处理为例进行介绍。
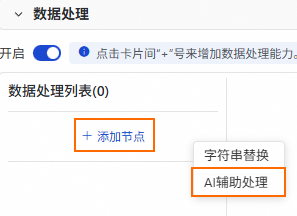
配置AI辅助处理相关信息。
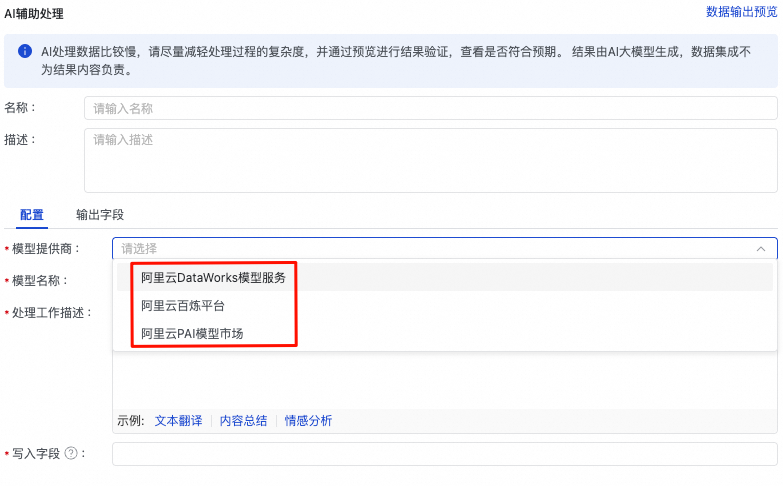
关键参数解释如下:
| 参数 | 描述 |
| 模型提供商 | 支持阿里云DataWorks模型服务、阿里百炼平台、阿里云PAI模型市场。 |
| 模型名称 | 负责智能数据处理的模型,按需选择。 |
| API Key | 访问模型的API KEY,请前往模型提供商获取。 阿里云百炼平台:获取百炼API Key。 阿里云PAI模型市场:前往部署的EAS任务,进入在线调试,获取Token,将其作为API KEY填写到此处。 |
| 处理工作描述 | 请使用自然语言描述对来源字段的处理,字段名以 |
| 写入字段 | 此处请输入存储结果字段的名称,如果对应字段不存在,将自动新增一个字段。 |
说明
本案例的示例配置中,会将来源表的feedback_info字段翻译成英文,并存储到feedback_processed字段中。
您可以单击AI辅助处理区域右上角的数据输出预览,查看输出的最终数据效果。
(可选)您可以配置多个先后按顺序执行的数据处理流程。

5、数据去向
配置数据同步的目标表信息,例如Schema、表名、分区等。
您可以单击一键生成目标表结构,快速生成目标表。
如果目标端中已存在表用于接收数据,则按需选择即可。
配置写入模式以及写入冲突策略。
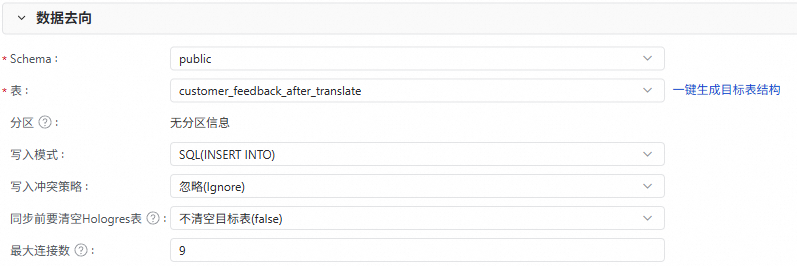
配置同步前是否要清空Hologres表中的已有数据。
(可选)配置最大连接数。
最大连接数仅在写入模式为SQL(INSERT INTO)下生效,在开启任务时请确保Hologres实例有充足的空闲连接。一个任务最多使用9个连接。
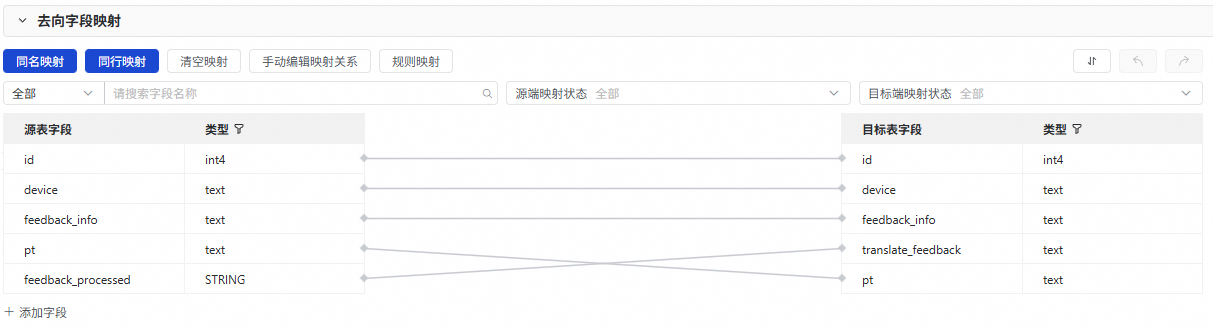
6、去向字段映射
配置完成数据来源、数据处理和数据去向后,会在此处展示来源与去向表间的字段映射关系,默认为同名映射和同行映射,你也可以按需进行调整。
说明
本案例中除了将源表已有字段(id、device、feedback_info、pt)同名映射外,还需要手动将源表中存储翻译后结果的feedback_processed字段,映射至目标表的translate_feedback字段中。
三、调试任务
在离线同步任务的编辑窗口右侧,单击调试配置,配置调试本节点使用的资源组和相关脚本参数。
单击节点顶部工具栏的保存,然后单击运行,等待运行结束,查看运行结果是否成功,您可以前往目标端数据库查看表数据是否符合预期。
四、调度配置
若离线同步节点需要周期性调度执行,您需要在节点右侧的调度配置中设置调度策略,配置相关的节点调度属性。
五、节点发布
请单击节点工具栏的发布图标唤起发布流程,通过该流程将任务发布至生产环境。只有在发布至生产环境后,才会进行周期性调度。
后续操作:任务运维
节点发布后,您可以在发布流程中单击补数据或去运维。
补数据:仅支持对当前节点进行补数据。如果需要更复杂的补数据功能请前往运维中心操作。更多信息,请参见执行补数据并查看补数据实例(新版)。
去运维:任务发布后将自动进入运维中心,您可在运维中心查看任务运行情况,或手动触发任务执行。详情请参见:运维中心。