ICCV2025 | GLEAM:通过全局-局部变换增强的面向视觉-语言预训练模型的可迁移对抗性攻击
GLEAM: Enhanced Transferable Adversarial Attacks for Vision-Language Pre-training Models via Global-Local Transformations
- 引言-Introduction
- 相关工作-Related Work
- 方法-Methodology
- 整体概述与攻击框架
- 问题定义与目标
- GLEAM 三大核心模块设计
- 基于 NURBS 的局部特征增强(LFE)模块
- 全局分布扩展(GDE)模块
- 跨模态特征对齐(CMFA)模块
- 多模态对抗数据增强与优化实现
- 实验-Experiments
- 实验设置
- 跨模型对抗迁移性
- 跨任务对抗迁移性
- 多模态大模型的对抗迁移性
- 消融研究
- 安全启示与防御评估
- 结论-Conclusion
论文链接
GitHub链接
为解决视觉语言预训练(VLP)模型黑盒对抗攻击中数据增强不足、全局语义结构破坏导致的对抗迁移性差问题,研究者提出GLEAM(Global-Local Enhanced Adversarial Multimodal attack)框架,该框架整合局部特征增强(LFE)、全局分布扩展(GDE) 和跨模态特征对齐(CMFA) 三大模块,在 Flickr30K、MSCOCO 等数据集上的图像文本检索(ITR)、视觉定位(VG)、图像描述(IC)任务中表现优异,相比现有方法,ITR 任务攻击成功率提升 10%-30%,对 Claude 3.5 Sonnet、GPT-4o 等大模型的迁移性提升超 30%,为 VLP 模型脆弱性评估及安全系统设计提供关键工具。
引言-Introduction
- VLP模型的价值与现状
- 核心能力:视觉语言预训练(VLP)模型通过大规模图文配对数据训练,构建了视觉与文本模态的联合语义表示空间,在图像文本检索、图像描述、视觉定位、视觉推理等下游任务中展现出卓越性能。
- 关键问题:现有研究表明,VLP 模型极易受到对抗攻击——当输入样本被施加精心设计的扰动时,模型会输出错误结果,导致下游任务性能急剧下降,这对其在安全关键场景中的可靠性构成严重威胁。因此,研究多模态对抗样本生成对发现跨模态表示缺陷、开发鲁棒 VLP 框架至关重要。
- 现有 VLP 模型对抗攻击方法的局限
- 早期单模态与跨模态攻击的不足
- 单模态攻击缺陷:早期方法(如基于图像的 PGD、基于文本的 BERT 攻击)因未利用跨模态对齐信息,应用于 VLP 框架时存在固有局限性。
- 首代跨模态攻击的局限:Zhang 等人提出的 Co-Attack 虽通过跨模态交互机制联合优化对抗图文对,在白盒场景取得一定成功,但依赖单一样本对,易过拟合到特定对齐模式,导致黑盒场景下跨模型迁移性极差。
- 后续提升迁移性方法的问题
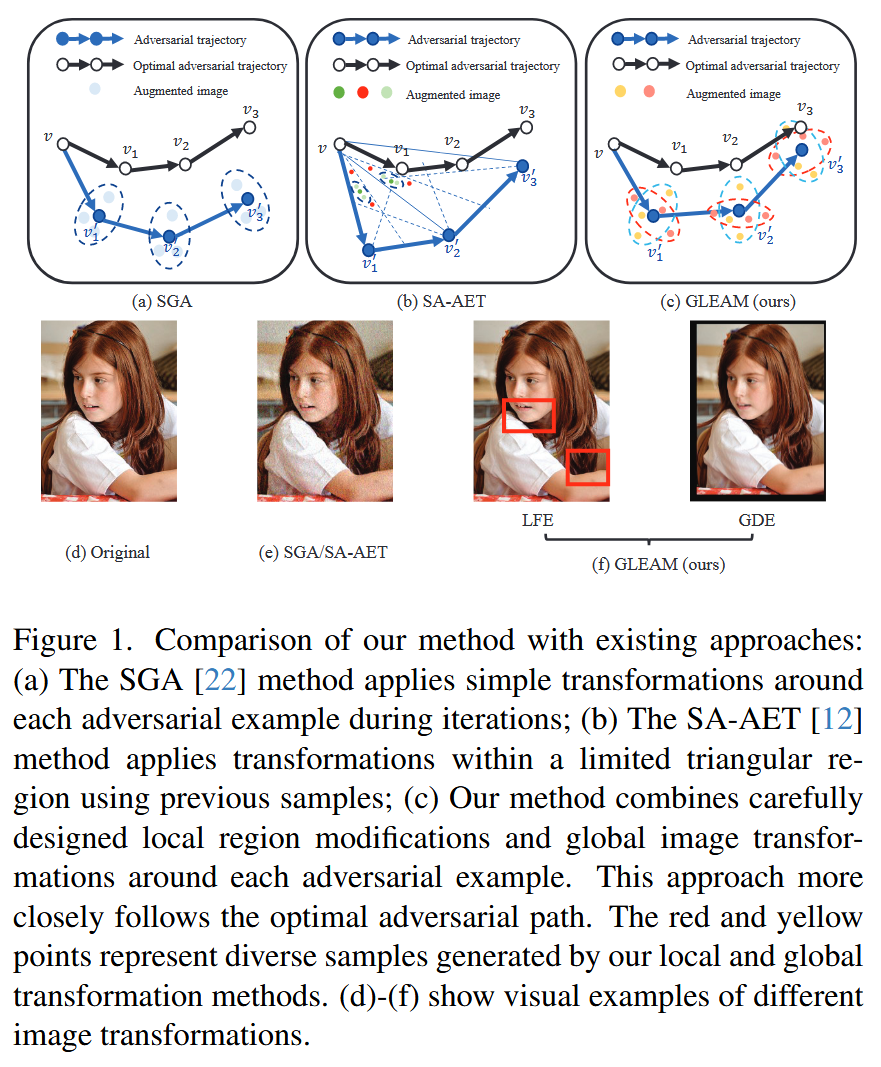
- SGA 方法的不足:SGA 利用图文多对多对应关系(如单图多文本描述)和深度模型尺度不变性构建多尺度图像以增加样本多样性,但在多步迭代生成对抗样本时,数据增强策略仅依赖多尺度缩放和噪声添加,常破坏图像全局语义信息与几何结构(如图1(e)),导致优化过程难以准确利用模型梯度信息,偏离最优攻击路径,限制对抗样本向其他模型的迁移性。
- DRA 与 SA-AET 的局限:二者虽引入创新采样机制(在当前对抗样本与前两步生成样本构成的“对抗子三角”内采样,如图1(b)),并保留 SGA 的多尺度与噪声增强策略以提升迁移性,但仍有两大问题:一是采样空间局限于子三角,可能引入路径采样偏倚;二是继承自 SGA 的增强策略仍会破坏图像全局语义与几何结构,限制其在更广泛场景的泛化能力。
- 共性关键缺陷
现有方法普遍仅依赖最终生成的对抗图像指导对抗文本生成,易导致对抗文本过拟合,进一步降低黑盒环境下的迁移性。综合分析可知,生成高迁移性对抗样本需解决三大科学挑战:- 如何在保持全局语义信息与几何结构的同时,实现多样化局部区域变换;
- 如何系统扩展多样化样本的分布范围,提升覆盖度与迁移性;
- 如何优化利用跨模态特征对齐信息,生成迁移性更强的对抗文本。
- 早期单模态与跨模态攻击的不足
- 本文GLEAM方法的核心设计与优势
- 方法概述
为解决上述挑战,本文提出GLEAM(Global-Local Enhanced Adversarial Multimodal Attack) 框架,通过三大协同组件提升对抗样本迁移性(如图1(c)、1(f)):- 局部特征增强(LFE)模块:可调整局部形状与内容,同时不改变图像语义与结构连贯性,通过在攻击每次迭代生成多种局部调整增强图像,提取更通用的局部特征;
- 全局分布扩展(GDE)模块:利用自适应随机缩放与上下文感知填充技术,在保留几何结构的同时增加样本多样性,系统拓宽对抗分布空间;
- 跨模态特征对齐(CMFA)模块:不同于现有方法仅依赖最终对抗图像,该模块利用优化轨迹中的所有中间视觉对抗样本指导文本生成,减少模态特异性过拟合。
- 实验验证方向
- 评估场景:在 Flickr30K 和 MSCOCO 数据集上,针对图像文本检索(ITR)、视觉定位(VG)、图像描述(IC)三大任务评估GLEAM性能,并测试其对 Claude 3.5 Sonnet、GPT-4o 等大模型的攻击效果。
- 核心结果:在 ITR 任务中,GLEAM 较现有最优方法攻击成功率提升10%-30%;在 VG 和 IC 任务中,能有效破坏特征对齐与输出质量;攻击大模型时,迁移性提升超 30%。
- 方法概述
- 本文核心贡献
- 提出统一框架,整合图像局部-全局变换与跨模态对齐,用于生成视觉语言任务中的迁移性对抗样本;
- 设计两级图像变换策略,实现多样化局部修改的同时保留全局语义,并系统扩展对抗样本分布;
- 提出利用中间对抗样本指导文本优化的跨模态优化方法,提升一致性与迁移性;
- 通过大量实验证明,在攻击成功率与跨模型迁移性上,GLEAM 达到现有最优性能。
相关工作-Related Work
- 视觉语言预训练(VLP)模型
VLP模型主要分为融合型(Fused) 与对齐型(Aligned) 两大架构,两类模型通过不同方式实现视觉与文本模态的语义关联,并借助特定预训练目标提升对齐效果:- 融合型模型:以 ALBEF、TCL 为代表,先为每种模态单独设计编码器,再通过多模态编码器融合两种模态的表示,实现跨模态信息交互;
- 对齐型模型:以 CLIP、ALIGN 为代表,保持各模态编码器独立,通过对比学习方法对齐视觉与文本的特征空间,在检索类任务中展现出更强的性能;
- 预训练目标:为进一步提升模态间语义对齐质量,研究人员设计了多种预训练目标,包括掩码特征预测、多模态特征匹配等,这些目标能有效增强模型对跨模态语义关联的捕捉能力。
- 下游视觉语言任务
本文研究聚焦三类核心下游多模态任务,这些任务从不同维度评估 VLP 模型整合视觉与文本信息的能力:- 视觉语言检索(VLR):核心是实现视觉与文本内容的双向匹配,具体包括 “视觉到文本”(根据图像检索对应文本)和 “文本到视觉”(根据文本检索对应图像)两种检索方向;
- 图像描述(IC):任务目标是为输入的视觉图像生成准确、连贯的文本描述,常用 BLEU、METEOR、CIDEr 等指标评估生成文本与参考文本的一致性;
- 视觉定位(VG):要求模型根据给定的文本描述,在图像中精准定位出与描述对应的特定区域,重点考察模型对“文本语义-图像区域”对应关系的理解能力。
- 对抗迁移性:对抗迁移性指在某一模型上生成的对抗样本,能够成功攻击其他模型的能力,该特性对实际黑盒攻击至关重要——在黑盒场景中,攻击者通常无法获取目标模型的内部结构、参数或梯度信息,只能依赖对抗样本的迁移性实现攻击。
- 单模态对抗迁移性的研究方向
针对单模态模型的对抗迁移性优化,研究主要沿四个互补方向展开:- 优化基于方法:如 MI-FGSM、NI-FGSM,通过改进梯度计算方式提升梯度稳定性,帮助生成更具迁移性的对抗样本;
- 输入变换技术:如 DIFGSM、TI-FGSM,通过数据增强(如平移、旋转等)增加对抗样本多样性,间接提升迁移性;
- 特征导向方法:通过修改目标函数,使对抗扰动直接作用于模型中间层表示,减少对特定模型表层特征的过拟合;
- 模型集成策略:整合多个不同架构模型的信息,降低对抗样本对单一模型的依赖性,提升跨模型迁移能力。
- VLP 模型多模态对抗攻击的研究进展
针对 VLP 模型的多模态对抗攻击,方法从 “模态特定型” 向 “跨模态协同型” 演进,具体包括:- 模态特定型攻击:如 Sep-Attack,将文本攻击与图像攻击分开进行,未利用跨模态关联信息,攻击效果与迁移性较差;
- 跨模态协同攻击:如 Co-Attack,通过利用模态间交互信息联合优化对抗图文对,提升了白盒场景攻击效果,但黑盒迁移性仍受限;
- 多样性生成优化:近期研究聚焦通过增加样本多样性提升迁移性,如 SGA 构建图文对变体集合、SA-AET 引入多尺度增强,但现有方法仍难以在多样化与语义完整性间平衡,跨 VLP 架构的鲁棒迁移性仍面临挑战,这也成为本文研究的核心动机。
方法-Methodology
整体概述与攻击框架
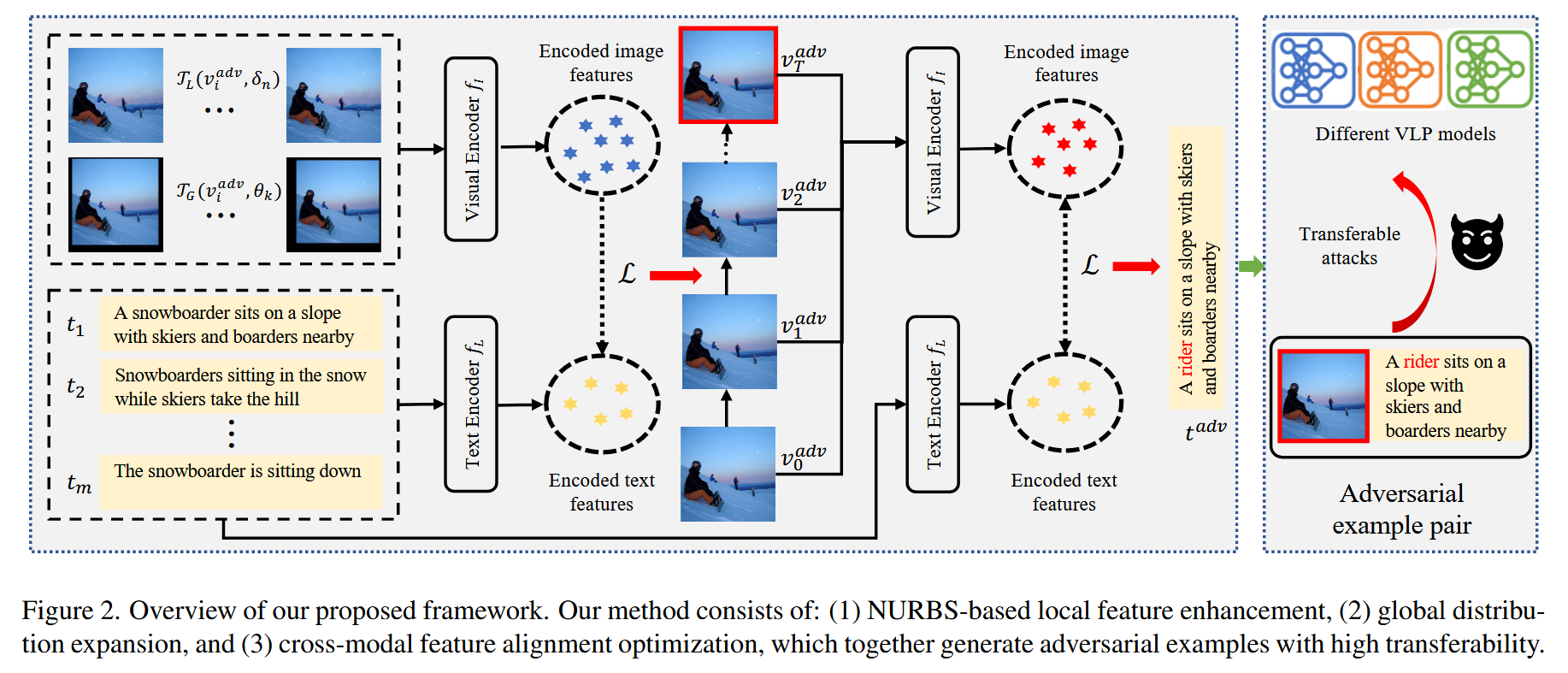
- 核心目标:提出跨模态对抗攻击框架,用于评估视觉语言预训练(VLP)模型的鲁棒性,核心是生成具有高迁移性的对抗样本,以有效暴露黑盒目标模型在多模态处理中的脆弱性。
- 框架逻辑:采用迁移式攻击策略——以完全可访问的代理模型(MsurrM_{surr}Msurr)作为白盒,在其上生成对抗样本,再将这些样本迁移至黑盒目标模型(MtargetM_{target}Mtarget)进行攻击测试。
- 威胁模型设定:
- 对白盒代理模型(MsurrM_{surr}Msurr):攻击者掌握其完整信息,包括架构、参数及梯度信息,可用于构建对抗样本;
- 对黑盒目标模型(MtargetM_{target}Mtarget):攻击者仅能观察输入输出行为,无法获取内部机制、参数或梯度信息。
问题定义与目标
- VLP 模型处理流程
VLP 模型 MsurrM_{surr}Msurr 对图文对 (v,t)(v, t)(v,t) 的处理可形式化为以下公式,其中各组件承担不同模态编码与特征融合功能:
ev=fI(v)et=fL(t)o=fMsurr(ev,et)\begin{array}{rlr} e_{v} &= f_{I}(v) & \\ e_{t} &= f_{L}(t) & \\ o &= f_{M_{surr}}(e_{v}, e_{t}) & \end{array} eveto=fI(v)=fL(t)=fMsurr(ev,et)- fIf_{I}fI:图像编码器,ev∈Rde_{v} \in \mathbb{R}^{d}ev∈Rd 为编码后的图像特征;
- fLf_{L}fL:文本编码器,et∈Rde_{t} \in \mathbb{R}^{d}et∈Rd 为编码后的文本特征;
- fMsurrf_{M_{surr}}fMsurr:多模态融合函数,ooo 为融合后的多模态特征编码。
- 对抗样本生成目标
需生成对抗图文对 (vadv,tadv)(v^{adv}, t^{adv})(vadv,tadv),在满足扰动约束的前提下最大化损失函数 JJJ,具体约束与优化目标如下:- 图像对抗样本(vadvv^{adv}vadv):需位于以原始图像 vvv 为中心、ϵv\epsilon_vϵv 为边界的 L∞L_\inftyL∞ 范数约束空间内,优化目标为:
vadv=arg maxvadv∈B[v,ϵv]J(vadv,t)v^{adv} = \argmax _{v^{adv} \in B\left[v, \epsilon_{v}\right]} J\left(v^{adv}, t\right)vadv=vadv∈B[v,ϵv]argmaxJ(vadv,t) 其中 B[v,ϵv]={vadv:∥vadv−v∥∞≤ϵv}B[v, \epsilon_{v}] = \{v^{adv}:\left\|v^{adv} - v\right\|_{\infty} \leq \epsilon_{v}\}B[v,ϵv]={vadv:vadv−v∞≤ϵv},定义图像的最大扰动范围。 - 文本对抗样本(tadvt^{adv}tadv):需控制词修改数量不超过 ϵt\epsilon_tϵt,且保持文本语义相似性,优化目标为:
tadv=argmaxtadv∈B[t,ϵt]J(v,tadv)t^{adv} = arg\ max _{t^{adv} \in B\left[t, \epsilon_{t}\right]} J\left(v, t^{adv}\right) tadv=arg maxtadv∈B[t,ϵt]J(v,tadv) 其中 B[t,ϵt]B[t, \epsilon_{t}]B[t,ϵt] 定义文本的最大词修改约束。
- 图像对抗样本(vadvv^{adv}vadv):需位于以原始图像 vvv 为中心、ϵv\epsilon_vϵv 为边界的 L∞L_\inftyL∞ 范数约束空间内,优化目标为:
- 核心设计动机
通过分析现有 VLP 模型对抗攻击方法的缺陷,明确 GLEAM 框架需解决三大关键问题,这也是后续模块设计的核心动机:- 现有方法在变换过程中易破坏图像全局语义信息与几何结构,导致对抗样本迁移性受限;
- 对抗样本的分布空间探索范围有限,难以覆盖多样化特征,影响跨模型泛化能力;
- 优化过程中对跨模态对齐信息的利用不充分,仅依赖最终对抗图像指导文本生成,易导致文本对抗样本过拟合。
GLEAM 三大核心模块设计
基于 NURBS 的局部特征增强(LFE)模块
- 设计目标
在实现图像局部区域多样化变形的同时,保持全局语义连贯性与几何结构完整性,避免传统变换对梯度信息的破坏,提升局部特征的通用性。 - NURBS 特性与数学定义
- NURBS优势:具备局部控制(控制点修改仅影响局部区域)、几何不变性(保留关键几何属性)、平滑性(变形连续可微)三大核心特性,为局部精准变形提供数学基础。
- NURBS曲面定义:NURBS 曲面 Q(u,v)Q(u, v)Q(u,v) 由控制点网格与有理基函数构成,公式如下:
Q(u,v)=∑i=0m∑j=0nPi,jRi,j(u,v)Q(u, v) = \sum_{i=0}^{m} \sum_{j=0}^{n} P_{i, j} R_{i, j}(u, v)Q(u,v)=i=0∑mj=0∑nPi,jRi,j(u,v) 其中 Pi,jP_{i, j}Pi,j 为 m×nm × nm×n 网格中的控制点,Ri,j(u,v)R_{i, j}(u, v)Ri,j(u,v) 为有理基函数,其计算依赖权重 wi,jw_{i,j}wi,j(设为1)与 B 样条基函数 Bi,p(u)B_{i,p}(u)Bi,p(u)、Bj,q(v)B_{j,q}(v)Bj,q(v)(阶数均设为 3):
Ri,j(u,v)=wi,jBi,p(u)Bj,q(v)∑k=0m∑l=0nwk,lBk,p(u)Bl,q(v)R_{i,j}(u,v) = \frac{w_{i,j}B_{i,p}(u)B_{j,q}(v)}{\sum _{k=0}^{m}\sum _{l=0}^{n}w_{k,l}B_{k,p}(u)B_{l,q}(v)}Ri,j(u,v)=∑k=0m∑l=0nwk,lBk,p(u)Bl,q(v)wi,jBi,p(u)Bj,q(v) B 样条基函数通过递归方式定义,确保变形的平滑性与连续性。
- 局部变换函数
定义局部变换函数 TL:X×Rm×n→X\mathcal{T}_{L}: X × \mathbb{R}^{m × n} \to XTL:X×Rm×n→X,通过 NURBS 变形生成局部调整后的图像:
TL(v,δ)=v+ΔS(δ)\mathcal{T}_{L}(v,\delta ) = v + \Delta S(\delta )TL(v,δ)=v+ΔS(δ)- δ∈Rm×n\delta \in \mathbb{R}^{m × n}δ∈Rm×n:控制点位移量,每个 δi,j\delta_{i,j}δi,j 服从 U(−ϵ,ϵ)U(-\epsilon, \epsilon)U(−ϵ,ϵ) 均匀分布;
- ΔS(δ)\Delta S(\delta)ΔS(δ):位移场,由 NURBS 计算得到,公式为 ΔS(δ)=∑i=0m∑j=0nδi,jRi,j(u,v)\Delta S(\delta) = \sum_{i=0}^{m} \sum_{j=0}^{n} \delta_{i, j} R_{i, j}(u, v)ΔS(δ)=∑i=0m∑j=0nδi,jRi,j(u,v),确保局部变形不破坏全局语义。
全局分布扩展(GDE)模块
- 设计目标
作为 LFE 模块的补充,通过全局层面的变换系统拓宽对抗样本的分布空间,在保留图像几何结构与宽高比的同时,提升样本多样性,增强跨模型迁移性。 - 全局变换函数
定义全局变换函数 TG:X×R2→X\mathcal{T}_{G}: X × \mathbb{R}^{2} \to XTG:X×R2→X,结合自适应随机缩放与上下文感知填充技术,公式如下:
TG(v,θ)=Resize(Tb(Ts(v,r),p),H)\mathcal{T}_{G}(v, \theta) = \text{Resize} \left(T_{b}\left(T_{s}(v, r), p\right), H\right)TG(v,θ)=Resize(Tb(Ts(v,r),p),H)- θ=(r,p)\theta = (r, p)θ=(r,p):随机参数集合,rrr 为缩放因子(服从 U(H,2H)U(H, 2H)U(H,2H) 均匀分布,HHH 为图像原始高度),ppp 为填充值;
- TsT_{s}Ts:缩放操作,TbT_{b}Tb:填充操作,ResizeResizeResize:将变换后图像恢复至原始高度 HHH,确保输出图像尺寸一致,同时保留整体结构。
跨模态特征对齐(CMFA)模块
- 设计目标
解决现有方法仅依赖 “最终对抗图像” 指导文本生成导致的过拟合问题,通过利用优化轨迹中的所有中间视觉对抗样本,提升文本对抗样本的跨模态一致性与迁移性。 - 核心策略:基于中间样本的文本优化
采用改进的 PWWS 算法生成文本对抗样本,核心是引入中间视觉对抗样本集合 Vadv={v0adv,v1adv,...,vTadv}V^{adv} = \{v_{0}^{adv}, v_{1}^{adv}, ..., v_{T}^{adv}\}Vadv={v0adv,v1adv,...,vTadv}(TTT为迭代次数),分两步实现文本优化:- 词重要性计算:对文本 ttt 中的每个词 wiw_iwi,计算其重要性得分,衡量该词对模型预测结果的影响:
I(wi)=P(y∣t)−P(y∣twi)I\left(w_{i}\right) = P(y | t) - P\left(y | t_{w_{i}}\right)I(wi)=P(y∣t)−P(y∣twi) 其中 P(y∣t)P(y | t)P(y∣t) 为模型对原始文本 ttt 的真实标签预测概率,twit_{w_{i}}twi 为移除词 wiw_iwi 后的文本。
- 词重要性计算:对文本 ttt 中的每个词 wiw_iwi,计算其重要性得分,衡量该词对模型预测结果的影响:
- 词替换得分计算:对词 wiw_iwi 的每个候选同义词 w′w'w′(基于 GloVe 词嵌入余弦相似度筛选),计算替换得分,选择得分最高的候选词作为最优替换:
S(wi,w′)=I(wi)⋅L(Vadv,tw′)wi∗=argmaxw′∈N(wi)S(wi,w′)S\left(w_{i}, w'\right) = I\left(w_{i}\right) \cdot L\left(V^{adv}, t_{w'}\right) \\ \quad \\ w_{i}^{*} = arg\ \operatorname* {max}_{w' \in N\left(w_{i}\right)} S\left(w_{i}, w'\right)S(wi,w′)=I(wi)⋅L(Vadv,tw′)wi∗=arg w′∈N(wi)maxS(wi,w′) 其中 L(Vadv,tw′)L(V^{adv}, t_{w'})L(Vadv,tw′) 利用所有中间视觉对抗样本评估替换词 w′w'w′ 的攻击效果,N(wi)N(w_i)N(wi) 为词 wiw_iwi 的同义词集合。
多模态对抗数据增强与优化实现
- 视觉对抗样本生成
基于动量迭代快速梯度符号法(MI-FGSM),结合 LFE 与 GDE 模块的变换函数,实现视觉对抗样本的迭代优化: - 迭代更新公式:在每次迭代中,根据动量梯度调整对抗图像,确保扰动不超出约束范围:
vi+1adv=Clipvϵv{viadv+α⋅sign(gi+1)}v_{i+1}^{adv} = Clip_{v}^{\epsilon_{v}}\left\{v_{i}^{adv} + \alpha \cdot sign\left(g_{i+1}\right)\right\}vi+1adv=Clipvϵv{viadv+α⋅sign(gi+1)} 其中 α\alphaα 为步长,ClipvϵvClip_{v}^{\epsilon_{v}}Clipvϵv 为裁剪函数(确保 (v_{i+1}^{adv})在(B[v, \epsilon_v])内),(g_{i+1})为动量梯度。 - 动量梯度计算:综合LFE与GDE变换后的梯度,提升梯度稳定性,公式如下:
gi+1=μ⋅gi+g~i∥g~i∥1g_{i+1} = \mu \cdot g_{i} + \frac{\tilde{g}_{i}}{\left\| \tilde{g}_{i}\right\| _{1}}gi+1=μ⋅gi+∥g~i∥1g~i 其中 μ\muμ 为动量系数,g~i\tilde{g}_{i}g~i 为多变换梯度均值(融合 NNN 个 LFE 变换与 KKK 个 GDE 变换的梯度):
g‾i=1N∑n=1N∇vJ(fI(TL(viadv,δn)),fL(t))+1K∑k=1K∇vJ(fI(TG(viadv,θk)),fL(t))\overline{g}_{i} = \frac{1}{N} \sum_{n=1}^{N} \nabla_{v} J\left(f_{I}\left(\mathcal{T}_{L}\left(v_{i}^{adv}, \delta_{n}\right)\right), f_{L}(t)\right) + \frac{1}{K} \sum_{k=1}^{K} \nabla_{v} J\left(f_{I}\left(\mathcal{T}_{G}\left(v_{i}^{adv}, \theta_{k}\right)\right), f_{L}(t)\right)gi=N1n=1∑N∇vJ(fI(TL(viadv,δn)),fL(t))+K1k=1∑K∇vJ(fI(TG(viadv,θk)),fL(t)) - 文本对抗样本生成
如 CMFA 模块所述,基于改进的 PWWS 算法,利用中间视觉对抗样本集合 VadvV^{adv}Vadv 指导文本词替换,生成满足 ϵt\epsilon_tϵt 约束(最大词修改数)且语义相似的文本对抗样本 tadvt^{adv}tadv. - 完整算法
GLEAM 框架的完整实现流程(含模块协同逻辑、迭代步骤)在附录 A 中提供,确保方法的可复现性。
实验-Experiments
实验设置
- 数据集
实验选用 3 个主流多模态基准数据集,覆盖不同下游任务需求:- Flickr30K:含 31783 张图像,每张图像对应 5 个文本描述,主要用于图像-文本检索(ITR)任务评估;
- MSCOCO:含 123287 张图像,每张图像约对应 5 个文本描述,同时用于 ITR 任务与图像描述(IC)任务评估(因标注更全面);
- RefCOCO+:含 19992 张图像,配套 141,564 个自然语言表达式(对应 50000 个目标),专门用于视觉定位(VG)任务评估。
- 评估模型
覆盖 VLP 模型两大核心架构,同时测试多模态大模型,以全面验证攻击迁移性:- 融合型 VLP 模型:ALBEF、TCL(先通过单模态编码器处理,再经多模态编码器融合特征);
- 对齐型 VLP 模型:CLIP(含两个图像编码器变体:基于ViT-B/16的 CLIPVIT_{VIT}VIT、基于 ResNet-101 的 CLIPCNN_{CNN}CNN,通过对比学习对齐模态特征,检索能力更强);
- 多模态大模型:BLIP-2、Qwen2-VL、Claude 3.5、GPT-4o-mini、GPT-4o(测试对先进大模型的攻击效果)。
- 基线方法与攻击参数
- 基线方法:选取 6 类代表性对抗攻击方法进行对比,确保评估公平性,包括 Sep-Attack、Co-Attack、SGA、TMM、DRA、SA-AET;
- 统一攻击参数:所有方法采用相同攻击强度——文本扰动预算 ϵt=1\epsilon_{t}=1ϵt=1(最多修改 1 个词),候选替换词表含 10 个同义词;图像最大扰动 ϵv=8/255\epsilon_{v}=8/255ϵv=8/255(L∞L_\inftyL∞ 范数约束),迭代次数 T=10T=10T=10.
- 实现细节与超参数
- LFE模块:采用 30×30 控制点网格,控制点位移量 δi,j∼U(−ϵ,ϵ)\delta_{i,j} \sim U(-\epsilon, \epsilon)δi,j∼U(−ϵ,ϵ)(ϵ=10\epsilon=10ϵ=10 像素);
- GDE 模块:缩放因子 r∼U(1.1,1.8)r \sim U(1.1, 1.8)r∼U(1.1,1.8)(均匀采样),通过上下文感知填充保持图像结构;
- 超参数分析:详细的消融研究与敏感性分析在附录B中呈现,验证参数选择合理性。
- 评估指标
- 核心指标:攻击成功率(ASR),基于 Top-1 排名(R@1)计算,即成功改变模型预测的对抗样本占比,ASR 越高表示攻击效果越好、迁移性越强;
- 辅助指标:VG 任务用 “准确率”(越低表示攻击效果越好),IC 任务用 BLEU、METEOR、ROUGE-L、CIDEr、SPICE(均为越低表示攻击效果越好)。
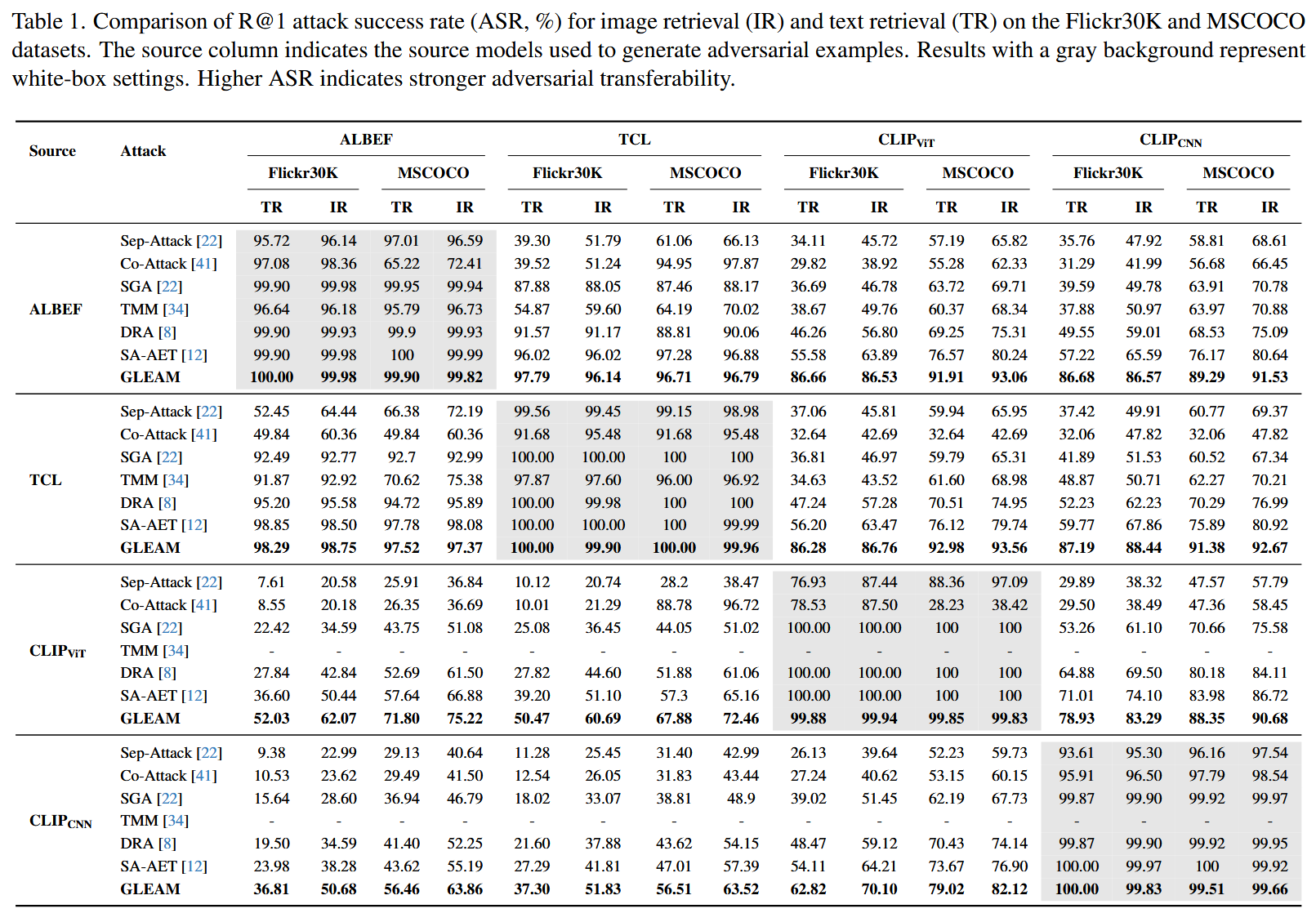
跨模型对抗迁移性
- 白盒场景:GLEAM 与 SA-AET、DRA 等基线方法表现相当,ASR 均超99%,证明其在白盒场景的有效性;
- 黑盒跨模型场景:GLEAM 显著优于所有基线,具体优势如下:
- 以 ALBEF 为源模型:在 Flickr30K 的 CLIPVIT_{VIT}VIT 文本检索(TR)任务中,GLEAM 的 ASR 为 86.66%,较 SA-AET(55.58%)提升超 30 个百分点;在 MSCOCO 的 CLIPVIT_{VIT}VIT TR 任务中,GLEAM 的 ASR 为 91.91%,较 SA-AET(76.57%)提升 15 个百分点;
- 以 TCL 为源模型:在 Flickr30K 的 CLIPVIT_{VIT}VIT 任务中,GLEAM 的 TR-ASR 为 86.28%、IR-ASR 为 86.76%,远超 SA-AET(TR-56.20%、IR-63.47%);
- 以 CLIP 为源模型:以 CLIPCNN_{CNN}CNN 为源模型时,GLEAM 在 Flickr30K 的 CLIPVITCLIP_{VIT}CLIPVIT TR任务中 ASR 为 62.82%、IR 任务为 70.10%,仍高于 SA-AET。
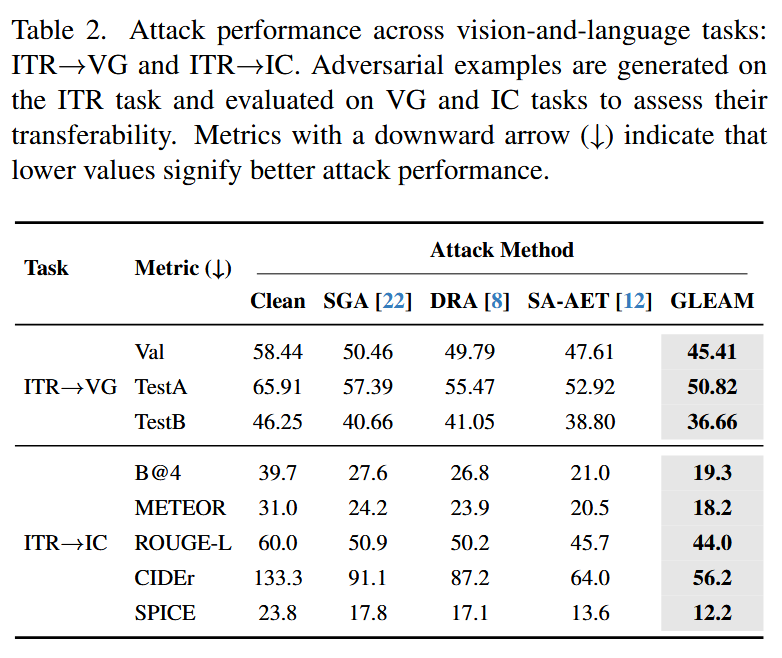
跨任务对抗迁移性
- VG任务:GLEAM 使模型性能下降最显著——Val 集准确率从干净样本的 58.44% 降至 45.41%,TestA 集从 65.91% 降至 50.82%,TestB 集从 46.25% 降至 36.66%,均低于 SGA、DRA、SA-AET 等基线;
- IC任务:GLEAM 对所有评估指标均造成最大降幅——BLEU-4 从 39.7 降至 19.3,METEOR 从31.0 降至 18.2,ROUGE-L 从 60.0 降至 44.0,CIDEr 从 133.3 降至 56.2,SPICE 从 23.8 降至 12.2,证明其生成的对抗样本可有效破坏模型的跨任务特征对齐能力。
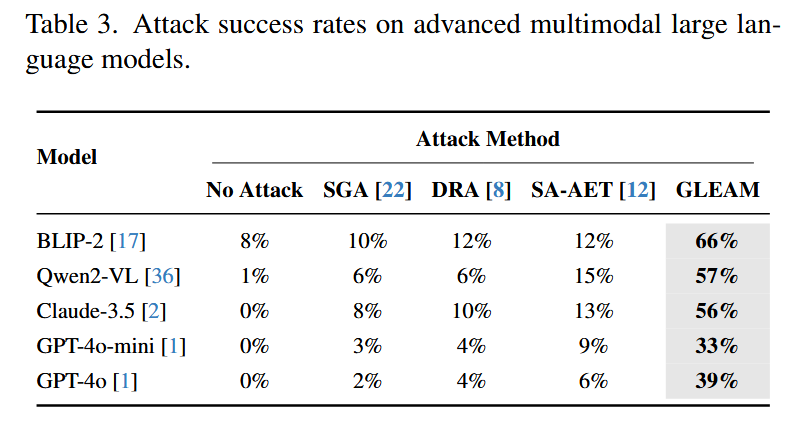
多模态大模型的对抗迁移性
- 评估方法
以 CLIP 为代理评估器:1)将干净/对抗图像输入大模型生成文本;2)将生成文本与干净图像输入 CLIP 计算相似度;3)相似度低于阈值则判定攻击成功,ASR 为成功攻击样本占比(需考虑大模型自身的误描述基线)。 - 关键结果
GLEAM 对所有大模型的攻击效果远超基线,具体如下:- 对 BLIP-2:GLEAM 的 ASR 为 66%,而 DRA、SA-AET 均仅为 12%;
- 对 Qwen2-VL:GLEAM 的 ASR 为 57%,SA-AET 仅为 15%;
- 对 Claude 3.5:GLEAM 的 ASR 为 56%,SA-AET 仅为 13%;
- 对 GPT 系列:GLEAM 在 GPT-4o-mini 上 ASR 为 33%(SA-AET 9%),在 GPT-4o 上 ASR 为39%(SA-AET 6%),即使对最先进的大模型仍保持强攻击能力。
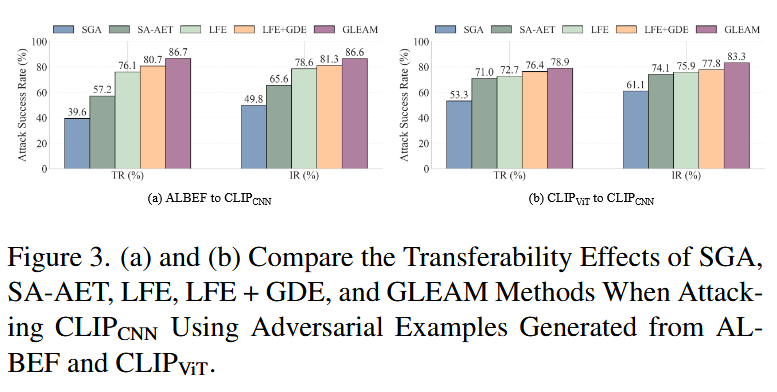
消融研究
-
模块有效性验证
对比 5 种方法变体,验证 GLEAM 各组件的必要性:- 单一模块/基线:LFE(仅局部增强)的迁移性优于 SGA、SA-AET;LFE+GDE(局部+全局)的性能进一步提升,TR-ASR 达 80.7%、IR-ASR 达 81.3%;
- 完整框架:GLEAM(LFE+GDE+CMFA)性能最优,TR-ASR 达 86.7%、IR-ASR 达 86.6%,较 LFE+GDE 提升 6.0 和 5.3 个百分点,证明 CMFA 模块对跨模态优化的关键作用。
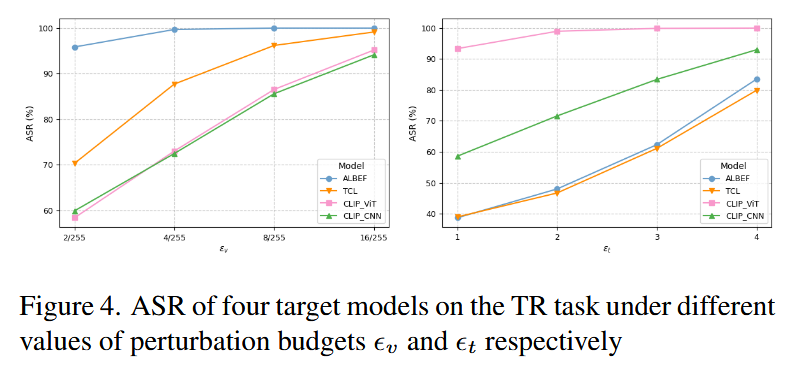
-
扰动预算敏感性分析
- 图像扰动 ϵv\epsilon_vϵv:随 ϵv\epsilon_vϵv 增大,ASR 整体上升;但即使 ϵv=2/255\epsilon_v=2/255ϵv=2/255(微小扰动),GLEAM 仍保持较高 ASR,证明其攻击的高效性;实验最终选择 ϵv=8/255\epsilon_v=8/255ϵv=8/255,平衡攻击效果与扰动不可感知性;
- 文本扰动 ϵt\epsilon_tϵt:ϵt\epsilon_tϵt 增大可提升 ASR,实验中设 ϵt=1\epsilon_t=1ϵt=1 以保证文本语义相似性,攻击者可根据需求调整以平衡效果与隐蔽性。
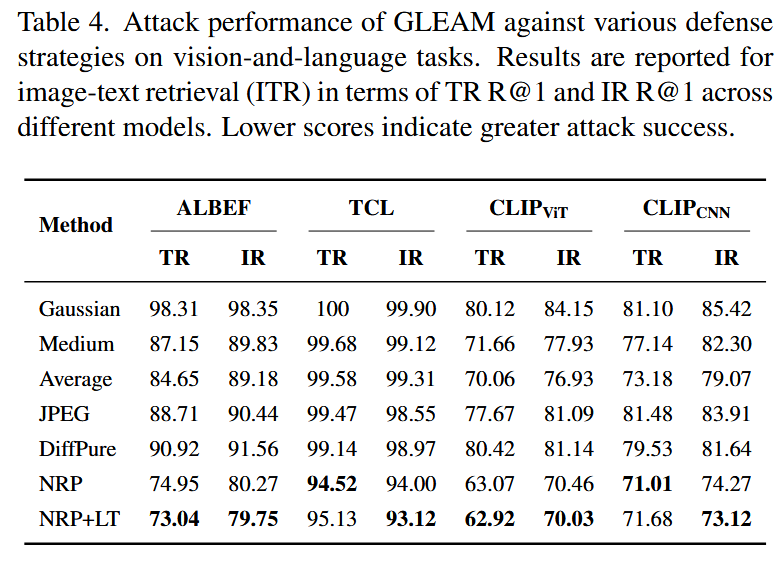
安全启示与防御评估
- 防御方法测试
测试 5 类主流防御机制对 GLEAM 的抵御效果,包括图像预处理、JPEG 压缩、DiffPure、神经表示净化(NRP)、NRP+LanguageTool(LT)(多模态防御)。 - 关键结论
- 现有防御仅能部分降低攻击效果:NRP+LT 是最优防御组合,可将 ALBEF 的 TR R@1 降至 73.04、CLIPVIT_{VIT}VIT 的 TR R@1 降至 62.92,但仍无法完全抵御 GLEAM 攻击;
- 需求:需设计针对 VLP 模型的专用先进防御机制,以应对多模态对抗攻击,确保其在安全关键场景的可靠部署。
结论-Conclusion
- 核心成果:本文提出 GLEAM 框架,专为视觉语言预训练(VLP)模型的黑盒场景设计,可生成具有高迁移性的对抗样本。该框架通过整合基于 NURBS 的局部变形与全局增强策略,在实现攻击多样性的同时,有效保留了图像的语义结构;同时,其跨模态特征对齐机制借助优化过程中的中间状态,进一步强化了对抗样本的迁移能力。
- 研究价值:GLEAM 的设计与实验验证,为评估 VLP 模型的对抗鲁棒性提供了可靠工具,也为后续研究提供了关键思路——即通过平衡局部操作与全局分布、优化跨模态信息利用,可更精准地暴露VLP模型的脆弱性。
- 研究期望:作者希望 GLEAM 相关工作能推动更多针对 VLP 模型对抗鲁棒性的研究,助力开发更安全、可靠的视觉语言系统,以应对实际应用中的安全挑战。