《Linux系统编程之开发工具》【版本控制器 + 调试器】
【版本控制器 + 调试器】目录
- 前言:
- ---------------版本控制器---------------
- 1. git的前世今生?
- 2. 什么是git?
- 小故事:游戏存档
- 3. git能解决什么问题?
- 4. git的核心特点有哪些?
- 5. 如何在GitHub/Gitee创建项目并使用git提交代码?
- -------GitHub + Xshell-------
- 第一步:创建远端Github仓库
- 第二步:配置 SSH 密钥
- (1)生成 SSH 密钥对
- (2)将公钥添加到 GitHub 账号
- (3)测试 SSH 连接
- (4)克隆仓库
- 第三步:向远端仓库提交代码
- (1)第一板斧:git add
- (2)第二板斧:git commit
- (3)第三板斧:git push
- -------Gitee + PowerShell-------
- 第一步:创建远端Gitee仓库
- 第二步:做一些准备工作
- (1)安装 Git for Windows
- (2)配置 Git 用户信息
- (3)克隆仓库
- 第三步:向远端仓库提交代码
- (1)进入仓库目录
- (2)提交三板斧
- ---------------调试器---------------
- 1. 什么是debug和release?
- 2. 在Linux上我们要怎么进行调试?
- 3. 怎么快速简单的使用gdb进行调试?
- 4. 如何更好的进行调试?
- 5. 掌握二个进阶调试技巧?
- watch命令
- set vat命令
- 6. 调试的本质是什么?
- 7. 什么是条件断点?
- 使用一:直接添加条件断点
- 使用二:给已存在的断点新增条件

往期《Linux系统编程》回顾:
/------------ 入门基础 ------------/
【Linux的前世今生】
【Linux的环境搭建】
【Linux基础 理论+命令】(上)
【Linux基础 理论+命令】(下)
【权限管理】
/------------ 开发工具 ------------/
【软件包管理器 + 代码编辑器】
【编译器 + 自动化构建器】
前言:
hi~ 小伙伴们大家好呀!(ノ≧∀≦)ノ
之前鼠鼠带大家学了 【软件包管理器 + 代码编辑器】、【编译器 + 自动化构建器】,本来以为大家都已经写出优雅代码,让程序在云服务器上稳稳跑起来了呢~٩(ˊᗜˋ*)و结果居然有小可爱说,写的时候踩了 bug,程序到现在还没成功运行?┻━┻︵ ╰(‵□′)╯︵ ┻━┻
嘤嘤嘤 (╥﹏╥),别慌别慌,鼠鼠这就带着 “救星工具” 来帮你! (。•̀ᴗ-)✧
今天咱们要学的核心内容就是 【版本控制器 + 调试器】!( ̄︶ ̄)↗
版本控制器:能帮你追踪代码修改、回溯历史版本,不怕改崩代码找不回原样调试器:则是找 bug 的 “火眼金睛”,能一步步排查问题、定位错误根源有了这俩 “神器”,搞定 bug、稳妥管理代码都不是事儿,赶紧一起解锁新技能吧~(っ´▽`)っ♡
---------------版本控制器---------------
1. git的前世今生?
git:是一个 开源的分布式版本控制系统(Distributed Version Control System,简称 DVCS),由 Linux 内核创始人 Linus Torvalds 于 2005 年开发,最初目的是解决 Linux 内核开发中 “多人协作、代码版本追踪、历史回溯” 的需求。
- 它就像一个 “代码的时光机 + 协作管家”:
- 既能,记录代码的每一次修改(谁改的、什么时候改的、改了什么)
- 也能,让多个人同时开发同一项目时,高效合并代码、避免冲突,还能随时回滚到之前的稳定版本
前世:BitKeeper 的使用与授权风波
- 在 git 诞生之前,Linux 内核项目在 1991 年至 2002 年期间,主要通过补丁和存档文件的形式来传递软件的更改内容,这种方式协作复杂、合并耗时,且对大规模并行分支支持不足
- 2002 年,BitKeeper 的开发商 BitMover 出于对开源社区的友好,免费授权给 Linux 社区使用,Linux 内核项目开始采用 BitMover 公司开发的商业专有分布式版本控制系统 BitKeeper,它在一定程度上满足了 Linux 内核开发的需求
- 然而这种和谐关系在 2005 年被打破,原因是当时开发 Samba 的 Andrew Tridgell 对 BitKeeper 进行了反向工程(试图开发一个开源替代品),这被 BitMover 公司视为违反许可协议的行为
- 于是BitMover 收回了对 Linux 社区的免费使用权,这使得 Linux 开发社区不得不寻找新的版本控制系统替代方案
今生:Git 的诞生与发展
- 横空出世:2005 年,Linus Torvalds 为了解决 Linux 内核开发的版本控制问题,决定亲自开发一个新的版本控制系统。
- 他设定了
速度快、设计简单、支持非线性开发、完全分布式以及能高效处理大型项目等目标- 并在短短 10 天内用 C 语言编写了 git 的初始版本,2005 年 4 月 7 日,Linus Torvalds 提交了 Git 的首个版本
- 发展完善:git 诞生后,Linus Torvalds 和其他贡献者不断对其进行完善,引入了许多新特性和优化。
- 如支持 HTTP 协议的 “smart” 传输、轻量级工作流、更强大的分支操作等
- 随着时间的推移,Git 逐渐从一个小众工具发展成为全球最流行的版本控制系统之一
- 生态拓展:后续 GitHub、GitLab 等代码托管平台的兴起,进一步推动了 git 的普及和应用,它们提供了图形化界面和丰富的协作功能,让 git 更加易用。
- 如今Git 已成为开源项目、商业项目以及个人项目等各种规模项目中不可或缺的版本控制工具,并且与 Jenkins、CircleCI、GitHub Actions 等持续集成和持续交付(CI/CD)工具无缝衔接,深刻改变了软件开发的方式和全球开源社区的生态
2. 什么是git?
小故事:游戏存档
一个生动的比喻:打游戏存档
想象你在玩一个很难的角色扮演游戏(RPG):
没有存档(没有git):你只能一路玩到底。
- 如果中途打错了、加错了技能点或者不小心删了重要道具,你可能就得从头再来,痛苦万分
有存档(使用git):你会在挑战大Boss前、到达新地图后、升级加点时都手动存一个档。
- 如果挑战失败或者不满意,你可以读档回到之前的状态,换一种策略再试,完全不用担心玩坏
在这个比喻里:
- 你的代码项目 == 这个游戏
- git commit(提交命令) == 手动存档的操作
- git仓库 == 你的存档文件夹,里面存放着所有存档点
- 切换分支或回退 == 读档,回到某个存档点的状态
3. git能解决什么问题?
git 解决的三大核心问题:
备份与恢复
- 问题:“天啊!我昨天改的代码今天发现改错了,怎么都回不去了!”
- 解决:git 记录每一次的修改。你可以轻松地把代码恢复到昨天、甚至上一个小时的状态
协作与同步
- 问题:“我和同事都在改同一个文件,改完发现互相覆盖了,代码全乱套了!”
- 解决:git 可以自动合并你们两人的修改。如果修改了同一处地方产生冲突,它会明确告诉你冲突位置,让你们协商解决,绝不会悄无声息地覆盖
- 追踪与问责
- 问题:“这行代码是谁写的?他为什么要这么写?什么时候引入的这个Bug?”
- 解决:git 的每一次“存档”都会记录是谁、在什么时间、为什么(提交信息)做了这个修改。你可以清晰地追溯每一行代码的来历
总结:
不管是个人开发还是团队协作,git 都能解决很多实际痛点:
- 个人开发:
- 不用担心 “改崩代码后回不去”—— 随时能回滚到上一个稳定版本
- 也能通过分支尝试新功能,失败了直接删除分支,不影响主代码
- 团队协作:
- 多个人同时改同一文件时,git 能智能合并代码(只冲突真正不一样的部分),避免 “互相覆盖代码” 的灾难
- 还能清晰看到每个人的修改记录,方便定位问题
- 行业标准:现在几乎所有互联网公司、开源项目(如 GitHub、GitLab 上的项目)都用 git 做版本控制,掌握 git 是开发者的基础技能
| 功能 | 没有 git 的世界 | 有 git 的世界 |
|---|---|---|
| 备份 | 手动复制文件夹,混乱且容易丢 | 自动记录每次更改,随时回退 |
| 协作 | 文件传来传去,合并靠人工 | 自动合并,冲突清晰标识 |
| 历史 | 靠注释和记忆 | 完整记录,责任清晰 |
| 试验 | 不敢轻易尝试,怕改不回来 | 开分支随意试验,失败即删 |
所以:git 是现代软件开发中不可或缺的基础工具,它让个人开发和团队协作变得高效、安全、有条不紊。无论是程序员、作家(虽然没那么常用),还是任何需要管理文本文件历史的人,都能从 git 中受益。
4. git的核心特点有哪些?
git 的核心特点:
- 分布式:这是 git 最革命性的特点。
- 每个参与项目的人电脑里都有一个完整的版本库,包含了全部的历史记录。这就像不是只有一台游戏机有存档,而是每个玩家自己手里都有一份完整的存档合集
- 好处就是你可以在没网的时候(在飞机上、地铁里)继续工作、提交代码,服务器的硬盘坏了也没关系,随便从任何一个开发者的电脑上就能恢复整个项目历史
- 分支管理:git 的分支功能极其强大和高效。
- 你可以把分支想象成【平行宇宙】,你想尝试一个激进的新功能,又怕把现在稳定的代码搞乱,怎么办?
- 你可以轻松地创建一个新的平行宇宙(分支),在这个宇宙里随便折腾。实验成功了,就把两个宇宙合并(merge) 起来
- 实验失败了,直接删掉这个分支就行了,完全不影响主宇宙(主分支)的稳定
5. 如何在GitHub/Gitee创建项目并使用git提交代码?
-------GitHub + Xshell-------
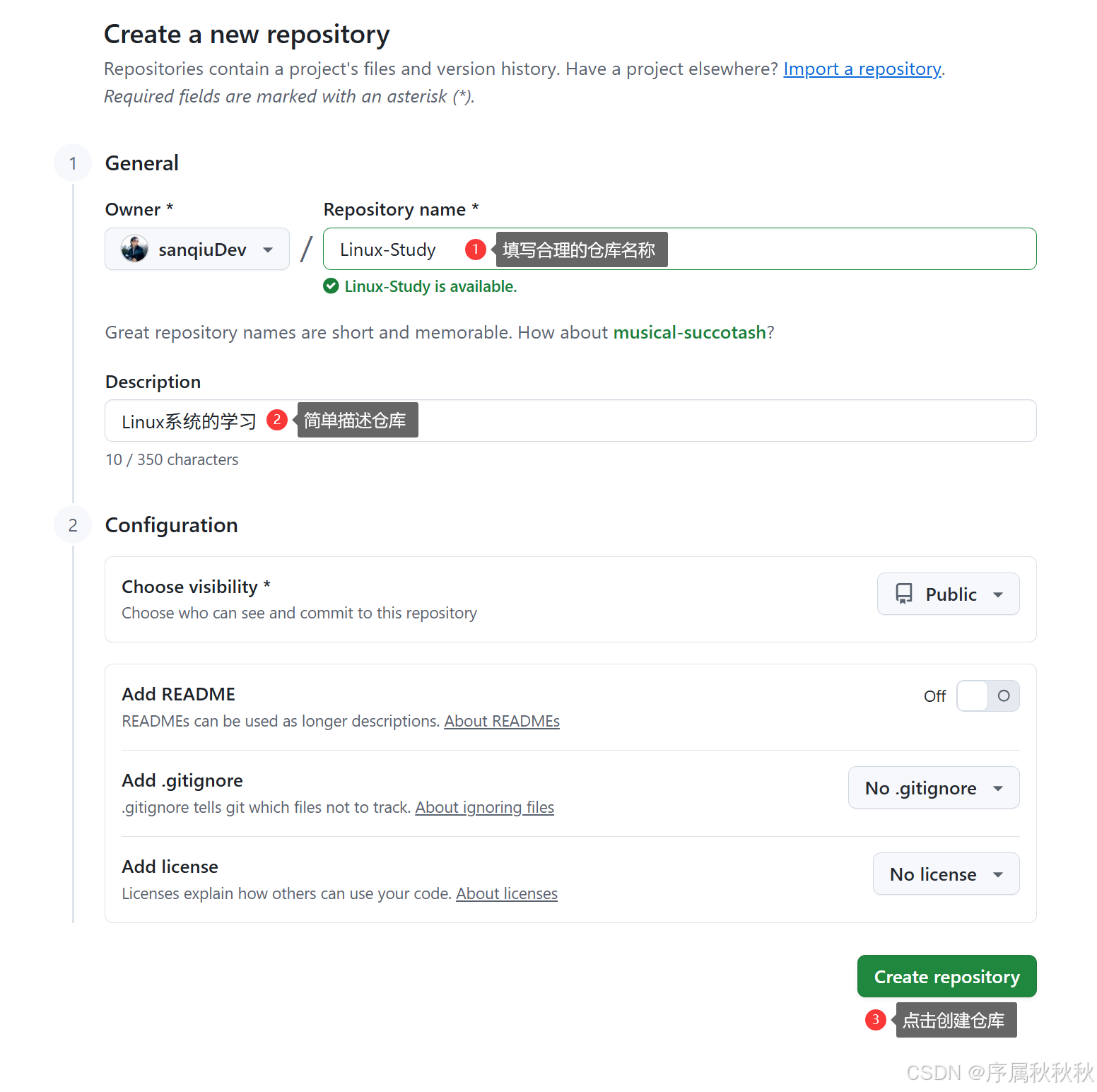
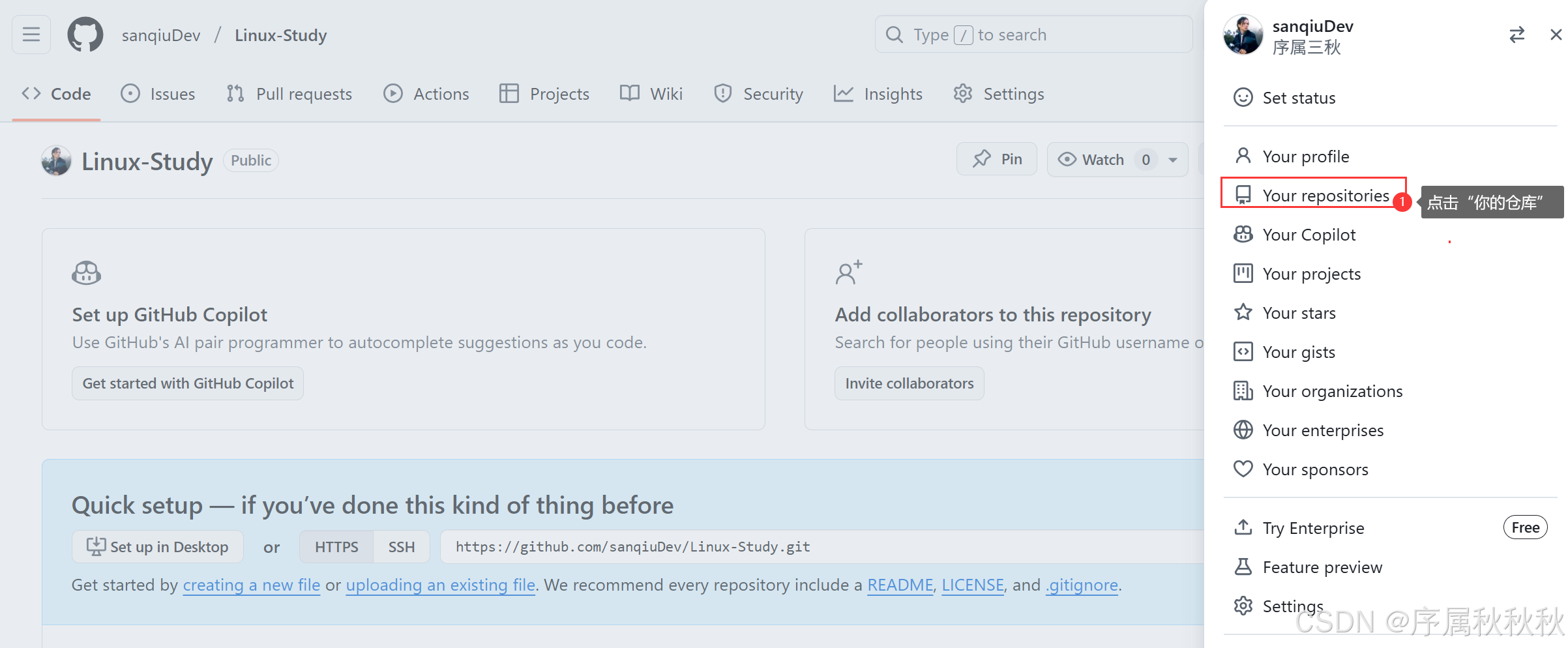
第一步:创建远端Github仓库
点击进入GitHub官网:GitHub



第二步:配置 SSH 密钥

(1)生成 SSH 密钥对
需要按照以下步骤生成 SSH 密钥,并将公钥添加到 GitHub 账号中:
步骤 1:生成 SSH 密钥对
在本地终端执行以下命令(替换成你自己的 GitHub 绑定邮箱):
ssh-keygen -t rsa -b 4096 -C "你的GitHub邮箱@example.com"执行后会有一系列提示,一路按回车即可(默认将密钥保存在
~/.ssh/目录下,文件名为id_rsa(私钥)和id_rsa.pub(公钥))

(2)将公钥添加到 GitHub 账号
步骤 2:将公钥添加到 GitHub 账号
- 查看公钥内容:执行
cat ~/.ssh/id_rsa.pub,会输出一长串以ssh-rsa开头的文本,复制这段文本- 登录 GitHub 账号,点击右上角头像 → 选择 Settings(设置)
- 在左侧菜单中,进入 SSH and GPG keys → 点击 New SSH key
- Title:给这个密钥起一个名字(比如:“我的 Ubuntu 机器”),方便识别
- Key:粘贴你刚才复制的公钥内容
- 点击 Add SSH key 完成添加
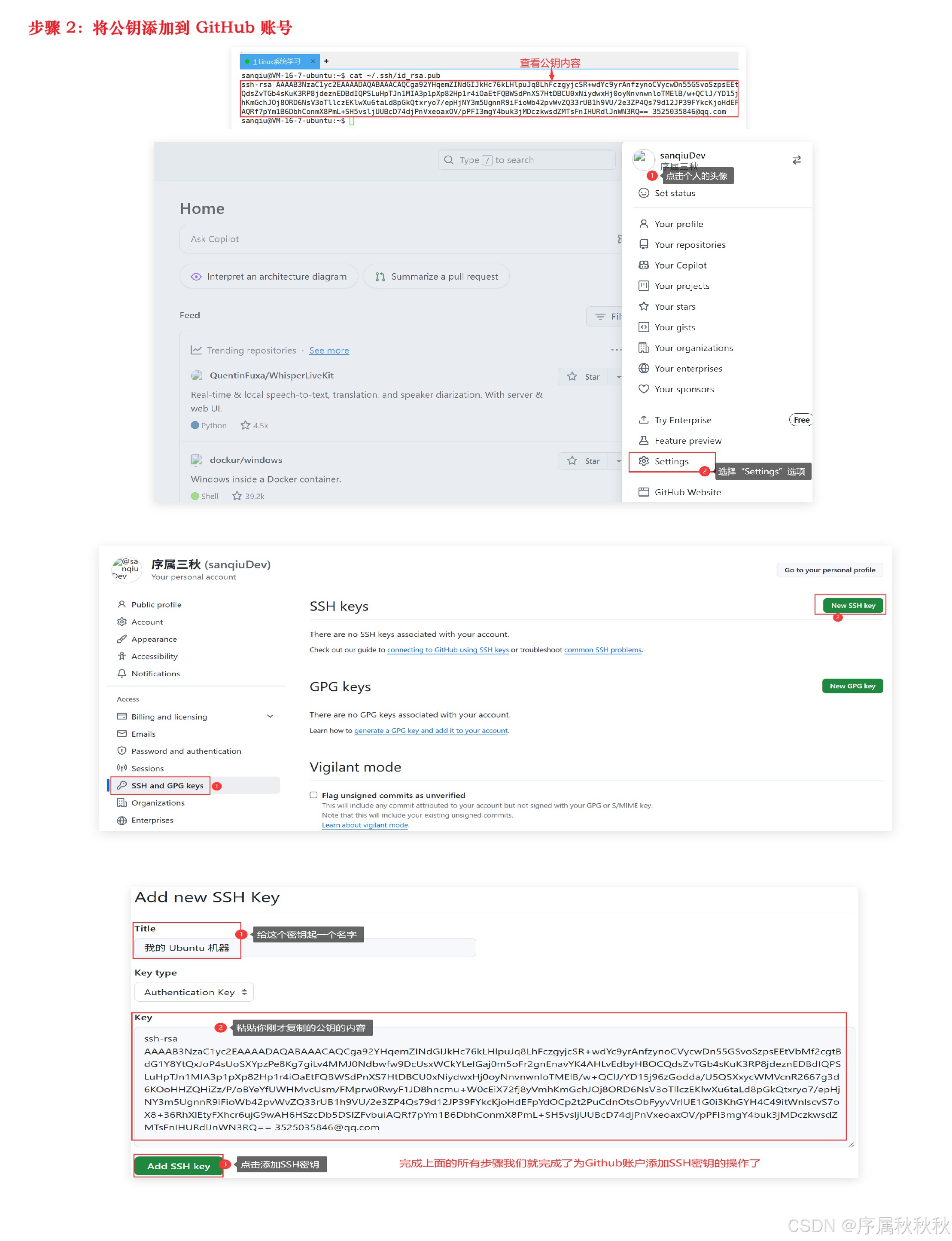
注意:并不是点击完“Add SSH Key”按钮,就是已经将公钥添加到 GitHub 账号上了,还需要输入密码进行“Confirm access”确认访问。


(3)测试 SSH 连接
步骤 3:测试 SSH 连接
执行以下命令,测试能否正常连接到 GitHub:
ssh -T git@github.com
- 如果看到类似
Hi sanqiuDev! You've successfully authenticated, but GitHub does not provide shell access.的提示,说明 SSH 连接配置成功
(4)克隆仓库
步骤 4:克隆仓库
现在执行克隆命令:
git clone 你的githum仓库的ssh链接
第三步:向远端仓库提交代码
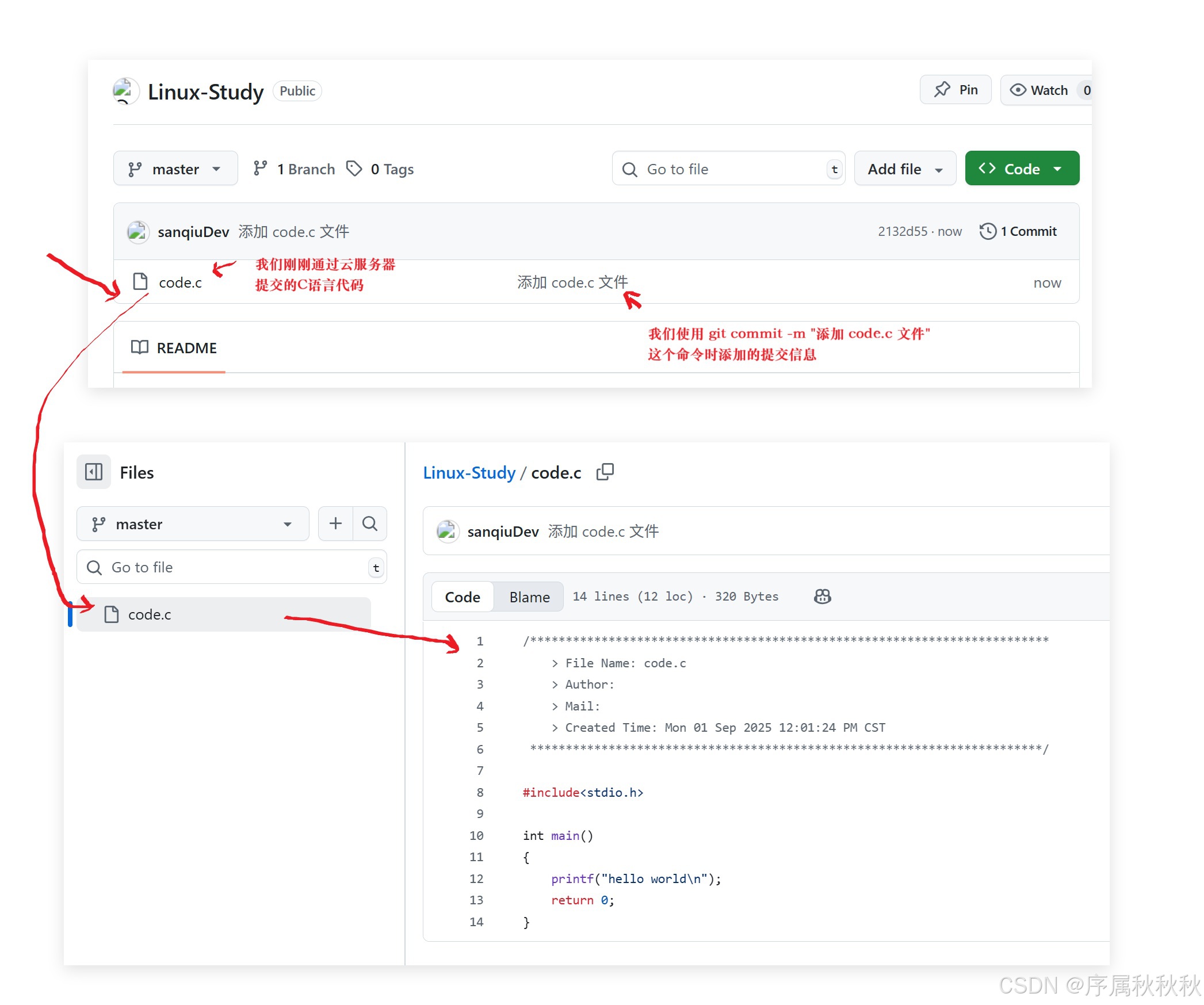
(1)第一板斧:git add
git add(添加文件到暂存区)
- 先把要管理的代码文件放到之前 克隆/创建 的仓库目录里
git add 文件名 # 添加单个文件,例如 git add code.c git add . # 添加当前目录下所有 新增/修改 的文件这个命令的作用是告诉 Git:“这些文件我要纳入版本管理啦”,把文件从工作区添加到暂存区(临时存储改动的地方),方便后续提交。
(2)第二板斧:git commit
git commit(提交到本地仓库)
- 确认暂存区的文件没问题后,执行提交命令
git commit -m "这里写提交说明" # 例如 git commit -m "修复登录功能的bug"这一步会把暂存区的所有改动正式提交到本地仓库,形成一个版本记录。
双引号里的文字要简洁清晰地描述这次改了什么(比如:新增功能、修复 bug 等),方便以后回溯历史时快速理解。
(3)第三板斧:git push
git push(推送到远程仓库)
- 本地提交后,想让代码同步到 GitHub 等远程服务器上
git push # 推送到默认的远程仓库和分支# 首次推送可能需要指定分支,例如:git push -u origin main执行后,本地仓库的提交记录会被上传到远程仓库,这样团队成员或其他设备就能获取到你的最新代码了。
总结:这三个命令是 Git 日常操作的核心流程,先标记要管理的文件,再保存到本地仓库,最后同步到远程服务器,确保代码安全和协作顺畅~

-------Gitee + PowerShell-------
第一步:创建远端Gitee仓库
点击进入Gitee官网:Gitee - 基于 Git 的代码托管和研发协作平台



第二步:做一些准备工作

(1)安装 Git for Windows
如果你的 Windows 系统还没有安装 Git,需要先下载并安装 Git for Windows
安装过程中保持默认设置即可,安装完成后,确保 Git 已经添加到系统环境变量中。
(2)配置 Git 用户信息
打开 Windows PowerShell,执行以下命令配置你的 Git 用户名和邮箱:
git config --global user.name "你的用户名" git config --global user.email "你的邮箱@example.com"
- 请将
"你的用户名"和"你的邮箱@example.com"替换为你在 Gitee 上注册的用户名和邮箱

(3)克隆仓库
在 PowerShell 中,使用
git clone命令克隆 Gitee 上的仓库。git clone 仓库的HTTPS链接
- 这会在当前目录下创建一个名为
linux-study的文件夹,并将仓库内容下载到该文件夹中


第三步:向远端仓库提交代码
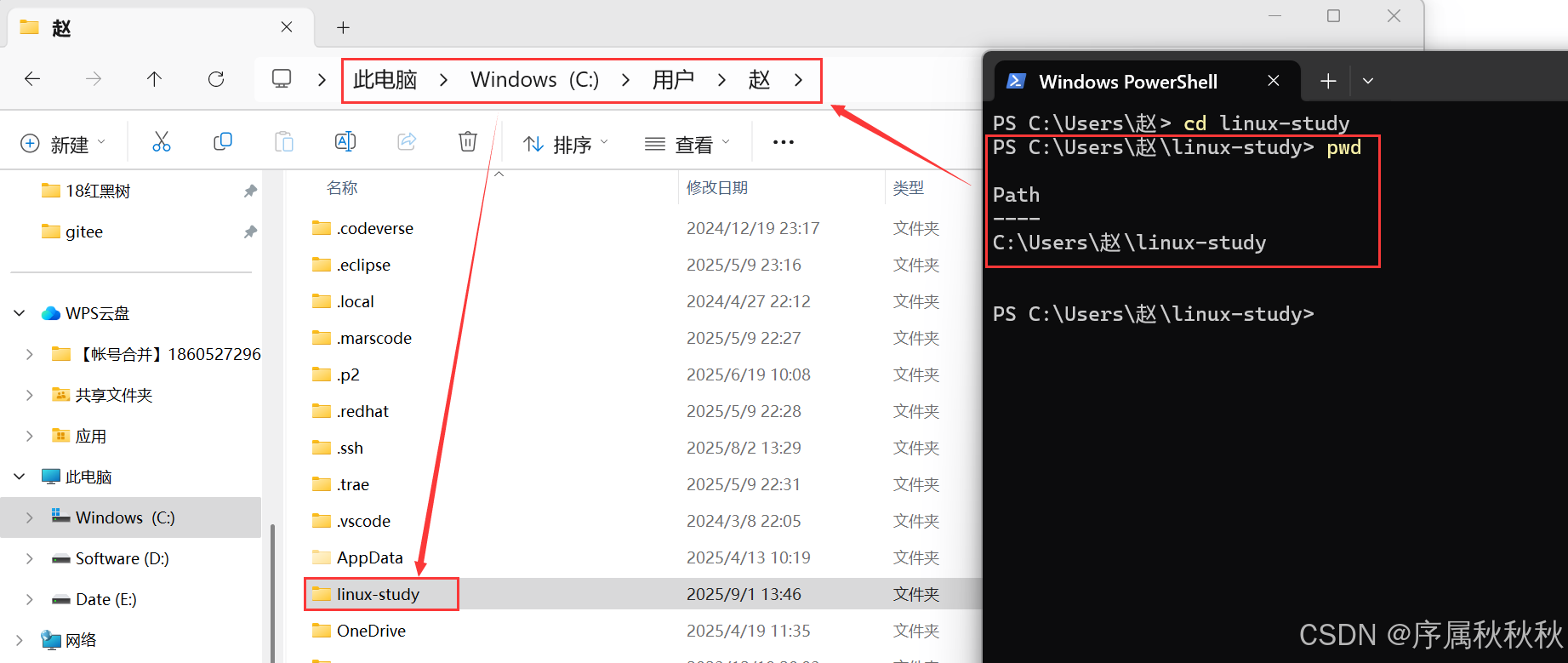
(1)进入仓库目录
使用
cd命令进入克隆好的仓库目录:cd linux-study
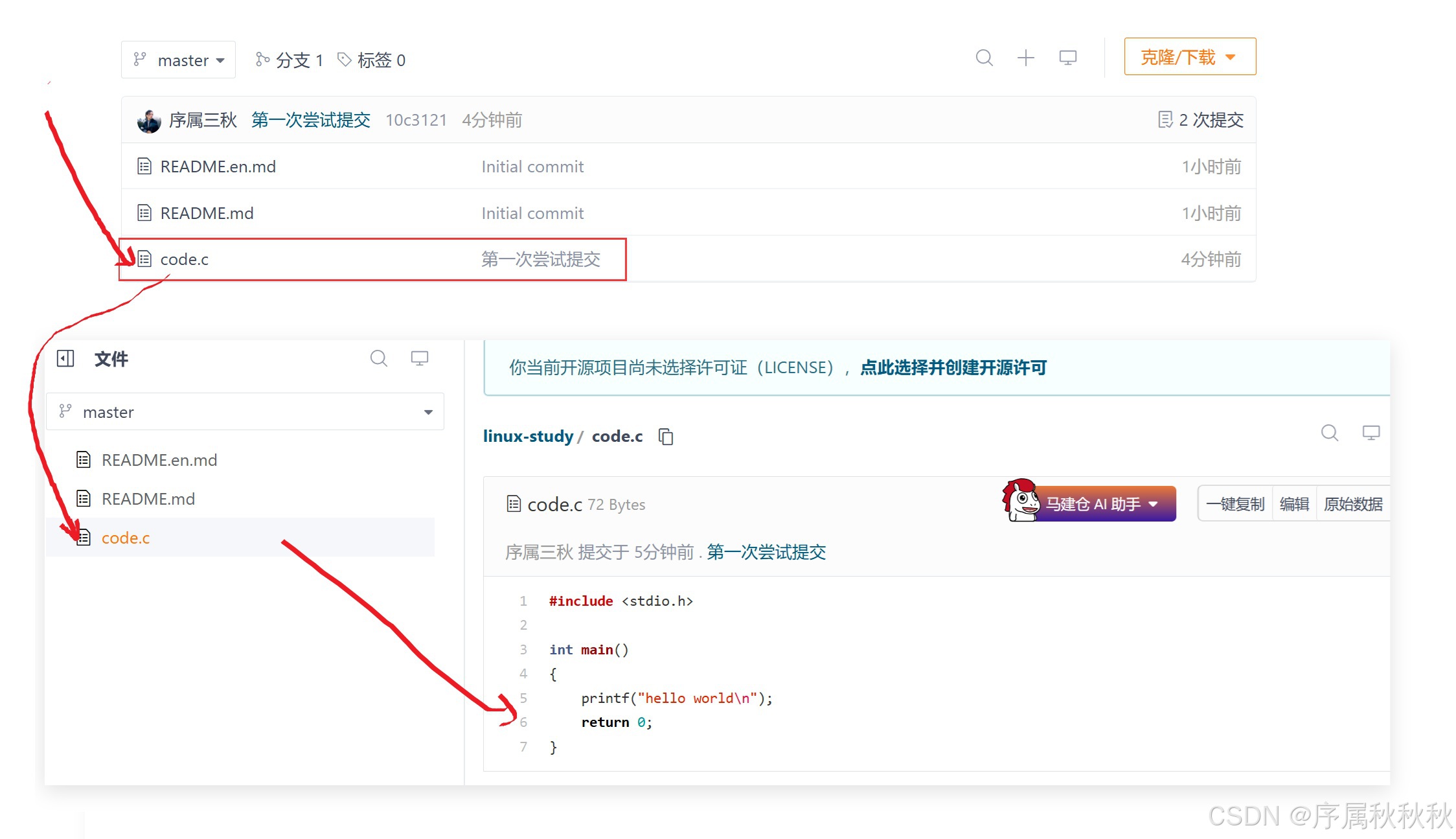
(2)提交三板斧

---------------调试器---------------
1. 什么是debug和release?
在软件开发中,
Debug(调试)和Release(发布)是两种常见的构建模式,它们服务于不同的目的,在编译选项、代码优化、可执行文件特性等方面存在显著差异。
1. Debug(调试模式)
核心目的:用于开发和调试阶段,方便开发者查找、修复代码中的错误。(如:逻辑错误、崩溃、内存泄漏等)
关键特点
包含调试信息:编译时会将大量调试相关的信息(如:变量名、函数名、代码行号与可执行指令的对应关系等)嵌入到生成的可执行文件或目标文件中
- 这样,调试器(如:GDB、Visual Studio 调试器)能精准定位代码执行到哪一行、变量当前的值等,助力调试
关闭或极少优化:编译器会关闭大部分代码优化(如:循环展开、变量重命名、死代码消除等)
- 因为优化可能会改变代码的执行流程(比如:调整代码顺序、合并变量),导致调试时的代码执行逻辑与开发者编写的原始逻辑不一致,增加调试难度
可执行文件较大:由于包含调试信息且缺乏优化,生成的可执行文件体积通常较大
运行速度较慢:没有经过编译优化,程序运行时的效率较低
2. Release(发布模式)
核心目的:用于最终发布给用户的版本,确保程序在用户环境中高效、稳定运行。
关键特点
- 无调试信息:编译时不会嵌入调试信息,可执行文件更简洁
- 开启全量优化:编译器会进行各种代码优化,比如:
- 代码优化:合并重复代码、消除不会执行的死代码
- 性能优化:对循环进行展开以减少循环 overhead、对变量进行寄存器级别的优化以加快访问速度、对函数调用进行内联(Inline)以减少函数调用的开销等
- 可执行文件较小:由于移除了调试信息且经过优化,生成的可执行文件体积更小
- 运行速度快:经过编译优化后,程序运行效率更高,能更好地利用系统资源
总结对比:
| 维度 | Debug 模式 | Release 模式 |
|---|---|---|
| 用途 | 开发、调试阶段 | 发布给用户的最终版本 |
| 调试信息 | 包含完整调试信息 | 无调试信息 |
| 代码优化 | 关闭或极少优化 | 开启全量优化 |
| 可执行文件大小 | 较大 | 较小 |
| 运行速度 | 较慢 | 较快 |
简单来说:Debug 是 “方便开发者找问题” 的版本,Release 是 “让用户高效使用” 的版本。
2. 在Linux上我们要怎么进行调试?
在 Linux 系统中,使用 gcc 或 g++ 编译程序时,默认采用的是类似 Release 的模式 —— 生成的可执行文件经过一定优化,且不包含调试信息。
- 而程序要进行调试(例如:使用 gdb 调试工具),必须以 Debug 模式编译
- 因为 Debug 模式会保留调试信息(如:变量名、代码行号映射等),这是调试工具能准确定位问题的基础
因此:Linux 下用默认方式编译的程序无法直接调试。
疑问:那我们要怎么切换到 Debug 模式呢?
若要切换到 Debug 模式,只需在编译时添加 -g 选项即可,例如:
# 以 Debug 模式编译单个源文件 gcc main.c -o program -g# 以 Debug 模式编译多个源文件 gcc main.c process.c -o program -g
- 添加
-g选项后,编译器会在生成的可执行文件中嵌入调试信息,此时就能用 gdb 等工具进行调试了(如:gdb ./program)

readelf -S code1/code2 | grep -i debug:用于查看可执行文件code1/code2中与调试(debug)相关的段(section)信息,帮助判断程序是否包含调试符号(即是否以支持调试的方式编译)
命令拆解
readelf -S code1/code2:执行后会列出code1/code2所有段的详细信息
readelf:是 Linux 下的工具,用于查看 ELF 格式文件(可执行文件、库文件等)的信息
-S:选项表示查看文件的 段(Section) 信息(段是 ELF 文件中承载不同类型数据的单元,比如:代码段、数据段、调试信息段等)
| grep -i debug:
|:是管道符,将前一个命令(readelf -S processbar)的输出传递给后一个命令(grep)
grep:用于在文本中筛选匹配的内容
-i:选项表示忽略大小写,debug是要匹配的关键词(筛选与调试相关的段)
实际效果
- 如果程序是以 Debug 模式编译(比如:用
gcc -g编译,包含调试符号),执行该命令会输出包含debug的段信息(例如:.debug_info、.debug_line等调试相关段)- 如果程序是以 Release 模式编译(默认编译,无
-g选项,无调试符号),执行该命令可能没有输出,或只有极少与调试无关的零星匹配(说明程序几乎不含调试信息)简单来说:这条命令是用来快速验证可执行文件是否包含调试符号的 “探针”~
3. 怎么快速简单的使用gdb进行调试?
1. 快速认识使用 gdb
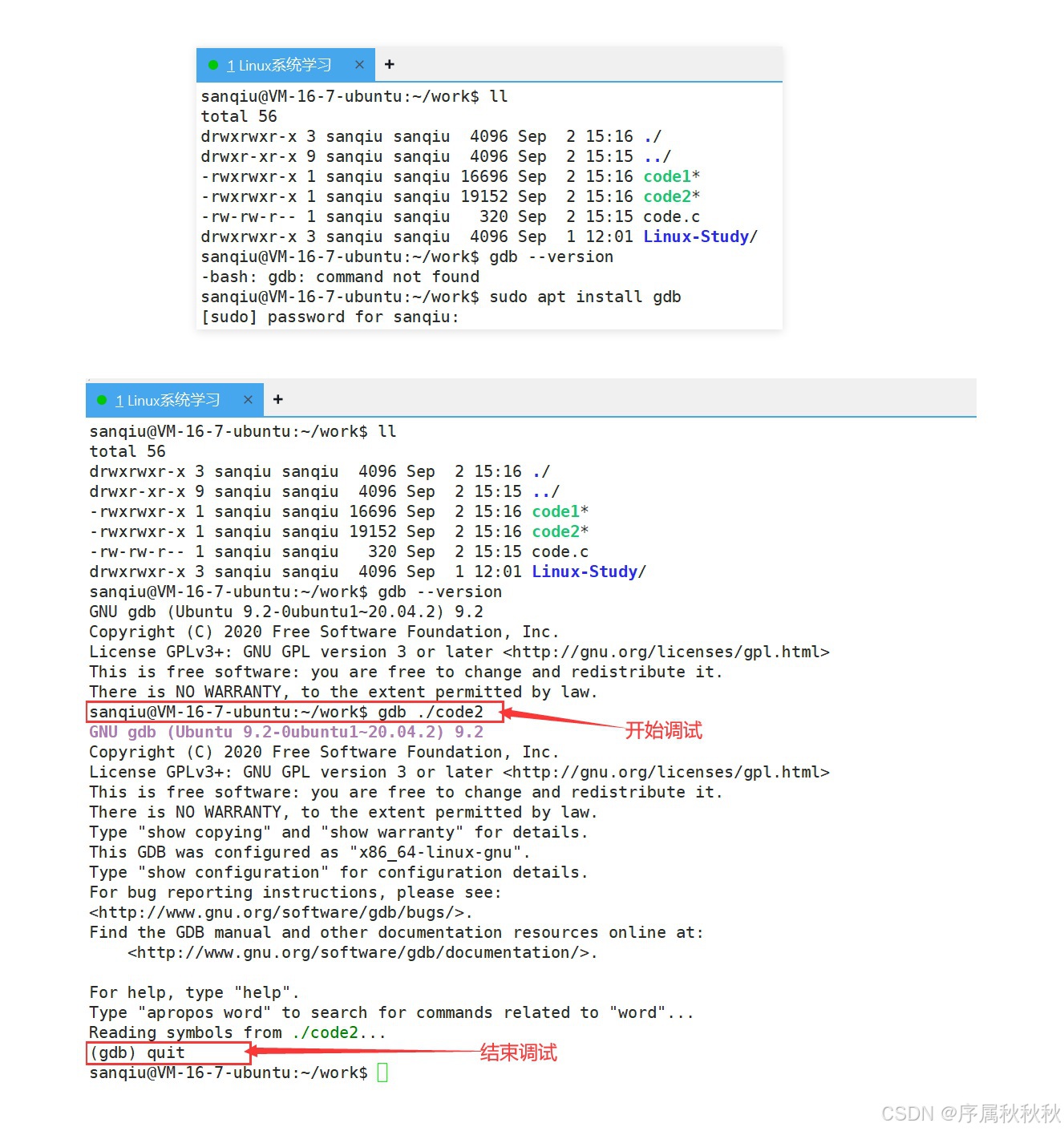
开始调试:要开始使用 gdb 调试程序,可通过命令
gdb 可执行文件(比如:gdb bin)启动 gdb 并加载待调试的可执行文件结束调试:当调试完成后,输入
quit命令即可退出 gdb 调试环境
2. 掌握基础调试命令
- 源代码查看
- 断点管理
- 程序运行控制
另外,在 gdb 不退出的情况下,多次设置断点,断点编号会依次递增,方便管理多个断点。
| 命令 | 作用 | 样例 |
|---|---|---|
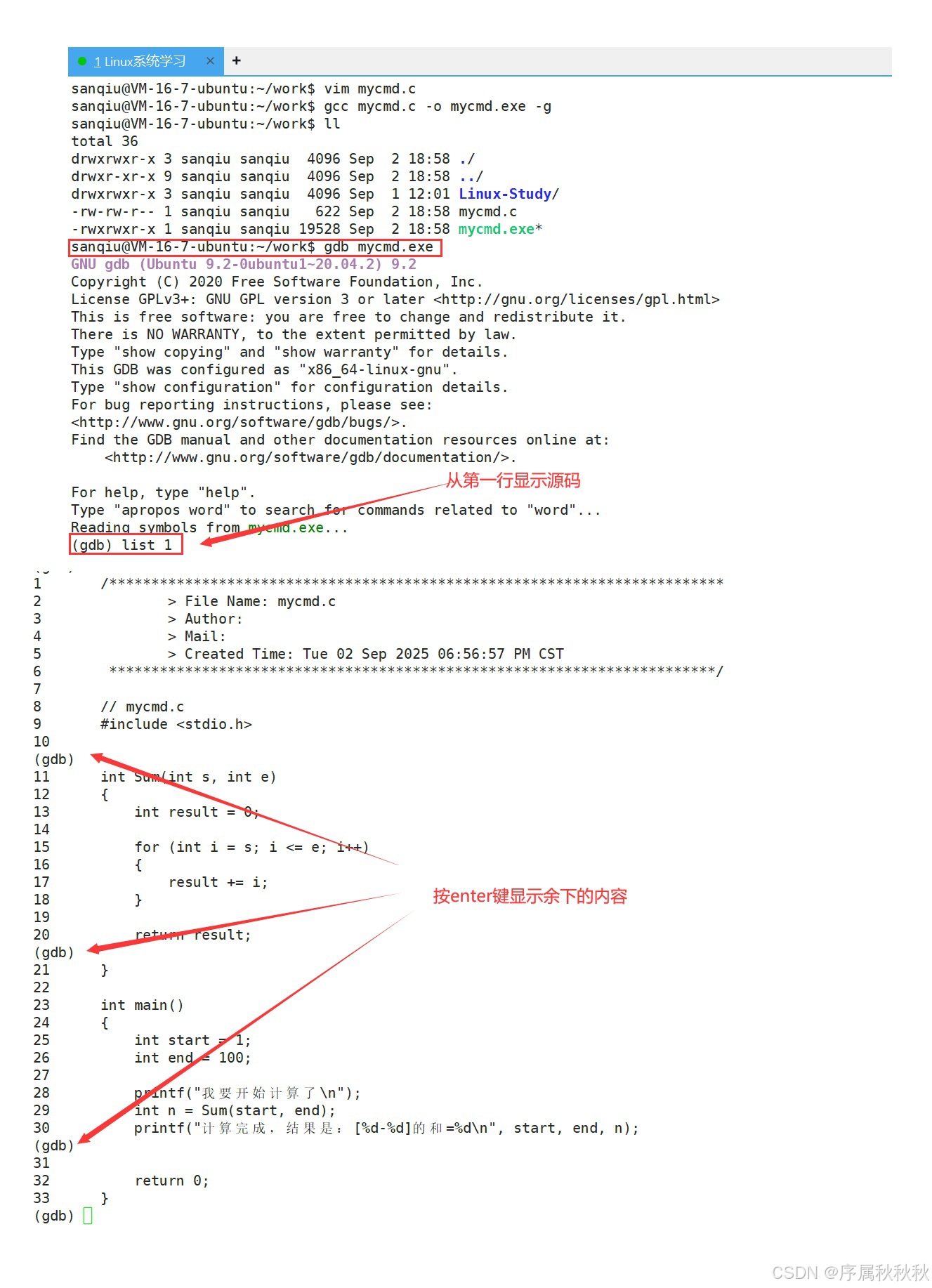
list/l | 显示源代码,从上次位置开始,每次列出 10 行 | list/l 10 |
list/l 函数名 | 列出指定函数的源代码 | list/l main |
list/l 文件名:行号 | 列出指定文件的源代码 | list/l mycmd.c:1 |
| 命令 | 作用 | 样例 |
|---|---|---|
break/b [文件名:]行号 | 在指定行号设置断点 | break 10break test.c:10 |
break/b 函数名 | 在函数开头设置断点 | break main |
info break/b | 查看当前所有断点的信息 | info break |
| 命令 | 作用 | 样例 |
|---|---|---|
r/run | 从程序开始连续执行 | run |
continue/c | 从当前位置开始连续执行程序 | continue |
n/next | 单步执行,不进入函数内部,逐过程(类似 F10) | next |
s/step | 单步执行,进入函数内部,逐语句(类似 F11) | step |

4. 如何更好的进行调试?
我们可以借助 cgdb 来改善 gdb 的使用体验,cgdb能让代码和调试信息同时展示,为 gdb 提供更友好的界面,方便调试时查看代码:
- 在 CentOS 系统上,使用
sudo yum install -y cgdb来安装 cgdb- 在 Ubuntu 系统上,使用
sudo apt install -y cgdb安装 cgdb
温馨提示:使用gdb/cgdb进行调试时候,指定调试的可执行程序一定要是使用
-g编译生成的,不然的话,无法显示要调试的代码。

简单的了解一下cgdb的分屏切换操作:

学会简单的使用cgdb的分屏界面切换后,接下来我们就来学习怎么在cgdb中进行调试啦。
这里先说明一下,我们使用的调试代码是:
// mycmd.c
#include <stdio.h>int flag = 0; //故意错误int Sum(int s, int e)
{int result = 0;for (int i = s; i <= e; i++){result += i;}//return result;return result * flag; //故意错误
}int main()
{int start = 1;int end = 100;printf("I will begin\n");int n = Sum(start, end);printf("running done, result is: [%d-%d]=%d\n", start, end, n);return 0;
}
| 命令 | 作用 | 样例 |
|---|---|---|
p 变量 | 打印指定变量的值 | p x |
finish | 执行到当前函数返回然后停止 | finish |
backtrace/bt | 查看当前执行栈的各级函数调用及参数 | backtrace |


在 gdb 中使用
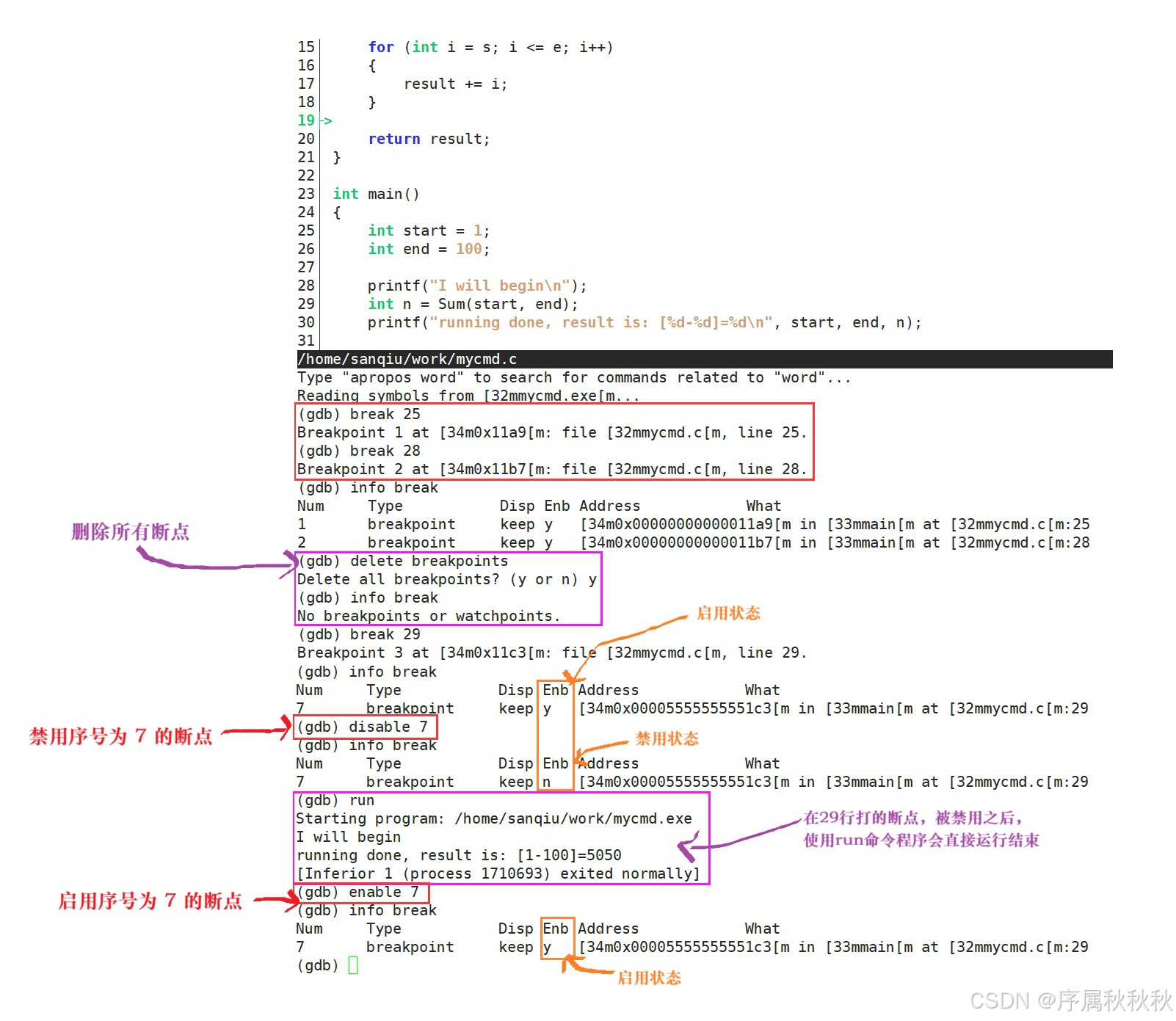
info break(或info breakpoints)命令查看断点信息时,输出的每一列都有其特定含义,下面来逐一解释:Num(断点编号):这一列显示的是断点的编号,是 gdb 为每个断点分配的唯一标识。
- 示例中显示为
1,说明当前只有一个断点,编号为 1- 通过这个编号,我们可以对特定的断点进行操作
- 比如删除(
delete 断点编号)、禁用(disable 断点编号)或启用(enable 断点编号)等
Type(断点类型):表示断点的类型,示例中是 breakpoint,即普通的软件断点。
- gdb 还支持其他类型的断点,不过在日常调试中,
breakpoint是最常用的,用于在指定的代码位置暂停程序执行
Disp(断点处置方式):说明当断点被命中后,该断点的状态变化。
- 示例中是
keep,意味着断点被命中后,仍然会保留,下次程序执行到该位置时,还会在此处暂停- 还有其他处置方式,比如:
delete(断点被命中后自动删除,仅生效一次)等
Enb(断点启用状态):显示断点是否处于启用状态。
- 示例中是
y(yes的缩写),表示该断点是启用的,程序执行到此处会暂停- 如果是
n(no的缩写),则表示断点被禁用,不会产生暂停效果
Address(断点地址):显示断点所在的内存地址。
- 示例中是类似
0x000000000001c3这样的十六进制地址,它对应着程序代码在内存中的具体位置,帮助我们从底层了解断点的位置
What(断点相关信息):这一列包含了断点的具体位置等详细信息。
- 示例中显示
in main at mycmd.c:29,意思是这个断点设置在mycmd.c文件中main函数里的第 29 行,明确了断点在代码层面的位置,方便我们快速定位到对应的代码处通过
info break命令输出的这些信息,我们可以全面了解当前所有断点的状态、位置等情况,从而更好地管理和使用断点进行调试工作。
| 命令 | 作用 | 样例 |
|---|---|---|
delete/d break | 删除所有断点 | delete break |
delete/d n | 删除序号为 n 的断点 | delete 1 |
| 命令 | 作用 | 样例 |
|---|---|---|
disable break | 禁用所有断点 | disable break |
disable n | 禁用序号为 n 的断点 | disable 1 |
enable break | 启用所有断点 | enable break |
enable n | 启用序号为 n 的断点 | enable 1 |
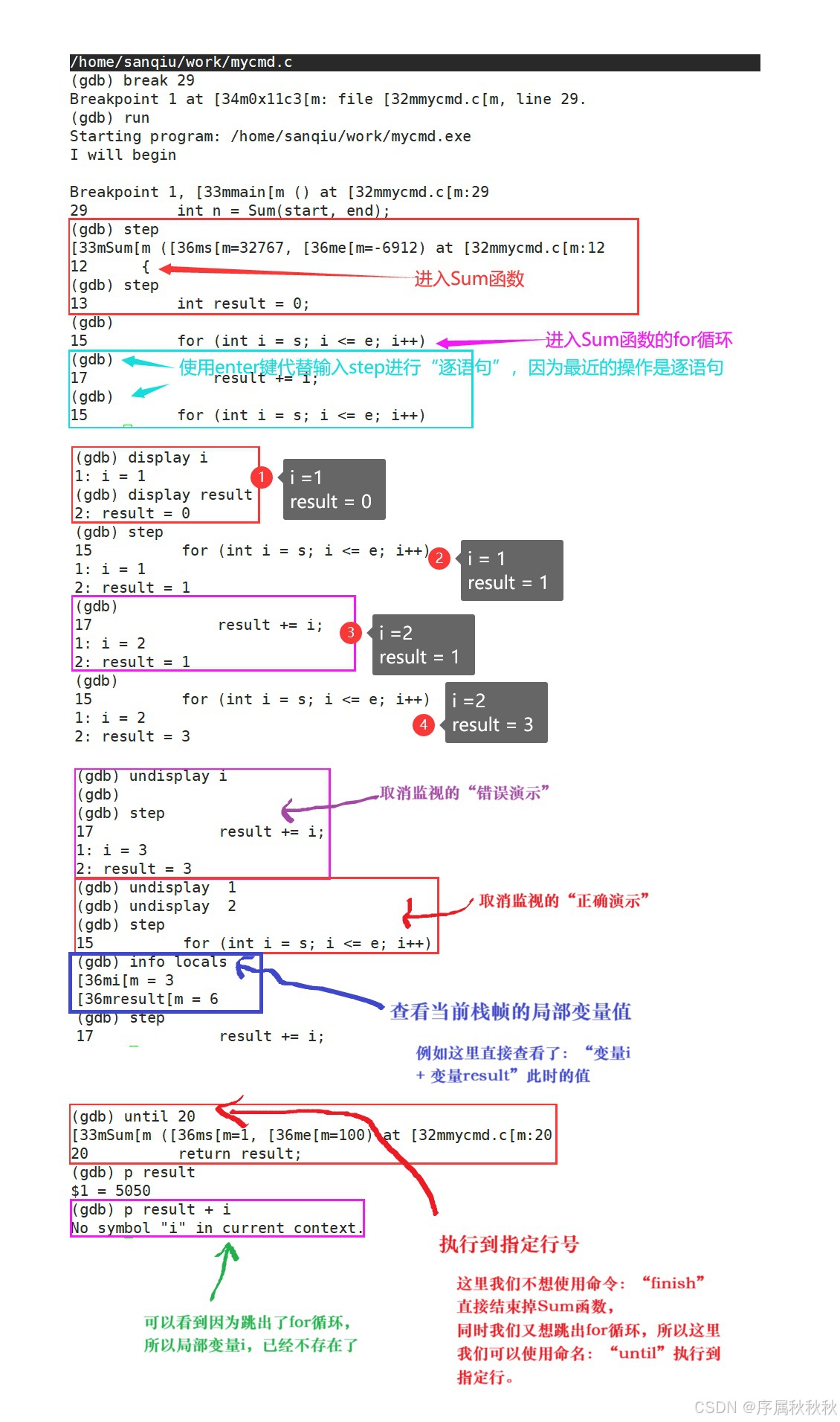
疑问:我们知道使用VS进行调试有一个非常好用的功能就是:“监视”,那么我们应该怎么使用cgdb进行监视呢?
| 命令 | 作用 | 样例 |
|---|---|---|
display 变量名 | 跟踪显示指定变量的值(每次停止时) | display x |
info/i locals | 查看当前栈帧的局部变量值 | info locals |
undisplay 编号 | 取消对指定编号的变量的跟踪显示 | undisplay 1 |
until 行号 | 执行到指定行号 | until 20 |
| 命令 | 作用 | 样例 |
|---|---|---|
print/p 表达式 | 打印表达式的值 | print start+end |
5. 掌握二个进阶调试技巧?
watch命令
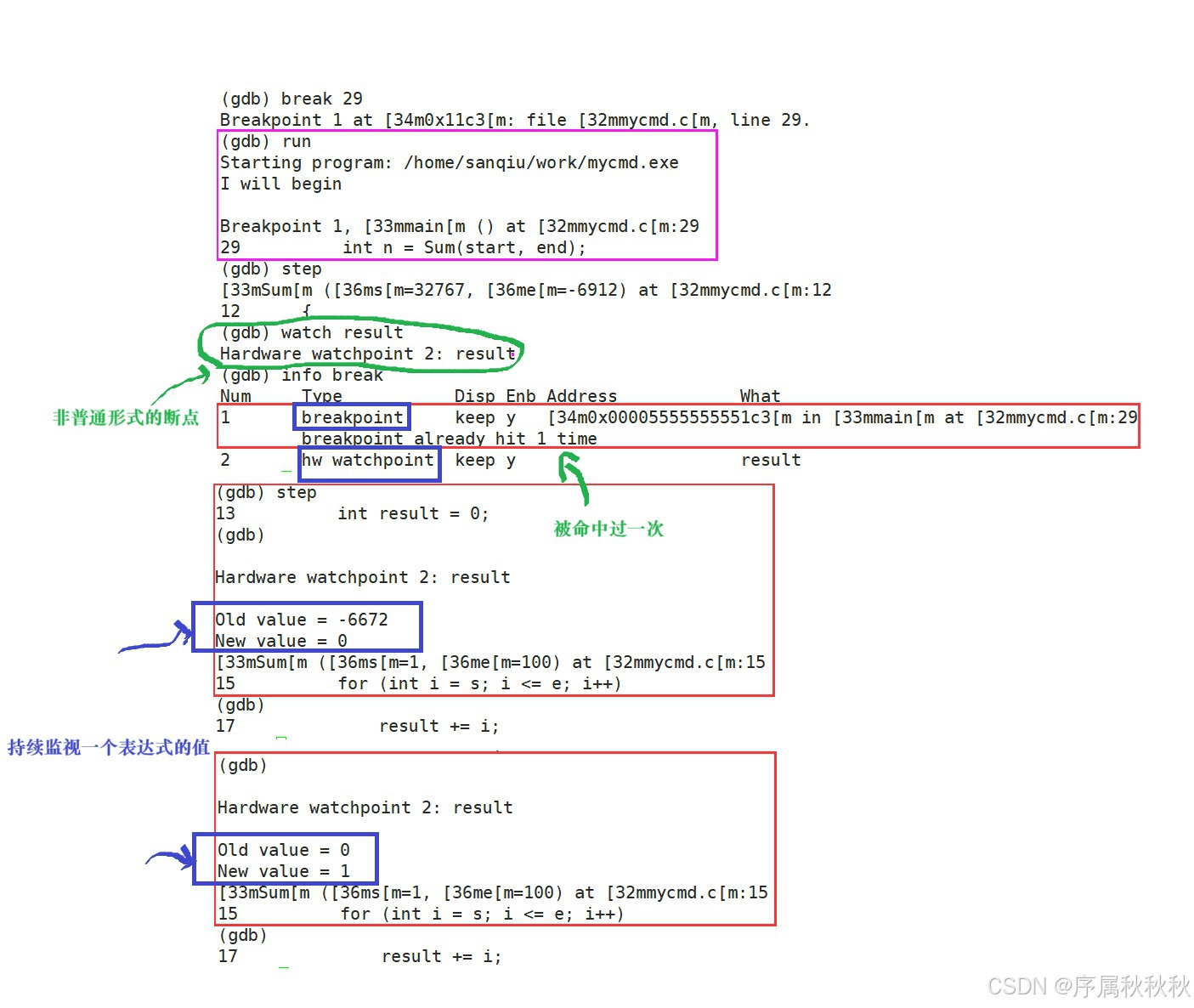
watch命令:变量与表达式监控watch 命令的核心作用是:在程序执行过程中,持续监视一个表达式(比如:变量、算术表达式等)的值
- 当被监视的表达式在程序运行期间发生变化时,gdb 会立即暂停程序的执行
- 并向开发者发出通知,方便及时排查因值变化引发的问题
使用场景
- 若有某个变量理论上不应被修改,但你怀疑它的意外修改导致了程序异常,就可以用
watch命令监视它- 一旦该变量的值发生改变,gdb 会立刻提醒你,帮助定位 “非法修改” 的源头
注意事项
watch不仅能监视单个变量,还能监视更复杂的表达式(如:a + b、ptr->value等),只要表达式的值发生变化,就会触发暂停
set vat命令
set var:修改变量以定位问题set var 命令的作用是:在调试过程中,手动修改程序中变量的值
- 通过主动改变变量的状态,我们可以模拟不同的执行场景,进而确定问题的原因(比如:验证 “变量取某一值时是否会触发异常”)
使用场景
- 假设程序中有一个标志位变量
flag,我们怀疑代码逻辑在flag为某一特定值时会出错- 此时可以用
set var flag = 1(假设目标值为 1)修改标志位,然后继续执行程序,观察是否会出现预期的问题,以此来验证问题是否由该变量的取值导致

6. 调试的本质是什么?
调试的本质可以概括为以下几个关键环节:
- 定位问题:这是调试的首要步骤,需要借助各类调试命令来找出程序中存在的错误或异常所在的位置
- 查看代码上下文:在定位到问题相关区域后,查看该区域前后的代码逻辑,以更好地理解问题产生的场景和条件
- 解决问题:根据对问题的分析,采取相应的措施修复程序错误
而断点在调试中有着重要作用:它的本质是对代码进行块级别的划分,能够以代码块为单位,帮助我们快速定位到可能存在问题的代码区域。
此外,还有一些调试命令也很实用:
finish命令:可以用于确认问题是否出在当前正在执行的函数内部until命令:能够实现局部区域代码的快速执行,方便我们跳过一些无需逐行调试的代码段
7. 什么是条件断点?
使用一:直接添加条件断点

使用二:给已存在的断点新增条件

