任务调度框架:PowerJob、XXL-Job、OpenJob
概述
说到任务调度框架,很多Java开发者第一想到的可能是Quartz?JDK Timer?或ScheduledExecutor?Spring Schedule?
实际上,此外还要很多可选项。
PowerJob
官网,原OhMyScheduler,新一代开源(GitHub,7.6K Star,1.3K Fork)分布式任务调度与计算框架,支持CRON、API、固定频率、固定延迟等调度策略,提供工作流来编排任务解决依赖关系,能让您轻松完成作业的调度与繁杂任务的分布式计算。官方文档。
XXL-Job的问题
- 数据库支持单一: 仅支持MySQL,使用其他DB需要自己魔改代码
- 有限的分布式计算能力: 仅支持静态分片,无法很好的完成复杂任务的计算
- 不支持工作流: 无法配置各个任务之间的依赖关系,不适用于有DAG需求的场景
PowerJob=任务调度+分布式计算和工作流,主要特性:
- 使用简单:提供前端Web界面,允许开发者可视化地完成调度任务的管理(增、删、改、查)、任务运行状态监控和运行日志查看等功能;
- 定时策略完善:支持CRON表达式、固定频率、固定延迟和API四种定时调度策略;
- 执行模式丰富:支持单机、广播、Map、MapReduce四种执行模式,其中Map/MapReduce处理器能使开发者寥寥数行代码便获得集群分布式计算的能力;
- DAG工作流支持:支持在线配置任务依赖关系,可视化得对任务进行编排,同时还支持上下游任务间的数据传递;
- 执行器支持广泛:支持Spring Bean、内置/外置Java类、Shell、Python等处理器,应用范围广;
- 运维便捷:支持在线日志功能,执行器产生的日志可以在前端控制台页面实时显示,降低debug成本,极大地提高开发效率;
- 依赖精简:最小仅依赖关系型数据库(MySQL/PostgreSQL/Oracle/MS SQLServer…),同时支持所有Spring Data JPA所支持的关系型数据库;
- 高可用&高性能:调度服务器经过精心设计,一改其他调度框架基于数据库锁的策略,实现无锁化调度。部署多个调度服务器可以同时实现高可用和性能的提升(支持无限的水平扩展);
- 故障转移与恢复:任务执行失败后,可根据配置的重试策略完成重试,只要执行器集群有足够的计算节点,任务就能顺利完成。
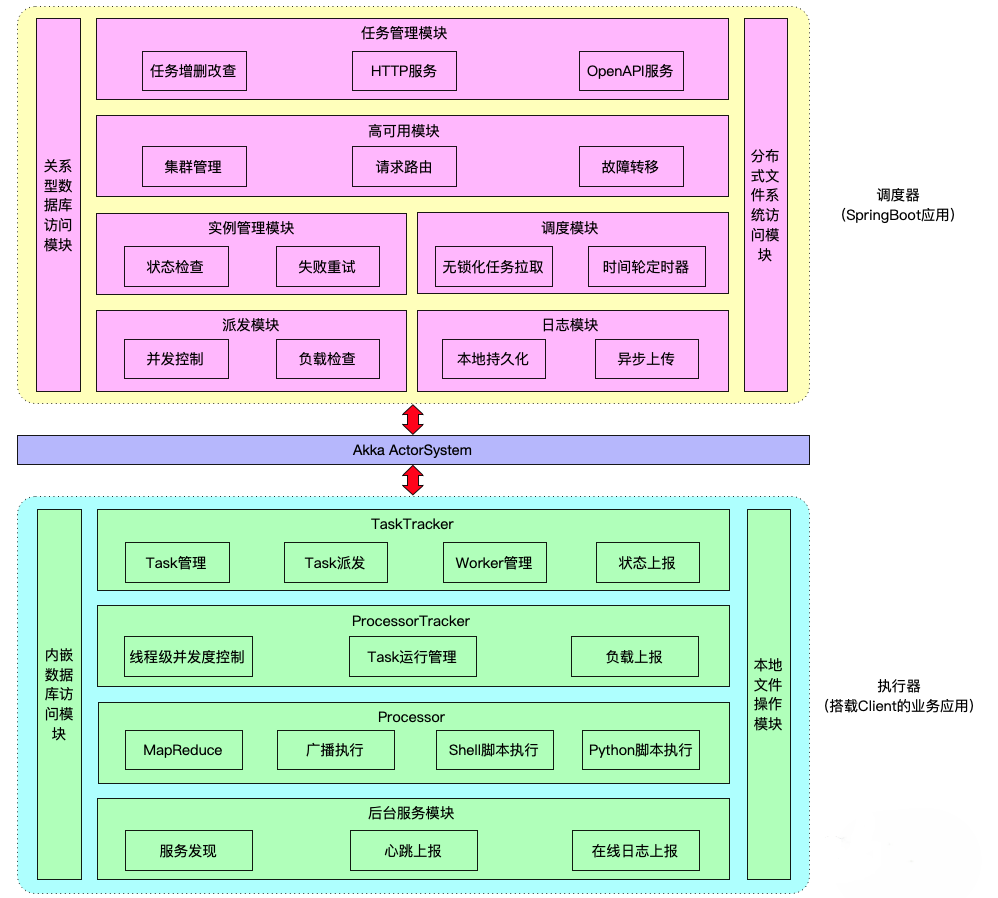
典型的server+worker架构:
- server:负责提供Web服务和完成任务的调度;
- worker:负责执行用户所编写的任务代码,同时提供分布式计算能力
实战
以Docker Compose方式部署:
git clone https://github.com/PowerJob/PowerJob.git
cd PowerJob/others/dev
# 必须执行,构建Jar
./build_test_env.sh
docker-compose up -d
官方并没有将构建好的Docker镜像上传到官方或三方仓库,需自行构建;其中./build_test_env.sh会从Maven仓库下载三方依赖,耗时可能会比较久。
为啥还要下载Python 2.7版本?
这一步还是很折腾的。
成功后,浏览器打开http://localhost:7700,即可体验Dashboard管理台界面功能:
选择第一个,钉钉官方文档给出的登录用户名密码无效;注册然后登录即可:
点开【用户管理】弹窗提示:
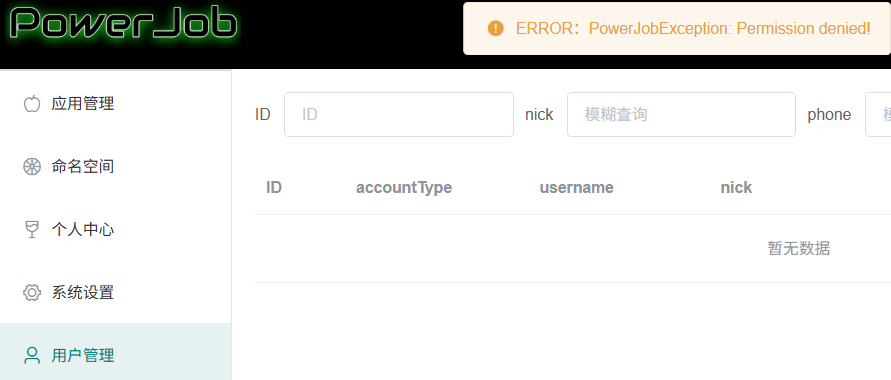
不支持修改全局管理员,没有权限:
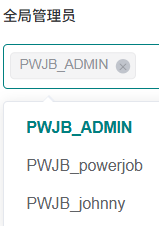
可是搜遍配置文件,试尽用户名密码,还是没找到预置的ADMIN账户。
集成
Maven项目引入
<dependency><groupId>tech.powerjob</groupId><artifactId>powerjob-client</artifactId><version>${latest.powerjob.version}</version>
</dependency>
@Slf4j
@Component
public class StandaloneProcessorDemo implements BasicProcessor {@Overridepublic ProcessResult process(TaskContext context) throws Exception {log.info("context: {}.", context);return new ProcessResult(true, "process successfully~");}
}
配置类:
@Configuration
public class SchedulerConfig {@Beanpublic OhMyWorker initOMS() throws Exception {List<String> serverAddress = Lists.newArrayList("127.0.0.1:7700");OhMyConfig config = new OhMyConfig();config.setPort(27777);config.setAppName("oms-test");config.setServerAddress(serverAddress);// 如果没有大型 Map/MapReduce 的需求,建议使用内存来加速计算config.setStoreStrategy(StoreStrategy.MEMORY);// 创建Worker对象,设置配置文件OhMyWorker ohMyWorker = new OhMyWorker();ohMyWorker.setConfig(config);return ohMyWorker;}
}
XXL-Job
个人最熟悉的框架,参考:
- XXL-JOB深度实战
- XXL-JOB任务有效期支持实现方案
- XXL-JOB逻辑自测及执行参数配置踩坑
- Spring @Scheduled定时任务接入XXL-JOB的一种方案(基于SC Gateway)
Elastic-Job
OpenJob
开源(GitHub,954 Star,96 Fork)的基于Akka架构的分布式高性能任务调度框架,支持多种定时任务、延时任务、工作流设计、轻量级分布式计算;底层使用一致性分片算法,采用无中心化架构,支持无限水平扩容;具有较高的可伸缩性和容错性,以及完善权限管理、强大的告警监控、原生支持多语言。
功能特性
- 高可靠:分布式无状态设计,采用Master/Worker架构,支持多种数据库,如MySQL、H2、PostgreSQL、Oracle、TiDB;
- 高性能:底层使用一致性分片算法,全程无锁化设计,任务调度精确到秒级别,支持轻量级分布式计算、无限水平扩容;
- 定时调度:支持分布式定时任务、固定频率任务、高性能秒级任务、一次性任务定时调度;
- 分布式计算:支持单机、广播、Map、MapReduce和分片多种分布式编程模型,轻松实现大数据分布式计算;
- 延时任务:基于Redis实现高性能延时任务,底层实现任务多级存储,提供丰富的统计和报表;
- 工作流:内置工作流调度引擎,支持可视化DAG设计,简单高效实现复杂任务调度;
- 权限管理:完善的用户管理,支持菜单、按钮以及数据权限设置,灵活管理用户权限;
- 报警监控:全面的监控指标,丰富及时的报警方式,便于运维人员快速定位和解决线上问题;
- 跨语言:原生支持Java/Go/PHP/Python多语言,以及Spring Boot、Gin、Swoft等框架集成。
供参考
| 项目 | Quartz | Elastic-Job | XXL-JOB | Openjob |
|---|---|---|---|---|
| 定时调度 | Cron | Cron | Cron | 1.定时任务2.秒级任务3.一次性任务4.固定频率 |
| 延时任务 | 不支持 | 基于cron | 基于cron | 基于Redis实现分布式高性能延时任务,实现定时与延时一体化 |
| 任务编排 | 不支持 | 不支持 | 不支持 | 通过图形化编排任务(workflow) |
| 分布式计算 | 不支持 | 静态分片 | 广播 | 1.广播2.Map/MapReduce3.多语言静态分片 |
| 多语言 | Java | Java或脚本任务 | Java或脚本任务 | 1.Java2.Go(Gin、beego)3.PHP(Swoft)*Python(Agent)4.脚本任务5.HTTP任务6.Kettle |
| 可视化 | 无 | 弱 | 1.历史记录2.运行日志(不支持存储)3.监控大盘 | 1.历史记2.运行日志,支持H2、MySQL、ES;3.监控大盘4.操作记录5.查看日志堆栈 |
| 可运维 | 无 | 启用、禁用任务 | 1.启用、禁用任务2.手动运行任务3.停止任务 | 1.启用、禁用任务2.手动运行任务3.停止任务 |
| 报警监控 | 无 | 邮件 | 邮件 | 邮件、Webhook(企微、飞书等) |
| 性能 | 每次调度通过DB抢锁,对DB压力大 | ZooKeeper是性能瓶颈 | 由Master节点调度,Master节点压力大。 | 务采用分片算法,每个节点都可以调度,无性能瓶颈,支持无限水平扩展,支持海量任务调度 |
原理
分片任务
分片模型主要包含:
- 静态分片:主要场景是处理固定的分片数,如分库分表中固定256个库,需要若干台机器分布式去处理。
- 动态分片:主要场景是分布式处理未知数据量的数据,例如一张大表在不停变更,需要分布式跑批。此时需要使用MapReduce任务。
任务特性:
- 兼容Elastic-job的静态分片模型;
- 支持Java、PHP、Python、Shell、Go四种语言;
- 高可用:分片任务执行机器异常时,会动态分配到其它正常机器执行任务;
- 流量控制:可以设置单机子任务并发数。例如有100个分片,一共3台机器,可以控制最多5个分片并发执行,其它在队列中等待;
- 失败重试:子任务执行失败异常时,自动重试。
@Component
public class ShardingAnnotationProcessor {@Openjob("annotationShardingProcessor")public ProcessResult shardingProcessor(JobContext ctx) {log.info("Sharding annotation processor execute success! shardingId={} shardingNum={} shardingParams={}", ctx.getShardingId(), ctx.getShardingNum(), ctx.getShardingParam());return ProcessResult.success();}
}
MapReduce
通过MapProcessor或MapReduceProcessor接口实现,相对于传统的大数据跑批(如Hadoop、Spark等),MapReduce无需将数据导入大数据平台,且无额外存储及计算成本,即可实现秒级别海量数据处理,具有成本低、速度快、编程简单等特性。
@Slf4j
@Component("mapReduceTestProcessor")
public class MapReduceTestProcessor implements MapReduceProcessor { @Overridepublic ProcessResult process(JobContext context) {if (context.isRoot()) {List<MapChildTaskTest> tasks = new ArrayList<>();for (int i = 1; i < 5; i++) {tasks.add(new MapChildTaskTest(i));}return this.map(tasks, TWO_NAME);}if (context.isTask("TASK_TWO")) {MapChildTaskTest task = (MapChildTaskTest) context.getTask();List<MapChildTaskTest> tasks = new ArrayList<>();for (int i = 1; i < task.getId()*2; i++) {tasks.add(new MapChildTaskTest(i));}return this.map(tasks, THREE_NAME);}if (context.isTask("TASK_THREE")) {MapChildTaskTest task = (MapChildTaskTest) context.getTask();return new ProcessResult(true, String.valueOf(task.getId() * 2));}return ProcessResult.success();}@Overridepublic ProcessResult reduce(JobContext jobContext) {List<String> resultList = jobContext.getTaskResultList().stream().map(TaskResult::getResult).collect(Collectors.toList());return ProcessResult.success();}@Datapublic static class MapChildTaskTest {private Integer id;}
}
广播任务
广播任务类型的任务实例会广播到应用对应的所有Worker上执行,当所有Worker都执行完成,该任务才算完成,任意一台Worker执行失败,任务就算失败。
应用场景
- 批量操作
- 定时广播所有机器运行某个脚本
- 定时广播所有机器清理数据
- 动态启动每台机器的某个服务
- 数据聚合
- 使用JavaProcessor->preProcess初始化
- 每台机器执行process时,根据自己业务返回result
- 执行postProcess,获取所有机器的执行结果做汇总
任务特性
广播任务类型可以选择多种,如脚本或Java任务;对于后者,支持preProcess和postProcess高级特性:
- preProcess:会在每台机器执行
process之前执行,且只会执行一次。 - process:每台机器实际任务执行逻辑。
- postProcess:会在每台机器执行
process完成且都成功执行之后执行一次,可以返回结果,作为工作流数据传输。
@Component("broadcastPostProcessor")
public class BroadcastProcessor implements JavaProcessor {@Overridepublic void preProcess(JobContext context) {log.info("Broadcast pre process!");}@Overridepublic ProcessResult process(JobContext context) throws Exception {log.info("Broadcast process!");return new ProcessResult(true, "data");}@Overridepublic ProcessResult postProcess(JobContext context) {log.info("Broadcast post process taskList={}", context.getTaskResultList());return ProcessResult.success();}
}
实战
以Java+Maven项目为例,引入依赖:
<dependency><groupId>io.openjob.worker</groupId><artifactId>openjob-worker-core</artifactId>
</dependency>
<dependency><groupId>io.openjob.worker</groupId><artifactId>openjob-worker-spring-boot-starter</artifactId>
</dependency>