Algorithm Refinement: ε-Greedy Policy|算法改进:ε-贪婪策略
-----------------------------------------------------------------------------------------------
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
----------------------------------------------------------------------------------------------
一、为什么需要探索
在强化学习的训练过程中,智能体需要不断地与环境交互,
通过观察状态、采取动作、获得奖励,逐渐学会什么是“好”的决策。
但这里有一个核心问题:
如果智能体总是选择当前看起来最优的动作,会怎样?
它可能会陷入局部最优——
也就是说,它学到的策略在局部区域看起来很好,
但在整个任务范围内,其实存在更高的奖励路径却被忽略了。
因此,学习过程不能只“利用”(Exploitation)当前最优动作,
还必须保留一定比例的“探索”(Exploration)。
探索让模型尝试未知的可能,
哪怕短期内得到较低奖励,长期却能帮助找到全局最优解。

这张图(Learning Algorithm)展示了训练流程的基础逻辑:
-
初始化神经网络作为 Q(s,a) 的估计器。
-
智能体在 Lunar Lander 环境 中执行动作。
-
将收集到的状态、动作、奖励和下一个状态 (s,a,R(s),s’)存储起来。
-
从这些经验中采样,用于更新神经网络的参数。
这意味着智能体并非一次就学会,而是通过大量的探索与试错逐渐改进。
探索,是强化学习智能体“发现更好世界”的唯一途径。
二、ε-贪婪策略的核心思想
强化学习中的一个核心挑战是:
如何在“探索”(尝试新动作)与“利用”(执行当前最优动作)之间取得平衡?
ε-Greedy 策略提供了一个简单而高效的答案。
它通过一个参数 ε(epsilon) 来控制随机性:
-
以 概率 1−ε 选择当前 Q 值最高的动作(Exploitation,利用)。
-
以 概率 ε 随机选择一个动作(Exploration,探索)。
也就是说,智能体大多数时候会根据当前经验选择最优动作,
但仍会有少部分时间“冒险”尝试其它动作。
这种受控的随机性让模型在学习过程中不会停滞在局部最优。

在图中可以看到两种选择方式(Option 1 与 Option 2):
-
Option 1(贪婪选择):永远选择当前看起来最优的动作。
优点是收敛快,但缺点是容易陷入局部最优。
-
Option 2(ε-Greedy):以 95% 的概率选择最优动作,以 5% 的概率随机探索。
优点是能保持适度探索,提高整体策略质量。
这就是 ε-Greedy 策略的核心哲学:
不盲目贪婪,也不完全随机,在理性中保留好奇心。
通过这种方式,智能体在训练早期可以广泛探索环境,
随着经验积累,它会逐渐减少探索比例,从而聚焦于稳定的高收益策略。
三、ε 的动态调整
在 ε-Greedy 策略中,ε 的数值决定了智能体的探索倾向。
但一个固定的 ε 无法适应整个学习过程:
训练初期需要更多探索,而后期则需要稳定收敛。
因此,ε 应该是动态变化的。
1. 训练初期:高 ε 值(High Exploration)
在初期,智能体几乎不了解环境,
此时应当增加探索,例如将 ε 设为 1.0。
这意味着智能体几乎随机选择动作,
帮助它积累多样化的经验,了解各种状态—动作组合的后果。
2. 训练中期:平衡探索与利用
当智能体开始形成对环境的理解后,
ε 会逐步减小(例如从 1.0 降到 0.1)。
此阶段智能体仍有一定的探索行为,
但更多地倾向于选择那些过去表现较好的动作。
3. 训练后期:低 ε 值(High Exploitation)
到了后期,智能体已经掌握了主要规律,
ε 逐渐降至 0.01 或更低,
此时基本不再随机行动,而是“专注执行”最优策略。
数学上常见的 ε 变化方式包括:
-
线性衰减(Linear decay):
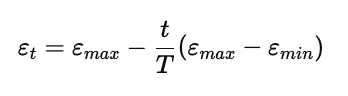
简单直接,训练越久探索越少。
-
指数衰减(Exponential decay):
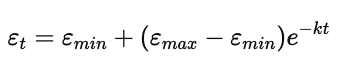
前期下降快,后期平稳,有助于模型稳定收敛。
通过这种逐步收缩 ε 的机制,
智能体能够在学习早期“勇于尝试”,
而在学习后期“稳健执行”。
这种自然过渡,是强化学习算法从混乱走向精确的关键。
四、Lunar Lander 中的实践与效果
在 Lunar Lander 环境中,智能体需要控制飞船安全降落到目标区域。
每个动作都对应不同的推力方向:
-
nothing:不点火;
-
left / right:使用左右推进器;
-
main:启动主推进器。
智能体的目标是根据状态 s(飞船位置、角度、速度等)
选择动作 a,最大化未来累计奖励 Q(s,a)。
1. ε-Greedy 的执行方式
在这个任务中,智能体会基于当前网络预测的 Q 值决定动作:
-
大多数时候(例如 95% 概率)选择当前最优动作;
-
其余时间随机选择动作,尝试不同策略。
这种随机探索使飞船能在早期“乱飞”时积累多样经验,
逐渐形成更准确的 Q 值估计。
2. 学习曲线的变化
训练初期,飞船的表现往往混乱——
它可能频繁坠毁、偏离目标、甚至点火过度。
但随着训练进行,Q 网络的预测更精准,ε 逐步下降,
智能体开始表现出显著改进:
-
学会提前调整姿态;
-
学会在接近地面时减速;
-
学会在不必要时节省燃料。
3. 策略稳定阶段
当 ε 接近 0.01 时,智能体已几乎停止探索。
此时它执行的是接近最优的落地策略,
飞船能平稳降落在两面旗帜之间,并且动作流畅。
最终结果表明:
ε-Greedy 并非只是“随机”,而是一种有意识的学习节奏控制。
它让神经网络在“混乱试探”中积累经验,
在“理性执行”中提炼出最优策略。
-----------------------------------------------------------------------------------------------
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
----------------------------------------------------------------------------------------------