【C++ 内存管理、模板初阶与 STL 简介】:打通高效编程的关键链路

💬 前言:
很多 C++ 开发者在进阶路上会遇到三个核心卡点:
写代码时担心内存泄漏却不知如何规范管控;
面对不同类型重复写相似逻辑,代码复用率极低;
想快速开发却不敢用 STL,怕踩底层实现的坑。
其实这三个问题的解决方案 ——内存管理、模板、STL,正是 C++ 从 “能写” 到 “写得好” 的关键。
本篇文章将按 “内存管控→通用代码→工程化库” 的逻辑,带你从底层理解内存分配原理,用模板写出跨类型的通用代码,再通过 STL 站在前人肩膀上高效开发。
✨ 阅读后,你将掌握:
- 从 malloc 到 new 的内存管理演进,避开泄漏、不匹配释放等陷阱;
- 用函数 / 类模板实现泛型编程,摆脱类型绑定的重复编码;
- STL 的核心组件与版本差异,学会在笔试、面试与工作中灵活运用 STL。
文章目录
- 一、C/C++ 内存管理:从底层管控到安全分配
- 1. 先搞懂:C/C++ 内存分布
- 2. C 语言的内存管理方式:malloc/calloc/realloc/free
- 3. C++ 的内存管理升级:new 与 delete
- 4. 底层原理:operator new 与 operator delete
- 5. malloc/free 与 new/delete 的核心区别
- 6. 定位 new 表达式(了解)
- 二、模板初阶:摆脱类型绑定的泛型编程
- 1. 为什么需要泛型编程?
- 2. 函数模板:通用函数的 “模具”
- 3. 类模板:通用类的 “蓝图”
- 三、STL 简介:站在前人肩膀上的工程化库
- 1. 什么是 STL?
- 2. STL 的主流版本
- 3. STL 的六大核心组件
- 4. STL 的重要性:笔试、面试、工作全覆盖
- 5. 学习 STL 的三个境界
- 四、思考与总结 ✨
- 五、自测题与答案解析 🧩
- 六、建议阅读顺序
- 七、下篇预告:C++ string 类常用接口实战
一、C/C++ 内存管理:从底层管控到安全分配
内存是程序的 “血液”,不规范的内存操作会导致泄漏、崩溃等致命问题。C++ 在 C 语言基础上优化了内存管理方式,核心是让自定义类型的内存分配与释放更安全、更自动化。
1. 先搞懂:C/C++ 内存分布
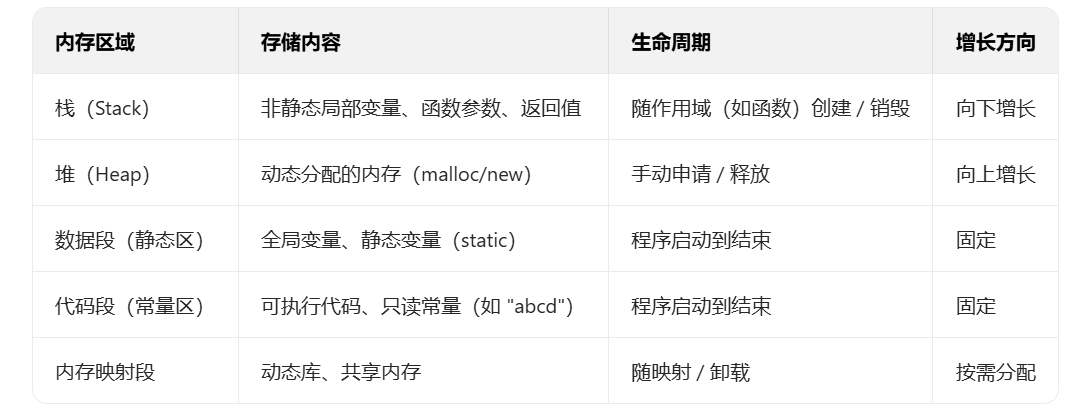
要管好内存,首先得知道不同变量存在哪。C/C++ 程序内存分为 5 个区域,各自有明确的存储对象与生命周期:
// 测试内存分布的代码
int globalVar = 1; // 数据段(静态区):全局变量
static int staticGlobalVar = 1; // 数据段:静态全局变量void Test() {static int staticVar = 1; // 数据段:静态局部变量int localVar = 1; // 栈:非静态局部变量int num1[10] = {1,2,3,4}; // 栈:数组(元素在栈上)char char2[] = "abcd"; // 栈:数组本身在栈,内容"abcd"在代码段,会拷贝到栈const char* pChar3 = "abcd"; // 栈:指针pChar3在栈,指向代码段的"abcd"int* ptr1 = (int*)malloc(sizeof(int)*4); // 堆:ptr1在栈,指向堆上的空间int* ptr2 = (int*)calloc(4, sizeof(int)); // 堆:同ptr1,空间初始化为0int* ptr3 = (int*)realloc(ptr2, sizeof(int)*4); // 堆:扩容ptr2指向的空间free(ptr1);free(ptr3); // 注意:realloc后ptr2失效,只需释放ptr3
}
内存区域划分与特点
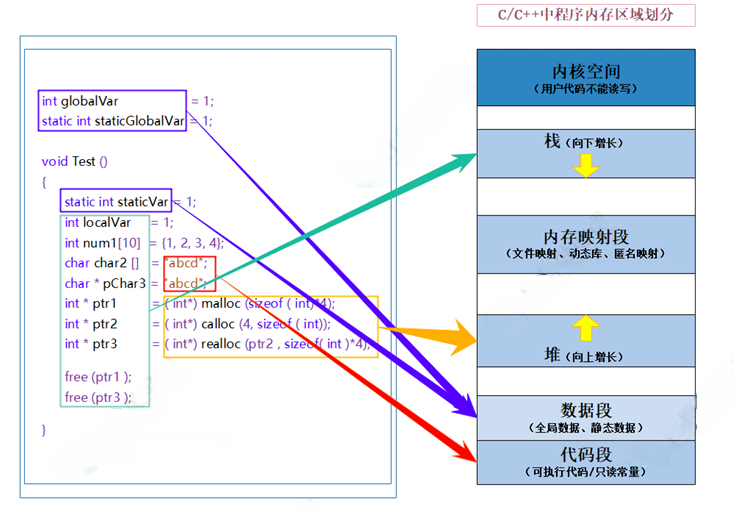
💡 高频面试题:
char2[]与pChar3的区别?
char2[]:数组在栈上,会把代码段的 “abcd” 拷贝到栈,修改char2[0]合法;pChar3:指针在栈上,指向代码段的只读常量,修改*pChar3会触发内存错误。
2. C 语言的内存管理方式:malloc/calloc/realloc/free
C 语言通过四个函数实现动态内存管理,但仅能完成 “开空间 / 释空间”,无法处理自定义类型的初始化与资源清理:
(1)三个分配函数的核心区别
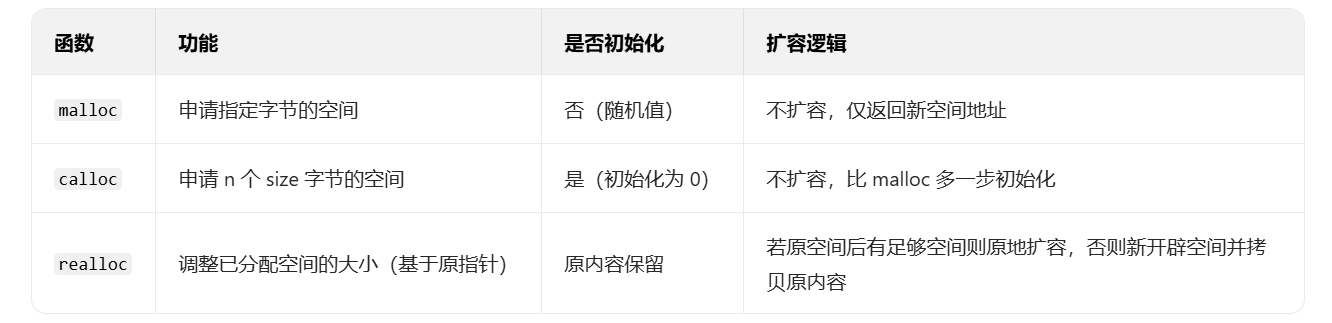
(2)使用注意事项
void Test() {// 1. calloc初始化:4个int,每个初始化为0int* p2 = (int*)calloc(4, sizeof(int)); // 2. realloc扩容:注意p2可能失效,需用新指针接收int* p3 = (int*)realloc(p2, sizeof(int)*10); // 错误:realloc成功后p2指向的旧空间已释放,不能再free(p2)// free(p2); free(p3); // 正确:仅释放扩容后的p3
}
💡 避坑点: realloc的原指针可能失效,切勿再操作原指针;若扩容失败返回NULL,需提前保存原指针避免内存泄漏。
3. C++ 的内存管理升级:new 与 delete
C 语言的内存方式无法满足自定义类型的需求(如构造 / 析构函数调用),因此 C++ 引入new和delete操作符,核心优势是对自定义类型自动调用构造 / 析构函数。
(1)new/delete 操作内置类型
与 malloc 类似,但无需计算字节数、无需强转,还支持初始化:
void Test() {// 1. 申请单个int空间(未初始化)int* ptr4 = new int; // 2. 申请单个int并初始化为10int* ptr5 = new int(10); // 3. 申请3个int的数组(未初始化,C++11支持{1,2,3}初始化)int* ptr6 = new int[3]; // 释放:必须与申请匹配!单个用delete,数组用delete[]delete ptr4; // 正确:释放单个元素delete ptr5; // 正确:释放单个元素delete[] ptr6; // 正确:释放数组// delete ptr6; // 错误:数组用单个delete,可能导致析构不完整//以上delete后指针都要置为nullptr
}
(2)new/delete 操作自定义类型(核心差异)
这是 new 与 malloc 的本质区别:new 会先开空间,再调用构造函数;delete 会先调用析构函数,再释空间。
class A {
public:A(int a = 0) : _a(a) {cout << "A():" << this << endl; // 构造函数}~A() {cout << "~A():" << this << endl; // 析构函数}
private:int _a;
};int main() {// 1. malloc:仅开空间,不调用构造A* p1 = (A*)malloc(sizeof(A)); // 2. new:开空间 + 调用构造(传参1)A* p2 = new A(1); // 3. free:仅释空间,不调用析构free(p1); // 4. delete:调用析构 + 释空间delete p2; p2 = nullptr; // 手动置空,避免野指针// 数组场景:new[]调用n次构造,delete[]调用n次析构A* p6 = new A[3]; // 3次构造delete[] p6; // 3次析构p6 = nullptr; // 手动置空,彻底避免野指针return 0;
}
输出结果(可见构造 / 析构的自动调用):
A():00CFF788 // p2的构造
~A():00CFF788 // p2的析构
A():00CFF79C // p6[0]的构造
A():00CFF7A0 // p6[1]的构造
A():00CFF7A4 // p6[2]的构造
~A():00CFF7A4 // p6[2]的析构(数组析构顺序与构造相反)
~A():00CFF7A0 // p6[1]的析构
~A():00CFF79C // p6[0]的析构
4. 底层原理:operator new 与 operator delete
new和delete是操作符,底层实际调用系统提供的全局函数operator new和operator delete:
(1)operator new:底层封装 malloc
operator new的核心逻辑是 “用 malloc 申请空间,失败则抛异常(而非返回 NULL)”,源码简化如下:
void* __CRTDECL operator new(size_t size) {void* p;// 循环申请:malloc失败时尝试调用用户自定义的空间不足处理函数while ((p = malloc(size)) == 0) {if (_callnewh(size) == 0) {// 申请失败,抛bad_alloc异常throw std::bad_alloc();}}return p;
}
(2)operator delete:底层封装 free
operator delete最终调用free释放空间,源码简化如下:
void operator delete(void* pUserData) {if (pUserData == NULL) return;// 加锁保证线程安全,最终调用free_mlock(_HEAP_LOCK);__TRY_free_dbg(pUserData, _NORMAL_BLOCK); // 封装free__FINALLY_munlock(_HEAP_LOCK);__END_TRY_FINALLY
}
💡 关键结论: new 的底层是 operator new + 构造函数,delete 是析构函数 + operator delete;operator new/delete 本质是对 malloc/free 的封装,增加了异常处理与线程安全。
5. malloc/free 与 new/delete 的核心区别
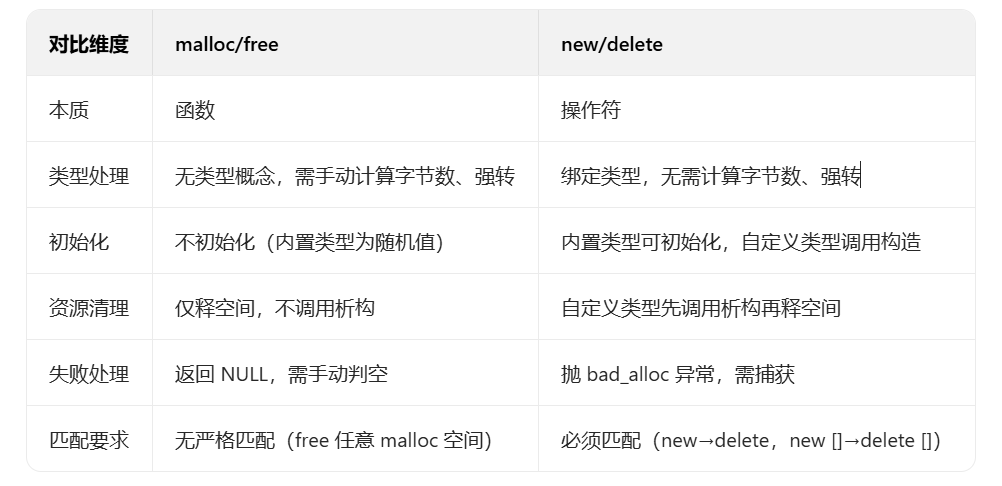
6. 定位 new 表达式(了解)
定位 new 是 “在已分配的原始内存中调用构造函数”,主要配合内存池使用(内存池分配的空间未初始化,需显式调用构造):
int main() {// 1. 用malloc分配与A同大小的原始空间(未调用构造)A* p1 = (A*)malloc(sizeof(A)); // 定位new:在p1指向的空间调用构造(可传参)new(p1)A(10); // 2. 手动调用析构(定位new无对应的delete,需显式析构)p1->~A(); free(p1); // 释放空间return 0;
}
这里 malloc 负责 “开空间”,定位 new 负责 “在空间上构造对象”。
二、模板初阶:摆脱类型绑定的泛型编程
写过Swap(int)、Swap(double)、Swap(char)的开发者都懂 —— 重复的逻辑只因类型不同,而模板正是为解决 “类型无关的通用代码” 而生,是泛型编程的基础。
1. 为什么需要泛型编程?
先看一个问题:如何实现一个支持所有类型的交换函数?
用函数重载的话,会有两个致命问题:
// 1. int版本Swap
void Swap(int& left, int& right) { int temp = left; left = right; right = temp; }
// 2. double版本Swap(重复逻辑,仅类型不同)
void Swap(double& left, double& right) { double temp = left; left = right; right = temp; }
// 3. char版本Swap(新增类型就要加,复用率低)
void Swap(char& left, char& right) { char temp = left; left = right; right = temp; }
- 复用率低:新增类型(如
string)需手动加重载; - 维护性差:一处逻辑修改(如加日志),所有重载都要改。
而模板就像一个 “代码模具”,编译器会根据传入的类型自动生成对应版本的代码,彻底摆脱类型绑定。
2. 函数模板:通用函数的 “模具”
(1)函数模板的概念与格式
函数模板代表一个函数家族,与类型无关,使用时通过实参推演生成具体类型的函数:
// 模板参数列表:typename关键字定义模板参数(也可用class,不能用struct)
template<typename T>
// 通用Swap函数:T是模板参数,代表任意类型
void Swap(T& left, T& right) {T temp = left; left = right; right = temp;
}
(2)函数模板的原理
模板本身不是函数,而是编译器生成函数的 “蓝图”。编译阶段,编译器会根据实参类型推演T的具体类型,生成对应代码:
int main() {int a = 10, b = 20;double c = 1.1, d = 2.2;char e = 'a', f = 'b';Swap(a, b); // 推演T为int,生成void Swap(int&, int&)Swap(c, d); // 推演T为double,生成void Swap(double&, double&)Swap(e, f); // 推演T为char,生成void Swap(char&, char&)return 0;
}
💡 形象理解: 模板就像 “饼干模具”,T是面团材质,编译器根据材质(类型)压出不同口味的饼干(具体函数)。
(3)函数模板的实例化
实例化是 “用具体类型替换模板参数” 的过程,分为隐式实例化和显式实例化:
① 隐式实例化:编译器自动推演类型
template<class T>
T Add(const T& left, const T& right) { return left + right; }int main() {int a1 = 10, a2 = 20;double d1 = 10.1, d2 = 20.2;Add(a1, a2); // 隐式推演T为int,正确Add(d1, d2); // 隐式推演T为double,正确// Add(a1, d1); // 错误:T同时推演为int和double,冲突return 0;
}
解决冲突的两种方式:
- 手动强转:
Add(a1, (int)d1);(将 d1 转为 int,T 推演为 int); - 显式实例化:
Add<int>(a1, d1);(指定 T 为 int,编译器尝试隐式类型转换)。
② 显式实例化:手动指定模板参数
在函数名后加<类型>,直接告诉编译器T的具体类型:
int main() {int a = 10;double b = 20.0;// 显式实例化:指定T为int,b隐式转为intAdd<int>(a, b); return 0;
}
(4)模板参数的匹配原则
当非模板函数与同名函数模板同时存在时,编译器会按以下规则匹配:
- 优先匹配非模板函数:若类型完全匹配,直接调用非模板函数;
- 模板更匹配则选模板:若非模板函数类型不匹配,但模板可生成更匹配的版本,选模板;
- 模板不支持自动类型转换:普通函数支持自动类型转换(如 int→double),模板仅在显式实例化时尝试转换。
// 1. 非模板函数:专门处理int
int Add(int left, int right) { return left + right; }
// 2. 函数模板:通用版本
template<class T>
T Add(T left, T right) { return left + right; }
// 3. 多参数模板:更灵活的通用版本
template<class T1, class T2>
T1 Add(T1 left, T2 right) { return left + right; }void Test() {Add(1, 2); // 匹配非模板函数(类型完全一致)Add<int>(1, 2); // 显式实例化模板,调用模板版本Add(1, 2.0); // 模板更匹配(T1=int,T2=double),调用多参数模板
}
3. 类模板:通用类的 “蓝图”
类模板与函数模板类似,是生成具体类的 “模具”,适用于容器(如栈、队列)等需支持多类型的场景。
(1)类模板的定义格式
template<class T> // 模板参数列表
class Stack {
public:// 构造函数:参数带默认值Stack(size_t capacity = 4) : _array(new T[capacity]), _capacity(capacity), _size(0){}// 成员函数声明(类外定义需加模板参数)void Push(const T& data);private:T* _array; // 通用类型数组size_t _capacity; // 容量size_t _size; // 有效元素个数
};// 类外定义成员函数:需加模板参数列表 + 类名后指定<T>
template<class T>
void Stack<T>::Push(const T& data) {// 扩容逻辑(简化)if (_size == _capacity) {T* tmp = new T[_capacity * 2];memcpy(_array, tmp, sizeof(T) * _size);delete[] _array;_array = tmp;_capacity *= 2;}_array[_size++] = data;
}
(2)类模板的实例化
类模板实例化与函数模板不同 ——必须显式指定模板参数,类模板名不是真正的类,实例化后的结果才是具体类:
int main() {// 错误:类模板不能隐式实例化,必须指定<T>// Stack st1; // 正确:显式实例化int类型的栈Stack<int> st1; st1.Push(1); st1.Push(2);// 正确:显式实例化double类型的栈Stack<double> st2; st2.Push(1.1); st2.Push(2.2);return 0;
}
💡 关键区别:函数模板可通过实参推演类型,类模板无实参可推演,必须手动指定<类型>。
(3)类模板的注意事项
- 声明与定义不分离:类模板的声明和定义建议放在同一文件(如
.h),若分离到.h和.cpp,会因编译器无法推演模板参数导致链接错误; - 每个实例化是独立类:
Stack<int>和Stack<double>是两个完全独立的类,占用内存大小可能不同(取决于 T 的大小)。
三、STL 简介:站在前人肩膀上的工程化库
STL(Standard Template Library)是 C++ 标准库的核心,封装了常用的数据结构(如 vector、map)和算法(如 sort、find),让开发者无需重复造轮子,专注业务逻辑。
1. 什么是 STL?
STL 不仅是 “可复用的组件库”,更是 “数据结构与算法的软件框架”。它基于模板实现,支持泛型编程,能适配任意类型,且跨平台性强。
2. STL 的主流版本
不同编译器采用的 STL 版本不同,核心差异在于可读性、可修改性与兼容性:
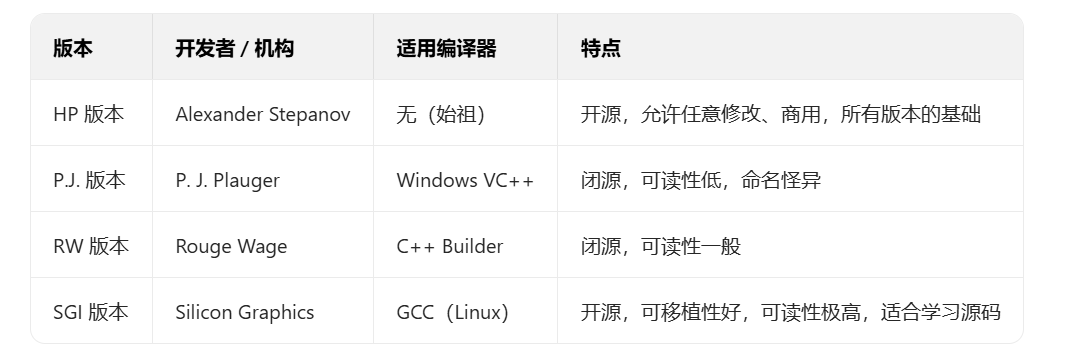
💡 学习建议:若想阅读 STL 源码,优先选择 SGI 版本 —— 命名规范(如_vector)、代码注释清晰,是理解 STL 实现的最佳范本。
3. STL 的六大核心组件
STL 由六大组件构成,组件间相互配合,形成完整的功能体系:

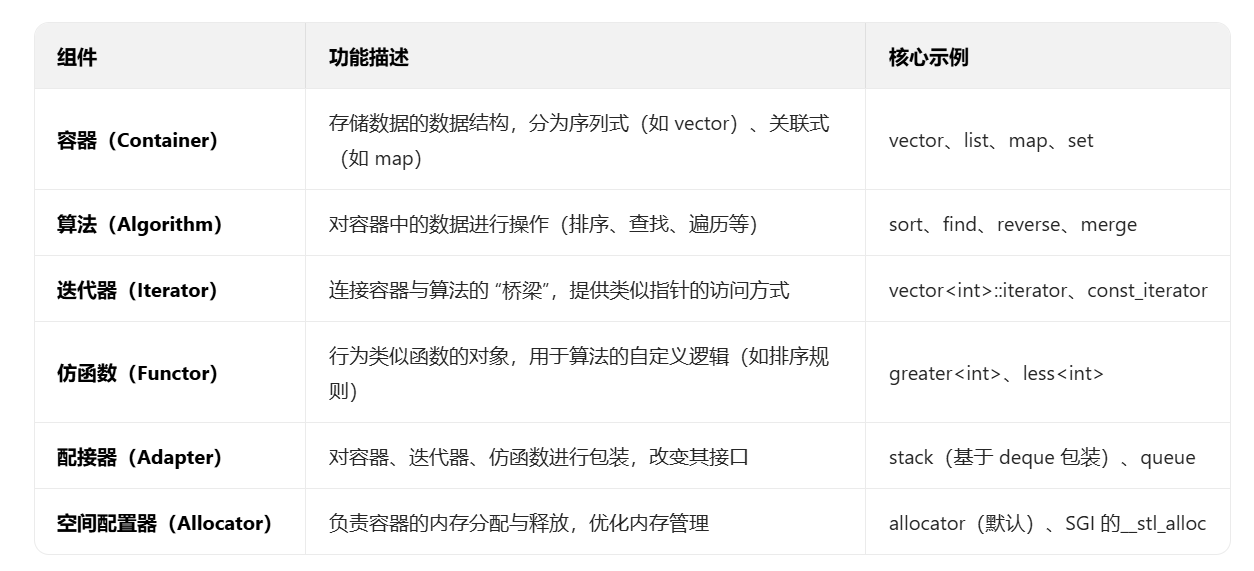
组件配合示例:用 vector+sort+iterator 实现排序
#include <vector> // 容器
#include <algorithm> // 算法
#include <iostream>using namespace std;int main() {// 1. 定义vector容器,存储int类型vector<int> v;v.push_back(3);v.push_back(1);v.push_back(2);// 2. 用迭代器遍历容器(未排序)cout << "排序前:";vector<int>::iterator it = v.begin();while (it != v.end()) {cout << *it << " "; // 输出:3 1 2++it;}cout << endl;// 3. 用sort算法排序(需包含<algorithm>)sort(v.begin(), v.end()); // 默认升序// 4. 遍历排序后的容器cout << "排序后:";for (int val : v) { // C++11范围for,底层也是迭代器cout << val << " "; // 输出:1 2 3}cout << endl;return 0;
}
4. STL 的重要性:笔试、面试、工作全覆盖
(1)笔试中的 STL
笔试算法题常需用 STL 简化代码,比如:
- 用
vector模拟数组,避免手动管理动态内存; - 用
stack实现 “两个栈模拟队列”; - 用
map统计字符出现次数。
(2)面试中的 STL 高频问题
面试官常通过 STL 考察底层理解,比如:
- vector 的
capacity增长机制(VS 下 1.5 倍,Linux 下 2 倍); - map 的底层实现(红黑树)与哈希表的区别;
- STL 迭代器失效的场景(如 vector 扩容后原迭代器失效)。
(3)工作中的 STL
工作中 STL 是效率利器,比如:
- 用
string处理字符串,避免 C 语言char*的越界风险; - 用
list处理频繁插入 / 删除的场景,比 vector 效率更高; - 用
algorithm中的算法快速实现排序、查找等逻辑,减少重复编码。
5. 学习 STL 的三个境界
STL 的学习不是一蹴而就的,可分为三个阶段,逐步深入:
- 第一境界:熟用
掌握常用容器(vector、string、map)和算法(sort、find)的基本用法,能在代码中灵活运用,解决实际问题。 - 第二境界:明理
理解核心容器的底层实现(如 vector 的动态扩容、list 的双向链表结构),知道算法的时间复杂度(如 sort 是快速排序优化版,平均 O (nlogn)),能避开底层陷阱(如迭代器失效)。 - 第三境界:扩展
基于 STL 的设计思想,自定义容器或算法,比如实现支持自定义排序规则的优先级队列,或为 STL 容器添加新的成员函数。
四、思考与总结 ✨

五、自测题与答案解析 🧩
-
判断题:new 申请的空间必须用 delete 释放,new [] 申请的空间必须用 delete [] 释放?
✅ 正确。不匹配释放会导致析构函数调用不完整(自定义类型)或内存泄漏。
-
选择题:下列关于函数模板的说法错误的是( )
A. 函数模板可通过实参推演模板参数类型
B. 函数模板支持显式实例化
C. 函数模板与非模板函数同名时,优先调用非模板函数
D. 函数模板支持自动类型转换(如 int→double)
答案:❌ D。函数模板仅在显式实例化时尝试类型转换,隐式实例化不支持自动转换。 -
简答题:vector 和 list 的核心区别是什么?分别适合什么场景?答案:
- 底层结构:vector 是动态数组(连续内存),list 是双向链表(不连续内存);
- 访问效率:vector 随机访问 O (1),list 随机访问 O (n);
- 插入 / 删除:vector 尾部插入 / 删除 O (1),中间 O (n);list 任意位置 O (1);
- 场景:vector 适合频繁访问、尾部插入的场景(如存储数据列表);list 适合频繁插入 / 删除的场景(如日志记录)。
六、建议阅读顺序
- 《C++ 类与对象 (上):封装与 this 指针深度解析》
- 《C++ 类与对象 (中):默认成员函数与运算符重载实战》
- 《C++ 类与对象 (下):进阶特性与编译器优化》
- 《C++ 内存管理、模板初阶与 STL 简介》(本文)
- 《C++ string 类常用接口实战》(下篇)
- 《C++ string 类模拟实现:从浅拷贝到深拷贝》(下下篇)
七、下篇预告:C++ string 类常用接口实战
搞定 STL 基础后,下一篇聚焦三大核心能力:
- 接口用法:从构造、容量到修改,吃透 string 核心接口逻辑;
- 简化技巧:用 auto 和范围 for 简化遍历,告别冗长代码;
- 实战应用:结合反转字母、验证回文等 OJ 题,掌握接口解题用法。
✨敬请期待,从接口用法到实战解题,帮你高效掌握 string 开发与笔试技巧。
🖋 作者寄语
内存管理是 C++ 的 “根基”,模板是 C++ 的 “灵活之魂”,STL 是 C++ 的 “效率利器”。这三者不是孤立的 —— 模板是 STL 的实现基础,而 STL 的容器又依赖内存管理实现安全的空间分配。掌握这三者,才算真正迈入 C++ 高效编程的大门。
