DeepSeek-OCR:革命性文档识别模型全面解析及实测
DeepSeek-OCR:革命性文档识别模型全面解析
概述
DeepSeek再次引领技术革新!最新发布的OCR模型在文档识别效率上实现重大突破。本文将通过本地部署和客观实测,深入分析这款识别准确率高达97%、支持100+语言、每日可处理3300万页文档的开源大模型。
项目地址: https://github.com/deepseek-ai/DeepSeek-OCR
如果您经常需要处理大量文档,或正在为AI模型的长文本处理能力困扰,那么本文将为您提供重要参考。DeepSeek最新发布的OCR模型,有望彻底改变传统文档处理的工作流程。
一、技术背景与需求分析
OCR(光学字符识别)技术已广泛应用于从纸质文档扫描到图像文字识别的各个场景。然而,传统OCR技术在处理长文档时存在明显瓶颈:效率低下且成本高昂。
设想这样一个场景:需要分析一份100页的研究报告,传统方法需将每个字符转换为数字信号(token),长文档可能产生数万个token。这不仅导致处理速度缓慢,还会显著增加显存占用和计算成本。
DeepSeek团队针对这一痛点提出了创新性解决方案:既然文字本身就存在于图像中,为何不让AI直接“阅读”图像,而非逐字识别呢?
二、核心技术突破
1. 光学上下文压缩:智能“压缩”技术
DeepSeek-OCR的核心创新在于“光学上下文压缩”(Optical Context Compression)技术。该技术将文档视为完整图像,通过视觉方式进行文字信息的压缩和理解。
其技术优势在于:包含大量文字的图像,使用视觉token表示比文本token更加高效。实验数据显示,在10倍压缩率下,模型仍保持97%的识别精度;即使压缩率达到20倍,精度仍可维持在60%左右。
这意味着传统OCR需要数千个token处理的文档,DeepSeek-OCR仅需数百甚至数十个token即可完成。
2. 双核智能架构
DeepEncoder(视觉编码器)
-
参数量: 约380M,作为系统的“视觉感知”组件
-
技术融合:
-
- SAM模型: 专注于局部感知,实现细节精准识别
- CLIP模型: 负责全局理解,把握文档整体布局
-
创新设计: 集成16倍卷积压缩器,将1024×1024图像从4096个区块压缩至256个token,平衡识别精度与计算效率
DeepSeek-3B-MoE(解码器)
- 模型规模: 30亿参数混合专家模型
- 高效推理: 每次处理仅激活约5.7亿参数
- 核心功能: 将压缩后的视觉信息解码为可读文本
3. 多模式分辨率适配
DeepSeek-OCR提供五种处理模式,适应不同应用场景:
| 模式 | 分辨率 | 视觉token数 | 适用场景 |
|---|---|---|---|
| Tiny | 512×512 | 64 | 简单收据、票据 |
| Small | 640×640 | 100 | 常规文本文档 |
| Base | 1024×1024 | 256 | 标准文档处理 |
| Large | 1280×1280 | 400 | 高精度需求 |
| Gundam | 动态调整 | 可变 | 复杂技术文档 |
三、性能表现评估
1. 卓越的处理效率
- Fox基准测试: 在文本token数为视觉token10倍以内时,解码精度达97%
- 实际应用: 单块NVIDIA A100 GPU日处理能力超过20万页文档
2. 高效的资源利用
- OmniDocBench测试: 仅需100个视觉token即可达到GOT-OCR2.0(256token)同等性能
- 对比优势: 相比MinerU 2.0的近7000个token需求,DeepSeek-OCR用不到800个token实现更优表现
3. 广泛的语言支持
全面支持100+种语言,包括英语、中文及各小语种,为多语言文档处理提供完整解决方案。
四、应用场景展望
文档数字化
实现纸质文档和PDF扫描件的快速电子化转换,保持原有排版格式,显著提升历史档案、合同文件等批量处理效率。
智能对话系统优化
创新性地应用于聊天机器人对话历史压缩,模拟人类记忆机制,实现有限算力下的长上下文处理。
训练数据集构建
为AI模型训练提供高效的文本数据提取能力,加速研究进程。
复杂文档解析
超越传统文字识别,支持图表、化学公式、几何图形等复杂内容的解析和结构化输出。
五、快速入门指南
DeepSeek坚持开源策略,模型免费向公众开放。
环境要求
- Python: 3.12.9
- CUDA: 11.8
- PyTorch: 2.6.0
- Transformers: 4.46.3
推荐配置
- GPU: NVIDIA系列(推荐RTX 3080及以上)
- 内存: 16GB及以上
- 存储: 50GB可用空间
快速开始
模型已经托管在Hugging Face平台上,你可以用几行代码就开始使用:
from transformers import AutoModel, AutoTokenizer
import torchmodel_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
model = model.eval().cuda().to(torch.bfloat16)# 对于文档,使用这个提示词
prompt = "<image>\n<|grounding|>Convert the document to markdown."
# 对于一般图片
# prompt = "<image>\n<|grounding|>OCR this image."res = model.infer(tokenizer, prompt=prompt, image_file='your_image.jpg')
github上运行示例是运行在linux下面,在windows下可以运行在WSL的Ubuntu子系统下。50系显卡配置环境有点麻烦。具体部署可以参数如下视频:https://www.bilibili.com/video/BV1SPWozJEos/
这里制作了一个在windows下的一键运行包,可以直接下载运行,在5090下也是兼容的。
下载windows一键运行包:https://pan.baidu.com/s/1-NBfc3muw2nfCu6NAv8ITg?pwd=i6ys
多种提示词支持
DeepSeek-OCR支持多种场景的提示词:
- 文档转Markdown:
<image>\n<|grounding|>Convert the document to markdown. - 通用OCR:
<image>\n<|grounding|>OCR this image. - 无布局提取:
<image>\nFree OCR. - 图表解析:
<image>\nParse the figure. - 图像描述:
<image>\nDescribe this image in detail. - 文本定位:
<image>\nLocate <|ref|>特定文字<|/ref|> in the image.
六、背后的故事
DeepSeek-OCR的发布其实也反映了当前AI行业的一些趋势。
今年,DeepSeek的旗舰模型R2因为硬件挑战(主要与中美科技竞争有关)而被无限期推迟。但这并没有阻止DeepSeek继续创新的步伐。发布DeepSeek-OCR,某种程度上也是一种战略调整——通过专注于高效、实用的开源工具,继续保持技术领先和社区影响力。
值得一提的是,DeepSeek一贯秉持的理念就是提高AI效率,降低使用成本。从去年底发布的V3模型,到今年2月的R1模型,再到现在的OCR模型,这条主线一直没有改变。在全球AI竞赛愈演愈烈的背景下,这种务实的路线显得尤为可贵。
七、实际测试结果
1、简单票据测试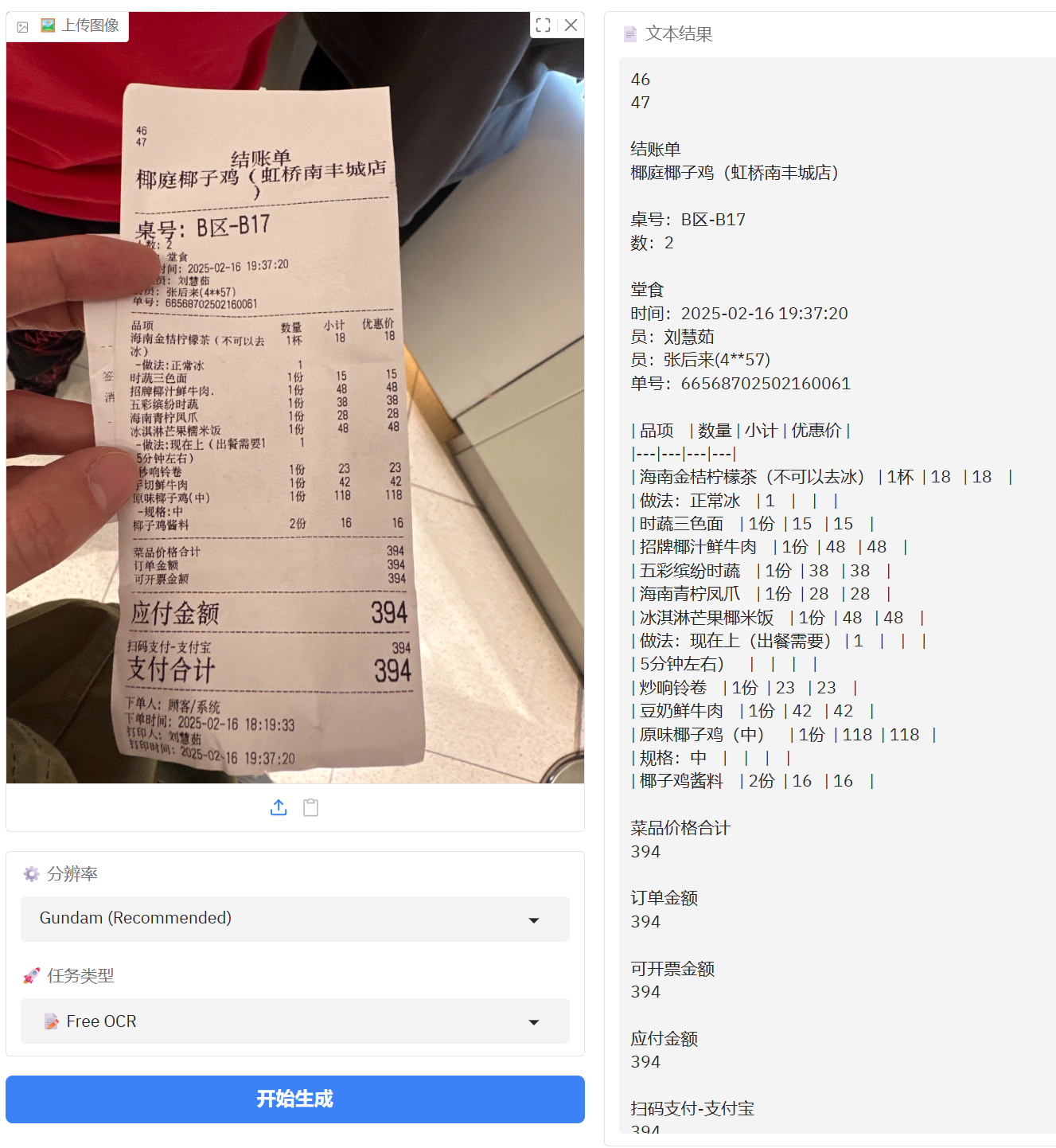
普通小票测试没有问题,完全可以识别。
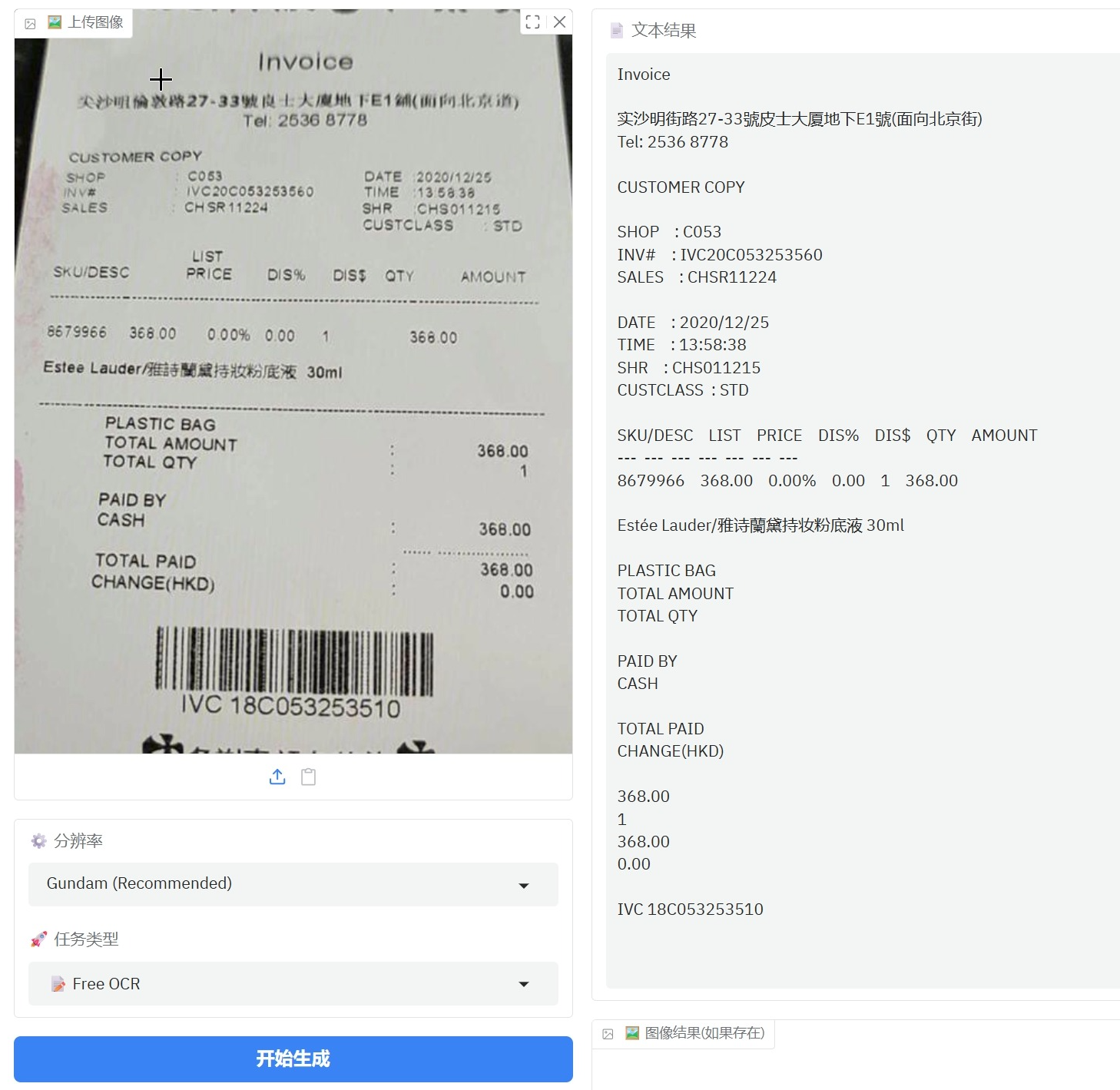
这是一张稍微有点模糊的票据,有个别中文字识别有误
“尖沙咀倫敦路27-33號良士大厦地下E1舖(面向北京道)”识别为 “ 实沙明街路27-33號皮士大厦地下E1號(面向北京街)”其中 尖、咀、倫、敦、良、舖、道 7个字识别错误。
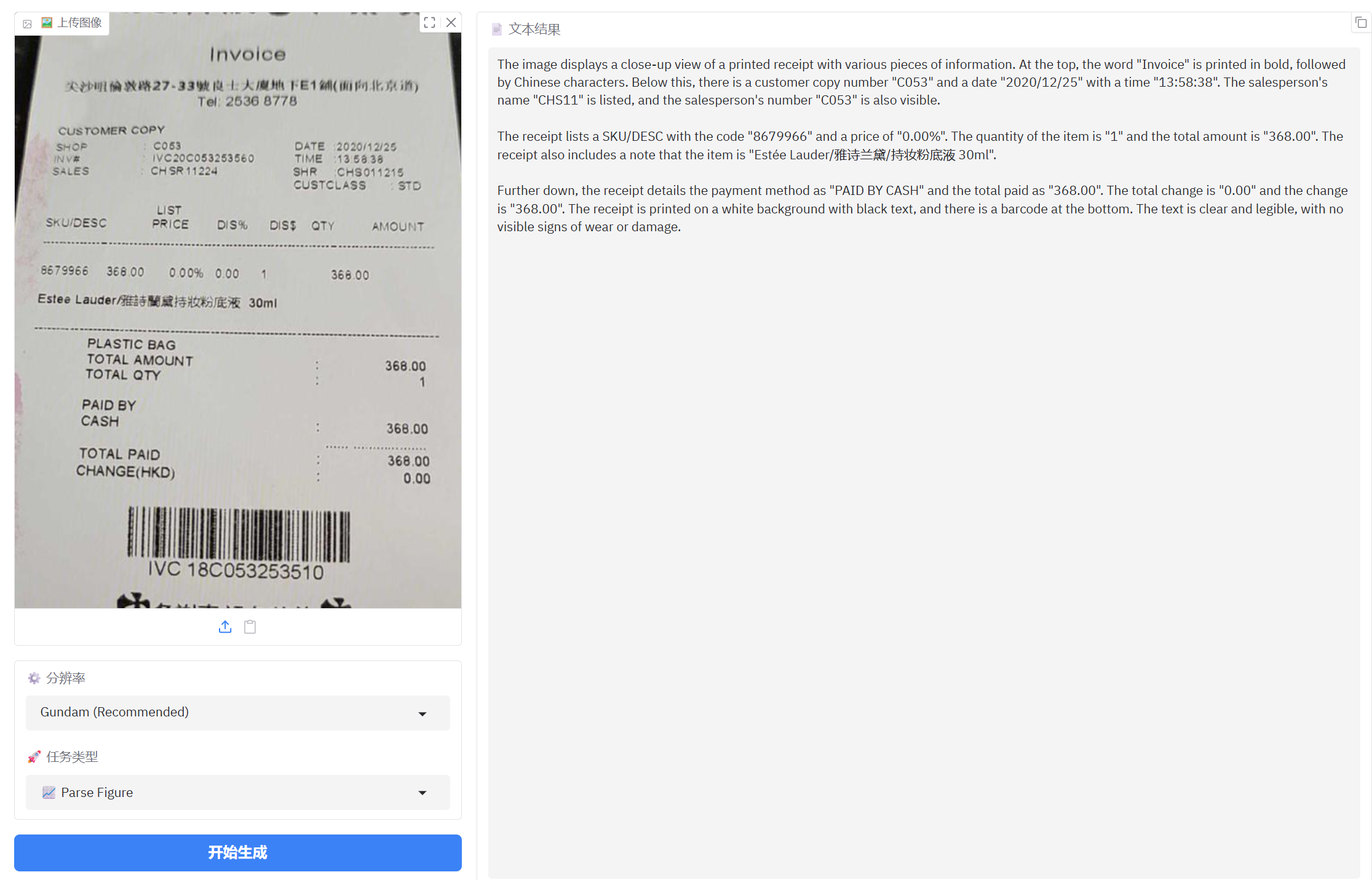
图片解析基本上没有问题
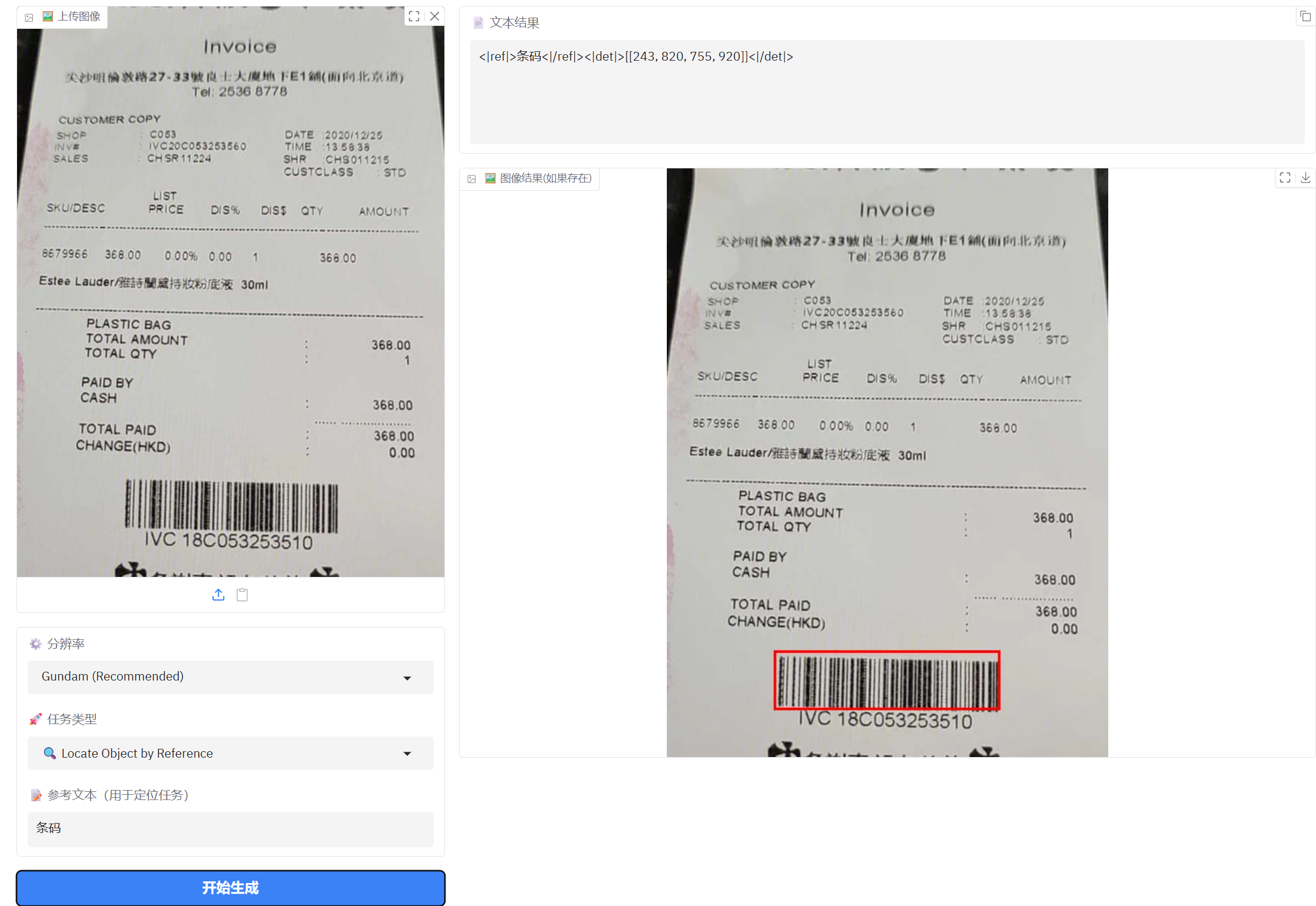
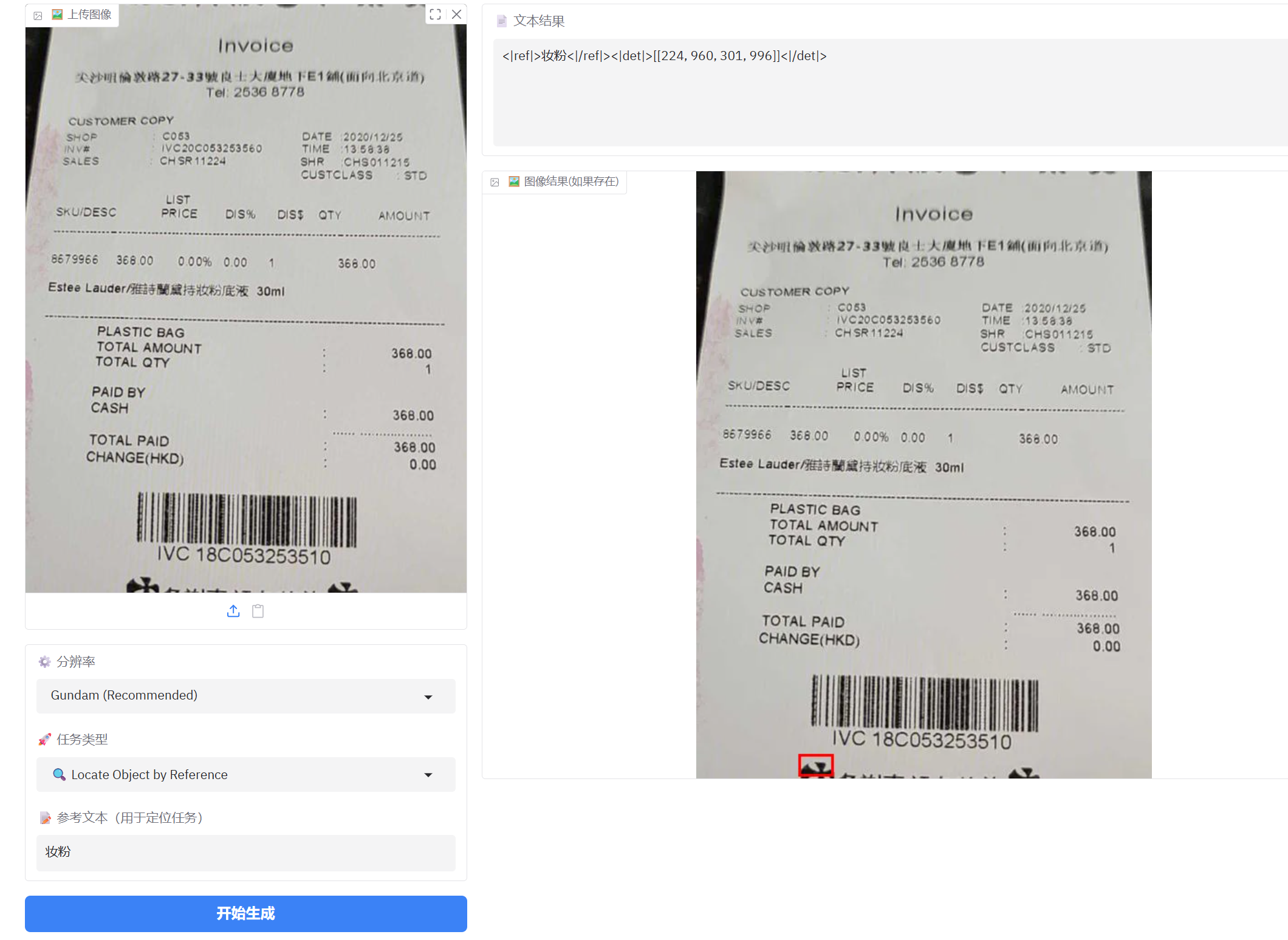
参考文本定位还是有点问题,但是对大的对象定位还可以。
2、手写文本图表文档

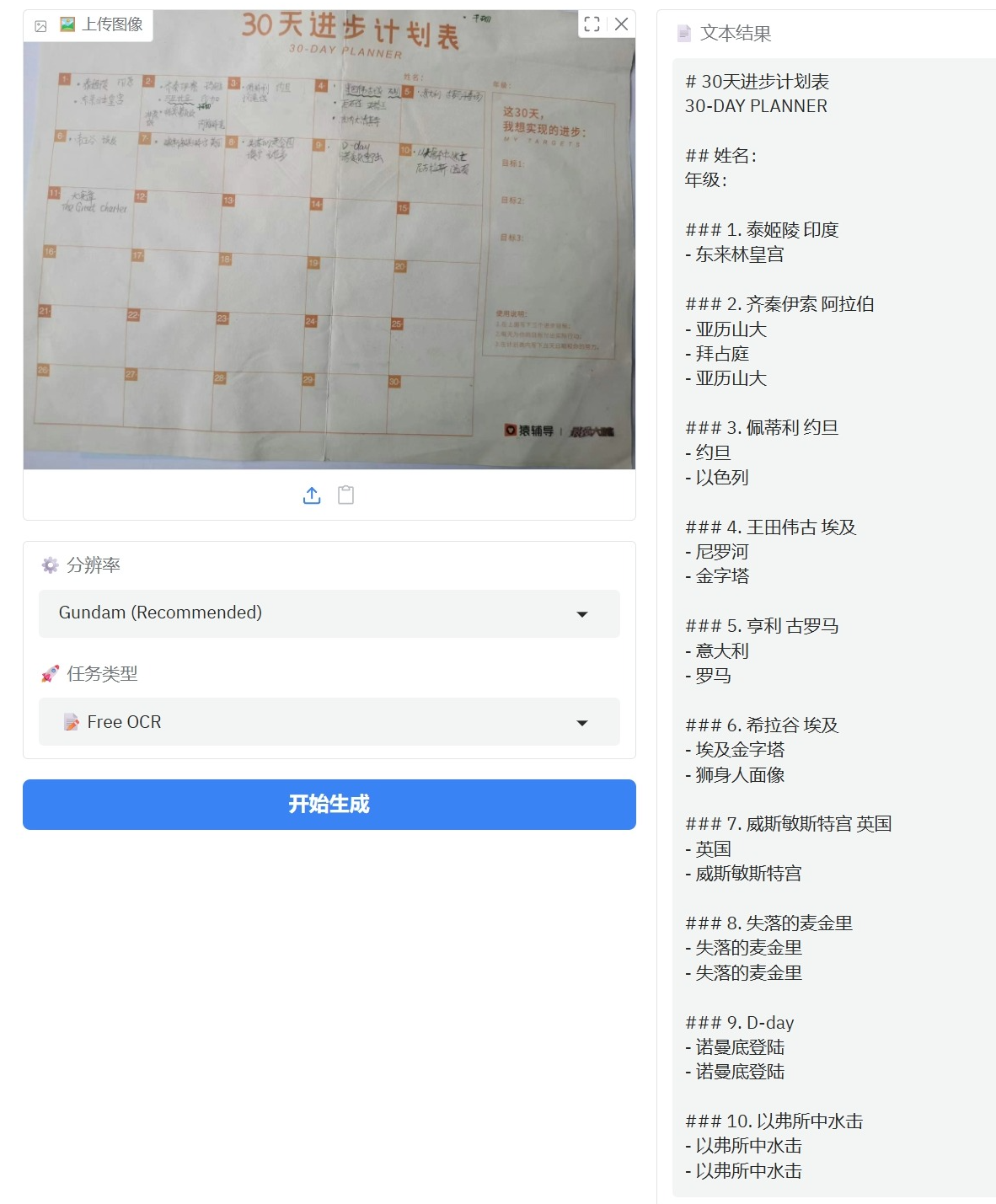
手写体字识别错误还是比较多的,不是太理想,还自己联想了一些不存在的文字(亚力山大,拜占庭等)。但是对图表能按日期顺序都列出来还是可以的。
3、手绘思维导图识别
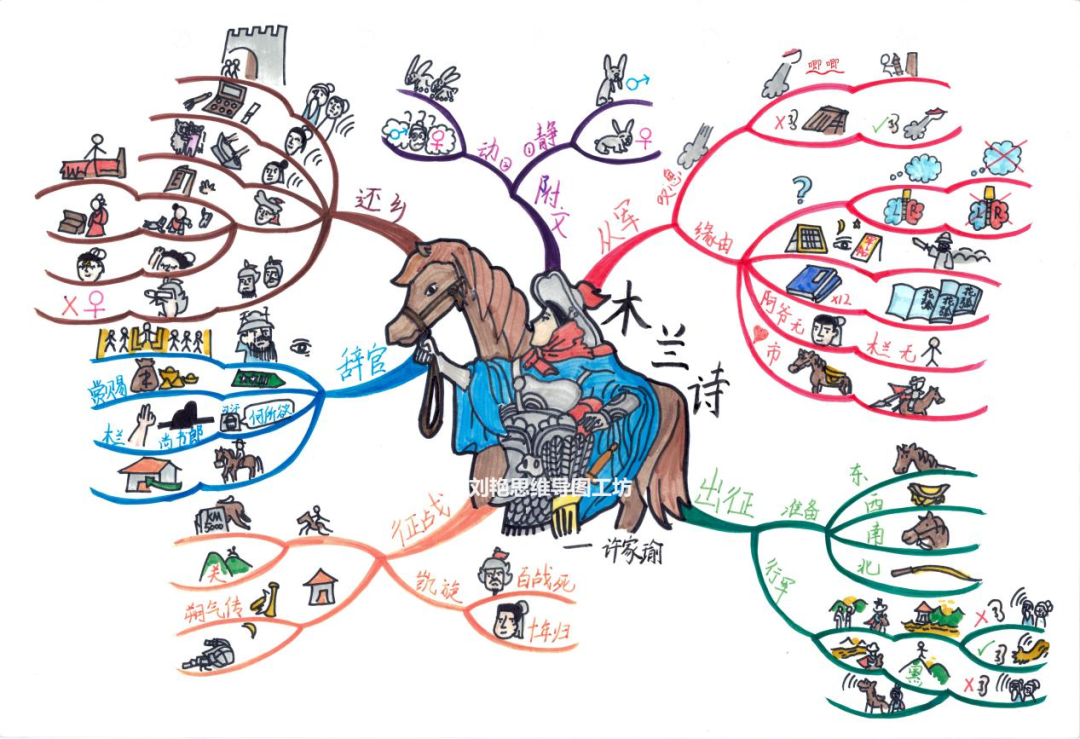
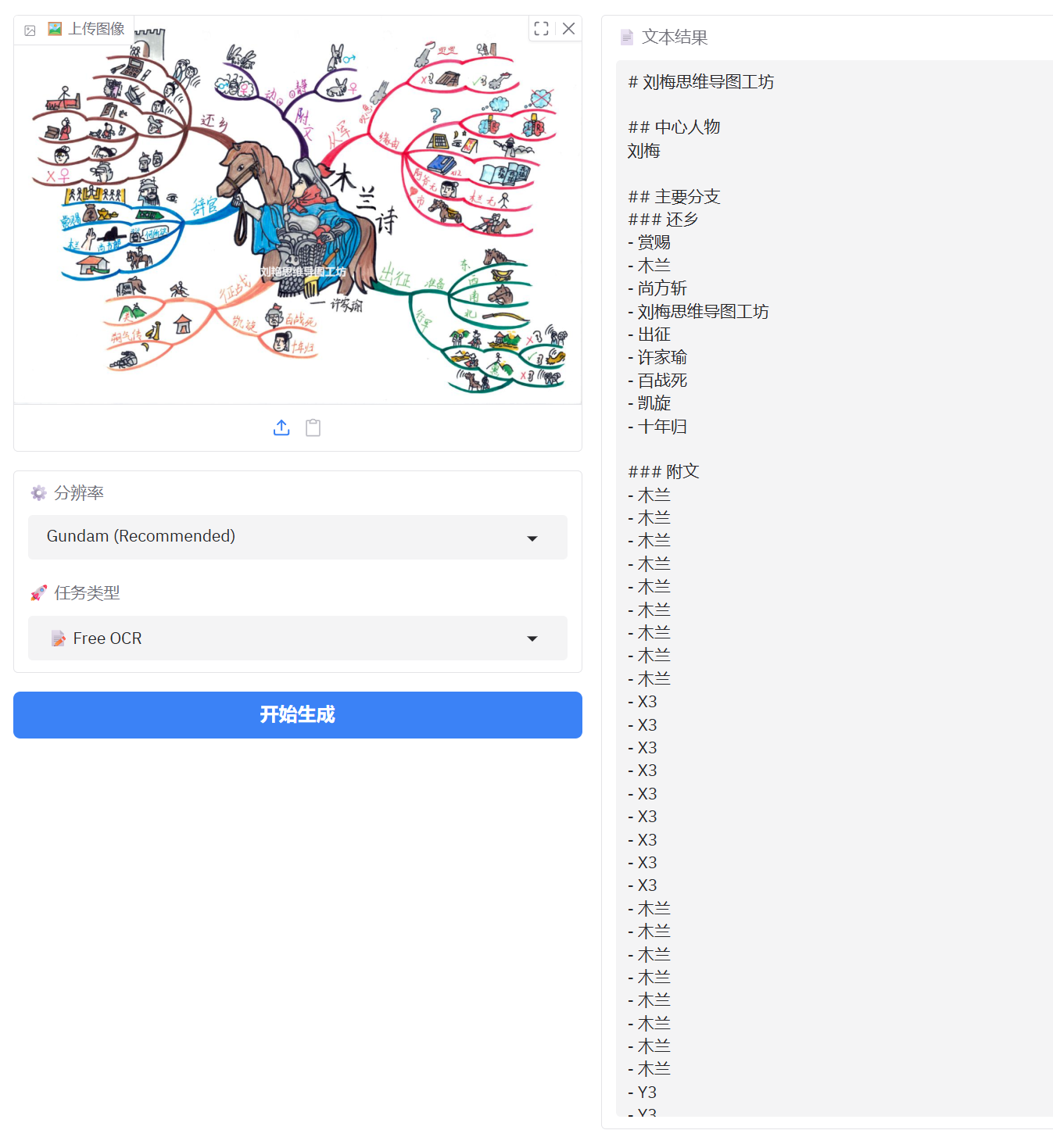
从识别表现上看不太适合手绘思维导图文字的识别
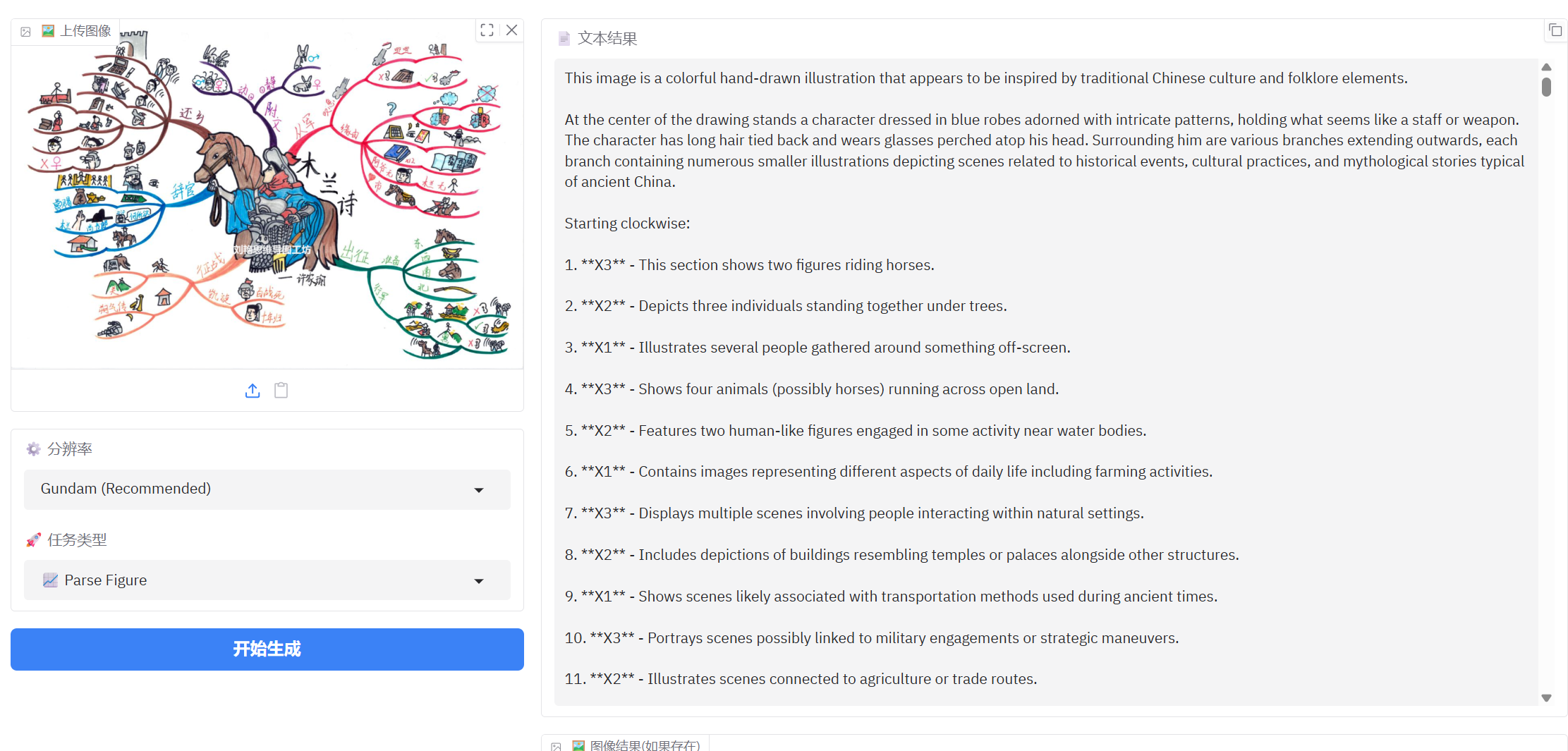
解析图表现也一般,可能因为是手绘图粗略表达意思的原因
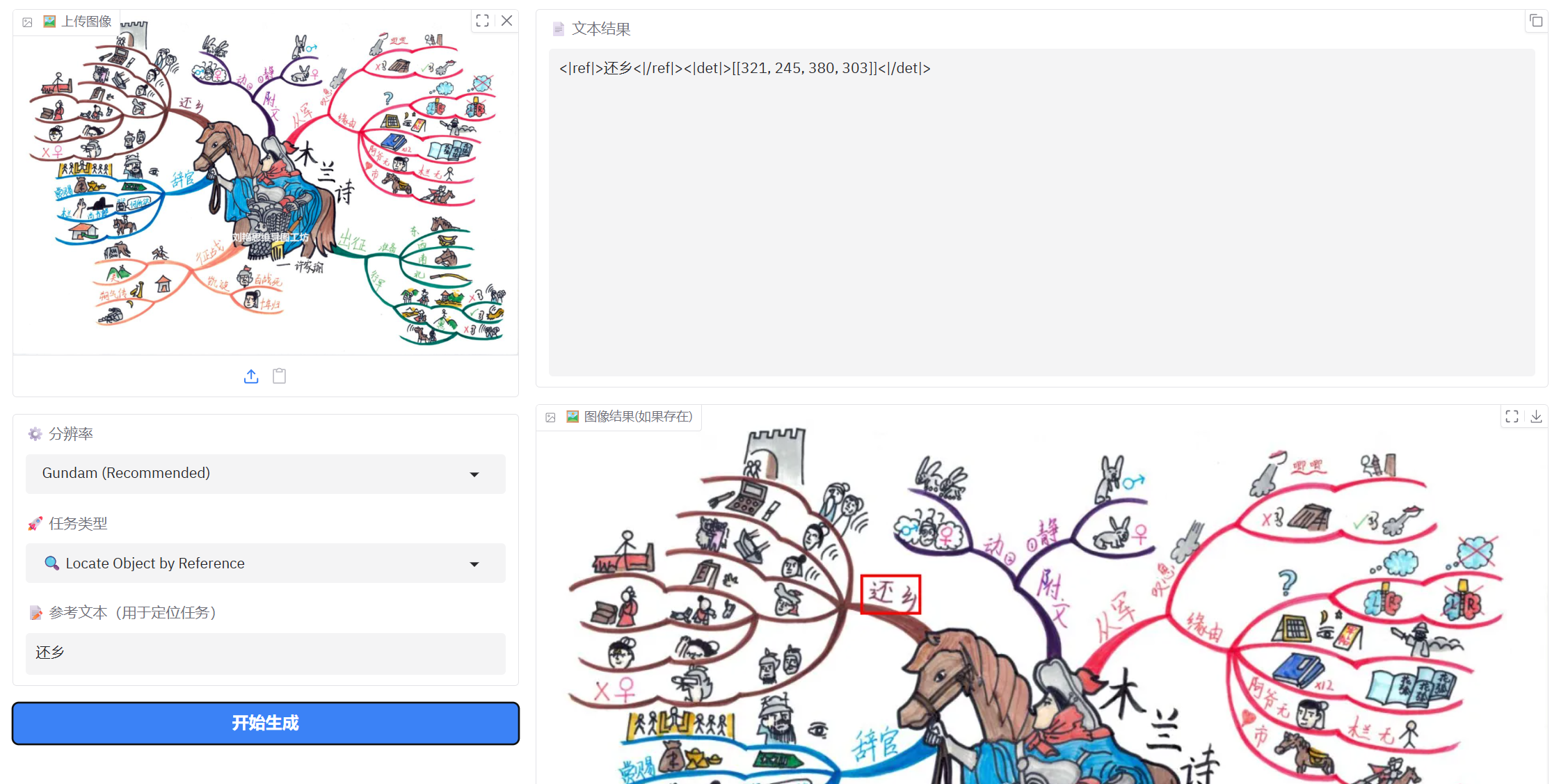
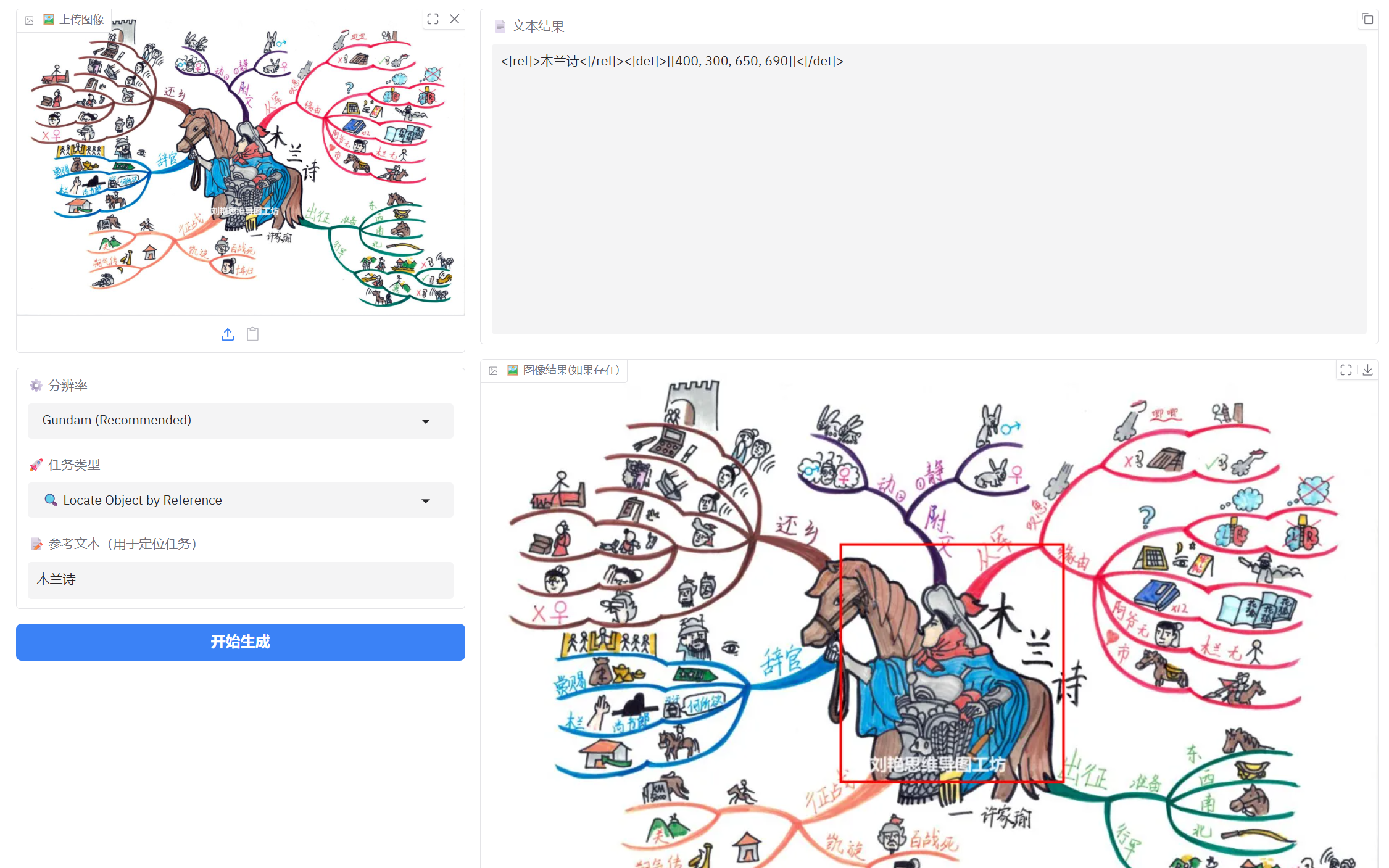
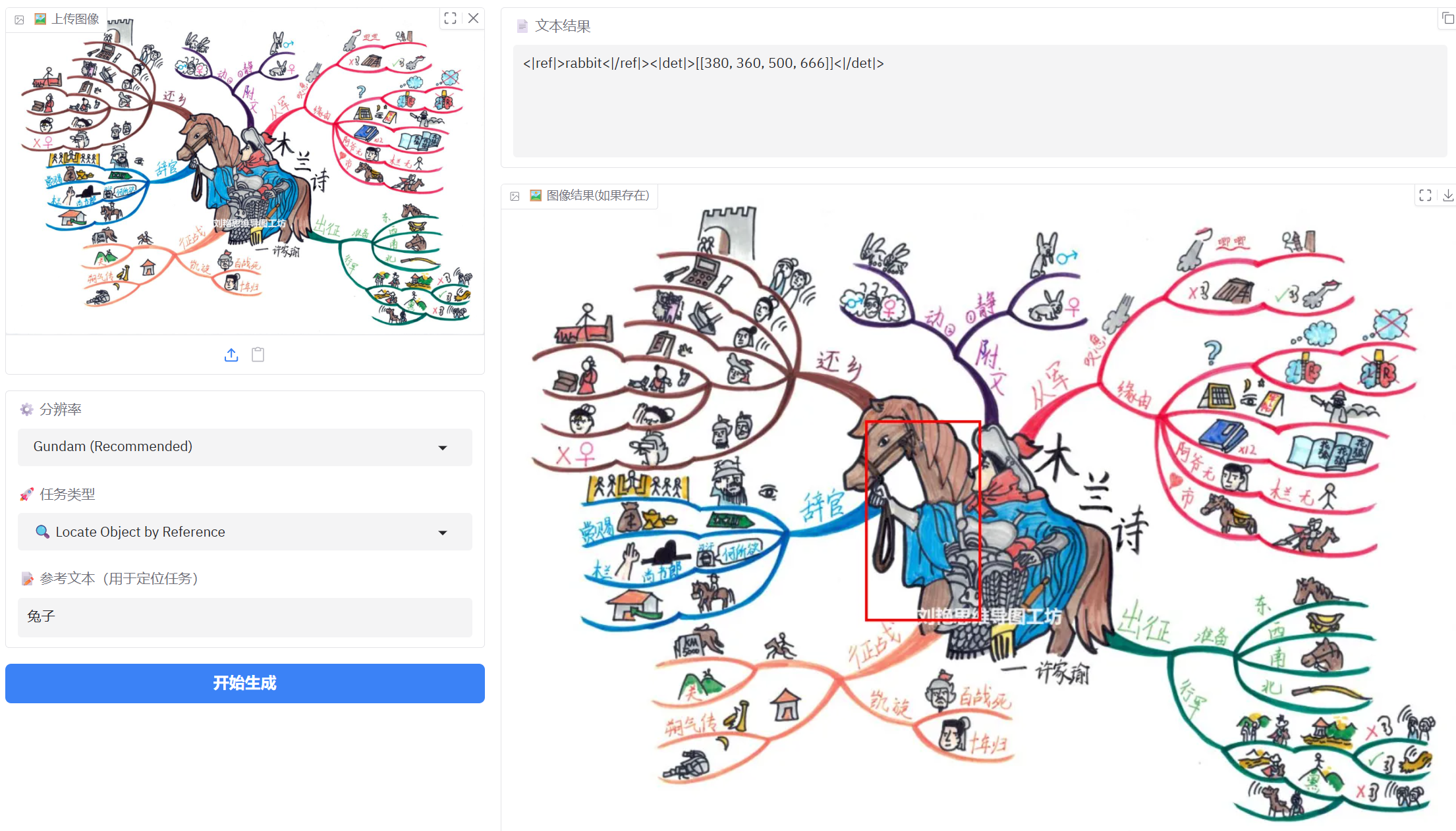
参考文本定位表现还不错,但是对简单图片识别还是不太理想,可能像素太小的原因。
4、图表识别
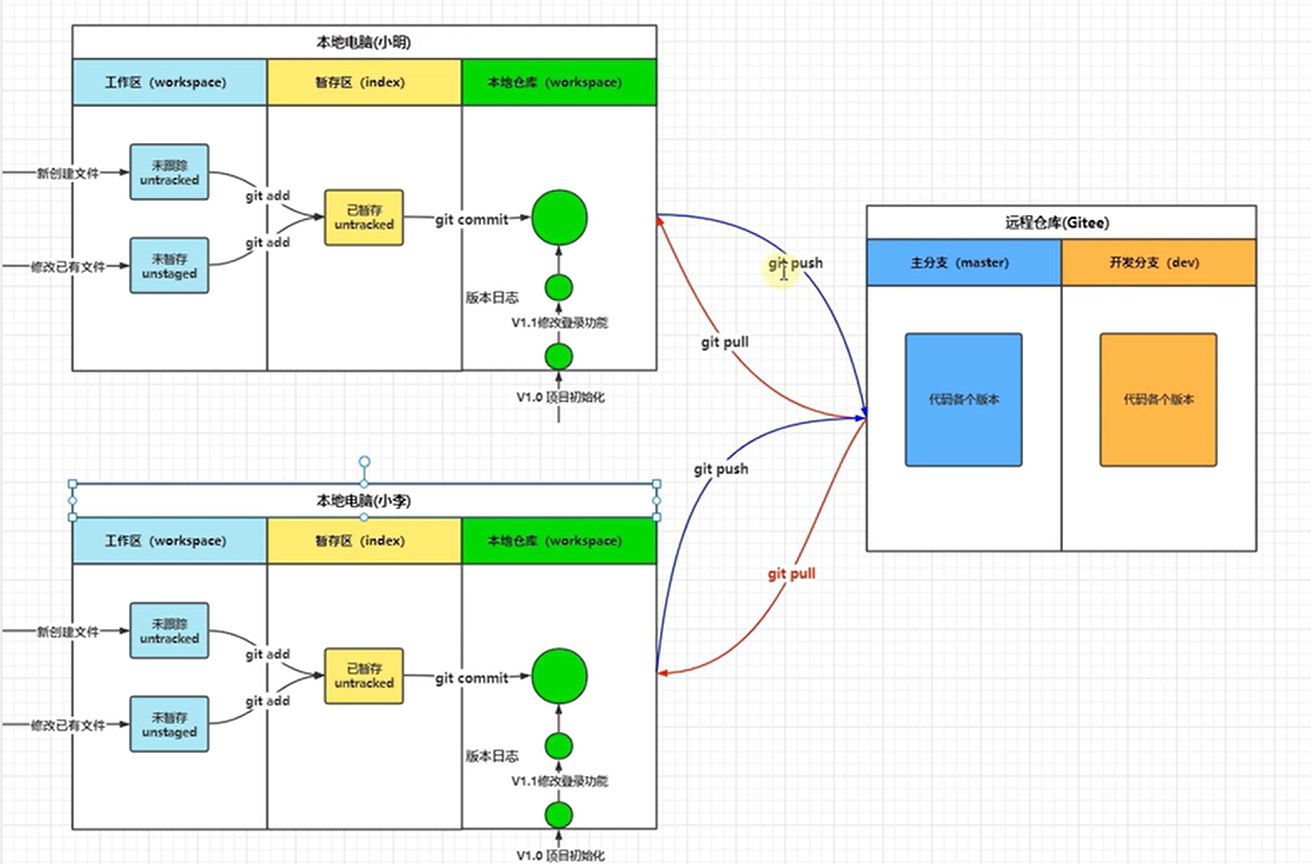
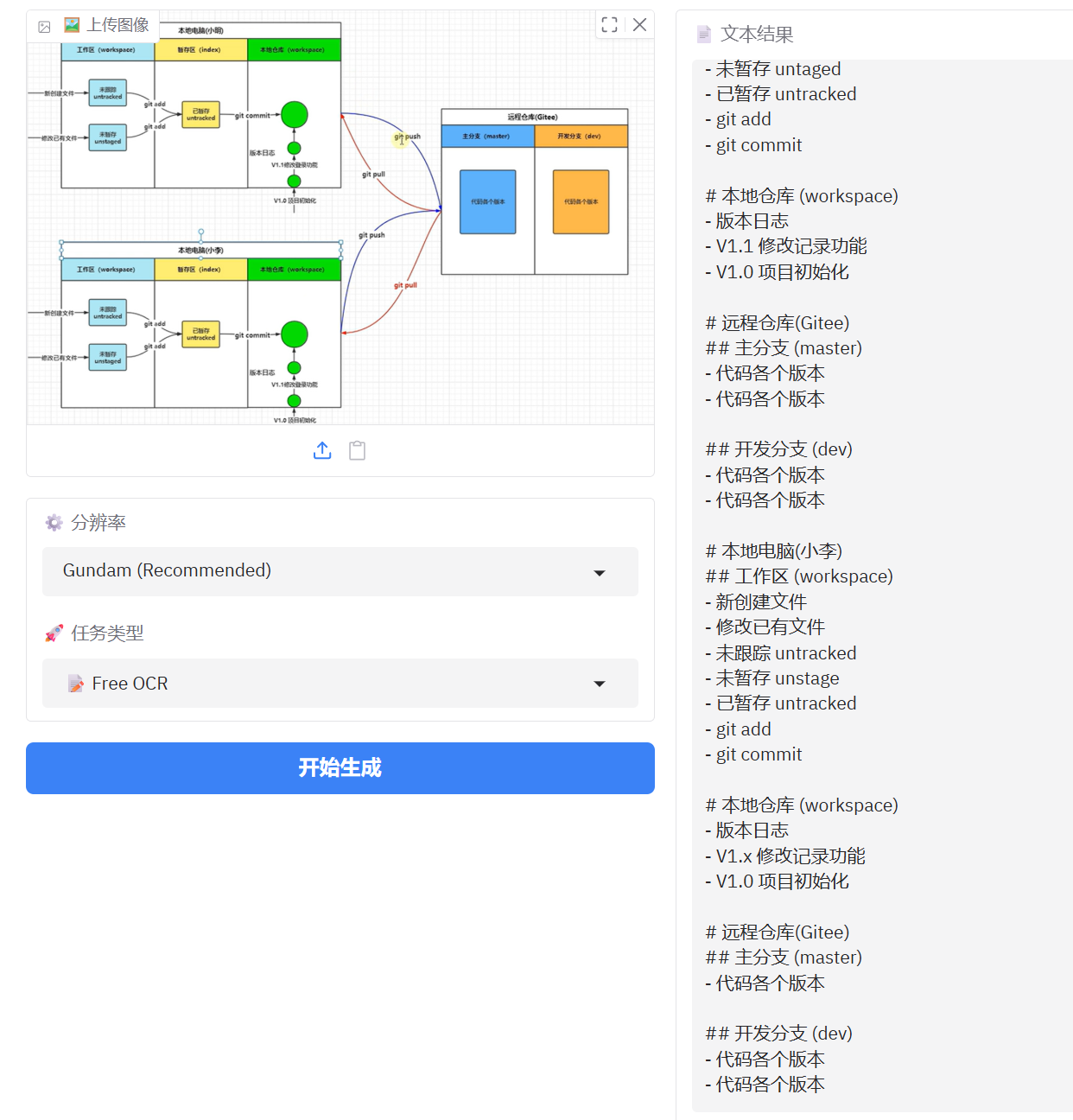
正常的图表识别基本没有问题
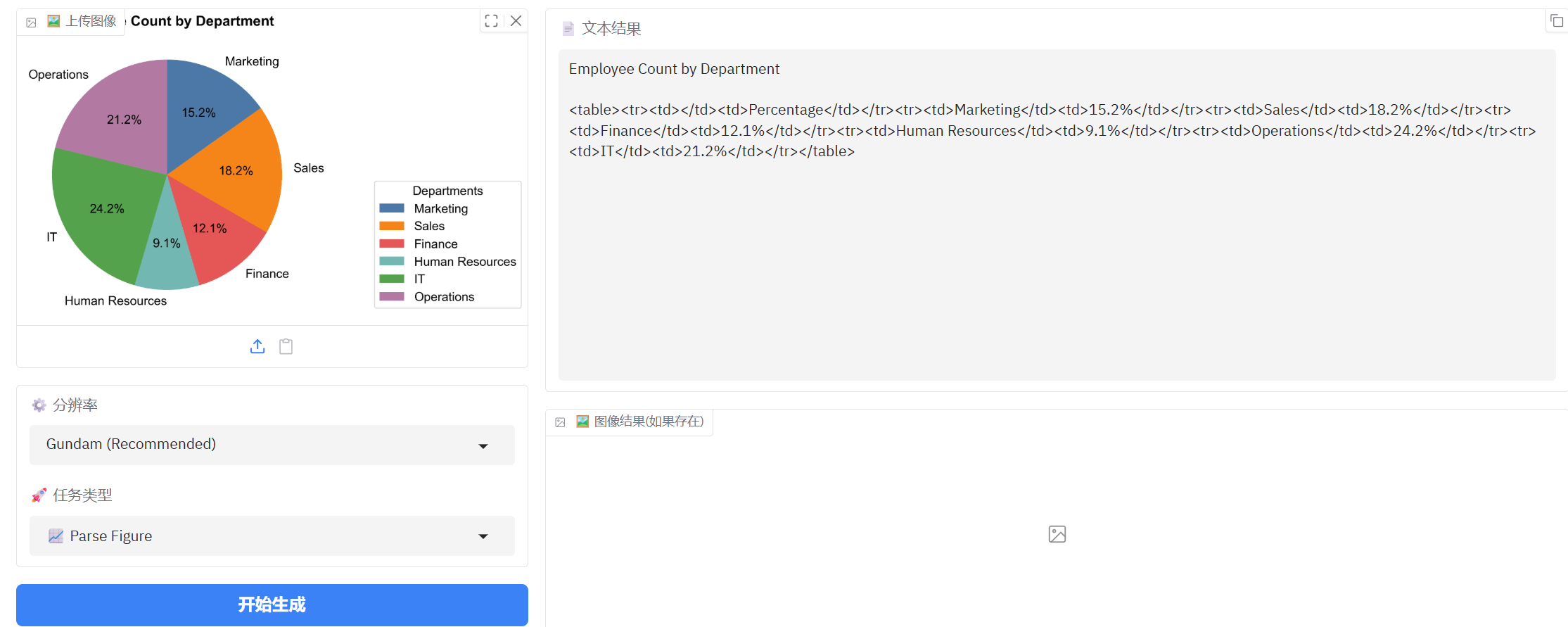
图表识别占比,最后两个比例反了,总体表现很好。
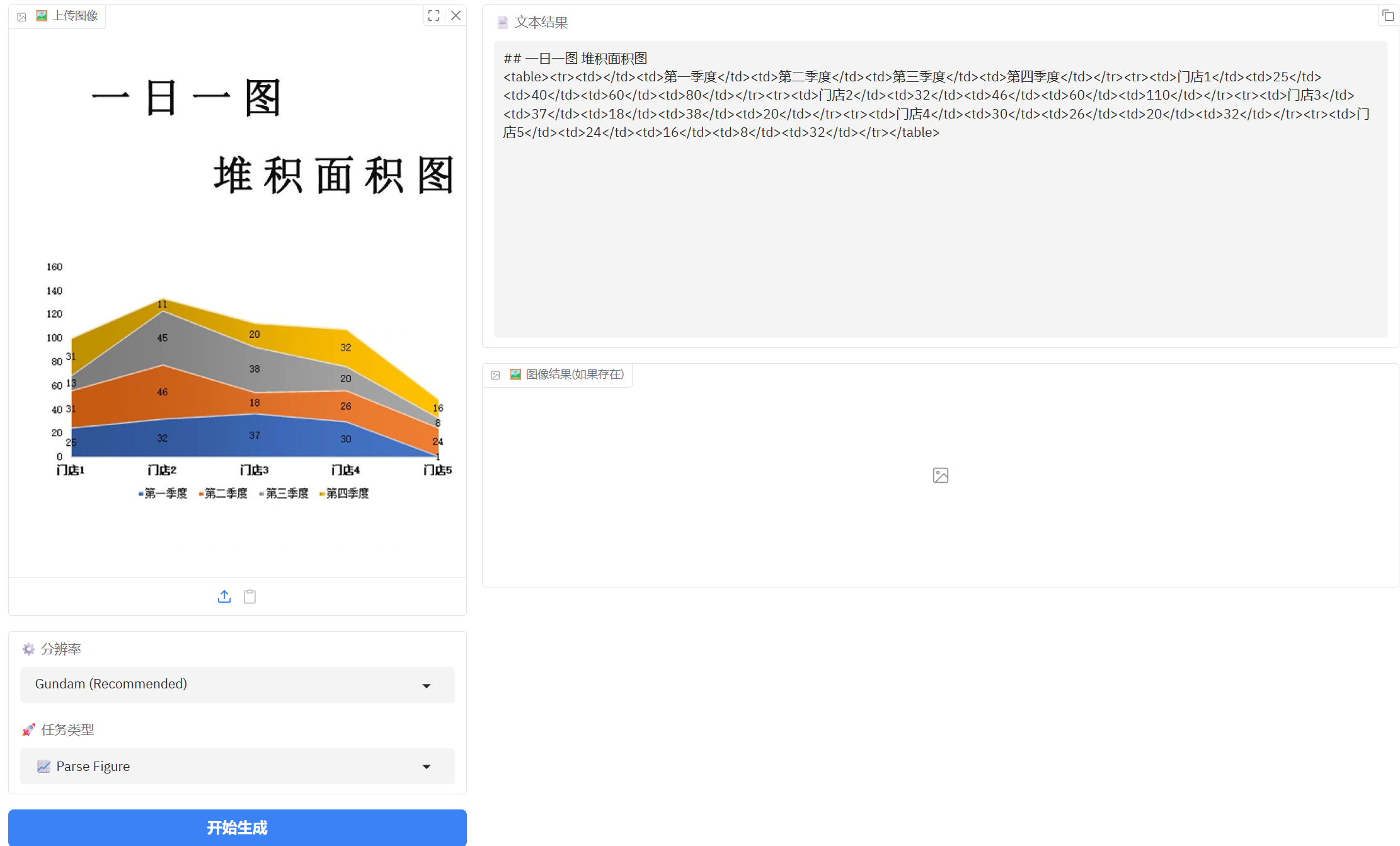
这张图表识别表现更差一点
5、文档转化为Markdown
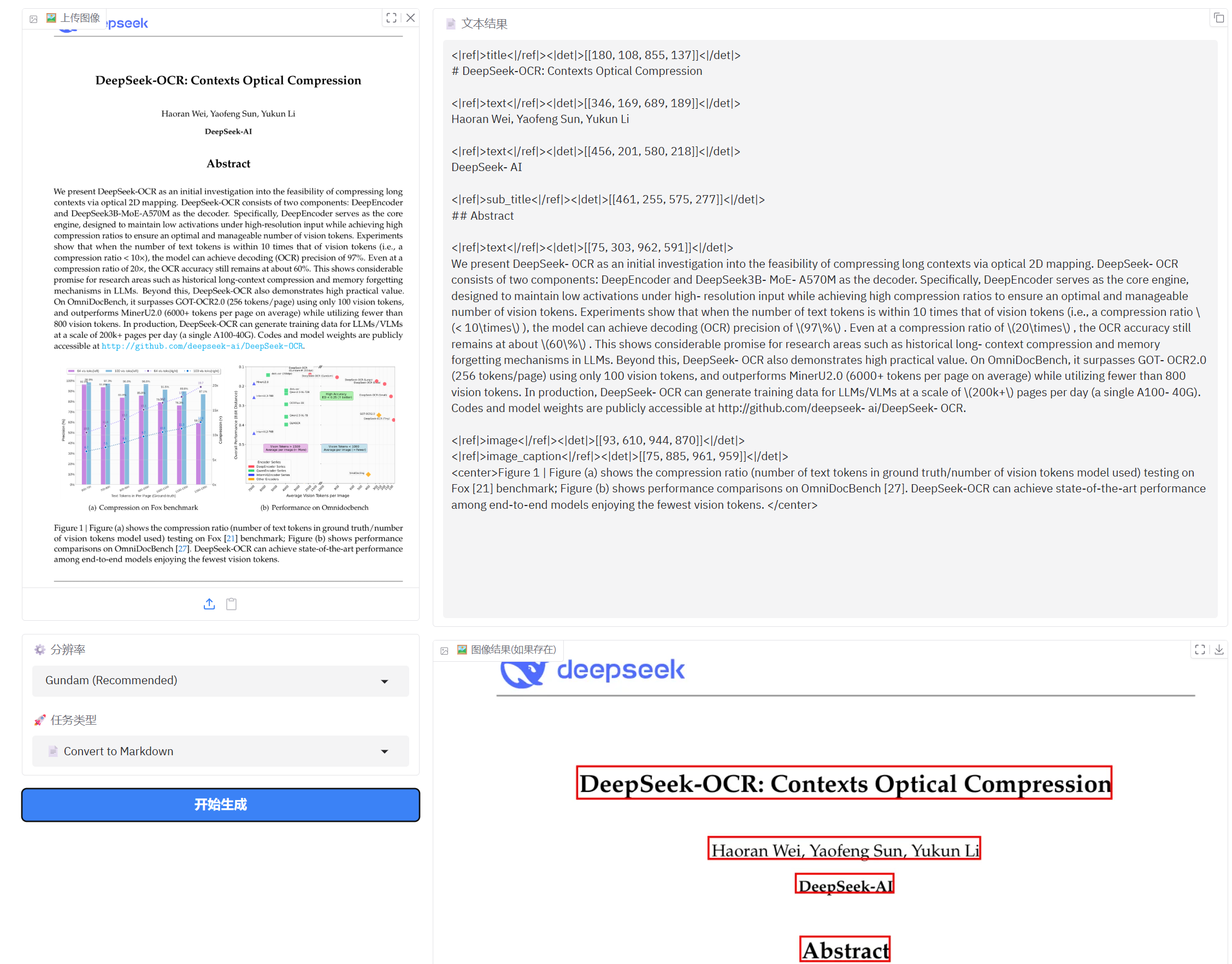
正常文档转化markdown结果还比较理想,只是漏掉了最上面的logo
总结: DeepSeek-OCR通过创新的光学上下文压缩技术和智能架构设计,在文档识别领域实现了突破性进展,为各行业的文档处理需求提供了高效、精准的解决方案。
本文基于实际测试数据撰写,仅供参考使用。