腾讯优图开源Youtu-Embedding通用文本表示模型,用处在哪?
目录
前言
一、AI语义模型的“偏科”困境:“ sprinter”无法跑马拉松
二、破局者Youtu-Embedding:一个“十项全能”的诞生
三、揭秘“炼成术”:如何培养一个AI通才?
3.1 第一步:通读3万亿Token,打下坚实的语言“底子”
3.2 第二步:搭建语义桥梁,从“语言模型”到“理解模型”
3.3 第三步:创新的“协同-判别式”微调,让多任务和谐共舞
四、不止于一个模型:开源框架的深远价值
结语

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 腾讯优图开源Youtu-Embedding
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在今天,我们与AI的交互越来越频繁,从智能客服到搜索引擎,再到内容推荐,背后都离不开一项核心技术——文本嵌入(Embedding)。这项技术的核心任务,是把人类的语言,转换成计算机能够理解和比较的“数字密码”,也就是向量。
理论上,有了这项技术,机器就能像人一样“理解”语言。你搜索“车辆保障”,系统应该能为你找到关于“汽车保险”的文档,即便这两个词在字面上完全不同。然而,现实却常常骨感。很多人都有过类似的体验:公司的智能知识库,面对稍微换了种问法的问题就“装傻”;电商平台的推荐系统,总是推送一些似是而非的商品。

问题出在哪里?难道是AI还不够聪明吗?在很多情况下,问题并非出在AI的“智商”,而是出在它的“偏科”。
一、AI语义模型的“偏科”困境:“ sprinter”无法跑马拉松
在文本Embedding领域,长期存在一个被称为“负迁移”(Negative Transfer)的魔咒。你可以把它理解为模型在学习过程中的“偏科”现象。
一个模型,如果它的训练目标是信息检索(IR),那么它的核心任务就是从海量文档中,快速找出与查询问题“相关”的内容。在这种模式下,模型就像一个 sprinter,追求的是速度和“相关/不相关”这种黑白分明的判断力。它需要学会抓住关键词和核心主题。
而另一个常见的任务是语义相似度(STS),它的目标是精准判断两句话在意思上的细微差别。比如,“今天天气不错”和“今天阳光明媚”,它们的意思非常接近;而“我想买苹果”和“苹果公司股价上涨”,虽然都包含“苹果”,但意思天差地别。要做好这个任务,模型必须成为一个精于细节的“鉴赏家”,能够捕捉语言的细微差异。
“负迁移”的魔咒就在于,当一个模型被训练成顶尖的 sprinter(信息检索)后,你再让它去跑马拉松(语义相似度判断),它往往会表现得很糟糕,反之亦然。为了追求极致的单项能力,模型会丢失处理其他任务的通用性。
这对企业和开发者来说,是一个非常头疼的问题。这意味着,如果你的应用既需要强大的搜索功能,又需要精准的意图理解,你可能需要维护两套甚至多套不同的AI模型,分别应对不同的场景。这不仅导致开发和维护成本飙升,也让系统的复杂度大为增加。
大家都在问:有没有可能,我们能培养出一个既能冲刺,又能跑马拉松的“十项全能”选手?
二、破局者Youtu-Embedding:一个“十项全能”的诞生
为了打破这个僵局,腾讯优图实验室给出了他们的答案——Youtu-Embedding。
这款模型在发布后不久,就以77.46分的高分成功登顶了权威的中文语义评测基准CMTEB。登顶榜单固然亮眼,但其背后更重要的意义在于,这个分数是在覆盖了检索、分类、相似度、聚类等多个不同任务后取得的综合成绩。
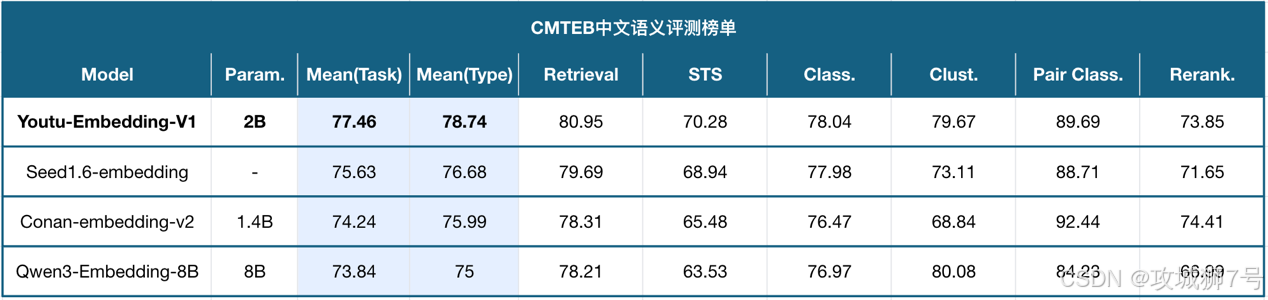
这证明了Youtu-Embedding并非一个“偏科生”,而是一个真正意义上的“通才”。它成功地破解了“负迁移”的魔咒,实现了一个模型能够同时胜任多种主流语义任务。
那么,这个“十项全能”选手,究竟是如何炼成的?答案在于其独特且精密的“三步走”训练策略。
三、揭秘“炼成术”:如何培养一个AI通才?
Youtu-Embedding的成功,并非简单地在某个开源模型上进行微调,而是源于一套从零开始、系统化的培养体系。
3.1 第一步:通读3万亿Token,打下坚实的语言“底子”
任何强大的理解力,都源于广博的知识。Youtu-Embedding的训练起点,是高达3万亿Token的中英文语料。这相当于让模型“通读”了一个巨大的数字图书馆,从海量文本中学习语言的结构、语法和基本常识。
更重要的是,它的“教材”并非随意挑选,而是经过精心准备的“数据燃料”,其中不仅包含了真实世界中常见的中文表达,还利用大模型辅助生成了大量高质量、贴近业务场景的合成样本。这确保了模型从一开始,就拥有一个扎实且贴近现实的语言基本盘。
3.2 第二步:搭建语义桥梁,从“语言模型”到“理解模型”
语言模型天生擅长的是“生成”,就像一个熟读唐诗三百首的学生,让他“床前明月光”后面接“疑是地上霜”很容易。但要让他判断“这句诗表达了什么样的思乡之情”,就需要更高阶的“理解”和“判断”能力。
为此,Youtu-Embedding引入了大规模的弱监督训练。通过海量的“问题-答案”数据对,让模型学习去识别那些“表达不同但意图一致”的句子。
例如,用户问“这款产品的保修期是多久?”和“如果坏了,能免费修理吗?”。这两句话从字面构成上看差异很大,但它们的核心意图高度一致。通过这类训练,模型开始在它的高维向量空间中,为这些意图相近的句子建立起一座“语义桥梁”,让它们的“数字密码”在空间中的位置彼此靠近。
经过这一步,模型完成了从“语言建模者”到“语义理解者”的关键转变。
3.3 第三步:创新的“协同-判别式”微调,让多任务和谐共舞
这是整个训练流程中最具创新性、也是解决“偏科”问题的核心所在。
面对检索、分类、相似度判断等不同任务,如果只是简单地把所有数据都丢给模型去学,结果很可能是模型“精神错乱”,各项能力互相干扰。为此,Youtu-Embedding设计了一套创新的“协同-判别式”微调框架,就像一位高明的课程设计师,为模型安排了一套科学的“课程表”和“评分标准”。
(1)统一格式,消除沟通障碍:不同任务的数据结构(比如相似度判断是句子对,检索是问题-文档对)往往不同。该框架首先通过统一的建模方式,将所有任务的数据转换成一种标准格式。这就像给来自不同国家的学生统一发放“标准答题卡”,让模型不必在理解不同任务格式上耗费精力。
(2)差异化训练,因材施教:框架为每一类任务都定制了专属的“评分标准”(即损失函数)。
* 对于检索任务,评分标准比较粗略,只需要判断文档与问题是“相关”还是“不相关”。
* 而对于语义相似度任务,评分标准则精细得多,需要模型能区分出“高度相似”、“有点相似”和“完全无关”等不同层次。
* 通过这种差异化的“评分标准”,模型清楚地知道在处理每项任务时,应该朝哪个方向努力,从而实现精准优化。
(3)动态采样,劳逸结合:在训练过程中,框架引入了动态采样机制,就像一张“智能课程表”。它不会让模型同时学习所有任务,而是有计划地进行轮训——今天重点练习“检索”,明天专攻“语义相似度”。这种方式确保了模型在每个任务上都能投入足够的精力,学得扎实,既避免了顾此失彼,也防止了因某个任务的训练数据过多而导致的“偏科”。
正是通过这套精妙的组合拳,Youtu-Embedding才得以在各项任务上都取得优异表现,最终成为一个强大的语义“通才”。
四、不止于一个模型:开源框架的深远价值
Youtu-Embedding的发布,对于广大开发者和企业而言,最大的价值并不仅仅是多了一个好用的模型。更重要的是,腾讯优图实验室开源了其完整的训练框架。
这意味着,开发者不仅可以直接使用这个性能顶尖的通用模型来快速构建自己的RAG系统、智能客服或推荐引擎,还可以基于这个框架,结合自身业务的私有数据进行再训练,打造出更贴合自己特定场景、同时又具备强大通用性的专属Embedding模型。
它极大地降低了企业构建高质量语义理解能力的门槛。过去,只有少数拥有顶尖AI团队的公司才能攻克“负迁移”这样的难题,而现在,这套经过验证的、先进的训练方法论被开放给了整个社区。
结语
从无法理解语义的关键词搜索,到能够精准捕捉意图的智能检索,Youtu-Embedding的出现,解决的是一个基础但至关重要的问题。它证明了“通用性”与“专业性”并非不可调和的矛盾。
通过系统性的训练设计和框架创新,AI模型可以成长为既博学又专精的“通才”。这对于加速RAG等企业级AI应用的落地,无疑是一次意义深远的推动。未来,我们有理由期待,那些曾经困扰我们的“不够智能”的AI应用,将变得越来越少。
GitHub源码(含微调框架):https://github.com/TencentCloudADP/youtu-embedding.git
Hugging Face模型下载:https://huggingface.co/tencent/Youtu-Embedding
论文链接:https://arxiv.org/abs/2508.11442
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!