AI Agent常用的RAG有哪些种,分别适用于什么情况
RAG(Retrieval-Augmented Generation,检索增强生成)并非单一架构,而是围绕 “检索 + 生成” 核心逻辑衍生出多种类型,分类维度主要包括检索精度、数据动态性、模态类型、架构复杂度等。不同类型的 RAG 在 “检索深度、实时性、成本、适用场景” 上差异显著,以下按 “核心能力维度” 分类,结合实际需求场景说明适用情况:
一、按 “检索精度 / 增强方式” 分:从基础到高阶的精度升级
这是最核心的分类维度,针对 “基础检索不够准” 的痛点,通过不同增强手段提升检索相关性,覆盖从简单问答到复杂需求的场景。
1. 基础 RAG(Basic RAG)
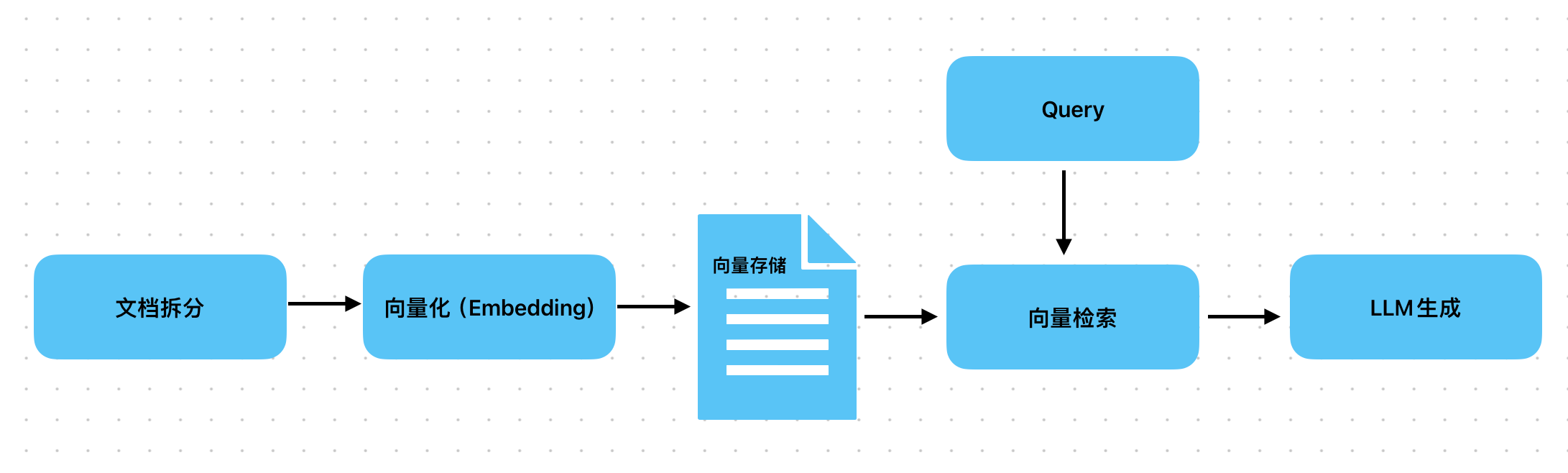
定义
最经典的 “文档拆分→向量嵌入→向量检索→LLM 生成” 流程,无额外增强逻辑,依赖单一向量索引(如 HNSW)做语义匹配。
核心逻辑
- 文档按固定长度(如 512/1024 字符)拆分成 chunk;
- 所有 chunk 转成单向量存入向量库;
- 用户 query 转向量后,检索 Top-K 相似 chunk,直接喂给 LLM 生成答案。
适用情况
- 场景特点:需求简单、query 清晰、文档短且结构规整;
- 典型场景:
- 客服 FAQ 问答(如 “产品保修期限是多久”);
- 小型知识库查询(如团队内部规章制度、工具使用手册);
- 低成本验证场景(小团队快速搭建 RAG 原型,验证业务可行性)。
不适用情况
- 长文档(如 100 页 PDF):单 chunk 无法覆盖上下文,易丢失逻辑;
- 模糊 query(如 “怎么优化那个搜索参数”,未明确 “搜索参数” 是 efConstruction 还是 M);
- 需精准定位细节的场景(如法律合同中的某条条款)。
2. 增强型 RAG(Enhanced RAG)
针对基础 RAG 的精度痛点,通过 “优化检索逻辑、补充上下文信息” 提升相关性,是目前工业界主流方案,细分类型如下:
(1)HyDE(Hypothetical Document Embeddings,假设文档嵌入)
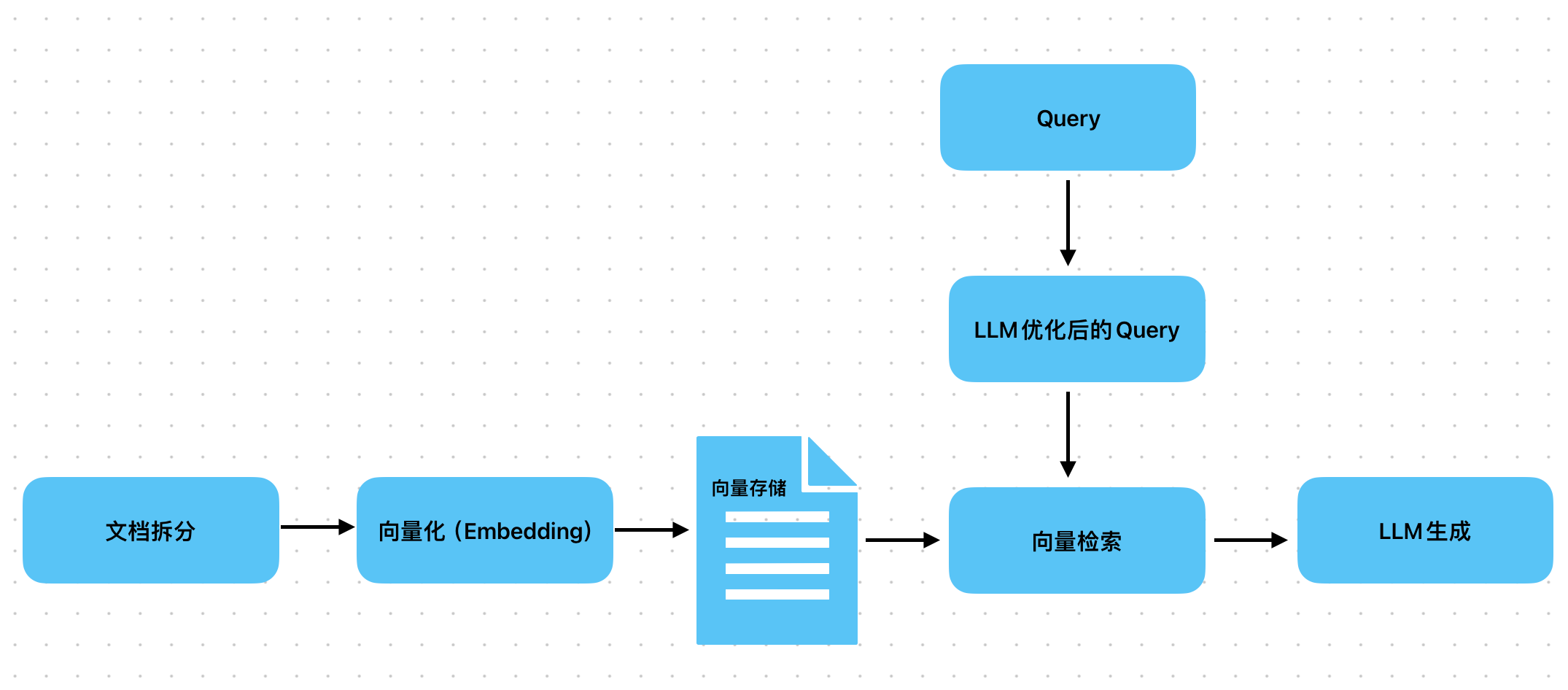
定义
先让 LLM 根据 query 生成 “假设性答案文档”,再用假设文档的向量去检索真实文档,而非直接用 query 向量检索。
核心逻辑
- Step1:Query → LLM 生成 “如果存在答案,文档可能长什么样”(如 query “RAG 怎么分类型”→生成假设文档 “RAG 按检索精度可分基础 RAG、HyDE、多向量 RAG...”);
- Step2:用假设文档的向量检索真实知识库,找到最匹配的 chunk;
- Step3:真实 chunk+query → LLM 生成最终答案。
适用情况
- 场景特点:query 模糊、抽象,或知识库中文档稀疏(直接检索难匹配);
- 典型场景:
- 技术问题模糊查询(如 “怎么调优那个向量搜索的参数”,未明确是 HNSW 的 M 还是 efSearch);
- 新兴领域问答(如 “2025 年 RAG 的新趋势”,知识库中相关文档少,需假设文档引导检索);
- 长 query 拆解(如用户输入一段业务需求描述,而非明确问题,HyDE 可提炼核心需求生成假设文档)。
(2)多向量 RAG(Multi-Vector RAG)
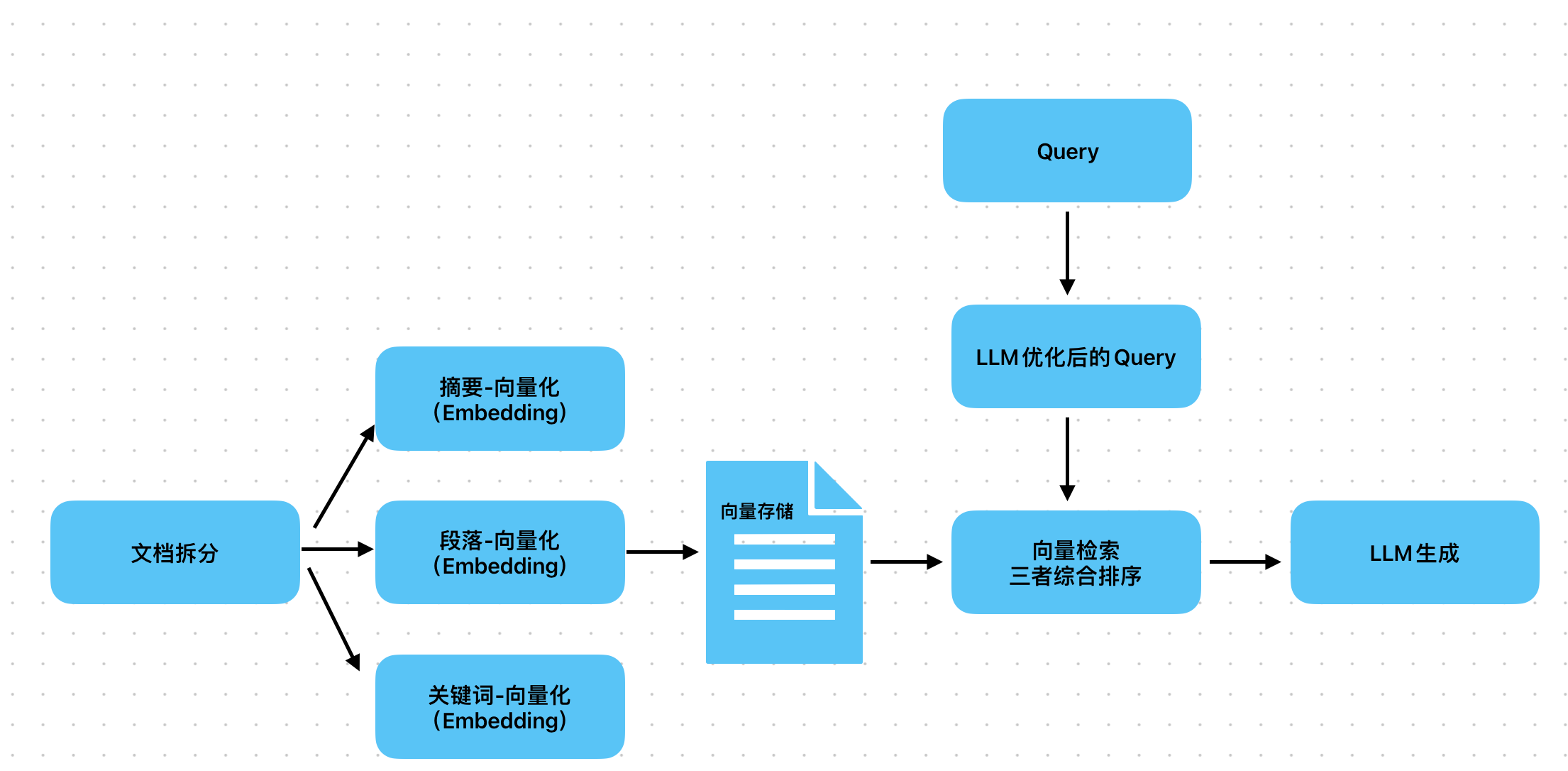
定义
不为文档 chunk 生成 “单一向量”,而是为 chunk 的 “不同维度信息” 生成多个向量(如摘要向量、段落向量、句子向量、关键词向量),检索时多维度匹配。
核心逻辑
- 文档处理:1 个 chunk → 生成 3 类向量:
- 摘要向量(chunk 的核心总结,用于快速定位主题);
- 段落向量(chunk 原文向量,用于精准匹配细节);
- 关键词向量(提取 chunk 中的核心术语,如 “efConstruction”“HNSW”,用于关键词匹配);
- 检索时:同时用 query 向量匹配这 3 类向量,综合排序后返回最相关的 chunk。
适用情况
- 场景特点:文档长(如 5000 字以上的报告)、需精准定位细节、query 可能关注不同维度;
- 典型场景:
- 法律合同检索(用户可能问 “合同中违约责任的条款”→摘要向量定位 “违约责任” 章节,段落向量匹配具体条款,关键词向量匹配 “违约责任” 术语);
- 技术文档查询(如 “Spark 的 Shuffle 优化步骤”→摘要向量定位 “Shuffle 优化” 章节,句子向量匹配具体步骤,关键词向量匹配 “Shuffle”“优化”);
- 学术论文问答(用户可能问 “论文的实验数据来源”→多向量同时匹配 “实验”“数据来源” 相关信息)。
(3)分层 RAG(Hierarchical RAG)
定义
按 “文档层级” 构建检索结构(如 “文档集→章节→段落→句子”),检索时从顶层到底层逐步缩小范围,类似 “目录导航 + 精准查找”。
核心逻辑
- 构建层级索引:
- 顶层:文档 / 章节的摘要向量(如 “第 1 章 HNSW 算法原理”);
- 中层:段落向量(如 “1.1 HNSW 的分层逻辑”);
- 底层:句子向量(如 “HNSW 用指数衰减概率分配向量楼层”);
- 检索流程:先检索顶层摘要→确定相关章节→再检索中层段落→最后定位底层句子,避免直接检索全量句子向量。
适用情况
- 场景特点:文档量大(十万级以上)、有明确层级结构(如书籍、手册、多章节报告);
- 典型场景:
- 企业知识库(如包含产品手册、技术文档、培训资料的百万级文档库,用户问 “产品 A 的安装步骤”→先定位 “产品 A 手册”→再找 “安装章节”→最后提取步骤);
- 电子书问答(如 “《大数据架构师指南》中关于 Kafka 的调优建议”→先定位 “Kafka 章节”→再找 “调优小节”→最后匹配具体建议)。
二、按 “数据动态性” 分:静态 vs 动态,应对数据更新频率差异
核心解决 “知识库数据是否需要实时同步” 的问题,两种类型在索引更新策略上完全不同。
1. 静态 RAG(Static RAG)
定义
知识库数据长期不变(更新周期≥1 个月),索引构建后无需频繁更新,一次构建可长期使用。
核心逻辑
- 离线处理:一次性将所有文档拆分、嵌入、构建向量索引(如用 FAISS/HNSW 构建静态索引);
- 检索时:直接查询静态索引,不触发索引更新;
- 更新方式:若需更新数据,需重新全量构建索引(或增量构建后合并)。
适用情况
- 场景特点:数据更新慢、变更频率低,且更新成本可接受;
- 典型场景:
- 产品手册问答(如手机说明书、家电使用指南,半年更新一次);
- 历史数据查询(如 “2023 年公司财报中的营收数据”,数据固定不变);
- 法规政策查询(如 “2024 年生效的《数据安全法》条款”,短期内不会变更)。
2. 动态 RAG(Dynamic RAG)
定义
知识库数据实时更新(更新周期≤1 小时,甚至秒级),索引需同步动态刷新,确保检索到最新数据。
核心逻辑
- 实时数据接入:通过 API、消息队列(Kafka)、CDC 等方式实时获取新数据(如新闻、股票信息、实时日志);
- 增量索引更新:新数据拆分、嵌入后,实时插入向量库(如 Milvus/Elasticsearch 支持增量写入),无需全量重建;
- 检索时:查询的是包含最新数据的动态索引,确保答案时效性。
适用情况
- 场景特点:数据更新快、需实时获取最新信息,过时数据无价值;
- 典型场景:
- 金融资讯问答(如 “今天 A 股的收盘指数是多少”“最新的央行降息政策是什么”,数据需秒级更新);
- 新闻摘要问答(如 “昨天发布的科技新闻中,有哪些关于 AI 的突破”,数据需日级更新);
- 实时业务日志分析(如 “过去 1 小时内,系统报错的主要原因是什么”,日志需分钟级同步)。
三、按 “模态类型” 分:文本 vs 多模态,应对不同数据格式需求
传统 RAG 仅处理文本,多模态 RAG 可融合图片、表格、音频、视频等非文本数据,覆盖更丰富的交互场景。
1. 文本 RAG(Text-only RAG)
定义
仅处理文本类数据(如文档、FAQ、新闻、论文),检索和生成均围绕文本展开,是最基础、最常用的类型。
适用情况
- 场景特点:需求仅涉及文本信息,无图片、表格等非文本数据;
- 典型场景:
- 客服文本 FAQ(如 “退款流程是什么”);
- 技术文档文本问答(如 “Flink 的 Watermark 机制怎么配置”);
- 学术论文文本检索(如 “这篇论文的实验结论是什么”)。
2. 多模态 RAG(Multimodal RAG)
定义
支持处理文本、图片、表格、音频、视频等多种模态数据,检索时可跨模态匹配(如用文本 query 检索图片,或用图片 query 检索相关文本),生成时可融合多模态信息。
核心逻辑
- 多模态嵌入:不同类型数据转成统一维度的向量(如用 CLIP 模型将图片和文本转成同维度向量,用 Table Transformer 将表格转成向量);
- 跨模态检索:如用户上传一张 “手机故障截图”(图片)→ 检索相关的 “故障排查文本指南” 和 “维修视频片段”;
- 多模态生成:生成答案时,可同时引用文本条款(如 “根据维修手册第 3 章”)和图片标注(如 “截图中红色框内为故障部件”)。
适用情况
- 场景特点:需求涉及非文本数据,需跨模态交互;
- 典型场景:
- 电商客服(用户上传 “商品破损图片”→ 检索相关的 “退换货政策文本” 和 “破损商品处理流程视频”,生成包含文本和图片指引的答案);
- 医疗问答(医生上传 “X 光片”→ 检索相关的 “病症诊断文本” 和 “相似病例图片”,生成综合诊断建议);
- 教育场景(学生上传 “数学公式图片”→ 检索相关的 “公式推导文本” 和 “解题视频”,生成多模态解题步骤)。
四、按 “架构复杂度” 分:简易 vs 工业级,应对不同团队资源
核心差异在 “是否考虑高可用、高并发、容错性”,覆盖从原型验证到大规模生产的需求。
1. 简易 RAG(Simple RAG)
定义
基于开源工具快速搭建,无复杂架构设计,仅满足 “能用” 的基本需求,适合小团队或原型验证。
核心组件
- 文档处理:Python 脚本(如 LangChain 的 DocumentLoader);
- 向量库:轻量级开源库(如 FAISS、Chroma);
- LLM:API 调用(如 OpenAI GPT-3.5/4、阿里通义千问);
- 部署:单机部署(如 Flask/FastAPI 搭建简单接口)。
适用情况
- 场景特点:小流量(日查询量<1000)、无高可用需求、快速验证业务;
- 典型场景:
- 小团队内部知识库(如 10 人团队的项目文档查询);
- 个人工具(如开发者自己的技术笔记检索);
- 业务原型验证(如验证 “用 RAG 做产品手册问答” 是否可行,再决定是否投入资源做工业级开发)。
2. 工业级 RAG(Industrial RAG)
定义
针对大规模生产环境设计,具备高并发、高可用、容错性、可监控性,需团队协作开发维护。
核心组件
- 文档处理:分布式 ETL(如 Spark/Flink 处理海量文档);
- 向量库:分布式向量数据库(如 Milvus、Weaviate、Elasticsearch 集群);
- LLM:私有部署(如 Llama 3、Qwen-7B 私有部署,避免 API 依赖);
- 架构设计:
- 缓存层(如 Redis 缓存高频查询结果,降低向量库压力);
- 负载均衡(如 Nginx/K8s 调度请求,支持水平扩展);
- 监控告警(如 Prometheus 监控检索延迟、召回率,异常时告警);
- 容错机制(如向量库主从备份,避免单点故障)。
适用情况
- 场景特点:大流量(日查询量>10 万)、高可用需求(可用性≥99.9%)、大规模用户使用;
- 典型场景:
- 企业级客服系统(如电商平台的百万级用户问答,需支持每秒数百次查询);
- 公有云 RAG 服务(如阿里云 “向量检索 + LLM” 的 RAG 服务,需支持多租户、高容错);
- 行业解决方案(如金融机构的智能投研系统,需处理海量研报,且满足合规和高可用要求)。
总结:如何选择适合的 RAG 类型?
按以下 4 个维度逐步判断,即可快速定位:
- 数据特性:数据是文本还是多模态?更新快(动态)还是慢(静态)?→ 排除不符合的模态 / 动态性类型;
- 需求精度:是简单 FAQ(基础 RAG)还是长文档细节查询(多向量 RAG)?query 是否模糊(HyDE)?→ 确定检索增强类型;
- 业务规模:是小团队原型(简易 RAG)还是大规模生产(工业级 RAG)?→ 确定架构复杂度;
- 资源成本:是否有能力维护分布式集群?是否能承担多模态嵌入的计算成本?→ 微调选择(如资源有限时,用 “基础 RAG + 混合检索” 替代多向量 RAG)。
例如:
- 电商客服(文本 + 图片咨询,数据实时更新,日查询 10 万 +)→ 多模态 + 动态 + 工业级 RAG;
- 小团队技术笔记查询(文本,半年更新一次,日查询 100+)→ 文本 + 静态 + 简易 RAG;
- 金融资讯问答(文本,秒级更新,需精准检索政策)→ 文本 + 动态 + 增强型 RAG(HyDE)。
推荐阅读
吃透大数据算法-算法地图(备用)
吃透大数据算法-量体裁衣-HNSW场景化参数调优
字节多Agent架构Aime—— 让多个 AI 像 “灵活团队” 一样干活的新系统
吃透大数据算法-百万商品库的 “闪电匹配”:HNSW 算法的电商实战故事