第7章 muduo编程示例(2)
7.4 muduo Buffer类的设计与使用
本节介绍muduo中输入输出缓冲区的设计与实现。文中buffer指一般的应用层缓冲区、缓冲技术,Buffer特指muduo::net::Buffer class。
7.4.1 muduo的IO模型
[UNP]6.2节总结了Unix/Linux上的五种IO模型:阻塞(blocking)、非阻塞(non-blocking)、IO复用(IO multiplexing)、信号驱动(signal-driven)、异步(asynchronous)。这些都是单线程下的IO模型。
C10k问题[注11:http://www.kegel.com/c10k.html]的页面介绍了五种IO策略,把线程也纳入考量。(现在C10k已经不是什么问题,C100k也不是大问题,C1000k才算得上挑战)。
在这个多核时代,线程是不可避免的。那么服务端网络编程该如何选择线程模型呢?我赞同libev作者的观点[注12:http://pod.tst.eu/http://cvs.schmorp.de/libev/ev.pod#THREADS_AND_COROUTINES]:one loop per thread is usually a good model。之前我也不止一次表述过这个观点,参见§ 3.3“多线程服务器的常用编程模型”和§ 6.6“详解muduo多线程模型”。
如果采用one loop per thread的模型,多线程服务端编程的问题就简化为如何设计一个高效且易于使用的event loop,然后每个线程run一个event loop就行了(当然、同步和互斥是不可或缺的)。在“高效”这方面已经有了很多成熟的范例(libev、libevent、memcached、redis、lighttpd、nginx),在“易于使用”方面我希望muduo能有所作为。(muduo可算是用现代C++实现了Reactor模式,比起原始的Reactor来说要好用得多。)
event loop是non-blocking网络编程的核心,在现实生活中,non-blocking几乎总是和IO multiplexing一起使用,原因有两点:
● 没有人真的会用轮询(busy-polling)来检查某个non-blocking IO操作是否完成,这样太浪费CPU cycles。
● IO multiplexing一般不能和blocking IO用在一起,因为blocking IO中read()/write()/accept()/connect()都有可能阻塞当前线程,这样线程就没办法处理其他socket上的IO事件了。见[UNP]16.6节“nonblocking accept”的例子。
所以,当我提到non-blocking的时候,实际上指的是non-blocking+IO multi-plexing,单用其中任何一个是不现实的。另外,本书所有的“连接”均指TCP连接,socket和connection在文中可互换使用。
当然,non-blocking编程比blocking难得多,见§ 6.4.1“TCP网络编程本质论”列举的难点。基于event loop的网络编程跟直接用C/C++编写单线程Windows程序颇为相像:程序不能阻塞,否则窗口就失去响应了;在event handler中,程序要尽快交出控制权,返回窗口的事件循环。
7.4.2 为什么non-blocking网络编程中应用层buffer是必需的
non-blocking IO的核心思想是避免阻塞在read()或write()或其他IO系统调用上,这样可以最大限度地复用thread-of-control,让一个线程能服务于多个socket连接。IO线程只能阻塞在IO multiplexing函数上,如select/poll/epoll_wait。这样一来,应用层的缓冲是必需的,每个TCP socket都要有stateful的input buffer和output buffer。
TcpConnection必须要有output buffer 考虑一个常见场景:程序想通过TCP连接发送100kB的数据,但是在write()调用中,操作系统只接受了80kB(受TCP advertised window的控制,细节见[TCPv1]),你肯定不想在原地等待,因为不知道会等多久(取决于对方什么时候接收数据,然后滑动TCP窗口)。程序应该尽快交出控制权,返回event loop。在这种情况下,剩余的20kB数据怎么办?
对于应用程序而言,它只管生成数据,它不应该关心到底数据是一次性发送还是分成几次发送,这些应该由网络库来操心,程序只要调用TcpConnection::send()就行了,网络库会负责到底。网络库应该接管这剩余的20kB数据,把它保存在该TCP connection的output buffer里,然后注册POLLOUT事件,一旦socket变得可写就立刻发送数据。当然,这第二次write()也不一定能完全写入20kB,如果还有剩余,网络库应该继续关注POLLOUT事件;如果写完了20kB,网络库应该停止关注POLLOUT,以免造成busy loop。(muduo EventLoop采用的是epoll level trigger,原因见下页。)
如果程序又写入了50kB,而这时候output buffer里还有待发送的20kB数据,那么网络库不应该直接调用write(),而应该把这50kB数据append在那20kB数据之后,等socket变得可写的时候再一并写入。
如果output buffer里还有待发送的数据,而程序又想关闭连接(对程序而言,调用TcpConnection::send()之后他就认为数据迟早会发出去),那么这时候网络库不能立刻关闭连接,而要等数据发送完毕,见p.191“为什么TcpConnection::shutdown()没有直接关闭TCP连接”中的讲解。
综上,要让程序在write操作上不阻塞,网络库必须要给每个TCP connection配置output buffer。
TcpConnection必须要有input buffer TCP是一个无边界的字节流协议,接收方必须要处理“收到的数据尚不构成一条完整的消息”和“一次收到两条消息的数据”等情况。一个常见的场景是,发送方send()了两条1kB的消息(共2kB),接收方收到数据的情况可能是:
● 一次性收到2kB数据;
● 分两次收到,第一次600B,第二次1400B;
● 分两次收到,第一次1400B,第二次600B;
● 分两次收到,第一次1kB,第二次1kB;
● 分三次收到,第一次600B,第二次800B,第三次600B;
● 其他任何可能。一般而言,长度为n字节的消息分块到达的可能性有2n−1种。
网络库在处理“socket可读”事件的时候,必须一次性把socket里的数据读完(从操作系统buffer搬到应用层buffer),否则会反复触发POLLIN事件,造成busy-loop。那么网络库必然要应对“数据不完整”的情况,收到的数据先放到input buffer里,等构成一条完整的消息再通知程序的业务逻辑。这通常是codec的职责,见§ 7.3“Boost.Asio的聊天服务器”中的“TCP分包”的论述与代码。所以,在TCP网络编程中,网络库必须要给每个TCP connection配置input buffer。
muduo EventLoop采用的是epoll(4)level trigger,而不是edge trigger。一是为了与传统的poll(2)兼容,因为在文件描述符数目较少,活动文件描述符比例较高时,epoll(4)不见得比poll(2)更高效[注13:http://sheddingbikes.com/posts/1280829388.html],必要时可以在进程启动时切换Poller。二是level trigger编程更容易,以往select(2)/poll(2)的经验都可以继续用,不可能发生漏掉事件的bug。三是读写的时候不必等候出现EAGAIN,可以节省系统调用次数,降低延迟。
所有muduo中的IO都是带缓冲的IO(buffered IO),你不会自己去read()或write()某个socket,只会操作TcpConnection的input buffer和output buffer。更确切地说,是在onMessage()回调里读取input buffer;调用TcpConnection::send()来间接操作output buffer,一般不会直接操作output buffer。
另外,muduo的onMessage()的原型如下,它既可以是free function,也可以是member function,反正muduo TcpConnection只认boost::function<>。
void onMessage(const TcpConnectionPtr&conn,Buffer*buf,Timestamp receiveTime);
对于网络程序来说,一个简单的验收测试是:输入数据每次收到一个字节(200字节的输入数据会分200次收到,每次间隔10ms),程序的功能不受影响。对于muduo程序,通常可以用codec来分离“消息接收”与“消息处理”,见§ 7.6“在muduo中实现Protobuf编解码器与消息分发器”对“编解码器codec”的介绍。
如果某个网络库只提供相当于char buf[8192]的缓冲,或者根本不提供缓冲区,而仅仅通知程序“某socket可读/某socket可写”,要程序自己操心IO buffering,这样的网络库用起来就很不方便了。
7.4.3 Buffer的功能需求
muduo Buffer的设计考虑了常见的网络编程需求,我试图在易用性和性能之间找一个平衡点,目前这个平衡点更偏向于易用性。
muduo Buffer的设计要点:
● 对外表现为一块连续的内存(char*p,int len),以方便客户代码的编写。
● 其size()可以自动增长,以适应不同大小的消息。它不是一个fixed size array(固定大小数组,例如char buf[8192])。
● 内部以std::vector<char>来保存数据,并提供相应的访问函数。
Buffer其实像是一个queue,从末尾写入数据,从头部读出数据。
谁会用Buffer?谁写谁读?根据前文分析,TcpConnection会有两个Buffer成员,input buffer与output buffer。
● input buffer,TcpConnection会从socket读取数据,然后写入input buffer(其实这一步是用Buffer::readFd()完成的);客户代码从input buffer读取数据。
● output buffer,客户代码会把数据写入output buffer(其实这一步是用TcpConnection::send()完成的);TcpConnection从output buffer读取数据并写入socket。
其实,input和output是针对客户代码而言的,客户代码从input读,往output写。TcpConnection的读写正好相反。
图7-2是muduo::net::Buffer的类图。请注意,为了后面画图方便,这个类图跟实际代码略有出入,但不影响我要表达的观点。代码位于muduo/net/Buffer.{h,cc}。

图7-2
本节不介绍每个成员函数的使用,而会详细讲解readIndex和writeIndex的作用。
Buffer::readFd()我在p.138写道:
在非阻塞网络编程中,如何设计并使用缓冲区?一方面我们希望减少系统调用,一次读的数据越多越划算,那么似乎应该准备一个大的缓冲区。另一方面希望减少内存占用。如果有10000个并发连接,每个连接一建立就分配各50kB的读写缓冲区的话,将占用1GB内存,而大多数时候这些缓冲区的使用率很低。muduo用readv(2)结合栈上空间巧妙地解决了这个问题。
具体做法是,在栈上准备一个65536字节的extrabuf,然后利用readv()来读取数据,iovec有两块,第一块指向muduo Buffer中的writable字节,另一块指向栈上的extrabuf。这样如果读入的数据不多,那么全部都读到Buffer中去了;如果长度超过Buffer的writable字节数,就会读到栈上的extrabuf里,然后程序再把extrabuf里的数据append()到Buffer中,代码见§8.7.2。
这么做利用了临时栈上空间[[注14:readFd0是最内层函数,其在每个I0线程的最大stack空间开销是固定的64KiB与连接数目无关。如果stack空间紧张也可以改用thread local的extrabuf,但是不能全局共享一个extrabuf。(为什么?)],避免每个连接的初始Buffer过大造成的内存浪费,也避免反复调用read()的系统开销(由于缓冲区足够大,通常一次readv()系统调用就能读完全部数据)。由于muduo的事件触发采用level trigger(电平触发),因此这个函数并不会反复调用read()直到其返回EAGAIN,从而可以降低消息处理的延迟。
这算是一个小小的创新吧。
线程安全?muduo::net::Buffer不是线程安全的(其安全性跟std::vector相同),这么设计的理由如下:
● 对于input buffer,onMessage()回调始终发生在该TcpConnection所属的那个IO线程,应用程序应该在onMessage()完成对input buffer的操作,并且不要把input buffer暴露给其他线程。这样所有对input buffer的操作都在同一个线程,Buffer class不必是线程安全的。
● 对于output buffer,应用程序不会直接操作它,而是调用TcpConnec-tion::send()来发送数据,后者是线程安全的。
代码中用EventLoop::assertInLoopThread()保证以上假设成立。
如果TcpConnection::send()调用发生在该TcpConnection所属的那个IO线程,那么它会转而调用TcpConnection::sendInLoop(),sendInLoop()会在当前线程(也就是IO线程)操作output buffer;如果TcpConnection::send()调用发生在别的线程,它不会在当前线程调用sendInLoop(),而是通过EventLoop::runInLoop()把sendInLoop()函数调用转移到IO线程(听上去颇为神奇?),这样sendInLoop()还是会在IO线程操作output buffer,不会有线程安全问题。当然,跨线程的函数转移调用涉及函数参数的跨线程传递,一种简单的做法是把数据拷贝一份,绝对安全。
另一种更为高效的做法是用swap()。这就是为什么TcpConnection::send()的某个重载以Buffer*为参数,而不是const Buffer&,这样可以避免拷贝,而用Buffer::swap()实现高效的线程间数据转移。(最后这点,仅为设想,暂未实现。目前仍然以数据拷贝方式在线程间传递,略微有些性能损失。)
7.4.4 Buffer的数据结构
Buffer的内部是一个std::vector<char>,它是一块连续的内存。此外,Buffer有两个data member,指向该vector中的元素。这两个index的类型是int,不是char*,目的是应对迭代器失效。muduo Buffer的设计参考了Netty的ChannelBuffer和libevent 1.4.x的evbuffer。不过,其prependable(可预置)可算是一点“微创新”。
在介绍Buffer的数据结构之前,先简单说一下后面示意图中表示指针或下标的箭头所指位置的具体含义。对于长度为10的字符串"Chen Shuo\n",如果p0指向第0个字符(白色区域的开始),p1指向第5个字符(灰色区域的开始),p2指向'\n'之后的那个位置(通常是end()迭代器所指的位置),那么精确的画法如图7-3的左图所示,简略的画法如图7-3的右图所示,后文都采用这种简略画法。
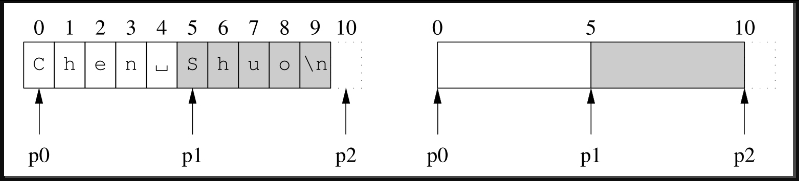
图7-3
muduo Buffer的数据结构如图7-4所示。
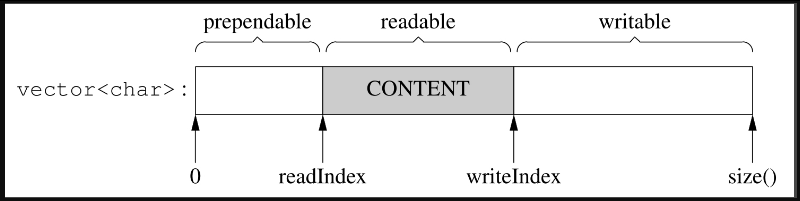
图7-4
两个index把vector的内容分为三块:prependable、readable、writable,各块的大小见式7−1。灰色部分是Buffer的有效载荷(payload),prependable的作用留到后面讨论。

readIndex和writeIndex满足以下不变式(invariant):
0≤readIndex≤writeIndex≤size()
muduo Buffer里有两个常数kCheapPrepend和kInitialSize,定义了prependable的初始大小和writable的初始大小,readable的初始大小为0。在初始化之后,Buffer的数据结构如图7-5所示,其中括号里的数字是该变量或常量的值。

图7-5
根据以上公式(见式7−1)可算出各块的大小,刚刚初始化的Buffer里没有payload数据,所以readable==0。
7.4.5 Buffer的操作
基本的read-write cycle
Buffer初始化后的情况见图7-4。如果向Buffer写入了200字节,那么其布局如图7-6所示。
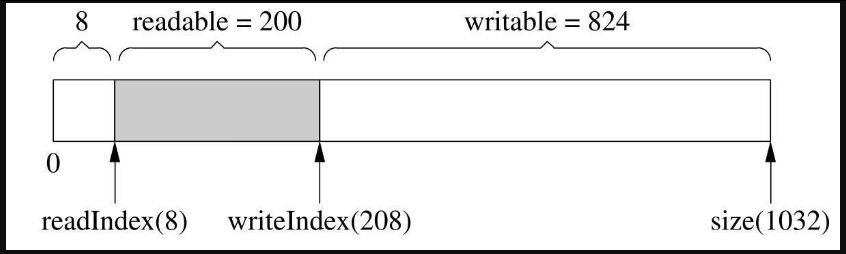
图7-6
图7-6中writeIndex向后移动了200字节,readIndex保持不变,readable和writable的值也有变化。
如果从Buffer read()&retrieve()(下称“读入”)了50字节,结果如图7-7所示。与图7-6相比,readIndex向后移动50字节,writeIndex保持不变,readable和writable的值也有变化(这句话往后从略)。
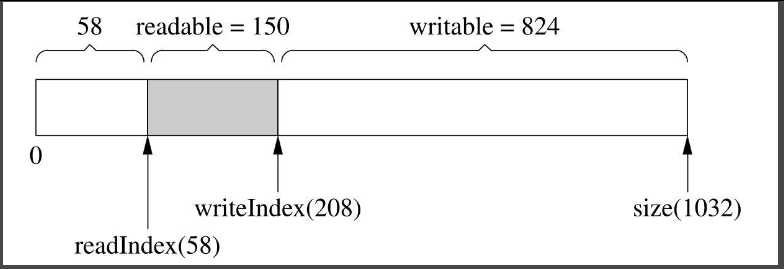
图7-7
然后又写入了200字节,writeIndex向后移动了200字节,readIndex保持不变,如图7-8所示。
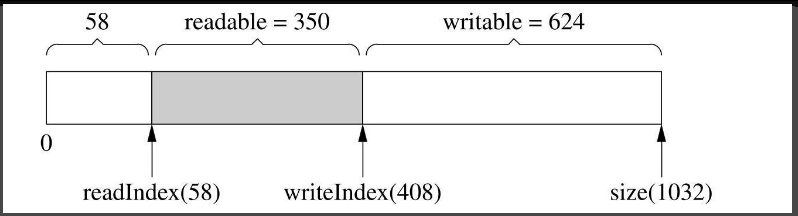
图7-8
接下来,一次性读入350字节,请注意,由于全部数据读完了,readIndex和writeIndex返回原位以备新一轮使用(见图7-9),这和图7-5是一样的。
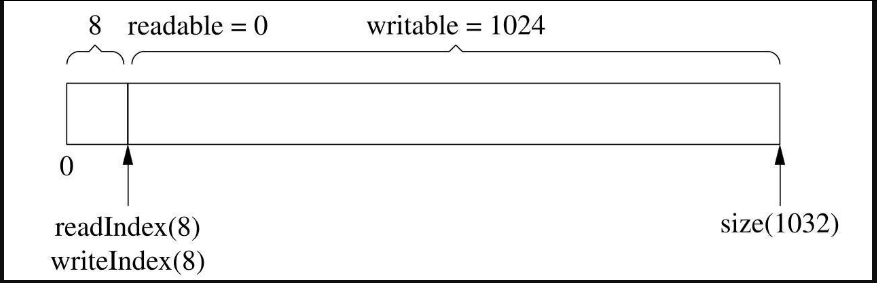
图7-9
以上过程可以看作是发送方发送了两条消息,长度分别为50字节和350字节,接收方分两次收到数据,每次200字节,然后进行分包,再分两次回调客户代码。
自动增长
muduo Buffer不是固定长度的,它可以自动增长,这是使用vector的直接好处。假设当前的状态如图7-10所示。(这和前面的图7-8是一样的。)
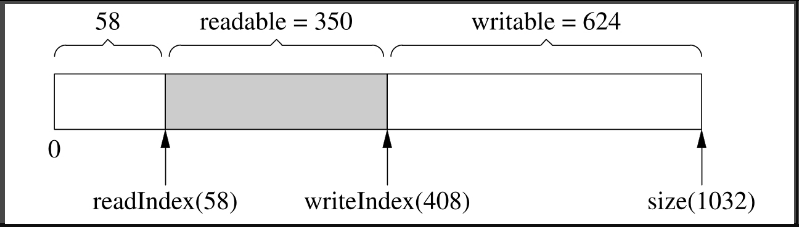
图7-10
客户代码一次性写入1000字节,而当前可写的字节数只有624,那么buffer会自动增长以容纳全部数据,得到的结果如图7-11所示。注意readIndex返回到了前面,以保持prependable等于kCheapPrependable。由于vector重新分配了内存,原来指向其元素的指针会失效,这就是为什么readIndex和writeIndex是整数下标而不是指针。(注意:在目前的实现中prependable会保持58字节,留待将来修正。)
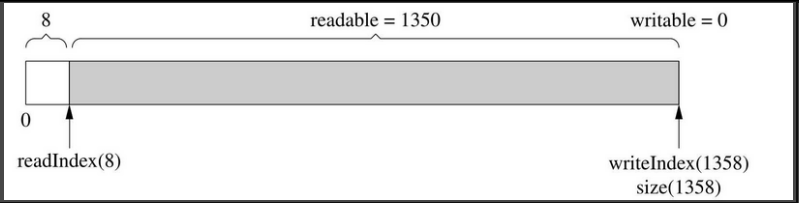
图7-11
然后读入350字节,readIndex前移,如图7-12所示。
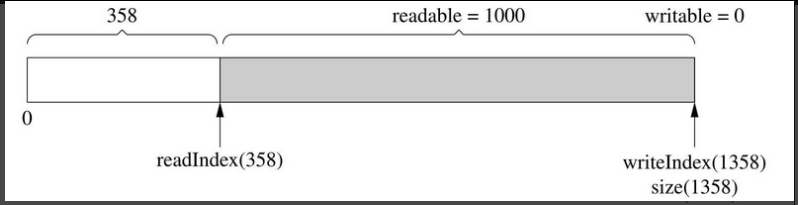
图7-12
最后,读完剩下的1000字节,readIndex和writeIndex返回kCheapPrependable,如图7-13所示。
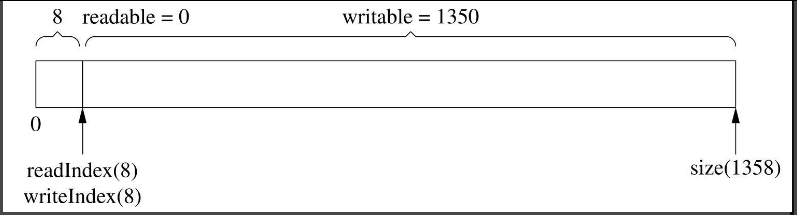
图7-13
注意buffer并没有缩小大小,下次写入1350字节就不会重新分配内存了。换句话说,muduo Buffer的size()是自适应的,它一开始的初始值是1kB多,如果程序中经常收发10kB的数据,那么用几次之后它的size()会自动增长到10kB,然后就保持不变。这样一方面避免浪费内存(Buffer的初始大小直接决定了高并发连接时的内存消耗),另一方面避免反复分配内存。当然,客户代码可以手动shrink()buffer size()。
size()与capacity()
使用vector的另一个好处是它的capacity()机制减少了内存分配的次数。比方说程序反复写入1字节,muduo Buffer不会每次都分配内存,vector的capacity()以指数方式增长,让push_back()的平均复杂度是常数。比方说经过第一次增长,size()刚好满足写入的需求,如图7-14所示。但这个时候vector的capacity()已经大于size(),在接下来写入capacity()−size()字节的数据时,都不会重新分配内存,如图7-15所示。

图7-14
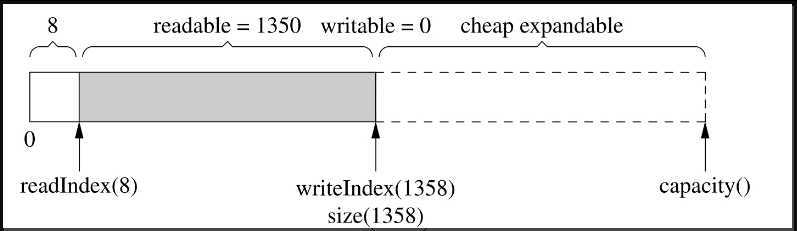
图7-15
思考题:为什么我们不需要调用reserve()来预先分配空间?因为Buffer在构造函数里把初始size()设为1KiB,这样当size()超过1KiB的时候vector会把capacity()加倍,等于说resize()替我们做了reserve()的事。用一段简单的代码验证一下:
//capacity_test.cpp
#include <vector>
#include <stdio.h>int main()
{std::vector<char> vec;printf("vec.size = %zd vec.capacity = %zd\n", vec.size(), vec.capacity());vec.resize(1024);printf("vec.size = %zd vec.capacity = %zd\n", vec.size(), vec.capacity());vec.resize(1300);printf("vec.size = %zd vec.capacity = %zd\n", vec.size(), vec.capacity());return 0;
}行结果:

细心的读者可能会发现用capacity()也不是完美的,它有优化的余地。具体来说,vector::resize()会初始化(memset()/bzero())内存,而我们不需要它初始化,因为反正立刻就要填入数据。比如,在图7-15的基础上写入200字节,由于capacity()足够大,不会重新分配内存,这是好事;但是vector::resize()会先把那200字节memset()为0(见图7-16),然后muduo Buffer再填入数据(见图7-17)。这么做稍微有点浪费,不过我不打算优化它,除非它确实造成了性能瓶颈。(精通STL的读者可能会说用vec.insert(vec.end(),...)以避免浪费,但是writeIndex和size()不一定是对齐的,会有别的麻烦。)
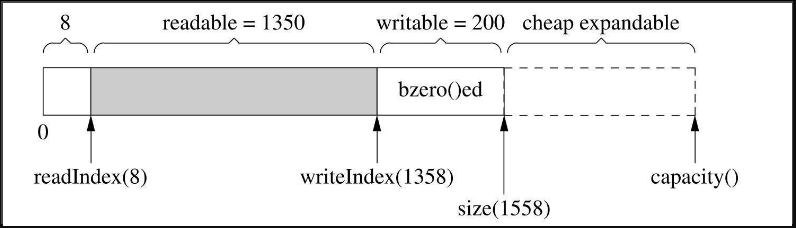
图7-16
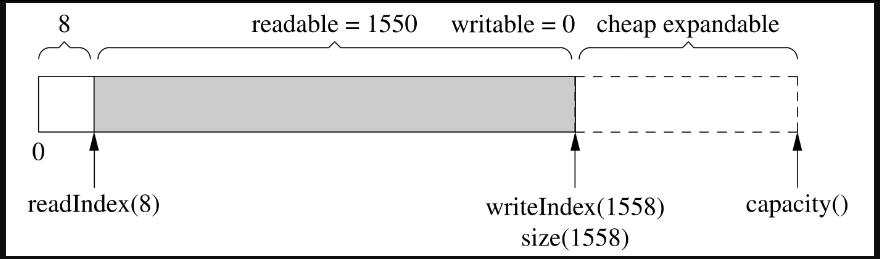
图7-17
Google Protobuf中有一个STLStringResizeUninitialized函数[注15:http://code.google.com/p/protobuf/source/browse/tags/2.4.0a/src/goog!e/protobuf/stubs/stl_util-inl.h#60],干的就是这个事情。
内部腾挪
有时候,经过若干次读写,readIndex移到了比较靠后的位置,留下了巨大的prependable空间,如图7-18所示。
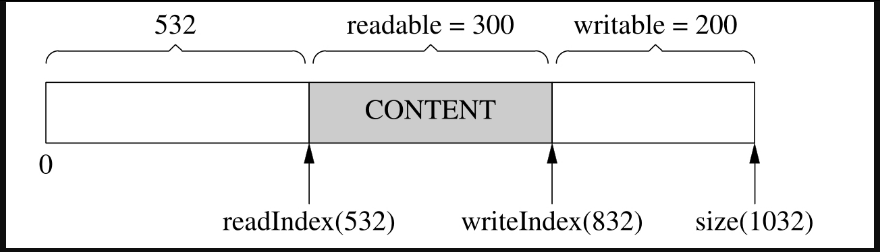
图7-18
这时候,如果我们想写入300字节,而writable只有200字节,怎么办?muduo Buffer在这种情况下不会重新分配内存,而是先把已有的数据移到前面去,腾出writable空间,如图7-19所示。
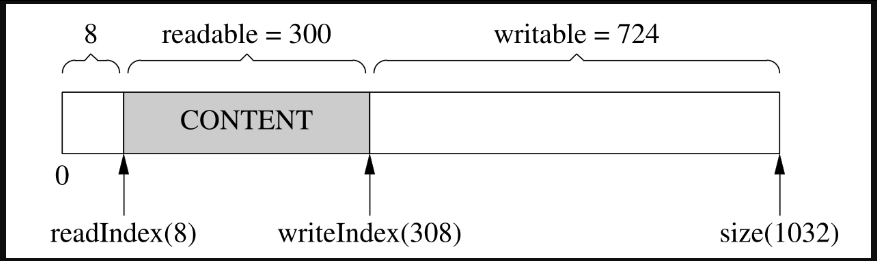
图7-19
然后,就可以写入300字节了,如图7-20所示。
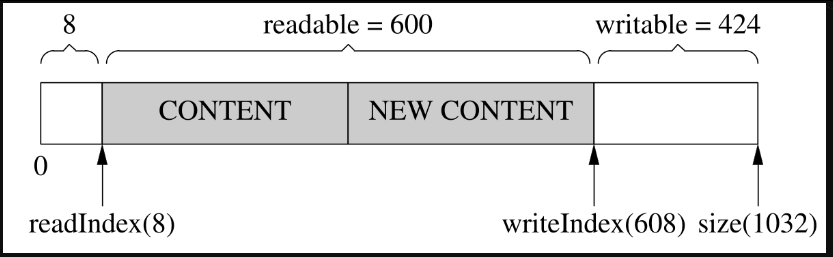
图7-20
这么做的原因是,如果重新分配内存,反正也是要把数据拷贝到新分配的内存区域,代价只会更大。
前方添加(prepend)
前面说muduo Buffer有个小小的创新(或许不是创新,我记得在哪儿看到过类似的做法,忘了出处),即提供prependable空间,让程序能以很低的代价在数据前面添加几个字节。
比方说,程序以固定的4个字节表示消息的长度(§ 7.3“Boost.Asio的聊天服务器”中的LengthHeaderCodec),我要序列化一个消息,但是不知道它有多长,那么我可以一直append()直到序列化完成(图7-21,写入了200字节),然后再在序列化数据的前面添加消息的长度(图7-22,把200这个数prepend到首部)。
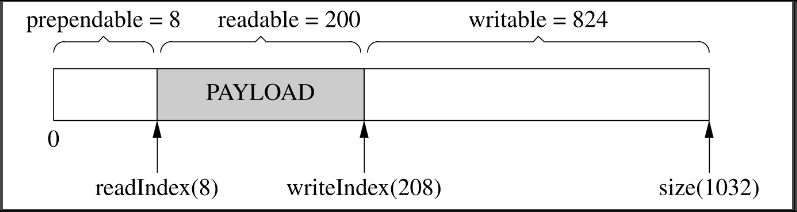
图7-21
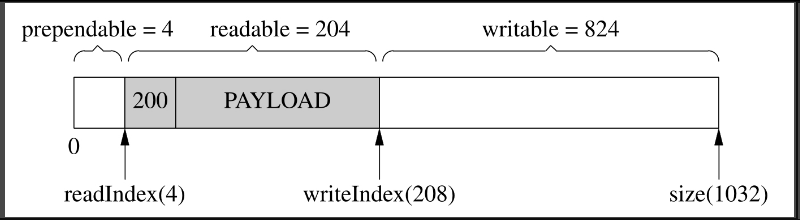
图7-22
通过预留kCheapPrependable空间,可以简化客户代码,以空间换时间。
以上各种use case的单元测试见muduo/net/tests/Buffer_unittest.cc。
7.4.6 其他设计方案
这里简单谈谈其他可能的应用层buffer设计方案。
不用vector<char>
如果有STL洁癖,那么可以自己管理内存,以4个指针为buffer的成员,数据结构如图7-23所示。
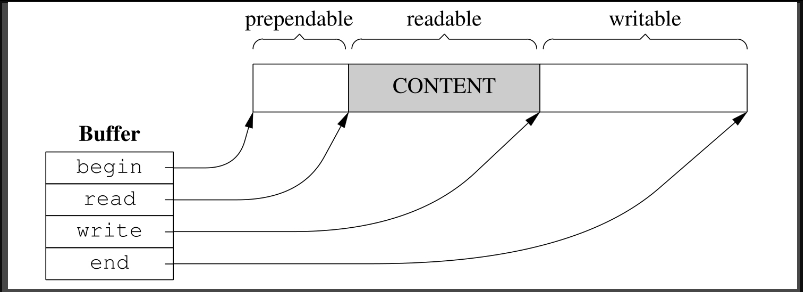
图7-23
说实话我不觉得这种方案比std::vector好。代码变复杂了,性能也未见得有能察觉得到(noticeable)的改观。如果放弃“连续性”要求,可以用circular buffer,这样可以减少一点内存拷贝(没有“内部腾挪”)。
zero copy
如果对性能有极高的要求,受不了copy()与resize(),那么可以考虑实现分段连续的zero copy buffer再配合gather scatter IO,数据结构如图7-24所示,这是libevent 2.0.x的设计方案。TCPv2介绍的BSD TCP/IP实现中的mbuf也是类似的方案,Linux的sk_buff估计也差不多。细节有出入,但基本思路都是不要求数据在内存中连续,而是用链表把数据块链接到一起。
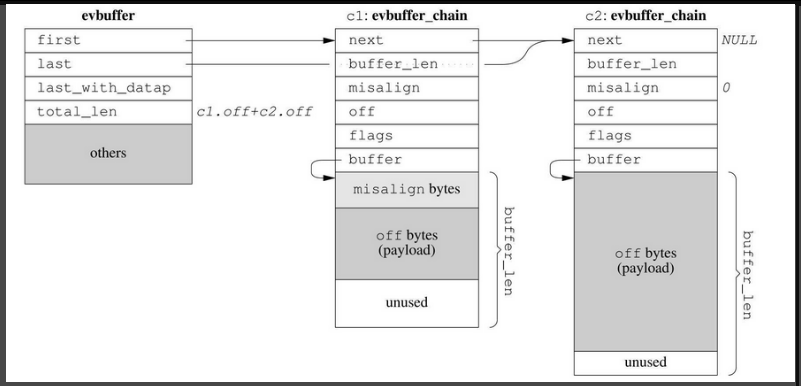
图7-24
图7-24绘制的是由两个evbuffer_chain构成的evbuffer,右边两个evbuffer_chain结构体中深灰色的部分是payload,可见evbuffer的缓冲区不是连续的,而是分块的。
当然,高性能的代价是代码变得晦涩难读,buffer不再是连续的,parse消息会稍微麻烦一些。如果你的程序只处理Protobuf Message,这不是问题,因为Protobuf有ZeroCopyInputStream接口,只要实现这个接口,parsing的事情就交给Protobuf Message去操心了。
7.4.7 性能是不是问题
看到这里,有的读者可能会嘀咕:muduo Buffer有那么多可以优化的地方,其性能会不会太低?对此,我的回应是“可以优化,不一定值得优化。”
muduo的设计目标是用于开发公司内部的分布式程序。换句话说,它是用来写专用的Sudoku server或者游戏服务器,不是用来写通用的httpd或ftpd或Web proxy。前者通常有业务逻辑,后者更强调高并发与高吞吐量。
以Sudoku为例,假设求解一个Sudoku问题需要0.2ms,服务器有8个核,那么理想情况下每秒最多能求解40000个问题。每次Sudoku请求的数据大小低于100字节(一个9×9的数独只要81字节,加上header也可以控制在100字节以下),也就是说100×40000=4MB/s的吞吐量就足以让服务器的CPU饱和。在这种情况下,去优化Buffer的内存拷贝次数似乎没有意义。
再举一个例子,目前最常用的千兆以太网的裸吞吐量是125MB/s,扣除以太网header、IP header、TCP header之后,应用层的吞吐率大约在117MB/s上下[注16:]。而现在服务器上最常用的DDR2/DDR3内存的带宽至少是4GB/s,比千兆以太网高40倍以上。也就是说,对于几kB或几十kB大小的数据,在内存中复制几次根本不是问题,因为受千兆以太网延迟和带宽的限制,跟这个程序通信的其他机器上的程序不会觉察到性能差异。
[注16:在不考虑jumbo frame的情况下,计算过程是:对于千兆以太网,每秒能传输1000Mbit数据,即125000000B/s,每个以太网frame的固定开销有:preamble(8B)、MAC(12B)、type(2B)、payload(46B~1500B)、CRC(4B)、gap(12B),因此最小的以太网帧是84B,每秒可发送约1488000帧(换言之,对于一问一答的RPC、其qps上限约是700k/s),最大的以太网帧是1538B,每秒可发送81274帧。再来算TCP有效载荷:一个TCPsegment包含IPheader(20B)和TCPheader(20B),还有Timestampoption(12B),因此TCP的最大吞吐量是81274x(1500-52)=117MB/S,合112MiB/s。实测见57.8.5.]
最后举一个例子,如果你实现的服务程序要跟数据库打交道,那么瓶颈常常在DB上,优化服务程序本身不见得能提高性能(从DB读一次数据往往就抵消了你做的全部low-level优化),这时不如把精力投入在DB调优上。
专用服务程序与通用服务程序的另外一点区别是benchmark的对象不同。如果你打算写一个httpd,自然有人会拿来和目前最好的Nginx对比,立马就能比出性能高低。然而,如果你写一个实现公司内部业务的服务程序(比如分布式存储、搜索、微博、短网址),由于市面上没有同等功能的开源实现,你不需要在优化上投入全部精力,只要一版做得比一版好就行。先正确实现所需的功能,投入生产应用,然后再根据真实的负载情况来做优化,这恐怕比在编码阶段就盲目调优要更effective一些。
muduo的设计目标之一是吞吐量能让千兆以太网饱和,也就是每秒收发120MB数据。这个很容易就达到,不用任何特别的努力。
如果确实在内存带宽方面遇到问题,说明你做的应用实在太critical,或许应该考虑放到Linux kernel里边去,而不是在用户态尝试各种优化。毕竟只有把程序做到kernel里才能真正实现zero copy;否则,核心态和用户态之间始终是有一次内存拷贝的。如果放到kernel里还不能满足需求,那么要么自己写新的kernel,或者直接用FPGA或ASIC操作network adapter来实现你的“高性能服务器”。
7.5 一种自动反射消息类型的Protobuf网络传输方案
本节假定读者了解Google Protocol Buffers是什么,这不是一篇Protobuf入门教程。本节的示例代码位于examples/protobuf/codec。
本节要解决的问题是:通信双方在编译时就共享proto文件的情况下,接收方在收到Protobuf二进制数据流之后,如何自动创建具体类型的Protobuf Message对象,并用收到的数据填充该Message对象(即反序列化)。“自动”的意思是:当程序中新增一个Protobuf Message类型时,这部分代码不需要修改,不需要自己去注册消息类型。其实,Google Protobuf本身具有很强的反射(reflection)功能,可以根据type name创建具体类型的Message对象,我们直接利用即可。[注17:Protobuf C++库的反射能力不止于此,它可以在运行时读入并解析任意 proto文件,然后分析其对应的二进制数据。有兴趣的读者请参考王益的博客
http://cxwangyi.blogspot.com/2010/06/google-protocol-buffers-proto.html 。]
7.5.1 网络编程中使用Protobuf的两个先决条件
Google Protocol Buffers(简称Protobuf)是一款非常优秀的库,它定义了一种紧凑(compact,相对XML和JSON而言)的可扩展二进制消息格式,特别适合网络数据传输。
它为多种语言提供binding,大大方便了分布式程序的开发,让系统不再局限于用某一种语言来编写。
在网络编程中使用Protobuf需要解决以下两个问题。
1.长度,Protobuf打包的数据没有自带长度信息或终结符,需要由应用程序自己在发生和接收的时候做正确的切分。
2.类型,Protobuf打包的数据没有自带类型信息,需要由发送方把类型信息传给给接收方,接收方创建具体的Protobuf Message对象,再做反序列化。
Protobuf这么设计的原因见下一节。这里第一个问题很好解决,通常的做法是在每个消息前面加个固定长度的length header,例如§ 7.3中实现的LengthHeaderCodec。第二个问题其实也很好解决,Protobuf对此有内建的支持。但是奇怪的是,从网上简单搜索的情况看,我发现了很多“山寨”的做法。
“山寨”做法
以下均为在Protobuf data之前加上header,header中包含消息长度和类型信息。类型信息的“山寨”做法主要有两种:
● 在header中放int typeId,接收方用switch-case来选择对应的消息类型和处理函数;
● 在header中放string typeName,接收方用look-up table来选择对应的消息类型和处理函数。
这两种做法都有问题。
第一种做法要求保持typeId的唯一性,它和Protobuf message type一一对应。如果Protobuf message的使用范围不广,比如接收方和发送方都是自己维护的程序,那么typeId的唯一性不难保证,用版本管理工具即可。如果Protobuf message的使用范围很大,比如全公司都在用,而且不同部门开发的分布式程序可能相互通信,那么就需要一个公司内部的全局机构来分配typeId,每次增加新message type都要去注册一下,比较麻烦。
第二种做法稍好一点。typeName的唯一性比较好办,因为可以加上package name(也就是用message的fully qualified type name),各个部门事先分好namespace,不会冲突与重复。但是每次新增消息类型的时候都要去手工修改look-up table的初始化代码,也比较麻烦。
其实,不需要自己重新发明轮子,Protobuf本身已经自带了解决方案。
7.5.2 根据type name反射自动创建Message对象
Google Protobuf本身具有很强的反射(reflection)功能,可以根据type name创建具体类型的Message对象。但是奇怪的是,其官方教程里没有明确提及这个用法,我估计还有很多人不知道这个用法,所以觉得值得谈一谈。
以下是笔者绘制的Protobuf class diagram(见图7-25)。我估计大家通常关心和使用的是这个类图的左半部分:MessageLite、Message、Generated Message Types(Person、AddressBook)等,而较少注意到图7-25的右半部分:Descriptor、DescriptorPool、MessageFactory。
在图7-25中,起关键作用的是Descriptor class,每个具体Message type对应一个Descriptor对象。尽管我们没有直接调用它的函数,但是Descriptor在“根据type name创建具体类型的Message对象”中扮演了重要的角色,起了桥梁作用。图7-25中的←箭头描述了根据type name创建具体Message对象的过程,后文会详细介绍。
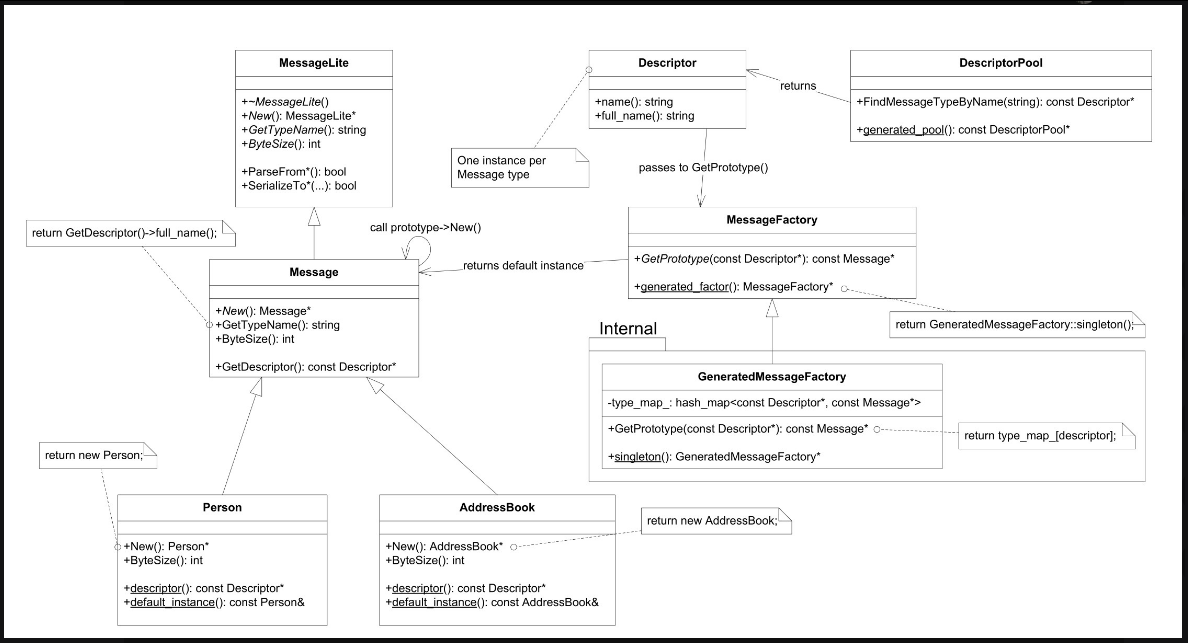
图7-25
原理简述
Protobuf Message class采用了Prototype pattern [注18:http://en.wikipedia.org/wiki/Prototype_pattern],Message class定义了New()虚函数,用以返回本对象的一份新实体,类型与本对象的真实类型相同。也就是说,拿到Message*指针,不用知道它的具体类型,就能创建和其类型一样的具体Message type的对象。
每个具体Message type都有一个default instance,可以通过Concrete-Message::default_instance()获得,也可以通过MessageFactory::GetPrototype(const Descriptor*)来获得。所以,现在问题转变为:1.如何拿到MessageFactory;2.如何拿到Descriptor*。
当然,ConcreteMessage::descriptor()返回了我们想要的Descriptor*,但是,在不知道ConcreteMessage的时候,如何调用它的静态成员函数呢?这似乎是个鸡与蛋的问题。
我们的英雄是DescriptorPool,它可以根据type name查到Descriptor*,只要找到合适的DescriptorPool,再调用DescriptorPool::FindMessageTypeByName(const string&type_name)即可。看到图7-25是不是眼前一亮?
在最终解决问题之前,先简单测试一下,看看我上面说得对不对。
验证思路
本文用于举例的proto文件:
package muduo;
message Query {required int64 id = 1;required string questioner = 2;repeated string question = 3;
}message Answer {required int64 id = 1;required string questioner = 2;required string answerer = 3;repeated string solution = 4;
}message Empty {optional int32 id = 1;
}其中的Query.questioner和Answer.answerer是§ 9.4提到的“分布式系统中的进程标识”。
以下代码[注19:recipes/protobuf/descriptor_test.cc]验证ConcreteMessage::default_instance()、ConcreteMessage::descriptor()、MessageFactory::GetPrototype()、DescriptorPool::FindMessage-TypeByName()之间的不变式(invariant),注意其中的assert:
typedef muduo::Query T;std::string type_name = T::descriptor()->full_name();
cout << type_name << endl;
const Descriptor* descriptor=DescriptorPool::generated_pool()->FindMessageTypeByName(type_name);
assert(descriptor ==T::descriptor());
cout << "FindMessageTypeByName()=" << descriptor << endl;
cout << "T::descriptor()" << T::descriptor() << endl;
cout<< endl;const Message* prototype=MessageFactory::generated_factory()->GetPrototype(descriptor);
assert(prototype ==&T::default_instance());
cout << "GetPrototype() =" << prototype<<endl;
cout << T::default_instance()=" << &T::default instance()<< endl;
cout<< endl;T* new_obj = dynamic_cast<T*>(prototype->New());
assert(new_obj != NULL);
assert(new_obj != prototype);
assert(typeid(*new_obj)== typeid(T::default_instance()));
cout<<"prototype->New()="<< new_obj << endl;
cout<< endl;
delete new_obj;程序运行结果如下:

根据type name自动创建Message的关键代码
好了,万事俱备,开始行动:
1.用DescriptorPool::generated_pool()找到一个DescriptorPool对象,它包含了程序编译的时候所链接的全部Protobuf Message types。
2.根据type name用DescriptorPool::FindMessageTypeByName()查找Descriptor。
3.再用MessageFactory::generated_factory()找到MessageFactory对象,它能创建程序编译的时候所链接的全部Protobuf Message types。
4.然后,用MessageFactory::GetPrototype()找到具体Message type的default instance。
5.最后,用prototype->New()创建对象。
示例代码如下。
Message* createMessage(const std::string& typeName)
{Message *message = NULL;const Descriptor* descriptor= DescriptorPool::generated_pool()->FindMessageTypeByName(typeName);if(descriptor){const Message* prototypeMessageFactory::generated_factory()->GetPrototyped(descriptor);if(prototype){message = prototype->New();}}return message;
}调用方式:
Message* newQuery = createMessage("muduo.Query");
assert(newQuery != NULL);
assert(typedid(*newQuery) == typedid(muduo::Query::default_instance()));
cout << "createMessage(\"muduo.Query\") = " << newQuery << endl;确实能从消息名称创建消息对象,古之人不余欺也:-)
注意,createMessage()返回的是动态创建的对象的指针,调用方有责任释放它,不然就会使内存泄漏。在muduo里,我用shared_ptr<Message>来自动管理Message对象的生命期。
拿到Message*之后怎么办呢?怎么调用这个具体消息类型的处理函数?这就需要消息分发器(dispatcher)出马了,且听下回分解。
线程安全性
Google的文档说,我们用到的那几个MessageFactory和DescriptorPool都是线程安全的,Message::New()也是线程安全的。并且它们都是const member function。关键问题解决了,那么剩下的工作就是设计一种包含长度和消息类型的Protobuf传输格式。
7.5.3 Protobuf传输格式
笔者设计了一个简单的格式,包含Protobuf data和其对应的长度与类型信息,消息的末尾还有一个check sum。格式如图7-26所示,图中方块的宽度是32-bit。
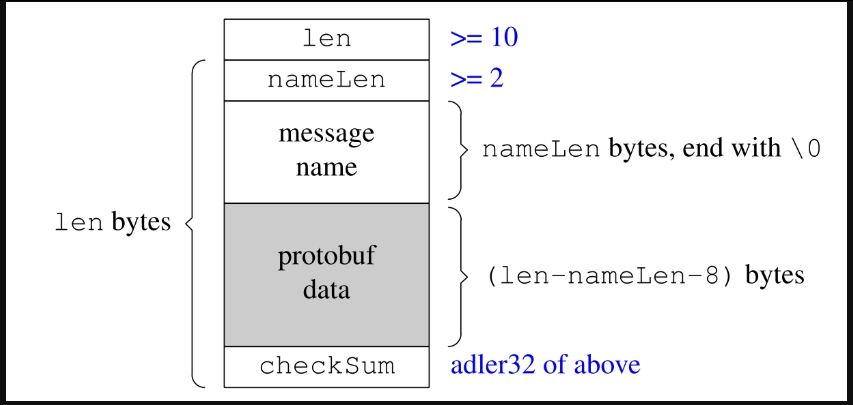
图7-26
用C struct伪代码描述:
struct ProtobufTransportFormat __attribute__ ((__packed__))
{int32_t len;int32_t nameLen;char typeName[nameLen];char protobufData[len-nameLen-8];int32_t checkSum; // adler32 of namelen, typeName and protobufData
};注意,这个格式不要求32-bit对齐,我们的decoder会自动处理非对齐的消息。
例子
用这个格式打包一个muduo.Query对象的结果如图7-27所示。
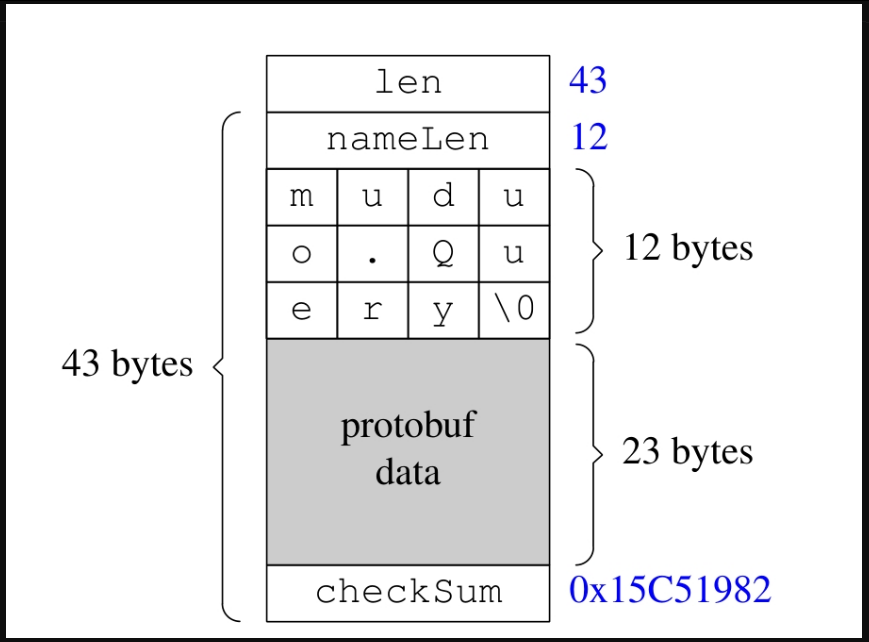
图7-27
设计决策
以下是我在设计这个传输格式时的考虑:
● signed int。消息中的长度字段只使用了signed 32-bit int,而没有使用unsigned int,这是为了跨语言移植性,因为Java语言没有unsigned类型。另外,Protobuf一般用于打包小于1MB的数据,unsigned int也没用。
● check sum。虽然TCP是可靠传输协议,虽然Ethernet有CRC-32校验,但是网络传输必须要考虑数据损坏的情况,对于关键的网络应用,check sum是必不可少的。见§A.1.13“TCP的可靠性有多高”。对于Protobuf这种紧凑的二进制格式而言,肉眼看不出数据有没有问题,需要用check sum。
● adler32算法。我没有选用常见的CRC-32,而是选用了adler32,因为它的计算量小、速度比较快,强度和CRC-32差不多。另外,zlib和java.unit.zip都直接支持这个算法,不用我们自己实现。
● type name以'\0'结束。这是为了方便troubleshooting,比如通过tcpdump抓下来的包可以用肉眼很容易看出type name,而不用根据nameLen去一个个数字节。同时,为了方便接收方处理,加入了nameLen,节省了strlen(),这是以空间换时间的做法。
● 没有版本号。Protobuf Message的一个突出优点是用optional fields来避免协议的版本号(凡是在Protobuf Message里放版本号的人都没有理解Protobuf的设计,甚至可能没有仔细阅读Protobuf的文档[注20:http://code.google.com/apis/protocolbuffers/docs/overview.html "A bit ofhistory"][注21:http://code.google.com/apis/protocolbuffers/docs/proto.html#updating][注22:http://code.google.com/apis/protocolbuffers/docs/cpptutorial.html “Extending a Protocol Buffer"]),让通信双方的程序能各自升级,便于系统演化。如果我设计的这个传输格式又把版本号加进去,那就画蛇添足了。

Protobuf可谓是网络协议格式的典范,值得我单独花一节篇幅讲述其思想,见§ 9.6.1“可扩展的消息格式”。