NVIDIA大模型推理框架:TensorRT-LLM软件流程(一)
背景
TensorRT-LLM介绍
NVIDIA TensorRT™ LLM is an open-source library built to deliver high-performance, real-time inference optimization for large language models (LLMs) on NVIDIA GPUs—whether on a desktop or in a data center. It includes a modular Python runtime, PyTorch-native model authoring, and a stable production API. Specifically customized for NVIDIA platforms, TensorRT LLM helps developers maximize inference performance to serve more users in parallel, while minimizing operational costs and delivering blazingly fast experiences.
- TensorRT-LLM 推理框架对于NVIDIA 显卡目前应该是运行大模型推理最快的。
- 本人一直是聚焦车载嵌入式方向的,目前都是使用Drive AGX Orin芯片,所以也是想到直接使用NV官方出品在部署端侧大模型,目前是使用5060Ti 16G硬件来部署的。
- 官方给出的教程介绍都是总体的架构,没有对各个部分流程详细的介绍。
- 所以这篇博客的目的,就是通过trtllm-serve启动部署大模型推理框架Server端作为切入点,对整个TensorRT-LLM推理引擎的启动、加载模型文件、接收推理请求并且给出推理结构的整个流程,给出代码层面的详细梳理!
源码安装流程
- 因为是需要修改代码进行调试的,所以安装方式使用源码安装,具体可以参考build-from-source-linux
- 这里主要介绍一些编译错误怎么解决。
- 首先推荐使用官方指示的Docker Container来编译源码,因为环境配置真的很复杂,容易把你的系统搞崩,不要这么干。就是编译Docker image 在国内需要修改Dockerfile换源或者是提前下载,然后copy到Docker根目录。
REPOSITORY TAG IMAGE ID CREATED SIZE
tensorrt_llm/devel latest f841355f55b0 2 weeks ago 37GB
- Docker image大小有37G,确实搞不定,留言,想办法直接把Docker image tar file提供给你。
python3 ./scripts/build_wheel.py
- 运行build_wheel.py脚本,然后会先编译python库、C++库、再把python库打包为tensorrt_llm*.whl安装包,然后直接pip安装就行。
- 流程是没问题的,但是因为默认会从github上面下载DEEP_EP、DEEP_GEMM、googletest等库,没有科学上网就会下载卡主然后报错,如下图所示:
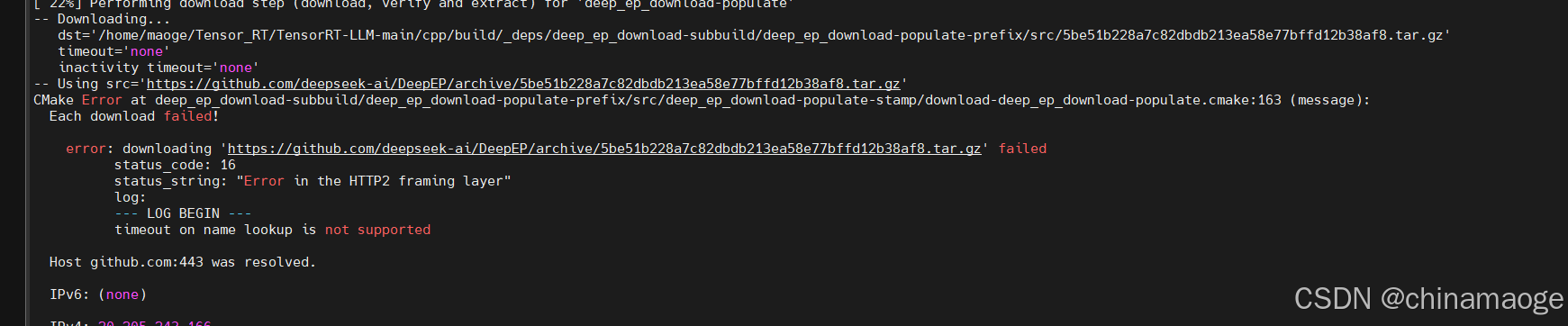
- 建议在cmake的时候把这些参数都设置为OFF,个人开发者,单个GPU运行推理模型是用不上这些库的。
// cmake命令,设置参数OFF
cmake -DCMAKE_BUILD_TYPE="Release" -DBUILD_PYT="ON" -DBUILD_DEEP_EP="OFF" -DBUILD_DEEP_GEMM="OFF" -DNVTX_DISABLE="ON" -DBUILD_TESTS="OFF" -DENABLE_UCX="OFF"//参数介绍:
DeepEP::优化大模型推理中的专家并行(Expert Parallelism)和计算效率,主要针对多 GPU 分布式场景(如 MoE 模型)。
DeepGEMM:提供特定场景下的 GEMM(矩阵乘法)优化内核,主要针对大模型高性能计算需求。
googletest测试组件:包含单元测试、集成测试等验证代码,依赖googletest框架,用于开发阶段验证功能正确性。
UCX:提供高性能分布式通信支持(如多机多卡间的数据传输),依赖rapids-cmake等分布式库。
CMakeLists.txt 没找到
- 如果第一次python3 ./scripts/build_wheel.py执行上述失败,再次执行python命令就会出现下面报错。
make: *** No targets specified and no makefile found. Stop.
CMake Error: The source directory "/**/Tensor_RT/TensorRT-LLM-main" does not appear to contain CMakeLists.txt.
-
这是因为第一次python3 执行错误,并没有生成makefile,所以直接build就会失败。加上上面参数设置直接执行cmake命令,然后再make -j6就可以了。
-
还有一种情况就是Makefile文件生成位置不是在默认的cpp/build路径,使用–build_dir参数设置
-
C++ 代码编译完会是下图这样:
-
电脑是8代i5编译了差不多一晚上,非常耗时。如果是新手建议checkout 到release/1.1.0rc3 branch,毕竟是release branch编译不会报错,如果是使用Master分支极小可能会编译报错,我遇到过一次。
-
C++ 编译完之后在链接中下载对应version package,直接安装 tensorrt-llm python package
-
以后有时间再慢慢解决上面的下载问题
version 查看文件:\TensorRT-LLM-main\tensorrt_llm\version.py# SPDX-FileCopyrightText: Copyright (c) 2022-2025 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
# SPDX-License-Identifier: Apache-2.0
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
__version__ = "1.2.0rc1"
Contribution
- 才开始调试TensorRT-LLM代码就遇到一个代码流程问题。修改提交pull request,并且merge到main branch,显摆一下:Merge Request:Fix the error where checkpoint_dir is assigned as NONE
TensorRT-LLM 代码流程
总体架构
- 安装成功之后一般是运行run.py文件进行测试,但是实际项目都是作为Server端提供HTTP服务形式存在的,所以介绍trtllm-serve启动流程。
- 整体架构图如下:
还没画完 - TensorRT-LLM提供两种模型类型的运行方式,一种是HF原生模型基于PyTorch backen,一种是深度优化过的engine格式模型基于TensorRT backen。聚焦于端侧高性能部署所以接下来的介绍都是engine格式,基于TensorRT backen的架构介绍,不涉及HF原生模型PyTorch代码部分。
- 模型是使用Qwen-7B-Chat,深度优化为.engine格式来使用,具体可以看:examples\models\core\qwen\README.md
trtllm-serve启动流程–python Layer
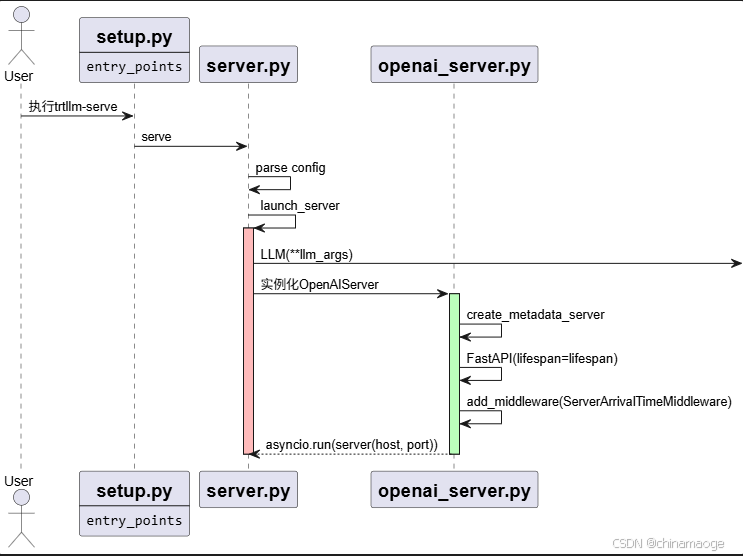
1. 创建openai server
- 终端输入的trtllm-serve命令执行运行,并不是使用bin文件执行的。而是通过entry_points映射实现的, entry_points机制是通过 setuptools 实现的命令行工具注册方式,允许将 Python 函数或模块与终端命令绑定,使得用户可以直接通过命令行调用 Python 代码。
trtllm-serve \Qwen3-30B-A3B/ \--host localhost \--port 8000 \--max_batch_size 161 \--max_num_tokens 1160 \--tp_size 1 \--ep_size 1 \--pp_size 1 \--kv_cache_free_gpu_memory_fraction 0.8 \--extra_llm_api_options ./extra-llm-api-config.yml#setup.py
entry_points={'console_scripts': ['trtllm-serve=tensorrt_llm.commands.serve:main',],
},
- 真正执行代码是在server.py文件 serve function,其中执行launch_server 就对使用的backend进行分类,我执行实例化的是tensorrt,所以创建_TrtLLM class 实例。
- 实例化OpenAIServer作为http Server使用接收http消息,init函数中有各种初始化操作。
## TensorRT-LLM-main\tensorrt_llm\commands\serve.py
main = DefaultGroup(commands={"serve": serve,"disaggregated": disaggregated,"disaggregated_mpi_worker": disaggregated_mpi_worker,"mm_embedding_serve": serve_encoder})
openai server创建流程图:
2. LLM 初始化–class _TrtLLM创建
- LLM(**llm_args)函数会实例化class _TrtLLM,先执行class BaseLLM init。
- 因为选择TensorRT backend,所以instantiate class TrtLlmArgs, 其中是对从模型构建、并行计算、量化优化到推理策略的全流程参数配置初始化,真正的参数赋值在llm_args_cls.from_kwargs function。
- 最后执行class _TrtLLM _build_model function,首先调用父类 class BaseLLM _build_model function。
- 初始化class CachedModelLoader之后,通过model_loader()调用call function,model_format就是设置的TLLM_ENGINE,所以直接返回engine和hf_model dir,后者为NONE。
- 之后调用C++ Layer tllm.ExecutorConfig初始化executor config 中间通过pybind11作为桥梁。
- 后续一些配置加载和参数初始化,然后通过_executor_cls.create调用到class GenerationExecutor create function中开始真正创建推理大模型engine。
流程图:

3. LLM 初始化–GenerationExecutor
- 这里从TensorRT-LLM 架构中的API Layer进入Runtime Layer,GenerationExecutor功能模块
- class _TrtLLM _build_model function 执行self._executor_cls.create调用到class GenerationExecutor staticmethod create。
- 构建worker_kwargs参数,然后调用_create_ipc_executor创建出GenerationExecutorProxy instance
- 因为instantiate GenerationExecutorProxy 没有传入worker_cls参数,所以默认为GenerationExecutorWorker对象
- GenerationExecutorProxy 创建一开始会执行GenerationExecutor init,其中有个关键函数是对shutdown function在atexit组件中注册。在程序正常退出时触发shutdown处理:1.abort all requests 2.notify the background threads to quit 3.close all the sockets。
- 创建MpiPoolSession用来GPU多进程之间通信,然后调用mpi_session.submit把worker_main任务发送到Mpi Process Pool中处理。
- 但是由mpi4py.futures.server进程执行,并没有使用Client子进程执行,因为创建MPIPoolExecutor(max_workers=self.n_workers, path=sys.path) 参数n_workers设置为1,只创建出Server进程同时协调和执行任务。
- 最后就是poll循环等待工作进程消息,正常情况是一直保活。
self.mpi_futures = self.mpi_session.submit(worker_main,**worker_kwargs,worker_cls=self.worker_cls,tracer_init_kwargs=tracer_init_kwargs,_torch_model_class_mapping=MODEL_CLASS_MAPPING,ready_signal=GenerationExecutorProxy.READY_SIGNAL,)
流程图:

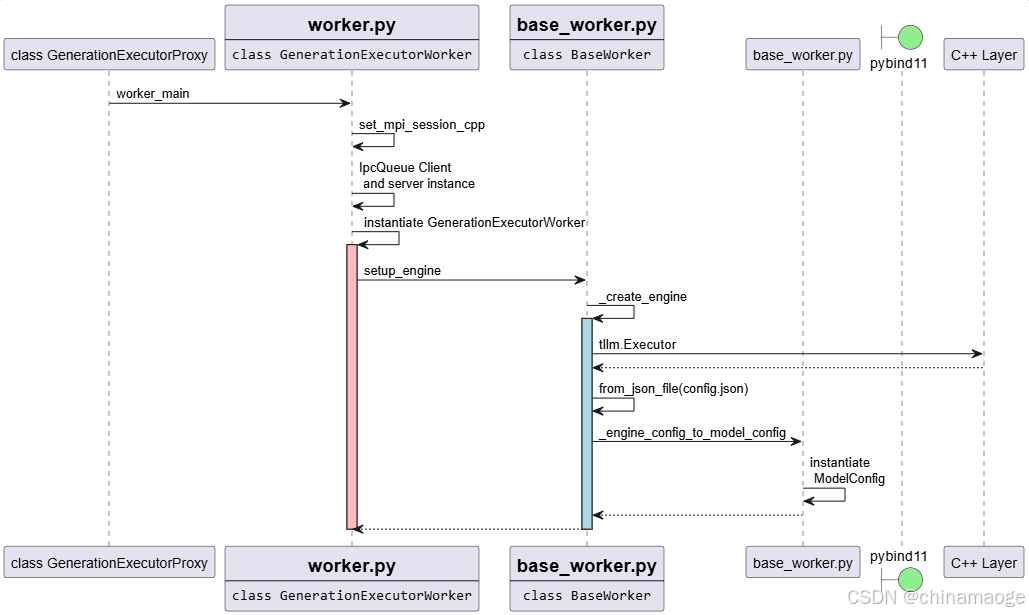
4. LLM 初始化–Executor Worker
- worker_main创建request_queue、worker_init_status_queue、mp_stats_queue、kv_cache_events_queue为IpcQueue instance Client发送IPC消息,result_queues instantiate FusedIpcQueue server接收IPC消息。
- 实例化class GenerationExecutorWorker,其中连续实例化父类class BaseWorker and class GenerationExecutor。
- 执行setup_engine function中,因为设置TensorRT backen 所以执行_create_engine。
- 通过tllm ExecutorConfig、LogitsPostProcessorConfig、ParallelConfig对config进行赋值,最重要是通过tllm.Executor调用到C++ Layer Executor启动推理引擎
- 从engine dir 中读取config.json文件的配置对model config进行赋值。
- 最后instantiate class ModelConfig
流程图:
C++ 部分单开一篇博客来写。。。内容太多了
参考资料
- developer.nvidia.com
- build-from-source-linux
- TensorRT LLM 1.0 正式上线
- TensorRT-LLM code