权威机构统计的 AI 编程模型排名
1. 排行榜一览:谁更强?
1.1 来自 Vellum AI 的 “Best LLM for Coding” 排行
根据 Vellum AI 公布的数据,以下为 2025 年 9 月整理出的「编程任务表现最强模型」列表:
| 排名 | 模型名称 | 得分/说明 |
|---|---|---|
| 第1位 | GPT‑5 | 得分 88;在“Coding LLM Leaderboard”中位列首位。 (Vellum AI) |
| 第2位 | Gemini 2.5 Pro | 得分 82.2。 (Vellum AI) |
| 第3位 | OpenAI o3 | 得分 81.3。 (Vellum AI) |
1.2 来自 OpenRouter 的 “Programming LLM Rankings” (导航使用量 + 令牌数统计)
另一维度由 OpenRouter 提供,其更偏向「模型被调用量/代码相关令牌数」的排行:
- 第1位:Grok Code Fast 1(由 x‑AI 发布),令牌数 1.06 万亿。 (OpenRouter)
- 第2位:Claude Sonnet 4.5(由 Anthropic 发布) 2.61 千亿。 (OpenRouter)
- 第3位:Claude 4 7.98 百亿。 (OpenRouter)
1.3 来自 AI Multiple 的 “AI Coding Benchmark” 分析
AI Multiple 在其网站中也对多个 AI 编程工具做了分析,指出像 Amazon Q Developer、GitLab AI、Replit AI 在编程助理任务中表现领先。 (AIMultiple)
2. 模型亮点详解
下面列出几款在编程任务中表现尤为突出的模型,并分析其特点。
2.1 GPT-5
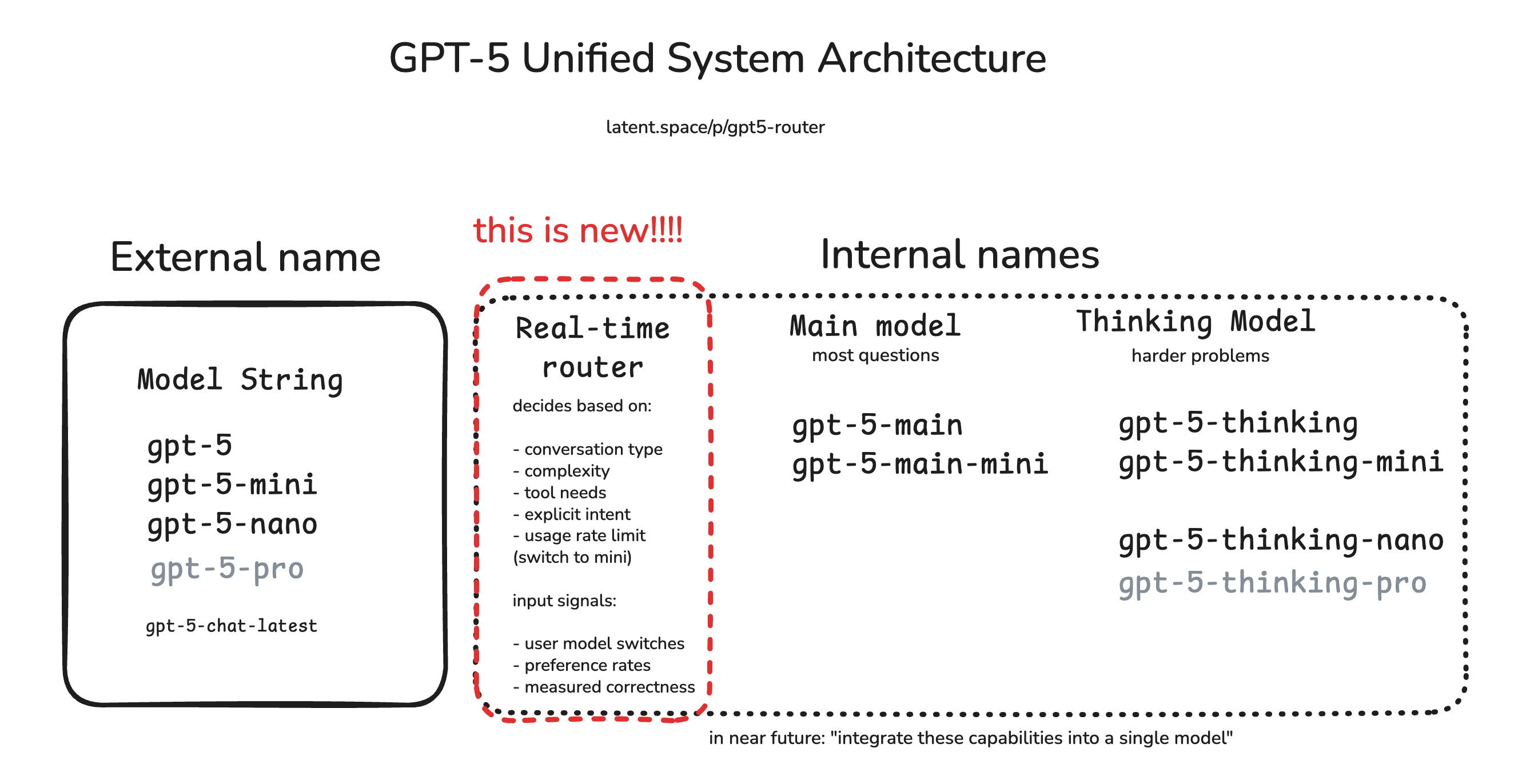



- 在 Vellum 的排行榜中得分最高,为 88 分。 (Vellum AI)
- 说明:作为 OpenAI 最新一代模型,GPT-5 在多语言、多范式编程任务中,生成能力与理解代码能力均有显著提升。
- 值得注意:得分虽高,但数据来源与评测覆盖可能仍然有局限(例如多语言 vs. 专语言、自动化 vs. 人工评测)。
- 提示:若希望部署或使用 GPT-5进行编程任务,建议先在自己的代码库或环境中进行实测,因为“排行榜第一” ≠ “适合所有场景”。
2.2 Gemini 2.5 Pro
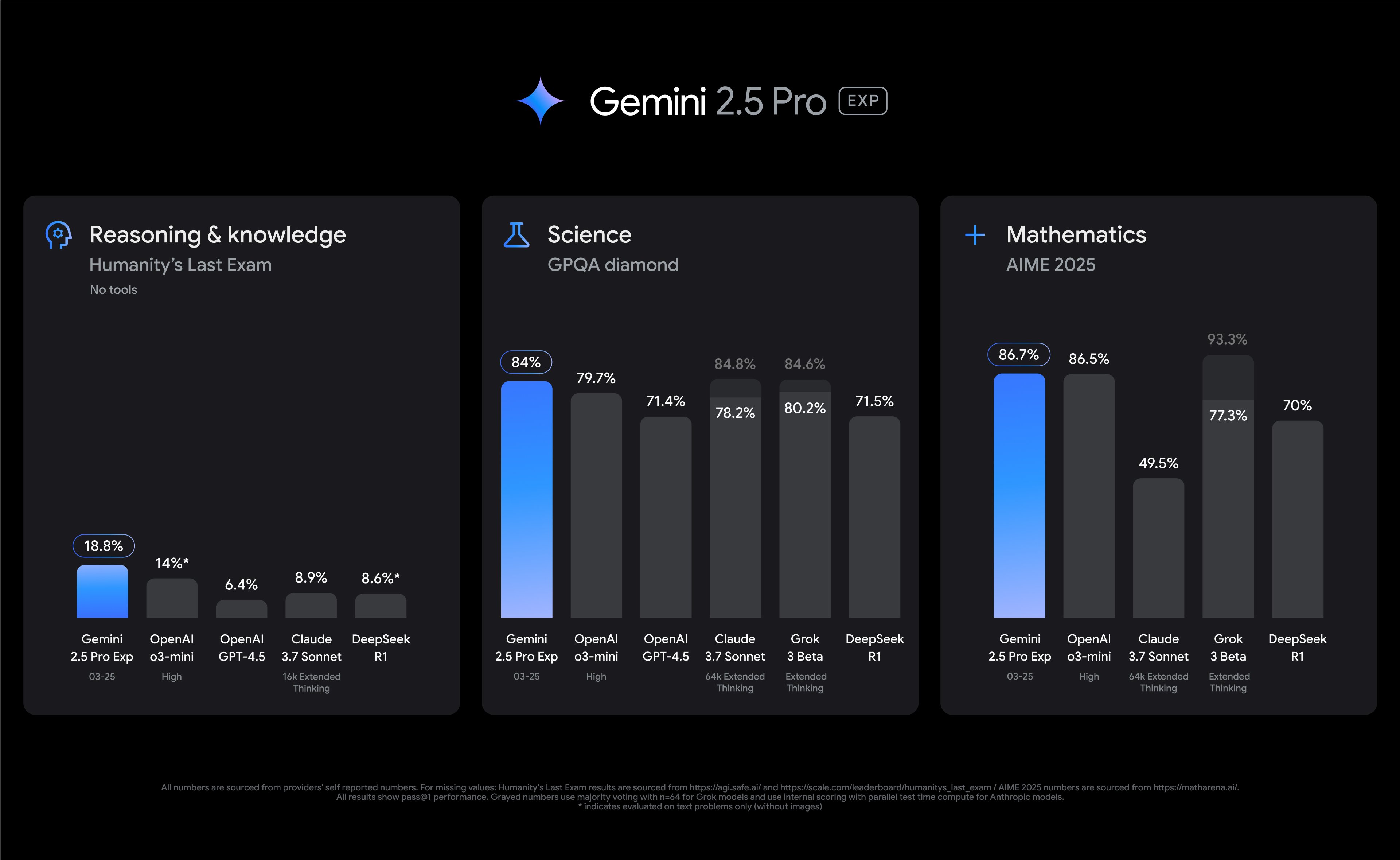

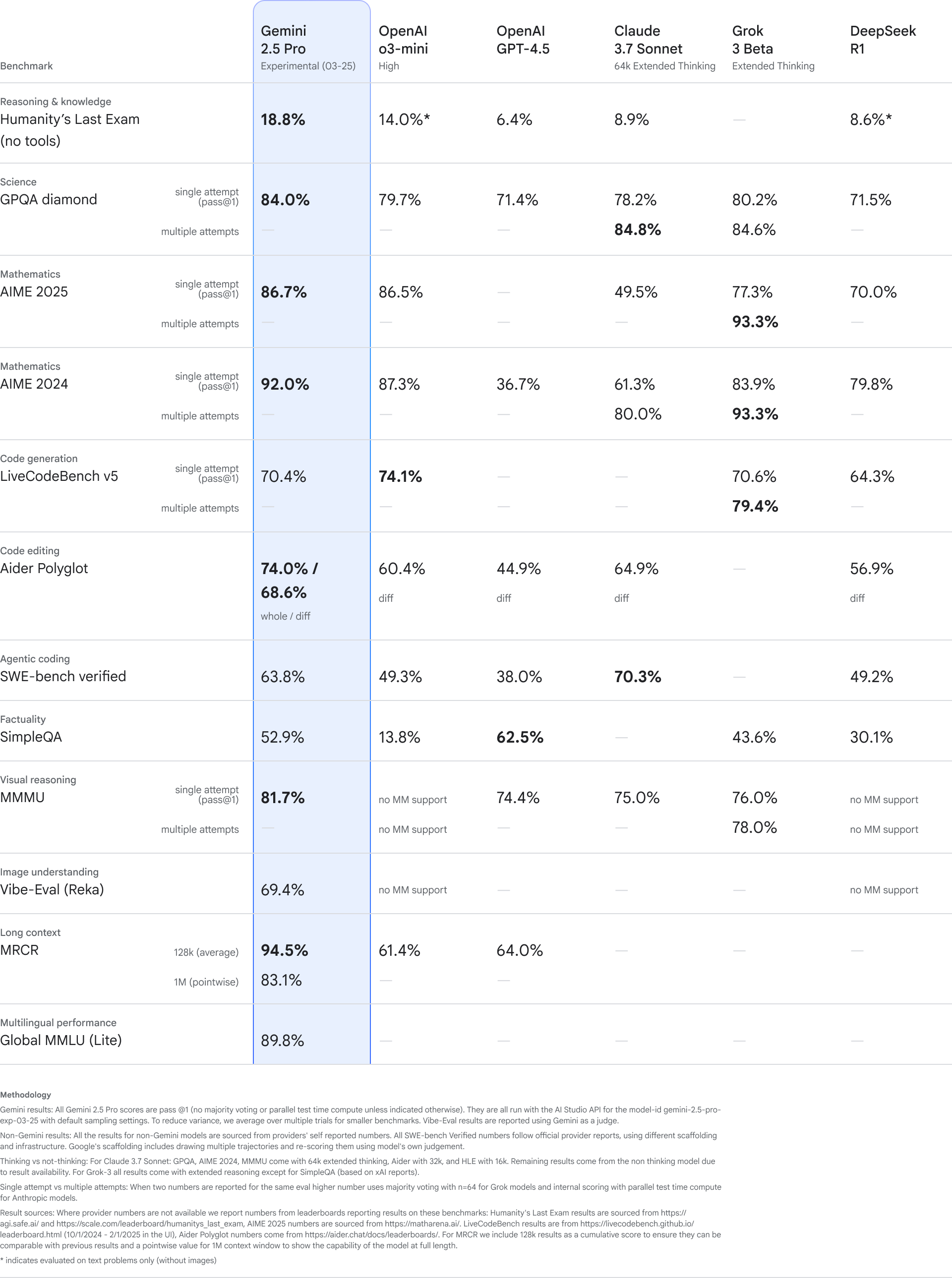


- 得分约为 82.2 分,在 Vellum 排行中位列第二。 (Vellum AI)
- 背景:由 Google 发布,其在跨语言、跨工具的编程任务上具备优势。
- 特点:在适应多任务、多语言且与 Google 其他产品(如 Cloud、Vertex AI)整合方面可能更为便利。
- 提示:如果您的项目偏向使用 Google 生态(例如 Cloud、Android、TensorFlow 相关),Gemini 2.5 Pro 是值得重点关注的选择。
2.3 Claude Sonnet 4.5
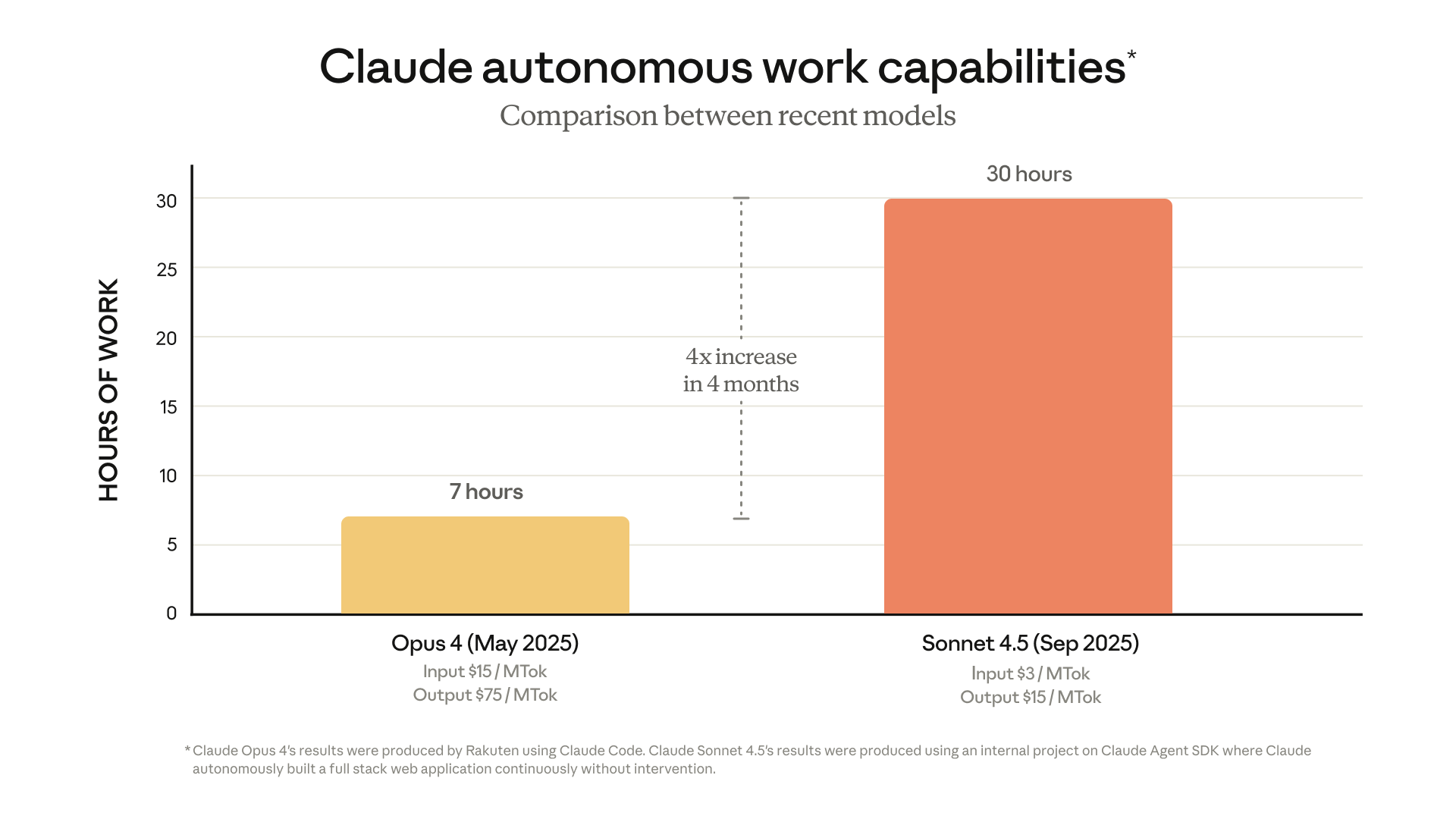

- 在 OpenRouter 的“代码代理模型调用”排行中排名第二,显示其被大量用作编程任务模型。 (OpenRouter)
- 发布公司 Anthropic 在其新闻中声称,该模型为“全球最佳编程模型”。 (The Times of India)
- 特点:强调“agentic coding”(即模型不仅生成代码,还能够理解、调试、甚至自主执行多步骤任务)。
- 提示:对高复杂性、长期任务(如大型项目、持续迭代)感兴趣的开发团队,可以考虑 Claude Sonnet 4.5 的集成。
3. 排行背后的评测基准与意义
3.1 常见的编程任务基准
- “SWE‐Bench”:用于衡量模型是否能够解决真实软件工程任务(如 GitHub issue、bug 修复、需求转换)—Vellum 提及该项。 (Vellum AI)
- “LiveBench”:更偏向综合能力评测,在其榜单中列出若干模型在代码任务中的得分。 (livebench.ai)
- “HumanEval-X”:多语言代码生成基准,由学术界提出,用于评价模型在多语言编程环境下的表现。 (arXiv)
3.2 为什么这些排行榜值得关注?
- 选择依据:开发者或企业在选型 LLM 时,不只是看“通用能力”,更在意“编程任务表现”,这类排行榜提供了量化参考。
- 趋势指引:从排行榜可见,模型间差距正逐渐缩小,“编码专用模型”/“agent 模型”愈加受重视。
- 实践警示:尽管模型排名优异,但不同场景(语言、框架、项目复杂度)表现可能差异极大。排行榜只是参考,实测仍必需。