【AI论文】MM-HELIX:借助整体式平台与自适应混合策略优化,提升多模态长链反思推理能力
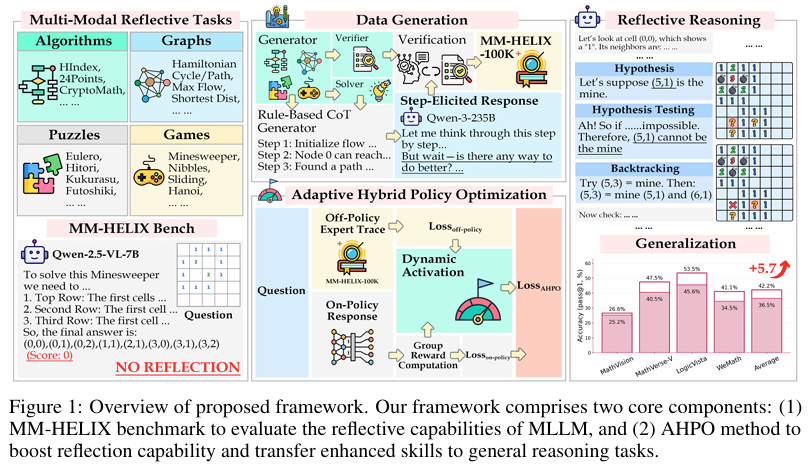
摘要:当前,多模态大语言模型(Multimodal Large Language Models, MLLMs)已在数学、逻辑等推理任务中展现出较强能力,但其在解决复杂现实问题所必需的长链反思推理能力方面,仍存在大量未被探索的领域。在本研究中,我们首先开展了一项广泛的实证调查,以评估这一能力。借助精心设计的数据合成引擎,我们构建了MM-HELIX多模态基准测试集,该测试集包含1260个样本,涉及42个极具挑战性的合成任务,这些任务需要迭代思考和回溯推理。在此基准测试集上的实证结果表明,现有MLLMs在长链反思推理方面存在显著的性能缺陷。为解决这一局限,我们生成了后训练数据,并进一步探索了利用此类数据的学习范式。我们首先开发了“步骤引导响应生成”流程,以创建MM-HELIX-100K这一大规模数据集,其中包含10万个高质量反思推理轨迹,用于指令微调阶段。鉴于标准强化学习在复杂任务中因奖励信号稀疏和监督微调后的灾难性遗忘问题而表现不佳,我们提出了自适应混合策略优化(Adaptive Hybrid Policy Optimization, AHPO)这一新型训练策略,该策略将离线监督和在线优化动态统一为一个阶段。此策略使模型能够在奖励稀疏时从专家数据中学习,并在熟练后进行独立探索。当应用于Qwen2.5-VL-7B基线模型时,我们的方法在MM-HELIX基准测试集上实现了+18.6%的准确率提升,并在一般数学和逻辑任务上表现出较强的泛化能力,平均性能提升+5.7%。我们的研究表明,MLLMs中的反思推理能力可以有效学习并泛化,为开发更具能力的MLLMs铺平了道路。Huggingface链接:Paper page,论文链接:2510.08540
研究背景和目的
研究背景:
随着人工智能技术的迅猛发展,多模态大型语言模型(Multimodal Large Language Models, MLLMs)在多个领域展现出了强大的能力,包括数学推理、逻辑推断以及视觉感知等。然而,尽管这些模型在单步推理任务中表现优异,但在需要长链反思性推理(long-chain reflective reasoning)的复杂现实问题中,其表现仍不尽如人意。长链反思性推理是一种涉及迭代思考、试错和修正的复杂认知过程,对于解决现实世界中的复杂问题至关重要。
例如,在科学实验设计、复杂系统调试或战略规划等任务中,模型需要具备自我修正和迭代优化的能力。
现有的MLLMs大多设计为一次性生成输出,缺乏内在的自我修正和迭代优化机制。
尽管一些研究通过引入链式思考(Chain-of-Thought, CoT)或多步推理策略来提升模型的推理能力,但这些方法往往依赖于固定的推理模板或外部监督信号,难以应对真实世界中复杂多变的任务需求。此外,标准强化学习(Reinforcement Learning, RL)方法在处理复杂任务时,常因奖励信号稀疏或灾难性遗忘等问题而表现不佳。因此,如何提升MLLMs的长链反思性推理能力,成为当前研究的重要课题。
研究目的:
本研究旨在通过构建一个专门用于评估MLLMs长链反思性推理能力的基准测试集(MM-HELIX),并探索一种结合离线监督和在线优化的自适应混合策略优化方法(Adaptive Hybrid Policy Optimization, AHPO),来提升MLLMs在复杂任务中的反思性推理能力。
具体目标包括:
- 评估现有MLLMs的长链反思性推理能力:通过构建MM-HELIX基准测试集,全面评估现有MLLMs在复杂多模态任务中的反思性推理能力,揭示其存在的不足。
- 提升MLLMs的反思性推理能力:通过生成大规模的高质量反思性推理训练数据,并利用AHPO方法进行训练,使模型能够从专家数据中学习并在熟练后进行独立探索,从而提升其反思性推理能力。
- 验证方法的泛化能力:通过在不同类型的复杂任务中验证AHPO方法的有效性,展示其在提升MLLMs反思性推理能力方面的泛化潜力。
研究方法
1. MM-HELIX基准测试集构建:
MM-HELIX是一个包含1,260个样本的多模态基准测试集,涵盖了算法、图形、谜题和游戏四大类共42个具有挑战性的合成任务。
每个任务要求模型进行仔细的视觉观察、深入理解复杂规则,并生成包含反思和回溯的长链思考过程。测试集通过规则生成代码、求解器和验证器三个模块构建,确保了任务的高质量和多样性。具体步骤包括:
- 规则生成:使用规则生成代码创建具有不同难度级别的多模态问题。
- 求解与验证:利用求解器生成问题的正确答案,并通过验证器验证模型输出的正确性。
- 难度分级:通过调整任务参数,生成五个难度级别的问题,以全面评估模型的能力。
2. 自适应混合策略优化(AHPO)方法:
AHPO是一种结合离线监督和在线优化的自适应训练策略,旨在解决标准强化学习在处理复杂任务时面临的奖励信号稀疏和灾难性遗忘问题。
具体步骤包括:
- 离线监督阶段:利用大规模的高质量反思性推理训练数据(MM-HELIX-100K)进行监督学习,使模型初步掌握反思性推理的基本模式。
- 在线优化阶段:在模型具备一定基础后,切换到强化学习模式,通过动态调整离线专家数据的利用比例,引导模型进行独立探索。具体来说,当模型在某任务上表现不佳时(即奖励稀疏),增加离线专家数据的利用比例;当模型逐渐熟练时,减少离线数据的利用,鼓励模型自主探索。
- 动态调整机制:通过引入激活系数ξ,动态调整离线损失和在线损失的权重,实现离线监督和在线优化的平滑过渡。
研究结果
1. MM-HELIX基准测试结果:
在MM-HELIX基准测试集上,现有MLLMs的表现普遍较差。
例如,即使是性能最好的专有模型GPT-5,其准确率也仅为58.1%,而其他模型的表现则更低。这表明现有MLLMs在长链反思性推理任务中存在显著不足。
2. AHPO方法的有效性:
通过应用AHPO方法,模型在MM-HELIX基准测试集上的表现显著提升。
例如,基于Qwen2.5-VL-7B基线模型,AHPO方法实现了18.6%的准确率提升,并在一般数学和逻辑任务中展现出5.7%的平均性能提升。这表明AHPO方法能够有效提升MLLMs的反思性推理能力。
3. 泛化能力验证:
在不同类型的复杂任务中,AHPO方法均表现出良好的泛化能力。例如,在数学和逻辑推理任务中,经过AHPO训练的模型能够显著优于仅使用监督微调或标准强化学习的模型。这表明AHPO方法不仅适用于MM-HELIX基准测试集中的任务,还能够泛化到其他类型的复杂任务中。
研究局限
尽管本研究在提升MLLMs的长链反思性推理能力方面取得了显著进展,但仍存在一些局限性:
1. 数据生成的效率和质量:
尽管本研究提出了Step-Elicited Response Generation (SERG)管道来生成大规模的高质量反思性推理训练数据,但数据生成过程仍较为耗时且成本较高。未来需要探索更高效的数据生成方法,以降低训练成本。
2. 复杂任务的覆盖范围:
MM-HELIX基准测试集虽然涵盖了多种类型的复杂任务,但仍可能无法完全覆盖现实世界中的所有复杂场景。
未来需要进一步扩展基准测试集的任务类型和难度级别,以更全面地评估模型的反思性推理能力。
3. 模型的可解释性:
尽管AHPO方法能够提升模型的反思性推理能力,但模型在推理过程中的具体思考路径和决策依据仍不够透明。
未来需要探索更有效的模型可解释性方法,以揭示模型在反思性推理过程中的内在机制。
未来研究方向
针对上述局限,未来的研究可以从以下几个方面展开:
1. 高效数据生成方法:
探索更高效的数据生成方法,如利用生成对抗网络(GANs)或自回归模型来自动生成高质量的反思性推理训练数据。
这将有助于降低训练成本并提高训练效率。
2. 扩展基准测试集:
进一步扩展MM-HELIX基准测试集的任务类型和难度级别,以更全面地评估模型的反思性推理能力。
同时,可以引入更多真实世界中的复杂任务,以检验模型在实际应用中的表现。
3. 提升模型可解释性:
研究更有效的模型可解释性方法,如引入注意力机制或可视化工具来揭示模型在反思性推理过程中的思考路径和决策依据。这将有助于理解模型的内在机制并优化其性能。
4. 跨模态反思性推理:
探索跨模态反思性推理方法,使模型能够在不同模态之间进行有效的信息交互和反思性推理。这将有助于提升模型在处理复杂多模态任务时的能力和灵活性。
5. 持续学习与自适应优化:
研究持续学习与自适应优化方法,使模型能够在不断变化的环境中持续学习和优化其反思性推理能力。
这将有助于提升模型的适应性和鲁棒性,使其能够更好地应对现实世界中的复杂挑战。