C语言基础知识回顾
预处理、编译、汇编、链接
预处理阶段:该阶段会进行宏替换,展开头文件,去掉注释、条件编译的操作,该阶段结束后会生成.i文件
编译:将高级语言翻译为汇编语言,该阶段结束后会生成.s文件,汇编代码
汇编:将汇编语言翻译为机器语言,该阶段结束后会生成.o文件,二进制代码
链接:该阶段会将函数声明与实现进行链接,生成可执行文件,该阶段结束后会生成.exe文件
基本数据类型的空间大小
char:8位,1个字节
short:16位,2个字节
int:32位,4个字节
long:32位,4个字节
float:32位,4个字节
浮点数的表示方式:
符号位(第 31 位)指数位(第 30-23 位) 尾数位(第 22-0 位)
double:64位,8个字节
long long:64位,8个字节
指针:32位机器下,不管是什么类型的指针,大小都是4字节
各类型的范围在这里就不过多解释了,一般弄清楚各个数据多少位就自然能计算出范围了。
结构体与联合体的对齐方式
为了优化访问效率,需要对结构体已经联合体进行对齐的操作。
结构体对齐规则
结构体对齐需要满足下面两个条件:
- 当前成员的偏移量必须是自身对齐数的整数倍,不够则需要在前面进行填充。
- 整个结构体的大小必须是所有成员中,对齐数最大的整数倍。
对齐数:就是上面基本数据类型中的字节数,对于数组而言,它的对齐数依旧是基本数据类型中的数量,例如int arr[100];的对齐数是4,而不是400。
例如下面这个结构体
struct student
{char a;short b;int c;
};
printf("%d",sizeof(struct student));// 输出8
对于该结构体,第一个成员char类型,大小为1字节,因为是第一个成员,因此偏移量是0,对于第二个成员,为short类型,大小为2个字节,他前面已经有1个字节的位置被使用了,他如果接着上一个成员的话,那么他的偏移就是1,但是1不是2的倍数,需要填充一个字节在前面,使偏移量为2才行,对于第三个成员,为int类型,大小为4个字节,因为第一个成员大小是1,第二个成员在前面填充了1字节,再加上第二个成员自身也有2字节,因此此时前面4个字节都不能使用了,第三个成员此时可以接在下一个地址后面,因为此时对于第三个成员而言,他的偏移量是4,刚好是自身大小的整数倍。空间示意图如下:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| a | 填充 | b | b | c | c | c | c |
现在,结构体对齐的第一个规则完全满足,再来看是否满足第二条规则,此时通过上面的示意图可以看到,整个结构体的大小为8个字节,而结构体内的最大成员大小是4,8是4的倍数,因此第二个条件也满足。所以sizeof(struct student)的输出结果是8.
联合体对齐规则
首先需要说明的是,联合体中的成员只能使用一个,不能同时使用多个成员,因此整个联合体是共用同一块内存空间的,共用同一个地址。联合体的对齐规则也有两条
- 必须保证能容纳联合体中最大的成员
- 联合体的大小必须为联合体成员中最大对齐数的整数倍,这里的对齐数可以理解为数据类型的大小,例如int就是4,double就是8,跟是不是数组无关
例如下面这个联合体
union u1
{char a;short b;int c;
};
其中最大的成员是int类型,4个字节,如果该联合体的大小4即可同时满足上面两个条件。所以该联合体的空间大小为4;再来看一个例子
union u2
{char arr[5];short b;
};
其中最大的成员是char数组,大小为5个字节,如果此时联合体的大小是5个字节是可以满足第一个条件的,但是最大对齐数是short,2,此时5不是最大对齐数的整数倍,因此需要在后面进行填充1个字节,达到6字节,注意这里是在后面进行填充,而不是前面。具体示意图如下(假设是小端存储),其中一列代表2字节
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| arr | arr | arr | arr | arr | 填充 |
| b | 填充 |
大端小端模式判断
大端:高字节存储在低地址
小端:低字节存储在低地址
因为这里是假设小端存储的,但是实际上我们可以通过联合体的特性,推导出电脑中数据是按照大端还是小端方式的存储。
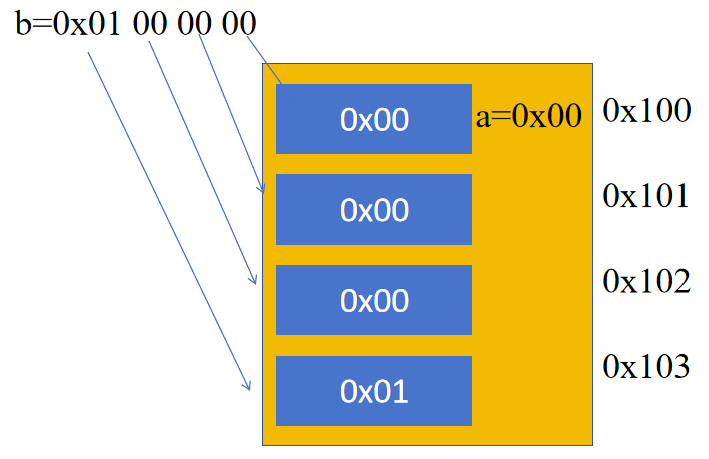
现在有如下代码:
union u2
{char a;int b;
};
int main()
{union u2 u;u.b=0x01000000;printf("%d\n",u.b);printf("%d %d\n",u.a,u.b); return 0;
}
输出结果为:
16777216
0 16777216
首先需要说明的是,对于一个数据,比如int类型的数据,系统分配空间时是分配的连续的四个字节给它的,并且在这段空间内,起始地址是低地址,比如系统分配了起始地址为0x100大小为4字节的空间,那么0x100、0x101、0x102、0x103,首地址一定是低地址的部分,也就是0x00,不要问为什么,这是规定。但是需要注意的是,首地址是低地址,不能代表字节的具体存储方式,因此只有这个信息是无法知晓大端还是小端模式。
接着来看上面的代码输出,第一次输出的是成员b的值,第二行分别输出的是成员a和b的值,因为我们知道,a和b是共用同一个地址空间的,这里我们只给b赋了初值,所以直接读取a的结果即可知道低地址(也就是a的首地址,同时也是b的首地址)存储的是高字节还是低字节。因为我们赋值给b的值是0x01000000,如果首地址存储的是低字节的话,那么读取出来的应该是0x00,如果首地址存储的是高字节的话,那么读取出来的应该是0x01,通过输出结果我们可以看到,读取出来的结果是0,说明首地址存储的是低字节,而首地址在一块连续的空间中是低地址,因此我们知道该系统是低字节存储在低地址,为小端模式。图示说明如下:
指针数组与数组指针
指针数组是一个数组,每个元素是指针;数组指针是指针,该指针必须指向同样大小的数组。
- []优先级高于*。
- 数组指针其实就是一个指针,并不是数组,后面的[4]只是用来限定需要指向的数组的大小的,而不是限定自己的。也可以把数组指针理解为一个被限定第二维数量了的双重指针,因为一般数组指针与二维数组的结合比较多,与一维数组的结合较少,一维数组可以直接用普通的指针即可。
// 指针数组
int*p1[4];
// 数组指针与二维数组结合
int arr1[3][2]={{1,2},{3,4},{5,6}};
int (*p1)[2];
p1=arr1;
printf("%d\n",p1[0][0]); // 访问二维数组的第一行第一列
// 指针数组与一维数组结合
int arr2[2]={6,8};
p1=&arr2;
printf("%d\n",p1[0][0]); // 访问一维数组的第一个元素
指针函数与函数指针
指针函数就是返回值为指针的函数,这个没什么好讲的。主要说一下函数指针。
首先在了解函数指针前,我们先说一下为什么要有函数指针,有时候我们想在一个函数中调用另一些函数,但是我们又不确定会调用哪一个,这个时候我们就可以使用函数指针,将一个函数的指针传入另一个函数,另一个函数此时就不用考虑具体做的是什么,而是直接调用这个函数指针完成对应的功能。
再来说函数指针,先回想之前的指针,比如整型指针int*,字符指针char*,他们存储的都是某个地址,而函数指针的本质其实也是地址,但与变量不同的是,该地址存储的是这个函数代码的地址,我可以通过这个地址依次查找下去,从而知道接下来的函数是做什么。
下面看一个函数指针的例子。这个例子对函数指针有两个不同用法,第一个是直接定义了一个函数指针,然后用这个函数指针去执行对应的操作。第二个是定义一个计算器函数,这个函数传入的是一个函数指针,从而可以在该函数内部执行不同的计算操作, 只需要在传入的参数中选择对应的操作函数即可。
int add(int a,int b)
{
return a+b;
}
int sub(int a,int b)
{
return a-b;
}
int caculator(int a,int b,int(*func)(int a,int b))
{return func(a,b);
}
int main()
{int a=3,b=2;int (*func)(int a,int b)=add;func(a,b);caculator(a,b,add);
}
指针常量与常量指针
以int类型的指针为例,在常量指针与指针常量中,int和*是不论如何都紧贴在一起的。先来看常量指针。const在int*前就是常量指针,const在int*后就是指针常量。记住以下规则:
1、指针常量必须在定义的时候就初始化
2、由第一条规则,容易知道,指针常量的指向位置不能变,否则不会要求在一开始就确定指向
3、常量指针指向可以改变,但是内容不能改变。
下面是例子:
int a=666,b=888;
// 指针常量 必须初始化
int*const p1=&a;
// p1=&b;是错误操作 初始化后就不能更改指向
// 常量指针
const int*p2;
p2=&b;
// *p2=a;是错误操作 不能更改指向的内容 p2=&a;是正确操作
总结技巧:不管是指针常量还是常量指针,都是指针,这一点是肯定的,关键就在于const修饰的是谁,那么怎么记忆const修饰的到底是指针还是值呢?可以在const后面的整体加上一个括号,可以看下面的代码块,此时是不是就很清晰了,const要确保的是后面的代码块的部分不能改变,我们可以先暂时把const去掉,对于p1,它其实就是一个指针,而int*p2,这不就是对指针进行取值吗?所以,对于指针常量,const修饰的是指针,因此指针不能变,对于常量指针,const修饰的值,因此内容(也就是值)不能变。
int* const(p1)=&a;
const (int*p2);
注意!const int * p和int const *p是一样的,都是常量指针,一般写法是第一种
malloc、realloc、calloc、memset、memcpy、memcmp函数
malloc
用于给指针分配空间,需要指定分配空间的大小,返回值默认是void*,必须进行强制类型转换,如果申请失败会返回NULL。
能否在1G的计算机中执行这样的代码?malloc(1.2G)
可以执行,虽然1.2G超过了真实的1G内存,但因为函数申请的空间并非真实的物理内存,而是虚拟内存,因此可以执行。
使用样例
int*p;
p=(int*)malloc(sizeof(int)*10);// 申请10个int大小的空间
realloc
用于对已经分配空间的指针进行重新分配,原始指针对应的空间数据会被自动移动到新的位置,增加的内存部分会自动赋值为0。
使用样例
int*p=(int*)malloc(sizeof(int)*1);
p[0]=1;
p=(int*)realloc(p,sizeof(int)*2);
// 此时p[0]=1 p[1]=0
calloc
和malloc作用类似,但是比malloc多了一步,malloc分配空间后没有初始化的操作,calloc分配空间后会自动进行初始化,默认初始化为0,此外语法也存在一些不同,下面是使用样例
// 分配两个int大小的空间
int*p=(int*)calloc(2,sizeof(int));
memset(void*s,int n,size_t size)
memset用于对连续的内存进行初始化,不局限于字符串、数组,还可以是结构体等数据。不过一般不用于数组的初始化,非要用一般也只能用于将内容初始化为0,因为该函数是以字节为形式进行初始化的,int类型是四个字节,直接使用memset进行初始化是无法对上原始数据的。
初始化字符串
char s[10];
memset(s,'6',10);
printf("%s\n",s); // 会输出"6666666666"
初始化数组,全部初始化为0
char arr[10];
memset(arr,0,sizeof(int)*10);
初始化结构体,全部初始化为0
struct Student {char name[20];int age;float score;
};
int main() {struct Student s;// 将结构体的所有字节设为0memset(&s, 0, sizeof(struct Student));printf("name: %s, age: %d, score: %.1f\n", s.name, s.age, s.score);// 输出:name: , age: 0, score: 0.0(所有成员被初始化为0)return 0;
}
void *memcpy(void *to, const void *from, size_t n);
用于将from中的内容复制到to中,赋值大小为n。是按字节复制,因此不限定复制的数据类型,字符串、数组、结构体等都可以进行复制。
复制字符串
char s1[100]="",s2[100]="123456";
memcpy(s1,s2,sizeof(char)*6);
printf("%s\n",s1);
复制数组
int arr1[3],arr2[3]={1,2,3};
memcpy(arr1,arr2,sizeof(int)*3);
printf("%d %d %d\n",arr1[0],arr1[1],arr1[2]);
复制结构体
struct Test*t1=(struct Test*)malloc(sizeof(struct Test)),*t2=(struct Test*)malloc(sizeof(struct Test));
t2->a=6;
t2->b=8;
memcpy(t1,t2,sizeof(struct Test));
printf("%d %d\n",t1->a,t1->b);
memcmp(void*a,void*b,size_t n)
用于比较两个变量的前n个字节的大小,如果a小于b,则返回-1,如果a等于b,则返回0,如果a大于b,则返回1。可以用于比较字符串、数组、结构体。
比较字符串
int res;
char s1[100]="123456",s2[100]="123456";
res=memcmp(s1,s2,sizeof(char)*6);
printf("%d\n",res); // 输出0
比较数组
int arr1[3]={0,0,0},arr2[3]={1,2,3};
res=memcmp(arr1,arr2,sizeof(int)*3);
printf("%d\n",res);// 输出-1
比较结构体
struct Test
{int a;int b;
};
struct Test*t1=(struct Test*)malloc(sizeof(struct Test)),*t2=(struct Test*)malloc(sizeof(struct Test));t1->a=1;t1->b=1;t2->a=0;t2->b=0;res=memcmp(t1,t2,sizeof(struct Test));printf("%d\n",res); // 返回1
strcat、strncat、strcmp、strcpy函数
这几个函数都必须包含头文件#include"string.h"
char* strcat(char*to,char*from)
在字符串to的后面拼接上from,并在末尾添加\0。
char s1[]="CSDN",s2[]="123456";
char*s=(char*)malloc(sizeof(char)*100);
s=strcat(s1,s2);
printf("%s\n",s);
char*strncat(char *to, const char *from, size_t n);
在字符串to的后面从字符串from顺序拼接n个字符,并在末尾添加’\0’。并返回拼接后的结果。
char s1[]="CSDN",s2[]="123456";
char*s=(char*)malloc(sizeof(char)*100);
s=strncat(s1,s2,3);
printf("%s\n",s);
strcmp(char*s1,char*s2)
按字典顺序比较字符串s1和s2的大小,如果s1==s2则返回0,如果s1<s2则返回负数,如果s1>s2返回正数
char s1[100]="A",s2[100]="B";
int res;
res=strcmp(s1,s2);
printf("%d\n",res);
strcpy(char*to,char*from)
将from中的字符串拷贝到to中,遇到 ‘\0’ 停止,不指定长度并返回拷贝结果
char s1[100]="",s2[100]="123456";
strcpy(s1,s2);
printf("%s\n",s1);
volatile、static、const、enum、#define、typedef、extern、aotu、register、sizeof
volatile:用于告知编译器该变量可能会被频繁使用,不要对该变量进行优化,在多线程中防止出现冲突,达到每次都是直接读取该变量的内存地址的效果,而不会先将变量进行缓存,避免了冲突的发生。
static:可用于修饰变量或函数,当修饰变量时,该变量只会初始化一次,也就是第一次初始化之后就不会再初始化了,例如我在一个函数中定义了这样的变量,static char i=0;i++;那么第一次执行这个函数时,会将i初始化为0.然后i++变为1,如果我再次调用这个函数,那么此时i不会再次初始化,而是函数一进来就是1,再次执行i++之后就变成2了。当修饰函数时,被修饰的函数只能在当前文件内使用,不可被外部文件使用。
const:一般用于修饰变量,使其成为常量。
enum:枚举类型,枚举类型的数据类型必须为整型,如果不对数据赋初值,则从第一个开始默认为0,依次递增,如果部分赋了初值,部分没有初值,那么没有赋初值的会自动赋值为前一个值+1;
#define:预处理命令,用于宏定义,本质上是文本替换,替换阶段会发生在预处理阶段,不会进行规则检查;
typedef:关键字,对一个数据类型进行重命名,一般用于结构体的重命名,与#define不同,typedef会进行规则检查,防止语法出错。
extern:与static类似,一般用于修饰变量或函数,起到声明的作用。当用于修饰变量时,表示这是一个全局变量,当用于修饰一个函数时,表示这是一个全局函数,可以被外部文件使用。一般来说,在.h文件中对函数的声明是默认带有extern的,只不过一般可以不加extern,除了这种情况,其他情况的声明都必须加extern关键字。注意extern只能是声明的作用,不起到定义的作用,使用extern进行声明时,不能同时定义,声明和定义必须分开,例如
// 正确
extern int a;
int a=1;
这样是规范的,如果在声明的同时又定义了,那么编译器会默认只有定义的作用,没有extern声明。
// 错误
extern int a=1;
auto:一般情况下,局部变量都是auto类型,不需要手动添加该关键字,此时数据是存储在栈中。
register:用于声明变量存储在寄存器中,即cpu内部,而非内存,使用register定义的变量不能进行取地址操作,因为寄存器没有地址。
sizeof:sizeof可以计算数据的大小,例如计算整型数据的大小,浮点型数据的大小,结构体的大小,单位是字节。
下面这段代码中,输出的i是1,而不是2,因为在sizeof中不会执行i++操作,sizeof只会计算空间大小,而不会执行里边的代码
int i=1;
sizeof(i++)
printf("%d",i);
四大内存区:堆区、栈区、全局/静态区、代码区
堆区:堆区中的数据由用户手动分配和释放,申请的空间不连续,空间上堆区的内存较大,但是效率低,在地址顺序上,堆区分配的地址顺序是依次增加的。
栈区:栈区是由系统自动申请和释放的,通常是连续的区域,空间上栈区的内存较小,但是效率高,在地址顺序上,栈区分配的地址顺序是依次减小的,通过下面的代码可以发现b的地址是比a的地址小4的。需要说明的是,在前面大端小端那里提到了数据的首地址是低地址,后面地址依次增加,但是到这里为什么又说是地址减小的呢?其实这是因为这里的地址是指在栈区上对不同数据起始地址的分配是减小的,比如在下面这段代码中,依次分配了a和b两个整型变量,他们的地址是减小的。但是前面说的起始地址是最低的,后续地址依次增加指的是对于分配了的整块数据而言,它的内部是由低到高来使用的。这两个是完全不同的情况,栈区对于变量地址的分配顺序,一个是变量内部地址的顺序,他们俩是互不影响的。
int a;
int b;
printf("%d %d\n",&a,&b);
全局/静态区:用于存储全局变量、静态变量、常量,只读,不可修改,强行修改会导致程序崩溃。
代码区:用于存放程序的二进制代码。
分区与内存的关系
代码区、全局/静态区的内容都是不能更改的,因此他们的初始值是放在flash(ROM)中的,程序启动时会将其从flash中拷贝到ram中,其中全局变量和静态变量是可以修改值的,这是因为他们的数据本体是在ram中的,只不过初始值在flash中,程序初始化的时候会将其拷贝一份到ram中,对于原本在flash中的全局变量、静态变量都是不能修改的,后续修改操作都是对ram中的数据进行的修改。
栈区、堆区里的内容可以修改,是放在ram中的。本质上,所有变量的本体都是放在ram中的,而之所以说他们是在flash中,是为了因为初始化的时候位置不一样。
全局变量与静态变量的深入认识
对于静态变量,static int a=6;很确定的是它就是在全局/静态区的,也就是flash区域,我们是没办法对该静态变量进行修改的,但是为什么全局变量也是在全局/静态区呢?一般我们是会对全局变量进行修改的,那么为什么又说它是存储在flash中的呢?这么说难道不是自相矛盾吗?其实不然,准确来说,应该这么讲,全局变量的初始值会作为一个无法修改的内容存储在flash中,初始完成后,程序会将flash中的初始值复制一份到ram中,此后,程序对全局变量所有的操作都会在ram中的本体上进行,这么做的意义就是为了在程序一开始为全局变量指定一个值。
其实把Flash中的数据叫副本,把RAM中的数据叫本体总感觉有点本末倒置的感觉,因为它们毕竟是在Flash中出生的,RAM中的是后来才拷贝过去的,但是一般都这么叫,也只能将错就错吧。。。
已初始化和未初始化的静态变量
static int a=6;
static int b;
已经初始化的静态变量在程序烧录期会将值保存在falsh的.data数据段中,程序启动时数据会被拷贝到ram中的.data数据段中,后续的操作实际上都是在对ram中的副本进行的操作。
未初始化的静态变量在程序烧录期是不会占用flash空间存储具体值,程序启动阶段会自动将没有初始化的静态变量初始为0。
全局变量的初始化也与上面相同。
对于全局变量和静态变量,Flash中存储的是变量的副本,RAM中存储的是变量的本体。任何对变量的操作都是对RAM中的数据进行的修改。
对于常量而言,由于常量是不能进行修改的,因此常量是直接存储在Flash中的,不会将常量拷贝到RAM中。
include<test.h>与include"test.h"的区别
用尖括号括起来的代表该头文件是系统文件,编译器将优先从标准库下进行搜索,如果你非要使用双引号来包含系统头文件的话,也可以,因为编译器找不到的时候会自动回到标准库进行搜索。如果是自己定义的头文件则需要使用双引号引入,代表是用户自定义的头文件,编译器将优先从当前文件目录中进行搜索。
.data段和.bss段
这两个段都是程序在RAM区开辟的用于存放全局变量和静态变量的地盘,它们的根本区别在于全局变量或静态变量是否有初始值。
对于.data段而言,它存放的是已经初始化的不为0的全局变量和静态变量,它们具有双重身份:
- 在Flash中存放着它们初始值的副本
- 在RAM中存放着它们运行时的本体
对于.data段,在main执行前,启动代码会将Flash中.data段的初始值拷贝到RAM中的.data段
int global_var = 100; // 进入 .data 段
static int static_global_var = 200; // 进入 .data 段
void func()
{static int static_local_var = 300; // 也进入 .data 段
}
对于.bss段而言,它存放的是未初始化的全局变量和静态变量,未初始化指没有给该变量赋初值,或显式地赋值为0,此时Flash中不会存储它们的初始值,因为全是0,存了也浪费空间,链接器只记录.bss段的大小和位置信息,当程序启动时,在执行main之前,启动代码会将RAM中整个.bss段对应的区域清零,这也是为什么未初始化的全局变量和静态变量的值都为0的原因。
这么做的原因是为了节省Flash空间,并加快启动速度。